基于对偶分解的数据中心网络流量工程方法
2022-07-20李建华
刘 奕,李建华,陈 玉
(1. 空军工程大学信息与导航学院,陕西 西安 710077;2. 空军工程大学研究生院,陕西 西安 710038)
1 引言
数据中心网络作为联合装备网络的核心,对战场信息进行存储和处理,实现各军种装备信息实时共享。然而,随着武器装备和信息技术的发展,数据中心网络通信量迅速增加,对网络带宽资源的需求与日俱增,给流量工程(traffic engineering,TE)带来新的挑战,需要在保证网络资源利用率基础上,提高数据中心网络的实时响应能力,增强联合装备网络系统效能。
软件定义网络(software defined network,SDN)作为新型的网络架构,通过OpenFlow技术将控制层面和数据层面相分离,并具有开放的可编程接口和全局化的网络视图,为网络流量的精细化、智能化管理提供新的思路。
目前数据中心网络中的TE方法主要分为启发式方法和最优化方法。文献[5]提出一种基于Hash表的等价多路径(equal cos t muti-path,ECMP)方法,该方法通过对数据流的包头进行哈希运算,根据运算结果将负载分发到多条路径上进行传输,充分利用网络中大量冗余路径,实现流量均衡分配和链路备份。该算法对于老鼠流可以实现有效的分配转发,而对于多条大象流可能会造成hash路径上的数据流碰撞,导致链路拥塞。文献[7]提出一种动态路径分区算法,利用ECMP方法将老鼠流调度在低延迟路径上传输,大象流调度在高吞吐量路径上传输。该算法有效降低了大小流的资源竞争,但在网络数据量较大时,单条路径很难满足大象流的带宽需求,导致传输延迟和链路拥塞。文献[8]提出一种基于SDN稳定匹配的流量调度算法,该算法通过计算大象流所需带宽与路径剩余带宽的匹配度是否满足预设阈值,来选择大象流最佳调度路径。算法可以有效提高网络带宽利用率,但匹配精度低,计算复杂度高,网络流量分配不均。文献[9]提出一种基于SDN的大象流多路径调度算法,该算法通过设置网络负载阈值来检测大象流,然后利用控制器OpenFlow特性将大象流分解成若干老鼠流进行传输,并实时检测网络链路状态,确保动态均衡。算法提高了网络链路利用率,但大象流的多次分解会造成数据包接收顺序错乱,导致网络丢包率增加。上述算法均属于启发式方法,当数据中心的服务器较多时,该类算法的搜索空间规模大幅增加,为了减小计算过程中的搜索空间,只考虑了部分流(通常是大象流),通过牺牲全局最优解的方式来降低计算时间。文献[10]结合对称拓扑网络结构特点,提出一种基于每包轮循的路由算法(digit-reverseal bouncing,DRB),能够在对称多根树拓扑中有效地分配每个数据包,提高了网络利用率,降低了延迟,但在实际的军事信息系统中,数据中心网络由于故障或遭受敌方攻击等因素容易导致拓扑结构并不对称,因此该方法鲁棒性较差,实际应用受限。
综上所述,为了实现数据中心网络流量的快速均衡调度,本文将最小化最大链路利用率作为目标函数,利用对偶分解技术,将原问题分解为若干独立的子问题,通过独立求解和并行计算的方式,得到每个链路利用率的最优上界,最大程度减少链路拥塞和运算时间,提高数据中心网络的实时响应能力,确保数据中心网络中的应用程序满足服务质量(quality of service,QoS)需求。
2 算法原理
本文采用线性规划方法来解决数据中心的资源分配问题,其目标函数是最小化网络中最大链路利用率,为了减少搜索空间,将原问题分解成若干子问题,然后结合OpenMp方法在多个计算核心上并行求解子问题,最后通过整合子问题解得到原问题的最终解。
2.1 数学模型
假设一k元Fat-tree网络结构G
(V
,E
),其中核心层有(k/
2)个交换机,主机总数为k
/
4,V
表示所有通信节点的集合,E
表示两通信节点的链路集合。对于每个interpod的通信需求,在网络中任意给定的源节点和目标节点对之间均有(k/
2)条可能的路径,并且这些路径中的每一条对应于一个核心交换机。本文目的是将通信需求分配到可用路径,从而最小化各路径的最大链路利用率,其最优化数学模型可表示为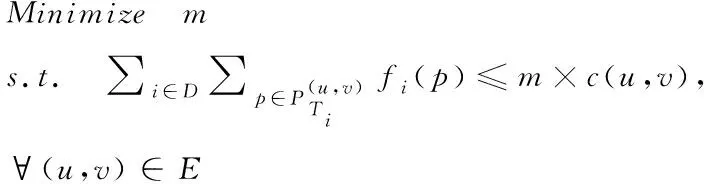
(1)
∑∈f
(p
)=d
,∀i
(2)
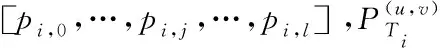
u
,v
)的所有路径的流量之和应低于该链路的容量,约束式(2)确保了通过与某个需求相关联的所有路径的流量始终等于该需求的总量。通过最小化最大链路利用率m
,实现数据中心网络的负载均衡,同时将过载链路上的流量转移到空闲链路上,防止个别链路的拥塞,导致网络长时间延迟和数据包丢失,从而提高数据中心网络的QoS。2.2 模型分解
为了减少计算时间,本文结合Lagrange 对偶原理,将主问题分解为若干独立子问题,则1.
1节最优化模型的对偶表达式为
(3)

X
(u
,v
)≤0(4)
其中D
是需求集,X
(u
,v
)和y
分别是对应约束式(1)和(2)的对偶变量。对于每个(u
,v
)∈E
,X
(u
,v
)为约束(1)的对偶变量,对每个i
∈D
,y
为约束式(2)的对偶变量。根据约束式(1)和(2),y
为任意,X
(u
,v
)≤0,约束式(3)和(4)分别对应于约束式(1)和(2)中每个i
∈D
、p
∈P
和m
的变量f
(p
)。约束式(3)中对应于变量f
(p
)的系数X
(u
,v
)和y
,与约束式(1)和(2)中每个(u
,v
)和i
的系数f
(p
)相等。另一方面,目标函数中的系数f
(p
)为零,则对应于对偶式中的变量f
(p
)的约束将是约束(3)。类似地,对于每个(u
,v
)和i
,约束(1)和(2)中的系数m
分别为-c
(u
,v
)和0,其目标函数中的系数为1。因此,其对偶约束为∑(,)∈-X
(u
,v
)×C
(u
,v
)≤-1,等价于约束式(4)。
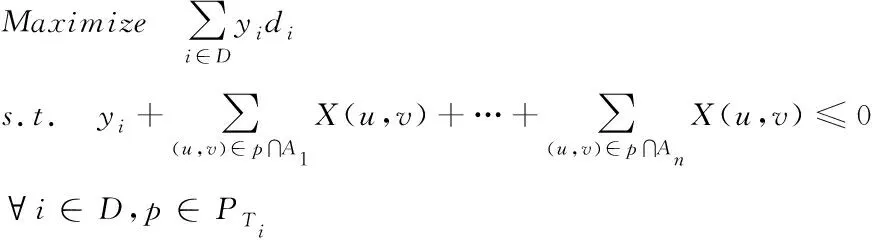
(5)
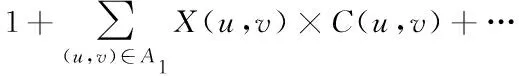
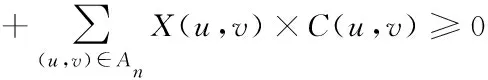
X
(u
,v
)≤0(6)



(7)
其中,


i
∈D
,p
∈P

X
(u
,v
)≤0(8)

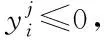
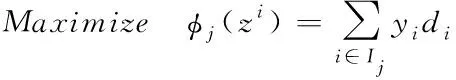
i
∈I
,p
∈P
(9)

X
(u
,v
)≤0(10)
其中I
={i
∈D
:∀p
∈P
,p
∩A
≠∅}。对于每个sub
,变量的数量是|A
|+|I
|,为了方便求解主问题的次梯度,求得sub
的对偶表达式为Minimize
Π
z

u
,v
)∈A
(11)
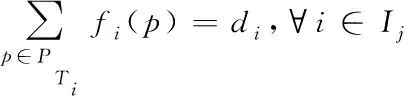
(12)
其中Π
是对应于约束式(10)的对偶变量,f
(p
)是对应于sub
中约束式(9)的对偶变量。2.3 主问题求解
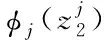

(13)
可得

(14)
将不等式(17)与φ
(z
)=Π
z
相加,可得
(15)
由式(15)可知,Π
是在点z
处的函数φ
(z
)的次梯度。因此,可在计算sub
的最优解之后,由式(16)求得主问题次梯度ξ
=(Π
,…,Π
)
(16)
设ξ
为第r
次迭代时Z
点上主问题的次梯度,I
(Z
)={j
:z
=0},则次梯度投影可由式(17)计算
(17)
根据投影的次梯度,即可计算直线搜索步长α
,如式(18)所示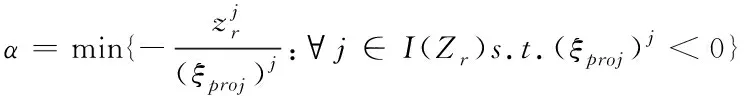
(18)
根据搜索步长α,可计算出第r+1次迭代的Z值,如式(19)所示
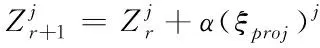
(19)
则主问题求解算法具体流程如下:
Step
1:初始化 ε∈(0,1),r=1,Z=(1/2,…,1);
Step3:根据式(16)计算主问题的次梯度;
Step4:根据式(17)计算主问题中每个j
=1,…,n
的次梯度投影;Step5:如果‖ξ
‖≤ε
,停止迭代,否则转向Step
6。Step6:利用式(18)计算直线搜索步长α,利用式(19)计算新的点,设置r=r+1,返回Step2。
3 仿真结果和分析
3.1 实验环境
为了有效检验本文所提算法对数据中心流量的快速均衡调度性能,构建k=16的Fat-tree模拟网络,其中每个主机有20个请求随机发送到其它pods的5个主机。模拟网络中有1024个主机和20480个流,网络交换机之间共有4096个链路。根据文献[12]设置流量需求分布,网络流量由查询流量(2至20 kB)、延迟敏感短信息(100 kB至1 MB)和大象流(1至100 MB)组成,主问题中的子问题数为32。
算法运行平台的操作系统版本:Windows 2012 R2,CPU:Quad 3.47 GHz Intel Xeon®X5690,内存:16GB,有8个可用的计算核心,每个核心运行一个进程线程。
3.2 实验分析
1)链路利用率分析
对比分析本文算法与文献[5,9,10]三种算法的链路利用率情况,如图1所示,实验中Fat-tree网络k=16。
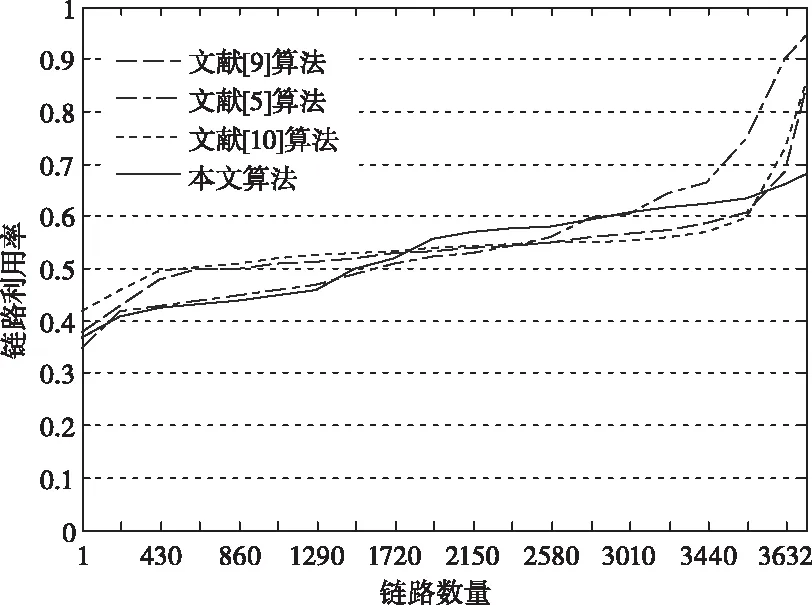
图1 四种算法的链路利用率
由图1可知,本文算法优化的流量负载较为均衡,没有链路是拥塞的,所有链路的利用率约为0.37~0.67。文献[5]ECMP算法的链路利用率约为0.34~0.98,随着链路数量的增加,导致ECMP算法的负载分配不均衡更加显著,当链路数量较多时,会发生链路饱和情况,主要是由于ECMP算法将大象流映射到同一条路径,从而导致明显的负载失衡。文献[9]算法的链路利用率约为0.38~0.85,该算法的链路利用率的最大值大于本文算法,主要是由于文献[9]算法只关注大象流,分别利用启发式方法和ECMP方法分配大象流和老鼠流,而本文算法对网络中所有流的路径进行了优化配置。文献[10]算法的链路利用率约为0.41~0.81,该算法的最大链路利用率较高,主要是由于其分配决策中并没有考虑网络的当前状态,导致当网络流量负载增多时,链路利用率增加明显,而本文算法结合当前网络状态,并对网络中所有流的路径进行了优化配置,有效避免了路径拥塞。
2)计算复杂度分析
对比分析k=4、k=8和 k=16三种Fat-tree网络结构下,文献[9,10]和本文三种算法的计算时间,如图2所示。

图2 三种算法的计算时间
由图2中可知,三种算法的计算时间均随着网络节点的增加而增加,文献[10]的最优化求解算法复杂度较高,随着网络节点的增加,计算时间增加明显。本文算法经过对偶分解,实现多线程并行运算,有效降低了计算时间,可以得到一个具有可容忍计算复杂度的最优解,几乎与文献[9]启发式算法的计算复杂度相同。
3)运算线程数分析
对比分析不同线程数量下,本文算法的计算时间,如图3所示,实验中Fat-tree网络k=16。

图3 不同线程数条件下的计算时间
本文经过对偶分解,将多个子问题并行求解来减少计算时间。由图3可知,当并行求解的线程数量较小时,计算时间较长,随着线程数增加,计算时间逐渐减少,当线程数超过8时,计算时间略有增加,主要是由于增加线程的数量也会增加并行度,但是考虑到实验平台只有8个计算核心,每个核心一次运行1个线程,超过8个线程后就都会导致线程争夺缓存资源,容易产生错误共享和计算时间增加,因此,在实际应用过程中,应根据硬件自身条件和需求,合理控制线程数量,已达到最佳流量均衡调度效果。
4 结语
针对数据中心网络链路拥塞问题,提出一种基于对偶分解的数据中心网络流量工程算法。利用对偶分解技术,将原问题分解为若干独立的子问题,通过独立求解和并行计算的方式,最大程度减少链路拥塞和运算时间,确保数据中心网络中的应用程序满足QoS需求。通过仿真表明:本文算法通过对网络中所有流的路径进行优化配置,相比启发式算法,降低了链路利用率,同时减少了计算时间,但在实际应用过程中,应合理控制线程数量。
