一种基于特征融合的医疗病例实体识别方法
2022-07-26帅英杰
帅英杰
(广西民族大学 人工智能学院,广西 南宁 530006)
医疗病历用于患者临床治疗过程中,是临床科学诊断治疗的基础材料[1]。医疗病历中包含大量的实体数据,可通过命名实体识别技术识别出其中有价值的数据,这些数据对医学数据挖掘具有重要意义。命名实体识别主要任务是在大量的文本中识别出有利用价值的实体数据。早期的命名实体识别模型主要有LaSIE-II、NetOwl等,早期的命名实体识别模型基于规则、词典或在线知识库等进行识别。基于规则的方法大多为相对固定的模型,主要包括字符串匹配和模式等,这些模型往往相对复杂,而且复用性较差。随着科学技术的发展,命名实体识别技术逐渐从基于规则的方法转向基于神经网络的方法。深度学习网络模型被证明在命名实体识别任务中表现更佳。其中,基于双向长短时记忆网络结合条件随机场[2](BiLSTM-CRF)的网络模型是命名实体识别中经典的模型结构。近几年,词嵌入技术被广泛地应用到自然语言处理的各项任务中,词嵌入技术就是将自然语言中的词转化为计算机可以识别的向量或矩阵形式,以便计算词语语义的相似程度[2]。传统的词嵌入技术Word2vec在进行语义表征时存在使用的词向量较为单一、提取特征相对不充分等不足,导致出现了计算机在识别过程中对词语语义理解不准确等问题。本文提出一种基于语义、词序、双向transformer编码模型(BERT)预训练模型相结合的多特征融合的提取方法,该方法中的神经网络模型采用双向长短时记忆网络结合条件随机场(BiLSTM-CRF)进行医疗病历的命名实体识别研究。该方法解决了传统网络模型对特征提取不充分等问题,同时可提升模型识别的准确率。
一、相关工作
医疗病历文本的命名实体识别主要包括以下3个步骤:首先对医疗病历的文本进行特征提取,其次通过神经网络模型对特征进行学习,最后进行医疗病历中命名实体识别及模型识别精确度的计算。
(一)命名实体识别方法
基于规则、词典或在线知识库进行识别,是早期的命名实体识别方法。这些方法运用语言学家手工构造的语言规则进行工作,对语言规则具有较强的依赖性,并且方法本身具有一定的复杂性。较为著名的基于规则的命名识别系统有LaSIE-II、NetOwl、Facile等。Alfonseca E和Manandhar S提出了一种基于WordNet的实体分类方法,WordNet区别于普通词典之处是词义根据语义而不是词形来组织词汇信息,WordNet相当于一部语义词典。这些基于规则和词典的方法往往是由人工编写的,并且大多数规则相对固定,在遇到新的问题时,往往需要编写新的规则来处理。由于医学领域的规则和词典并不完整,后期对词典和规则进行补充和完善的难度也比较大。另外,不同细分医学领域的规则不能通用,所以此类方法往往难以推广到其他领域。
随着科技的进步,基于深度学习的命名实体识别方法被广泛应用于自然语言处理的各项任务中,并取得了显著成效。张海楠等人提出了一种用于深度学习框架的字词联合方法,此方法将字特征和词特征结合起来,既弥补了词特征分词错误蔓延和字典稀疏的不足,又改善了字特征因固定窗口大小导致的上下文缺失[3]。李正民等人针对传统字向量难以表达上下文语义以及抽取的特征较为单一等问题,提出基于BERT(Bidirectional Encoder Representation from Transformers)的多特征融合模型BERT-BiLSTM-IDCNN-Attention-CRF,该模型通过BERT建模字向量的上下文语义关系,并融合双向长短时记忆网络(BiLSTM)和迭代膨胀卷积(IDCNN),分别抽取上下文特征和局部特征,使两种特征进行互补以提升实体抽取效果[4]。相对于传统的命名实体识别方法,基于深度学习的命名实体识别方法更具有灵活性,且节省了人工编写规则的成本;在识别过程中,不再局限于有限的规则,大大提高了命名实体识别任务的效率。在基于深度学习的命名实体识别方法中,较经典的是基于双向长短时记忆网络结合条件随机场的方法。其中,双向长短时记忆网络是改进的循环神经网络(RNN)模型,条件随机场是一种隐马尔科夫模型(HMM)的改进方法,该模型在命名实体识别任务中表现出较为出色的效果,可较好地提升模型识别的精确度。
近些年,词嵌入技术被应用到自然语言处理的各项任务中,传统的词嵌入技术包括Word2vec、Fasttext等。Word2vec主要针对的是语义提取,包括Skip-gram模型和CBOW模型,二者都是依据上下文语境来预测词语的语义。其中,Skip-gram模型是以一个词语作为输入来预测它周围上下文的语义。CBOW模型是以一个词的上下文作为输入,来预测这个词本身的语义。Word2vec本质是把词语从one-hot编码形式降维成Word2vec编码形式。Fasttext模型主要针对词序的提取,它的优点不仅是在模型训练时间上比深度网络要快得多,而且在分类任务中能取得与深度网络相接近的精度。Fasttext的主要实现方法是将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做Softmax多分类[5]。随着深度学习模型的发展,Vaswani A等人提出了Transformer机制。Devlin J等人进一步提出了基于Transformer机制的BERT模型。该模型主要是以动态的方式获取词向量的语义,解决了传统Word2vec无法解决的一词多义问题。因此,笔者提出一种特征融合的词向量提取方式,将Word2vec、Fasttext、BERT 3种技术获取的词向量进行融合,再通过卷积神经网络把融合的词向量进行再提取,从而获得更加有意义的数据特征。
(二)研究动机
提取医学领域的实体对医疗信息挖掘有较大的价值。如何针对医疗病历文本进行多方面的特征提取至关重要,且如何能更加精确地提升医疗实体识别模型的识别效果也同样关键。为此,笔者提出一种多特征融合结合神经网络的命名实体识别方法进行医疗病历实体识别,该方法包含了对词序特征、语义特征的提取,并且加入了BERT预训练词向量提取动态语义特征。该方法在保证多方面提取医疗病历实体特征的同时,提高了识别的精确度。
二、多特征融合模型
针对医疗病历文本中的数据特点,本研究提出一种多特征融合结合双向长短时记忆网络以及条件随机场的命名实体识别方法。传统的Word2vec方法重视语义表达,利用词语在相同语法中的语义相同这一特点,把相同的词语编码为相同的词向量,无法表达一词多义的情况,且与单词出现的上下文位置有关,忽略了词语在文本中的顺序问题。为此,引入Fasttext提取词序词向量,通过BERT预训练词向量解决词语中出现的一词多义问题。相对Word2vec而言,BERT生成的词向量表示是由词周围的词动态通知的,因此可以更加精确地表达词语的意思。多特征融合模型的架构如图1所示。

图1 多特征融合模型
(一)特征融合层
在特征融合层中,本研究使用Word2vec提取语义词向量,该方法通过词语的上下文来预测中心词的语义或者根据中心词来预测上下文的语义,再使用Skip-gram模型并根据上下文预测中心词的语义。使用Fasttext提取词序词向量,该方法根据输入文本的词序来获取词语对应标签的预测概率,并根据此概率构建哈夫曼树,再将哈夫曼树的输出作为最终的词序向量。通过BERT预训练模型获取BERT预训练词向量,解决语义上一词多义的问题。最后本文通过cat的链接方式将3种词向量进行融合,得到融合后的特征词向量。特征融合模型结构如图2所示。

图2 特征融合模型
(二)BERT预训练词向量
BERT发布于2018年末,是一种预训练语言表示的方法,该模型可以免费下载和使用,可以用于自然语言处理的任务中,也可从文本中获取高质量的数据特征。使用者可以使用自己的数据进行模型参数的微调,来完成命名实体识别任务。BERT模型使用双向Transformer作为模型的主要框架,该模型能从双向捕获句子中词语的语义,它使用遮蔽语言模型和下一句预测进行预训练,可充分利用上下文信息,产生语义更丰富的动态词向量,解决一词多义的问题,以获取更能表征语义特征的词向量。另外,BERT底层应用Attention机制编码单词和上下文的相关性,增强了模型的并行计算能力。因此,笔者使用该模型生成预训练词向量。
(三)文本卷积神经网络层
笔者引进了文本卷积神经网络来对融合后的特征进行再提取。卷积神经网络主要是对文本局部特征进行提取,其结构主要包括数据输入层、卷积层、池化层、激活层以及全连接层等。笔者使用卷积操作的卷积核大小分别为2、3、4,每个尺寸的卷积核个数为2,共得到6个特征向量。通过全连接层将不同卷积核得到的特征向量进行拼接得到组合字符特征向量,最后通过Softmax层进行分类。文本卷积神经网络的结构如图3所示。
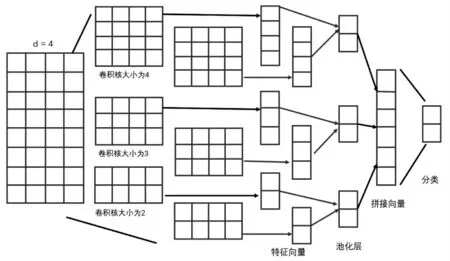
图3 文本卷积神经网络模型
(四)长短时记忆网络结合条件随机场模型
为了提高实体识别模型的识别精确度,笔者在模型的后面拼接了双向长短时记忆网络结合条件随机场模型(BiLSTM-CRF),该模型包括双向长短时记忆网络模型和条件随机场模型。其中,双向长短时记忆网络模型能很好地提取文本的上下文特征,条件随机场用来进行实体识别的任务。该模型结构如图4所示。

图4 BiLSTM-CRF模型
三、实验
(一)实验数据及字词特征
1.数据集简介及标注
此实验中,使用生物医学文本挖掘任务语料库(ChineseBLUE)。该语料库由不同的生物医学文本挖掘任务和语料组成,涵盖了各种文本类型和不同大小的数据集,具有较高的实用价值,因此使用该语料库进行实验的结果具有较好的可参考性。此实验使用的数据集为该语料库中医疗病历文本数据集(cMedQANER),该数据集包括疾病、药物、综合征等25个分类标签,采用传统的“BIO”标注规则,结合医学领域的特定情况,给出了较为详尽的医学领域的标签。具体的分类标签如表1所示。

表1 医学领域实体标签分类及解释
2.数据集预处理
此实验对数据进行了数据格式转换和数据清洗工作,过滤掉文本中的空格、字符表情符号等无意义的数据内容,以便获取更高质量的数据,同时也保证了实验结果的客观性。
(二)实验评价指标
命名实体识别任务通常采用的评价指标为精确率(Precision)、召回率(Recall)和F1-Measure 3个评价指标。各评价指标的计算公式分别如下文的(1)(2)(3)所示,其中P、R、F1分别表示精确率、召回率、F1-Measure:

(三)实验环境及参数设置
此实验中,实验环境为RTX8000、CUDA9.2,开源的框架选用Python3.8和Pytorch1.8.0。实验参数的设置分别为:语义词向量训练模型为Word2vec,使用Skip-gram算法,训练窗口大小为5,词频小于1次的词被丢弃,使用HS的方法,词向量维度为512,训练轮次为50轮;词序词向量训练模型为Fasttext,训练窗口大小为5,词频小于1次的词被丢弃,词向量维度为512,训练轮次为50轮;双向长短时记忆网络(BiLSTM)设置为2层,输入词向量大维度为512,每个批次读取数据的大小为64,Dropout为0.5,隐藏层的维度为1024。模型的训练轮次为50轮,神经网络模型的学习率为0.001,优化器采用Adam优化器。
(四)实验结果与分析
此实验采用的网络模型是由Word2vec、Fasttext、BERT多特征融合结合双向长短时记忆网络加条件随机场模型的方式实现,实验数据集为ChineseBLUE语料库中提供的命名实体识别任务数据集(cMedQANER),此实验共设计了4组对照实验,将BiLSTM-CRF、Word2vec-BiLSTM-CRF、Fasttext-BiLSTM-CRF和Word2vec-Fasttext-BERT-BiLSTM-CRF等用于命名实体识别的模型进行对比实验,实验对比结果如表2所示。
由于Word2vec能更好地提取语义特征向量,Fasttext能更好地提取词序向量,BERT预训练词向量可以解决Word2vec无法实现的一词多义的问题,笔者将三者进行拼接,以更好地捕获文本特征,由表2的BiLSTM-CRF、Word2vec-BiLSTM-CRF、Fasttext-BiLSTM-CRF和Word2vec-Fasttext-BERT-BiLSTM-CRF可以看出,拼接后的模型相比其他模型,其F1-Measure、精确率(Precision)、召回率(Recall)等评价指标均有一定的提升。最后,由于卷积神经网络能更好地提取有价值的数据特征,笔者将融合之后的特征向量再经过卷积层,然后将经过卷积层输出的特征向量输入到BiLSTM-CRF神经网络模型中进行标签预测,可发现笔者构建的模型(Word2vec-Fasttext-BERT-CNN-BiLSTM-CRF)相比其他模型在精确度、召回率和F1-Measure的评价指标上都有一定的提升。

表2 Chinese BLUE中c Me dQANER数据集测试结果
结 语
命名实体识别是自然语言处理中一个较为高级的任务。首先,此次实验将语义向量、词序向量、BERT预训练词向量进行拼接,实现了多特征融合。其次,实验将融合的特征经过了卷积层,实现了特征的进一步提取,提取更有价值的数据特征。最后,实验证明此方法在医疗病历文本的实体识别任务上表现出了更佳的识别效果,在各评价指标上有一定的提升。在今后的研究中,研究人员可以提升模型的训练速度,实现GPU的并行运行,节约时间成本。
