基于BP神经网络的钢尾渣-矿渣基充填料强度预测
2022-07-14朱子康顾宝澍代梦博袁邦兴林振林春铁军
昌 欢,朱子康,顾宝澍,代梦博,袁邦兴,林振林,春铁军
(安徽工业大学冶金工程学院,安徽 马鞍山 243032)
随着科学充填采矿技术的日益发展,多种冶金固废被陆续用于胶结充填矿山采空区[1-2]。钢渣磁选尾渣(简称钢尾渣)是一种大宗量冶金固废,可利用钢尾渣微膨胀性补偿充填体的收缩,防止地压灾害,达到以废治害的目的[3-5]。然而钢尾渣活性较低,需外加激发剂激发其胶凝活性[6-7]。目前一般通过相似实验、经验公式估算等方法探寻固废制备充填料的适宜掺量配比,但充填体系映射关系复杂多变,采用以上方法需进行大量充填实验、耗费大量时间[8-10]。
误差反向传播(back propagation,BP)神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,也是应用最广泛的神经网络[11]。随着统计学、计算机等工具的发展,深度挖掘足量样本信息,构建符合实际情况的BP神经网络模型,可推进矿山充填的科学性和智能化发展,且已引起学者们的广泛关注[12-13]。董越[14]和刘恒亮等[15]采用正交BP神经网络对相应目标充填体系进行了预测,相对误差在5%以内;Rafat等[16]采用人工神经网络预测密实混凝土的抗压强度,模型相关系数大于0.9;刘志祥等[17]采用遗传算法的BP神经网络预测磷石膏充填的强度,误差在4%以内;魏微等[18]通过调整神经元数优化改进BP 网络,训练函数方法为附加动量的梯度下降法,预测结果的最大相对误差较小,但模型配比范围较窄;胡凡等[19]利用BP神经网络模型成功预测不同胶凝材料、灰砂比等条件下制备充填体的强度,但对充填体强度较低的试块预测精度有待提高。现有学者对于充填体强度预测的研究,多是建立强度预测模型,少有建立扩展度和强度的综合预测模型,且训练样本的选取代表性不强,钢尾渣-矿渣基充填料BP神经网络模型的泛化性有待进一步提高。鉴于此,选取正交试验样本及灰砂比、钢尾渣掺量、外加剂与胶材比等单因素试验样本,建立BP 神经网络预测模型,对填充体系的扩展度、抗压强度进行预测研究,以期用于指导优化充填原料配比、缩短实验周期。
1 试验原料与方法
1.1 试验原料
试验原料为胶材(钢尾渣、矿渣)、外加剂(专用添加剂、脱硫灰、水泥熟料)、砂(铁尾矿)等,其主要化学成分、原料粒度及比表面积如表1。其中D10,D50,D90为粒径分布曲线上粒径累积质量分别占总质量10%,50%,90%的粒径。

表1 试验原料的主要化学成分及细度Tab.1 Main chemical composition and fineness of raw materials
1.2 试验方法
1.2.1 充填体的制备
参照GB/T 50080—2016《普通混凝土拌合物性能试验方法标准》,JC/T 2478—2018《矿山采空区充填用尾砂混凝土》,用钢尾渣替代部分矿渣制备钢尾渣基充填体。按表1 所示配比称料,依次向砂浆搅拌机中加入胶凝材料、细骨料、水,料浆质量分数为62%,搅拌5 min 至均匀后将其一次性浇注在尺寸为70.7 mm×70.7 mm×70.7 mm 的标准混凝土三联试模中;试模内壁涂薄层机油,用插捣棒从边缘向中心按螺旋方向均匀插捣,并使充填料浆高出试模顶面;插捣结束,轻轻敲打试模侧面,使浆体表面平齐,将充填料带试模在实验室环境中静置48 h 后刮平,套上保鲜膜,将其置于湿度90%、温度(20±2)℃的水泥混凝土标准养护箱中养护7 d和28 d,得到待测试的充填体。
1.2.2 料浆扩展度及抗压强度的检测
选取扩展度表征料浆流动性。将搅拌充分的充填料浆迅速注入截锥圆模(上口直径36 mm、下口直径60 mm、高60 mm)内,并用抹刀将上口刮平;清除筒边玻璃板上的料浆后,人工垂直平稳提起截锥圆模,为避免提起速率与高度的影响,指定每次动作为迅速提起至肩膀高度;当料浆不再扩散时,使用钢尺测量料浆流淌部分互相垂直的两个最大直径,取平均值作为充填料浆的扩展度。使用万能压力机测试相应龄期充填体的抗压强度,试件受力面为非刮平面的侧面且上下垫有大于试件尺寸的钢垫板,载荷速率控制在100~250 N/s并靠近100 N/s,记录破坏荷载F,采用p=F/A计算试件的抗压强度p,其中A为受压部分面积,为4 998.49 mm2。
1.3 BP神经网络预测模型的设计
BP神经网络预测模型的设计思路如图1。选取正交试验结果作为BP神经网络的主体训练样本,单因素试验和其余配比试验结果作为补充训练样本,设计BP神经网络模型。以原料的灰中占比、灰砂比为输入层,以充填料3个指标(料浆扩展度、7 d和28 d充填体抗压强度)为输出层,选择合适的传递函数和训练函数并确定训练参数。依据训练情况采用试错法,初步确定隐含层神经元个数,选取4 组样本检验模型预测误差,最终确定神经元个数并保存已训练好的网络。利用建立的BP神经网络充填料强度预测模型,预测不同配比的充填料扩展度及抗压强度。
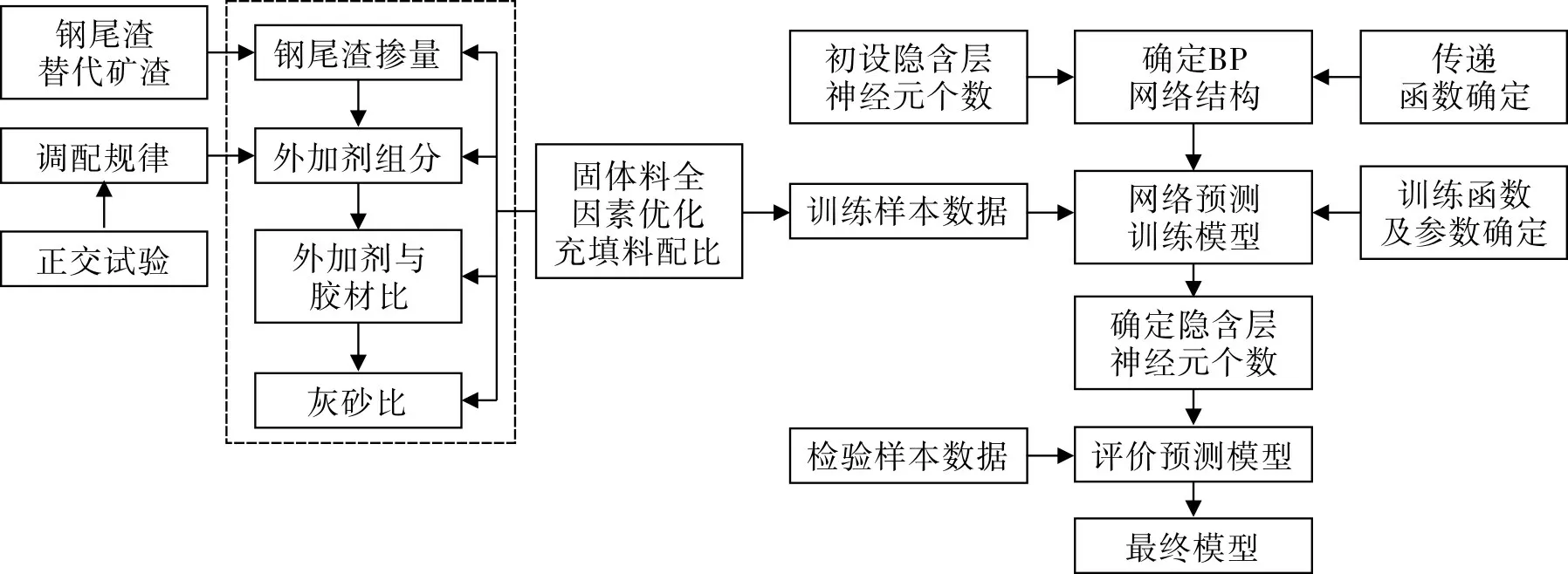
图1 样本选取及模型设计流程Fig.1 Process of sample selection and model design
2 预测模型的建立与训练
2.1 样本选取
2.1.1 正交试验样本
控制灰(外加剂、矿渣、钢尾渣)、砂(铁尾矿)的固体料总量及矿渣在固体料中的占比不变,选取钢尾渣、专用添加剂(简称添加剂)、脱硫灰、水泥熟料4种固体料占比为因素,其中铁尾矿和灰砂比为因变因素。采用四因素四水平L16(45)正交表,以正交试验结果作为BP神经网络的主体训练样本,正交试验方案及结果如表2。
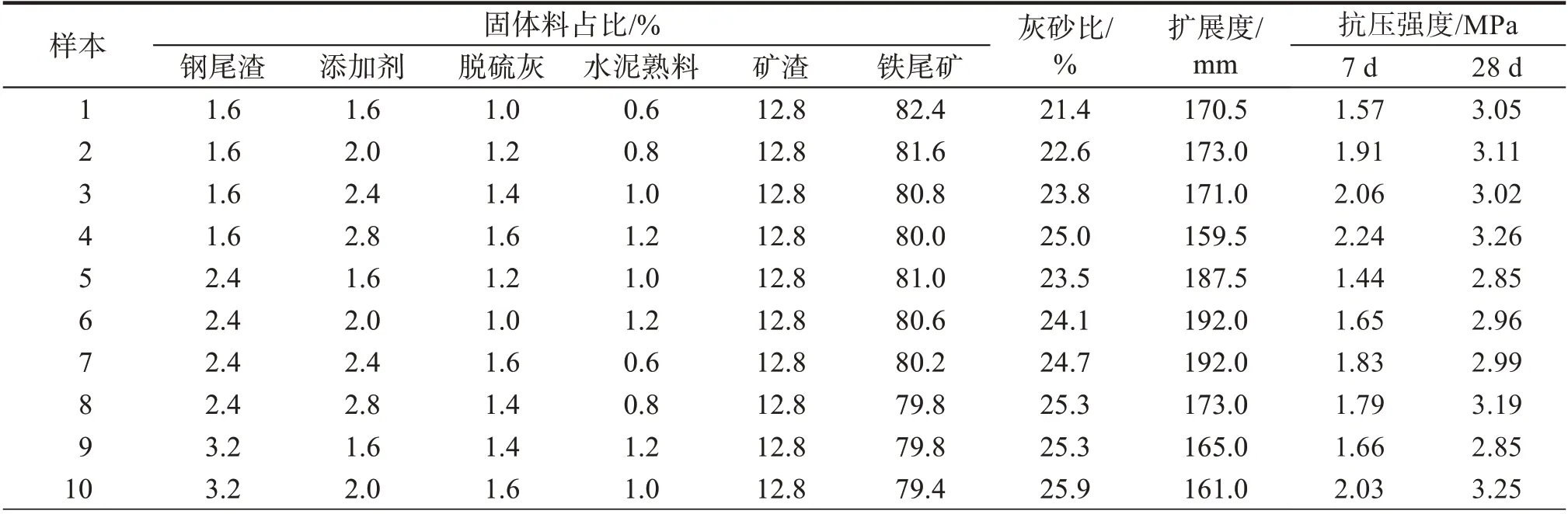
表2 正交试验方案及结果Tab.2 Orthogonal test scheme and result

续表2
2.1.2 单因素试验样本
为增强设计模型的泛化性,在16 组正交试验样本的基础上,选取灰砂比、外加剂与胶材比、钢尾渣掺量等单因素试验结果作为补充训练样本,试验方案及结果如表3。下述试验方案均控制灰总量不变,钢尾渣、矿渣、添加剂、脱硫灰、水泥熟料的掺量均以其在灰中的占比表示。编号17~20 为不同灰砂比试验方案及结果;编号21~23为不同外加剂与胶材比试验方案及结果;编号24~26为不同钢尾渣掺量试验方案及结果;编号27~35为其余配比试验方案及结果。
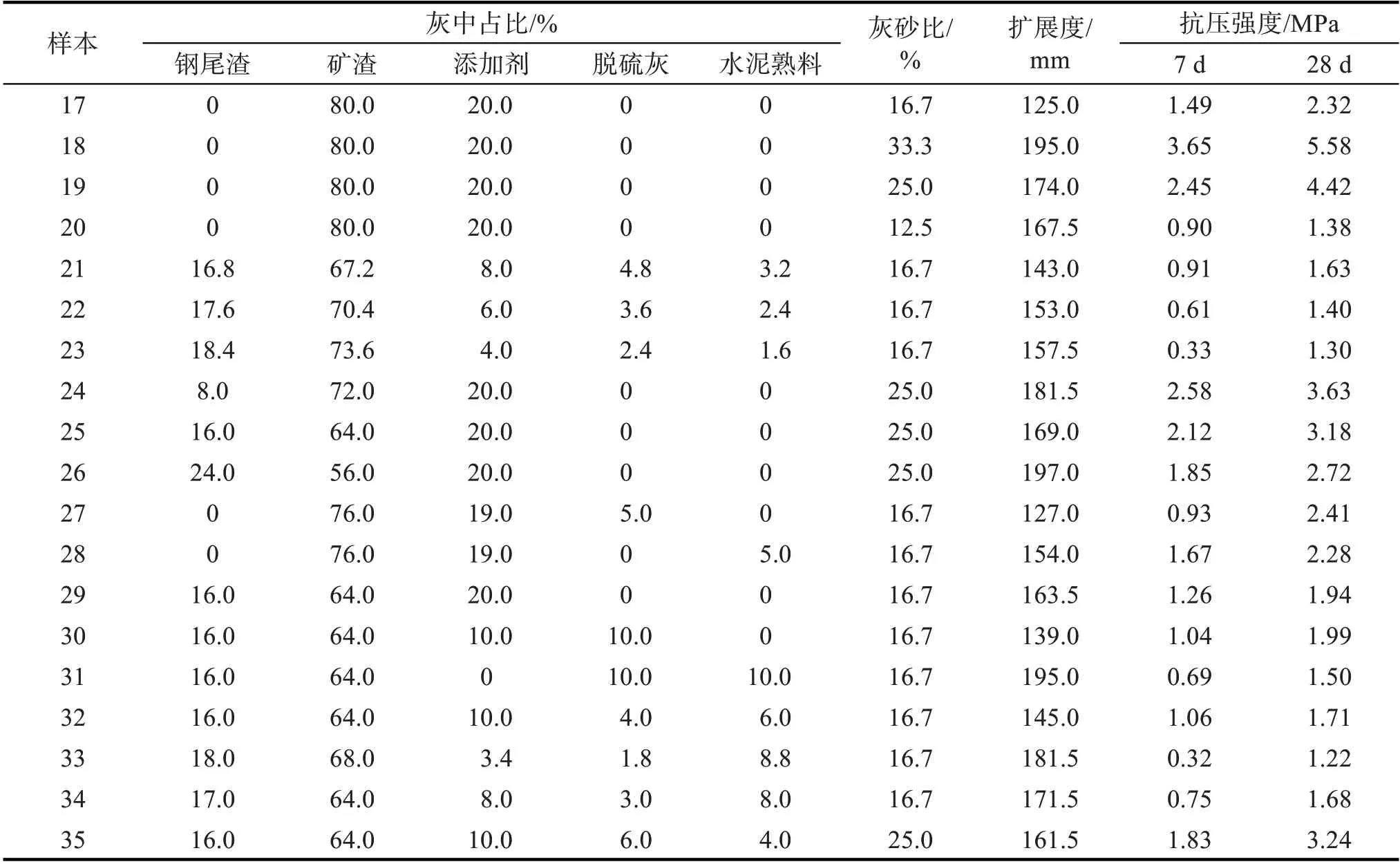
表3 不同条件的试验方案及结果Tab.3 Test scheme and result under different conditions
2.2 模型建立
样本数据均通过归一化处理,数据处理在[0,1]范围易形成极值,使网络深陷。为使训练的网络有足够增长区间,创建网络训练的输入和输出样本后,采用mapminmax 函数将其处理为[0.50,0.95]范围的样本数据,消除因素间水平数量级差别;测试样本同样经过归一化处理,通过该函数的反归一化功能将网络仿真模拟的结果还原为原数量级数据。
采用newff 函数创建BP 神经网络。输入层神经元为6 个,分别为钢尾渣、矿渣、专用添加剂、脱硫灰、水泥熟料的灰中占比以及灰砂比;输出层神经元为3个,分别为扩展度、7 d抗压强度、28 d抗压强度。选取隐含层传递函数tansig,将数据映射在[-1,1];选取输出层传递函数logsig,将数据映射在[0,1]。训练样本个数为35,属于中小型网络。Levenberg-Marquardt算法作为BP 神经网络的改进算法,是梯度下降法和拟牛顿法的结合,收敛速度最快、计算精度较高。故文中采用基于Levenberg-Marquardt 算法改进的训练函数trainlm 对网络进行训练,trainlm在训练样本的同时会检验样本,提高模型的泛化能力。
2.3 模型训练
设置模型训练的目标误差为0.000 1、训练次数为1 000,一旦达到目标拟合误差,训练就停止。隐含层神经元个数的选取是BP神经网络预测模型的关键之一,神经元个数较少,映射关系差,易导致拟合模型难以收敛至目标误差;神经元个数较多,易导致训练次数较少,使网络失去泛化及判断能力。根据经验公式[10],初定隐含层神经元为8~15个,多次运行代码训练不同隐含层神经元个数的BP神经网络模型,以训练次数与拟合相关系数为指标,其模型拟合误差曲线和回归分析曲线如图2。由图2 可看出:隐含层神经元为14 个时,训练次数均较少,为77次;神经元模型拟合相关系数最大,达0.999以上。由此确定隐含层神经元为14个。
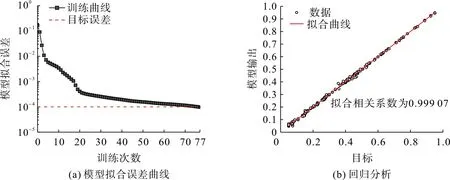
图2 隐含层神经元14个时模型拟合误差曲线和回归分析Fig.2 Model fitting error curve and regression analysis of 14 neurons in hidden layer
3 预测模型的评价与应用
3.1 样本内预测
为检验隐含层神经元为14 个时训练样本的预测误差,随机选择4 组样本预测其扩展度及7 d 和28 d 的强度,结果如图3。结果表明,扩展度和7 d抗压强度最大相对误差分别为0.41%和1.33%,相比之下,28 d抗压强度相对误差略大,最大相对误差为2.23%。以样本9为例,扩展度的预测与实测值分别为165.12,165.00 mm;7 d抗压强度的预测与实测值分别为1.68,1.66 MPa;28 d 抗压强度的预测与实测值分别为2.95,2.85 MPa。3 组数值均比较接近,表明隐含层神经元为14个时模型预测精度较高,在样本内预测效果较好。
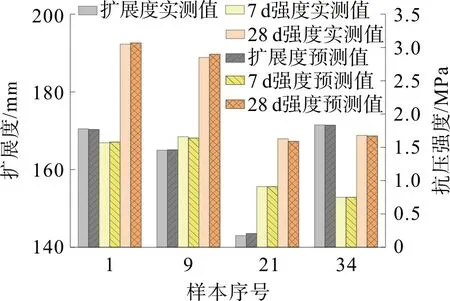
图3 14个隐含层神经元模型样本内预测结果Fig.3 Intra sample prediction results of 14 hidden layer neuron model
3.2 样本外预测
为进一步验证模型对不同配比的适应性,利用14 个隐含层神经元的BP 网络模型对随机配比充填料的料浆扩展度、7 d 和28 d 抗压强度进行预测,随机配比方案如表4。根据随机配比方案制备充填体的料浆扩展度和抗压强度的实测与预测结果如图4。图4 表明,与样本内预测的相对误差相比,样本外预测相对误差较大。以样本39 为例,扩展度的预测与实测值分别为179.56,179.50 mm,相对误差0.24%;7 d 抗压强度的预测与实测值分别为0.26,0.24 MPa,相对误差8.33%;28 d 抗压强度的预测与实测值分别为1.33,1.34 MPa,相对误差0.75%。综合来看,隐含层神经元为14 个时模型具有一定的泛化能力,对样本外的预测仍具有适应性。
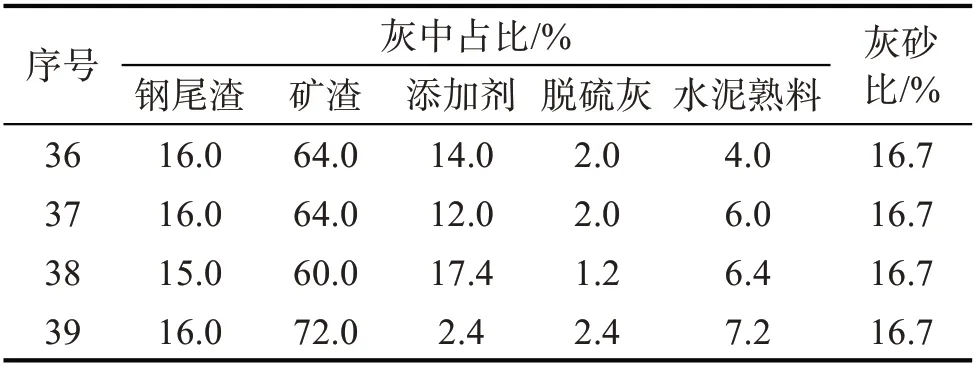
表4 随机配比充填方案Tab.4 Random proportioning filling schemes

图4 14个隐含层神经元模型样本外预测结果Fig.4 Out of sample prediction results of 14 hidden layer neuron models
3.3 原料配比优化应用
以第32 组充填料为例,扩展度为145 mm,7 d和28 d 抗压强度分别为1.06,1.71 MPa。在钢尾渣灰中占比为16%的条件下,将脱硫灰和水泥熟料的灰中占比分别由4.0%和6.0%调整到6.0%和4.0%,通过建立的模型预测其填充料浆扩展度、7 d和28 d抗压强度,结果见表5。经比较分析,优化组预测的性能结果优于32 组充填料的性能。进一步地,根据优化的配比制备充填料,检测发现28 d 抗压强度提高0.42 MPa,即在钢尾渣占比16.0%条件下,优化后m(专用添加剂)∶m(脱硫灰)∶m(水泥熟料)=10∶6∶4,其充填料28 d抗压强度由1.71提高至2.13 MPa。由此看出,本文建立的预测模型可有效指导充填原料配比,提高充填体抗压强度。

表5 原料的优化配比Tab.5 Optimized proportion of raw materials
4 结 论
1)利用35组训练样本建立以钢尾渣、矿渣、专用添加剂、脱硫灰、水泥熟料等掺量与灰砂比为输入,扩展度、7 d 抗压强度、28 d 抗压强度为输出的BP 神经网络预测模型。通过比较试验误差得出:模型预测主要误差来自28 d 抗压强度,预测网络模型的隐含层神经元个数为14 时模型预测精度较高,扩展度的最大相对误差为0.36%,28 d抗压强度的最大相对误差为2.23%。
2)利用建立的BP神经网络模型指导优化充填原料配比,在钢尾渣配比16.0%条件下,通过BP神经网络预测优化外加剂配比制备充填体,其28 d抗压强度由1.71 MPa提高到2.13 MPa,预测与实测结果相差较小,预测精度较高。由此表明,本文建立的BP 神经网络预测模型可用于指导寻求最优充填原料配比,对减少充填实验工作量、缩短实验周期具有一定意义。
