考虑样本不平衡的电力系统鲁棒暂态稳定评估
2022-07-26刘书池刘颂凯张雅婷晏光辉
刘书池,刘颂凯,张 磊,张雅婷,晏光辉,周 倩
(三峡大学电气与新能源学院,湖北宜昌 443002)
0 引言
随着现代电力系统的广域互联,电力系统形态结构愈发复杂,运行方式愈发多样,系统运行的安全稳定性面临着极大的挑战[1-2]。对其进行预想故障下的快速暂态稳定评估,有助于系统监控人员及时采取后续的预防控制措施,对维持系统暂态稳定性而言十分重要[3-4]。
传统的暂态稳定评估方法主要包括时域仿真法[5]和直接法[6],由于电力系统的结构和规模愈发复杂与庞大,传统方法将消耗大量的计算资源与时间,难以满足现代电力系统暂态稳定评估的实时性与有效性要求[7-8]。随着同步相量测量单元(Phasor Measurement Unit,PMU)的应用,系统运行数据的采集效率有了极大的提升,这使得基于数据驱动的暂态稳定评估方法被广泛用于电力系统暂态稳定分析领域[9-13]。然而,在实际电网中,由于失稳样本十分稀缺,用于训练暂态稳定评估模型的原始样本存在严重的类别分布不平衡问题,失稳样本的数量远少于稳定样本的数量,暂态稳定评估模型对稳定样本过拟合现象严重,致使评估结果准确性下降[14]。
部分研究者针对样本类别分布不平衡导致的问题做出过改进,文献[15]通过焦点损失函数调节类别权重来改变模型对样本的倾向性,但不可避免地增大了模型误判率。文献[16]基于改进深度卷积生成对抗网络生成新的失稳样本,但在特征提取时丢失了部分信息。文献[17]采用自适应综合采样算法(Adaptive Synthetic Sampling,ADASYN)改善样本不平衡问题,但放大了数据中的噪声,导致决策边界的样本难以识别。这些在改善样本类别分布方面的研究均取得了一定成果,但尚且存在不足之处。一方面,在改善样本类别分布的同时,出现信息丢失导致的样本数据缺失或者放大原始样本数据中原本的噪声都将使得暂态稳定评估模型的评估精度有所下降。另一方面,实际电力系统量测数据本就可能存在数据缺失或者数据噪声,顾此失彼的改进方式将进一步扩大二者带来的影响。
针对目前部分研究在改善样本类别分布方面的不足,本文提出了一种考虑样本不平衡的电力系统鲁棒暂态稳定评估方法。首先通过MAHAKIL 过采样[18]算法在保全原始样本特征信息与提高样本数据分布多样性的基础上生成新的平衡样本集。然后提出基于套袋受限学习机(Bagging Constrained Learning Machine,BCLM)的鲁棒模型,通过对极限学习机[19-20](Extreme Learning Machine,ELM)进行原理改进并通过bagging 策略生成集成化的暂态稳定评估模型,在生成平衡样本集的基础上进一步提升暂态稳定评估模型对样本数据缺失及数据噪声的鲁棒性;随后提出模型更新机制保证评估模型在线实时应用的可靠性。最后在新英格兰10 机39 节点系统中验证了本文所提方法的有效性。
1 MAHAKIL过采样
传统过采样方法如随机过采样(Random Oversampling,ROS)、综合少数过采样技术(Synthetic Minority Oversampling Technique,SMOTE)和ADASYN 方法倾向于将失稳样本聚类在特定组中,基于K 近邻算法生成新样本,只能为分类器提供有限的信息,如图1(a)所示,其中虚线框为传统过采样方法估计的决策边界。基于遗传算法和马氏距离(Mahalanobis Distance)的MAHAKIL 过采样算法避免对少数类样本直接复制,而是根据失稳样本的特性生成新的失稳样本。合成的新样本最大程度上不同于初始样本,能在保全样本特征信息的基础上最大化样本的多样性。如图1(b)所示,其中实线框为MAHAKIL 方法估计的决策边界,可见该边界和真实的决策边界几乎一致。
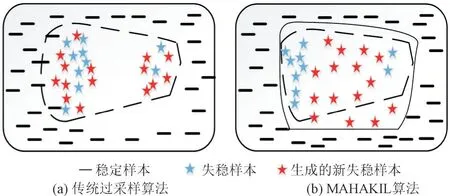
图1 过采样方法对比Fig.1 Oversampling algorithm comparison
MAHAKIL 过采样算法采用马氏距离作为样本多样性的衡量标准。与传统测量采用的欧式距离不同,马氏距离能够更有效地衡量样本集之间的相似度,其计算不会受到样本特征量纲的影响,可以排除样本特征之间的相关性带来的干扰,这使得基于马氏距离的MAHAKIL 过采样算法可以避免样本特征量纲不一致所导致的过采样误差,从而使得过采样过程中所衡量的样本特征之间的关系更加符合实际情况。因此,本文采用基于马氏距离的MAHAKIL过采样算法能够在规避样本特征维数影响的同时有效测量样本之间的距离从而进行后续配对。
MAHAKIL 算法分为3 个阶段:
1)确定生成新少数类样本数量。根据原始样本集N中的多数类样本数Nmax与少数类样本数Nmin计算出需要生成新少数类样本的数目T=Nmax-Nmin。
2)样本分组和标签分配。在少数类样本集Nmin中计算任意两样本间的马氏距离D,如式(1)所示:

式中:向量m1和n1为两个少数类样本;S-1为样本协方差的逆矩阵。
如图2 所示,将少数类样本按马氏距离降序排序,并以中间位置为分界点,将少数类样本分成两组作为初始样本集S1和S2。两组初始样本集中的每个样本被依次标记,其中两组之间被分配相同标签的样本,被系统有序地配对。配对顺序完成,标签相同的一对样本将用于合成子代样本。
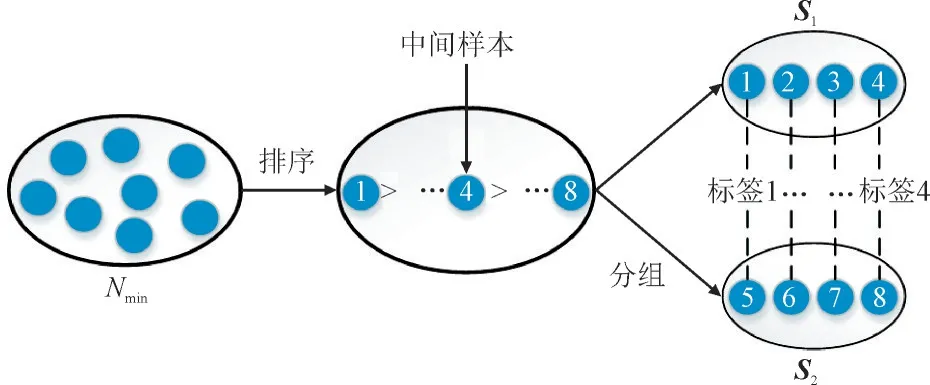
图2 数据分组和标签分配Fig.2 Data grouping and label allocation
3)生成新样本。将遗传算法的交叉算子引入样本生成过程中,结合2 个具有相同标签的样本生成新样本,此时生成的新样本是唯一的,与其直接父代样本相关。计算第g次生成的新失稳样本集为:

直至生成的新失稳样本的数目为T时,将新少数类样本与原始样本集N相结合,形成一个平衡样本集。
少数类样本生成原理如图3 所示。初始样本集S1和S2中的样本交叉合成新样本集C01后,子样本集C01又同初始样本集S1和S2相结合,生成2 个新的子样本集C11和C12……之后每个新的子样本集都与其直接的父代样本集相结合,生成下一代子数据集。重复上述过程,直至少数类样本达到原始特征集所需的样本数目T为止。

图3 MAHAKIL原理图Fig.3 Schematic diagram of MAHAKIL
2 BCLM算法
2.1 CLM算法
受限学习机(Constrained Learning Machine,CLM)是基于极限学习机改进而来的算法。是一种广义单隐藏层前馈神经网络,二分类任务下的CLM结构图如图4 所示。

图4 CLM网络结构Fig.4 Structure of CLM network
通过输入层-隐藏层间节点权重和偏置系数将输入样本从原始特征空间映射至新的特征空间,能有效提升网络对样本的分类精度。与ELM 随机生成节点参数不同,CLM 基于标签不同的异类样本间的差向量生成网络参数,规避了因节点参数随机生成可能导致的样本特征映射规模化散乱,有效避免了因此造成的网络模型过拟合或欠拟合,在ELM 的基础上进一步提升了分类精度。其改进原理简介如下:
以向量x1表示一个标签为y1的样本;向量x2表示一个标签为y2 的样本;2 个样本构成一组异类样本。α为输入层到隐藏层的层间节点权重矩阵,即:

式中:λ为归一化因子。
单隐藏层神经网络输入与输出值之间的关系即为:

式中:β为隐藏层节点偏置项。
基于式(3),可以进一步将式(4)表达为:

根据式(5)可反推得归一化因子λ和偏置项β为:

根据式(3)、式(6),输入层到隐藏层的层间节点权重矩阵α可以根据样本x1与x2的差向量求得:

根据异类样本间的差向量生成层间节点权重及偏置参数,可以有效避免因随机生成节点参数而导致的样本映射散乱,提升模型对样本数据的拟合效果,保证模型后续的分类精度。
2.2 Bagging集成策略
CLM 作为广义单层神经网络,容易受到数据缺失及噪声的干扰。为提升模型对数据缺失、噪声等因素的鲁棒性,将多个弱分类器集成化,构成强分类器是较为有效的手段。为了保证集成的效果,弱分类器之间需要具有较大的差异性,但实际操作中的弱分类器往往都是同质的,在难以实现模型本身特性差异化的情况下,可以利用Bagging 策略让单一弱分类器对样本进行差异化采样实现模型的差异化。
Bagging 策略的基本流程即:对初始样本集进行随机的有放回采样,重复K次采样,就能获得一个大小为K的训练样本集;重复该流程,采样出N个大小为K的训练样本集,对应并行训练N个CLM,再将这N个CLM 进行结合,形成强分类器即Bagging-CLM(BCLM)。由于每个CLM 都是在略微不同的训练集上拟合完成训练的,因此每个CLM 在预测同一个未知样本时会存在略微的差异,形成的强分类器BCLM 对于样本数据中的冗余信息不会过度拟合,无论是对数据缺失或者数据噪声都有较强的鲁棒性。
3 暂态稳定评估流程
本文提出的考虑样本不平衡的鲁棒暂态稳定评估方法以MAHAKIL 过采样算法和BCLM 暂态稳定评估模型为基础,主要分为离线训练、模型更新和在线评估3 个部分,如图5 所示。
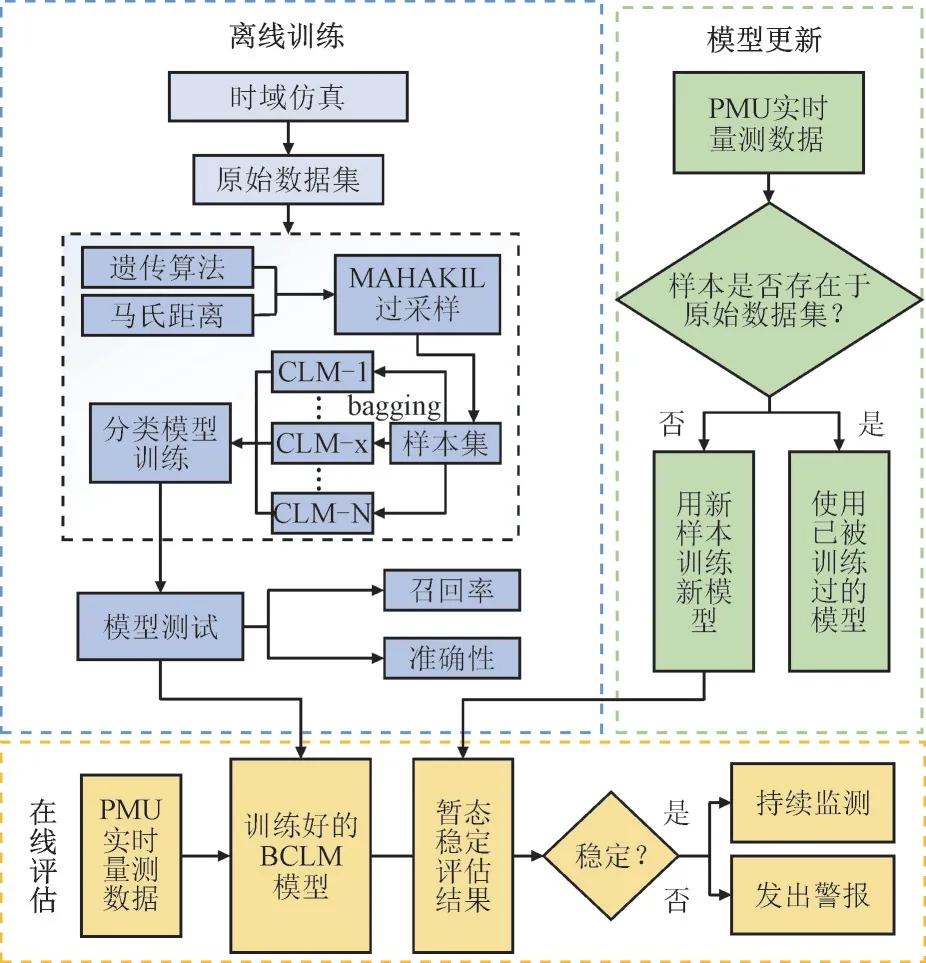
图5 暂态稳定评估框架Fig.5 Transient stability assessment framework
3.1 暂态稳定指标
暂态稳定裕度(Transient Stability Margin,TSM)可以反映电力系统当前运行点到安全边界的距离,其通常被用来描述电力系统的暂态稳定程度[21]。本文使用故障的临界切除时间和实际切除时间来构建TSM,如式(8):

式中:TCC为在保证电力系统稳定运行前提下的最大故障清除时间;TAC为该故障实际的切除时间;MTS为一个-1 到1 范围内的连续值。
仿真设置----MTS为MTS的临界值,该值可根据电力系统的安全需求灵活设定。根据MTS与----MTS之间的关系,可将电力系统故障下的运行状态分为稳定和不稳定,即:

3.2 离线训练
在离线训练阶段,首先从时域仿真中获取暂态稳定评估原始数据集,每个样本的特征包括节点电压幅值和相角、发电机有功功率和无功功率、线路损耗等,相应的暂态稳定标签根据式(9)确定。利用MAHAKIL 过采样方法对原始数据集进行过采样,使得失稳样本和稳定样本的数量基本达到平衡。经MAHAKIL 采样后的样本集采用五倍交叉验证,循环将样本集的80%作为训练集,剩余20%作为测试集,对训练集进行重复有放回采样,并行训练20 组CLM 以集成BCLM 模型,模型输入和输出分别为样本特征与其对应的暂态稳定标签,模型训练之后在测试集上对模型性能进行初步验证。
3.3 模型更新
由于系统中存在着负荷分布变化、发电机出力分布变化、拓扑变化等不确定性因素[22-24],离线训练得到的模型难以适应实时多变的场景。为了提高模型实时应用的可靠性,设立更新机制对模型进行更新以应对系统运行工况的潜在变化。
模型更新过程如图5 中所示。通常从电网公司获得历史故障列表后,离线训练阶段会为每个故障准备对应的BCLM 评估模型。当接收到PMU 实时量测数据时,若变化的运行工况已被包含在离线数据库中,则使用对应的已训练的BCLM 模型进行暂态稳定评估;若变化的运行工况未包含于离线数据库中,则将使用新的变化工况训练新的评估模型。值得一提的是,模型更新是一个长期的过程,系统监控人员可根据日前调度计划对未来一段时间内的运行工况进行预测,若遇数据库中尚未计及的工况变化,也有时间充分训练新的BCLM 模型,理论上随着模型更新机制的重复执行,离线数据库中记录的不同运行工况将不断增加,最终实现实时的暂态稳定评估。
3.4 在线评估
将训练好的BCLM 模型投入在线应用,当系统实时的PMU 量测数据输入训练好的BCLM 模型时,电力系统当前运行状态的暂态稳定评估结果可以被立即给出。若当前运行状态被评估为稳定,则保持对电力系统的持续监测,否则,向系统监控人员发出警报信息。
3.5 模型性能评估指标
考虑到临近暂态稳定边界的样本被错误分类的可能性,本文采用准确率Ac和召回率Rc作为模型性能评价指标[25],定义如下:

式中:Ts和Tu分别为被正确分类的稳定样本和失稳样本数;Fs和Fu分别为被错误分类的失稳样本和稳定样本数。
准确率Ac表示所有样本中被正确分类的样本比例,召回率Rc表示所有失稳样本中被正确分类的样本比例;两指标能从不同方面反映评估模型的分类性能,指标越高,表明模型对临近稳定边界的样本分类准确性越高。在5 倍交叉验证测试集上的初步性能测试显示,BCM 的准确率Ac和召回率Rc分别达到了98.14%和97.20%。
4 算例分析
为验证所提方法的有效性,本文在新英格兰10机39 节点系统上进行了测试,如图6 所示,该系统包含10 台发电机(G)、39 条母线和46 条线路。所有性能测试均在配置为Intel Core i7 3.40-GHz CPU/8 GB RAM 的设备上进行。

图6 新英格兰10机39节点系统图Fig.6 New England 10-machine 39-node system
4.1 样本生成
基于PSS/E 仿真软件进行暂态稳定仿真,在80%~130%范围内设置11 种负荷水平,相应地调整发电机出力以保证潮流收敛。在线路0%,20%,50%,80%的位置处设置三相短路故障,故障持续时间分别设置为0.1 s,0.15 s,0.18 s,0.2 s,仿真总时长设置为5 s。最终生成9 642 个样本,其中稳定样本与失稳样本约为7:1。经过MAHAKIL 过采样后,失稳样本和稳定样本数量达到平衡。
4.2 不同采样方法对比
为了验证MAHAKIL 过采样算法的优越性,将其与ROS、SMOTE 和ADASYN 算法进行对比。分别对4.1 节生成的原始样本集进行采样处理,再利用BCLM 模型进行评估,评估结果如表1 所示。

表1 不同采样方法下BCLM的测试结果Table 1 Test results of BCLM under different sampling method
从表1 中可以看出,ROS,SMOTE,ADASYN 和MAHAKIL 算法均对评估结果有一定提升。但与其它方法相比,MAHAKIL 过采样法能有效提升新样本的多样性,样本间的重叠率极低,评估模型不易过拟合。由对比结果可见,MAHAKIL 过采样法对样本分布不平衡的改善效果相较于其它采样算法更为显著。
4.3 原始样本集规模的影响
为了进一步验证MAHAKIL 过采样算法对于评估准确性的提升效果,选取不同规模的原始样本集进行测试,测试结果如图7 所示。当样本数目为1 000时,评估准确率为98.12%,召回率为97.18%。之后再增加样本数目,模型准确率和召回率无明显提升,但模型训练时间大幅度增加。可见,少量MAHAKIL过采样算法生成的样本就能使得评估模型的拟合效果达到较高的水准,间接说明MAHAKIL 过采样算法对样本特征信息有着较高的保全程度。

图7 原始特征集样本数目的影响Fig.7 Effect of sample size of original feature set
4.4 模型评估性能对比
为验证BCLM 模型的评估性能,将其与常用的数据驱动方法进行对比分析,包括决策树(Decision Tree,DT)、人工神经网络(Artificial Neural Network,ANN)、ELM 和CLM 模型。ANN 采用五层结构,隐含层单元数目为100;DT 采用CART 算法。测试结果如表2 所示。
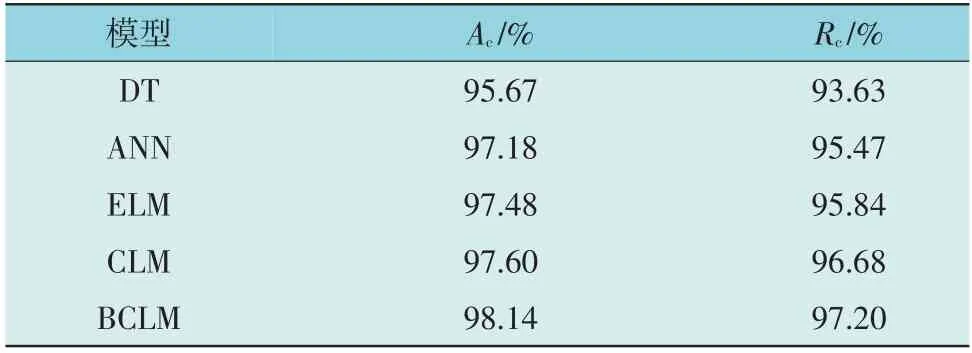
表2 不同模型的测试结果Table 2 Test results of different models
由表2 可以看出,ELM 的分类性能较DT 和ANN更为优异,而经ELM 改进后的单一CLM 分类精度显然更高,通过Bagging 策略集成后的BCLM 则表现出了更为良好的分类精度,其准确率和召回率分别达到了98.14%与97.20%。综合可见最终模型的实际暂态稳定评估效果与前文所述完全吻合。
4.5 缺失数据和测量噪声的测试
为了验证所提暂态稳定评估方法对数据缺失和噪声的鲁棒性,本文做了如下验证测试:
1)缺失数据:在测试集中随机选取缺失样本,使用不同的缺失数据百分比ρ。在这个测试中,ρ分别被设置为5%、10%、20%和40%,相应的检验结果如表3 所示。
从表3 结果可以看出,随着ρ的增加,缺失数据对模型的评估结果产生的负面影响逐渐上升,但BCLM 模型的各项性能指标仍能维持在可接受的水平(>96%),可见,该方法对缺失数据具有较强的鲁棒性。

表3 不同比例缺失数据的评估精度Table 3 Assessment accuracy of missing data in different proportions
2)测量噪声:考虑到在实际系统中测量数据容易受到许多因素的干扰,通过PMU 获取的量测数据与真实值之间可能存在量测误差。根据IEEE C37.118 标准,PMU 产生的量测误差通常保持在1%以内,本文向MAHAKIL 过采样方法处理后的数据集中添加10~40 dB 的高斯白噪声来模拟测量误差,对应实际数据噪声范围约0.01%~3%,测试结果如图8 所示。

图8 噪声对各模型评估性能的影响Fig.8 Influence of noise on evaluation performance of each model
由图8 可见,随着高斯白噪声水平的不断提高,DT,ANN,ELM,CLM 模型的准确率和召回率下降幅度均逐渐增大,而BCLM 模型在面对噪声干扰时的表现相对稳定,在噪声水平升高的过程中其准确率和召回率波动微小。即便在噪声水平为10 dB的条件下,其准确率和召回率仍分别达到97.64%和96.13%的水平,由此可见BCLM 模型与其他模型相比,在应对噪声时亦具有更强的鲁棒性。
5 结论
1)通过MAHAKIL 过采样方法对原始样本集进行采样处理,生成新的平衡样本,有助于提高后续暂态稳定评估模型的评估性能。与ROS、SMOTE 和ADASYN 方法相比较,MAHAKIL 过采样算法对样本分布失衡的改善效果更好。
2)通过选取不同的原始样本集规模进行模型性能测试,发现MAHAKIL 过采样算法在解决原始样本不平衡问题的同时,对样本特征信息的保全程度较高,用较小的样本规模训练出准确率较高的评估模型,大大减少模型训练所需时间。
3)将BCLM 与其余4 种的数据驱动模型进行对比分析,BCLM 表现出更高的预测准确率和召回率,其暂态稳定评估性能相比之下更加优越。
4)在检验缺失数据对训练模型评估性能影响的实验中,尽管原始样本数据产生不同程度缺失,BCLM模型仍能在暂态稳定评估中保持令人满意的分类精度,说明本文方法对缺失数据具有较强的鲁棒性。
5)在数据中含有不同分贝的高斯白噪声的情况下,BCLM 模型依然能保持较高的准确率及召回率,表现出对数据噪声较高的鲁棒性。
