复杂环境下弓网接触位置动态监测方法研究
2022-07-16张乔木钟倩文罗文成柴晓冬
张乔木,钟倩文,孙 明,罗文成,柴晓冬
(1.上海工程技术大学 城市轨道交通学院,上海201620;2.上海申通地铁维护保障公司 供电分公司,上海200031;3.常州路航轨道交通科技有限公司,江苏 常州213164)
高速列车在区段的运行过程中,可能会出现受电弓弓网放电、受电弓跌落、受电弓部件脱落、碳滑板磨耗、接触点位置异常等问题。对受电弓及接触网进行视频监测能有效保障列车行车安全。目前对于受电弓的监测主要是非车载系统。非车载系统只能在列车通过检查地点时进行瞬时检测,实时性较差。在受电弓检测方面,对受电弓与接触网的接触点的监测研究取得了一定的进展,但列车运行中环境复杂且多变,因此在复杂环境下达到有效的监测变得尤为重要。
目前对受电弓的监测主要包括:(1)采用红外热成像技术监测弓网接触点发热情况;(2)运用力学传感器来监测受电弓运动过程中的受力状态;(3)采用双目测量技术以及图像处理的方法监测受电弓的磨损状况。文献[1]运用Harr检测原理,通过增大滑窗来增大接触点火花检测实时性。文献[2]通过一次标定靶平面,采用单目相机与线激光器来进行磨耗检测。文献[3]利用图像采集模块采集滑板磨耗图像和裂纹图像,对其用改进的Canny算法提取滑板磨耗边缘,并计算裂纹长度,绘制磨耗曲线。文献[4]用图像二值化法区分弧光与背景,并用改进的Canny算子检测弧光边缘,得到了燃弧重心横坐标,达到识别燃弧的目的。文献[5]对单目红外图像中的弓网接触线、点的检测与跟踪算法进行了深入研究,提出了接触线和碳滑板的特征增强方法,解决了接触线被定位器拉折时直线检测不准确的问题。文献[6]对受电弓脱落、羊角缺失等追踪进行研究,引入了一种检测机制对KCF(Kernel Correlation Filter)追踪算法进行矫正,并取得了良好的检测效果。
本文针对复杂环境下对受电弓与接触线的接触点进行识别监测的问题,提出一种复杂环境下弓网接触位置动态监测方法。本文通过对高速列车采集到的视频数据进行帧间差运算得到图片数据;然后,为了加强复杂环境下接触点特征,通过PSPNet(Pyramid Scene Parsing Network)语义分割构建新特征数据集;最后,通过优化YOLOv4(You Only Look Once)网络结构对数据集进行训练,得到检测模型,以此权重模型对受电弓与接触网的接触位置进行跟踪,达到监测的目的。
1 受电弓视频数据预处理
弓网位置动态实时监测算法的流程图如图1所示。本文通过帧间差提取视频中的图像,并通过PSPNet网络进行语义分割,构建特征数据集,然后利用优化的YOLOv4网络训练对目标进行识别、定位。

图1 算法流程框图Figure 1. Block diagram of algorithm
为了构建受电弓数据集,对受电弓视频图像做特征帧提取。在视频图像空间域中提取视频的每一帧图像,并采用等量帧间差运算来提取出受电弓视频图像[7],如图2所示。

图2 帧间差提取受电弓图像Figure 2. Extraction of pantograph images by frame difference
将RGB空间转换到HSV空间,并通过H、S、V构造综合分量[8]
G=HQsQv+SQv+V
(1)
综合分量G的各值在图像中像素的直方图为
Hi=(hi1,hi2,…,hik)T
(2)
Hj=(hj1,hj2,…,hjk)T
(3)
直方图帧间差为式(4)。
(4)
在列车高速运行情况下采集受电弓视频图像。然后,通过空间分量帧提取方法[9],可从不同区间列车运行的视频中分离出3 000张背景良好,且包含支柱架或桥洞的弓网图像,如图3所示。

图3 视频图像帧提取效果图Figure 3. Video image frame extraction renderings
2 基于PSPNet网络受电弓与接触网语义分割
基于深度学习的图像分割算法主要分为两种:一种是基于卷积神经网络(Convolutional Neural Networks,CNN)特征编码对目标图片进行特征提取的框架[9];另一种是基于全卷积网络(Fully Convolutional Networks,FCN)的上采样与反卷积分割框架。前者在卷积和池化过程中易丢失图像细节,且采用全连接层获取类别概率的方式不能标识每个像素类别,因此无法做到精确分割。后者在CNN基础上把全连接层改为卷积层,在多次池化操作前加入了上采样,虽然解决了精确分割问题,但边缘提取效果不佳[10]。
目前,基于FCN模型的主要问题是缺乏合适的策略来利用全局场景中的类别线索[11]。运行列车动态视频的弓网目标较小,通过局部和全局线索的共同作用可提高预测准确率。
以原始数据集图像中的受电弓和接触网为前景,其余的为背景。在前景中,接触网的电线是很小的物体且易与支柱架和桥洞混为一体,而受电弓在图像中是相对固定区域。分割图像前,需要给图像中的每个像素标定一个类别标签。通过对图像中的动态对象分割,实现逐像素分类。由于受电弓接触线具有单一的直线型结构,使得其对大片连续区域的对象在语义理解上有所不足。PSPNet通过对不同区域的上下文进行聚合,提升了网络提取全局特征信息的能力,能够完成有效分割。PSPNet模型的结构如图4所示。

图4 PSPNet模型结构(a)输入 (b)特征图 (c)金字塔池化模块 (d)输出Figure 4. PSPNet model structure(a)Input (b)Feature map (c)Pyramid pooling module (d)Output
PSPNet主要结构可分为特征提取模块、金字塔池化模块和输出模块。在PSPNet中,使用ResNet提取图像特征。ResNet具有较大的深度,能有效地提取图像深层特征[12]。在进行卷积操作时,通过卷积核权值共享减少网络中参数,防止过卷积操作的计算式为
(5)

ReLU为激活函数,其计算式为
rectifier(x)=max{0,x}
(6)
池化操作为

(7)
其中,H×W为池化核大小。
通过使用不同窗口大小的池化操作,得到不同尺寸的输出,然后缩放到相同的尺寸,再进行特征融合。
对于原始特征图,所通过的池化大小分别为1×1、2×2、3×3、6×6。然后分别使用1×1卷积调整通道数至1/N(N为池化层个数,本网络为4)。然后将这些特征图通过双线性插值的方法完成上采样。再将这些池化特征图和原始的特征图(跳跃连接)全部concat(特征融合的方式,即通道数合并)起来,得到最终输出的特征图。concat的作用是防止因为池化和上采样丢失过多的接触网和受电弓的细节信息。通过上述处理,最终可以得到分割的预测结果。
PSPNet提取受电弓前景的过程如图5所示:首先输入铁路受电弓的原始图像;经过一系列的卷积池化后,提取4种尺度的金字塔特征;经过特征融合,最后输出受电弓的前景部分。目标分割速度能稳定达到42 fps,可满足正常高铁运行的实时分割要求。

图5 语义分割后的弓网图像Figure 5. The image of the bow net after semantic segmentation
3 视频图像弓网接触位置识别
3.1 YOLOv4结构
YOLOv4属于one-stage检测算法。检测时,首先将待测图片分割成n×n的网格,每个网格负责不同的区域。当待检测目标的中心落在某个网格中,则由该网格完成对目标的检测[13]。YOLOv4的主干网络CSPDarknet53(Cross Stage Partial Darknet53)是算法的核心。YOLOv4在上一个YOLO版本上,对每个残差块网络增加CSP结构,将其特征映射划分为两部分,再通不同阶段层次结构合并来提高准确率。YOLOv4的激活函数是比ReLU计算量更大的Mish函数,这种改变可提高目标检测的准确率。
在特征金字塔结构部分,YOLOv4构建了SPP(Spatial Pyramid Pooling)结构和PANet(Path Aggregation Network)结构。SPP结构可对特征层P5输出的特征图经过卷积后的结果进行最大池化。池化过程中共使用4种不同尺度的池化层进行处理,其池化核大小分别为1×1、5×5、9×9、13×13。SPP结构可有效增加感受野,便于分离出显著的上下文特征。PANet结构是由卷积操、上采样、下采样、跨层的特征层融合构成的循环金字塔结构。在YOLOv4的网络结构中,PANet可实现高层特征与底层特征信息融合,达到提高小目标检测物的检测精度的目的。最后,对每个特征层的3个先验框进行判别,判断是否包含目标及目标种类,并进行非极大抑制处理和先验框调整,从而得到最终的预测框。YOLOv4的网络结构如图6所示。
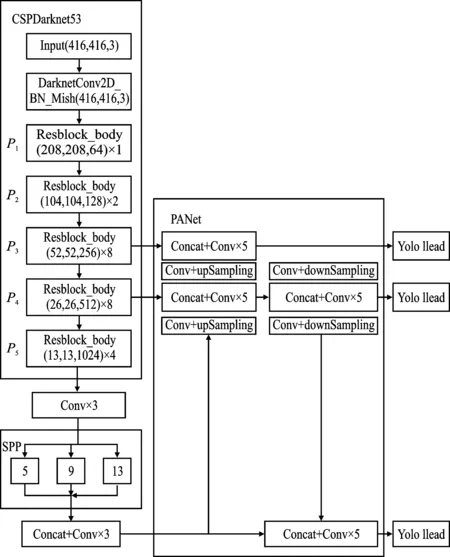
图6 YOLOv4网络结构Figure 6. YOLOv4 network structure
YOLOv4网络的损失函数为
(8)
其损失函数由回归框预测误差、置信度误差、分类误差组成。
对于回归框预测
(9)
(10)
式中,a为度量trade-off的参数;ν度量长宽比的相似性;gt表示ground truth;wgt为真实框宽度;hgt为真实框高度;w为预测框宽度;h为预测框高度。当真实框和预测框的宽高相似,则ν为0,该惩罚项就不起作用。所以这个惩罚项的作用就是控制预测框的宽高,使预测框宽高能够尽可能快速接近真实框的宽高。
ρ2(Actr,Bctr)为预测框与真实框中心点的欧式距离。参数ρ2(Actr,Bctr)/m2通过最小化两个检测框中心点的标准化距离, 加速损失的收敛过程。
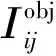
3.2 YOLOv4算法改进
3.2.1 K-means聚类
原始YOLOv4算法的先验框是在VOC数据集的标注上进行聚类得到的。由于VOC数据集包含的目标多样,目标的长宽比例不同,其先验框的大小也不同[15]。对于受电弓与接触网的接触点位置检测而言,接触点特征在不同帧基本一致,因此无法直接使用原模型的先验框。通过K-means算法对语义分割后的数据集标注框聚类能起到较好的效果,因此本文用K-means算法来获取与接触点特征比例相匹配的基准框。本文对数据进行迭代,得到聚类中心[15],并用聚类中心与标签的交并比IOU(1,c)作为聚类的相似度参数来代替欧式距离以减少误差。聚类距离计算式如下所示[16]。
dIoU=1-IOU(1,c)
(11)
3.2.2 改进网络结构
在YOLOv4的基础上,对其结构进行了优化,使其更加适用于受电弓图视频识别。YOLOv4算法使用CSPDarknet53作为主干特征提取网络,并输出3个不同大小的特征层[17]。特征层P3、P4、P5的宽和高分别为原始输入尺寸的1/8、1/16、1/32。特征层P3和P4分别经过一次1×1的卷积操作后进入PANet结构中进行特征融合。特征层P5经过1×1、3×3、1×1的3次卷积操作后进入SPP结构中进行最大池化。这些操作在一定程度上可对受电弓与接触网特征进行提取,但由于区段上的接触网线较多,且支柱架与受电弓特征比较相近,若直接使用原始YOLOv4算法进行训练与检测,则无法获得理想的检测结果。
因此,针对经过桥洞和支柱架时,前景与背景特征区分度不明显的问题,本文借鉴原始YOLOv4算法中卷积层的设计思想,在网络的P1和P2中间加入了1×1卷积层和3×3卷积层这两层网络来加强对浅层特征的提取。将CSPDarknet53输出的特征层P3、P4后的1个卷积层增加为3个卷积层,卷积核分别为1×1、3×3、1×1、3×3、1×1。上述多次小卷积改进处理,不仅可加深网络深度,进而增加网络容量和复杂度,还能获得更大的感受野,增强提取全局及语义层次更高特征的能力,从而更加有效地提取接触点目标的特征。
相比YOLOv3,YOLOv4对特征提取能力的增强,使得网络的检测平均精度mAP(Mean Average Precision)得到了提升。将修改后的模型与YOLOv4、YOLOv3、SSD(Single Shot MultiBox Detector)和FastR-CNN进行对比,结果如表1所示。
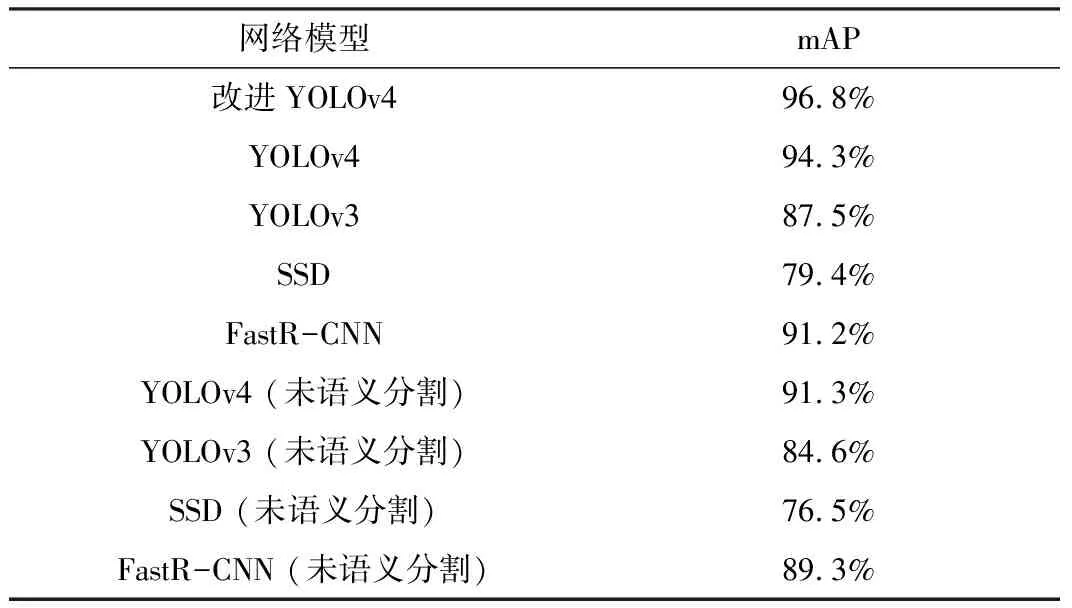
表1 网络模型mAP对比表Table 1. Comparison of mAP of network models
本文对5个网络进行了横向对比,经过语义分割后,由于接触特征加强,检测效果得到明显提高。对于同一语义分割后的数据集训练后的检测效果,FastR-CNN检测精度相比于YOLOv3和SSD这一类one-stage的算法要更加准确。YOLOv4网络由于采用了新的CSPDarknet53网络结构,增强了网络整体的特征提取能力,并采用了多尺度检测机制,提高了对小目标的检测精度。经过语义分割后,使用改进YOLOv4的检测精度比未语义分割的YOLOv4提高了5.5%。随后,在带有NVIDIA Quadro P5000GPU的情况下,对5种算法的检测速度进行了测试(语义分割的受电弓视频),测试对比结果如表2所示。

表2 网络模型FPS对比表Table 2. Comparison of FPS of network models
改进YOLOv4模型的检测精度得到了较大提升,但其检测速度有所下降。FastR-CNN由于具有复杂的网络结构,因此检测速度最慢。YOLOv4为one-stag结构,因此其检测速度要比同为端到端网络的SSD模型更快。
以上mAP和FPS的对比结果证明,修改后的网络模型的整体性能要优于YOLOv4。修改后的网络模型对于目标特征的提取能力更强,更适用于本次设计的运用场景。
4 实验结果与分析
4.1 实验环境
本文使用Quadro P5000进行运算,同时在服务器上搭建用于进行实验的环境,如表3所示。

表3 弓网接触位置监测实现环境Table 3. Implementation environment for monitoring the contact position of the pantograph and net
4.2 实验结果
对语义分割后的数据集使用改进YOLOv4模型进行训练,训练为80个epoch,权重衰减系数设置为0.000 5。前40个epoch学习率为0.001,后40个epoch学习率为0.000 1。整个训练迭代到16 000次。
通过以上的训练可获得权重,运用训练好的网络模型能够从视频图像中识别出受电弓与接触网的位置关系,并能输出受电弓与接触网的接触点在图像中的坐标。无语义分割的情况下,YOLOv4在支柱架下不能检测出接触点位置,而语义分割后的数据集在改进的YOLOv4检测下,可在列车运行时对动态接触位置进行有效监测,目标监测效果对比如图7所示。

(a)

(b) 图7 支柱架下检测效果对比(a)无语义分割的改进YOLOv4检测 (b)语义分割后的改进YOLOv4检测Figure 7. Comparison of detection results under the pillar frame(a)YOLOv4 detection without semantic segmentation (b)YOLOv4 detection after semantic segmentation
图8为动态接触点的输出曲线,加粗黑线为受电弓运动的中线。
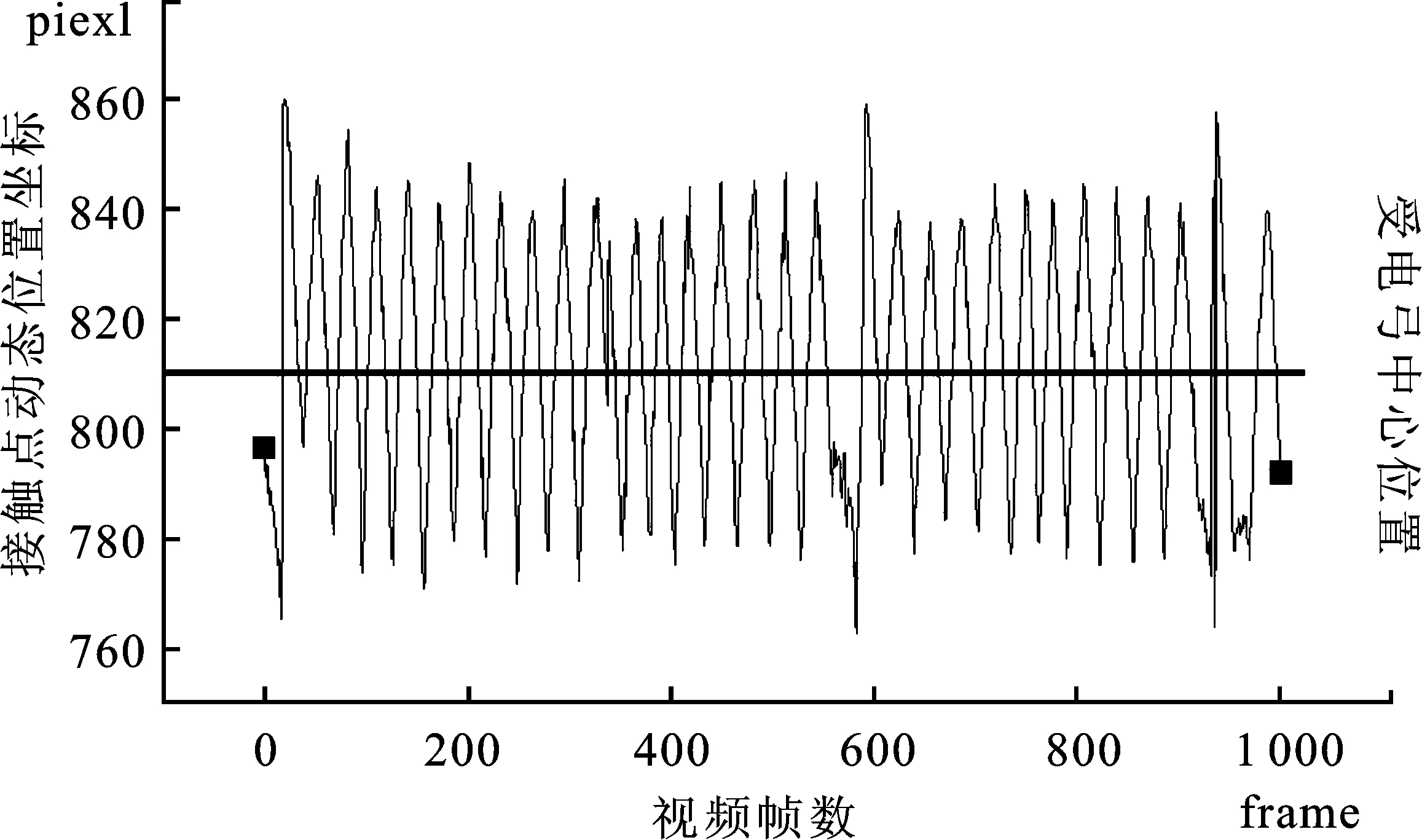
图8 受电弓接触点动态监测Figure 8. Dynamic monitoring of pantograph contact points
5 结束语
本文提出了一种基于视频图像的弓网接触位置动态监测方法,能够有效地在复杂的运行环境下进行监测。该方法通过PSPNet语义分割加强复杂环境下接触点特征;通过优化YOLOv4网络结构增强了全局及语义层次更高的特征提取能力,从而更加有效地提取接触点目标的特征。在未来研究中,将尝试对原始数据进行预处理,在满足特征要求的前提下降低图片的尺寸,同时对网络结构进行优化,以期提升接触点检测速度,建立更好的轨道交通受电弓实时智能化检测方法。
