面状地形要素快速提取方法研究
2022-07-20李柯桦
李柯桦
(云南省测绘工程院,云南 昆明 650031)
0.引言
研究如何高效地从∶测绘工程生产的AutoCAD地形图中提取地形要素对于空间数据库的构建尤为重要,GIS数据与CAD数据在设计与应用上的初衷不同,导致二者在数据结构上的差异很大。目前,多种商业软件如FME、EPS、ArcGIS等都提供了GIS数据与CAD数据的转换方式,提高了内业数据处理效率。但是,此类商业软件转换后的数据都存在属性丢失或图形错误等问题,无法直接进行数据入库。
针对数据转换中存在的问题,很多学者进行了研究,王化娟使用FME软件对CAD数据与GIS数据之间的转换关系进行研究,并且分析与处理了数据转换后存在的数据信息丢失、属性不全、图形错误等问题;陈能提出并研究了在CAD数据与GIS数据转换前对CAD数据进行预处理;针对要素因图形分割不连续问题,彭春晖提出了将要素属性作为自动接边的参照。上述方法虽然提高了地形数据提取效率,但是都需要人工参与,自动化程度不高,需要研究更加自动化的要素提取方法。
本文在传统地形要素提取的基础上,根据要素之间的几何关系,提出了基于空间拓扑关系的面状要素提取方法。该方法不仅可以快速提取面状几何要素,还能自动进行分类属性信息的识别与获取。
1.提取面状地形要素内容
以GIS建库的数据质量要求对AutoCAD格式的数据源进行质量控制,AutoCAD格式数据源在命名、分层、拓扑及成图上都有相应的规范要求。针对数字地形数据在GIS中与AutoCAD中的表现形式与分层等的差异,首先对数字地形图中需要提取的面状地形要素在GIS与AutoCAD中的表现形式进行梳理。数字地形图中需提取面状要素及其表现形式(如表1所示):
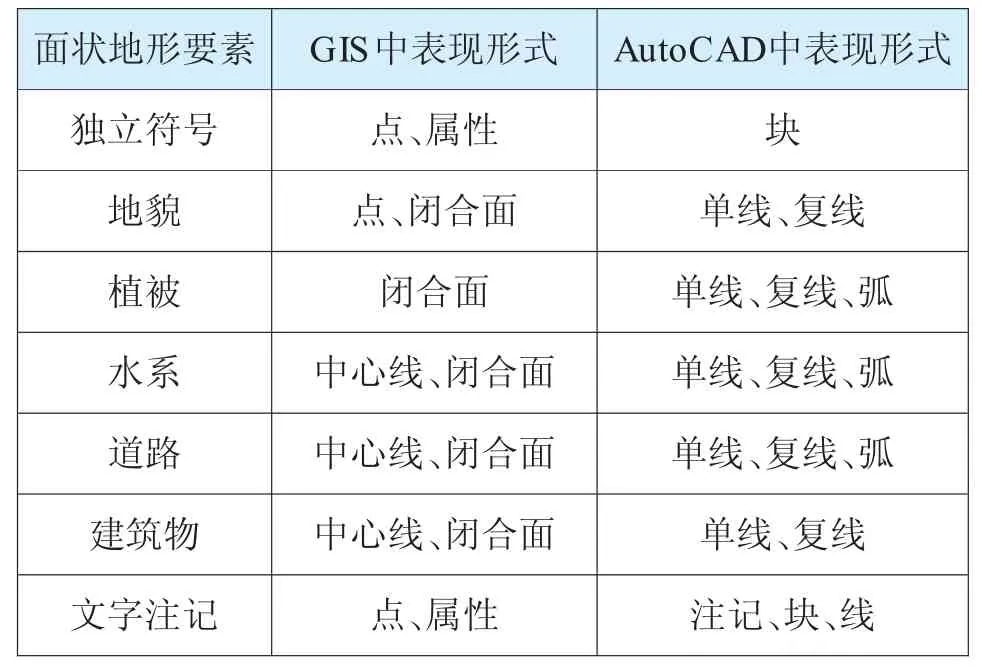
表1 两种软件数据结构对比
在GIS中,大部分地形要素如水系、道路、建筑物等表现为闭合面,但在AutoCAD中则表现为单线或复线。文字注记与独立符号在GIS中表现为点和属性,在AutoCAD中多存储为块或注记形式,块或注记可以对地形要素进行标识,如,植被的类别、建筑物的层数等,对块或注记本身却没有属性描述。GIS地形数据与AutoCAD地形数据产生差异的原因主要是应用目的与领域不同:GIS更加侧重于描述地理实体的数学模型,AutoCAD侧重于地形要素的成图与符号化。
各商业软件都对软件的数据结构进行定义,以解决各软件之间数据结构的差异造成信息无法匹配问题,在数据转换过程中尽可能保留原始信息[10]。以ArcGIS数据向AutoCAD数据转换为例,首先按照几何类型对转化后的数据进行分层,数据导入AutoCAD中将自动按照图形类型与图层划分存储;文字将转换为注记,注记的样式、颜色、分层等信息将会自动保存与显示。可见,数据结构的改变仍然会保留绝大部分的数据信息,但是两种软件在数据存储格式及符号化等方面差距较大,导致数据在转换过程中发生错误或者丢失情况。AutoCAD数据中缺少数据间的拓扑联系,由于节点难以捕捉,会产生例如缝隙、重复边、悬挂线等拓扑错误[11]。此外,由于地形图的制作是以图幅为单位的,所以还会造成图形边界的错位、分割等情况。
为了快速提取得到地形要素,目前还需要解决的问题有:(1)对地形图数据中的隐含信息进行充分挖掘,弥补商业软件之间数据转换造成的部分数据丢失问题;(2)对转换后的数据进行处理,得到满足入库要求的成果数据。
2.提取面状要素方法
针对前文中提到问题,本文提出了一种自动提取面状地形要素方法,该方法基于数据的空间拓扑关系。首先,为保证面状地形要素的闭合,利用地形要素间的邻接关系进行拓扑容差和组合图层的设置,并且通过拓扑构面实现面状地形要素的快速构建;其次,通过面状要素与文字注记或独立符号的包含关系,补充与滤除构建的数据集;最后,构建地形要素与独立符号之间的映射关系,通过面状要素与独立符号的包含关系对地形要素进行识别与分类。
2.1 图形构建
将AutoCAD中的线转为面是构建图形的首要条件,线转面分为两个步骤:(1)筛选得到面;(2)对线要素进行拓扑构面。这种方法可以快速生成面要素,但是会造成提取效果不理想,主要原因有以下三个方面:(1)图形是按照图幅划分,图幅边界造成的错位和分割会导致无法构面;(2)由于悬挂线的错误无法构面;(3)数据转换过程中导致线不闭合,也无法构面,如,花圃面由房屋边界与花圃边界共同构成的情况。通过传统方法对建筑物进行提取出现的问题(如图1所示):

图1 传统方法提取建筑物出现问题
出现上述建筑物提取的问题主要原因就是使用单要素图层进行构面,AutoCAD数据中没有图形拓扑关系,存在公共边的多个图形很难能够同时闭合。因此,可以使用多要素组合构面法以保证图形闭合,并且对所有参与构面的图层集合进行分析;设置拓扑容差,分析容差与成图比例尺、数据分辨率间的关系,实现拓扑自动闭合;完成要素属性编辑后,针对图形分割导致的边界不连续问题,可以通过对要素属性进行约束及对边界缓冲区进行分析的方法进行数据接边。
2.2 数据检查
使用邻接关系进行图形构建会产生以下问题:(1)由于数据质量问题导致的图形漏提;(2)为了保证图形闭合,会产生较多的错误数据。图2为构建植被时出现的错误,将房屋及道路也加入构面图层中以确保临近房屋或道路的植被图形闭合,因此也提取得到道路与房屋的情况(如图2(a)和图2(b)所示);图2(c)中植被的公共边界可能是任一图层中的要素,造成图形无法构建的原因可能是构面图层不全;悬挂点也会导致图形无法构建(如图2(d)所示)。针对上述问题,将本文方法应用到实际生产中的关键是对构建的数据集进行检查,使数据集满足生产要求,内容包括两个方面:(1)对遗漏图形的补充;(2)对错误图形的滤除。

图2 植被构建主要面临的问题
通过分析数据得到,在AutoCAD中对于要素属性信息的描述缺乏,一般情况下主要通过两种方式对地形要素进行识别:(1)将文字注记或者独立符号绘制在要素范围内,通过面状要素与文字注记或者独立符号的包含关系检查构建的数据集;(2)通过对数据进行分层管理,分层信息可作为要素识别的参考存储进要素属性中。
首先,通过AutoCAD对指定图层的文字注记及独立符号进行读取,将包络线中线点或块的插入点作为检查点,随后对叠加构建的面要素数据集与检查点进行分析。如果点要素在面要素范围外则表示漏提图形,面要素包含的点要素数量为零则表示面要素为错误数据。
2.3 分类的识别与提取

图3 土质与植被的符号图示
对于面状要素,主要通过独立符号与文字注记进行分类识别。目前已有多种行业标准规范对数据的质量进行控制。在国家规范标准的基础上,各省市又进行了进一步地完善及细化,制定适应本地数据生产的行业标准规范。这些行业规范对要素的分类编码、分类名称等都进行了要求与规定。国家标准中的土质与植被的符号示意(如图3所示):
对于地形要素分类的提取,需要根据相关标准规范要求。根据传统做法提取地形要素分类,首先是通过标准规范对分类的编码及名称进行确定,其次使用属性挂接或手工编辑的方式录入分类信息。但是由于地形要素分类众多且复杂,传统方法容易出现分类错误且工作量巨大。因此,在使用空间拓扑关系检查及构建图形后,进行AutoCAD独立符号与地形要素分类间的映射关系,就可以同时完成独立符号的识别与检查点的提取,在中线点属性中将独立符号进行存储。进行叠加滤波时,分类名称与编码就可以通过映射关系得到,从而能够自动识别地物分类信息。同样,该方法可以在地名自动匹配、房屋层数等文本注记的提取中得到应用。
3.应用实例
以昆明市1∶2000比例尺地形图建库项目为依托,对本文方法的可行性进行检验。选择连续的10幅地形图作为实验数据进行专项用地、房屋及绿地的提取。实验中使用的商业软件为ArcGIS、AutoCAD及EPS等,通过商业软件及工具进行数据预处理、数据转换及数据编辑工作。实验环境能够真实反映行业的生产情况,符合当前数据生产工作状况。
在特征符号与数据分层都符合标准规范的情况下,通过统计实验结果可知,本文方法可以有效提取数据,同时满足生产要求。使用传统方法与本文方法提取面状要素的效率对比(如表2所示):

表2 提取面状要素效率对比
通过表2可知:本文提出的方法可以高效提取面状要素,优化数据生产方式,实现自动化数据提取。将作业员从繁重的数据提取工作中解放出来,把更多的精力与时间放在数据质量检查上。本文的研究具有一定的应用价值。
4.结束语
本文对地形要素提取中的关键进行分析,使用拓扑构面、叠加分析及构建映射关系等,对地形图中的面状要素进行快速构建、数据检查及自动识别等。以昆明市1∶2000比例尺地形图建库项目为依托对本文方法的可行性进行检验。实验结果表明:本文使用的方法可以对数据生产方式进行优化,提高数据的提取效率。下一步将研究增加针对文字注记或独立符号摆放错误、悬挂点超出容差限定范围造成的数据错误的排查机制,进一步提高算法的自动化水平。
