基于机器算法的药材种类与产地鉴定
2022-07-26冯超玲梁家伟刘存涛韦儒和
冯超玲,何 力,梁家伟,刘存涛,韦儒和
(1.广西职业技术学院 大数据学院,广西 南宁 530226;2.南宁师范大学 数学与统计学院,广西 南宁 530001)
中药材是中医防治疾病的物质基础,药材的质量和药性,直接关系着人民群众的身体健康和生命安全,因此关于中药材质量和药性的研究受到广大医药工作者的关注。不同中药材表现出的光谱特征差异较大,而来自不同产地的同一种药材,因其无机元素的化学成分及有机物等存在差异性,在近红外、中红外光谱的照射下也会表现出不同的光谱特征,因此对中药材进行鉴定是非常重要的。
目前关于利用某种物质的光谱数据解决其品质鉴定问题的研究,更多的是关于物质的产地鉴定、活性成分的含量测定、结构鉴定和定性鉴定。例如:利用中红外光谱技术(Mid-infrared spectroscopy,MIR)结合支持向量机(Support Vector Machine,SVM)建立模型解决山茱萸的产地鉴定和活性成分的含量测定问题[1];利用红外光谱法对煤(除无烟煤)的种类及产地进行鉴定[2];利用近红外漫反射光谱结合模式识别方法解决6种易混淆根茎类中药材的定性鉴定问题[3];通过红外光谱等技术对10种大米的整体红外特征吸收峰进行分析[4];采用中红外光谱开展芝麻油的结构研究,拓展MIR光谱技术在重要农产品结构鉴定的研究范围[5]。上述研究和解决的问题,是利用物质的一种光谱数据对它的某一品质进行鉴定。但是,在国内同时利用近红外、中红外光谱数据对某种物质进行鉴定的文献并不多,因此同时利用两种以上的光谱数据去鉴定物质的品质,是一个值得研究的课题。
对于中药材而言,最重要的是对药材种类和药材品质的鉴定,而中药材的道地性是以产地为主要指标,所以产地的鉴别对于药材品质鉴别显得尤为重要。然而,不同产地的同一种药材在同一波段内的光谱比较接近,使得光谱鉴别的误差较大。另外,有些中药材的近红外光谱区别比较明显,而有些药材的中红外光谱区别比较明显。当样本量不够充足时,可以借助近红外和中红外的光谱数据来相互验证,对中药材产地进行综合鉴别。本文研究的问题是根据中药材的近红外、中红外光谱数据[6],借助基于Python实现的K-means聚类算法和机器学习中的监督学习SVM,解决药材的种类或产地的鉴定问题。
一、机器学习算法
机器学习(Machine Learning,ML)是一门多领域交叉学科,是人工智能技术的核心,它涉及数据挖掘与分析、统计学、概率论、神经网络、逼近理论、系统辨识、优化理论、计算机科学、脑科学、算法复杂度理论等多门学科和多种理论。该学科专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,从而不断改善自身的性能[7]。传统的机器学习是利用经验改善系统自身的性能,现在的机器学习更多是利用数据改善系统自身的性能。基于数据的机器学习是现代智能技术中的重要方法之一,它从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。目前机器学习的应用十分广泛,例如数据挖掘、语音和手写识别、计算机视觉、自然语言处理、搜索引擎、生物特征识别、医学诊断、DNA序列测序、战略游戏和机器人运用等[8]。
机器学习算法可以分为3大类:监督学习、无监督学习和强化学习。监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习可用于一个特定的数据集(训练集)具有某一属性(标签),但是其他数据没有标签或者需要预测标签的情况。常见的监督学习算法包括回归分析和统计分类,主要应用于分类和预测。无监督学习又称归纳性学习(Clustering),利用K均值聚类(K-means)建立中心(Centriole),通过循环和递减运算(Iteration&descent)来减小误差,达到分类的目的。无监督学习可用于给定的没有标签的数据集(数据不是预分配好的),目的是找出数据间的潜在关系。强化学习位于两者之间,每次预测都有一定形式的反馈,但是没有精确的标签或者错误信息[9]。
SVM属于监督学习,它是一种建立在统计学习理论基础上的机器学习方法,能非常有效地处理分类问题。通过学习算法,SVM可以自动寻找那些对分类有较好区分能力的支持向量,由此构造出的分类器可以最大化类与类的间隔,因而具有较好的推广性能和较高的分类准确率[10]。
K-means聚类算法属于无监督学习中聚类问题的一个重要算法,是数据挖掘中的一个重要研究领域,广泛应用于天文学、商务、生物学、地质统计学等领域,作为其他算法的预处理。K-means聚类算法也称为K均值聚类方法,是一种划分聚类分割方法。其划分方法的基本思想是:给定一个有N个元组或者记录的数据集,利用分裂法构造K个分组,每一个分组就代表一个聚类,K<N。并且,这K个分组需要满足下列条件:1.每一个分组至少包含一个数据记录;2.每一个数据记录属于且仅属于一个分组。
对于给定的K,算法首先给出一个初始的分组方法,然后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次更好。而判断“好”的标准是:同一分组中的记录越近越好(即已经收敛,反复迭代至组内数据几乎无差异),而不同分组中的记录越远越好。
二、药材种类的鉴定
此部分依据药材的中红外光谱数据对药材种类进行鉴定。根据几种药材的中红外光谱数据来研究不同种类药材的特征和差异性,并鉴定药材的种类。因此需要寻找数据指标来区分药材的种类,并使得不同种类的药材之间能有明显的区分度,即需要选择合适的方法和衡量指标来计算药材的指标值,然后根据每种药材的数据指标特征及其差异性对药材进行种类划分。此部分采用K-means聚类算法来解决药材的种类鉴定问题。
一般地,可以考虑对每种药材在不同光谱波数下的吸光度数据进行分析讨论,画出不同种类的药材在不同波数下吸光度的二维曲线图,通过光谱数据的二维曲线图来分析药材的数据特征和差异性,从而解决药材的产地鉴定问题。由于只给定一部分药材的种类,但需要根据这些已给定种类的药材光谱数据研究药材的特性,并解决其他药材的种类鉴定问题。因此,需要对所有药材在不同光谱波数下的吸光度数据进行可视化处理,由可视化结果可以看出,有3条曲线跟其他药材的曲线有很大的差异。由于不同药材表现的光谱特征差异较大,故本研究将这3条差异较大的曲线当成异常数据处理。通过再次对去除异常数据后的药材光谱数据进行分析发现,原数据集中的数据量大、凌乱,且数据的区分度不大。若是根据这些数据集中的光谱数据对药材的种类进行划分,再加上有些药材的种类未知,就很难用常规的方法对药材进行分类,也难以直接利用机器学习中的监督学习来对不同药材种类进行划分,必须寻找合适的方法解决药材种类的划分问题。
为了寻找解决问题的方法,接下来先利用主成分分析法对数据集中的光谱数据进行降噪、降维等数据预处理,再将经过预处理后在不同光谱波数下的吸光度数据进行可视化处理,结果如图1所示。
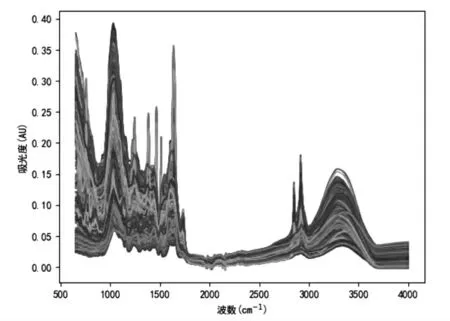
图1 不同药材的波数与吸光度曲线
通过对图1的观察可以发现,药材的光谱数据曲线图十分相似,区分度不大,难以用一般的方法对药材种类进行划分。聚类算法是根据样本之间的相似性,将样本划分到不同的类别中,该算法主要用于将相似的样本自动归到某一个类别。通过对聚类算法进行研究分析,决定使用基于Python实现的K-means聚类算法[11]对不同药材的光谱数据来解决种类划分问题。由于没有明确知道药材有哪些种类,因此先通过K-means肘部法[12]的手肘图确定药材最优分类数,再利用K-means聚类算法去解决药材种类的划分问题。把相应的数据代入计算,得到拐点肘部处的位置所对应图2中的3值,即为药材最优分类数K=3。

图2 K-means算法的手肘
可见,通过K-means肘部法的手肘图可知药材可划分为3类,于是将药材数据集中的光谱数据代入Python中的sklearn库中的KMeans()函数进行无监督分类,最后得到药材的种类划分信息,药材种类共分为3类,其种类划分结果及相关信息如表1所示。

表1 药材种类的鉴定结果及相关信息
为了更突出药材的特征和差异性,对每一种类的药材光谱数据进行拟合,使每一种类药材对应一条曲线。通过研究分析,运用模型1对3种药材的光谱数据进行显著化处理,这样处理便于通过药材的特征去鉴别药材种类,同时也便于显示不同种类药材之间的区分度。

其中,xij表示种类i的各种药材在不同波段j光谱照射下的吸光度,xi表示种类i的药材在不同波段j的光谱照射下的吸光度,n表示种类i的药材数量,x表示种类i的各种药材在不同波段j光谱照射下的吸光度的均值。
最后将分好种类、经过显著化处理的药材光谱数据进行可视化处理,如图3所示。从可视化结果可以看出:在一定范围波数下,不同种类药材的光谱数据曲线的变化趋势和变化幅度明显不同。故可以认为不同种类药材之间的特征和差异性,是在一定范围波数下的吸光度的特征和差异性。

图3 不同种类药材的波长与吸光度的关系分类
三、药材产地的鉴定
此部分根据某一种药材数据集中的红外光谱数据来鉴定药材的产地。通过对数据集中的光谱数据进行分析和研究,同时结合一些已知产地的药材的相关数据信息及其特征,对未知产地的药材进行产地鉴定。最终利用机器学习中的监督学习SVM(支持向量机)解决药材的产地鉴定问题。
(一)根据中红外光谱数据鉴定药材产地
为了方便、直观地对不同产地药材的特征信息进行分析研究,将已知产地的药材在不同光谱波数下的吸光度数据分离出来,然后进行可视化处理,如图4所示。

图4 不同产地药材的光谱曲线
由图4可以看出,不同产地药材的光谱数据曲线图十分相似,很难用眼睛直观地去分辨其差异性。由于已知部分药材的产地信息,经过分析和研究,认为可以利用机器学习中的监督学习SVM解决药材的产地鉴定问题,即由已知产地的药材数据信息,运用监督学习SVM来解决药材的产地鉴定问题。
使用监督学习SVM方法解决药材产地的鉴定问题时,首先将已知产地的药材光谱数据分离出来,已知产地的药材不用进行鉴定;针对未知产地的药材,则根据其光谱数据信息对药材的产地进行鉴定。以已知的产地为标签,以波数列为数据,按照8∶2的比例把已知产地的药材数据分为训练集与测试集,然后利用监督学习SVM方法(线性分类模型)并使用穷举法找出模型的最优参数,最后将训练集进行线性拟合得到训练好的线性分类模型(模型2)如下所示,其训练的相关信息和参数如表2所示。
使用监督学习SVM方法解决药材产地的鉴定问题时,首先将已知产地的药材光谱数据分离出来,已知产地的药材不用进行鉴定;针对未知产地的药材,则根据其光谱数据信息对药材的产地进行鉴定。以已知的产地为标签,以波数列为数据,按照8:2的比例把已知产地的药材数据分为训练集与测试集,然后利用监督学习SVM方法(线性分类模型)并使用穷举法找出模型的最优参数,最后将训练集进行线性拟合得到训练好的线性分类模型(模型2)如下所示,其训练的相关信息和参数如表2所示。

表2 监督学习SVM(支持向量机)的参数及评估分数

其中,X表示近红外或中红外光谱的数据,Y表示药材的种类或产地的编号,test_size表示从已知产地的药材光谱数据中分割出测试集的数据比例,random_state表示控制随机状态,train_X表示用于训练模型的近红外或中红外光谱数据,train_Y表示用于训练模型的药材种类或产地的编号,test_X表示用于评估模型的近红外或中红外光谱数据,test_Y表示用于评估模型的药材种类或产地的编号,clf表示一个支持向量机模型,C表示惩罚参数,kernel表示使用参数为“linear”的核函数,decision_function_shape表示决策函数类型,默认参数为’ovr’,’ovo’表示one vs one,’ovr’表示one vs rest,probability表示是否启用概率估计,clf.fit表示支持向量机模型训练函数,score表示评估分数,metrics.accuracy_score表示评估函数,y_true表示已知种类或产地的药材编号,y_pred表示预测种类或产地的药材编号,clf.predict表示模型预测函数。
对于拟合后的线性分类模型,利用测试集对模型进行性能评估之后就可以对未知产地的药材进行鉴定。由于不同产地药材在同一种波段的光谱数据比较接近,这使得光谱鉴别容易出现比较大的误差。从表2的评估分数和不同产地的药材光谱数据来看,监督学习SVM方法是适合用来鉴定药材产地的方法。因此根据未知产地的药材中红外光谱数据,同时利用监督学习SVM方法并结合已知产地的药材数据可以解决药材的产地鉴定问题。利用监督学习SVM方法将相关的光谱数据集进行训练计算后即可鉴别出产地原值为空的药材产地信息。产地原值为空的药材产地的最终鉴定结果如表3所示。

表3 药材产地的鉴定结果
将各种药材的光谱数据通过模型1对其特征进行显著化处理,然后对结果进行数据可视化处理,结果如图5所示。

图5 不同产地的药材吸光度曲线
通过对图5进行研究分析,可知不同产地药材的特征和差异性。可以明显看出,不同产地的同一种药材光谱曲线的变化趋势和变化幅度差异不大,说明不同产地的同一种药材在同一波段内的光谱差异性不大,特征不够明显,区分度不大。
(二)根据近红外和中红外光谱数据鉴定药材产地
此部分根据某一种药材近红外和中红外光谱数据鉴定药材的产地,结合已知产地药材的近红外和中红外这两种光谱数据,来解决药材的产地鉴定问题。
通过研究分析,发现根据近红外和中红外光谱数据鉴定药材产地问题与根据中红外光谱数据鉴定药材产地问题的解决方法类似,所以依据本文第三大点的第一个内容“(一)根据中红外光谱数据鉴定药材产地”所建立的模型方法建立模型2,利用监督学习SVM方法,分别以近红外光谱数据与中红外光谱数据为参数,对药材的产地进行鉴定。以模型的评估分数为参考,则可以解决药材的产地鉴定问题。其中,模型的评估参数及药材产地的鉴定结果分别如表4和表5所示。

表4 线性分类模型参数及评估分数

表5 药材产地的鉴定结果
由表5可知,大部分药材的产地,利用近红外与中红外光谱数据进行鉴定的结果基本一致,但也有少部分药材的产地鉴定结果不同。如编号15与编号209的药材,其鉴定结果就不一致。从模型2内(参数)比较可发现,近红外线性分类模型的置信度高于中红外线性分类模型的置信度;从模型2外(结果)比较可知,近红外线性分类模型的评估分数高于中红外线性分类模型的评估分数。对编号15和编号209的药材,分别从模型内和模型外比较它们的置信度和评估分数,结果如表6所示。从比较结果可以发现,采用近红外线性分类模型所鉴定的结果更为准确。因此,药材产地最终的鉴定结果如表7所示。

表6 编号为15和209的药材产地鉴定相关信息

表7 药材产地的最终鉴定结果
四、药材种类和产地的鉴定
此部分根据已知部分药材的种类和产地的近红外光谱数据,解决未知种类或产地药材的鉴定问题。由于在近红外光谱数据中已知部分药材种类或产地信息,需要去鉴定药材的未知种类和产地的问题。根据研究分析,不同种类药材表现的光谱特征差异比较大,故对药材种类的鉴定难度比较小,所以优先考虑鉴定药材种类,再鉴定药材的产地。
首先鉴定药材种类。通过分析,发现此问题与第三大点中解决问题的方法类似。利用与第三大点的第一个内容“(一)根据中红外光谱数据鉴定药材产地”类似的方法,把已知种类的药材的光谱数据分离出来,再利用监督学习SVM方法对这些数据进行数据拟合和评估,然后对药材的种类进行鉴定。评估参数及药材的种类鉴定结果分别如表8和表10所示。

表8 监督学习SVM(支持向量机)参数及评估分数
然后鉴定药材的产地,具体鉴定过程是按药材的种类分别对药材的产地进行鉴定。利用与第三大点的第一个内容“(一)根据中红外光谱数据鉴定药材产地”类似的方法,把已知产地的药材光谱数据分离出来,然后利用SVM(支持向量机)方法进行数据拟合、评估,对药材的产地进行鉴定。评估参数及药材的产地鉴定结果分别如表9和表10所示。

表9 监督学习SVM(支持向量机)参数及评估分数

表10 利用监督学习SVM(支持向量机)对药材种类和产地的鉴定结果
结 语
SVM是一种监督学习的方法,可广泛应用于统计分类以及回归分析中,并对通常的分类和回归等问题进行简化。本文运用监督学习SVM对药材数据集中的近红外、中红外光谱数据进行处理,以此来鉴定药材的种类或产地。其过程如下:首先,将已知种类或产地的药材光谱数据分离出来,以已知的药材种类或产地为标签,以波数列为数据,按照8∶2的比例把已知种类或产地的药材数据分为训练集与测试集;其次,利用监督学习SVM方法并使用穷举法找出模型的最优参数;再次,将训练集进行线性拟合得到训练好的线性分类模型;最后,对于拟合后的分类模型,利用监督学习SVM方法,并结合已知种类或产地的药材数据和监督学习SVM的参数及评估分数,将相关的光谱数据集进行模型分类后,即可鉴别出种类或产地原值为空的药材信息。
中药材的种类或产地不同,其疗效也有差异。因此,准确地鉴定药材品质是保证用药安全和提高药物疗效的前提,也是药材质量控制的重要环节。利用近红外、中红外光谱数据鉴定药材,是一种无损的分析方法。该方法具有成本较低、操作简单、分析时间短等优点,目前在中药材和其他植物的品质鉴定方面有着广泛的应用。监督学习SVM对异常值不敏感,少数支持向量决定了最终结果,不仅可以更好地抓住关键样本、“剔除”大量冗余样本,而且具有算法简单、“鲁棒性”较好、泛化能力强等特点。虽然关于药材种类或产地的鉴定有各种不同的方法,但随着各种技术的不断更新和提高,利用机器学习中的监督学习SVM的方法解决药材的鉴定问题是一种值得借鉴的方法。
