基于书目题名数据的超短文本分类研究
2022-07-18苏东出
苏东出,孙 萍
(平顶山学院,河南 平顶山 467000)
随着以深度学习为代表的神经网络技术的发展,很多研究者开始将研究目光转向这一新兴的领域,图书馆界也出现了一批利用神经网络对文本语料进行深度学习的研究成果,比如吉林大学管理学院张海涛教授利用卷积神经网络对微博舆情进行情感分类研究[1],徐彤阳、尹凯基于THUCNews数据集,研究了如何利用CNN、根据文档特征词向量对文档进行分类的问题[2]。这些研究为我们提供了一个将深度学习和神经网络与图书馆业务相结合的方向。
通过调研发现,目前的研究成果大部分都是基于长文本语料:比如微博内容、论坛帖子、网络新闻等。这类文本具有明显的统计优势:①大文本数据在词频统计上更具有一般性,因此选择出的可以代表文档特征的关键词更为准确;②大文档可以统计出更多代表文档的关键词,在进行分类的时候,能更准确的表述文档的内容特征。
目前图书馆的数字资源则刚好和上述研究成果的研究对象相反:图书馆最多的资源不是各种可自由访问的超长文本数据,而是几十万甚至上百万条书目数据,这些数据具有以下特征:①内容简短。大多数题名只有十几个字符,有的题名甚至只有一个中文字符。②书目数据附加信息少,很多书目数据缺少主题词等信息。
这些特征导致我们在用NLP技术对文献书目数据进行处理的时候,很难得到足够多的、能代表文献分类特征的关键词,因而也不能直接借用上述研究成果,因此需要寻求更合理灵活的办法来解决这个问题。
1 超短文本的特征表示
文本的特征表示是文本处理的基础,也是NLP(自然语言处理:Natural Language Processing)和深度学习的基础,好的文本特征表示算法不仅能准确反映原始文本的内容,而且还有利于提高文本算法的准确度,当前的文本特征表示技术基本上都基于统计模型,包含分词和词的向量化两个步骤。
1.1 分词和词的向量化
分词是NLP的基本任务,其主要目的就是从连续的字符序列中提取出可以代表文档内容特征的基本词汇。相对于西文分词技术,中文分词的技术难度更大,在词义消歧、粒度大小、词性标注方面需要解决的问题更多。近年来,随着互联网的发展,分词技术虽然在算法原理上没有突破性的发展,但是以大数据为统计样本建模,并且从应用角度来看,中文分词越来越成熟,正确率和召回率都有了大幅度的提升,比如清华大学的THULAC[3](THU Lexical Analyzer for Chinese)的F1值可达97.3%,可以说已经具备了工业化应用的水平。
分词的目的不仅仅是为了表示文档的主题内容,更是为了将文档表示为计算机能够识别、处理的一系列有意义的数字信息,目前应用最广泛的就是词向量化技术,又称词嵌入(Word Embedding)技术[4],通过将单词嵌入到(或者说映射到)一个多维实数空间中来实现词的数字化表示,虽然有很多理论和模型都可以实现词嵌入,但是归根结底,根据生成词向量的类型,只有稀疏词向量和稠密词向量两种。
1.1.1 稀疏词向量。稀疏词向量根据BOW(词袋)大小设置向量空间的维度,比如BOW有1 000个不重复词汇,则生成的向量为1 000维向量,如果词袋单词数量达到1万以上,每1个单词就需要1万个实数来表示,多个单词同时表示所需的空间复杂度和时间复杂度是服务器难以承受的,虽然可以根据字典序号压缩表示,比如TFIDF模型生成的向量[5,6],但是在运算的时候仍然需要“升维”,表示虽然简单,但是运算复杂度却提高了,因此,稀疏词向量模型通常用于逻辑简单、训练语料数据较少的应用场合。
1.1.2 稠密词向量。稀疏词向量的种种弊端导致了稠密词向量的产生,在稠密词向量中,表示向量的实数值不再是离散型的整数,而是连续性的实数,向量的维度也固定为有限的数值,比如很多模型限制为100维,向量格式形如:
[-0.018229000153951347,…,-0.01511262892
7454352,-0.10122359311208129,-0.079580809455
36494,0.019655946758575737]
1.2 目前短文本向量化存在的问题
通常情况下,假如一篇长文档中根据一定规则提取出m个分词作为关键词,每一个关键词根据模型算法得到一个n维的词向量,那么就可以用一个m×n的矩阵表示该文档,L篇文档就是L个m×n的矩阵。对于长文本,这通常没有问题,假设L个文档的关键词数量分别为:m1,m2,…ml,只需找到关键词最少的文档m=min{m1,m2,…ml},并以此作为m×n的m值即可,但是对于诸如书目数据这样的超短文本,由于每一个书目的题名可能提取的关键词数量相差甚大,这就导致以下问题。
1.2.1 文档维度不统一。比如《忆》只有一个关键词可以生成词向量,其所生成的文档矩阵大小为:1×100,而《软组织 与 骨肿瘤 病理学 和 遗传学 Pathology genetics tumours of soft tissue and bone》有10个分词可以作为关键词,其文档矩阵为10×100。
1.2.2 不同维度的文档特征矩阵无法进行运算。矩阵的运算对矩阵的形状有着严格的要求,因而,无论是作为神经网络还是NLP,都无法处理维度、形状不一致的数据。
为了解决上述问题,许多学者进行了有益的探索,比如利用外部语料库的文本特征扩展特征向量[7,8]与基于短文本自身内容特征扩展特征向量[9-11],这些算法都着重于扩充文档向量的维度以增加其辨识度。但是这些技术方法对于书目题名数据并不合适:①特征扩充严重依赖外部语料的完整性,100%的完整度不可能做到;②题名数据之间几乎不存在上下文相关性。
1.3 基于权重的题名向量降维算法
笔者采用了“基于分词权重”和“稠密向量”相结合的方法,该方法指导思路如下:①词向量采用固定维度的稠密向量格式,比如采用word2vect后的词向量维度默认是100。②将作者作为题名向量空间中的元素加以考虑。对于题名超短的数据,加入作者词向量可以有效提高数据的辨识度和分类的准确率。③所有题名的特征向量统一降维为1×100大小,可以解决题名只含有一个分词的书目数据向量化的问题。目前常用的特征选择和特征抽取降维方法[12,13]不适合短文本。笔者的重点之一在于解决这个要求,其算法原理如下:

由于各个分词不同,我们可以把集合V的各个元素看作向量空间的一组线性无关的“基”向量,因此V具备张集的特征,根据基向量的性质,必然存在如下一一对应关系:
k1a1+k2a2+…kmam=bki∈,ai∈V
(1)
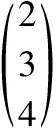
笔者基于稠密词向量的文档特征向量生成方法借鉴了以上概念,文档特征向量的计算公式如下:
w1a1+w2a2+…wmam=bwi∈{TFIDF},ai∈V
(2)
其中wi为每一个词向量的权重,鉴于不同的分词具有不同的TFIDF值,TFIDF值越大,表示该分词的信息熵越低,越能代表文档的确切内容,因此,笔者采用TFIDF值作为词向量权重并作词向量的线性降维运算。
从理论上来说,该方法不但能保留文档所有词向量的信息,而且还保留了每一个词向量的权重信息。
2 基于卷积神经网络短文本分类模型
本研究模型分两个部分:题名特征向量的生成和特征向量的分类训练。
2.1 短文本特征向量空间生成
本研究采用Jieba作为分词工具,word2vect作为稠密词向量生成工具。word2vect是google开源的一款词向量计算工具,可以在百万级的数据上高效训练,同时可以将文本中的特征词在空间上映射为低纬度的稠密向量[14]。
模型从原始文本到特征向量,经过以下步骤:①数据清洗。所谓数据清洗,就是发现并纠正文本数据中可识别的错误,包括检查数据的一致性,处理无效值和缺失值NAN等,在本模型系统中,数据清洗主要的工作有:去除爬虫数据中题名包含的书名号、单双引、换行符号等非文字字符(空格字符起到分割英文单词的作用,因此除外);去除一些与书目信息无关的网页数据,保持数据的一致性,比如图书馆OPAC检索结果中可能包含的“[点击查看详细信息]”之类的文本。②数据规范。从合著、独著、译著等责任者方式中分离出责任者;从出版社字段中分离出出版社,二者作为命名实体数据,避免被分词工具强行分词;纠正原始著录错误,比如去掉题名中多余的空格,以免出现长度为0的无效分词。③根据第一步创建的命名实体词典和停用词表,利用jieba分词。④利用word2vect生成词向量和词向量模型。基于TFIDF权重的文档特征向量降维代码部分如下:
Import numpy as np
...
for i in range(len(trainX)):
line = trainX[i]
v = np.zeros(100)
cp = dict.doc2bow(line)
weights = tfidf[cp]
for w in line:
idx = dict.doc2idx([w])[0]
weight = list(filter(lambda x:x[0]==idx,weights))
v = v + model.wv._getitem__(w)* weight[0][1]
trainX[i]= v
print(’生成’,i,’条文档向量’)
...
代码说明:trainX为待训练文档的关键词列表数据,dict为训练后的词袋词典,tfidf为训练后的TFIDF模型,model为训练后的word2vect模型。限于篇幅,以上代码仅供参考。
2.2 卷积神经网络的结构改进
各种分类问题是神经网络的主要研究方向,目前图书馆界的各种基于神经网络和深度学习的研究基本上也以分类问题为主,比如各种舆情分析、情感分类等,对于题名一类的超短文本文档,虽然也可以借鉴以上思路,但是不能照搬传统神经网络的模型结构。
卷积神经网络(convolutional neural networks,CNN)是深度学习领域的重要模型,是根据生物学上“感受野”机制提出的一种前馈神经网络[15]。典型的卷积神经网络结构如图1所示,由若干个卷积池化层和一个全连接层构成,每一个卷积层通过卷积核对原始数据提取特征,经过池化层的有损压缩后输入到下一层,最终形成分类结果。同全连接BP神经网络相比,卷积神经网络因其权值共享,在处理大数据的时候性能更具优势,因此广泛应用于图像数据的分类处理上。近年来,很多学者尝试将卷积神经网络应用于文本数据的分类处理,并取得了不错的效果。
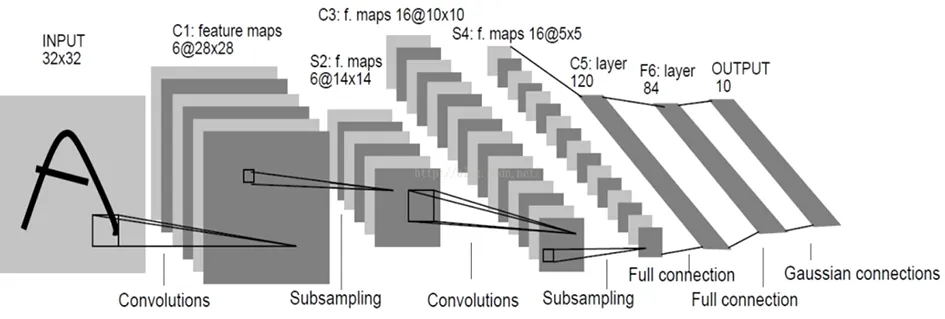
图1 卷积神经网络模型结构
但是经过多次实验对比,这种传统的结构在处理短文本文档的分类时候表现并不理想,经过分析,发现原因有以下两点:①题名的特征向量维度太低,比如通常默认只有100。而卷积神经网络最初是为大维度的向量数据设计的,我们以降为1维的向量做对比:比如最小的彩色图标文件尺寸为3×32×32像素,转换为一维向量后,其维度为3 072,稍微大一些的图片数据,更是远远大于文档的特征向量。②卷积层和池化层的有损压缩导致文档的特征向量丢失信息。从本质上来说,文档的稠密特征向量已经对文档的信息进行了压缩,经过卷积和池化后,数据的维度大幅度降低(如表1所示),严重影响分类学习的效果。
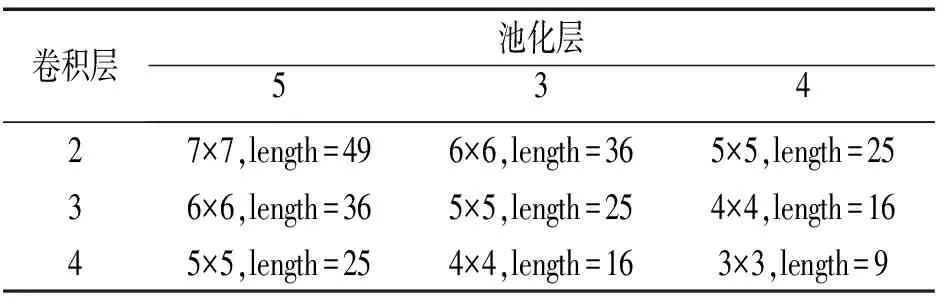
表1 不同尺寸卷积核一次卷积池化后对数据维度损失的影响
从表1可以看出,经过每次卷积池化,特征向量的维度都会大幅下降,事实上,即使采用较小的3×3的卷积核,经过两次卷积池化运算后,文档的特征向量只有4×4大小,维度降低为16维,信息损失84%。
笔者通过以下两种方法避免特征向量降维而损失信息:①卷积层通过padding补零来保证卷积后的维度不变。②取消池化层。无论是最大池化还是平均池化,都不可避免地会对数据进行有损压缩,取消池化层可以避免这个问题。实验证明,池化层并不是卷积神经网络必不可少的,对于低纬度特征向量的运算来说,取消池化层后的回归效果更好。
改进后的神经网络如图2所示。
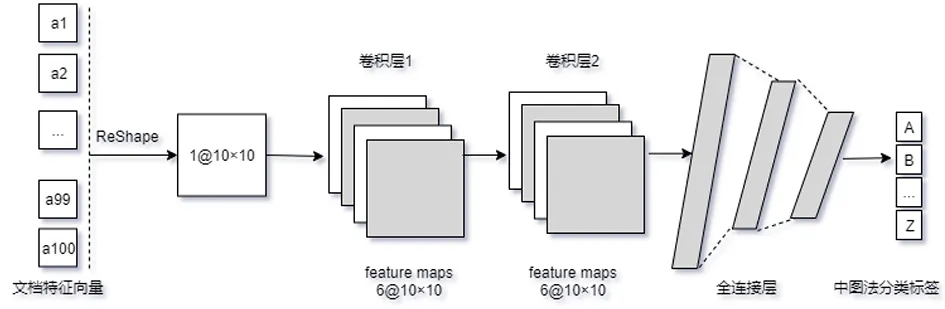
图2 基于短文本的CNN结构
2.3 实验结果
本研究以平顶山学院图书馆OPAC页面抓取的153 816条数据作为原始文档,数据经过清洗、分词,并按照中图法生成22个分类标签,前15万条作为神经网络训练数据,后3 816条作为测试数据;利用word2vect针对分词生成稠密词向量,word2vect函数的频数阈值min_count设置为1,以避免当文献题名只有一个汉字的时候不能生成词向量;利用gensim的 TFIDF模型生成每一个分词的向量权重数据,在卷积神经网络上经过100次迭代训练后,基于交叉熵的损失稳定下降(见图3),证明经过训练,该卷积神经网络确实通过深度学习,具备了一定的短文本分类能力,最终实验结果:3 816条数据的22分类整体正确率为67.5%,各个分类的正确率、召回率和F1值见表2。
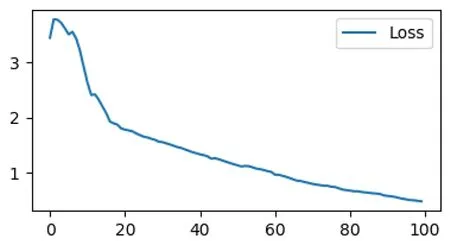
图3 100次迭代损失值变化
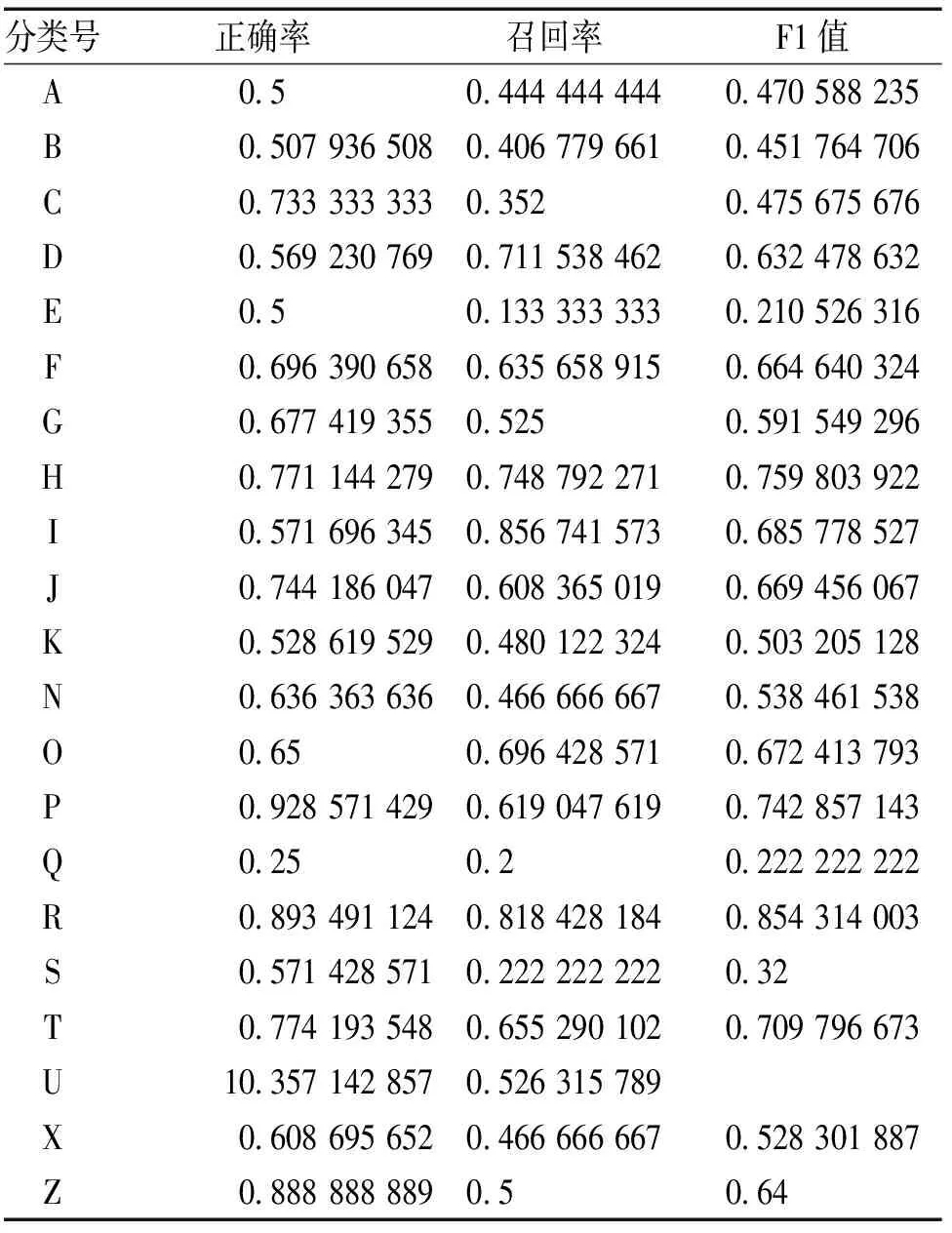
表2 22元分类的正确率、召回率和F1值
从分类统计结果可知,专业特征明显的书籍容易得到较高的F1值:比如语言学、天文地球科学、医学、工业技术,这和我们人工分类的直观感受一致,该分类结果基本上具备了参考价值。
3 结论
笔者以文献题名数据为对象,研究了基于题名数据的超短文本分类问题,涉及超短文本的特征向量的建立、卷积神经网络的优化等方面,具有一定的理论研究价值和实践意义。在理论层面,基于向量空间中基的原理,提出了基于TFIDF权重的、不同尺寸的文档特征矩阵降维的方法,验证了卷积神经网络在取消池化层后,针对低纬度向量的分类具有更好的效果。在实践层面,该网络模型对于智能助手开发、文献智能分类都具有借鉴意义。
限于研究环境和个人学术水平等因素,也存在不足,比如:由于爬虫获取数据效率太低,本模型未能获取完整的图书馆书目数据,语料数据不足对于模型的准确度会有较大的影响;硬件配置较低,无法利用腾讯AI LAB开源的800万词向量模型来提高词向量的质量;分类准确度仍需进一步提升,而且还无法做到更详细的分类。这些问题需要在以后的研究中针对数据和模型持续优化,不断提高。
