改进MobileNetV3的脱机手写汉字识别
2022-07-15程若然周浩军刘露露
程若然,周浩军,刘露露,贺 炎
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引 言
文字是人类社会最重要的交流载体之一,随着互联网与人类社会的联系越发紧密,手写汉字识别在人们生活中起到越来越大的作用。手写文字识别主要分为联机手写汉字识别和脱机手写汉字识别。前者使用相关设备记录书写轨迹的各项数据,利用笔顺信息来进行文字识别;后者则使用图像采集设备获取手写文字图像,通过学习图像与汉字字符编码之间的映射来识别文字。
手写汉字识别从上世纪80年代起不断发展,传统方法逐渐形成“预处理、特征提取、分类”的流程来进行手写汉字识别,并获得了不错的识别效果。但在实际应用中,更复杂的手写风格和识别模式使得文字识别率下降,用户难以获得最佳的性能体验。近年来,一些研究人员开始利用深度学习方法进行手写汉字识别。2013年的ICDAR手写汉字识别竞赛的优胜者,利用深度学习方法获得了远超传统方法的识别率,展现了深度学习在文字识别领域的极大潜能。
目前,基于深度学习的手写汉字识别方法存在训练时间长、高资源消耗的问题。为此,本文利用MobileNetV3作为主干网络进行脱机手写汉字识别,融合多尺度空间特征,提高了训练速度。
1 MobileNetV3网络模型
MobileNetV3是2019年Google研 发 的MobileNet系列的新作。MobileNet系列网络模型是为了能在移动端设备(如在手机上)运行而设计的轻量型网络,且继承了V1版本的深度可分离卷积(Depthwise Separable Convolution)和V2版本的逆残差(Inverted Residuals)和线性瓶颈(Linear Bottlenecks)结构。为了进一步提升分类准确率,V3版本引入了SE(Squeeze-and-excitation)结构,并对网络进一步剪枝以减少计算量,加快训练速度。
1.1 深度可分离卷积
如图1所示,标准卷积是每个卷积核与输入特征图的所有通道按位进行卷积计算,参数量为k×k×C×C、计算量是k×k×C×C×W×H。

图1 标准卷积与深度可分离卷积Fig.1 Standard convolution and depth separable convolution
其中,是卷积核大小;C、C是输入通道数(输入特征图的通道数以及卷积核通道数)和输出通道数(即卷积核个数);和是输出特征图的宽和高。
深度可分离卷积分为深度卷积和点卷积两步完成:深度卷积是用C个大小为、通道数为1的卷积核,对输入特征图的C个通道分别进行卷积计算,参数量为1×C、计算量为1×C×W×H;点卷积是使用C个通道大小为11、通道数为C的卷积核,对深度卷积的输出进行标准卷积操作,参数量为11×C×C,计算量为11×C×C×W×H。因此,深度可分离卷积在参数量上减少为标准卷积的1/C+1(k×k×C),在计算量上减少为标准卷积的1/C+1()。当使用33大小的卷积核时,理论上深度可分离卷积的计算速度应是标准卷积的89倍,而精度只与标准卷积相差1。
1.2 带线性瓶颈的逆残差结构
逆残差结构是依据ResNet的残差结构改进而得。残差结构先用1×1卷积核压缩输入特征图的通道数,再用3×3卷积核进行特征提取,最后用1×1卷积核扩张回原本的通道数,整体流程为“压缩-特征提取-扩张”,特征图通道数量先减小后增大。逆残差结构先用1×1卷积核扩张输入特征图的通道数,再用3×3卷积核进行深度卷积,最后用1×1卷积核压缩回原本的通道数,整体流程为“扩张-特征提取-压缩”,特征图通道数量先增大后减小。二者结构如图2所示。

图2 残差结构与倒残差结构Fig.2 Residual structure and inverted residual structure
由于低维分布嵌入到高维空间之后,再使用RELU激活函数由高维空间投影回低维空间,将会造成信息损失。针对该问题,MobileNet V2引入了线性瓶颈,即将逆残差模块最后一层的RELU改为激活函数。
1.3 MobileNetV3
MobileNet V3在前代版本的基础上,首先调整了网络的输入输出层,减少了输入输出层的卷积操作,以降低计算机资源消耗,提升了15%的运算速度;其次去除了函数的计算,改用计算消耗更小的函数;在逆残差模块中3×3深度可分离卷积之后引入SE模块,结构如图3所示。
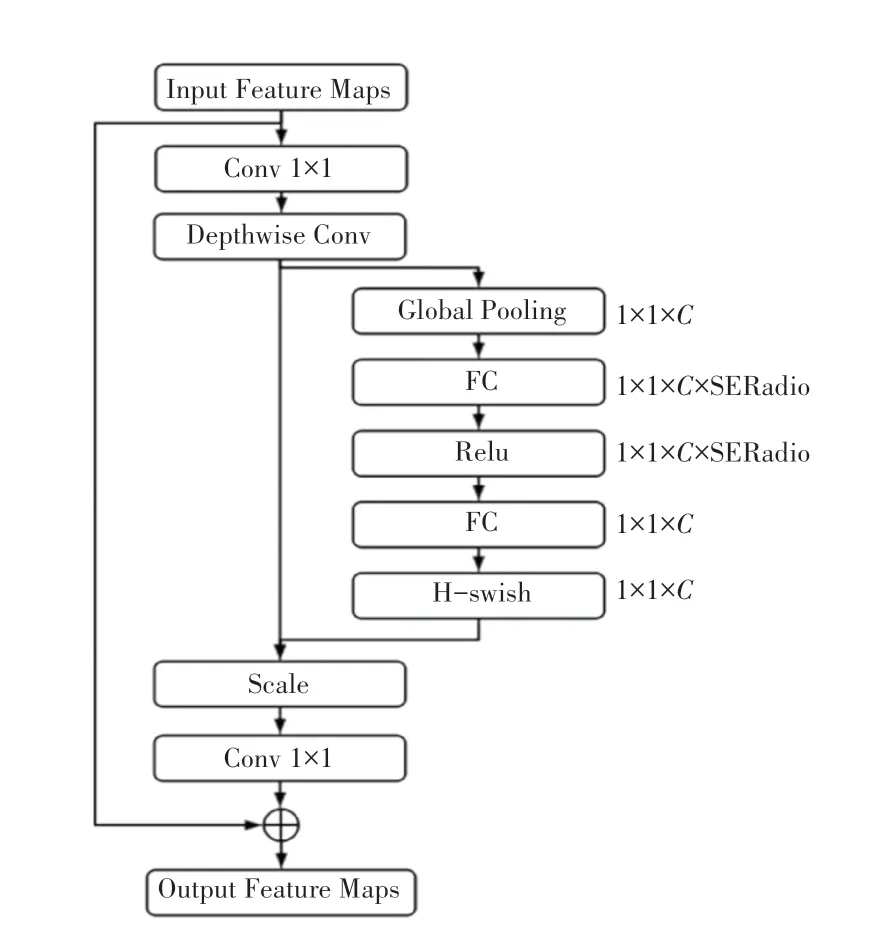
图3 MobileNet V3-SE模块Fig.3 MobileNet V3-SE module
MobileNet V3-SE的基本实现过程为:先进行全局池化压缩(Squeeze)获得一个1×1×的向量;然后经过两次“全连接层-激活(Excitation)”操作(为减少计算时间将第一次“全连接层-激活”操作的输出通道数压缩为原来的1/4),输出1×1×的向量;最后将得到的向量与深度可分离卷积的结果按位相乘,以调整每个通道的权值,从而提升网络精度。V3总体网络结构的设计中,首先通过NAS算法,对网络结构进行搜索优化(如网络中Block的排列和结构),得到大体的网络构成,最后使用NetAdapt算法来确定每个filter的channel数量。
2 基于MobileNetV3的脱机手写汉字识别
本文研究目标是脱机手写汉字的识别,主要面临两个问题:
(1)汉字数量多,相当于数千级别的分类问题。如此大数量的分类网络,需要更丰富的特征信息。
(2)形近字的识别容易得到错误结果(如“巳”和“已”)。
针对上述问题,本文以MobileNetV3为主干网络,设计了一种多尺度特征提取方案,并使用一种新的注意力机制进行特征融合,改进后的MobileNetV3能够更好地适应脱机手写汉字识别任务。
2.1 改进的MobileNetV3
本文在输入图像进行多次特征提取之后,加入一个特征提取模块来丰富特征信息。该模块包含两个支路:使用多尺度大小的卷积核来获取原始输入图像上不同范围大小的感受野,并利用注意力机制融合这两个分支的特征信息。优化后的网络模型如图4所示,其中虚线框所指模块即为本文的改进之处,MS-CAM是多尺度通道注意力模块。

图4 改进的MobileNetV3Fig.4 Improved MobileNetV3
2.2 感受野
在卷积神经网络中,感受野是一个非常重要的概念,指的是每个网络层输出的特征图像上,每个神经元所能“看见”的原始输入图像上对应区域的范围大小。如图5所示,每一层的卷积核大小都为3×3,卷积步长为1,填充大小为0。下一层特征图的每个神经元能看到上一层特征图3×3大小的区域,进而能看到再上一层5×5大小的区域。也就是说,越深的网络层越能看到原始输入图像上更多的内容。
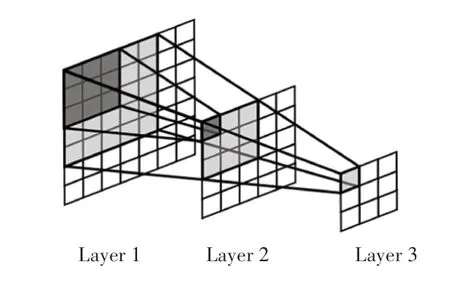
图5 感受野示意图Fig.5 Receptive field diagram
网络中不同大小的感受野会带来不一样的性能表现,而感受野的大小则受到各参数的影响(如卷积核大小、卷积步长、填充大小等)。为了能够从原始输入图像获得更丰富的特征信息,本文网络使用3×3和5×5多尺度大小的卷积核,来获取原始输入图像上不同范围大小的感受野。
2.3 多尺度通道注意力特征融合
特征融合是来自不同层或分支特征的组合,是卷积神经网络中常见的操作内容,通常通过简单线性的操作(如:求和或拼接)来实现。文献[8]中认为,这样的特征融合方式并不是最佳选择,因此提出了一种新的基于注意力的特征融合方法。本文利用该方法中提出的多尺度通道注意力模块(MS-CAM),通过不同特征的通道注意力来赋予两个分支不同的权重,从而完成其融合,其结构如图6所示。
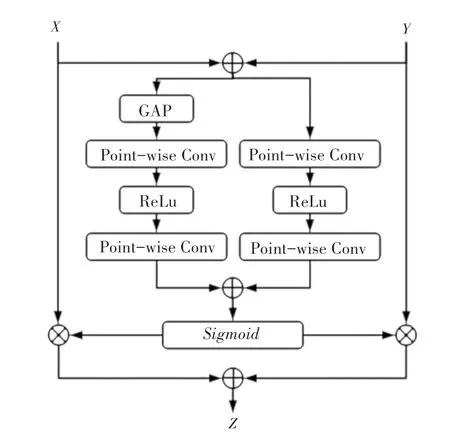
图6 MS-CAM结构图Fig.6 Structure of MS-CAM
MS-CAM除了进行池化,还有一个分支使用逐点卷积来进行特征提取,并将两个特征进行融合。前者更关注全局尺度上的大型对象,而后者更关注通道注意力不同尺度上下文的特征信息。SE的计算方式非常容易丢失原始图像上的细节信息,而MS-CAM利用多尺度特征提取方式,更好地捕获局部特征信息。
3 实验
3.1 数据集
本文使用CASIA-HWDB脱机单字符数据库中的HWDB 1.1数据集进行实验。该数据集由中国科学院自动化研究所模式识别国家实验室建设。脱机单字符数据库包括3个字符集,其统计数据见表1。其中,HWDB 1.0数据集的3 866个汉字包含GB2312-80字符集3 755个一级汉字中的3 740个汉字;HWDB 1.1数据集的3 755个汉字即为GB2312-80字符集一级汉字全集;HWDB 1.2数据集的3 319个汉字与GB2312-80字符集一级汉字集不相交。
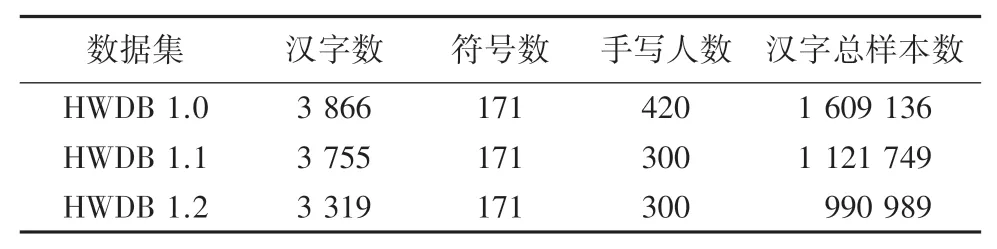
表1 脱机单字符数据库Tab.1 Database of offline single character
由于样本尺寸不一致,在输入网络之前均将其处理成224×224大小。训练、测试、验证集随机划分成8∶1∶1。数据集内部分样本示例如图7所示。

图7 部分样本示例Fig.7 Part of samples
3.2 评价标准
实验使用准确率()作为评价指标,当进行二分类时,其计算公式如下:
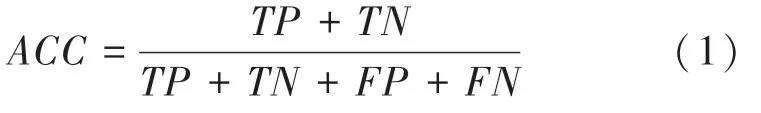
其中,、、、属于混淆矩阵的概念,其含义见表2。

表2 混淆矩阵及其含义Tab.2 Confusion matrix
准确率的含义就是被正确分类的样本数量与总样本数的比值。本文的目标任务是一个多分类(类别数3 755)问题,将二分类扩展为多分类,在计算第个类别的准确率ACC时,应将第类视为正类,其它类别视为负类,计算完所有类别的准确率后计算平均值。因此准确率的计算公式如下:
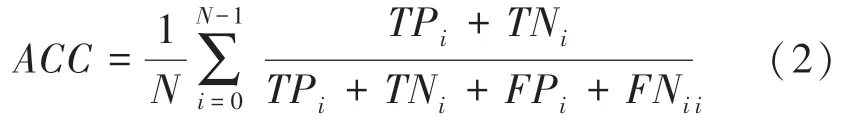
3.3 实验结果分析
本文所有的实验均在Ubantu 18.04系统上使用CUDA并行计算架构,并在Cudnn加速计算库的基础上搭建PyTorch框架,然后进行加速计算。实验所用显卡为NVIDIA GEForce GTX3090(24 G),内存为32.0 GB,CPU为Intel(R)Core(TM)i7-6950X CPU@3.00 GHZ。迭代次数Epoch为100,优化器选择Adam,优化参数选择默认。迭代学习率为0.000 1,权值衰减率为1e-5,批大小为80。无预训练和其他前置任务,每个Epoch后进行一次训练和一次测试,测试时不更新参数。将结果最好的模型参数保存,最后在验证集上进行验证。
本文将VGG19、ResNet18、MobileNetV2、MobileNetV3与改进网络进行对比实验。图8展示了5种网络使用同一数据集训练的准确率曲线,可以看出本文所提方法的准确率最高。
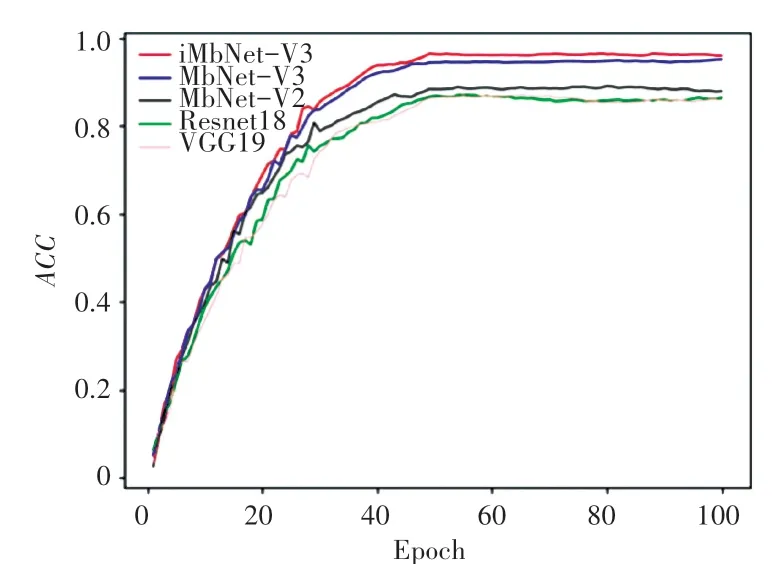
图8 各网络准确率曲线对比Fig.8 Comparison of accuracy curves of all networks
表3显示了各网络模型的准确率和参数量对比结果,其中本文所提方法不但有最好的识别准确率,而且没有因为进行3 755类汉字的分类而增加过多的参数量。

表3 各网络模型的对比结果Tab.3 Comparison results of various network models
4 结束语
本文针对目前手写识别网络训练时间长、高资源消耗的问题,提出了一种基于MobileNetV3的脱机手写汉字识别网络模型,在不降低识别率的基础上减少计算机资源消耗,加快训练速度。本文的主要改进工作:
(1)使用多尺度卷积核获取不同大小的感受野,丰富特征信息。
(2)采用多尺度通道注意力特征融合将多分支网络提取的特征进行全局和局部的特征融合,以提高网络性能。实验结果表明,本文提出的的改进网络获得了更好的识别结果。
