融合音节部件特征的藏文命名实体识别方法
2022-07-15洛桑嘎登索南尖措仁增多杰
洛桑嘎登,群 诺,索南尖措,仁增多杰
(西藏大学信息科学技术学院,西藏 拉萨 850000)
命名实体识别(NER)是自然语言处理的基础任务[1].NER被广泛应用于下游的自然语言处理任务中,如机器翻译、构建知识图谱、智能问答系统、信息抽取、信息检索等[2].最早的NER方法是基于规则和词典匹配的NER方法以及基于统计机器学习的NER方法.随着计算机算法、计算能力、数据规模的不断发展,深度学习方法在自然语言处理领域大放异彩,在NER任务中取得了很好的成绩.
可实现NER的深度神经网络模型包括双向长短时-条件随机场(BiLSTM-CRF)模型、BERT(bidirectional encoder representation from Transformers)-CRF模型以及双向门控循环单元(BiGRU)模型等.在面向英语的NER任务中,融入字符信息的BiLSTM-CRF模型取得了最好的结果[3].在面向汉语的NER任务中,为了解决汉语词边界难以区分的问题,常在模型的输入端结合词典信息或改变网络的结构以适应汉语的NER任务[4-9].最近被提出的FLAT(flat-lattice Transformer)[10]方法,以BiLSTM-CRF为基准模型,融合汉语词典信息,在汉语NER的一个简历数据集上F1达到了94.93%.
藏语NER不同于以上两种,藏语句子中词语之间不仅没有明显的分隔符,还存在黏着词的特性,导致藏语NER任务相对复杂.藏语NER方法包括了传统的基于统计机器学习的方法和通过词嵌入或字(音节)嵌入方式的深度神经网络方法.
最早,华却才让等[11]提出一种基于音节特征感知机训练模型,重点研究了利用藏文紧缩格识别音节的方法,F1值达到了86.03%.珠杰等[12]利用CRF方法研究藏文人名的自动识别,并利用格助词等信息进行后处理,藏文人名识别率达到80%左右.加羊吉等[13]提出了基于规则和CRF相结合的藏文人名识别方法,F1值达到了91.55%.头旦才让等[14]实现了基于CRF的藏文地名实体识别,F1值达到了88.45%.王志娟等[15]为了降低藏文人名实体识别语料标注成本,提出基于置信度的藏文人名识别主动学习模型.贡保才让[16]实现了基于单个音节(字)的深度神经网络藏文NER.李晓敏[17]研究了基于深度学习的藏文NER方法,所提出的改进的IDCNN(iterated dilated CNN)-CRF模型在藏文NER中F1值达到了80.16%.藏文NER不适合用BERT和Tansformer等模型,这是因为目前藏文NER的语料量有限,远远达不到复杂模型需要的百万级的数据量,采用复杂的网络容易造成过拟合的问题.
藏文与英语和汉语相比,藏文词语之间没有明显的分隔符,词语边界不清晰,存在黏着词的特性[18],这是藏文NER的主要难点.传统的词嵌入方法没法表征一词多义的问题,而简单的字(音节)嵌入,容易忽略构成藏文音节部件的局部特征,如黏着词的信息等.
针对以上问题,本文首次提出了一种融合构成藏文音节部件和音节特征的藏文NER神经网络模型SL-BiLSTM-CRF(syllable level BiLSTM-CRF).该模型将构成藏文字(音节)的部件信息和藏文音节特征作为两种不同模态的输入,融合两种模态作为NER神经网络的输入.这样模型可以充分提取构成藏文音节的局部特征,包括黏着词的特征,从而提高模型的预测能力.
1 SL-BiLSTM-CRF
藏文NER需要解决两个问题.1) 确定表示实体词语的边界,包括带有黏着词的实体词边界.2) 对实体进行分类,即判断实体属于哪种类型.本文首次提出了一种融合构成藏文音节部件特征的藏文NER神经网络模型SL-BiLSTM-CRF,模型整体架构如下.
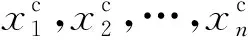

图1 SL-BiLSTM-CRF 网络架构Fig.1 SL-BiLSTM-CRF neural architecture
1.1 藏文音节特征表征层
在英文NER中,因为英文词与词之间有明显的分隔符(空格),所以英文NER任务实质上是一种分类任务,其难点在如何提取英文命名实体特有的特征,比如大小写特征等.在汉语NER任务中,汉语的词语之间没有明显的分隔符,一般先对汉语句子进行分词之后再识别实体并分类[19].藏语NER不同于以上两种,藏语句子中词语之间不仅没有明显的分隔符,还存在黏着词的特性,导致藏语NER任务相对复杂.目前,有学者借助汉语NER的思想,先对藏文句子进行分词再识别实体,但是这类方法存在错误传播的问题.
藏文的每个音节由前加字、基字、上加字、下加字、后加字、再后加字和元音7部分按照一定的规则组成.但是藏文与汉语不同的是藏文是一种拼音文字,藏文中存在黏着词的特性,有些实体词以黏着词的形式出现在文本中,例如:


图2 SL融合Fig.1 SL fusion
上图中Vc∈Rn是指藏文音节部件的特征信息,Vs∈Rm是指单个音节的特征信息,V∈Rk表示融合后的特征向量.n、m、k=n+m分别表示Vc、Vs和V的特征维度.其中,Vc是通过对每个藏文音节嵌入成8位独热编码,作为一个单层BiLSTM模型的输入,在输出门的隐藏层输出一个128维的特征向量.Vs通过将一个句子中的20个单音节作为BiLSTM的输入,得到一个128维的隐藏层特征向量,将两种特征向量进行连接,作为整个藏文NER模块中的BiLSTM层的输入.此时,输入整个藏文NER模块中的BiLSTM层的特征向量不仅包含有单个音节在句子中的特征信息,还包含了该音节的构成部件的特征.相比传统的基于单个音节(字嵌入)的模型,该模型学习了构成音节部件的局部特征,而藏文的黏着词作为构成音节的一个局部信息,被模型成功的学习到,从而提升实体类型预测的效果.
1.2 BiLSTM层
BiLSTM模型是前向LSTM模型和后向LSTM模型的结合,其克服了单向LSTM模型只能考虑之前出现的信息,而无法考虑上下文信息的弊端.从上文可发现,本文共有3个BiLSTM模块,分别负责提取构成音节部件特征、音节特征和预测实体标记.对于每个模块经过BiLSTM得到3个不同的隐藏层输出:
Ot=σ(wi·Vt+bi),
ht=Ot·tanh(ct),
(1)
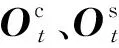
1.3 CRF层
BiLSTM模型层,尽管能算出当前词的标签概率,但是没有考虑相邻标记之间的转移概率.这样有可能出现预测的前一个标签为O,接着下一个标签预测成I-PER.显然这样的预测顺序是不合理的.为了让模型充分考虑相邻标签之间的关系,采用CRF模型.设一个藏文句子x={x1,x2,…,xn},把x={x1,x2,…,xn}当作观测序列,记一个与观测序列等长的标签序列y={y1,y2,…,yn},把y={y1,y2,…,yn} 当做状态序列,用Tyi,yi+1表示从状态yi到状态yi+1的转移分数,hxi,yi表示从第i个观测序列xi到标签yi的发射分数.那么模型针对给定的句子x,预测出序列y的得分公式为:
(2)
其中,S(x,y)表示给定观测序列x预测出标签序列y的得分.发射分数hxi,yi其实就是上节中预测实体标记的BiLSTM层模型的隐藏层输出的第i个元素.转移分数Tyi,yi+1则由CRF层训练得到.进而利用Softmax归一化之后,得到最终的实体标签的概率为:
(3)
2 实验对比
2.1 实验设计
为了验证SL-BiLSTM-CRF模型中SL层在藏文NER任务中的有效性,本文与单个藏文音节(字嵌入)的BiLSTM-CRF模型进行了对比实验,同时验证SL-BiLSTM-CRF模型在同类NER模型中的优势,在标注语料不变的前提下,与在藏文NER任务中取得了不错效果的统计机器学习模型HMM和CRF,以及BERT-CRF模型进行对比.
2.2 数据和评价指标
本文研究所用数据均通过网络获取,通过爬虫技术抓取数据、清洗数据、人工矫正等步骤,总共收集了近5×104的句对,包含藏文字符数约5×105.语料均来自公开的藏文网站、博客等.实验语料中的标签设置为B-PER、I-PER、B-ORG、I-ORG、B-LOC、I- LOC和O,分别代表人名首字、人名非首字、组织机构名首字、组织机构名非首字、地名首字、地名非首字和该字不属于命名实体.为了调节模型中超参数和获得更好的近似估计模型的泛化能力,把语料按照6∶2∶2的比例进行训练集、验证集和测试集的划分,具体大小及各实体个数如表1所示.本文中选取精确率(P)、召回率(R)和F1值作为模型的评价指标.

表1 训练和验证集的数据统计
2.3 模型训练
模型使用学习率为0.001的Adam优化算法,训练集次数epoch设置为50次.音节部件的表征编码维度设置为8,完整音节的编码维度为100.在BiLSTM 的输入和输出部分使用了采样概率为0.5的dropout层,以避免训练时过拟合.操作系统环境为Windows 10.深度学习框架使用Python开源库Pytorch 1.8.1版本.
2.4 实验结果与分析
为了证明融入音节特征可以有效提高BiLSTM-CRF模型的NER效果,在相同的标注语料上,本文对比了SL-BiLSTM-CRF模型与单个藏文音节(字嵌入)的BiLSTM-CRF模型在NER任务中的效果,实验结果如表2所示.

表2 两种模型的效果
如表2所示,本文提出的SL-BiLSTM-CRF模型融入了构成藏文音节部件的信息之后,模型比传统的基于音节(字嵌入)的方法精确率、召回率、F1值均提高了2.64,0.66和1.58个百分点.这是因为融入了藏文音节部件信息之后,模型学到了构成藏文音节的局部特征,从而学习到了音节中黏着词的特征,因此对实体边界的区分更加准确,从而提升了实体识别的效果.
同时,本文将该方法和目前在藏文NER领域取得不错成绩的传统统计机器学习方法和基于BERT-CRF的预训练模型进行了对比实验,实验结果如表3所示.

表3 各类模型的效果
如表3所示,SL-BiLSTM-CRF方法与传统的统计机器学习方法相比,模型的精确率、召回率、F1值都有较高的提升.其中:相比于HMM模型,SL-BiLSTM-CRF的F1值提高了12.88个百分点;相比于CRF,F1值提高了5.80个百分点;相比于BERT-CRF,F1值提高了4.49个百分点,在藏文的NER任务上,BERT-CRF模型的性能低于SL-BiLSTM-CRF的原因可能在于:1) 本文引入了音节特征;2) 本文的数据量对于BERT这类需要百万级数据量的模型来说还不够。表4分析了不同模型在不同实体上的精确率、召回率和F1值.
从表4可以看出,在3个实体中,人名(PER)的精确率、召回率、F1值相对较高,这个可能和大多数新闻语料中提及的人名为政治人物或公众人物,这类人物相对来说具有一定的规范性,而且写法相对统一,所以效果更好些.地名(LOC)和组织机构名(ORG)的精确率、召回率和F1值偏低.分析结果发现,地名和组织机构名之间存在多种嵌套,如图2所示,例子中“青海”一词即是地名也是组织机构名“青海师范大学”的一部分,这类错误导致了地名和组织机构名分类不准确的问题.

表4 不同模型在3种实体识别上的性能对比

图2 实体嵌套的例子Fig.2 Examples of entity nested
3 总 结
因为藏文词语边界不清晰,存在黏着词的特征,导致藏文分词困难,易忽略音节局部特征,本文提出一种融合藏文音节部件信息和藏文音节信息的藏文深度神经网络NER方法SL-BiLSTM-CRF.其中,SL模块对构成音节的部件信息和藏文的单个音节进行特征编码,将两种不同模态的特征融合之后送入BiLSTM模型进行特征提取并预测实体标签,再通过CRF对BiLSTM模型的预测结果进行矫正,最终输出藏文NER结果.在藏文NER任务中,对比基于单个藏文音节(字嵌入)的BiLSTM-CRF模型,SL-BiLSTM-CRF模型融入音节特征可以有效提高藏文NER的性能.与之前在藏文NER任务上取得不错效果的HMM、CRF和BERT-CRF相比,由于SL-BiLSTM-CRF加入了藏文音节部件信息的表征向量,在低资源的情况下,仍能取得较明显的性能优势.
相比于词向量作为网络的输入,基于音节(字)向量的输入可以避免在训练词向量时依赖分词结果的准确性,避免了分词任务的错误传播到NER任务中.但是,单独基于音节(字)向量的输入容易忽略音节的局部特征.本文将音节部件信息特征和音节(字)向量信息的表征共同作为网络的输入有效改善了以上问题,这也给处理藏文的其他自然语言任务提供了新的思路.当然,本文实验部分仅考虑了单个命名实体的标注结果,没有考虑在日常文档中存在的实体名称嵌套的问题,实体名称嵌套是一种很常见的文本现象,下一步本文需要进一步去研究探讨,如何解决实体名称嵌套的问题.此外,本文提出的方法仅在NER任务上做了实验研究,下一步在其他任务上是否也有类似的表现值得研究.
