基于特征降维的网络文本数据分析算法研究
2022-07-26杨旭沈俊鑫王春佳远俊红李若娟
◆杨旭 沈俊鑫 王春佳 远俊红 李若娟
基于特征降维的网络文本数据分析算法研究
◆杨旭1,2沈俊鑫2王春佳3远俊红1李若娟1
(1云南林业职业技术学院 云南 650225;2昆明理工大学 云南 650031;3云南师范大学 云南 650092)
由于网络数据大规模增长而导致文本数据的高维稀疏性,使得在对高校学生网络舆情分析时带来了巨大挑战。为解决该问题,本文在传统文档频率、互信息和卡方检验基础上,提出融合三种特征降维算法优化方法。首先在互信息算法中加入文档频率因子,解决低频词缺陷问题。然后,在卡方检验算法中加入标准评分因子来解决负相关问题。最后计算平均值,融合三种算法优点,提出一种新的改进降维算法。仿真结果表明,该算法对文本数据进行处理后,情感分析的准确率得到了提高并保持在95%以上。召回率90%以上,F值保持在92%~94%之间。在此区间上高于其他改进算法且趋于稳定,说明该算法在处理海量文本数据时,能够有效提高微博文本数据分析的准确率和效率。
特征降维;文本情感;特征选择;Hadoop
文本数据作为网络舆情信息主要载体,是数据分析研究重点,由于网络数据大规模增长而导致文本数据的高维稀疏性[1],使得在对高校学生网络舆情分析时带来了巨大的挑战。如何从海量微博数据中快速获取有效信息,这就需要对聚类算法进行全面深化的研究。目前,通行做法是使用特征选择来降低数据特征维度,本文主要针对文档频率、信息增益、互信息和卡方检验等算法进行比较研究。提出DF-MI-CHI融合优化算法促进分类器的性能提高,实现提高文本数据信息的分类准确率和召回率。
1 常用特征选择算法
特征降维一般采取的通行做法是对其文本数据进行特征选择,并为文本分类提供更高效率。在对文本分类时,需进行预处理得到特征词的特征空间。在预处理阶段通过去噪删除大量无意义词,从而降低空间维度。但是,对于文本分类,该特征空间比较大,导致文本特征越来越稀疏,降低分类效率和准确率。因此,需要通过特征选择算法来降低文本特征向量复杂程度。目前,广泛使用的特征选择方法有以下几种。
1.1 文档频率(DF)
文档频率是一种简单易懂的选择算法。它是通过计算一个特征词在文档中出现的次数来实现。其实现过程首先是设置文档频率的参数上限和下限值,即每个特征词的阈值。然后,计算语料库中每个特征词的文档频率。最后,保留满足阈值的特征词,删除超过阈值的特征词。文档频率计算如公式(1)所示。
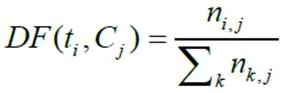

1.2 互信息(MI)
互信息是一种用于描述两个变量是否有关系,以及关系强弱的算法。在互信息的计算中引入了信息熵的概念,用于衡量数据集中数据不稳定或突发的程度。其计算公式如公式(2)所示。

公式(2)中,表示将该训练集所包含的信息熵,P用于表示目标属性出现在所有样本中的概率。信息熵值越小,目标属性分布越纯。所以,通过公式(2)可以看出来,当P= 1的时候,信息熵=0,最小。也就意味着,所有样本的目标属性取值相同。对于互信息,假设特征项由t表示,类别由表示。其方程如公式(3)所示。

在公示(3)中,(t,)表示特征项在类中t 出现的概率,(t)表示特征项t在整个语料库中出现的概率,()表示类别出现的概率。互信息值越大,特征和类的共现度越高。因此,当互信息的值达到最大值时,特征项是最好的类别特征。互信息的缺点是忽略了特征词的词频,过分关注特征项的文档频率,会导致一些重要特征项的丢失。
1.3 卡方检验(CHI)
该方法主要用于统计数据的实际取值与理论推断值之间的偏离程度,也称为平方拟合检验2统计方法。用于衡量相关程度在特征词和类别之间。其计算公式如公式(4)所示。
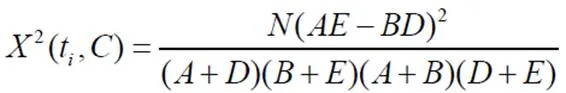
在公式(4)中,表示语料库文档总数[2]。表示在类别文档中特征项t的频率。表示在不属于类别文档中特征项t的频率。表示在类别文档中特征项t没有出现在文档中的频率。表示既不包含特征项t也不包含类别的文档频率[3]。默认假设为特征项和类别独立的情况下,如果公式的值较小或为零,则偏差程度较小。如果值较大,即误差程度较大,则原假设不成立,特征项与类别相关。卡方检验的终值通常采用最大值计算或平均值计算,如公式(5)所示是最大值的计算方式。

对于多类划分,实验表明使用最大卡方值作为筛选条件可以获得更好结果。因此,本文选择卡方检验的最大值作为特征t的最终值。
2 中文微博文本数据获取
本次研究主要针对新浪微博和腾讯微博上用户发布的有关校园学习、生活的文本信息和评价信息作为研究的基本数据,并使用比较常见的中文语料库进行数据分析。文本数据获取是研究的第一步。有两种常用的数据获取方法。一种是基于Hadoop的网络爬虫进行数据获取,另一种是微博官方对外开放的API接口方法。获取的数据存储在基于 Hadoop 的HDFS中,以供进一步分析和使用。
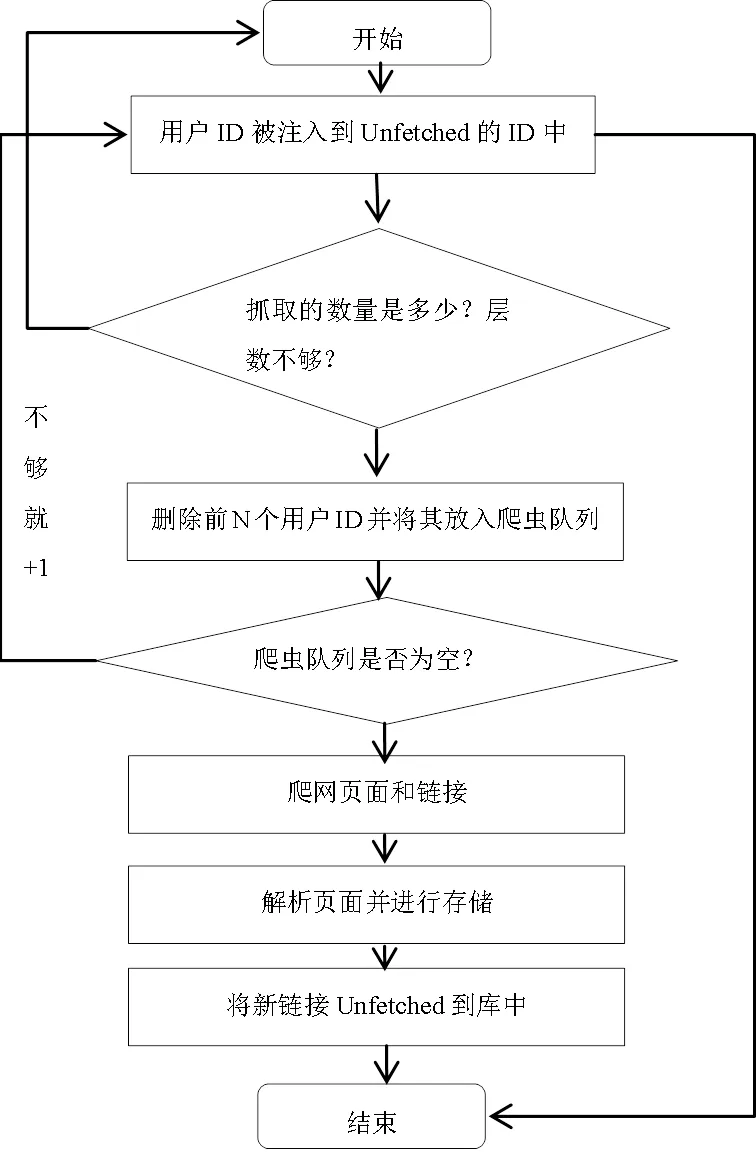
图1 Hadoop分布式爬虫工具流程图
2.1 文本数据预处理
用户在微博上发表或评论时,通常会有一些无意义的词汇,这给文本数据的处理带来了干扰。这需要对存储数据进行预处理。原始文本语料,分词Tokenize,词性标记POSTag,词干化Lemma/Stemming,去除停用词和处理后的文本语料。文本预处理流程图如图2所示。
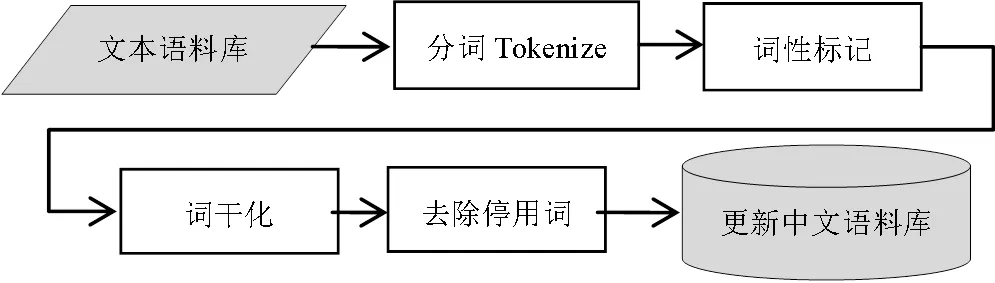
图2 文本预处理流程图
获取文本数据后,首先对文本进行切分。中文文本数据不同于英文文本。在英文文本中,单词可以被明显的空格或符号分割,但中文文本中的单词之间没有明显划分。通常分词都是基于词典匹配法和基于词频统计分词法。本文使用频率高、性能稳定、准确率高的Python语言版本的“jieba”组件对微博文本进行分词[3]。分词后要每个词进行词性标注。例如,“我”是名词,“跑步”是动词,“开心”是形容词。基于规则的词性标注、基于统计的词性标注及其组合是目前常用的词性标注方法。本文结合使用两种方法对词性进行标注。首先,使用基于规则的词性标注来标注常用词和简单词,然后使用统计词性标注来标注复杂词和网络新词汇,这将有利于提高语料库的综合效率。停用词处理也称为去噪处理。它主要删除文本中没有情感意义的词,如“走”、“去”、“上”、“的”等,这些词在中文文本信息中很常见。删除它们后,可以有效提高文本分类的准确率,并且可以在一定程度上降低向量空间的维数。
2.2 文本数据存储(HDFS和MapReduce)
HDFS(Hadoop Distribution File System)是Hadoop系统架构中重要的分布式文件存储结构,非常适合存储TB、PB等海量数据。HDFS分布式集群由三部分组成:Client、NameNode和DataNode。客户端访问文件并管理数据块到DataNode点的映射,DataNode负责存储和管理数据块。每个块报告中会根据DataNode的块副本的块ID生成相应的标签和块长度,形成集群中数据块的更新视图。HDFS分布式文件系统的主要优点是容错性高、存储容量大、成本低。因此,本文采用HDFS分布式文件系统来存储从微博上爬取到的大量增量数据。
MapReduce是一种用于处理大量半结构化数据的程序开发模型。它是一种处理和构建特定问题的方法。例如,在关系型数据库SQL中,使用集合语言来执行查询。告诉语言你想要什么结果并将其提交给系统以找出如何生成计算。也可以使用更传统的语言(C++、Java)来解决问题。MapReduce和 Hadoop 是独立的并且可以很好地协同工作。MapReduce将计算过程分为两个阶段:Map 阶段和 Reduce 阶段。Map阶段对应mapper处理功能,可以对原始数据进行过滤和变换。Reduce阶段对应reducer函数,主要聚合mapper函数的处理结果,输出最终的处理结果。MapReduce的具体处理如下:首先将待处理的输入数据分成更小的Split子块,发送给Mapper。Mapper调用自定义Map方法对Split子块进行处理,并转化为中间结果。将结果存储在本地磁盘上。然后调用Reduce 函数聚合中间结果。最后将输出存储在HDFS中。
3 特征选择算法及改进
特征选择主要为确定表征文本主题的特征集,即选择与分类相关度高的相关特征集和特征项的权重计算[4]。以往的特征降维算法大多只是从一个方面考虑,侧重于解决某个因素对特征降维算法的影响。改进的文本频率算法(TF-IDF)侧重于网络新词对特征降维的影响,而忽略了稀有词被过滤掉的问题。基于最大条件联合互信息(MCJMI)的特征选择算法侧重于解决低频词对特征降维的影响,但没有考虑词频对文本分析的影响。基于方差的卡方检验(Var-CHI)特征选择算法侧重于解决特征词分布不均的问题,而忽略了低频词缺陷的问题。该算法首先计算文档频率的值,并在互信息(MI)算法之前添加文档频率因子。然后计算卡方检验(CHI)值并乘以标准分数因子。最后,将前两步的值相加计算平均值。该算法可以弥补文档频率(DF)、互信息(MI)、卡方检验(CHI)对低频词分析的不足,该算法提高了分类的效率和准确性。基于以上分析,本文提出的新算法方程如公式(6)所示。
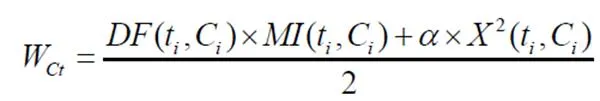
在上面的公式(6)中,(t,C)表示文档频率因子(t,)代表相互的信息价值,X(t,C)表示卡方检验的值,是用于解决问题的标准分数卡方检验(CHI)中的负相关问题,其计算方法如公式(7)所示。


4 实验和分析结果
通过网络爬虫,实时获取5000条微博文本和评论信息。采用随机抽样,70%的微博数据作为训练样本,30%作为测试样本。所有爬取的数据都存储在基于Hadoop的HDFS分布式文件存储结构中。
4.1 实验评价指标
在微博情感分析中,通常以准确率、召回率和F值作为判断微博情感的标准。我们通常使用表格来描述相关变量。根据表1,精确率、召回率和F值方程可以定义如下。
表 1 Precision 和 Recall 相关变量说明
相关无关 RetrievedTrue Positives (TP)False Positives (FP) Not RetrievedFalse Negatives (FN)True Negatives (TN)
上述关于精度P,召回R和F值中,用于表示微博情感分析中正确分类的微博文本的数量。表示检索到但分类错误的微博文本的数量[5]。是未检索到但属于该类别的微博文本数。是未检索到且不属于此类别的文档数。因此,是系统中应判断为该类别情感的微博总数。是应判断为类别的微博文本数量。最后将分析计算的结果用Matlab绘制出来,便于观察和分析。
4.2 实验结果分析
本文使用改进的文本频率算法(TF-IDF)[6]对1500条微博文本数据进行测试,将新的网络词融入向量空间模型;最大条件联合互信息(MCJMI)[7];基于方差的卡方检验算法(Var-CHI)[8];和提出的DF-MI-CHI融合改进的降维算法,对微博文本的积极情绪进行分析和测试。积极情绪倾向分析的准确率、召回率和F值分别如图4、5、6所示。
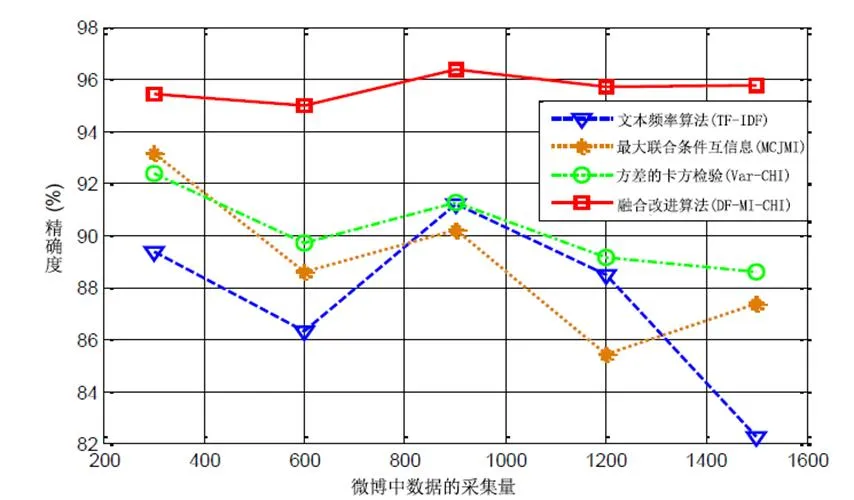
图3 四种微博情感分析降维方法精度结果对比
从图3可以看出,在分析小规模微博的情绪时,四种算法的准确率都比较高。随着微博文本数量的增加,改进的TF-IDF算法旨在将新词融入网络,忽略出现频率较低的生词。在分析更复杂的微博文本时,会有一些具有重要意义且出现频率较低的稀有词。由于改进的降维算法综合了三种算法的优点,有效地解决了过滤掉稀有词的缺点,所提DF-MI-CHI降维算法的整体准确率高于其他三种方法。随着微博文本数量的增加,呈现出相对稳定的趋势。
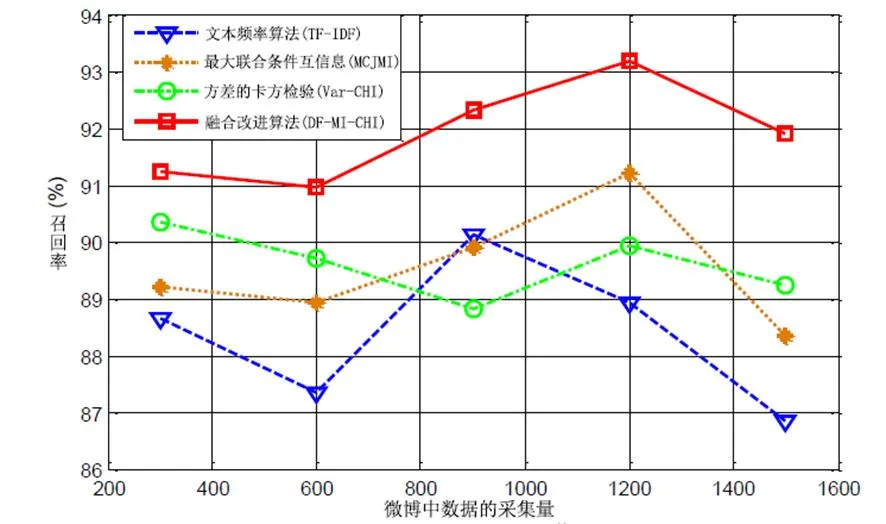
图4 微博情感分析四种降维方法召回率对比
召回率是针对测试集中的测试结果。对于微博情感分析,积极微博情感回忆率表示正确的积极情感倾向微博文本数与正确的微博文本数之比。微博测试集中真实积极情绪倾向微博文本的数量。经分析,基于四种降维算法的微博情感分析召回率如图4所示。最大条件联合互信息(MCJMI)算法在分析一定数量的微博文本时具有较高的召回率因为它倾向于使用低频词。然而,由于最大条件联合互信息(MCJMI)算法没有考虑词频对微博情感分析的影响,更多的文本伴随着不可能性。消除冗余会导致较低的召回率。改进后的DF-MI-CHI综合降维方法在互信息中加入了文档频率因子,填补了改进的最大条件联合互信息(MCJMI)算法存在的问题。召回率明显高于其他三款,相对稳定。有效提高了在对微博文本进行分析时的准确性。
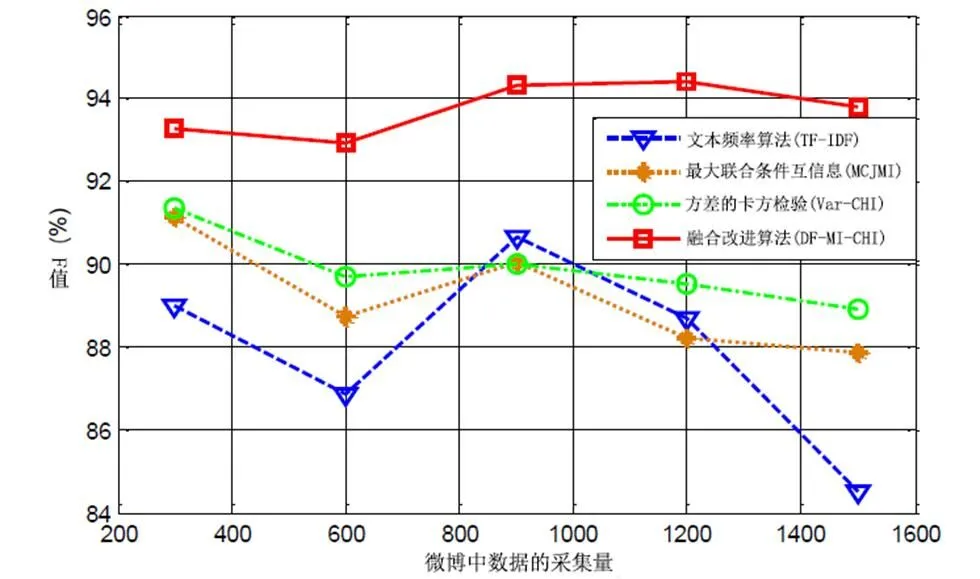
图5 四种微博情感分析降维方法F值对比
该F值是一个综合指标,用于满足不同类别文本分析对不同准确率和召回率的需求。我们可以通过调整表达式中的因素来调整准确率和召回率的比例。在本文中,我们取因子为1,即准确率和召回率同等重要,如图5所示。改进文本频率(TF-IDF)算法的准确率和召回率波动较大。基于全局联合互信息的最大条件联合互信息(MCJMI)算法和基于方差的改进卡方检验(Var-CHI)算法相对稳定,但词频和低频词处理的准确率和召回率不够高。基于改进提出的DF-MI-CHI集成降维算法,弥补了三种方法的不足。准确率和召回率高且稳定,F值趋于稳定。
5 结束语
面对微博文本数据的爆炸式增长,在分析微博情感倾向时,特征词数量的增加导致“维度灾难”的发生。针对该问题,本文提出了一种新的改进降维算法。首先,我们需要爬取微博数据,使用基于Hadoop的分布式爬虫工具获取微博的实时数据,并将获取到的微博数据存储在基于Hadoop的分布式文件系统HDFS中。然后,我们对获取的数据进行预处理,通过分词、词性标注、删除停用词等方式将其存储到微博语料中。最后,我们将其保存在微博语料中。本文使用了所提出的 DF-MI-CHI 的改进降维算法,它结合了文档频率(DF),互信息(MI)和卡方检验(CHI)。经过对微博积极情绪倾向的测试分析,提出的DF-MI-CHI改进降维算法的准确率为95%。召回率在90%以上。与其他三种算法相比,随着微博文本数量的增加,准确率、召回率和F值趋于稳定。
[1]古倩.基于特征向量构建的文本分类方法研究[D].西安理工大学,2019.
[2]刘振岩,田野.面向舆情分析的海量短文本分类关键技术研究[D].中国科学院大学,2016.
[3]朱颢东,李雯琦,张昭.基于语义规则和表情加权的中文微博情感分析方法[J].轻工学报,2019.
[4]刘楠楠.文本分类中特征降维算法的研究与应用[D].电子科技大学,2018.
[5]孔杏,林庆.主观性文本情感分类研究综述[J].信息技术,2018.
[6]叶雪梅,毛雪岷,夏锦春,等.文本分类TF-IDF算法的改进研究[J].计算机工程与应用,2019.
[7]王志国.网络舆情监控过程中微博文本分类处理的实现方法[J].图书情报导刊,2016.
[8]邱云飞,王威,刘大有,等.基于方差的CHI特征选择方法[J].算机应用研究,2012.
2021年云南省教育厅科学研究基金项目(2021J1086)
