维汉人名翻译中不雅字或OOV的前处理研究
2022-07-23阿里木赛买提沙丽瓦尔阿里木吐尔根依不拉音段雪明古丽尼格尔阿不都外力麦合甫热提吾守尔斯拉木
阿里木·赛买提,沙丽瓦尔·阿里木,吐尔根·依不拉音,段雪明,古丽尼格尔·阿不都外力,麦合甫热提,吾守尔·斯拉木
(1.新疆大学信息科学与工程学院多语种信息技术实验中心,新疆 乌鲁木齐 830046;2.新疆开放大学,新疆 乌鲁木齐 830049;3.新疆科大讯飞信息科技有限责任公司,新疆 乌鲁木齐 830015)
0 引言
人工智能的不断发展,深度学习技术推动了机器翻译等自然语言处理技术重大进展,并且通过大量的训练数据的支撑下核心效果不断提升[1].在神经机器翻译模型中Arthur等[2]引入外部词汇从而解决翻译过程中的数据稀疏问题.文献[3-5]提出的基于注意力机制的神经机器翻译相比传统基于统计的短语翻译方法,翻译性能也取得了大幅改善,部分场景下翻译效果接近人类翻译水平.
维吾尔语是典型的黏着语种,自右向左横写,有8个元音字母,24个辅音字母,构词和构形附加成分很丰富,每个字母按出现在词首、词中、词末的位置有不同的形式,有些字母只有单式和末式,有些字母所带的符号除作独立形式和词首形式的标志外,还起隔音的作用[6].32个字母实际共有126种写法.维吾尔语因其黏着语言特征构词和构形附加成分很丰富而具有一个词杆可同时连接单个或多个词缀导致不断派生出新词的特点,易造成集外词问题,使维吾尔语信息处理技术成为众多研究者们的学术热点的原因之一,尽管采用BPE切词[7]、扩展词表等业界主流的方法后,在一定程度上缓解了部分集外词的翻译效果,但本质上并未解决集外词翻译问题,仍然伴有集外词错译、漏译、欠译、过译等现象,同时,维吾尔人名在机器翻译中除了面对集外词问题以外还会出现不恰当表示、不雅词或字等问题,因此维吾尔人名的翻译问题是维汉机器翻译中需要解决的重要问题之一.同样维吾尔语人名因其数据稀疏性,在机器翻译中易造成OOV问题,因此需要在前处理工作中除了需要做好人名译文体验感方面的工作外,还需要在建立神经网络翻译模型时将OOV问题的处理工作考虑在内.
OOV即训练集以外的词,可以有两种解释[8]:一是指已有的训练语料中未曾出现过的词;二是指已有的词表中没有收录的词又称为未登录词(unknown word).通常情况下将OOV与未登录词视为同一个概念.
尽管对于机器翻译而言,人名翻译是其中至关重要的环节,但由于维吾尔语人名存在着命名不规范、空间难以界定、在语料库中出现频率低等问题,维吾尔语人名识别和翻译一直是学术界和工业界研究的方向.也正是因为维吾尔语人名存在的上述特性,通常情况下,维吾尔语人名翻译不能与英文人名或汉语人名一样采用通用的规则或翻译方法进行处理.因此,维吾尔语人名翻译本质上是以信达雅为导向,对其进行字符级端到端的神经网络模型的建模.
维吾尔语人名具有频率稀疏性、边界模糊性、语义独立性、组成不规则性和译文多样性等特点,并且对译文的准确性和规范性的要求更高.不同语言的人名在构成方式和翻译规律方面也存在较大的差异,汉族人名译维吾尔语是按照字或者词为单位的发音进行音译和意译,并且翻译方向是顺序的,通常采用输出原词或音译相结合的方法进行翻译.维吾尔语人名处理不仅仅要解决普通句子翻译的固有问题,如词语选择与译文准确及流畅,还需要解决译文是否符合信达雅的问题.可见,维吾尔语人名的翻译是机器翻译中一个极具挑战的任务.
本文从机器翻译的角度出发.引入了一套前处理流程,提出了Fast align + NER组合方法,通过从常规维汉句对数据中进行识别及对齐,有效地解决了维汉对照人名数据稀少、难以获取的问题.
1 建立维汉人名数据集
命名实体识别(name entity recognition,NER)是指从大量的非结构化或结构化文本中抽取出相应的人名、地名或组织机构等实体,并对其进行精确的分类识别.而传统的命名实体识别方法非常依赖于语言学知识和特征工程,忽略了文本中实体所隐含的潜在信息,从而增加了文本中命名实体的识别难度.因此,如何利用有效的特征和神经网络技术来提高文本中命名实体的识别准确度已成为研究的一个热点课题.随着人类生活水平的提高,每天在互联网上出现海量的人名信息.对人名信息的处理能力受到的关注度越来越强烈.
本文通过收集历届机器翻译研讨会CWMT及CCMT提供的维汉双语平行训练集和通过人民网、天山网自建的维汉平行训练数据集上进行维汉人名抽取.在整理好的维汉平行语料基础上通过汉语命名实体识别方法与维吾尔语命名实体的识别方法进行了人名抽取并且分词后通过Fast align快速词对齐工具进行了维汉人名的识别对齐及抽取,对齐实例见表1.

表1 Fast align 对齐操作实例
本文在中文人名识别中使用了业界开源且比较主流的哈工大语言技术平台(Language Technology Platform,LTP)提供的中文命名实体识别能力.在维吾尔语命名实体的识别方法中使用了引入子词向量的bi-LSTM+CRF的方法[9],传统的bi-LSTM+CRF神经网络模型中,输入向量以单词为基本单位.然而,维吾尔语是一种由词干和词缀组成的黏着语言.如果只考虑单纯的使用词向量,就不能充分学习语义信息,导致词法过程中数据的稀疏性.因此,我们考虑利用更小的承载单元子词选为基本单元.这里的子词是将维吾尔语单词通过形态切分将一个单词的词缀与词干切分开后的输入单元进行训练建模的方法.
2 维汉端到端神经网络人名翻译模型
被NER识别后抽取出来的人名信息会传输到端到端的字符级神经网络翻译模型中.在传统的维吾尔语汉语机器翻译结果中,在维译汉方向经常会出现不雅字或词.不能使译文达到信达雅.例如:“bEkriyE”对应的常见人工翻译的恰当选词结果为“拜克热亚”,但在以往的机器翻译结果中经常会看到“拜可日牙”或将“turGun”翻译成“吐儿滚”等不雅词(而正确的选词结果应该为“图尔洪”).对该类情况的出现综合分析认为:
(1) 部分是因早期维吾尔人名用汉字记录证件时未有一个恰当的选词标准;
(2) 当时人们的恰当选词意识不强;
(3) 因汉字常用多音字而维吾尔语一音一字,造成维吾尔语人名可对应多个汉语,结果无法统一.
因此使该类数据混入机器翻译训练数据呈现数据稀疏状态易造成OOV问题,而另一个原因可能是因为在常规的训练数据的形式为句对形式为主,而对应的人名数据因在数据中的比例较少,可能在常规的机器翻译结果中会出现非规范的结果.为解决上述问题,使得维吾尔语人名翻译结果能够尽可能准确、雅观,通过一个基于纯维汉人名的端到端的神经网络翻译模型,使抽取到的实体能够通过该模型给出准确的译文,提高用户体验效果.
因此,选用词对形式的纯人名训练数据,并且为了从人名训练数据中去除影响译文雅观的潜在因素,将汉语维吾尔族人名通过N-gram语言模型进行训练,分别得到1—4阶语言模型,找到数据中一个维吾尔文人名对应的多个中文表示(1对N)的数据,根据语言模型对人名列表进行打分,去除打分结果中每个得分最优的两个汉语人名表示以外的结果,见图1.最后结合人工审核,获取精炼后的人名训练数据集,因精炼后的数据集量级较少,避免OOV问题的困扰,为此选用字符级的建模方案,选用Lee等[10]提出的字符级端到端的神经网络框架完成对维汉人名翻译模型的训练(见图2).
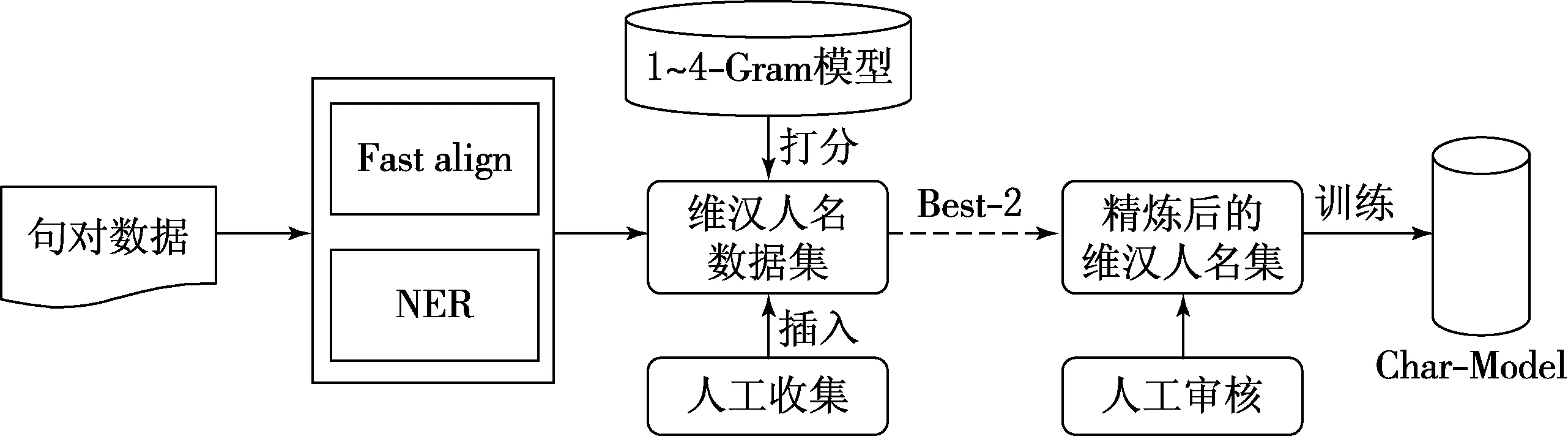
图1 维汉人名翻译前处理总框架
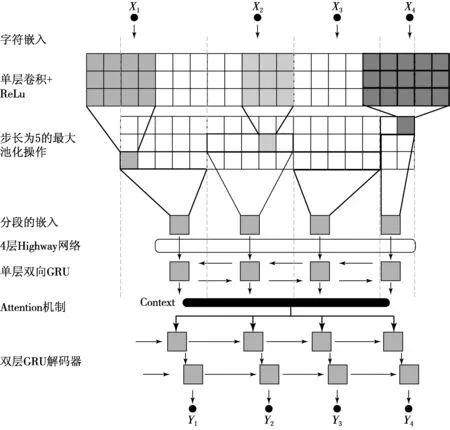
图2 字符级维汉人名翻译模型
3 实验数据与实验环境
考虑到目前国内各机器翻译研讨会提供的维汉双语平行训练集都以句子级语料,无公开维汉人名数据集,因此本文通过收集历届CWMT及CCMT等研讨会提供的维汉句对数据为主进行人名的抽取及精炼获取最终的维汉人名训练集.目前已从61万条维汉句对数据中抽取并人工收集维汉人名训练集,在通过对数据进一步预处理分别完成了形式转换、编码转换、全角半角转换、标点符号的规整、乱码过滤、去重等预处理过程后最终获得32 126条人名集.
目前业界无公开且符合我们需要的维汉人名数据,因此无法通过公开且统一的测试集进行衡量,为了降低维汉机器翻译中维吾尔语人名译文中不雅字或词的出现及避免OOV问题的困扰,采用人工收集人民网、天山网中出现频率比较高的汉语维吾尔人名,自建500条维汉双语维吾尔人名测试集.
实验环境采用CentOS 7.3 64 位操作系统,内存64 GB,Tesla p40,Intel(R)Xeon(R)CPU E5-2650 v3@2.30 GHz 2CPU 20核处理器.在实验部分,使用了开源的基于 Theano 深度学习库的dl4mt-c2c框架进行模型训练,模型网络参数基本以开源base版本参数一直使用GPU单卡训练.

表2 实验过程参数
在实验过程中网络的源端词表大小为97,目标端词表大小为542,训练和解码时长、模型大小参数见表2,该系统采用网络结构为CNN+RNN网络形式;encoder隐层节点数目为512;decoder隐层节点数目为1 024;Embedding向量长度方面source embedding为128 MB,Target embedding为512 MB;Highway网络为4 layers;Cnn_kernel_width=(3,5);Initial_learning_rate为0.000 2;Conv_embed_num_filters为200-250-300-300-400-400-400-400;Pooling Strid值设为5;BatchSize大小为64.
4 实验结果与分析
实验结果见表3.由表3可见,当对训练数据通过1—4阶N-Gram语言模型打分后,其在自建的用字恰当的人名测试集上的译文BLEU结果提升了0.95分.但一个维吾尔语人名除去带有不雅字的结果外常还有其他译文易导致机器打分存在歧义,因此,在无权威公开用字准确且标准的维汉人名测试集的前提下用BLEU打分机制结果具有片面性,无法全面体现本文的研究成果,但通过对比加入本文前处理方法后,在处理不雅字或诡异表达效果较好,表4为译文数据中抽取出的较典型的实例.由表4可以看出,虽然加入了本文前处理方法后的模型结果中仍有“吐”,“沙”等字样的出现,但是在雅观或体验上都有了显著的提升.
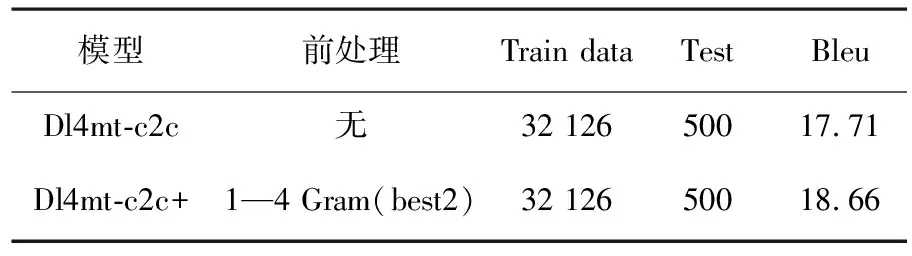
表3 实验结果
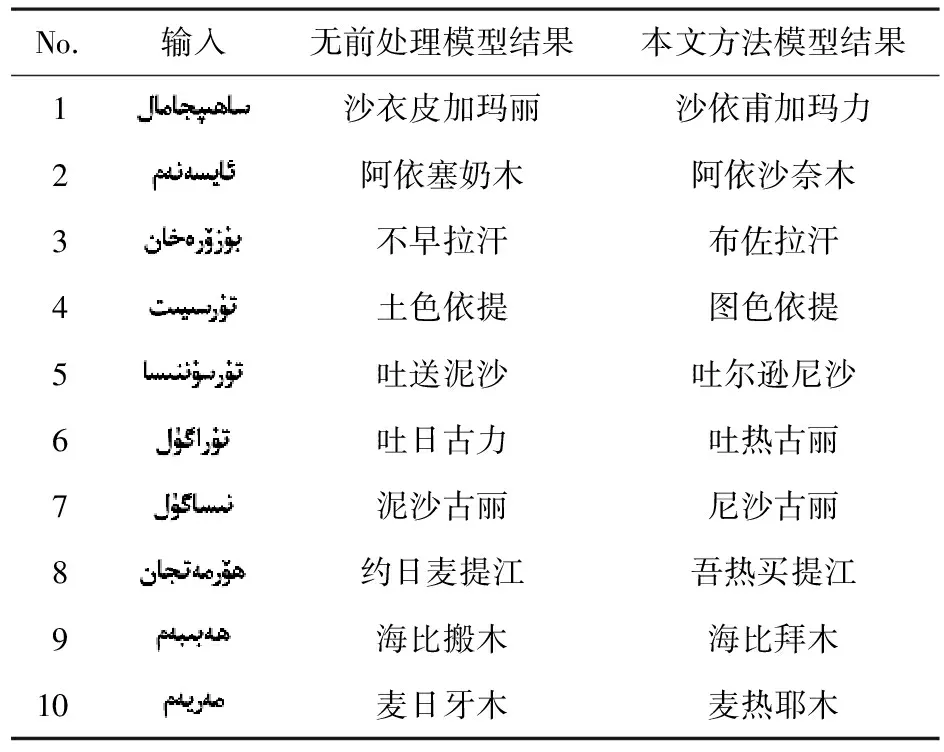
表4 典型实例展示
本文以维汉人名翻译中译文结果中出现OOV或不雅字问题的处理方法为初始目标进行探索,通过实验分析规划出了一套完整地将含有不雅字或词的人名数据处理方法,考虑到数据稀疏原因,为避免模型训练无法达到良好的收敛效果,选用轻量级的dl4mt-c2c框架,本文方法对处理不雅字或不恰当的表示有明显的改善.
