基于Deeplab-v3+的小目标与边缘增强热图像语义分割网络
2022-07-15任莎莎张晓东
任莎莎,刘 琼*,张晓东
(1.华南理工大学软件学院,广东 广州 511436;2.皖西学院机械与车辆工程学院,安徽 六安 237012)
基于语义分割的图像理解[1]作为计算机视觉的基本任务之一,旨在为图像中的每个像素分配语义标签[2-6].一般通过预测每个像素的位置、类别等特征来实现对图像的完全理解,又称语义分割.该任务对于自动驾驶[7]、姿态估计[8]、图像搜索引擎[9]、医疗影像诊断[10]等应用领域来说具有重要的研究价值.虽然在最近几年内基于语义分割的图像理解已经取得了很多进展.如目前使用最广的PSPNet[11]和Deeplab[12]语义分割方法提出了特征金字塔池模块,通过聚合多个尺度的特征来获得多尺度上下文,优化目标边界细节信息.Cheng等[13]和Bertasiu等[14]提出同时学习分割与边界特征的检测网络,恢复池化层丢失的高分辨率特征.而文献[15-16]则提出学习边界作为中间表征来辅助分割.Takikawa等[17]在Deeplab-v3+[18]的基础上通过增加一个由门控网络构成的边缘形状学习分支网络来捕获图像中的边缘特征,并且在网络中引入多任务的损失函数来监督网络的训练过程,同时引入多任务的正则化项来防止过拟合.由于该网络良好的边界特征学习能力,其在Cityscapes验证集上可见光的图像分割精度达到了78%左右,且在小目标的分割精度上有大幅度提高.又如Ding等[19]提出了一种边缘感知的特征传播网络,与直接增强网络中的边缘特征不同,该网络把图像中的边缘作为一种附加类,学习图像中的边缘特征,以控制其特征的信息流在边缘像素点内进行传播,取得了较好的成果.但在夜晚和恶劣环境(雨﹑雪﹑雾天气等)下得到的可见光图片,对其进行准确分割仍存在很大的挑战.然而热红外相机通过捕获超过绝对零度以上物体的温度而成像,可以不受环境和光照变化的影响,因此在恶劣天气下热红外图像获得的信息会更多.由于热红外设备成像过程中物体边缘红外辐射能量分布与环境温度差异较小,导致其成像图片存在边缘模糊,细节信息极弱,以及因红外辐射能量分布与目标颜色分布相关性较弱而缺少颜色信息等问题.现有研究的算法未充分考虑到边缘和微小目标的语义细节,而且对所有目标使用相同的边缘增强标准,会导致微小细节容易丢失且大目标内部不一致的问题.另外,现有的基于深度学习的方法对数据集有很强的依赖性,而热红外图像公开的数据集较少,这大大限制了热红外图像分割的发展.因此研究热红外数据分割对夜晚等恶劣天气下自动驾驶与智能环境监控等应用有着重要的意义.
近年来出现了很多热红外图像分割的研究.如在可见光与热红外数据集RGB-T的语义分割[20-22]中,虽然在原有数据集上增加了热红外数据,可以在一定程度上改善夜间、雾雪等能见度低的恶劣天气下的图像分割问题,但偏远地区的夜间及其恶劣天气下图像很难获得,即使花费很大成本获得偏远地区恶劣天气下图像,其图像清晰度也十分差,不利于提高RGB-T图像的分割质量.且恶劣天气下的热红外图像信息也未被充分挖掘.为此,有人专门对热红外图像分割问题进行了研究.如Li等[23]构建了热红外图像分割数据集SODA,并提出了一种边缘条件卷积神经网络(EC-CNN)算法.在该网络中设计了一个门控特征转换层,以适应性地纳入边缘先验知识.经过端到端训练,可以产生具有边缘引导的高质量分割结果.又如Xiong等[24]提出了一个带有多级注意模块和多级边缘增强模块的多级校正热图像语义分割网络(MCNet).该模块通过多级校正过程有选择地捕捉类间和类内的关联性,然后在每个级别中不断结合精确的上下文信息和边缘先验知识来修正最终边缘特征.但这些工作中未考虑对热红外图像分割中语义边缘与小目标等信息的分割问题,且分割精度未能满足实际应用的需求.如夜间车载场景下远处的红绿信号灯、柱子和远处的行人等小目标的精确分割和理解对自动驾驶的安全行驶具有重要的意义.因此,怎样提高热红外图像小目标和边缘的分割质量是本文关注与解决的问题.
1 本文方法
本文方法的整体框架如图1所示,在编码-解码的基础上增加了多级像素空间注意模块(MPAM)、边缘提取模块(EEM)和小目标提取模块(TTM).其中MPAM模块通过对主干网络不同层级特征进行优化并逐级传导,最终在底层级得到具有较强语义信息的图像特征并输出.EEM和TTM对目标外轮廓和小目标进行显式建模,把具有语义信息的底层级图像特征中的边缘和小目标特征提取出来.用专门设计的损失函数对其进行监督训练来提高各类别边缘相交区域像素点的预测精度.最后把边缘和小目标特征与主干网络的分割特征相融合,弥补主干网络中丢失的边缘和小目标等细节信息.
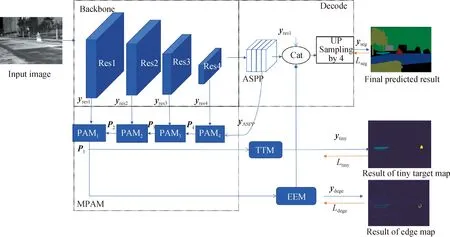
图1 整体网络框架Fig.1 The overall network framework
具体方法为:使用ResNet101[25]作为主干网络,并用不同空洞率的卷积来获得不同尺度的特征图,通过聚合上下文来得到更多的语义信息,从而获得更准确高效的特征输出yASPP.虽然此时特征yASPP有较高的语义信息,对其进行梯度求导,能获得较大目标的轮廓信息.但由于此时特征图较小,小目标和边缘等细节信息已丢失.为了在恢复网络丢失的细节信息的同时保持其语义信息,MPAM模块通过多级引导过程把高层的类间和类内的关联性语义信息不断传导到相邻低层级.在各级中结合精确的上下文信息和先验知识来修正.最后在底层级得到具有较强语义信息的图像特征.EEM和TTM分别对具有较强语义信息的像素空间的底层级进行边缘和小目标特征显式建模,提取边缘特征yedge和小目标特征ytiny,并设计特定的损失函数Ledge和Ltiny对其进行监督训练.最后,用带有语义的边缘特征yedge、小目标特征ytiny、yASPP和yres1一起融合,并输出到解码模块来恢复小目标和目标边界等细节信息,以期获得更准确的分割性能.其过程如下:
yseg=UPSampling(yres1‖yASPP‖yedge‖ytiny),
(1)
其中,UPSampling表示上采样操作,‖表示合并操作.
1.1 MPAM
MPAM由多个像素空间注意模块(pixel spatial attention module,PAM)组成.如图1所示.MPAM通过PAM把高层的类间和类内的关联性语义信息不断传导到相邻低层级,即yASPP引导yres4通过PAM4获得特征P4,P4引导yres3通过PAM3获得特征P3,P3引导yres2通过PAM2获得特征P2,P2引导yres1通过PAM1获得特征P1的输出.其数学过程如下:
P1=PAM1(PAM2(PAM3(PAM4(yASPP,yres4),
yres3),yres2),yres1).
(2)
PAM的原理如图2.首先将具有较强语义信息的高层特征yh(具体包括yASPP,P4,P3,P2),经过全局池化(global pooling,包含全局平均池化和全局最大池化)得到全局上下文信息作为低层特征yl(具体包括yres1,yres2,yres3,yres4)的指导信息,再经过并行平均和最大化(avg&max)的轻量级池化,来加强全局类别的空间细节的注意力.具体地,对低层次特征执行1×1的卷积操作,以减少CNN特征图的通道数.高层次特征每个通道依次经过全局平均池化和全局最大池化,然后经过共享网络产生通道注意力映射图.该共享网络是由2个全连接层以及非线性sigmoid函数组成多层感知网络(multi-layer perceptron,MLP),为了减少网络参数,隐含层激活函数尺度设置为R1×1×C/r.r为通道降低率,然后通过元素求和合并2个输出.输出经过批量归一化(batch normalization, BN)和非线性变换、1×1卷积等操作(记为δ1)生成具有全局上下文信息的特征,接着再与经过卷积运算后的低层次特征相乘,获得图像的通道语义关系:

图2 像素注意力模块Fig.2 Pixel attention module
yC(yh,yl)=δ1(MLP(AvgPool(yh))+
MLP(MaxPool(yh))⊗conv(yl).
(3)
其中,⊗表示外积.
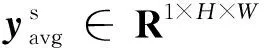
(4)
1.2 EEM
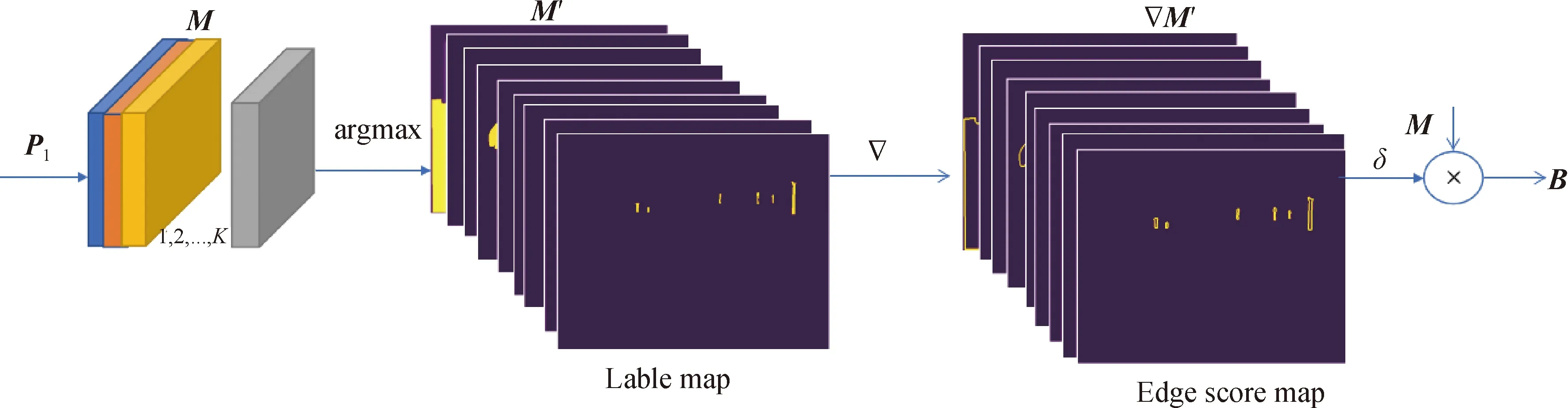
图3 热图像边缘提取模块Fig.3 Edge extraction module

(5)
(6)

(7)
其中:δ为sigmoid函数;dis为距离转换符,该运算主要通过计算非背景像素点与背景像素点最近距离,来计算目标与背景之间的边界处点的梯度值;⊙表示对应元素相乘;边缘特征B=yedge.同理,可以得到边缘实况图.
1.3 TTM
为了获得具有语义类别的小目标特征,对MPAM模块输出的特征图进行argmax处理得到标签图,在对标签图中每一个目标的像素数进行统计分析并对其进行排序,将每个目标的像素数numK依次与最大目标的像素数nummax相比,默认比值小于0.01(可调)时,该目标为小目标.设置小目标的像素值不变而其余值为零,即得到小目标掩膜版(small score map).用sigmoid函数处理后的小目标掩膜版,再与K个通道的特征图M相乘,最后得到带有语义信息的小目标特征图ytiny.具体过程如图4所示.由于MPAM模块输出的特征中像素空间位置具有较强的语义关系,所以提取的小目标特征含有语义类别信息.
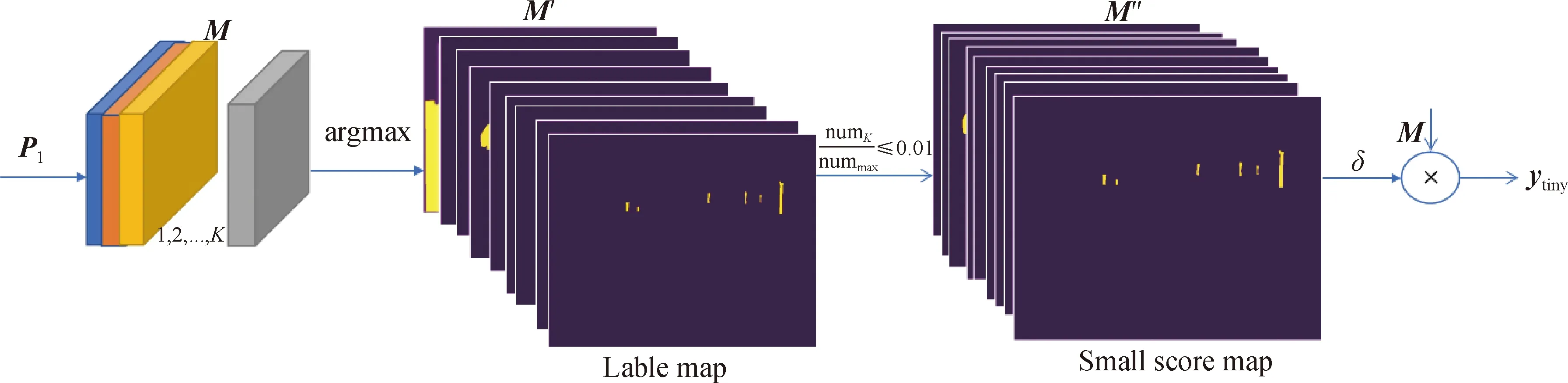
图4 热图像小目标提取模块Fig.4 Tiny object extraction module
同理,对数据集的实况图中目标的像素数进行统计分析,当得到的各个目标的像素数依次与最大目标的像素数的比值小于0.01(可调)时,默认此为标注实况图中小目标.再用小目标掩膜版,可以得到小目标实况图.
1.4 损失函数
交叉熵损失函数能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异.其标准形式一般为:
(8)
其中,x表示样本,y表示实际标签,p表示预测输出,n表示样本总数.交叉熵的值越小,模型预测效果就越好.一般在分类问题中需要采用softmax对网络输出的结果进行处理,使其多个分类的预测值的和为1,再通过交叉熵来计算损失.在用梯度下降法对网络权重进行更新时,参数的更新受到交差熵的影响,当交差熵的值大时,权重更新快;当交差熵的值小时,权重更新慢.训练过程样本采样存在困难样本的问题,本文采用OHEM(online hard example mining)算法对网络进行训练,以缓解样本不平衡带来的问题.
(9)
(10)
(11)
(12)
其中,Cφ(xj|z)为小目标像素j处的预测标签xj概率分布,yj为实况图的小目标像素j处的标签.此外,主干网络分割监督损失函数表示为:
(1-yi)ln(1-Cφ(xj|z))],
(13)
其中Cφ(xj|z)为图像分割像素j处预测标签xj的分配概率,yj为分割实况图的标签.网络建模中的总损失表示为:
L=α1Lseg+α2Ledge+α3Ltiny,
(14)
其中α1,α2,α3为网络超参数.分别为分割损失,边缘损失和小目标损失的权重.
2 实 验
本实验采用Linux环境下Pytorch学习框架,基于Python编程语言,硬件环境:CPU为因特尔E5-2650 V4,GPU为微星NVIDIA GeForce RTX 2080Ti.为了验证本文方法,首先选择在热红外数据集(SCUT_SEG)上,与多个最相近的算法进行大量的对比实验,并将各个结果进行了可视化展示与分析.为了更进一步地验证所提出的各个模块的有效性,还进行了有关的消融实验,并对每个消融实验进行了详细的分析.最后,在另外两个热红外数据SODA[23]和合成热红外数据集STI-Cityscapes上进行了实验.在对各个算法进行对比时,本文采用热图像分割最常见的评价的度量均交并比(mean intersection over union, mIoU)作为评价度量.
2.1 热红外数据集
1) SCUT_SEG数据集:SCUT_SEG数据集是本课题组采集并标注的校园及周边场景的热红外图像,该数据集从拍摄的300 000张热红外图像(70 000张夏季图片,230 000张冬季图片)中挑选了2 010张图像进行精标.用比较流行的语义分割开源图片标注工具Lableme[23-24]对本文的原始数据进行标注.其中训练集包含1 345张图片,665张图片用于测试.图片分辨率为576×720,该数据集包括10个类别,分别是背景(background)、道路(road)、人(person)、骑手(rider)、汽车(car)、卡车(truck)、栅栏(fence)、树(tree)、公共汽车(bus)和杆(pole).为了确保数据集的标注质量,雇佣8个有经验的人对数据进行标注,然后采用多轮检测的手段对已标注的数据进行检查,并对其中10张非标准的标注图片进行修复,最后形成高质量标注的热红外校园场景数据集.与SODA数据相比,本文数据采集的图片来源于更多的季节,因此场景更为复杂,且在边缘与小目标分割任务上更具有挑战性.图5为本文数据集的分析结果(从30万张图片中挑选出2 010张图进行精标的结果),其中,图5(a)为数据中每个类别像素的占比数,右边图表示路面、背景和其他类别占比,左图表示其他类别中汽车、骑手、人、电线杆、巴士、树、栅栏和卡车的像素比例.图5(b)为对不同尺度(以像素占比为准)目标数量的统计情况.由图5(b)可见,目标越小,其目标个数越多,小目标分割越显重要.

图5 SCUT_SEG数据分析Fig.5 SCUT_SEG data analysis
2) SODA数据集:Li等[23]采集并标注了SODA数据集,该数据集包含2 168张精心标注的校园及校园周边场景的红外热图像,其中训练图像1 168张,测试图像1 000张,该数据集有20个语义区域标签,包括人(person)、建筑(building)、树(tree)、路(road)、杆(pole)、草(grass)、门(door)、桌子(table)、椅子(chair)、汽车(car)、自行车(bicycle)、灯(lamp)、监视器(monitor)、交通锥标(T-Cone)、垃圾桶(trash can)、动物(animal)、栅栏(fence)、天空(sky)、河流(river)、人行道(sidewalk)和一个背景标签.
大学生身心已基本发育成熟,自控能力比中小学生要强,经过小学、中学阶段的学习,他们有了一定的英语学习基础,具备了一定的网络自主学习的能力。随着电脑及智能手机的普及,大学生可以充分利用互联网教学资源及学校的网络教学平台资源进行自主学习,这种网络学习方式具有很大的灵活性,不受时间地点的限制,可以满足学生个性化的学习需求。
3) STI-Cityscapes:参考Li等[23]的工作,为了节约标注成本和提高标注质量,本文同样采用合成的热红外数据对算法进行训练和测试.该合成数据集是由Cityscapes数据中的RGB城市场景图像转化成热红外城市景观图像,生成的一个新的合成热红外数据集,由5 000张精细标注热红外图像组成,其中有2 975 张训练图,500张验证图和1 525张测试图.在标注类别中有8个大类,每个大类中包含若干子类,共有30个小类,除去一些像素出现频率较小的类别,用19个类作为评估.
2.2 实验参数设置
超参数设置:为了更充分地利用每一层特征信息,恢复主干网络丢失的细节信息,对边缘和小目标特征进行提取,网络损失函数的系数分别设置为1.参考COCO数据中设定小目标数据的准则[27],设置小尺度目标的像素数相对占比为0.01.
SODA数据集训练策略:在训练本文网络时,使用4个GPU,总batch_size为16,在NVIDIA GeForce RTX 2080Ti上进行训练.使用OHEM函数训练此网络,8×104次迭代,学习率为0.9,采用多项式衰减策略.为了增加稳定性,提高网络参数学习效果,图像预处理采用随机裁剪方案,裁剪大小480×480.此外,使用缩放尺度为0.5,1.0和2.0的多尺度方案,且在训练过程中未使用粗标注数据集.
SCUT_SEG数据集训练策略:训练协议参考文献[28].在训练过程中,本文仍然采用多项式衰减策略,初始学习率为0.05,并使用裁剪采样作为预处理,裁剪大小512×512,批标准化参数[3]在训练过程中进行微调.模型分别从零开始进行训练,迭代次数8×104.
STI-Cityscapes数据集训练策略:为了进一步排除实验的偶然性,在训练过程中对所有网络进行相同设置.优化器:为了保证训练过程中参数更新的准确率和运行时间的开销,选择使用SGD(stochastic gradient descent)作为网络训练的优化器,初始学习率为0.01,动量参数0.9,学习率采用ploy衰减策略.训练过程中,初始学习率与0.9·[1-t/(T-t)]相乘进行衰减,其中T和t分别表示总迭代步数和当前迭代步数.使用4个GPU,每个GPU的批尺寸设置为2.数据增强使用随机翻转、随机调整大小、随机裁剪等手段,其中随机调整大小的范围为(0.5,2.0),随机裁剪尺度为512×1 024.
2.3 SCUT_SEG数据集实验结果与可视化分析
首先在实验室的SCUT_SEG数据集上对各个算法的分割性能进行对比,结果如表1所示.其中包括UNet[29]、FCN-32s和FCN-16s[30]、DFN[31]、BiseNet[32]、PSPNet[11]、PSANet[33]、Deeplab-v3[34]、Deeplab-v3+[18]和MCNet[24].实验表明本文算法分割性能比目前最流行的热红外图像分割算法的分割性能略优,本文算法的mIoU达到了72.06%.与当前最新的算法MCNet、Deeplab-v3+和PSANet分割性能相比,本文算法的mIoU分别提高2.27,4.06和4.74个百分点.对比单个类别的IoU,可以发现:本文算法在保持其他类别分割性能的同时,可以提高边缘和小目标分割性能.从表1还可以看出,与其他算法的大部分类别的分割性能相比,本文算法都有提高.其中,与Deeplab-v3+相比,在行人、骑车的人以及柱子等小目标类别分割任务中,本文的IoU分别提高了3.05,4.40,6.71个百分点.与MCNet相比,在行人(person)、骑车的人(rider)、车(car)、树干(truck)、栏杆(fence)、树木(tree)、公共汽车(bus)、柱子(pole)等类别分割任务中的IoU分别提高 1.49,2.17,2.58,7.80,2.60,0.88,2.14,3.07 个百分点.
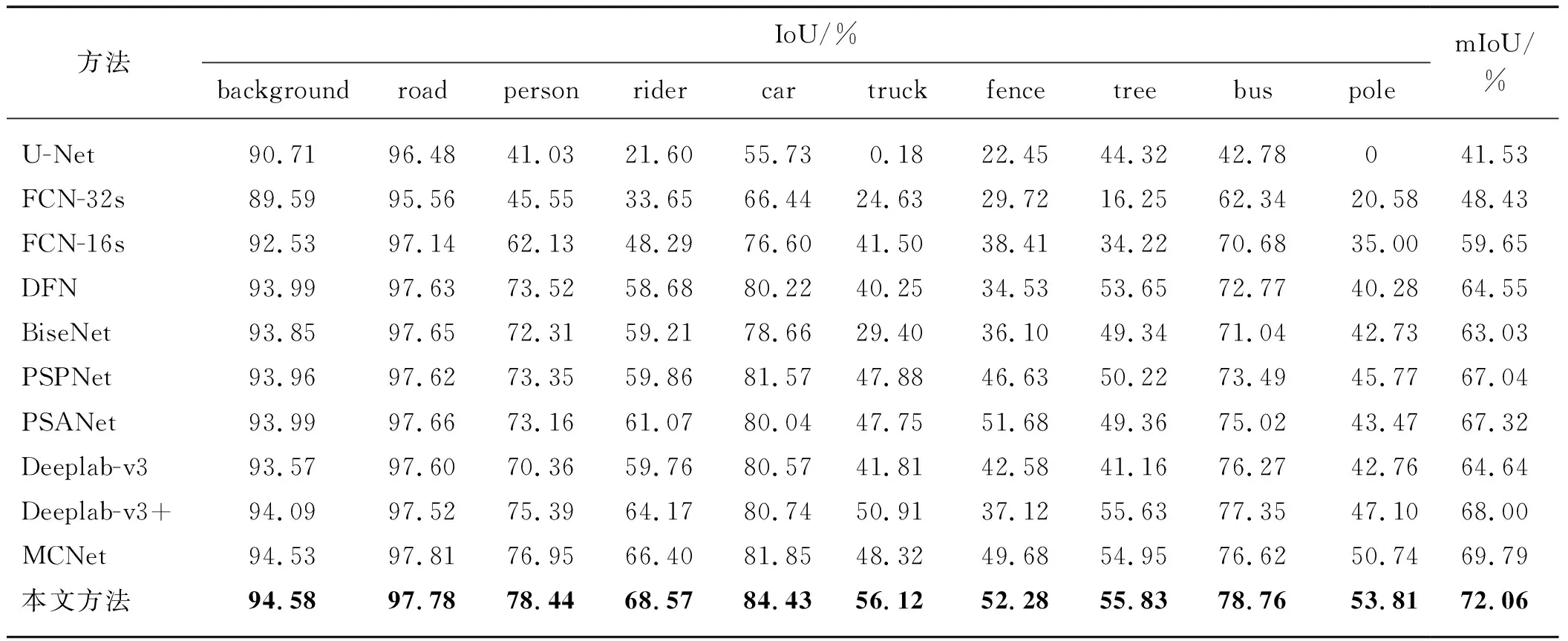
表1 基于scut_seg数据集最流行分割算法性能对比
1) 可视化结果分析:为了更进一步验证本文算法,用训练好的网络对SCUT_SEG数据集的大量图片进行预测并对部分分割结果进行了可视化分析,如图6所示.从给出的5张图片的结果可以看出,与Deeplab-v3、PSPNet、FCN相比,本文方法分割效果都略优.首先,与Deeplab-v3+相比,本文方法的分割效果在小目标和边缘等细节方面表现较好,边缘分割也更为清晰.图5(a)中的公交车前面的后视镜、路边的行人腿脚和树干的枝丫等细节的分割结果都表明本文算法的分割效果在视觉上明显好于FCN、Deeplab-v3+和PSPNet,其中FCN对近处大目标(公交车)的分割过于粗略,只能很粗糙的勾勒出其中一些目标的轮廓,甚至丢失了大部分目标的细节信息,易造成内部不连续现象.图5(b)和(c)中:虽然Deeplab-v3+算法较为细致的分割出各个类别,但是对于有些类别(远处的行人、树干与柱子等)的边界定位与检测存在缺陷,而本文提出的方法与之相比在细节上表现效果较好,特别是远处的行人、树干与柱子的边界.图5(d)和(e)中:FCN、PSPNet仍然只能粗略的分割出各个类别的目标;Deeplab-v3+算法分割结果中对于近处的行人手脚与树干的枝丫等细节出现黏连现象和部分像素类别产生混淆的现象;本文方法不仅增强了一些目标的边界像素的定位,还减轻了对近距离大目标类别像素的不连续易混淆现象.
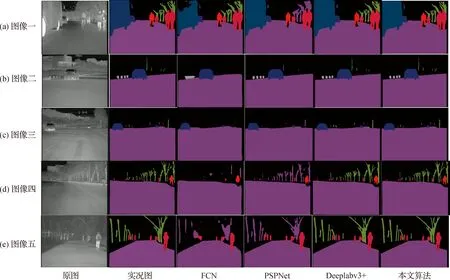
图6 各个算法可视化实验结果Fig.6 Visualization results of each algorithm
2) 边缘分割结果可视化分析:为了更为直观地对比本文算法的优势,本文对各个算法的实验结果进行了可视化.如图7和8所示.从其边缘可视化效果来看,与FCN分割的边缘相比,本文方法无论是较小物体分割还是较大物体分割都有一定改进效果,具体之处见图7中标红之处.在图7中公交车等大目标内分割不连续现象得到了缓解,树木等类别的边缘的噪声(斑点)等也被抑制,远处的行人等小目标细节也有所恢复.当与Deeplab-v3+边缘分割效果相比,本文方法对边缘和小目标等分割效果也略胜一筹,图中的行人与树干以及交通柱子等类别的分割具有更多的细节信息.具体见图8中标黄之处.

图7 FCN和本文算法边缘可视化效果Fig.7 Edge visualization results of FCN and ours

图8 Deeplabv3+与本文算法边缘可视化结果Fig.8 Edge visualization results of Deeplabv3+ and ours
3) 算法的各个部件可视化分析:为了更清楚地观测每个模块的特征输出结果,对本文各个模块的特征进行了可视化分析.如图9所示.图(a)~(f)分别为原图、与原图对应的实况图(ground truth,GT)、PAM模块的输出特征可视化结果、EEM模块输出的可视化结果、TTM模块输出结果以及最后特征的可视化结果.可以看出:PAM模块输出的特征含有丰富的细节信息,比如存在很多边、角和点等;EEM模块输出结果包含大量的边缘细节信息;TTM模块输出结果包含很多小目标信息特征;最终本文算法的输出结果(Output)具有清晰的边缘与小目标细节.

图9 我们算法各个组成部分可视化结果Fig.9 Visualization results of each components of our algorithm
4) 消融实验
(i) 与相近方法比较:表2为本文算法与当前最相关算法的性能比较,其中FLOPS为每秒浮点运算次数,实验表明本文算法性能最优.相比于DCN[35]、GCN[36]、PSANet[33]和 MCNet[24],本文算法仅在增加少量计算量的前提下,mIoU分别提高了2.26,1.90,4.47,2.27个百分点.
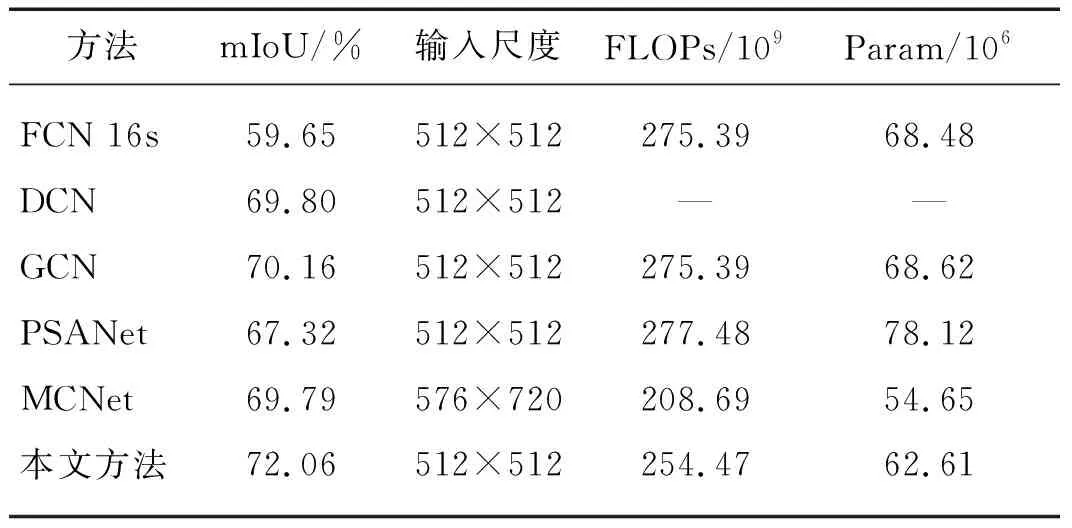
表2 最相近方法比较
(ii) 基于基线模型的改进:为了证明本文模块可以适应不同的基线模型,选择了FCN[30]作为消融实验的基线,并分别使用ResNet50和ResNet101作为主干.如表3所示,当主干网络为ResNet50时,在基线模型的基础上分别嵌入本文提出的EEM模块和TTM模块,其分割性能都略有提高,分别提高了0.49和1.59个百分点,当同时嵌入TTM和EEM模块后,其分割性能提高了3.02个百分点.当主干网络为ResNet101的基线模型时,同时嵌入TTM和EEM模块后,其分割性能提升了3.87个百分点.由表3可以看出:基于ResNet101的模型比ResNet50的模型仅高出了1.21个百分点,说明网络达到一定层数时,其性能的提升和网络层的深度未成线性正比.ResNet50+EEM+TTM的分割性能为70.03%,比ResNet101+ASPP的分割性能67.37%高2.66个百分点,这说明网络增益不仅来自于主干网络深度的加深,而且还来自于本文中设计增加的模块EEM和TTM.

表3 基于基线模型的改进
(iii) 不同损失函数对分割性能的影响:本文基于FCN,选择不同损失函数对其进行消融实验,实验结果如表4所示.本文发现如果仅用边缘损失对图像分割任务进行监督,分割性能仅相对于Lseg提高了0.6个百分点,边缘特征增强虽然可以通过去除边缘噪音来增强边缘分割效果,但边缘像素数量占比较少,导致其分割效果提高并不明显.但在Lseg的基础上增加边缘特征对图像分割任务进行监督,分割性能有了较明显的提高.当对边缘使用二值交差熵函数Ledge-bce和交差熵损失函数Ledge-ohem对图像分割任务进行监督时,分割性能提高了1.4和1.9个百分点.

表4 基于不同损失函数分割的消融实验
2.4 其他数据集实验结果
表5和表6仅为使用SODA精标数据集得的实验结果.从表5中可以看出:使用FCN[30]、PSPNet[11]、Deeplab-v3+[18]3种目前最广泛的语义分割算法得到最好的分割精度也只有46.2%、54.9%、61.2%,而本文提出的算法分割精度达到66.8%.相对于主干网络采用ResNet50,采用ResNet101时,PsPNet[11]、GCNet[36]、Deeplab-v3+[18]3种分割算法性能更好.为了更详细的分析本文算法与其他算法对各个类别上的分割性能,本文在SODA数据上选择了12种算法进行对比实验,其结果如表6.由表6可知,现有最好的热红外图像分割算法EC-CNN的分割精度为63.64%,低于本文算法分割精度3.16个百分点;与U-Net[29]、DFANet[37]、FCN-16s和 FCN-32s[30]、GCN[36]、Deeplab-v2[12]、DeepLab-v3[34]、DUC[38]、DT-EdgeNet[39]、ERFNet[40]、DFN[31]、EC-CNN[23]相比,本文算法在保持其他类别分割性能的基础上,对杆﹑自行车﹑监视器﹑交通锥标等小目标类别的性能都有显著提高.
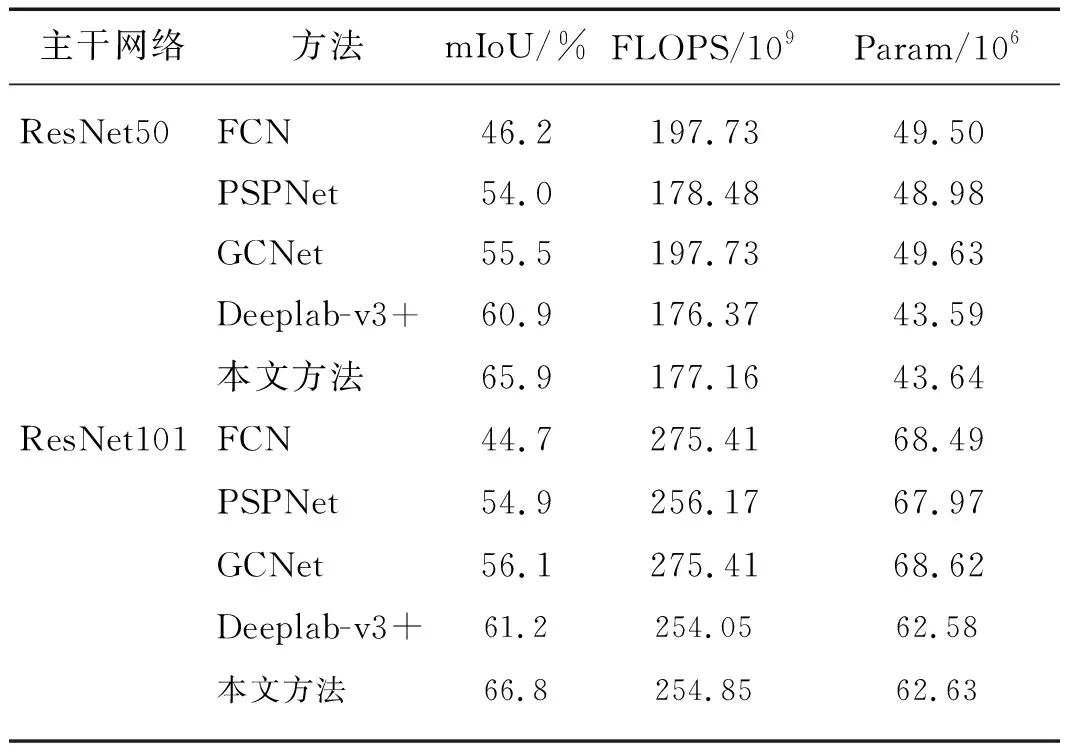
表5 本文算法基于SODA数据集与最流行算法分割性能的对比
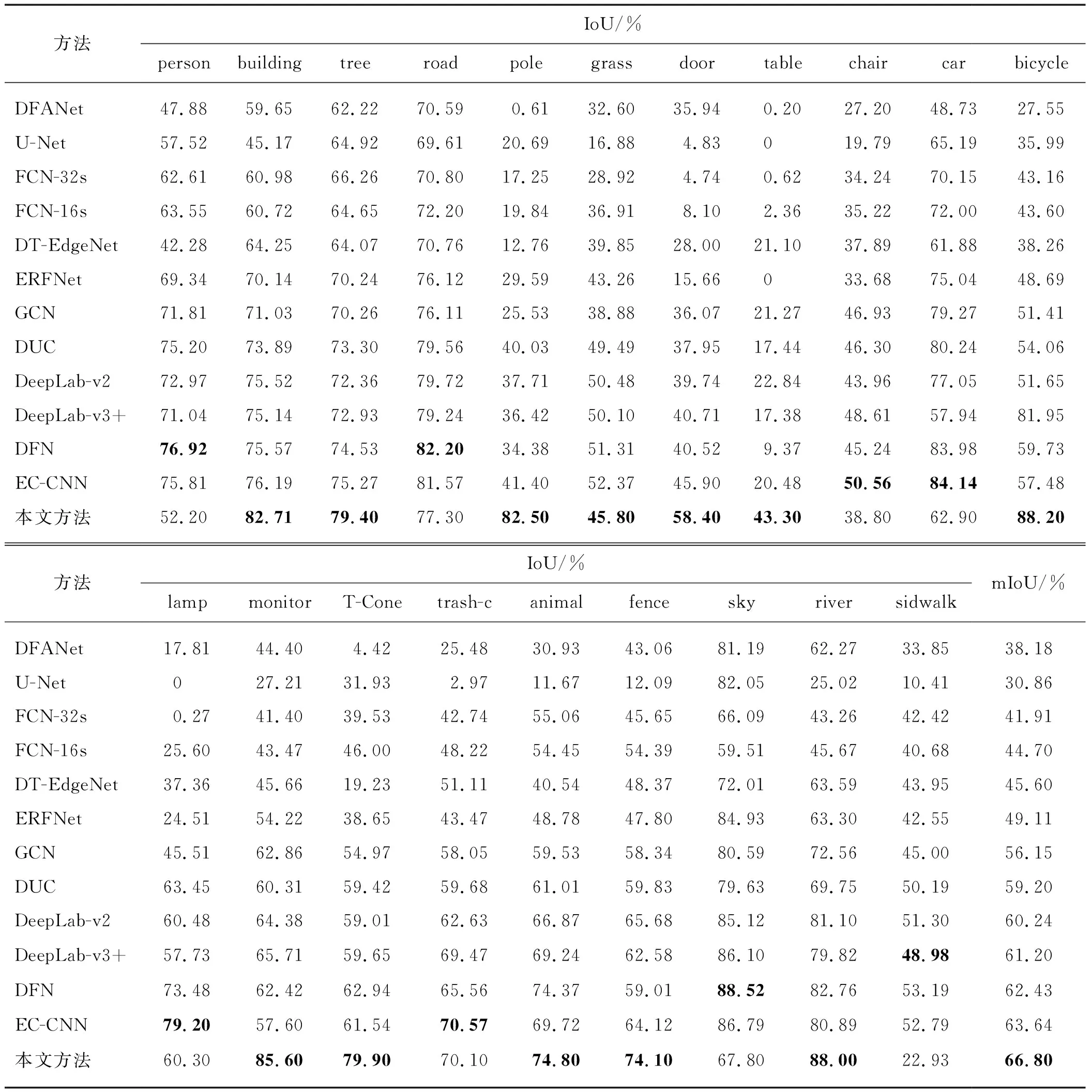
表6 基于SODA数据集最流行算法各个类别分割性能的对比
表7是本文在STI-Cityscapes热红外数据集上进行对比实验的结果.当分别采用ResNet50和ResNet101作为主干网络时,本文方法比FCN的分割精度分别高7.50和5.16个百分点左右.即使与最流行的分割算法PSPNet[18]、Deeplab-v3+[11]和MCNet[24]相比,本文的算法分割精度也略有提升,分别提高了2.96,0.73和12.87个百分点(ResNet101主干网络).
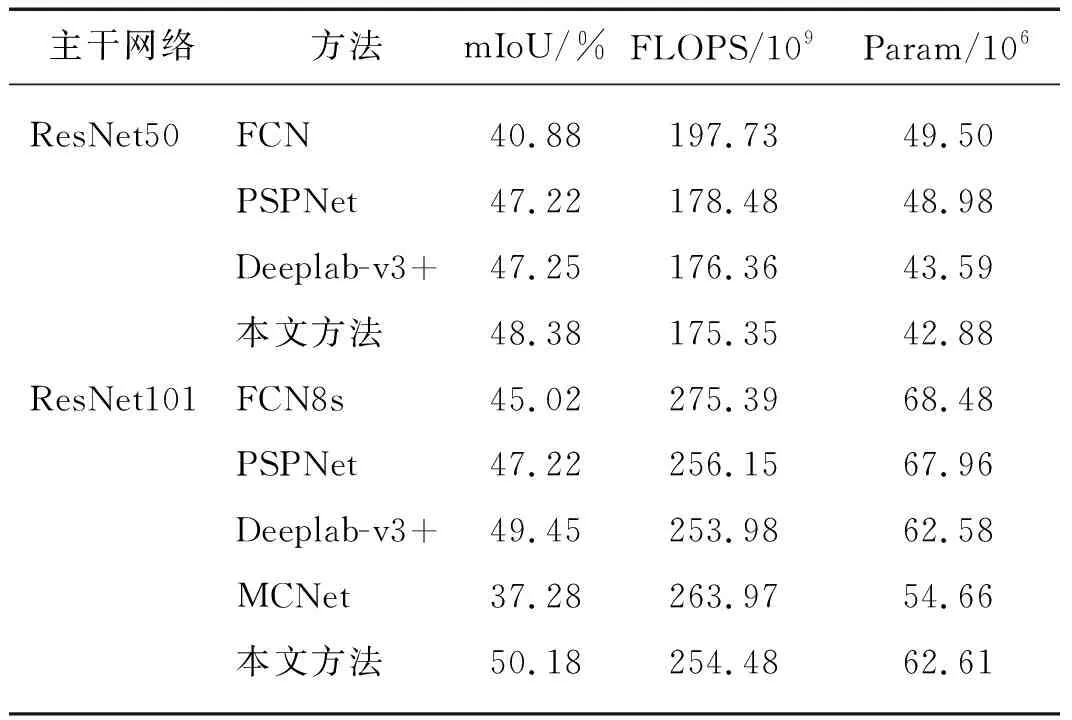
表7 基于STI-Cityscapes合成热红外数据集各个算法分割性能对比
3 总 结
实验结果表明,现有的语义图像分割算法应用在热红外图像的分割过程中,存在着小目标与边缘等细节丢失的问题.在基于卷积神经网络的语义分割方法中,由于强度﹑形状和纹理等特征混杂,不利于小目标及目标轮廓附近像素的分割.而网络为了获得较强语义信息,层层堆叠导致特征丢失大量细节信息.在SCUT_SEG、SODA和STI-Cityscapes等3个热红外数据集上,本文提出的算法无论是在具体目标类别的分割精度上,还是在小目标与边缘等细节的分割效果上,相对于对比算法均表现出最优的分割效果.结果表明:本文设计的强化外轮廓﹑弱化内轮廓的带有矫正的边缘增强模块有利于获取目标边界信息,提高边缘分割精度.
本文的主要贡献:1) 提出了基于编码-解码的小目标与边缘增强热图像语义分割算法.在编码-解码的基础上,充分利用主干网络各层特征,把高层图像特征中较强的语义信息传导至底层图像,再通过图像边缘特征和小目标特征增强算法提高其预测精度来弥补主干网络中丢失的边缘和小目标等细节信息,本文算法最高分割精度mIoU达到了72.06%(SCUT_SEG数据集),其性能较目前最新分割算法MCNet提升了2.27个百分点.2) 设计了多级像素空间注意模块(MPAM).MPAM模块通过多级引导过程把高层语义信息的类间和类内的关联性不断传导到相邻低层级.在各级中结合精确的上下文信息和先验知识来修正.最后在底层级得到具有较强语义信息的图像特征.3) 为了增强边缘特征的语义信息,设计了一种新的边缘特征增强模块EEM,并且获取的边缘特征含有语义类别信息.4) 为了增强小目标特征的语义信息,设计了一种新的小目标特征提取模块TTM,并且获取的小目标特征含有语义类别信息.5) 最后设计了专门的损失函数对其进行监督训练来提高各类别边缘相交区域和小目标像素点的预测精度.然后把训练后的边缘和小目标特征与主干网络的分割特征相融合,弥补主干网络中丢失的边缘和小目标等细节信息.
