一种基于FPGA+DDR3的雷达数据高速重排方法
2022-07-22黄禹铭
黄禹铭
(中国电子科技集团公司第二十九研究所 成都 610036)
0 引言
随着电磁环境的日益复杂,为改善严重杂波背景下检测小运动目标的性能,动目标显示(MTI)及动目标检测(MTD)在雷达信号处理中获得比较普遍的应用。MTD是一种利用相参积累来提高信噪比,从而提高雷达在杂波背景下检测动目标能力的技术。回波信号要进行MTD处理,需要将雷达回波信号进行存储和重排。
FPGA处理速度快,数据吞吐量大,常作为雷达平台上信号处理的主处理器,但FPGA是以硬件实现的系统,内部的存储容量有限,不能满足回波信号存储需求,因此必须外接存储芯片。目前常用的芯片有DDR和QDR两类。考虑到需要储存的数据量和价格成本等两方面因素,大多数雷达系统使用存储容量大且价格低的DDR作为外接存储芯片,特别是以DDR3作为主流的外接存储芯片。
DDR3利用双数据速率实现高速工作,采用了bit预读取技术,数据传输效率高,多Bank的设计可使存储容量更大。但是DDR3工作时需要刷新和预充电,会产生一定的时间损耗,且对跳变地址的读写,存在频繁换页操作,会导致读写速率大幅降低。
根据重排原理可知,重排过程中需要频繁的跳变地址,由于DDR3跳变地址读写速率低的器件特性,导致使用DDR3进行重排时,重排速率受限于跳变地址的读写速率,且速率往往较低。以DDR3-1333 / 8Gbit为例,对512个脉冲重复周期(PRI),7500个距离单元进行重排,48Bit位宽的数据,实测最大速率仅为19.23MHz。
随着雷达技术的发展,雷达的信号带宽和数据率也在逐步提升,因此对雷达信号处理能力、速度提出了更高的要求和挑战。但由于当前使用DDR3进行重排的速率低,已不能满足现代大带宽、高数据率雷达信号处理的需求。如一部信号带宽5MHz,基带采样率6.25MHz,有和、方位差、俯仰差、辅助四个波束的雷达,其对重排速率的最低要求为6.25MHz×4 = 25MHz,大于当前重排的最大速率,因此本文提出一种基于FPGA+DDR3的雷达数据高速重排方法,可有效提高重排的速率,解决当前重排速率不能满足现代雷达要求的问题。
1 改进思路
根据上述可知,当前使用DDR3进行重排速率低主要原因是重排过程中频繁的跳变地址所导致,想要提升DDR3重排速率,可从以下两方面入手:一是提升跳变地址读写速率;二是减少跳变地址次数。
跳变地址读写速率主要是由器件性能和跳变地址步进决定,器件性能是固有属性,无法从使用层面上进行优化和提升;跳变地址步进跟雷达波形参数和基带采样率有关,一旦确定,不能随意变更,否则影响雷达性能。因此无法通过使用层面提升跳变地址读写速率。
由此只能通过减少跳变地址次数来提升重排速率,根据DDR3器件特点,为充分利用DDR3数据总线位宽大、顺序地址读写速率高等优点,可从以下三点进行优化改进,以减少跳变地址次数,提升重排速率:
1)输入数据拼位,充分利用总线位宽。通常输入数据的位宽较DDR3的数据位宽小很多,可将多个数据拼接成一个写入DDR3的数据总线中,以此减少读写次数。
2)按块读取,减少重排读数时地址跳变次数。重排读数时不再是按单个存储单元读取,而是将相邻的多个存储单元视为一块,按块进行读取,以此减少地址跳变次数,提升DDR3访问效率。
3)设计同时读写时序,减少地址跳变次数。由于重排采用乒乓方式存储数据,可能会同时产生读写请求,且由于乒乓存储区域地址相隔较远,产生的读写请求地址存在跳变,因此需要合理设计MIG总线控制时序,在保证读请求按块操作的同时,均衡的响应读写请求,高效率的访问总线,以提升重排速率。
2 实现过程
根据上述改进思路,对重排流程进行重新设计,由于按块读取出的数据不满足重排输出数据格式要求,因此需要将DDR3读取出的数据再缓存至RAM,进行二次重排,以输出正确数据格式,由此将重排过程分割成一次重排和二次重排两个步骤完成,具体流程如图1所示。

图1 重排流程图
2.1 一次重排
一次重排主要包含数据拼接、DDR3读写控制、数据拆分等三部分,各部分详细介绍如下:
数据拼接是将个距离单元数据拼接成一个位宽接近或者等于DDR3数据总线的数据,然后以此数据写入DDR3数据总线,从而实现多个距离单元数据写入到一个DDR3地址中,充分利用DDR3数据总线的同时,也节约了数据的存储空间。原本单个PRI内个距离单元需要占据个存储单元和进行次总线操作,在进行数据拼接后均缩减为原来的1,一次读写可操作个距离单元,等效于DDR3的读写效率提升了倍。
DDR3读写控制主要实现功能为:
1)根据DDR3型号和参数设置Memory Interface Generator(MIG)核,实现FPGA对DDR3的总线控制。FPGA与DDR3的高速接口通过Xilinx公司开发提供的MIG IP核来实现,在产生MIG IP核时,可通过图形界面设置相关参数来产生一个存储器模型。用户不需要设计存储器内部复杂的读写操作时序,只需设计MIG核的读写控制逻辑,就可以完成对DDR3读写操作。
2)设计同时读写时序,减少地址跳变次数,以此提升重排速率。在实现重排时,主要包含用户层和MIG时序控制层两部分逻辑,用户层根据输入数据控制乒乓读写时序,产生MIG读写请求(读请求包含读使能和读地址,写请求包含写使能、地址和数据),并存入相应的FIFO中;MIG时序控制层根据时序读取FIFO中的读写请求,并控制MIG总线状态,从而实现DDR3读写操作。
在MIG时序控制层中,为保证读取操作按块进行,不被其他地址操作所打断,只有当读请求FIFO中请求个数大于等于时,才执行读操作;当已经连续读了个地址,且FIFO中剩余请求个数小于时,则停止读操作。而写操作则不需要按块进行约束,因为写地址连续,不论写操作在何处被读操作打断,其执行期间的地址均为连续,所以写操作是否按块进行不会导致地址跳变次数的减少或增加。但如果写操作也按块约束,当读写请求均不足个时,会出现总线闲置,导致总线资源时间上的浪费,因此写操作采用写请求FIFO非空即执行的方式。MIG时序控制状态图和时序图如图2、图3所示。
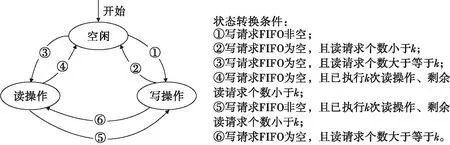
图2 MIG时序控制状态图

图3 k=4时,MIG时序控制时序图
图3中Wr_En、Wr_Addr、Wr_Data为用户层产生的写请求使能、地址和数据;Wr_Empty为写请求FIFO空标志位;Rd_En、Rd_Addr为用户层产生的读请求使能和地址;Rd_Count为读请求FIFO中剩余请求个数;Rd_Timer为连续执行读操作次数;Mig_State为时序控制机状态,0x0-空闲,0x1-写状态,0x2-读状态;app_rdy表示DDR3已经准备好接收命令,高有效;app_en为命令使能,高有效;app_cmd为当前请求命令,0x0-写请求,0x1-读请求;app_addr为当前请求操作的地址;app_wdf_wren为当前要写入DDR3的数据使能,高有效;app_wdf_data为当前要写入DDR3的数据。
由此,MIG的时序实现了从按单个存储地址进行跳变读取到仅块间跳变地址读取的优化。地址跳变次数由原来的每个地址跳变,缩减到连续执行次后才跳变,地址跳变次数缩减为原来的1/。
数据拆分是对应于数据拼接的逆操作,主要是将DDR3读出的大位宽数据拆分成个距离单元,以方便二次重排时使用。
一次重排输出数据格式如图4所示,图中(,)表示第个PRI内的第个距离单元回波数据。
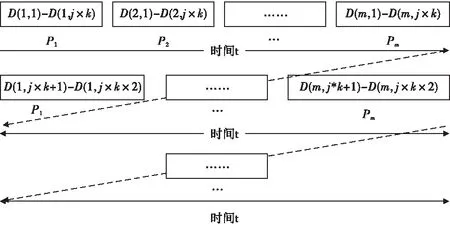
图4 一次重排输出数据流
2.2 二次重排
由于一次重排输出的为重排不完全的数据流,每个多普勒维中均还包含大小为×的连续距离单元,由于有个PRI,因此需要在FPGA内开辟两个深度为××的RAM,用于进行二次重排,以将数据完全转换成多普勒维。
二次重排按照常规方式进行,即按单个距离单元地址跳变读取数据,每当RAM中写满××个数据后,乒乓读写切换,同时启动上一写满RAM的读数。每完成一次RAM数据读取,则完成了×个距离单元的多普勒维数据输出,当执行完(×)次RAM数据读取后,即完成了CPI内所有数据从距离维到多普勒维的重排。
由此,通过上述步骤,可实现重排的优化和速率提升,但值得注意的是,方法中重排的速度提升跟数据拼接个数和分块的地址个数有关,当= 1且= 1时,本方法与常规重排一致,为重排速度最慢的情况。随着、数值的增加,重排速度也会逐步提高。但、的取值也不能任意取值和增加,存在一些限制条件:
1)为了让时序控制简化,、的取值应使和(×)均为整数;
2)由于二次重排中需要在FPGA内开辟两个深度为××的RAM,但FPGA片内RAM资源有限,、的取值需考虑片内资源情况。
3 验证
使用Vivado 2016.2创建工程并编码实现,在硬件平台中进行验证,其中使用FPGA 1片,型号为XC7K325T-2FFG900I;使用DDR3 4片,型号为DDR3-1333 / 8Gbit,4片DDR3并联接入FPGA中,从而构建出64Bit位宽的DDR3数据总线。读写请求FIFO缓存深度为512,MIG IP核设置参数为:Clock Period=625MHz,Input Clock Period=156.25MHz,Data Width=64。
输入数据为512个PRI,每个PRI有7500个距离单元,每个距离单元为I、Q复数,I、Q均为24Bit,取值范围为0~7499的递增数,I、Q按从高到低进行拼位,由此构成48Bit的输入信号。
验证时,所有信号均在250MHz的时钟下进行观测,通过Virtual Input Output(VIO)设置不同的读写速率,并校验输出数据是否正确,来验证、取值不同情况下的最大重排速率。详细验证结果如下:
1)=1,=1,此时为常规重排,最大无错误输入输出速率为13个时钟周期输入输出1个数据,因此当前最大重排速率为重排速率为250MHz/13=19.23MHz,验证结果图如图5所示。
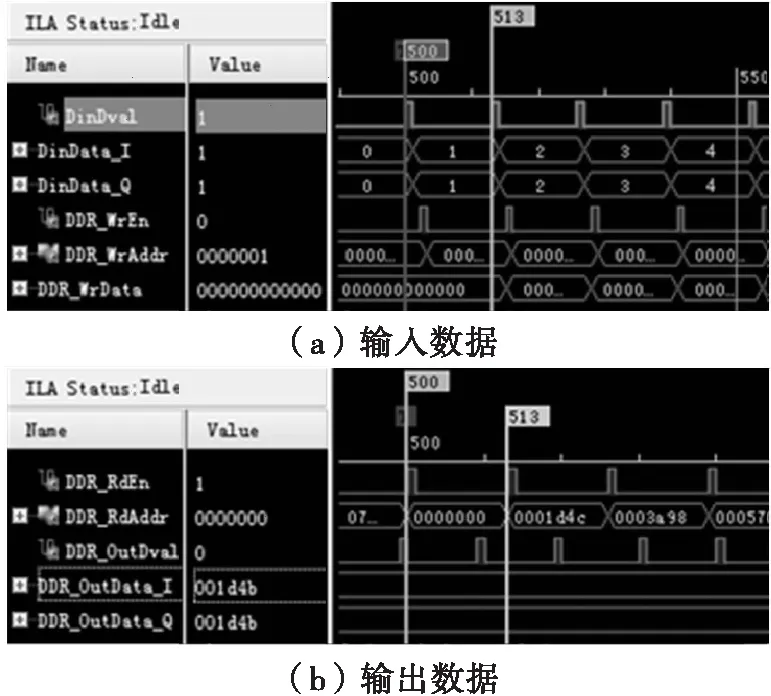
图5 j=1,k=1验证结果图
2)=10,=1,此时仅进行数据拼位,最大无错误输入输出速率为13个时钟周期输入输出10个数据,因此当前最大重排速率为250MHz×10/13=192.3MHz,验证结果图如图6所示。

图6 j=10,k=1验证结果图
3)=1,=10,此时仅进行按块读取,最大无错误输入输出速率为40个时钟周期输入输出10个数据,因此当前最大重排速率为250MHz×10/40=62.5MHz,验证结果图如图7所示。
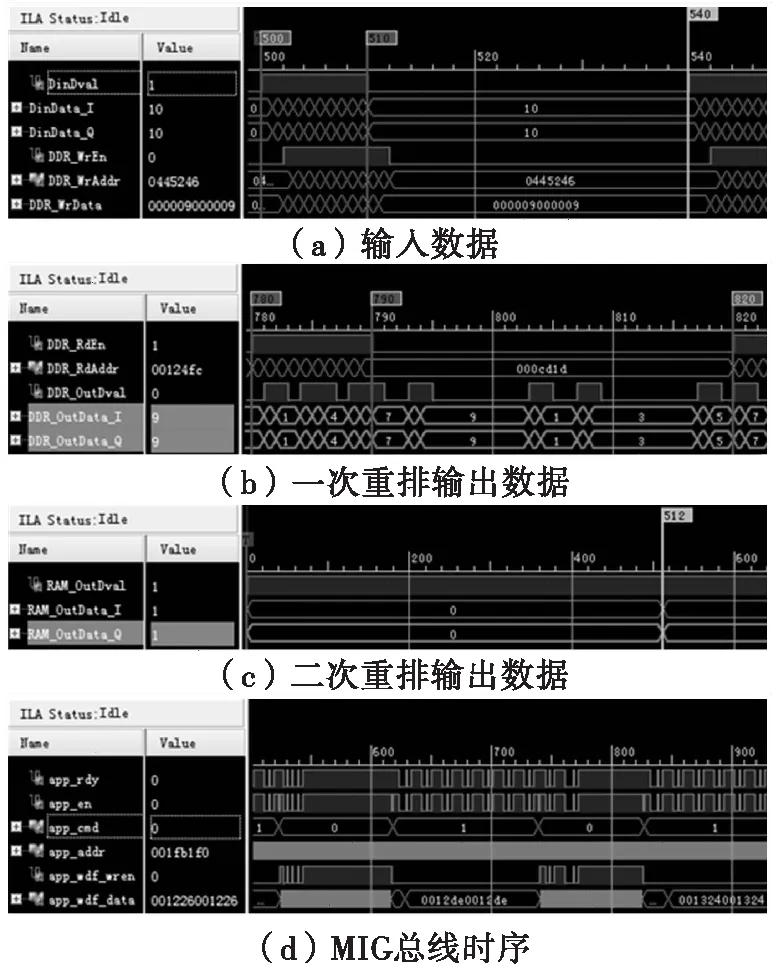
图7 j=1,k=10验证结果图
对比1)和2)的验证结果,2)中输入输出数据速率虽然是1)的10倍,但由于2)将10个数据拼接成1个大位宽的数送入MIG总线,对于MIG总线来说,均为13个时钟周期操作1次总线,因此数据拼接个数可实现不增加MIG总线操作的前提下,将重排速率提升倍。
对比1)和3)的验证结果,重排速率提升了3.25倍,说明按块读取可有效提升重排速率,由于频繁操作总线导致访问效率下降,因此虽不能将重排速率提升倍,但随着分块地址个数的增加,对重排速率的提升也会越发明显。
综上所述,在使用同一硬件平台、相同设置参数、输入数据位宽和格式一致的前提下,改进后不同取值情况下重排速率对比如表1所示。
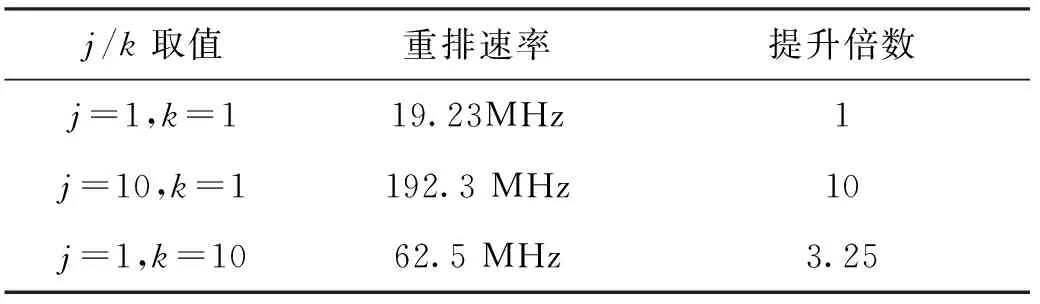
表1 重排速率对比
4 结束语
本文中提出了一种基于FPGA+DDR3的雷达数据高速重排方法,该方法以使用FPGA部分RAM资源和增加重排复杂度为代价,充分利用DDR3顺序地址读写效率高、FPGA片内RAM访问速度快等优点,尽可能地规避DDR3跳变地址读写效率低的缺点,最大程度地减少了DDR3跳变地址的次数,有效提升了重排速率,能满足现代雷达信号处理数据量不断增加,数据率不断提升的需求。
