深度学习行人检测方法综述
2022-07-15罗艳张重阳田永鸿郭捷孙军
罗艳,张重阳*,田永鸿,郭捷,孙军
1.上海交通大学电子信息与电气工程学院,上海 200240;2.北京大学信息科学技术学院,北京 100871;3.上海交通大学网络空间安全学院,上海 200240
0 引 言
行人检测是计算机视觉中的一个基本任务,主要研究从图像或者图像序列中准确识别并定位行人目标。当前,行人检测技术不仅广泛应用于智能交通系统和智能安防监控等多种实际场景,而且作为技术支撑,为人体行为识别和人体动作理解等研究热点提供理论基础。因此,探索更加高效的行人检测技术具有重要的实际应用价值和学术意义。
在深度学习兴起前,行人检测主要依赖于手工设计的特征进行目标表征,常用的特征提取算子包括结合了人体运动和外观模式的Haar小波特征(Papageorgiou和Poggio,2000),运用边缘方向信息描述行人轮廓的梯度方向直方图(histogram of oriented gradient,HOG)特征(Dalal和Triggs,2005),具有灰度不变性以及旋转不变性的LBP(local binary pattern)特征(Ojala等,2002),以及具有尺度不变性的结构性特征(scale-invariant feature transfor-mation,SIFT)(Lowe,2004)。以上手工特征的核心是利用人工设计针对特定任务的图像特征描述算子来帮助区分目标位置或目标类别。这些手工特征相对而言比较简单并且易于使用,但是也具有明显的局限性。1)手工特征主要利用行人外观等浅层信息作为判断依据,容易误检;2)手工特征较难适应视角不同、相互遮挡和姿态变化的行人目标,由此会导致大量漏检。因此传统的基于手工特征的行人检测方法很难适应当前的高精度高效率行人检测应用需求,研究者将目光转向了基于深度学习的行人检测方法。
深度学习模型在当前的目标检测中处于主流地位,与前述的手工特征不同,基于卷积神经网络的深度学习方法通过构建多层网络学习隐含在数据内部的关系,从而使得学习到的特征具有更强的表征和泛化能力。随着深度学习技术的不断发展,行人检测作为通用目标检测的重要分支引起了学术界和工业界的广泛关注。在简单无遮挡场景下,学者将通用目标检测模型,如基于锚点的两阶段检测器Faster R-CNN(region-based convolutional neural network)(Ren等,2017)和基于锚点的单阶段检测器SSD(single shot multibox detector)(Liu等,2016),直接应用于行人检测已经取得了良好的性能。但是在实际应用中,行人检测依然面临严峻挑战,主要体现在以下两个方面:1)遮挡问题。在智能监控和无人驾驶等真实场景中,图像中行人目标遮挡的情况通常难以避免。一般而言,遮挡可以分为两类:(1)行人目标与场景物体间的遮挡(例如行人与街边树木栏杆、道路车辆等相互遮挡),即人与物之间的遮挡;(2)行人目标之间的相互遮挡,即人与人之间的遮挡。以上两种遮挡情况均对行人的整体结构特征造成破坏,并且由于遮挡模式的多样性,导致通用的数据驱动的检测器难以学习一致的遮挡行人目标特征。所以往往需要设计独立的模块用以提高模型对遮挡行人的表征能力,从而有效降低漏检率。2)尺度变化问题。在行人检测中,距离摄像头较近的行人目标往往在图像中呈现较大的尺寸,而距离摄像头较远的行人目标往往尺寸较小。因此,在待检测的图像或图像序列中往往存在尺度不一致的行人目标。这种尺度不一致性会带来两个问题:(1)小尺度目标有用信息较少,很难精准检测;(2)大尺度目标与小尺度目标特征差异较大,例如大尺度行人目标往往具有清晰的纹理特征以及骨架信息,而小尺度行人目标只具有模糊的轮廓信息,因此较难对不同尺度的目标设计统一的特征处理策略。
围绕上述面临的问题与挑战,本文以基于深度学习的行人检测技术为研究对象,对不同行人检测算法的原理、适用场景以及优缺点进行了详细分析,同时介绍了行人检测通用数据集以及不同算法的实验结果,并对行人检测领域未来可能的发展方向进行展望。
1 基于锚点框的行人检测
基于锚点框的目标检测(例如Faster R-CNN和SSD)是当前较为成熟并且应用较为广泛的一类算法,该方法利用数据集的先验信息设置一系列大小形状不同的锚点框,并利用卷积神经网络对锚点框进一步分类与回归,得到最终的行人检测结果。根据研究思路及针对问题的不同,本文将基于锚点框的主流行人检测方法分为基于行人部位的方法、基于行人整体与部位加权的方法以及基于级联的方法。
1.1 基于行人部位的方法
基于行人部位的方法是处理遮挡行人检测问题最常见也是非常有效的一类方法。该方法利用遮挡行人可见部位判断行人是否存在。从部位检测的角度,该类方法分为基于部位检测器的方法和基于注意力机制的方法。
1.1.1 基于部位检测器的方法
基于部位检测器的方法往往是通过已训练好的人体关键点或部位检测网络简单有效地识别遮挡行人可见身体部位。Xu等人(2019)提出了一种提取行人特定部位信息的网络结构,如图1所示,图中FC(fully connected network)表示全连接网络。该算法通过人体关键点检测网络识别每个行人目标的6种关键节点,包括头部、上身、手臂、腿部等,并利用关键节点重建相应的部位信息。将含有特定语义的部位信息进行整合,即得到最终更加鲁棒的行人特征表达。研究结果表明,该方案直观有效,对于提升检测器的抗遮挡性能有明显效果。但是缺点也显而易见,一是此类方法需要额外的部位标注训练人体关键点或部位检测网络;二是依赖数据驱动的部位检测器往往难以适配遮挡模式的多变。因此,如何降低部位检测器的计算成本,以及如何更有效地利用部位检测器仍然是一个值得探索的问题。
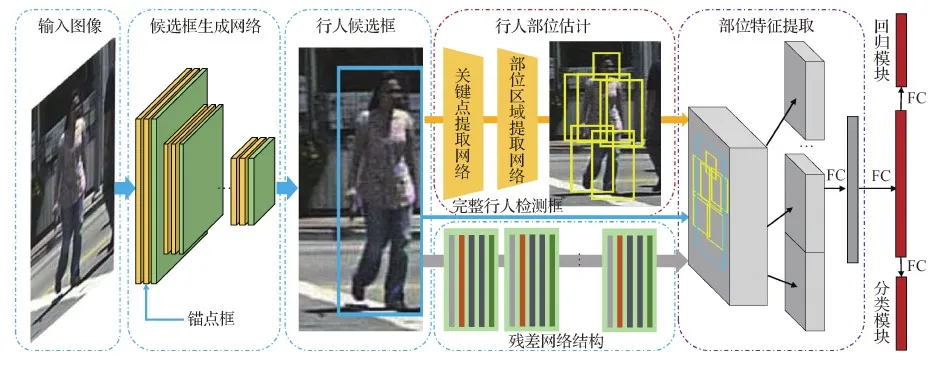
图1 基于部位检测器的行人检测框架图(Xu等,2019)Fig.1 Framework of pedestrian detection based on part detector (Xu et al.,2019)
近年来,研究者发现可以将基于统计的部位模型直接与卷积神经网络特征相结合,从而有效减少部位检测所需时间,典型的部位模型如图2所示,图中数值表示该区域为行人部位的概率值。Zhang等人(2018a)构建了由5种行人部位组成的部位模型,并通过卷积神经网络度量各个部位可见度,最后综合所有部位的可见得分,得到整体行人的检测结果。这种方法的局限性在于,使用的部位往往是人工定义的,而行人遮挡的类型理论上有无穷多种,尽管可以定义主要的遮挡模式近似表示,但仍然难以达到最优。这种局限性也促使研究者探讨是否存在行之有效的方法可以避免复杂的部位检测网络,同时保证遮挡行人的检测精度。
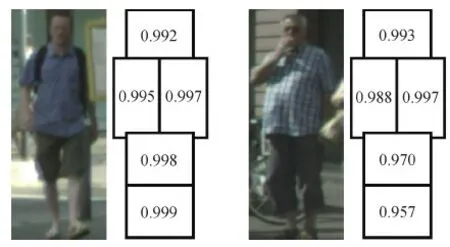
图2 基于部位模型的行人检测(Zhang等,2018a)Fig.2 Pedestrian detection based on part model(Zhang et al.,2018a)
1.1.2 基于注意力机制的方法
与部位检测器时间开销大、数据依赖程度高不同,基于注意力机制的方法以弱监督的方式自适应地引导行人检测网络更多地关注遮挡行人的可见部位。Zhang等人(2018b)发现特征图的不同通道可以用来感知行人不同的身体部位,由此提出了基于通道注意力的行人检测网络。该网络针对性地加权原始通道特征图,建立选择注意力机制,使遮挡行人可见身体部位对应的通道获得更高的权重,以此降低遮挡噪声对行人检测器的干扰,提升遮挡行人的检测精度。与之类似,Pang等人(2019)提出利用行人的可见身体部位构建逐像素的空间注意力模块MGAN(mask-guided attention network),如图3所示。该模块通过空间掩膜引导检测器重点关注行人可见的身体区域,同时一定程度上降低行人的遮挡部分的特征权重,以此获得更加鲁棒的特征。

图3 基于注意力机制的行人检测(Pang等,2019)Fig.3 Pedestrian detection based on attention mechanism (Pang et al.,2019)
以上两种典型的基于注意力机制的行人检测方法尝试从不同角度解决遮挡行人检测问题。通道注意力机制聚焦在“什么”是有价值的特征,为了有效计算通道注意力,往往需要对输入特征的空间维度进行压缩。空间注意力更聚焦于“哪里”是最具有信息量的部分,这是对通道注意力的有效补充。因此,如何融合不同的注意力机制,如何合理地提升行人特征的表达能力,也是值得进一步探讨的问题。
1.2 基于行人整体与部位加权的方法
基于部位的行人检测方法较为有效地降低了遮挡行人漏检率,但是由于过于依赖局部(部位)特征,导致对结构形似行人部位的背景目标产生误检。例如,主体结构形似行人躯干的树干、形状形似行人头部的路灯等。显然,仅基于行人部位的检测算法较难满足实际应用的需求。因此,研究者提出了基于行人整体(全局特征)与部位(局部特征)加权的方法,旨在同时保证遮挡行人的低漏检率以及无遮挡行人的低误检率。Zhou和Yuan(2018)提出了一种典型的基于该方法的行人检测框架BiBox,如图4所示。

图4 基于整体与部位加权的行人检测(Zhou等,2019)Fig.4 Pedestrian detection based on re-weighting between full-body and parts (Zhou et al.,2019)
BiBox利用一个网络同时进行整体行人检测和遮挡估计,具体而言就是在同一网络中设计并行的两条分支,分别输出两组预测框用以表征整体行人目标以及行人可见部分。该方法显著提高了遮挡及无遮挡检测精度,但是代价也显而易见,即需要数据集额外标注出行人目标的可见部分用于网络训练,故该方法无法在没有可见部分标注的数据集上使用。
Chi等人(2020b)、Lin等人(2019)和Zhang等人(2019)提出了基于行人头部特征与行人整体特征融合的检测算法。此类检测算法主要基于两点考虑:一是在遮挡场景下,头部特征往往具有较好的辨别性,因此可以有效改善遮挡行人检测性能;二是行人整体特征包含较多的上下文信息,可以有效降低过于依赖头部特征而导致误检,算法流程如图5所示。
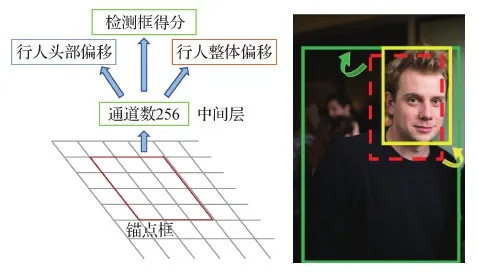
图5 基于行人头部与整体加权的检测网络(Zhang等,2019)Fig.5 Pedestrian detection based on joint learning of head and full-body features (Zhang et al.,2019)
此类方法通过对行人头部和全身同时进行检测,直观有效地缓解了行人检测中的遮挡问题,但仍存在局限性:一是与BiBox类似,需要额外的头部标注框,无法适用于没有额外标注的数据集;二是此类方法往往是通过双支并行的结构分别预测部位及整体检测框,因此计算量增大,时间复杂度较高,处理效率差强人意。对此类方法而言,如何保证较高的行人检测准确率,同时保证较为有效的处理速度,仍是亟待解决的问题。
1.3 基于级联的方法
近年来,主流的行人检测算法多基于通用的目标检测框架,因此也面临与通用目标检测相似的两个问题。1)训练阶段的候选框与测试阶段不一致。在训练阶段,检测器可以依据标签将交并比(interse-ction over union,IoU)大于某一阈值(例如0.5)的候选框作为正样本用于训练分类网络及回归网络,因此候选框质量往往较高。而在测试阶段,由于缺少真值标签,所有候选框均参与分类与回归过程,此时候选框质量往往较低。这种训练与测试候选框分布不一致的情况通常会影响检测器的检测精度(Cai和Vasconcelos,2018)。2)难以为候选框设置合适的交并比阈值。一方面,较高的交并比阈值固然可以获得高质量的候选框,但是检测器也面临候选框过少、过拟合等风险;同时,过度提高交并比阈值会加剧上述的不匹配问题;另一方面,较低的交并比阈值会增加大量低质量的候选框,并不利于检测器的训练。如图6所示,其中u为交并比阈值,AP为平均精度,一味地提高交并比阈值反而会导致检测性能降低。
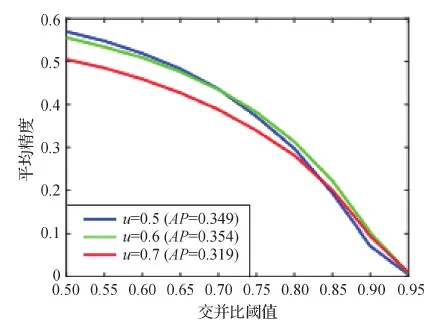
图6 不同交并比阈值对检测性能的影响(Cai和Vasconcelos,2018)Fig.6 Performance of different IoU (Cai and Vasconcelos,2018)
目前,如何缓解检测框架中的不匹配问题,如何为候选框设置合理的交并比阈值,也是研究者广泛探讨的热点问题之一。研究者认为,单一的阈值无法适应候选框的变化(Cai和Vasconcelos,2018),由此引入了基于级联(设置多种交并比阈值)的检测方法。本文将基于级联的行人检测方法分为基于两阶段检测器的级联方法和基于单阶段检测器的级联方法两类。
1.3.1 基于两阶段检测器的级联方法
两阶段的检测器是指检测算法包含候选框产生和候选框修正两个阶段。以两阶段Faster R-CNN网络为例,候选框通过RPN(region proposal network)模块产生,并经过R-CNN模块进行修正,由此得到更加精确的检测结果。本文首先介绍一种典型的基于两阶段检测器的级联方法Cascade R-CNN(Cai和Vasconcelos,2018),如图7所示,其中H表示检测模块,B表示检测框回归结果,C表示检测框分类得分,conv及pool分别表示卷积层及池化层。Cascade R-CNN采用级联式的网络框架,将检测结果迭代式地回归,前一级检测模型的输出作为下一级检测模型的输入,并逐步提高正负样本分类时的交并比阈值。这种结构具有3种显著优势:1)与Iterative Bbox(Gidaris和Komodakis,2016)不同,Cascade R-CNN在不同阶段针对不同的候选框分布设置不同的检测网络参数(H1,H2,H3),由此可以更好地提取不同分布下的候选框特征用于网络训练;2)与integral loss(Zagoruyko等,2016)不同,Cascade R-CNN是级联式的结构,下一级的检测输入与上一级的检测输出息息相关;3)Cascade R-CNN利用交并比阈值递增的策略,逐步改善了训练过程中正负样本不平衡的问题。
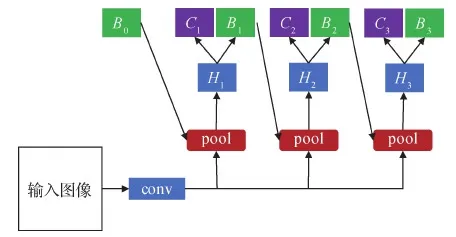
图7 Cascade R-CNN 算法框架图(Cai和Vasconcelos,2018)Fig.7 Framework of Cascade R-CNN (Cai and Vasconcelos,2018)
值得注意的是,此类方法通过多级级联的模式对检测结果逐步精调,可以取得更好的分类精度和更好的定位效果。利用这个特性,Brazil和Liu(2019)设计了基于级联的自回归框架AR-Ped(auto regressive network),旨在进一步提高行人检测器的定位精度,如图8所示,其中P1、P2和P3表示下采样模块。一方面,AR-Ped沿用Cascade R-CNN的检测思路,采用级联的方式渐进地提高候选框的采样阈值。另一方面,AR-Ped设计了新颖的编码—解码(encoder-decoder)模块,为候选框提供语义信息更丰富的底层特征,由此提高检测精度。
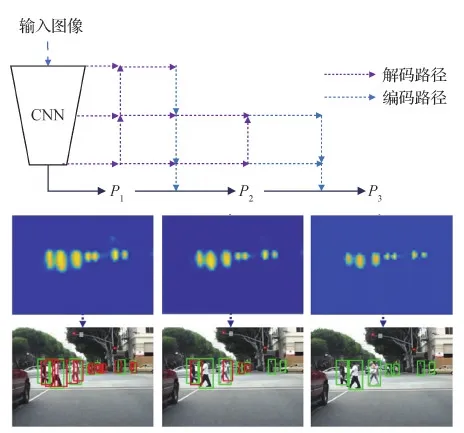
图8 AR-Ped框架图(Brazil和Liu,2019)Fig.8 Framework of the AR-Ped (Brazil and Liu,2019)
诸如此类的基于两阶段检测器的级联方法对候选框进行了多次递进式的分类与回归,检测精度较高,但是相对速度较慢。
1.3.2 基于单阶段检测器的级联方法
单阶段检测器是指无需经过候选框生成,可以通过锚点框直接预测分类结果和边界框的回归位置。因此,单阶段检测器往往效率较高、速度较快,但是面临着严重的正负样本不平衡问题,检测精度较低。受Cascade R-CNN的启发,有研究者提出将级联方法应用于单阶段检测器中,在保证检测速度的同时提高检测精度。典型的行人检测模型是ALFNet(asymptotic localization fitting network)(Liu等,2018)。其主要思想是多级渐进定位,即使用较高交并比阈值筛选第1级的检测框作为第2级检测框的输入,之后逐步提高网络的交并比阈值,从而训练更精确的行人检测器,具体的网络框架如图9所示,其中,h及w分别表示特征图高度及宽度,CPB(convolution prediction block)表示卷积预测模块。通过该级联的方式,一方面,可以为下一级检测网络提供更加精准可靠的行人特征;另一方面,通过加权多级检测置信度,可以得到更加可靠的检测结果。相比于Cascade R-CNN,ALFNet更面向实时的行人检测应用,提供了一种高效准确的行人检测方案。此外,ALFNet的研究结果表明,多步预测是提升行人检测器定位精度的关键所在。
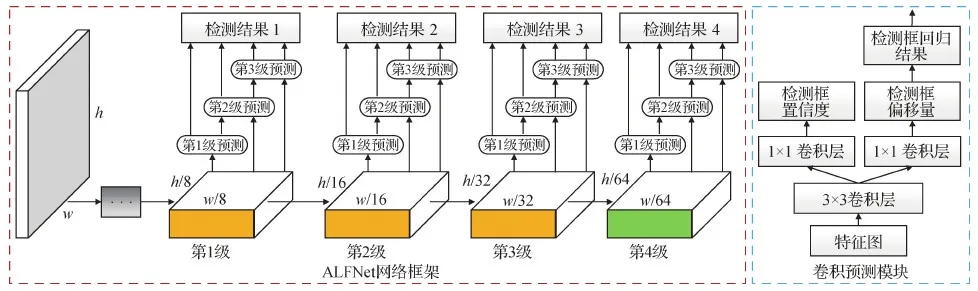
图9 ALFNet检测框架图(Liu等,2018)Fig.9 Framework of ALFNet (Liu et al.,2018)
1.4 基于尺度的方法
尺度变化问题也是行人检测面临的挑战之一。本文将其主要难点概括为两类:1)小尺度行人目标漏检率高。小尺度行人通常指在图像中成像尺寸较小的目标,在Caltech(Dollr等,2012)和CityPersons(Zhang等,2017)等行人检测通用数据集中,小尺度行人定义为高度小于30像素的行人目标。因此小目标在原图中往往只具有模糊的轮廓,缺乏较为精细的行人骨架及纹理特征,检测难度较大。2)行人目标尺度分布不均衡。本文概括了两种不均衡问题:1)单一图像中大小尺度行人特征分布不均衡。例如,大尺度行人目标往往具有清晰的纹理特征以及骨架信息,而小尺度行人目标只具有模糊的轮廓信息,因此较难对不同尺度的目标设计统一的特征处理策略。2)大小尺度行人目标数目不均衡。在通用的行人检测数据集中,往往小尺度行人目标较少,因此在训练过程中小尺度行人难以得到充分学习,导致训练后的模型对小尺度行人检测精度较低。按以上两个难点,本文将基于尺度的行人检测方法分为基于特征融合的方法和基于尺度自适应的方法。
1.4.1 基于特征融合的方法
研究者认为,小尺度目标往往在图像中呈现轮廓特征模糊、细节纹理不清晰等特点,因此如何捕获高质量的特征是提高小目标行人检测性能的关键。本文介绍一种典型的基于特征融合的目标检测方法,用于提高小尺度行人目标检测精度。
Lin等人(2017)认为顶层特征具有较为清晰的语义特征,同时底层特征具有更丰富的细节信息,包括图像边缘、轮廓和纹理等,因此通过顶层与底层特征融合互补的方法可以构建更加鲁棒的特征表达。如图10所示,Lin等人(2017)提出通过自上而下的结构进行特征融合,顶层特征经过双线性插值与较低层的特征图进行逐像素相加。这种结构增强了网络对多尺度特征的提取能力,并作为基础模块广泛应用于各种目标检测框架,取得了显著的性能提升。
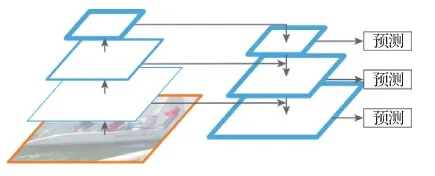
图10 基于特征融合的网络结构(Lin等,2017)Fig.10 Network structure based on feature fusion (Lin et al.,2017)
1.4.2 基于尺度自适应的方法
大多数小尺度行人具有轮廓模糊的特点,很难与杂乱的背景和其他重叠实例区分。同时,大尺度的行人目标通常表现出与小尺度行人不同的视觉特征。例如,大尺度行人的身体骨骼信息可以为行人检测提供丰富的语义特征,而小尺度目标的骨骼无法轻易识别。如图11所示,大尺度行人目标具有较大身体骨架特征响应,而小尺度行人目标仅具有模糊的局部特征。

图11 大尺度与小尺度行人目标特征响应值(Li等,2018)Fig.11 Feature activation of large-scale pedestrians and small-scale pedestrians (Li et al.,2018)((a)large-scale pedestrians;(b)small-scale pedestrians)
这种大小尺度行人目标的特征差异导致较难设计统一的行人检测网络。针对这个问题,Li等人(2018)提出可以利用多尺度特征,采用分治理念解决关键的尺度变化问题。基于这一思路,Li等人(2018)认为统一的框架可以包括多个单一模型,每个模型专门通过捕获尺度特定的视觉特征来检测特定范围尺度的行人目标,具体的检测框架SAF R-CNN(scale-aware fast R-CNN)如图12所示。SAF R-CNN由两条并行支路组成,分别用以检测大尺度与小尺度行人目标。该框架通过门函数加以控制,当输入大尺度目标时,为大尺度分支分配较高的权重;反之,赋予小尺度分支的权重更大。通过加权两路分支的输出,SAF R-CNN实现对不同尺度行人的精准检测。
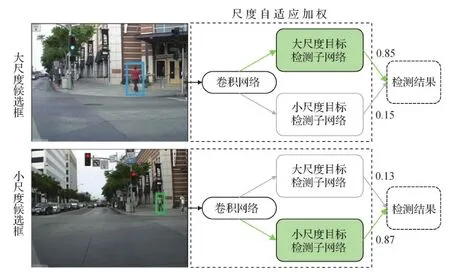
图12 SAF R-CNN算法框架图(Li等,2018)Fig.12 Framework of SAF R-CNN(Li et al.,2018)
2 基于无锚点框的行人检测
基于锚点框的行人检测方法通过预设大量尺寸和比例固定的行人目标先验框,用类似“穷举”的方法罗列行人目标的所有可能性。此类方法往往较为鲁棒且具有更好的泛化性能,但存在一定局限性。例如,难以为不同数据集设定具有针对性的锚点框超参数、大量冗余的锚点框会导致计算资源的浪费以及正负样本不均衡。因此,基于无锚点框的方法逐渐引起研究者的关注,如CenterNet(Zhou等,2019)和CornerNet(Law和Deng,2018)。此类方法并不需要额外设置先验框参数,而是直接利用特征图进行分类预测以及位置回归,推动了目标检测领域的巨大进步。近年来,研究者将基于无锚点框的方法应用于行人检测,本文将其主流方法概括为基于点的行人检测方法和基于线的行人检测方法。
2.1 基于点的方法
基于点的行人检测方法的出发点是认为行人目标可以用含有特定语义信息的点表示,例如角点、中心点等。CSP(center scale prediction)(Liu等,2019b)即是此类算法中的典型代表。CSP网络的主要思路是:1)通过卷积神经网络直接预测行人目标中心点热力图,热力图上响应较大的点即为行人目标置信度较高的位置;2)通过卷积及全连接层预测相应的行人检测框高度。具体框架如图13所示,其中h及w分别表示输入图像高度及宽度。
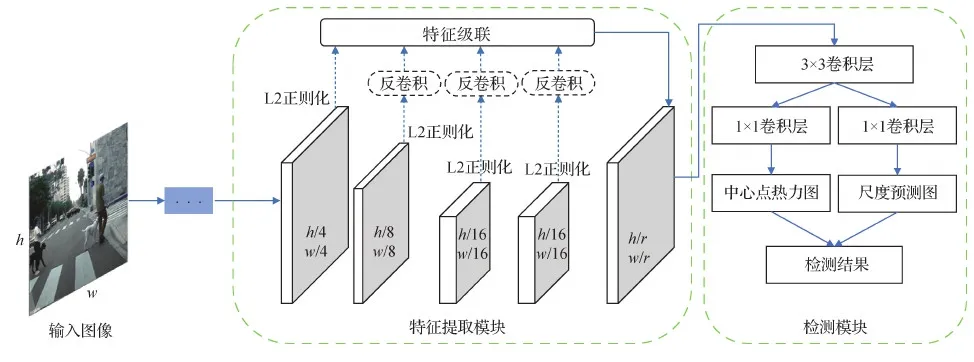
图13 CSP算法框架图(Liu等,2019b)Fig.13 Framework of CSP(Liu et al.,2019b)
与基于锚点框的方法相比,基于点的方法优点在于:1)降低了锚点框训练推理过程中的计算复杂度;2)基于点的方法更多依赖于行人可见部位特征而非整体行人特征,因此往往对于遮挡行人检测较为有效。但是,由于基于点的方法仅使用中心点或角点附近区域的特征,因此有用信息相对有限,导致模型训练测试过程不稳定,往往需要设计额外的约束或加权模块用以稳定检测结果。
2.2 基于线的方法
与CSP不谋而合,Song等人(2018)也尝试跳脱出锚点框的限制,但是与CSP基于行人中心点的检测思路不同,Song等人(2018)提出可以利用直立行人的垂直特征,设计了基于垂直线的行人检测网络TLL(topological line localization),具体框架如图14所示,其中h及w分别表示输入图像高度及宽度。
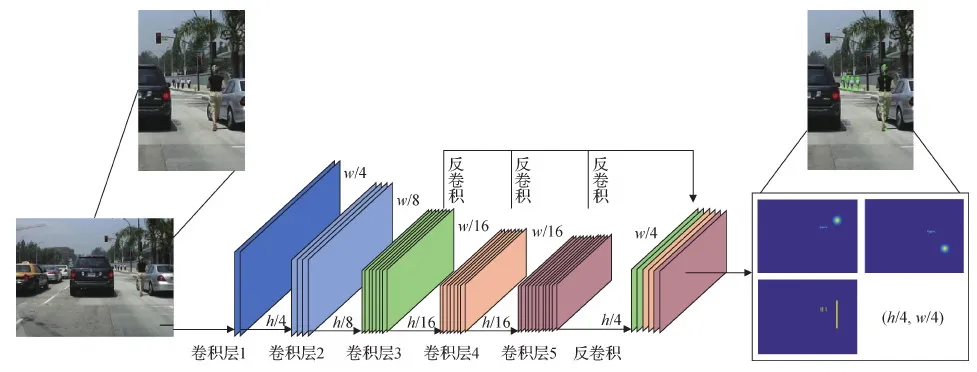
图14 TLL算法框架图(Song等,2018)Fig.14 Framework of TLL(Song et al.,2018)
从基于线的检测思路出发,TLL将行人检测划分为3个子任务,分别是行人目标上顶点预测、行人目标下顶点预测以及行人目标中轴线预测。与CSP类似,预测结果用热力图表示,且热力图上响应较大的点即为行人目标置信度较高的位置。相较于基于锚点框的行人检测方法,基于线的方法有两个显著优势:1)无需根据数据集人工设定大量先验框,降低了计算复杂度。2)基于锚点框的检测方法不可避免地引入背景噪声,而基于线的方法具有更明确、更清晰的语义特征。相较于基于点的行人检测方法,基于线的方法对行人结构有垂直约束,在检测性能上表现更为鲁棒。此外,TLL通过提取相邻帧间的运动信息,进一步提高了小尺度行人目标检测的召回率。总的来说,如何合理利用行人结构信息,如何合理提取帧间行人运动信息,也是行人检测领域值得探讨的研究方向。
3 行人检测通用技术改进
无论是基于锚点框还是基于无锚点框的行人检测方法均依赖于一些通用技术模块。针对通用技术模块的改进,往往可以直接有效地提升行人检测器的性能。本文总结了近年来研究者对于行人检测通用技术的改进,并将主流的改进算法概括为损失函数的改进和后处理方式的改进。
3.1 损失函数的改进
损失函数通常是由人工设计,并作为卷积神经网络的优化目标,用于估量模型预测值偏离真实值的程度。在目标检测中,损失函数作为模型的重要组成部分,其改进方法引起广泛关注。本文针对目标检测或行人检测中的不同问题,介绍3种典型的损失函数。
1)针对目标检测中的回归定位问题,研究者提出将交并比作为损失函数用于模型优化。但是交并比作为损失函数存在两点不足:(1)交并比在目标没有重叠时为0,无法反映两个目标之间的真实距离;(2)交并比无法区分两个目标的相对方向,更确切地讲,存在不同方向上交并比完全相等的情况。因此,Rezatofighi等人(2019)提出了广义交并比(generalized intersection over union,GIoU)损失函数,计算为
(1)
式中,AC表示两个框的最小闭包区域面积,即同时包含了预测框和真实框的最小框的面积,U表示两个框并集的面积。由式(1)可以得出,广义交并比GIoU具有两点优势:1)继承了原交并比算法的优点,包括非负性、尺度不敏感性等;2)在两框重合时取最大值1,在两框无交集且其相距无限远时取最小值-1,因此是有效的距离度量指标。GIoU作为高效的通用损失函数已经应用到目标检测的各个领域,行人检测作为目标检测的重要分支也因此取得了较高的精度提升。
2)Lin等人(2020)认为目标检测中通用的交叉熵损失函数(cross entropy function,CE)无法缓解正负样本不平衡的问题。CE的计算式为
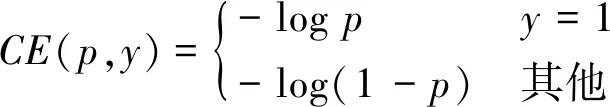
(2)
式中,p为模型预测置信度,y为真值标签。对于式(2)的交叉熵损失函数而言,正负样本以相同的权重相加得到总的损失值。因此,在正负样本极度不均衡的情况下,此交叉熵损失函数直接导致训练模型对于负样本的学习能力过强,正样本无法得到有效训练。Lin等人(2020)提出的FL(focal loss)通过加权因子,有效降低了大量简单负样本在训练中所占的权重。
3)针对行人遮挡问题,Wang等人(2018)提出RepLoss(repulsion loss),如图15所示。Wang等人(2018)认为如何精确地定位密集人群中每个行人目标是检测器最为关键的问题之一。密集遮挡的主要影响表现在显著增加了行人定位的难度,候选框难以准确匹配其对应的真实目标框,造成漏检及误检增多。因此,Wang等人(2018)通过改进检测算法中常用的回归方法,使候选框距离与之匹配的真实目标框较近,距离其他真实目标框较远,同时使得属于不同真实目标框的候选框彼此距离也较远。通过这种方式,RepLoss大幅提升了遮挡场景下的检测精度,并在通用目标检测中进一步证明了其有效性。
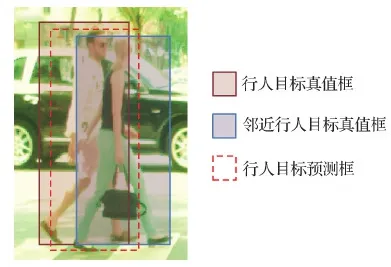
图15 RepLoss原理图(Wang等,2018)Fig.15 Illustration of RepLoss (Wang et al.,2018)
3.2 后处理方式的改进
本文提到的后处理方式主要指非极大值抑制算法(non maximum suppression,NMS)。非极大值抑制是一种重叠框去除方法,广泛应用于主流的目标检测框架中,非极大值抑制算法的性能与检测精度息息相关,因此也是行人检测通用技术的研究热点之一。针对行人检测任务的特殊性,非极大值抑制算法主要用于提升密集场景中遮挡行人目标的检测性能,本文介绍两种典型的非极大值抑制算法。
1)Liu等人(2019a)提出了场景自适应的非极大值抑制方法Adaptive NMS,通过对密集场景及稀疏场景设置不同的非极大值抑制阈值提升遮挡行人检测性能,具体框架如图16所示。Liu等人(2019a)认为较高的非极大值抑制阈值会导致稀疏场景误检率增高,而较低的非极大值抑制阈值无法有效地减少密集场景中大量重叠的检测框。因此,依据场景密度动态调整非极大值抑制阈值至关重要。Adaptive NMS通过引入密度预测分支(density subnet)合理估计不同场景的密集程度,并据此密度等级设置相应的非极大值抑制阈值。
图16 Adaptive NMS算法框架图(Liu等,2019a)Fig.16 Framework of Adaptive NMS (Liu et al.,2019a)
2)Huang等人(2020)提出可以利用行人部位检测框改进非极大值抑制算法R2NMS。如图17所示,该思路的出发点是行人的可见部位有效缓解了遮挡问题,因此,利用行人可见部位的交并比设置非极大值抑制阈值可以充分抑制重叠误检框,同时保证遮挡场景的低漏检率。

图17 基于行人部位的NMS改进算法(Huang等,2020)Fig.17 Improved NMS based on pedestrian parts (Huang et al.,2020)
4 数据集及各算法性能比较
4.1 数据集
数据是人工智能技术发展的基础,深度学习技术的进步离不开数据的支撑,常用的公开数据集也是各领域评估模型性能的重要依据。随着行人检测领域不断发展,越来越多复杂多样、具有针对性的行人检测数据集涌现,数据类型更加丰富、场景更加真实,更为贴近实际应用环境。
表1列出了常用的行人数据集。USC(University of Southern California)(Wu和Nevatia,2005)、INRIA(Dalal和Triggs,2005)以及ETH(Eidgenossische Technische Hochschule)(Ess等,2007)均为早期公开的行人检测数据集。其中USC(USC pedestrian detection test set)包含3组数据,即USC-A、USC-B和USC-C,3组子集分别针对不同的行人检测场景。USC-A中的图像来自网络,行人间不存在相互遮挡,拍摄角度为正面或背面;USC-B中的图像主要来自CAVIAR视频库,包括各种视角的行人,行人之间有相互遮挡;USC-C中的图像同样来自网络,均为正面无遮挡行人目标。戴姆勒行人检测标准数据集Daimler(Enzweiler和Gavrila,2009)图像采集自车载相机,均为灰度图像,另包含3个辅助的非行人图像集。Caltech(Dollr等,2012)和City-Persons(Zhang等,2017)是较为广泛用于评估行人检测性能的数据集。Caltech数据集包含大量小尺度行人目标及遮挡行人目标,可以有效检验复杂场景下行人检测器性能。此外,Caltech和CityPersons含有可见部位标注,有利于部位检测器的训练。CrowdHuman(Shao等,2018)和WiderPerson(Zhang等,2020)因场景复杂、行人间遮挡严重,近年来受到研究者的广泛关注。CrowdHuman数据集不仅具有整体行人标注,还提供了行人可见部位标注和行人头部标注。WiderPerson聚焦于野外场景,图像采集自网络,同时标注遮挡类型,为训练遮挡模板提供了可能。
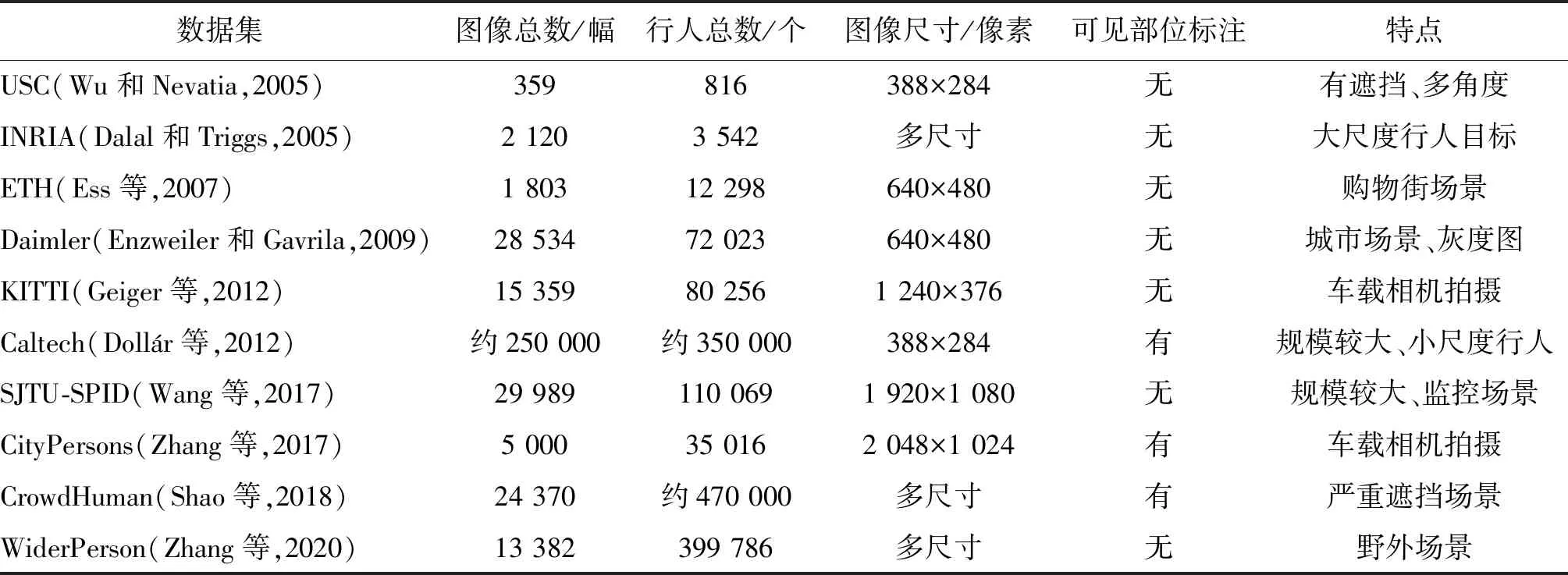
表1 行人检测常用数据集Table 1 Widely used datasets for pedestrian detection
4.2 评价指标
本文主要介绍两种常用的行人检测评价指标,均是目前主流的判断行人检测器优劣的标准。
1)平均对数漏检率(log-average miss rate) (Dollr等,2012)。该指标通过同时计算MR(miss rate)和每幅图误检个数(false positives per image,FPPI)衡量行人检测器性能。MR计算为
MR=1-TP/N
(3)
式中,TP(true positive)表示预测正确的行人目标个数,N表示真实行人目标总数。通过绘制MR-FPPI曲线,平均对数漏检率为9个FPPI值下的平均MR值,记为MR-2,其中9个点是对数区间[10-2,100]上的均匀采样。MR-2表示在指定误检率的情况下行人检测器的漏检率。MR-2越低,表示模型漏检率越低,检测性能越好。
2)平均精度AP(average precision)。该指标通过同时计算准确率(precision)以及召回率(recall)衡量行人检测器性能。准确率表示预测为正的样本中含有真正正样本的比例。召回率表示真正正样本中正确预测的比例。通过计算precision-recall曲线的线下面积,即可得平均精度值AP,AP值越大,模型精度越高,性能越好。
4.3 子集划分
在验证行人检测算法性能时,一般希望能够综合评估算法在不同情况下的表现,因而需要在数据集的各个子集上进行测试,这些子集有着不同的侧重点,例如有的子集目标尺寸较小、有的子集目标严重遮挡。通过在这些不同的子集上验证,可以考察算法针对尺度变化、遮挡等问题的处理能力。各子集的详细描述如表2所示。

表2 行人数据集子集划分方法Table 2 Method to divide pedestrian datasets
4.4 各算法性能比较
表3总结了不同算法在Caltech数据集上的实验结果。ACF(aggregated channel features)(Dollr等,2014)和LDCF(locally decorrelated channel features)(Nam等,2014)均采用手工特征进行行人检测,尽管采用了特征融合等方式,检测性能依然落后于基于深度学习的行人检测方法。TLL-TFA(topological line localization and temporal feature aggregation)(Song等,2018)采用基于线的检测方式,在遮挡和小尺度行人检测中显著超越其他算法。JointDet(Chi等,2020a)和PedHunter(Chi等,2020b)采用基于整体与部位加权的方法,通过平衡的方式同时降低漏检及误检率,检测性能在通用行人检测中更为突出。
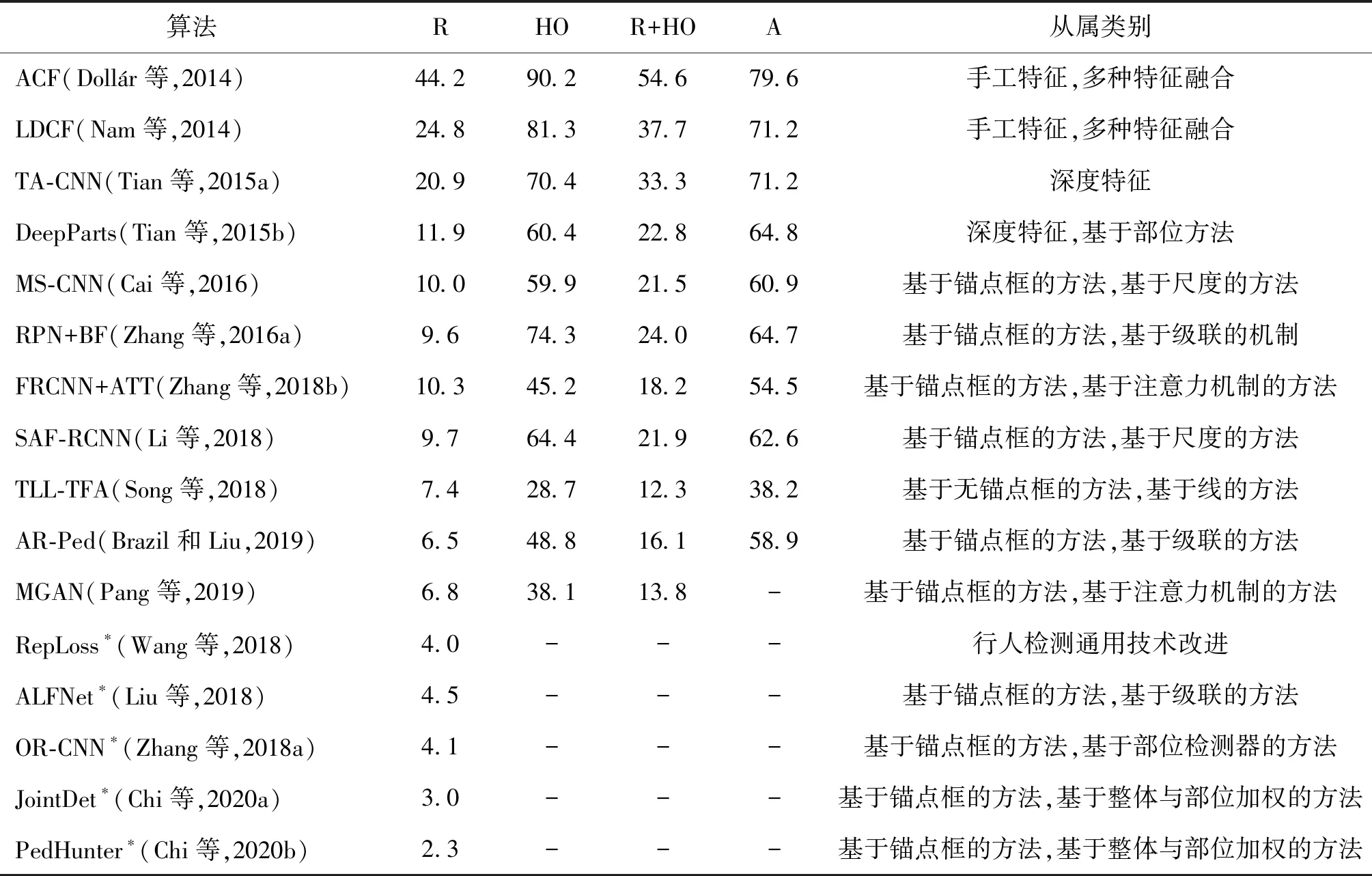
表3 以MR-2为评价标准,不同行人检测算法在Caltech数据集上的性能比较Table 3 MR-2 of different pedestrian detection algorithms on Caltech pedestrian dataset /%
表4总结了不同算法在CityPersons数据集上的实验结果。一方面,基于锚点框与基于无锚点框的方法CSP和TLL + MRF在通用行人检测子集R上性能相差无几,但是基于无锚点框的方法可以有效缓解行人遮挡问题。另一方面,基于改进的非极大值抑制的方法Adaptive-NMS和R2NMS,以及基于部位检测的方法MGAN表现优异,主要得益于对遮挡问题的有效处理。

表4 以MR-2为评价标准,不同行人检测算法在CityPersons数据集上的性能比较Table 4 MR-2 of different pedestrian detection algorithms on CityPersons pedestrian dataset /%
此外,相比于手工特征,基于深度学习的行人检测技术取得了较好的性能,但是目前的检测效果与人类自身表现之间仍有较大差距。
4.5 待解决问题及未来发展方向
根据以上实验结果和已有的研究思路,本文总结了基于深度学习的行人检测技术待解决问题和未来发展方向。
1)遮挡处理问题。遮挡普遍存在于行人检测和人脸检测等诸多计算机视觉任务中,是这些任务的核心挑战之一。在遮挡场景下,行人身体结构信息破坏,与检测器学习到的无遮挡行人特征差异较大,从而导致漏检。此外,由于遮挡程度或遮挡模式的不同,有遮挡行人特征往往呈现多样性的特点,因而对依赖数据驱动的通用行人检测框架提出了更高要求。目前,针对遮挡问题的解决方案大致分为以下两类:(1)引入部位特征辅助检测;(2)通过改进的后处理方法保留更多的检测框以匹配遮挡行人目标。虽然这些方法一定程度上缓解了遮挡问题,但是往往需要引入额外的网络结构,如部位检测网络(Huang等,2020)、密度预测网络(Liu等,2019a),因而复杂度较高,处理速度较慢,较难满足实际应用的需求。如何合理提升遮挡行人表征能力,如何提高遮挡行人检测器效率,是目前遮挡行人检测亟待解决的问题。
2)尺度处理问题。尺度变化是行人检测面临的另一个严峻挑战。由于行人距离摄像机的远近不同,在同一图像中往往呈现尺度差异较大的行人目标。一方面,小尺度目标轮廓模糊、有用信息较少,检测器难以精准检测。另一方面,大尺度目标与小尺度目标特征差异较大,难以针对不同尺度的目标设计统一的特征处理策略。本文总结了当前行人检测算法针对尺度变化的处理方法,包括特征融合、尺度自适应等。此外,仍有两个研究方向值得探索:(1)针对小目标行人设计专用的特征提取网络。现有的特征提取算法大多基于通用目标,而行人外观表现模式具有一定的特点,例如行人大多直立、行人宽高比相对固定等,因此小目标行人容易形成其特殊的外观特性,检测器可以针对这种外观表现设计合适的特征提取策略。(2)引入多任务学习机制。由于大小尺度行人目标的特征不一致性,可以构建多任务模型,分别检测大小尺度目标,同时通过联合学习以获得更多有利于小目标行人检测的信息,提升小目标检测的性能。
3)检测器效率问题。当前行人检测器效率问题主要体现在两个方面:(1)时间复杂度高。为了缓解遮挡、尺度变化等问题,主流的行人检测框架通常引入额外的网络框架,因而导致计算量增加,检测速度变慢,难以满足实际应用的实时性需求。(2)主流的行人检测器多针对行人检测的某一类特定问题,如RepLoss针对遮挡行人检测、MS-CNN(Cai等,2016)针对行人尺度变化,因此难以同时满足遮挡检测及尺度自适应的需求。如何提升算法效率,如何兼顾遮挡与尺度问题,也是未来一个重要的研究方向。
4)有效利用多模态信息问题。现有的行人检测方法主要集中于单一视角的图像模态,这种单一的模态信息往往无法避免随之而来的遮挡问题、尺度问题以及视角问题等。因此,如何挖掘多种信息、如何构建多模态信息的交互也是行人检测未来可行的研究方向之一。例如,利用深度信息(即行人目标距离摄像机的远近)可以感知行人的尺度变化,因此可以有效提高多尺度行人检测性能;利用俯视图信息可以有效缓解绝大多数的行人遮挡问题,由此提高遮挡行人检测精度。Luo等人(2020)基于该思路提出了一种多模态融合的行人检测网络,通过融合深度信息、俯视图信息以及正视图信息极大提高了遮挡行人检测性能。
5 结 语
行人精确检测是智能视频监控、无人驾驶和智能机器人等领域深度应用的基础性关键问题。本文关注行人检测面临的两个核心问题:遮挡及尺度变化,从基于锚点框的行人检测、基于无锚点框的行人检测和行人检测通用技术改进3个角度对基于深度学习的行人检测算法进行综述,对比分析了行人检测通用数据集及主流算法在数据集上的实验结果。最后,总结了行人检测待解决的4个问题,即如何进行遮挡处理、如何进行尺度处理、如何提高检测器效率以及如何有效利用多模态信息,同时提出了针对性的解决方案。
总而言之,以卷积神经网络为代表的深度学习方法极大推动了行人检测领域的进步,但是依然面临遮挡及尺度变化的严峻挑战,也是当前行人检测领域亟需解决的问题之一。近年来,行人检测方法已经广泛应用于自动驾驶、安防监控和机器人自动化等领域,但是距离高效率高精度的检测目标仍有一定差距,因此提高检测效率、提升检测精度以及拓宽应用领域也是窥见可行的发展方向。
