基于改进DarkNet 框架的YOLO安全帽检测模型
2022-07-24程阳黄灵湛陈立汪宇玲
程阳 黄灵湛 陈立 汪宇玲
(东华理工大学信息工程学院,南昌,330013)
0 引 言
目标检测是指通过输入图像以确定目标物体的位置和类别的过程,它是图像处理领域的一个重要研究方向,在安全帽识别、桃花检测、船舶跟踪等领域都有应用。据相关数据统计,施工过程中因种种原因致人员伤亡等造成的经济损失平均每年逾百亿元[1]。在建筑行业中,除了对施工人员进行三级安全教育以外,还要做好“三宝”措施——安全帽、安全带、安全网。然而,施工人员可能会出现忘记佩戴安全帽、长时间脱下安全帽等情况,导致意外发生[1]。
在基于计算机视觉的安全帽检测领域,目标检测算法有传统检测算法和深度学习的检测算法两大类。传统的目标检测方法包括帧差法[2]、光流法[3]、HOG 检测器[4]、YCbCr 色彩模型[5]等,这些算法利用了肤色、头部和人脸信息配合图像处理和机器学习来得到目标检测结果。传统的检测方法在特定的环境下可以取得良好效果,但在真实复杂的环境下,基于传统方案的安全帽检测会受影响,其准确性难以得到保证,导致安全帽识别不准确。同时,传统的目标检测方法的主观性强,检测过程繁琐,计算开销大,泛化能力不足,在检测的场景中往往具有很大的挑战性。
近年来人工智能发展迅速,目标检测作为计算机视觉领域的一个研究热点[6],越来越多的研究者采用基于卷积神经网络(CNN)[7]的目标检测方法实现安全帽检测。徐守坤[7]等在算法Faster-RCNN 的基础上实现安全帽佩戴检测,检测准确率高,但是算法实现复杂,训练步骤繁琐,检测速率慢;肖体刚等[8]通过增大输入图像尺度,添加深度可分离卷积结构,减少特征的丢失。基于卷积神经网络的目标检测算法,不需要人为地设计和选择特征,而是通过向深层网络输入已有的大量训练数据,不断训练深度网络模型,从而获得深度学习特征,再利用这些特征对需要测试的图片进行预测,并且可以根据预测结果不断地进一步优化特征。深度学习特征能够获得图像更深层次的抽象特征,能表征图像高层语义,在诸多应用领域,深度学习检测算法相比传统算法都表现出众。
YOLOv3 算法使用了One Stage 思想,特征图直接回归目标的类别和位置,检测速度较快,且同时吸收了残差网络和特征金字塔等优点,提高了模型的精度[9]。YOLOv3算法检测速度较Faster-CNN算法已经有了提升,但对于小目标和集群式的目标检测效果并不好。因此,为了提高小目标和集群式的目标检测精度,本文提出一种基于改进的DarkNet 目标检测算法,通过调整DarkNet的卷积层网络,使用反卷积模块对网络进行采样,使得YOLOv3 检测较集中地被目标遮挡也有较好的效果,最后进行相关实验,实验结果表明检测精度有一定的提升。
1 安全帽检测的关键技术
1.1 DarkNet 深度学习框架
DarkNet 深度学习框架是由Joseph Redmon[10]提出的一个用C 语言和CUDA 编写的开源神经网络框架,其主要作用是提取训练图像的相关特征[10-11]。它支持CPU和GPU(CUDA/cu DNN)计算,且支持Open CV 和Open MP,同时DarkNet 框架结构清晰,源代码查看、修改方便。DarkNet 借鉴了ResNet[12]网络中的 shortcut 方法,对前后提取的特征值进行组合,加强对于特征数据的训练。DarkNet 能够对于目标检测做出合理的网络设计[13],该结构的出现使得使用该网络结构的 YOLO 算法在精度和检测综合性能上面都得到了很大的提升,成为 YOLOv3 等新算法主要采用的主网络结构。
1.2 YOLOv3 网络结构
YOLOv3 是一种实时对象检测算法,可识别视频、实时供稿或图像中的特定对象。YOLO 的 1-3 版本由Joseph Redmon 和 Ali Farhadi 创建[10],是用于进行对象检测的深度卷积神经网络模型 (DCNN)。它允许模型在测试时查看整个图像,因此它的预测由图像中的全局上下文提供信息,根据区域与预定义类的相似性对区域进行“评分”。
YOLOv3 对图片分区域进行特征提取和训练,以更好地区别目标和背景。YOLOv3 算法将整个图片分为若干个区域,在对图像进行输入时,会将图像置于某个区域进行检测和预测,在每次预测时会有一个置信度,从而根据置信度判断该检测区域是否会被分类和贴上相应的标签,既而完成从检测到预测的过程。YOLOv3 的网络结构如图1 所示,图2 是 YOLOv3 与主流检测算法的性能对比图,对比可以看到YOLOv3 检测速率和准确率比大部分算法优秀。因此,本文选用YOLOv3 进行安全帽检测,以达到提高小目标和集群式的目标检测精度的效果。

图1 YOLOv3 网络结构

图2 YOLOv3 与其他算法性能对比
2 基于改进DarkNet 框架的YOLO 安全帽检测模型
2.1 卷积操作
在深度学习中,计算机视觉领域最常见的网络是卷积神经网络,卷积操作是卷积神经网络最基础的组成成分。如图 3 中,左侧的Source pixel 可看成是一张图片的数据,中间的Convolution kernel 是卷积核(滤波器),右侧的New pixel value 是卷积之后的结果。卷积的计算过程如图3 右侧,即对应位置相乘的结果累加。当卷积核向右移动一个步长后,做同样的操作,则得到第二个值。很容易计算得出第二个值也是-8。经过5 次计算之后,需要将窗口对准下一行的开头,同样可以计算出5 个值。当依次完成所有操作就可以得到一个5×5 的数组。

图3 卷积操作
该操作可以提取所需要的目标特征。可简单理解为,当卷积核的数字固定时,则就代表它能够检测某个特征,当图像中有这个特征存在时,按照卷积的操作,结果的数值会很大,数值越大就代表存在这样特征的可能性越高。当网络越深,抽取的特征也就更抽象。
2.2 批归一化
学习数据分布是卷积神经网络的特征学习本质,如果训练数据与测试数据的分布不同,网络泛化能力就会大大降低。另一方面,卷积神经网络训练过程复杂,只要前面网络发生微小的改变,该改变就会在逐层传递的过程中被累积放大,造成网络模型的不稳定,这将大大降低网络的训练速度。在对网络进行训练时,由于每一层的参数不断地向前传播,不断地更新,所以各层的输入数据分布都在不断地发生改变,其分布会逐渐发生偏移,Loffe 等[14]针对该变化提出批归一化算法,通过批归一化算法可以使输入数据保持正态分布,从而加速收敛,以减少网络数据分布的改变对神经网络参数训练的影响,从而加快神经网络的收敛速度和稳定性。其主要步骤如下:


2.4 损失函数
在训练初期的时候,由于网络参数的初始化,位置信息、类别信息和置信度信息与真实的值会有较大的差别,于是YOLOv3 根据预测框和真实框的中心点坐标以及宽高信息设定了MSE 损失函数[15]。
YOLOv3 损失函数主要包括3 部分:坐标误差、IoU误差、分类误差。其公式为:

2.3 激活函数
在卷积层后,通常会添加偏置,为此会引入激活函数。在卷积中会对图像的每个像素点赋予权值,但该操作并不适合所有的情况,针对这个问题,本文考虑进行线性变化或引入非线性的因素来解决,激活函数则是其中一种较为普遍的方法。它可以将线性数据映射到非线性中,从而增强网络拟合能力。

2.5 反卷积网络
将特征图像还原到原图像空间的方法称为反卷积网络。本文通过将YOLOv3 原来的上采样过程变换到反卷积模块,用于重建输入图像的边缘细节信息以及增加特征图像的分辨率,从而提高小目标和集群式的目标检测精度。使用如图4 所示的反卷积来替代原采样过程,让网络的反卷积结构与原复杂的模块具有更好的精度,且使网络更加高效。

图4 反卷积结构
3 实验分析
本文实验基于DarkNet 框架下进行,操作系统为Windows-64,硬件环境为:Intel(R) Core(TM) i5-8265U CPU@ 1.60GHz 1.80 GHz, 内 存 为8GB,NVIDIA Tesla V100 GPU,显存为16GB。
3.1 实验数据集与预处理
在深度学习中,数据集质量的高低直接影响最终检测效果的好坏,同时由于网络要充分学习待检测目标的特征,这便需要大量的样本。本文在实验中采用数据集的方法,共采集7581 张图片,样本示例如图 5 所示。由于数据是xml 格式,需要先提取图片中物体的位置和大小信息,每一张图片对应一个文本,每一个目标对应该文本的一行数据,一张图片有多个目标,因此可能有多行数据,每行数据包括位置中心坐标、长宽以及类别信息。提取的xml文件关键数据包括:目标类别(class)、目标位置(x-min,y-min, x-max, y-max)、图像宽高(width, height)。

图5 样本示例
将目标位置信息变换成相对图片大小的数值,用空格分开,分别是:目标x 中心点、目标y 中心点、目标相对宽度、目标相对高度,位置信息的取值范围均在0~1之间。一个文本存放一张图片的所有目标类别和位置信息,每一行只存放一个目标的类别和位置信息,若一张图片有n 个目标,则该文本就有n 行5 列数据。训练流程如图 6 所示。

图6 训练流程图
3.2 网络训练
本文通过对数据进行聚类处理,以获取先验框,降低计算的难度,由于DarkNet 框架已经自带了聚类的命令,因此可以很容易地得到聚类结果。
笔者将数据集划分为三部分,其中5581 张图片用于训练,1000 张用于验证,1000 张用于测试;在数据增强方面,笔者对训练集中的图片执行裁剪、翻转等操作以生成更多的样本;在配置文件中修改学习率、图片大小、batch-size、sub_batch 等相关参数。
训练结果如图 7 所示。

图7 准确率及损失函数趋势
3.3 不同模型解的对比
本文使用的网络结构包括YOLOv3_416、YOLOv3_608、YOLOv3_spp_416、YOLO3_spp_608、csresnext50_panet_spp_416、YOLOv3_5l_416、YOLOv3-tiny _416(移 动端)。416、608 代表网络将输入的图片重构的初始大小为416×416 或608×608,设置7 组实验的目的是为了寻找一套最佳的网络结构和权重参数。不同网络模型参数最终的结果如表1 所示。
从模型结果中,综合各项指标(见图 8 )可以看出,csresnext50-panet-spp_416 网络结构最优。
此外,从测试集进一步验证,csresnext50-panetspp_416 网络结构依然是最优结果,其他网络优化度不足,可能出现了训练过拟合或欠拟合,结果如表2 所示。
从图 9 可以明显看出,csresnext50-panet-spp_416 优于其他网络结构。
在表1、表2、图8、图9 中,Hat AP、Person AP 分别表示检测佩戴安全帽的平均精确度和检测未佩戴安全帽的平均精确度;recall 表示召回率;F1 score 表示精确度和召回率的调和平均数;mAP@0.5 表示交并比设置为0.5 下的均值平均精度;average IoU 表示平均交并比;FPS RTX2060 表示使用RTX2060 6G 显卡时每秒传输帧数。

图8 验证集各项指标趋势图
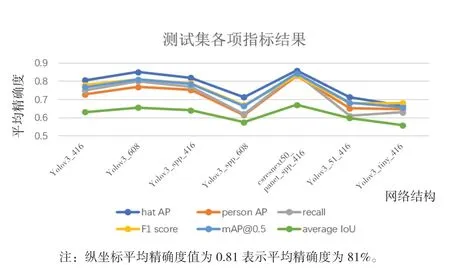
图9 测试集各项指标趋势
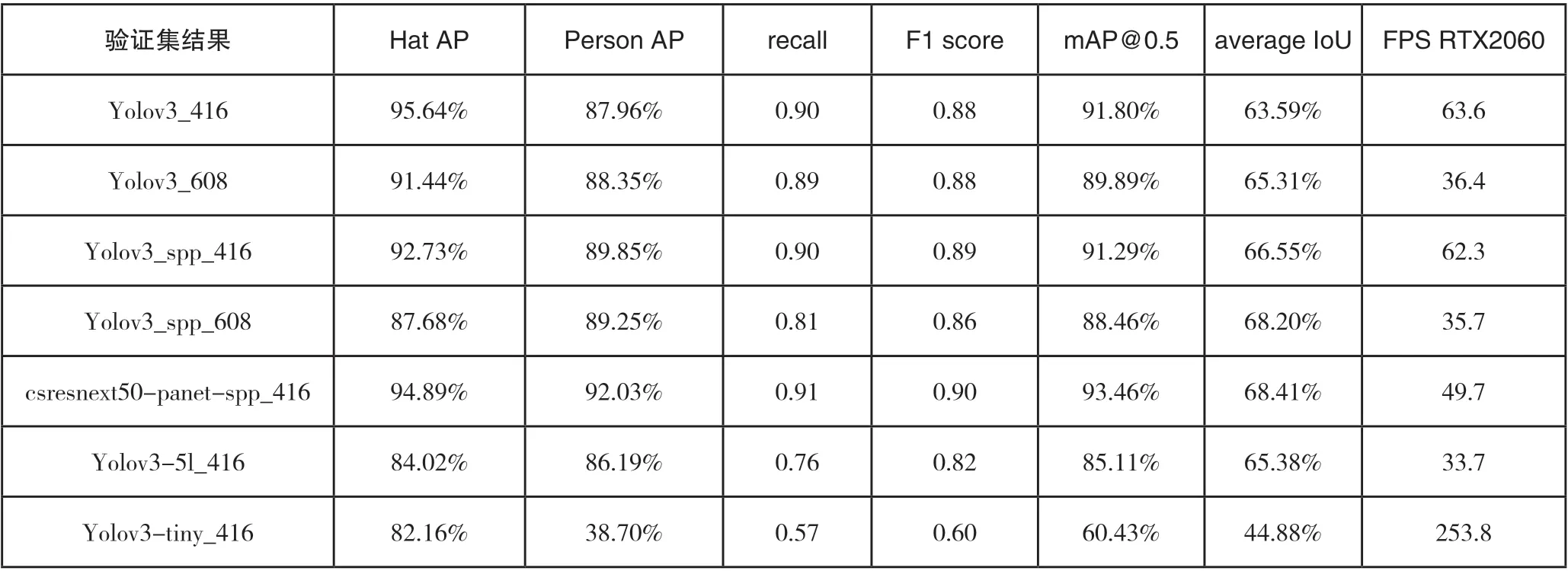
表1 验证集结果

表2 测试集结果
本文使用采集得到的验证集,得到部分安全帽检测模型结果示例如图 10 所示,可以看出,改进的DarkNet在不同场景下均有较强的检测能力,其中图中佩戴安全帽的施工作业人员上方出现 “ hat ” 字样,未佩戴安全帽的施工作业人员上方出现 “ person ” 字样。由此可知,本文使用的模型在复杂背景等不利因素下,提高了小目标和集群式目标检测精度,整体效果较为理想。

图10 安全帽检测模型结果
4 结 语
针对安全帽的佩戴检测,本文提出了一种基于改进的DarkNet 框架下YOLO 系列的安全帽佩戴检测方法,该方法可以有效检测现场未佩戴安全帽人员的情况,从而避免因未佩戴安全帽而导致的人员伤亡以及经济损失,保障人员生命及财产安全。另外,由于部分遮挡的目标检测准确率低,会导致检测不精确,对此类问题的解决是下一步研究的主要工作。
