基于改进的PCA和ISSA-BPNN的定量构效关系预测模型
2022-07-15王登文铁治欣
陈 强,王登文,铁治欣,2,洪 亮
(1浙江理工大学 信息学院,杭州 310018;2浙江理工大学 科技艺术学院,浙江 绍兴 312369;3浙江传媒学院 媒体工程学院,杭州 310018)
0 引 言
据近几年全球癌症统计数据表明,乳腺癌症发病率和死亡病例逐渐增加,其防治须引起人们高度重视。临床、流行病学和生物学证据表明,雌激素参与了乳腺癌的发生和发展。雌激素化合物的大多数生理功能,在基因调控水平上主要由雌激素受体(ER)调节,这些蛋白质在细胞核中发挥作用,控制着各种器官系统的关键生理功能,并通过与相关的DNA调控序列相结合,来调节特定靶基因的转录。雌激素受体α亚型(Estrogen receptors alpha,ERα)在乳腺癌病中起着至关重要的作用,但在正常乳腺上皮细胞中极少被表达。通过使用选择性雌激素受体调节剂(SERM)和雌激素受体降解剂(SERD),可用来降低ERα的稳定性。
目前,在药物研发中,为了节约时间和成本,通常采用建立化合物活性预测模型的方法,来筛选潜在活性化合物。这种定量构效关系(Quantitative Structure Activity Relationship,QSAR)方法是一种预选工具,旨在减少化合物的数量,并增加选择候选药物的可能性。其以一系列分子结构描述符作为自变量,化合物的生物活性作为因变量建立模型,根据可测量的物理、化学参数,精确预测化合物的生物活性,或者对已有活性化合物的结构进行优化,QSAR本质上是数据驱动模型。近年来,人工智能、机器学习、大数据等技术的发展,为QSAR带来了挑战和机遇,通过成千上万的化学结构数据集,为药物的生物活性和安全性进行更精确的回归和分类预测带来了可能,对推动中国化学品的管理有着重要的意义。
QSAR预测模型主要分为基于统计分析方法的预测模型和基于机器学习算法的预测模型。例如:El Ghalia Hadaji以多元线性回归构建QSAR预测模型;Afaf Zekri以多元线性逐步回归构建QSAR预测模型;Lu Yang基于遗传算法的多元线性回归构建QSAR预测模型;Svetnik Vladimir以随机森林算法构建QSAR预测模型;代志军以支持向量机回归构建QSAR预测模型;杨杰元以BP神经网络算法构建QSAR预测模型;Li Jingshan以梯度下降树决策树(GBDT)构建QSAR预测模型。虽然或多或少实现了预测,但是基于统计分析的方法随着变量急剧增多也变得束手无策。为了提高基于机器学习算法的预测精度,本文提出了基于改进的PCA和ISSA-BPNN的预测模型。
1 相关预测方法
1.1 BP神经网络预测算法
BP神经网络(BPNN)结构简单,使用方便,非循环多级网络训练算法,使其具有广泛的实用性,能够实现输入到输出的非线性映射。BPNN是单向传播的多层前向神经网络(结构如图1所示),由输入层(个节点)、输出层(个节点)和多个隐含层组成。
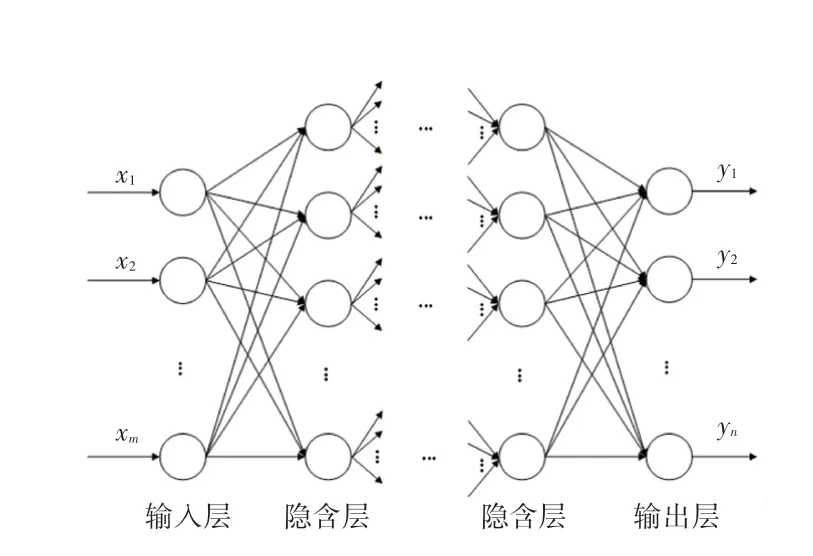
图1 BP神经网络结构图Fig.1 BP neural network structure
1.2 SVR预测算法
支持向量机回归(SVR)是将支持向量机分类(SVM)算法应用于回归预测中,两者不同的是:SVM将间隔之内的空间样本算入损失函数中,以达到分类的目的;而SVR则是将间隔之外的空间样本算入损失函数中,以达到回归的目的。对于非线性SVR模型,使用核函数将数据映射到高维空间,而后进行回归预测。由于径向基核函数(RBF)应用广泛且具有较好的回归效果,因此本文选择RBF作为SVM分析的核函数。
1.3 XGBoost预测算法
XGBoost(Extreme Gradient Boosting)是在Boosting算法基础上进行改良的,在预测精度以及训练速度方面有较大的突破,属于GBDT的范畴,并且也是一种前向特征的算法,本质上是由许多回归和分类的决策树组成。XGBoost相较于GBDT而言:前者加入正则项防止过拟合,对目标损失函数进行二阶泰勒展开,从而增加了精度,根据最佳切分点进行叶子节点分裂优化计算,从而优化结果。
2 QSAR模型
本文实验数据集源自乳腺癌治疗靶标ERα时,得到的1 974个化合物作为ERα生物活性数据样本。其中包括729个分子描述符信息和(实际QSAR建模中,一般采用来表示生物活性值,即因变量),值越大表明生物活性越高。
由于变量的数量比较多,本文首先提出基于改进的PCA特征选择算法,对模型的输入变量进行筛选,然后提出ISSA-BPNN算法对BPNN算法进行改进。
2.1 基于改进PCA的特征提取
改进的PCA算法流程如图2所示。首先对数据进行标准化,然后在729个分子描述符信息中,用基于Pearson、MIC和RF的加权得分算法得到前20个特征变量,最后基于PCA算法提取4个新特征代替原特征,作为模型的主要输入变量。

图2 改进的PCA算法流程Fig.2 Improved PCA algorithm
2.1.1 最大互信息系数法(MIC)
MIC是一种通过绘制变量散点图计算两个变量的互信息,来衡量变量间关联程度的算法。其实现步骤如下:
(1)散点图网格化,计算互信息值。给定个有序对数据集(,),将数据集划分为的网格,方向和方向的网格数分别为、。互信息值的计算如式(1):

式中,(,)为与之间的联合概率密度,()和()分别为和的边缘概率密度。
(2)互信息值归一化,如式(2):
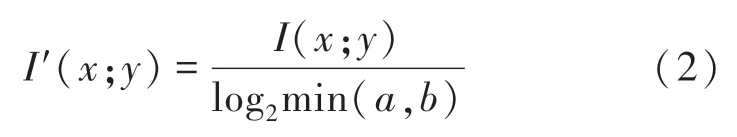
(3)变换网格划分情况,选择不同尺度下互信息的最大值作为值,如式(3):
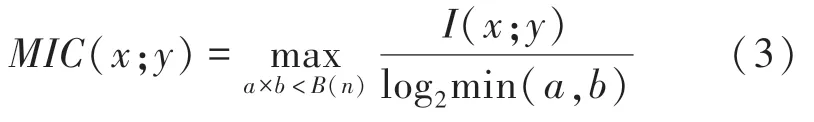
由文献[20]可知,当()=时,效果最好。
2.1.2 随机森林(RF)特征选择法
随机森林(Random Forest,RF)实质是一个包含多个决策树的组合分类器。其通过特征随机置换前后的误差分析,计算每个特征重要度得分,分值越高,特征越重要,从而进一步确定特征排序。随机森林结合Bootstrap重采样技术和决策树,构建一个包含多个基本分类器的树型分类器集合,采用简单多数投票的方法得到结果。
RF中决策树数目为N,原始数据集有个特征,单特征X(1,2,…,)基于误差分析的特征重要性度量,按以下步骤计算:
(1)计算第棵决策树相应的袋外数据OOB的袋外错误样本数;
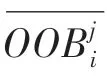
(3)重复步骤(1)、(2)得到:
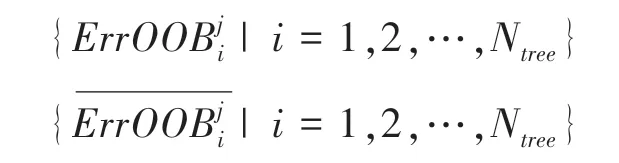
(4)由式(4)计算特征X的重要性得分。
(4)要加强地质人才培养,引进人才激励机制。地质人才是理论创新、技术变革的重要基础,也是进行深部找矿的关键,为此我们应该加强地质人才的培养,建立健全人才激励机制,鼓励更多的地质人才去为深部找矿发展做贡献。一方面要采取相应的鼓励机制,鼓励更多的人报考地质领域的相关专业。另一方面要保障地质工作者的各方面待遇,在改善他们生活条件的同时也要加强队伍培养和人才业务能力建设。鼓励更多专业素养过硬、有吃苦耐劳精神的年轻人加入,同时也要完善相关的人才激励机制,加强技能培训力度,更好地激发他们的积极性和工作热情,不断提高他们的实践能力。只有人才得到保证才能使我国的地质事业更好地可持续地发展下去。
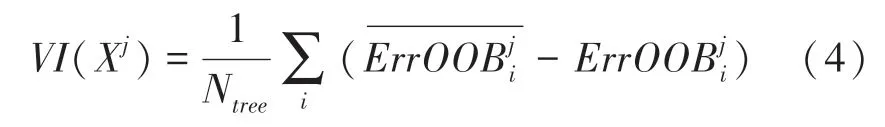
2.1.3 基于Pearson、MIC和RF的加权得分算法
由于各变量的数值量纲之间存在较大差异,为了消除量纲的影响,需要对数据进行标准化处理。本文采用Z-score标准化方法,对变量进行归一化处理,如式(5):

Pearson和MIC反映了自变量与因变量之间的线性和非线性关系,而RF是以特征重要度计算值来表示自变量与因变量的相关性。加权得分由式(6)计算得到:
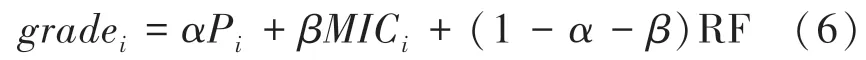
其中,g r a d e表示第(1,2,3,…,729)个分子描述符的加权分;P表示第个自变量与因变量的Pearson系数绝对值;MIC表示第个自变量与因变量的最大互信息系数绝对值;RF表示第个自变量与因变量的特征重要度计算值,和均应在0和1之间(本文取025)。
由式(6)计算得到20个主要特征变量见表1。
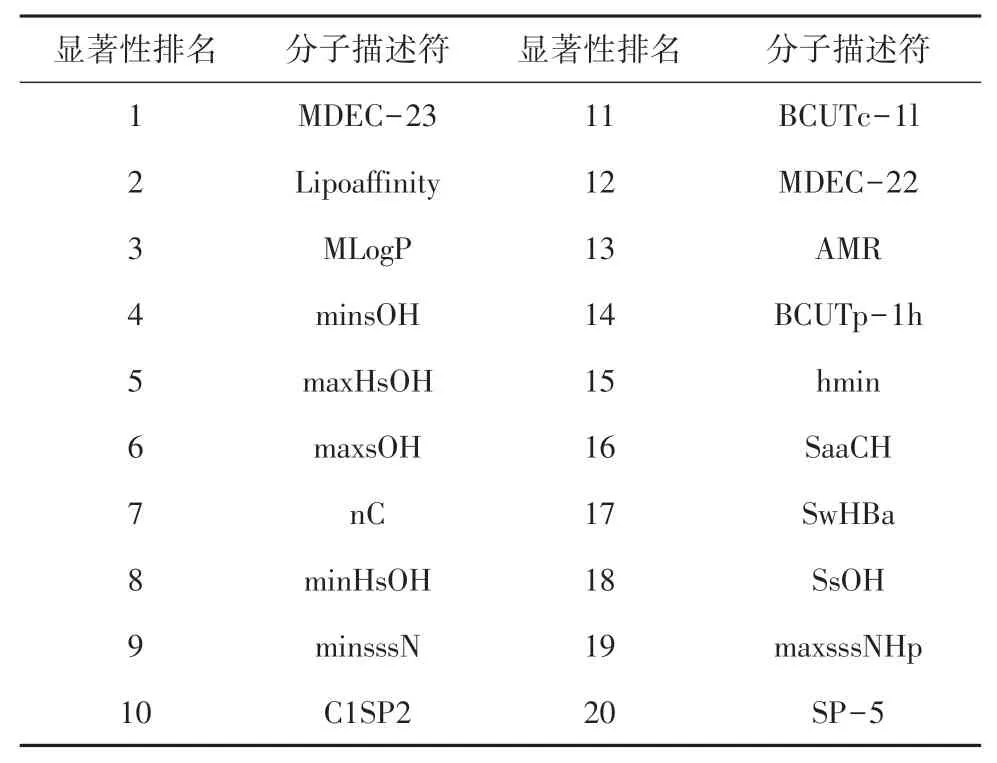
表1 加权得分分子描述符显著性排序Tab.1 Significance ranking of weighted score molecular descriptors
2.1.4 确定模型输入变量
PCA算法的原理是以原始特征的线性组合方式,得到新特征来代替原特征,从而达到降维的效果。根据方差越大新特征越重要的原则,对个主成分按照贡献率进行排序,再从中提取个主成分来代表全部数据,最后将新特征作为QSAR模型的输入值。算法流程如下:
(1)计算数据的协方差矩阵。假设原始数据集为,其协方差矩阵记为;
(3)计算累计贡献率并确定主成分个数。
将表1中的20个特征变量由PCA算法特征提取后,得到新特征的贡献率见表2。
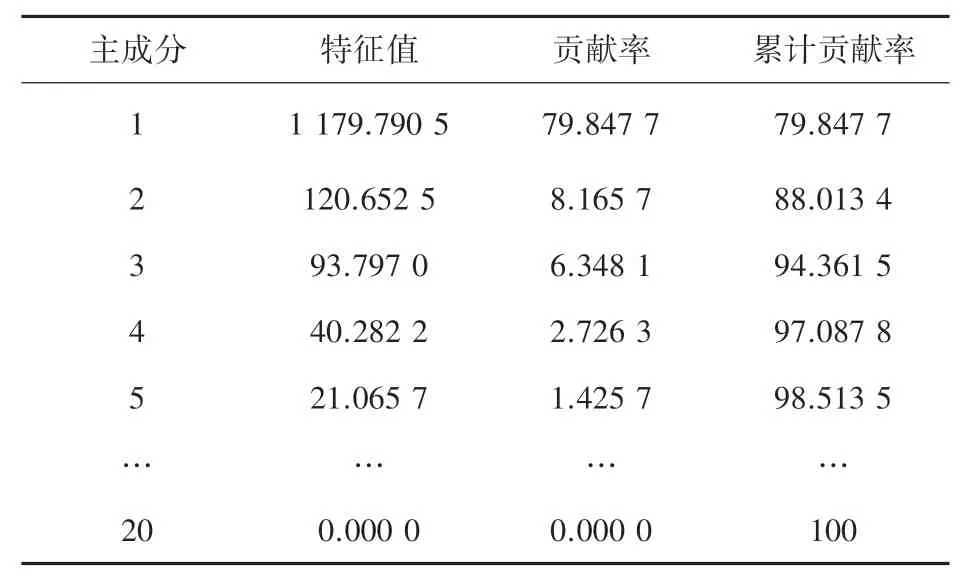
表2 新特征累计贡献率Tab.2 Cumulative variance contribution rate of new features
由表2可知,前4个新特征已包含原始特征95%以上的信息。故本文取前4个新特征代替原特征作为模型的主要输入变量。
2.2 ISSA-BPNN
传统的BPNN对权值和阈值较敏感,存在收敛速度慢和极易陷入局部最优的问题。因此,本文通过改进的麻雀搜索算法(improved sparrow search algorithm,ISSA)来优化BPNN的权值和阈值。
SSA是根据麻雀觅食并逃避捕食者的行为而提出的群智能优化算法,其模拟了麻雀群觅食的过程。在SSA中有3种状态,分别是发现者、加入者、侦察者。其中,适应度值较好的发现者是为了获得食物的同时,为所有加入者提供觅食的方向;侦察者选择安全第一为目标,在发现危险的情况下,提醒种群放弃食物。
由于SSA容易陷入局部最优,且全局搜索能力较弱,可将SSA中发现者和加入者位置更新公式分别改为式(7)、(8)。加入者以一定概率向发现者靠拢,保证了全局收敛。同时,后加入的麻雀要尽快飞到其他区域觅食。
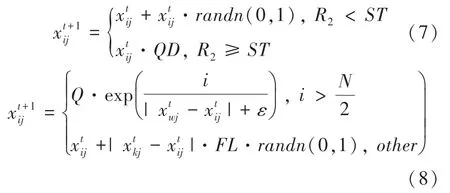
其中,代表当前迭代次数;(0,1)和是服从标准正态分布的随机数;是1的矩阵,代表维度;x是第个麻雀在第维的位置;∈[0,1]代表预警值;∈[05,1]代表安全值。
当≥时,表示发现者已经发现捕食者,此时种群内其它麻雀尽可能飞到其它安全地方进行觅食;当时,发现者可以广泛搜索。是种群规模,x是当前全局最差的位置,x是当前发现者的位置,∈[1,1]表示加入者跟随生产者寻找食物的概率。当2时,表示适应度值较差的第个加入者处于挨饿状态,需要尽快飞到其它区域继续寻找食物来获得能量。
侦察者的位置更新如式(9):
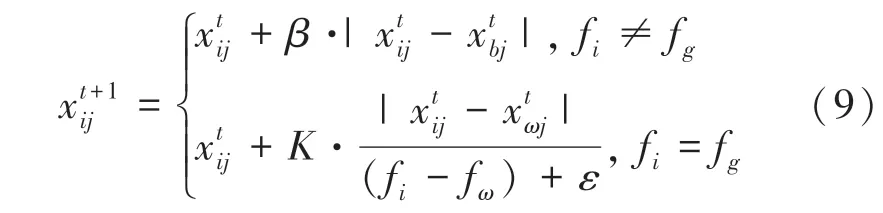
式中,是[1,1]范围内的一个随机数;是步长控制参数,其服从标准正态分布的随机数;x表示当前的全局最佳位置;f、f和f分别代表当前麻雀的全局最差、全局最优和个体适应度。分母加上一个常数量,是为了防止分母出现0的情况。
本文提出的ISSA-BPNN流程如图3所示,其实现步骤为:
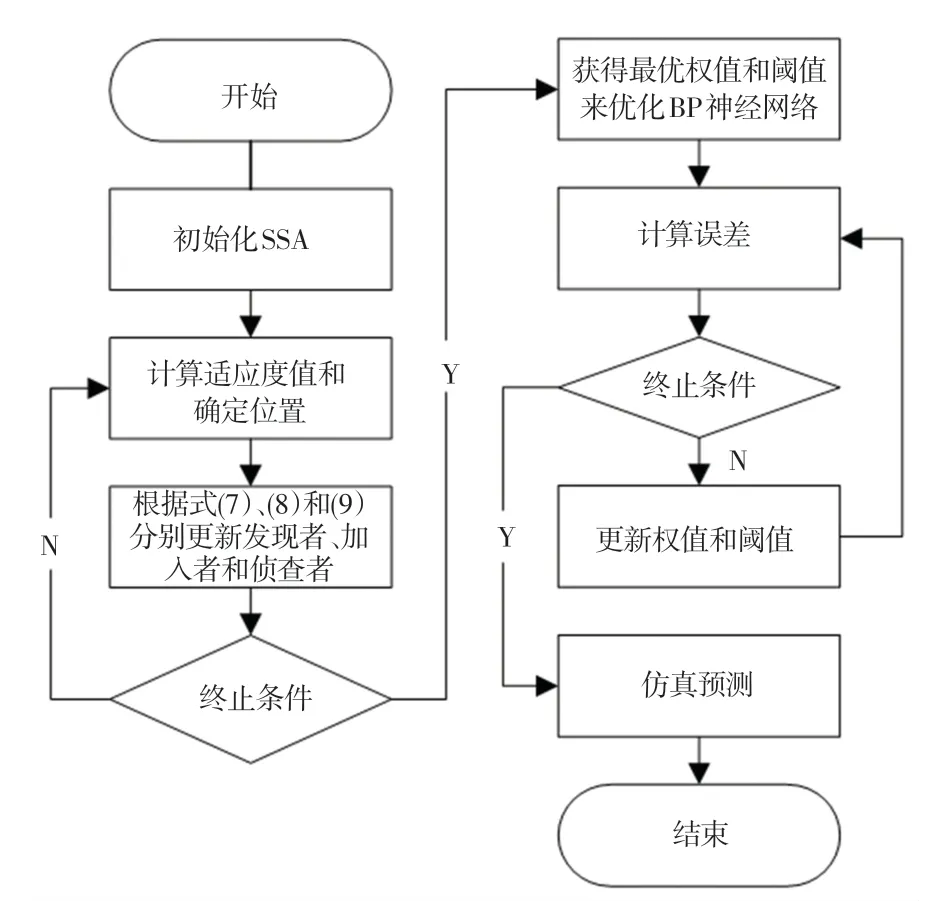
图3 ISSA-BPNN流程Fig.3 ISSA-BPNN flow chart
(1)初始化麻雀搜索算法;
(2)计算麻雀种群个体适应度,并得到最佳位置、最差位置和最佳适应度值、最差适应度值;
(3)根据式(7)~(9)分别更新发现者、加入者和侦查者的位置信息,并更新适应度值;
(4)若算法达到最大迭代次数或达到最初设定的收敛精度,则执行步骤(5),否则返回步骤(2);
(5)将得到的最优值赋给BPNN的权值和阈值;
(6)使用BPNN进行学习,不断调整直至达到训练终止条件,最终实现预测输出。
3 实验结果与分析
依据上述方法对数据进行新特征选取后,将1 974个样本按照7:3的比例划分训练集和测试集。训练集用来拟合模型,测试集用来对模型的性能进行评价。验证本文所提出模型的有效性,分别利用SVR、XGBoost、BPNN和ISSA-BPNN模型对前述数据集合进行预测。
3.1 预测模型的评价指标
本文采用平均绝对误差()、平均绝对百分比误差()和均方根误差()评价模型的预测精度。其计算公式分别为式(10)(12):
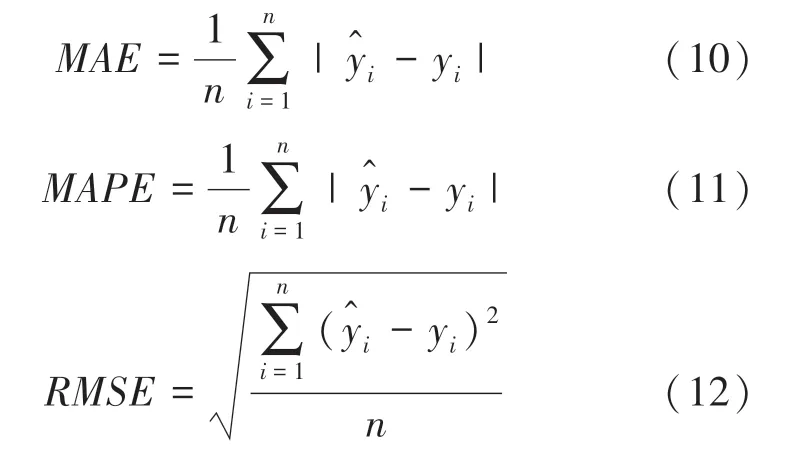
3.2 结果分析
4种模型的预测值与真实值曲线对比如图4所示,预测精度对比结果见表3。
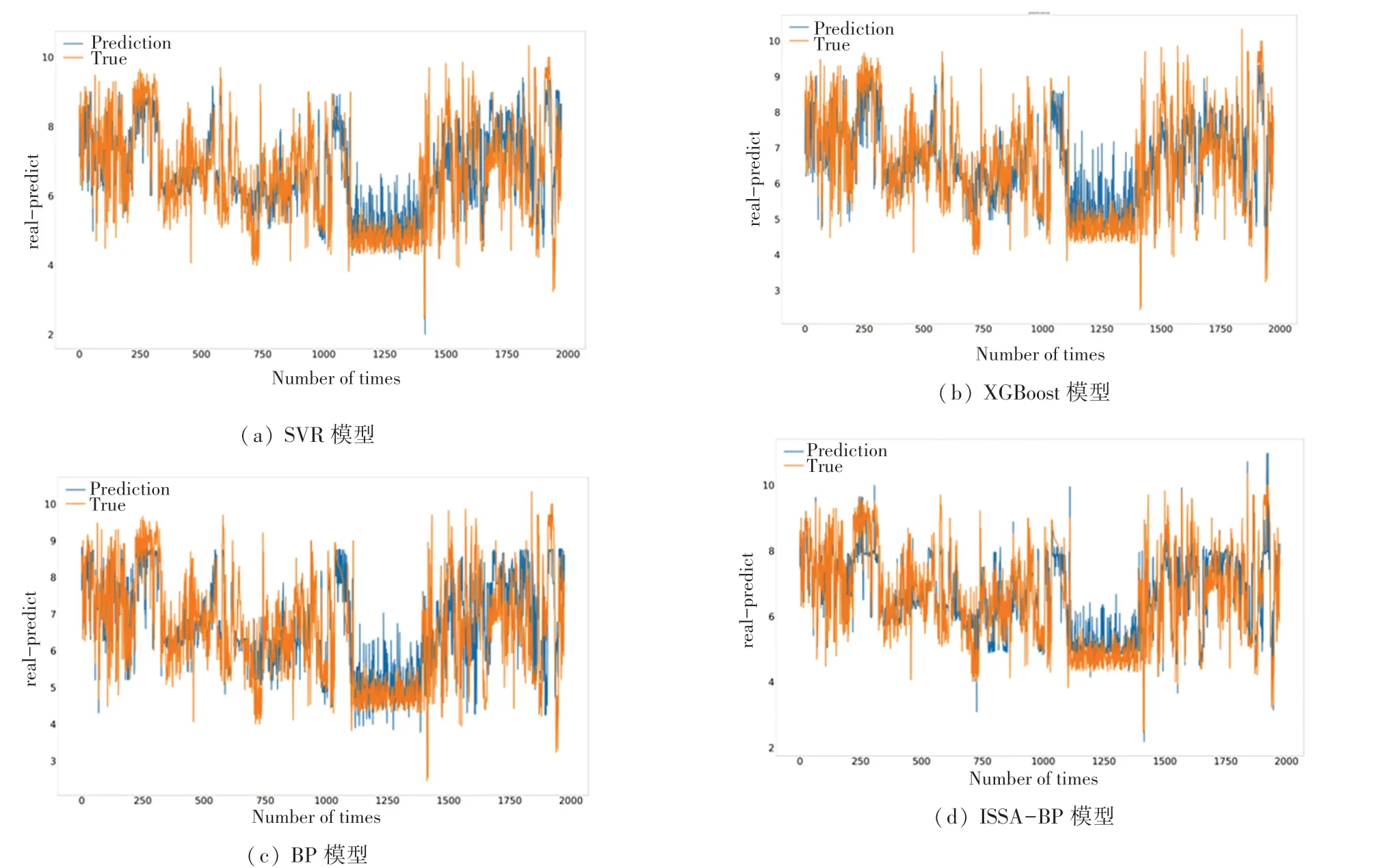
图4 4种模型的pIC50预测值与真实值对比Fig.4 Comparison of predicted pIC50 values and true values of four models
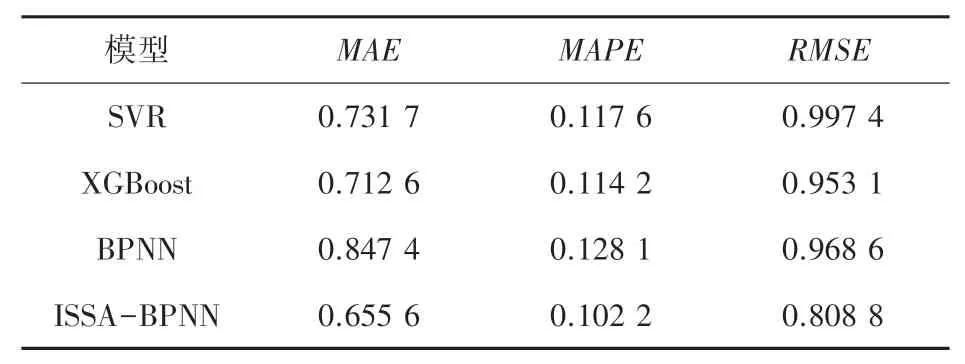
表3 4种模型预测精度对比Tab.3 Comparison of prediction accuracy of four models
由表3可知,ISSA-BPNN模型的、、均是最低的,表明ISSA-BPNN预测误差值最小、稳定性最高、效果最佳。其中,ISSA-BPNN模型的值较SVR模型提高了13.10%,较XGBoost模型提高了10.53%,较BPNN模型提高了20.22%。
4 结束语
为了更精确地预测化合物的生物活性,本文提出了一种基于改进的PCA和改进的麻雀搜索算法优化BP神经网络(ISSA-BPNN)预测模型,其具有良好的寻优能力。
算法中,利用改进的PCA算法提取模型的主要变量,再利用ISSA优化BPNN的权值和阈值,改善了BPNN易陷入局部极值的缺点。通过实验对比结果表明,基于ISSA-BPNN预测模型的预测精度最高,并具有较强的拟合能力和泛化能力。但是,由于训练的数据量较少,导致模型的预测精度不是太高,后期研究可增加训练数据来提高模型的预测精度。
