以标准和数据为支撑的一致性质量分析应用机制研究
2022-07-28内燃机可靠性国家重点实验室潍柴动力股份有限公司李松五李明磊贺秀娜赵久滨
内燃机可靠性国家重点实验室 潍柴动力股份有限公司 □李松五 李明磊 贺秀娜 王 亮 赵久滨
1 背景
在掀起品质革命,打造精品工程背景下,科学合理地分析供方过程保证能力,发掘改进点推动精准改进,提升产品一致性是业务模式变革的重点。目前企业较多关注符合性质量(合格与否),对合格产品的质量波动、产品一致性情况缺乏细致研究。没有对检验数据进行分析利用,数据的价值没有真正体现出来。具体表现在以下方面:
1)因缺少DFMEA的传递,无法充分有效识别质量控制风险,同时零部件检验指导书依据师徒传承的方式进行编制、更新和执行,通用性差且没有固化,质量探测项目未实现标准化。
2)检验数据无法实时采集,不便于统计分析;无有效的手段实现检验数据自动式一致性分析,无法根据数据波动实施预警和动态监控,预防性管理能力不足。
3)传统的过程分布模型假设分布中心不变,离散不变,即默认为数据样本瞬时分布是同一个分布,这是非常理想的过程分布模型。在来料抽检环节,大部分检验数据的瞬时分布是变化的,特别是对于单边公差特性,多数不服从正态分布。离线版分析软件均无法对非正态分布的过程绩效指数进行精准计算,分析结果偏差较大,数据一致性分析结果真实性不足。
2 整体思路
以标准化的探测项目为依据,以质量管理系统为支撑,实现探测项目、检验数据的标准化、智能化管理。
依托一致性分析系统工具,建立多分布自动匹配的数据分析模型,搭建数据一致性分析与监控平台,对检验数据进行一致性分析,实现质量特性过程绩效指数实时展示,供方一致性水平多维度分析,定期矩阵化推送分析结果。
依据一致性分析情况,对异常波动数据、过程绩效指数不达标零件及供应商进行预警,为各环节改进、供方质量提升提供支持。
3 主要做法
(1)检验计划策划与实施
设计、工艺、采购、质量部门组成多功能小组,识别每类零部件来料探测项目,对探测项目进行标准化处理,建立质量检验标准库,形成企业标准。制定包含检验特性、量检具、工作站等属性的检验计划,在WQS系统形成以件号、供方编码为惟一标识的检验订单,指导开展检验工作。
(2)检验执行与数据采集
依据在WQS系统中部署的检验频次动态规则和抽样规则,以来料入库产生的检验订单为驱动。各工作站检验人员依据指派任务在WQS系统内开展检验工作。检验现场配置无线传输量具,依托智能测量技术,实现检验数据自动上传,规避人为因素影响。
(3)一致性分析
基于生产计划和抽检经济性的考虑,来料检验环节抽取的样本与供方生产批次没有明确的对应关系,抽取时间、数量及频次不符合统计控制原则,对于单值总体偏离正态分布比较严重的情形,即使应用中心极限定理,所得到的子组均值分布也仍然不能近似服从正态分布。因此仅使用基于正态分布的过程绩效指数计算方法已不合适,需寻求更加合适的方法,对非正态分布下过程绩效指数进行计算。
田志友等著《非正态过程能力指数研究中的几个问题》对非正态过程能力指数估计方法进行了总结,包括数据转换方法、曲线拟合方法、经验分布方法、广义能力指数计算方法。广义能力指数计算方法是对基于正态分布的过程能力指数进行一般化,重新定义能力指数的计算公式,然后将其应用到不同的随机分布条件下。本文基于ISO 22514-2∶2017《过程管理中的统计方法 能力和性能:时间相关过程模型的过程能力和性性》、ISO 22514-4∶2016《过程管理中的统计方法 能力和性能:过程能力估计和性能测量》标准,结合探测项目类型及单/双边公差要求,采用广义能力指数计算方法,建立多分布自动匹配的数据模型,制定基于正态分布和二项分布的判稳原则。
1)质量特性匹配分布模型
按照质量特性类型匹配初始分布,对应关系见表1。其他通用双边公差特性默认正态分布,单边公差特性默认威布尔分布(概率密度函数见图1)。
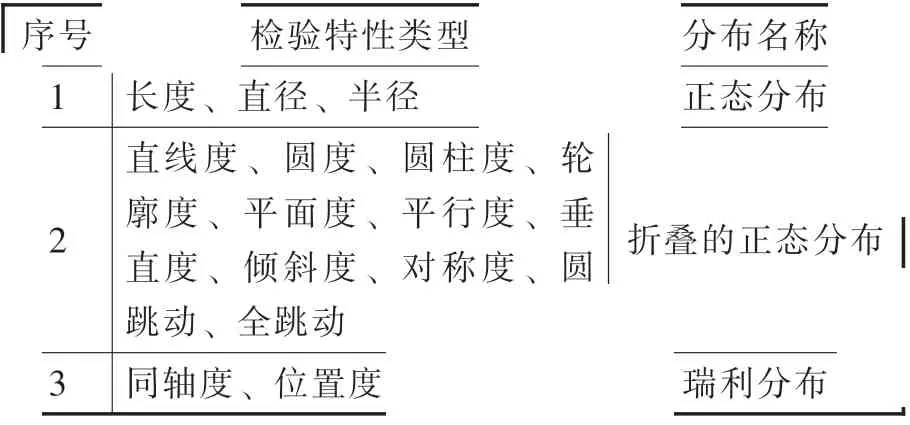
表1 质量特性与分布函数初始对应关系

图1 威布尔分布概率密度函数
2)假设检验
运用统计分析方法,可对总体参数的某个命题所构成的假设做出拒绝或接受的判断。对于机械加工制造过程,一般很难通过直观图形判断某质量特性的分布情况,往往使用非参数检验方法进行假设检验。本文假设检验内容见表2。
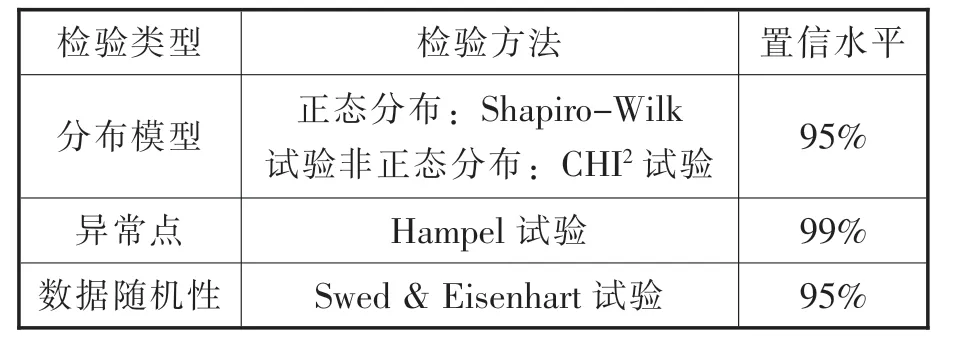
表2 假设检验内容
3)选取最优分布
若通过假设检验,选取最初匹配的分布模型;若未通过假设检验,从分布模型库(对数正态分布、折叠正态分布、瑞利分布、混合分布等)中寻找合适的分布模式,计算回归系数,选择匹配性最好的分布。
4)判定数据稳定状态
若检验数据未超差,且控制界限之外的数目未超出Binomial分布的偶然离散带的界限,则数据处于稳定状态。若数据处于非稳定状态,控制图中显示具体数值、检验人员、检验时间、量检具等信息,便于查找、确认异常因素。
5)计算过程绩效指数
针对数据不服从正态分布的情况,Clements(1989)提出了一种计算过程能力指数的通用化公式,见式(1)。

其中,θ=θμ-θl。
Rodriguez(1992)提出了利用数据拟合方法对非正态数据进行处理,并给出广义能力指数的计算公式,见式(2)、式(3)。
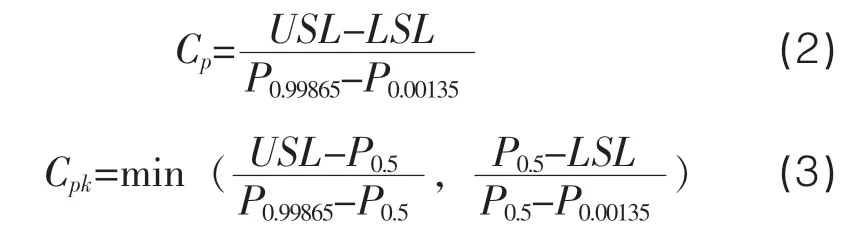
ISO 22514-2标准提出利用分位数法/百分位法计算广义过程绩效指数Ppk。利用概率密度函数下侧分位数X0.135%、上侧分位数X99.865%计算过程变差宽度。对于正态分布,其偏离均值-3σ、+3σ的分位点恰好分别等于正态分布的下侧分位数X0.135%、上侧分位数X99.865%。
上、下侧分位数计算原理,见式(4)、式(5)。

其中,p(x):概率密度函数;X0.135%:下侧分位数;X99.865%:上侧分位数。
ISO 22514-4标准提出简化计算方案,首先计算该分布的偏度系数和峰度系数,然后在Pearson分布族表中查找对应分位点,计算上下侧分位数。
单侧下限过程绩效指数,见式(6)。

单侧上限过程绩效指数,见式(7)。

实际过程绩效指数,见式(8)。
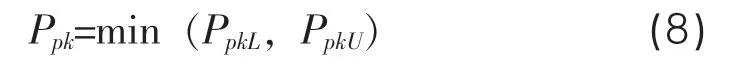
其中,Xmid:位置参数;△:变差参数。
ISO 22514-2列出了不同时间分布的模型、主要特点及适用于不同时间分布的计算方法。计算方法见表3。

表3 不同时间分布模型的计算方法
本文基于采购产品来料特点、数据采集方式,选取适合的计算方法。若服从正态分布,位置参数Xmid采用样本均值,选择第一种计算方法;若不服从正态分布,位置参数Xmid采用样本中位数,选择第二种计算方法。
位置参数第一种计算方法,见式(9)。

位置参数第二种计算方法,见式(10)。
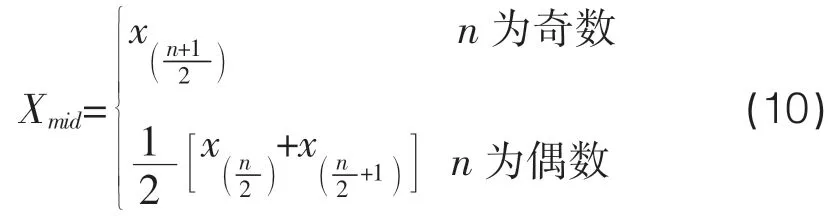
变差参数的计算方法,见式(11)、式(12)。


其中,xi:测量值;n:测量数量;k:子组数量。
6)一致性分析结果展示及应用
利用Ppk对同一件号零件不同供应商的一致性水平进行分析,对同一供应商不同零件的一致性水平进行分析;利用Ppk达标率评价供应商过程保证能力。达标率计算公式见式(13)。

利用信息化手段对各业务系统进行集成,实现检验数据自动传输至分析系统,分析报告及报表实时传输至质量管理系统,进行逻辑运算及多维度展示,通过设置不同查询条件,查阅、展示分析结果。一致性分析模块展示界面见表4。
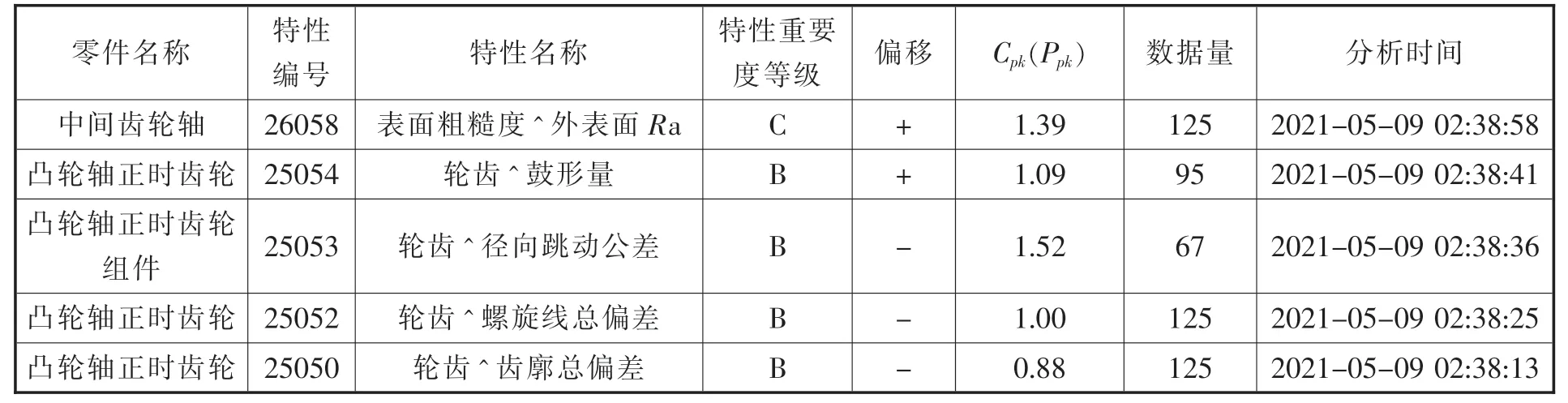
表4 部分零件质量特性Ppk分析结果
针对一致性分析结果不达标的零件、特性,生成一致性分析报表,基于质量技术人员分工矩阵表,按零件分工定期矩阵化推送邮件提醒,关注异常波动。邮件提醒格式包括主要为供应商、零件名称、零件件号、质量特性、是否达标、实际Ppk、最优Ppk。
4 效果及意义
建立了检验数据自动采集与一致性分析模型,实现了检验项目的标准化,提高了数据分析准确性和效率,为检验方法优化、产品一致性质量提升提供数据支撑,填补了企业一致性分析与管控的空白,是企业质量管理模式里程碑式的转变。
结合概率论、SPC知识,利用大数据分析技术实现了质量数据复杂分析的常态化,为企业其他相关领域数据的深入监控和分析提供了参考方案。该模式不仅适用于零部件一致性质量管控,更适用于制造过程的一致性质量管控。
5 下一步研究方向
推行供应商质量管控前移,供应商现场部署数据在线采集功能,自动采集制造过程数据,监控供应商制造过程质量表现,分析结果实现快速共享。
规范供应商生产批次与供货批次的关系,调整来料检验模式及重点,提高检验有效性;基于产品阶段及Ppk表现,推行供应商质量免检信任机制。
