面向情绪识别中脑电特征分布不均匀的双策略训练方法
2022-07-20贾巧妹胡景钊郑佳宾张丽丽赵晨宇吴东亚
贾巧妹,胡景钊,郑佳宾,王 晨,张丽丽,赵晨宇,吴东亚,冯 筠, 2
(1.西北大学 信息科学与技术学院,陕西 西安 710127;2.新型网络智能信息服务国家地方联合工程研究中心,陕西 西安 710127)
情绪是人类生活中很重要的一部分,在人机交互领域,人们希望计算机有一定的能力去识别人类的情绪,理解并帮助他们[1]。近年来,研究人员在情绪识别技术上进行了广泛的研究[2],目前的情绪识别主要是通过对语音[3]、面部表情[4]、生理信号[5]和姿态[6]等信息分析并识别主体的情感。但由于人们可能会掩饰自己的情绪,因此使用语音、面部表情和姿态对情感识别含有一定的主观性。而生理信号可以客观反应人的情绪,与眼电、心电等生理信号相比,脑电(electroencephalography,EEG)可以直接准确地反应人类的情绪[7]。因此,本文重点聚焦于使用脑电进行情绪识别。
传统采用脑电进行情绪识别的方法主要是提取脑电的时间、频率或时频域特征,如微分熵(DE)特征、谱密度(PSD)和小波熵[8]等,然后使用机器学习模型进行情绪分类,如支持向量机(SVM)。近年来,随着深度学习的发展,越来越多的研究人员将深度学习用于脑电情绪识别,以更好地挖掘脑电潜在的情绪特征[9]。尤其是卷积神经网络(CNN)和长短期记忆网络(LSTM)尤其被广泛应用于脑电情绪识别[10]。使用端到端的深度神经网络则可以对直接输入的脑电数据进行情感识别,无需手动提取脑电的情感特征。一些研究者还将机器学习和深度学习结合起来用于脑电情绪识别,例如将深度神经网络与bagging或boost算法结合起来以获得更好的识别性能[11]。
传统的机器学习方法依靠专家知识手动提取特征,而深度学习方法可以对直接输入的脑电进行分析识别情绪,并且尽可能多地挖掘脑电中含有的情感信息[12]。虽然深度学习方法较传统的机器学习方法有一定的识别性能,但使用脑电进行情绪识别的准确率仍然不高。为了提高基于脑电的情绪识别准确性,一些研究者采用了迁移学习的方法[13]。脑电的低信噪比(SNR)[14]、非平稳性以及受试者之间情绪表达方式的不同,都会导致从不同受试者甚至单个受试者采集脑电的特征存在差异。这些因素均会造成深度网络提取的脑电样本特征的非均匀分布,导致模型过拟合[15-16]。
本文针对以上问题提出了一种双策略训练方法来识别情绪。该方法通过在模型学习推理过程中动态地调整脑电特征的权重,提高脑电情绪识别模型的泛化能力。
1 相关工作
许多研究者已经使用脑电来识别情绪,目前在提取脑电的情绪特征和运用机器学习方法或深度学习方法对情感分类的研究取得了一定的进展。还有一些研究者使用原始脑电作为网络的输入进行情绪识别。
Wang等人提取了3种脑电特征,分别是功率谱、小波变换和非线性动力学分析(nonlinear dynamical analysis),然后通过线性动态系统(LDS)对特征进行平滑处理,去除与任务无关的噪声,并使用支持向量机(SVM)进行分类[17]。Aggarwal等人提取了脑电的9个统计特征,如均值、方差等,用于情绪分类,并探讨了XGBoost和LightGBM两种提升方法对脑电情绪识别的影响[18]。Wang等人提出了一个三维卷积神经网络EmotioNet,它使用原始脑电作为网络的输入,该网络可以自动提取脑电的时空特征用于情绪识别[19]。Huang等人提出了一个集成卷积神经网络(ECNN)用于提取脑电和周围生理信号的有效特征,5种不同架构的CNN被用于脑电情感识别,最后,使用集成学习对多个网络的预测进行投票得到最终结果,从而提高了模型的性能[20]。
在上述工作中,脑电情绪识别一般使用机器学习和深度学习方法。本文中使用双策略方法训练ScalingNet,以提高脑电情绪识别模型的泛化性能,ScalingNet是一种用于脑电情绪识别的端到端卷积神经网络[21],双策略训练方法见图1。实验结果表明,与以往工作相比,本文方法在脑电情绪识别方面具有更好的性能。
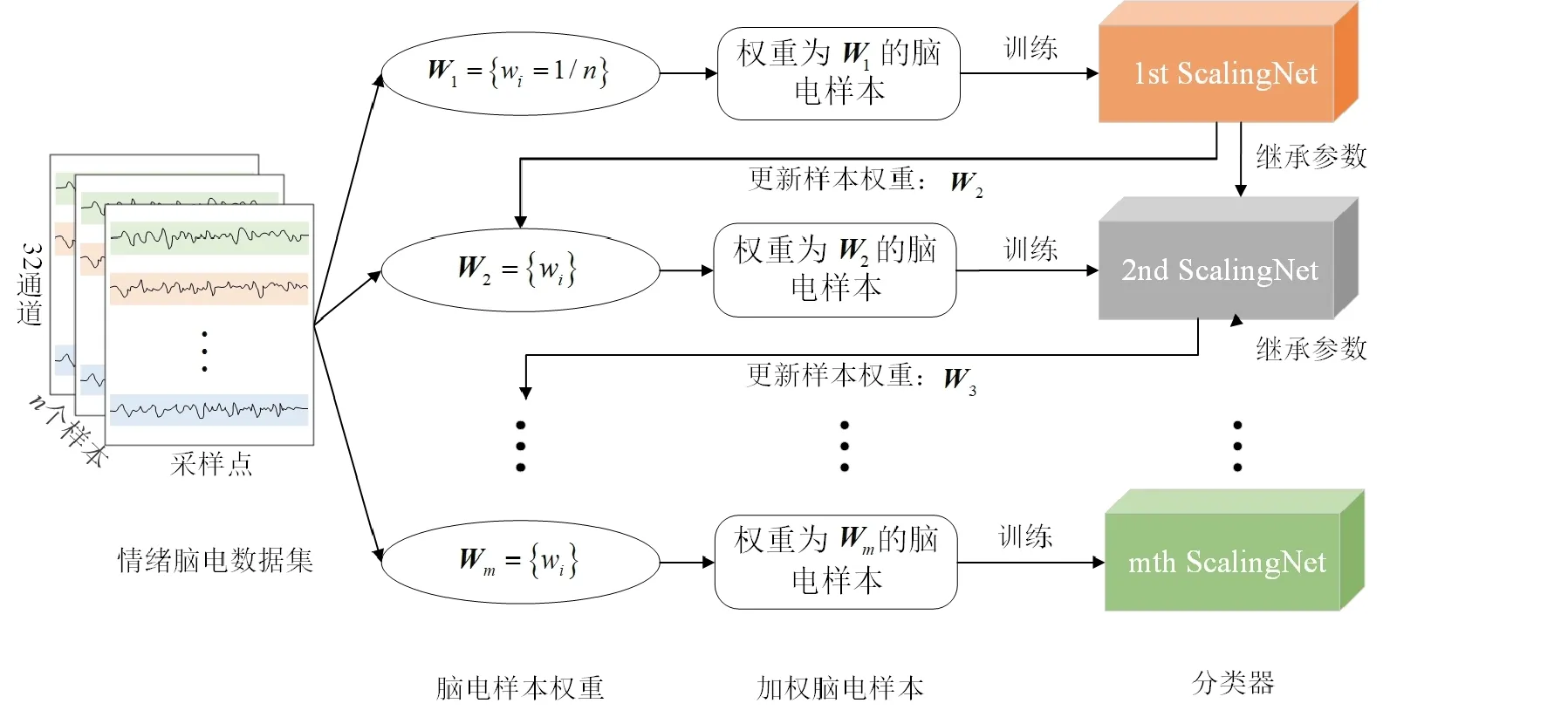
图1 双策略训练方法Fig.1 Bi-strategy training method
2 本文训练方法
为了解决脑电样本情绪特征分布不均匀而引起模型过拟合的问题,本文提出了一种将boost算法和梯度下降法相结合的双策略训练方法来训练脑电情绪识别模型。
2.1 双策略训练方法
本文提出的双策略训练方法通过数据驱动的方法动态调整情绪脑电样本特征分布,以提高脑电情绪识别模型的泛化性能。
如图1所示,该方法的输入是情绪脑电数据集。ScalingNet是一种端到端的脑电情绪识别神经网络,作为该方法的分类器。首先,初始化输入的情绪脑电数据集的样本权重,并随机初始化第1代分类器(1st ScalingNet)的网络参数;其次,利用初始化后的加权脑电样本训练第1代分类器,基于梯度下降法迭代更新一趟网络参数;然后,依据boost算法更新脑电样本权重,并且训练第2代分类器,其网络参数继承自上一代分类器训练后得到的情绪识别模型。循环上述过程,迭代训练多个分类器,直至触发停机准则。
本文采用AdaBoost中SAMME的变体SAMME.R算法,SAMME.R算法使用概率预测真实值[22]。梯度下降法采用Adam(adaptive moment estimation)算法[23]。
以ScalingNet作为分类器,随机初始化第1代分类器的网络参数。假设输入的情绪脑电数据集为X={x1,x2,…,xn},对应的情绪类别标签为Y={y1,y2,…,yn},其中,n是情感脑电数据集的样本数,xi是第i个样本,是s×d维的向量,s是采样点数,d是脑电通道数,并且yi是第i个样本的标签。假设输入情绪脑电数据集的脑电样本权重为{w1,w2,…,wn},其中,wi为第i个样本的权重。初始化脑电样本权重为wi=1/n。第j个分类器输入的脑电样本权重向量为Wj={wi},j=1,2,…,m,m是训练的分类器数量。
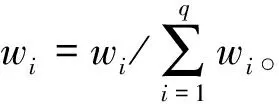
(1)
算法1双策略训练算法
输入 情绪脑电数据集X,类别标签Y,分类器ScalingNet
输出 泛化性能最好的脑电情绪识别模型
1) 随机初始化ScalingNet的网络参数,令j=1,即第1代分类器。
2) isStop=False
3) while not isStop do
4) ifj=1 then
5) 初始化输入脑电数据的样本权重为W1={wi=1/n},其中,i=1,2,…,n,n是样本数,并训练第1代分类器,依据Adam算法迭代更新一趟网络参数。
6) else
7) 第j代分类器的网络参数继承第j-1代分类器。训练第j代分类器,依据Adam算法迭代更新一趟网络参数。
8) 样本权重公式(7)更新为Wj+1={wi}。
9) 保存第j代分类器,并且获得泛化性能最好的分类器为第j代分类器。
10) 判断是否满足停机准则,满足则isStop=True
11)j=j+1
基于计算出的加权损失L,采用Adam算法对分类器的网络参数进行更新使损失最小化,
(2)
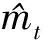
(3)
(4)
其中:mt是偏差一阶矩估计;ut是偏差二次原始矩估计;β1和β2是时间步长t时的指数衰减率估计,
mt=β1mt-1+(1-β1)gt,
(5)
(6)
其中:gt是相对于θ的损失函数的梯度,即gt=θL(θt-1);L(θt-1)是损失函数;β1=0.9;β2=0.999。
然后,根据AdaBoost中的SAMME.R算法更新脑电样本权重,训练下一代分类器,
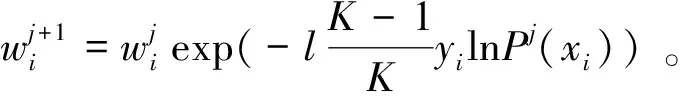
(7)
其中:wi是第i个样本的权重;l为学习率;Pj(xi)是第i个样本对应的第j个分类器的输出预测概率。
输入到第2代分类器(2nd ScalingNet)的脑电样本权重可以从式(7)中获得。第2代分类器继承了第1代分类器的网络参数,而不需要从头开始训练网络。脑电样本权重根据式(7)进行更新,以训练第3代分类器(3rd ScalingNet)。综上,依次迭代训练多代分类器,具体过程如算法1所示。
2.2 加权情绪脑电样本训练ScalingNet
本文中使用的ScalingNet是一个用于脑电情绪识别的端到端的神经网络架构。如图2所示,ScalingNet有3个部分。第1部分是缩放层,通过多核卷积提取类频谱特征图,然后,将特征图堆叠成三维张量;第2部分是进行特征图变换的3层卷积层;第3部分是全局平均池化层和一个线性层,特征图经过这部分进行情绪分类。
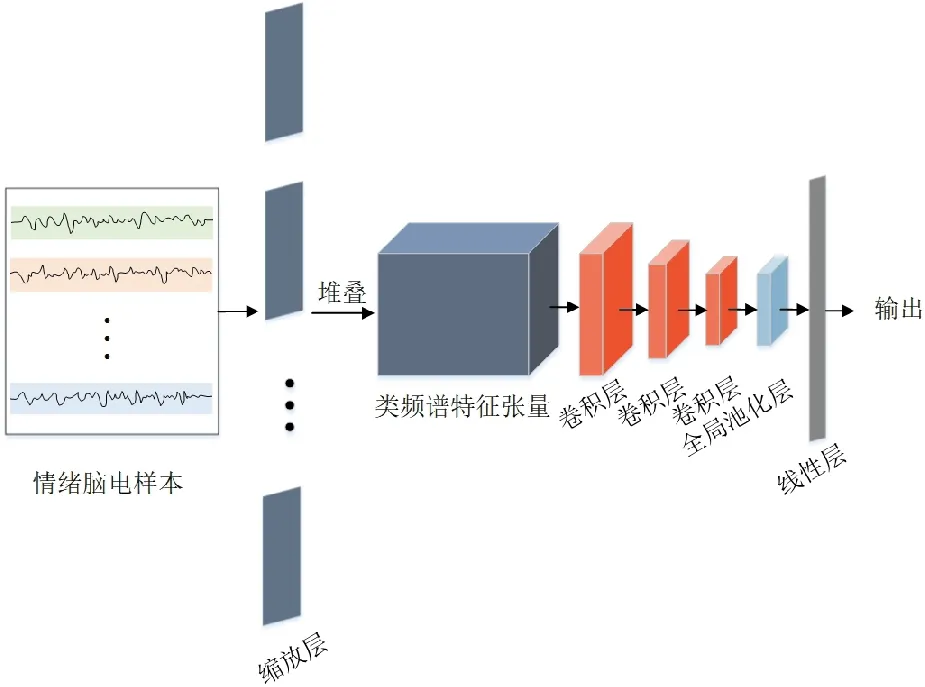
图2 ScalingNet网络架构Fig.2 ScalingNet architecture
Adam算法用来更新ScalingNet的网络参数使损失函数最小化,交叉熵损失作为损失函数。本文在交叉熵损失中引入了脑电样本权重,如式(7)所示。
3 实验结果
3.1 DEAP数据集和预处理
本文使用DEAP数据集[24]验证所提方法的有效性。DEAP数据集是一个包含脑电的多模态情感数据集,一共有32名受试者,每个受试者观看40个视频,每个视频时长为1 min,当受试者观看视频时,采集他们32通道的脑电信号。每个样本数据长为63 s,其中,前3 s为基线信号,是观看视频的前3 s。在观看视频后,受试者按照9分制对效价(valence)、唤醒(arousal)和优势度(dominance)3个方面进行评分,通过这3个维度对人的情绪进行量化。
对脑电信号以128 Hz进行重采样,将后60 s的脑电信号减去前3 s基线信号均值,做基线校正处理,减少基线漂移。根据效价、唤醒和优势度3个维度的得分,以5作为阈值,小于5的为0类,大于或等于5的为1类,将任务抽象为3个二元分类问题。本文输入数据集的大小为1 280×7 680×32(试次×采样点数×通道数), 其中, 1 280为32×40(受试者数×视频数),7 680为60×128(脑电数据时长×采样率)。
3.2 实验设置
实验通过五折交叉验证的方法评估本文所提方法在脑电情绪识别上的性能,五折的平均分类准确率作为最终的情绪识别结果。本文方法在脑电情绪识别模型训练过程中设置的重要参数如表1所示。本文所提方法使用PyTorch框架实现,所有实验都在Geforce RTX 2080 Ti上进行。
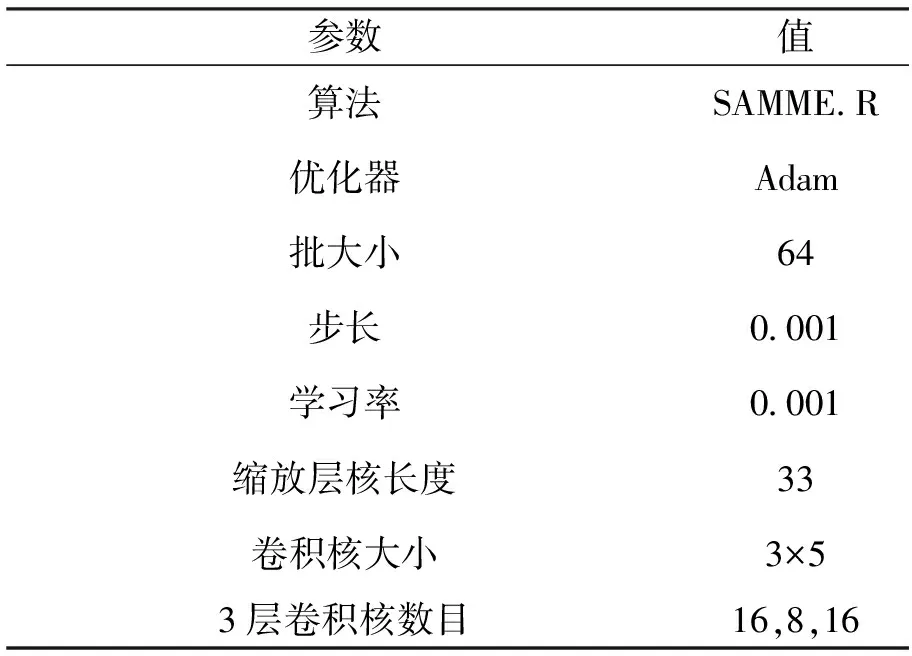
表1 本文所提方法的参数
3.3 结果和讨论
将本文所提方法与已有研究的性能进行比较。同时,在基线模型ScalingNet上使用Focal Loss[25]进行比较实验,并与本文方法进行对比,结果如表2所示。本文方法在效价、唤醒和优势度上的准确率分别达到了71.25%、 71.48%和71.80%, 优于其他对比研究。 与Hu等人提出的基线模型ScalingNet[21]相比, 本文方法在效价、 唤醒和优势度上的准确率分别提高了0.001 2,1.014 9和0.010 2。
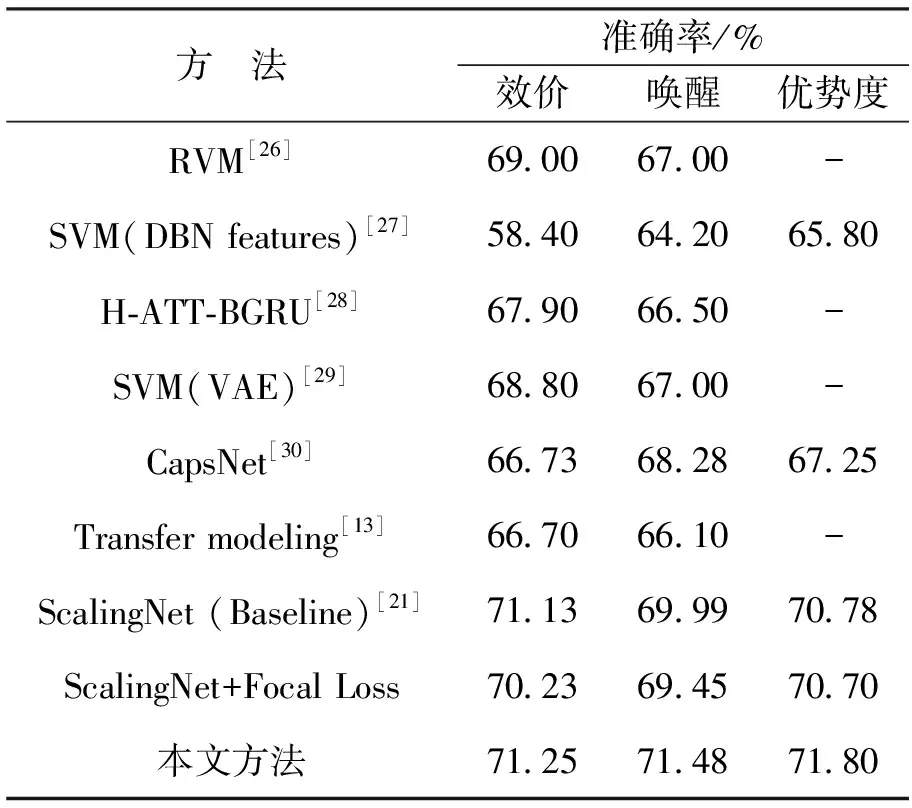
表2 本文方法的实验结果与已有研究的比较
在进行脑电情绪识时, 大多数研究都没有考虑到情绪脑电样本特征非均匀分布所导致的脑电情绪识别模型泛化性能差的问题。 本文结合了两种训练策略, 交替更新脑电情绪识别模型, 以调整样本特征分布, 进而提高模型的泛化性能。 本文方法通过先验概率有效调整了脑电样本特征的分布。
为进一步探讨本文方法是否有效地调整了情绪脑电样本特征的分布,使用t-SNE[31]可视化网络最后一层的特征表示,如图3所示为不同训练阶段即不同代分类器的可视化结果,网络训练过程中不断调整样本权重使其特征分布更均匀。图4为不同方法在DEAP数据集上的可视化特征表示,可以观察到,ScalingNet+Focal Loss并不能有效地调整情绪脑电样本特征分布,因为ScalingNet+Focal Loss和基线模型ScalingNet脑电样本特征都存在分布不均匀的问题。当情绪脑电样本特征非均匀分布时,网络训练产生的情绪分类的决策边界将很复杂,复杂的决策边界可能会将训练数据集中的类别完全分开,导致测试样本容易被错误分类,并造成模型的过拟合。与基线模型和Scaling Net+Focal Loss相比,在可视化结果表面,本文方法有效地调整了脑电样本特征的分布,使特征分布更加均匀。在这种情况下,生成的决策边界更加平滑,模型的泛化性能将得到改善。
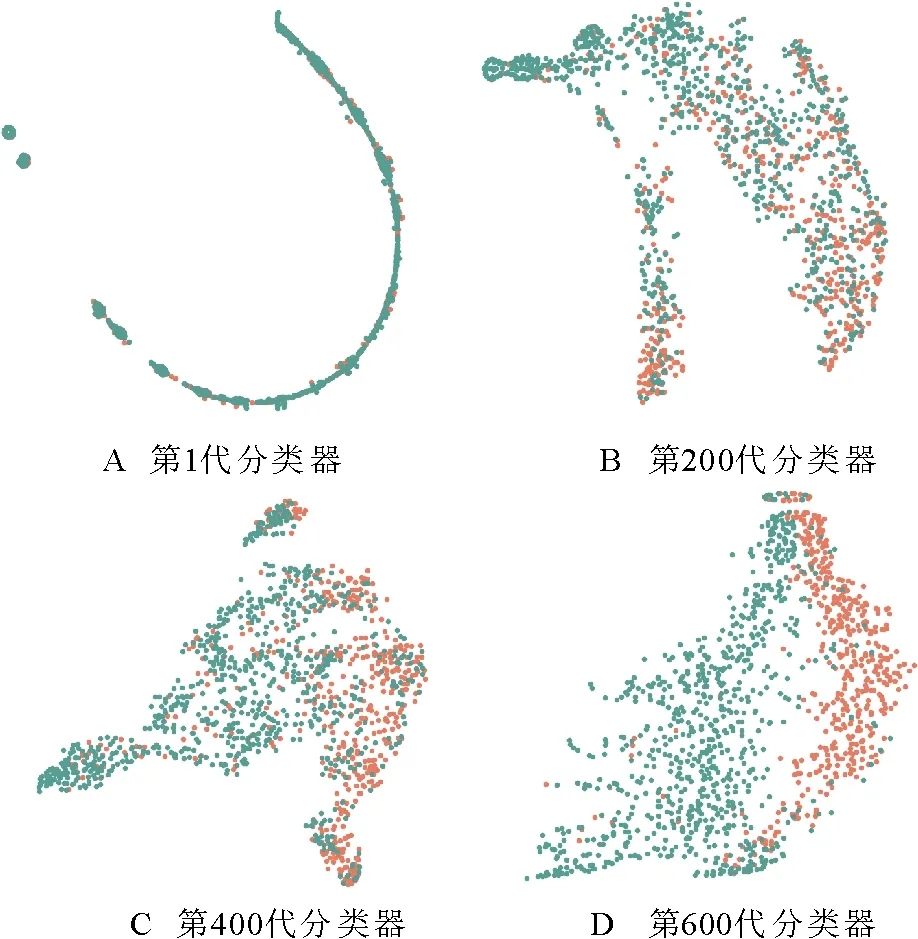
图3 本文方法在不同训练阶段的可视化特征表示Fig.3 Visual feature representation of our method at different training stages
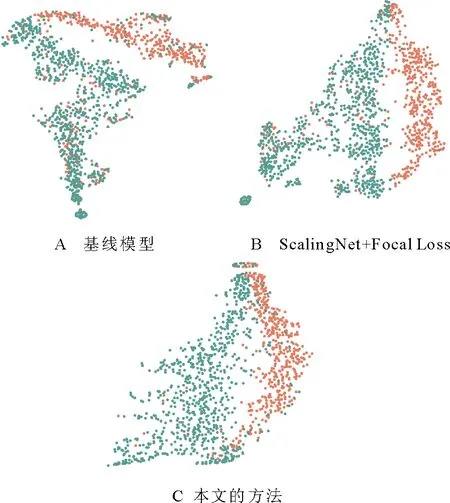
图4 不同方法在DEAP数据集上的可视化特征表示Fig.4 Visualization of feature representation of different method on DEAP dataset
根据本文方法的特点,依据是否继承上一代分类器的网络参数,以及是否更新情绪脑电样本权重进行情绪识别,进行了模型消融实验,结果如表3所示。模型1即为本文所提出的方法,分别比较模型1和3、模型2和4,由实验结果可以看出,更新样本权重可以有效地提高脑电情绪识别模型的泛化性能。从模型1和2、模型3和4的对比结果可以看出继承网络参数的重要性。网络参数的继承有助于当前网络在学习过程中获得上一代网络的情绪信息,有利于情绪识别。通过在学习推理过程中更新情绪脑电样本权重,可以动态调整情绪脑电样本特征分布,以提高脑电情绪识别模型的泛化性能。综上所述,在模型消融实验中,模型1具有最佳的泛化性能。
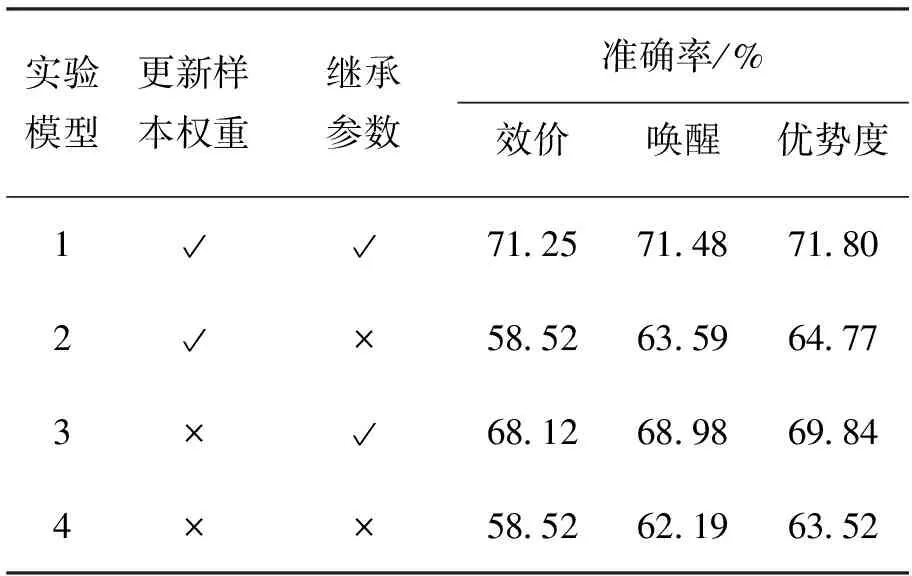
表3 模型消融实验对比Tab.3 Model ablation experiments comparison
4 结语
本文提出了一种用于非均匀脑电情绪识别的双策略训练方法。 在模型的训练过程中, 采用梯度下降法更新脑电情绪识别模型的网络参数, 采用boost算法更新情绪脑电样本的权重, 以调整脑电样本特征的分布。 实验表明, 与已有研究相比, 本文方法具有更好的情绪识别性能。 并且通过t-SNE可视化特征表示的结果表明,与基线模型ScalingNet+Focal Loss相比,本文方法有效地调整了情绪脑电样本特征的分布。通过调整样本特征分布,提取更鲁棒的情绪脑电图特征,提高了脑电情绪识别模型的泛化性能。为使用脑电进行情绪识别的实际应用提供了更大的可能性,今后将结合更多的训练策略,进一步探索脑电情绪识别模型的训练方法。
