基于CNN-BiGRU的方言语种识别*
2022-07-12刘增力
付 英,刘增力,汤 辉
(1.昆明理工大学,云南 昆明 650504;2.江西省科技基础条件平台中心,江西 南昌 330003)
0 引言
全球化的今天,不同国家不同地区的人们跨语种交流的机会越来越多,随着深度学习技术趋于成熟,语种识别研究也成为众多研究者关注的重点。语种辨识逐渐应用到各个领域,而能否迅速、准确判断说话者所说的语言是其他功能正常运行的基础[1]。方言语种识别是语种识别中的一个特例,由于方言之间具有相似性,因此针对方言语种识别的研究更具挑战性。
语种识别是通过给定一段语音并判别所属区域的过程,其作为语音信号处理的前端技术,在语音识别等相关领域发挥着重要作用,主要应用在语音翻译、公共安全、多语言对话系统等方面[2]。到目前为止,许多技术已成功应用于语种识别中,特别是针对易混淆的方言语种辨识。传统的声学模型如高斯混合—通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[3]、隐马尔可夫模型(Hidden Markov Model,HMM)[4]等常用于语种辨识中,但这些声学模型往往结构复杂且训练时间长。
近年来,深度学习依靠快速的计算能力以及对大数据的分析处理能力,在语音研究领域被广泛应用。早期,众多研究者利用深度学习提取语音深度瓶颈特征(Deep Bottleneck Feature,DBF)[5],替代了传统的GMM-UBM结合声学特征的方法,该特征能高效表征语种信息,使语种更具有区分性,但模型结构较为复杂。之后,基于各种神经网络结构搭建端到端语种辨识系统的方法应运而生。最早Lopez-Moreno等人[6]将深度神经网络(Deep Neural Network,DNN)应用在短时语种识别中。之后,Gonzalez-Dominguez等人[7]提出长短时记忆递归神经网络(Long Short Term Memory-Recurrent Neural Network,LSTM-RNN)用于自动语种识别,有效解决了RNN中梯度消失的问题,但此模型结构复杂且训练时间长。Geng等人[8]搭建了基于LSTM和注意力机制的端到端语种识别系统,并应用在短时语种分类中,但由于LSTM并未考虑到语音未来的信息导致识别效果并不理想。Fernando等人[9]搭建了基于双向长短时记忆网络(Bidirectional LSTM,BiLSTM)的端到端语种识别系统,有效考虑了语音过去和未来的信息,经实验表明,BiLSTM在短时语种识别中表现良好。Mao等人[10]将双向门控循环单元网络(Gated Recurrent Unit networks,GRU)用于多分类语种识别中,相比于BiLSTM网络结构更加简单且识别率有所提升。此外,卷积神经网络(Convolutional Neural Network,CNN)[11,12]也常用于语种辨识中,它提取语音信号的局部特征,有效提升了语种识别效果。
对于语种识别辨识系统,常使用交叉熵(Cross Entropy,CE)损失函数进行分类,但并未考虑到数据不均衡和语种易混淆的问题。2017年,何凯明等相关研究者提出用于密集物体检测的焦点损失(Focal Loss,FL),实验表明,焦点损失能有效解决这个问题,提高模型的性能[13]。Zhao等人将焦点损失作为语音识别任务中的优化策略之一,通过对难易分类的权重不同分配来提高识别率[14]。
基于以上研究,本文首先搭建一个CNN模型,通过对比不同特征提取算法在方言语种识别中的识别效果,选取最佳输入特征;其次,搭建基于CNN-BiLSTM的网络,对比焦点损失不同参数对模型识别率的影响,从而选取最优参数;再次,搭建不同模型对不同时长的方言进行识别,得到最终识别模型;最后,分别采用不同的语音增强方式对数据集进行扩增,提高模型的泛化能力。
1 特征处理
语种识别中常用的声学特征有梅尔频率倒谱系数(Mel-Frequency Ceptral Coefficients,MFCC)[15]、对数滤波器能量(Log Mel-filterbank energy,Log Fbank)特征[16]、语谱图特征[17]等。本文对比以上3种特征,选取识别率最高的特征作为后续模型的输入特征,并且考虑到方言为有调语音,将声学特征与音调特征进行融合,提高方言语种识别率。
1.1 MFCC
由于人耳对声音频率的感知并非呈线性关系,因此使用MFCC特征仿真人耳对声音感知的关系,可近似表示为:
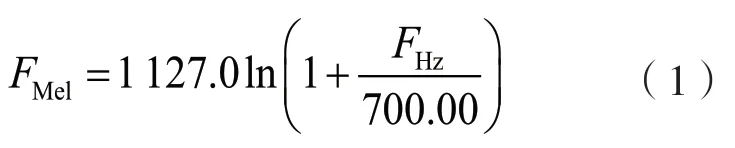
式中:FMel为人耳感知的频率;FHz为声音的真实频率。
提取MFCC特征的流程如图1所示。首先,语音信号x(n)经过预加重(预加重系数为0.97)、分帧(帧长为25 ms,帧移为10 ms)、加窗后得到每帧信号xi(n);其次,对xi(n)进行FFT变换得到频谱Xi(k),并得到对应的能量谱Ei(k);再次,经过Mel滤波器组后得到Si(m),进行对数运算得到Yi(m);最后,进行离散余弦变换(Discrete Cosine Transform,DCT)得到MFCC特征。本文滤波器组数取26,经DCT变换后得到13维MFCC特征向量。
1.2 LogFbank
LogFbank特征的提取与MFCC特征提取过程基本一致,在图1中不经过DCT变换即可得到LogFbank特征。相比于MFCC特征,LogFbank特征向量间具有较高的关联性且耗时短,被广泛应用于神经网络中。本文提取了40维的LogFbank特征作为模型的输入。

图1 MFCC和LogFbank特征提取对比
1.3 语谱图
语谱图是语音信号的频率随时间变化的图像表示,是语音信号经过短时傅里叶变换而得到的,保留了语音信号最原始的信息。语谱图既可以观察频谱的变化过程,又能突出频谱的精细结构,是信号常用的时频分析方法之一。根据窗函数的大小,语谱图可分为宽带语谱图和窄带语谱图。以上海话为例,图2展示了宽、窄语谱图的区别,图2(a)为宽带语谱图,时间分辨率高,而图2(b)频率分辨率高,为窄带语谱图。
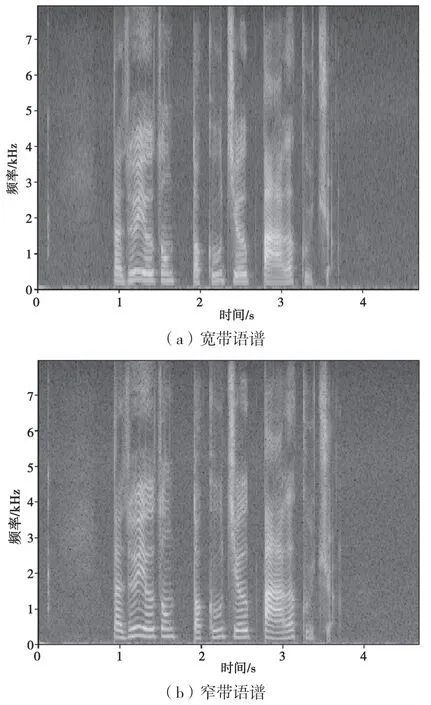
图2 语谱图展示
1.4 音调特征
对于汉语方言而言,音调是方言较为显著的特征,进行汉语辨识时,可利用一种方言中存在这个音调而另一种方言中不存在进行区分。由于传统声学特征只保留语音的音色特征,而忽略了语音的音调特征,所以本文采用短时自相关函数法提取每一帧的基音信息表示音调特征。
2 CNN-BiGRU模型
2.1 CNN
1960年,Hubel和Wiesel[18]两位科学家在猫的大脑中发现不同于常规神经网络的神经元结构,受Hubel和Wiesel对猫视觉皮层电生理研究的启发,Fukushima等人[19]提出了一个包含卷积层和池化层的神经网络结构,由此卷积神经网络诞生。由于CNN网络存在权值共享以及稀疏连接,因此CNN的网络结构大幅度减小了复杂水平。
CNN的结构主要由3部分组成:第1部分是卷积层,它对输入图像进行过滤并通过滑动窗口方法计算与提取有意义的值;第2部分是池化层,本质是一个下采样过程,可减小通过卷积操作提取的特征的大小,常用的池化方式有最大池化和平均池化方法;第3部分是全连接层,和经典神经网络结构一样连接所有的神经元。
2.2 BiGRU
GRU是目前非常流行的一种神经网络,它是LSTM的一种简化网络,2014年由Cho等人[20]首次提出,用于解决长期记忆和反向传播中的梯度问题。与LSTM相比,GRU用更新门代替了LSTM中的遗忘门和输入门,结构简单且参数少,更有利于模型收敛,计算效果和LSTM差不多,一定程度上提高了模型训练的效率,有效缓解了梯度爆炸或消失问题。由于方言之间具有一定的相关性,需要考虑语音数据中的上下文信息,所以本文采用双向门控循环单元(Bidirectional GRU,BiGRU)搭建模型,它是由前向GRU和后向GRU组成,同时考虑了数据过去和未来的信息。
2.3 CNN-BiGRU-MFA
本文提出基于CNN和BiGRU的模型实现方言语种识别,其整体结构如图3所示。该模型主要由Block块、多层特征聚合(Multi-layer Feature Aggregation,MFA)、BiGRU层、全连接层组成,其中,每个Block包含卷积层、ReLU层、批量归一化层。首先,提取方言语音信号的特征输入到卷积块中,利用卷积层提取方言信号的局部特征;其次,利用MFA将多层卷积层特征进行聚合,将整合特征输入到BiGRU层中提取时序相关特征;再次,将BiGRU层的输出特征输入到全连接层中;最后,通过Softmax函数将输出向量映射到(0,1)区间,并计算方言类别之间的概率来预测汉语方言的类别标签。在训练过程中,本文使用焦点损失代替传统的交叉熵损失函数来优化模型参数。
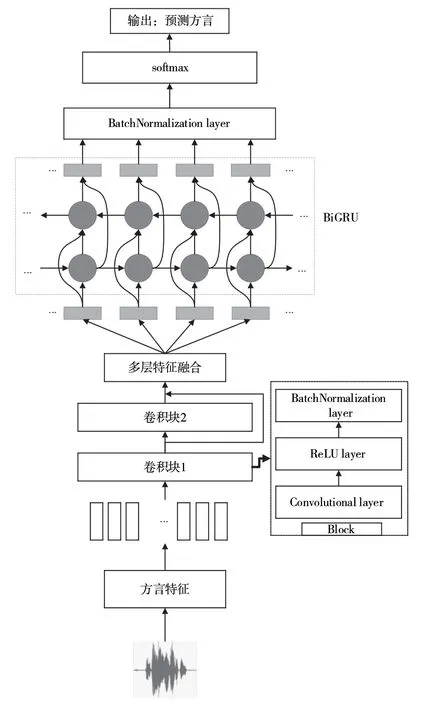
图3 基于CNN-BiGRU的方言语种识别系统结构
3 改进多类别交叉熵损失函数
对于语种识别任务,常使用交叉熵损失函数(Cross Entropy,CE),并将其最小化进行模型优化,CE是计算真实类别标签分布与预测的类别标签分布之间的距离,其定义为:
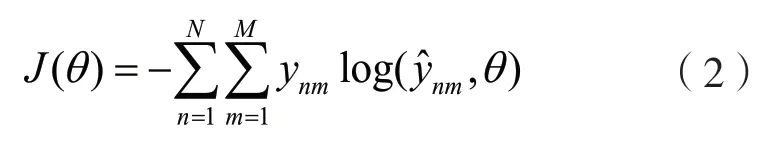
则交叉熵损失函数LCE定义为:

式中:N为语音样本数;M为语种类别数;ynm∈{0,1},如果样本n的真实类别为m时则取值为1,否则为0;y^nm为观测样本n属于类别m的预测概率值;θ为模型的参数;ym为某个类别的真实值;y^m为该类别的预测值。
交叉熵损失函数在样本均衡且易分类的样本中表现良好,但针对本文研究的方言数据具有易混淆性且各样本数据不均衡的情况,引入焦点损失函数作为多语种识别的损失函数。焦点损失是交叉熵损失的一种延伸,本质是使用一个合适的函数衡量难易样本对总损失函数的贡献,并以此优化模型。
针对样本不平衡问题,焦点损失(Focal Loss,FL)引入权重系数α对正负样本的权重进行平衡,减少多样本数据对损失函数的影响,定义为:

α虽然平衡了各个语种之间的样本数,但不能区分相似度较高的语种样本。因此,引入调制系数β调整难易分类的权重,将模型的训练重点放在难分类样本上,定义β为:

此时的焦点损失LFL定义为:

假设式(7)中的pm接近于1时,(1-pm)γ趋近于0,则预测为正确样本数的损失很小,对总的损失贡献减小,其权重下降;反之,当pm的值很小,(1-pm)γ趋近于1时,对总损失贡献较大,权重增大。将α与(1-pm)γ结合,得到最终的FL定义为:

式中:α∈[0,1],γ∈[0,5],当αt=1,γ=0时为交叉熵损失。通过对权重的控制,能较好地区分易混淆的方言语音数据。
4 实验结果与分析
4.1 实验准备
本文实验是基于NVIDIA RTX 3090的硬件平台实现的,所有深度学习模型框架使用Keras框架实现。实验数据来源于4部分,具体如下文所述。
(1)2018年科大讯飞方言保护竞赛数据集。该数据集中每种方言有40人的朗读语音,每种方言训练集有6 000句,测试集有500句,训练集和测试集的说话人均无重复,录制环境有多种场景,以pcm格式存储,16 bit量化,采样率为16 000 Hz。选取其中的8种方言,分别为长沙、河北、合肥、南昌、宁夏、陕西、上海和四川方言。
(2)Common Voice数据集。该数据集覆盖了世界各地几十种不同的语音,语音数据丰富而且质量较好,数据以mp3格式存储。从该数据集下载了粤语用于实验分析。
(3)中国语言资源保护工程采录展示平台。该平台覆盖了全国34个省区市的数据,调查语种包括123种语言和全部汉语方言。在该平台上收集了云南10个地方的方言组成云南话用于研究。
(4)利用各视频网站对方言数据进行收集。考虑到收集的音频数据集少且说话人单一,所以在视频网站收集了长沙、河北、合肥、南昌、宁夏、陕西、上海、四川、云南和粤语10种方言的音视频,以mp4格式存储。
由于收集的方言数据来源广泛,所以需要将方言音频数据统一格式,方便语音处理,统一将数据转化为wav格式的文件,以采样率为16 kHz,16 bit量化,单声道进行存储,共有10种不同的方言种类。
4.2 评价指标
方言语种识别系统的性能评价指标以语种识别正确率Racc进行评价,则有:

4.3 参数设置
本文模型的输入特征分别为MFCC特征、LogFbank特征、语谱图特征以及将LogFbank特征与基音特征F0融合的特征,使用Adam优化器,初始学习率设置为0.001,最小批量大小为64,迭代次数为30,损失函数分别使用交叉熵函数和焦点损失函数对模型进行优化。
4.4 实验仿真与分析
基于CNN-BiGRU的方言语种识别实验主要由4部分组成。实验1:搭建CNN系统,对比不同输入特征的方言识别率。实验2:针对方言易混淆性和数据的不平衡性,进一步研究焦点损失对方言识别率的影响,对焦点损失的权重因子α和调制因子γ不同参数的选取进行了实验仿真,模型基于CNN-BiLSTM-MFA。实验3:对比本文提出的模型与其他模型的识别率,验证本文模型在方言语种识别中是否具有优越性。实验4:采用数据增强方式对训练集进行扩增,提高模型的泛化能力。
4.4.1 实验1
将MFCC特征、LogFbank特征、语谱图以及LogFbank+F0特征作为CNN的输入。卷积层的卷积核大小为3,卷积步长为1,填充方式为same,卷积层输出后经过批量归一化层、激活层后再进行全局平均池化,最后经全连接层后对方言识别分类。实验结果如表1所示。

表1 不同特征提取参数方言识别结果
从表1可以看出,方言语种识别结果依次是LogFbank+F0>LogFbank>语谱图>MFCC。由于LogFbank特征向量之间的相关性以及方言的有调性,选择LogFank+F0特征作为后续研究的输入特征。
4.4.2 实验2
为了选取FL的最佳参数,采用控制变量法对α∈{0.25,0.5,0.75},γ∈{1,2,3,4,5}进行不同时长方言识别率对比实验。分类模型采用CNN-BiLSTMMFA,模型结构依次为卷积块、卷积块、多层特征融合、双向LSTM层、全连接层。实验结果图4所示。

图4 不同α和γ时,方言识别率对比
从图4中可以看出,FL不同参数的选择对难易样本权重加权比例有影响。当α=0.5,γ=2时,不同时长的方言识别率都达到了最高,识别率分别达到了81.12%,84.58%,85.03%,86.44%。
4.4.3 实验3
为了评估所提方法的有效性,对比不同模型对不同时长的方言的识别率,本文的基线系统采用2018年科大讯飞方言识别竞赛所提供的识别模型LSTM-DNN-CE。模型结构依次为输入层(输入维度为(None,None,41))、LSTM层(隐藏层节点数为128)、全连接层(神经元个数为10),并使用Softmax函数对方言进行分类。在此基础上分别搭建了6种不同的模型进行对比:模型1为GRU-DNNCE模型,模型结构与基线系统类似,将LSTM层换成GRU层;模型2为BiLSTM-DNN-CE模型,考虑到语音的上下文相关性,将基线系统的LSTM层替换成BiLSTM,节点数保持不变;模型3将模型2中的BiLSTM换成BiGRU层,节点数保持不变;模型4为CNN-BiLSTM-MFA-CE,具体在基线系统的基础上加入两层卷积块,模型结构如实验2所示,并使用交叉熵损失函数进行优化;模型5为CNNBiGRU-MFA-CE,具体是将模型4中的BiLSTM层换成BiGRU层,并使用交叉熵损失函数进行优化;模型6为CNN-BiGRU-MFA-FL,是将模型5中的交叉熵损失函数换成本文提出的焦点损失函数。实验结果如表2所示。
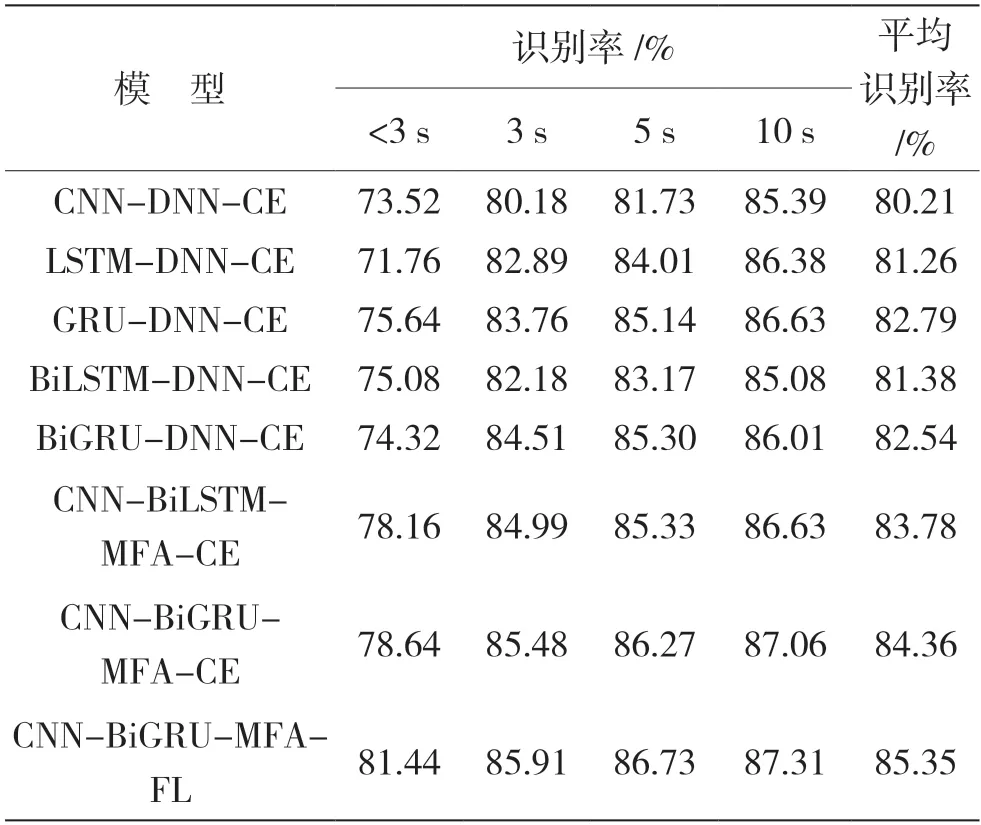
表2 不同模型的对比结果
从表2可以看出,CNN能有效提取方言信号的局部特征,但由于方言是时序序列,LSTM等变体能较好表征语音中的时序信息,因此将两者进行结合,可以提升对不同时长方言的识别率,进一步验证了所提模型对方言分类有效。另外,使用FL代替CE,进一步提高了不同时长方言的识别率,相比CNN-BiGRU-MFA-CE模型,平均识别率提升了0.99%。最终,选择CNN-BiGRU-FL作为本文的识别模型,相比于基线系统,所提方法平均识别率提升了4.09%。
4.4.4 实验4
由于方言数据多数是在纯净环境下录制且数据量少,所以使用audiomentations工具包对方言数据进行增强,增加方言数据量和噪声数据,提高模型的泛化能力和鲁棒性。主要增强方式如表3所示。
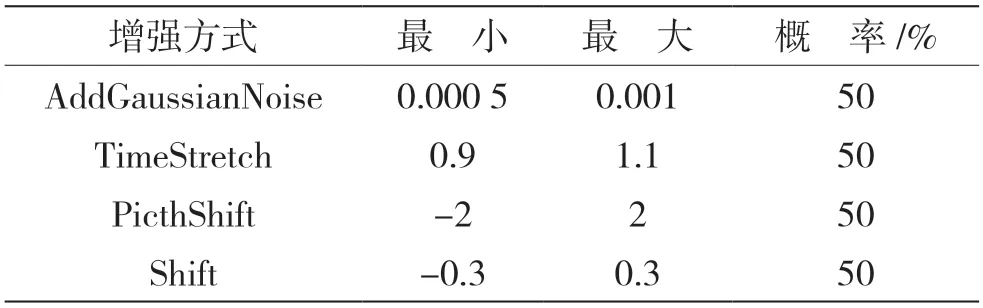
表3 数据增强参数设置
在相同环境下,使用实验3中选择的最优模型CNN-BiGRU-MFA-FL进行实验仿真。通过表3中的增强方式对语音数据进行增强,比较不同时长方言识别率的大小。共仿真了5组对比实验,其中第1组是采用原始数据进行训练得到不同时长测试集的识别率,其余4组为随机选取25%的数据集进行数据增强后的识别结果,实验结果如表4所示。
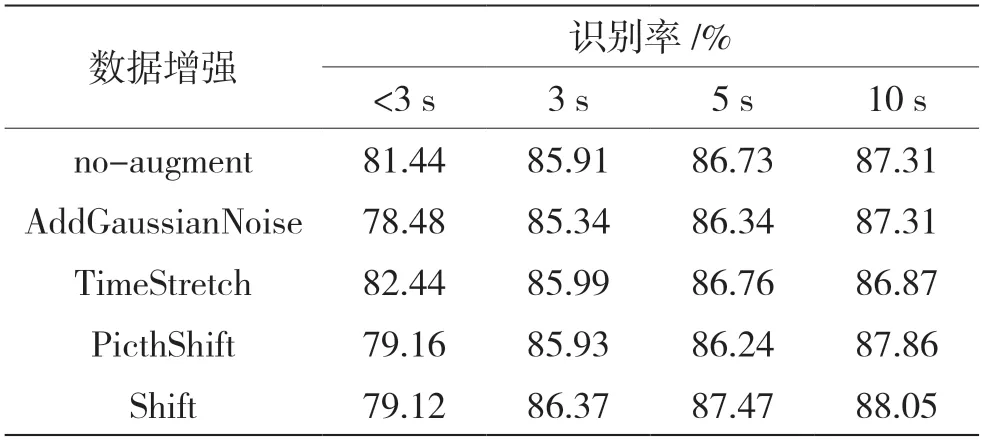
表4 数据增强对方言识别率的影响
从表4可以看出,相比于不进行数据增强,使用不同的增强方法对方言识别均有一定的影响,采用添加高斯噪声的方式增加训练集虽然对方言识别率影响不大,但提高了模型的泛化能力,其余3种增强方法对不同时长方言数据的识别率有不同的提升,其中采用时移变换Shift的增强方法有效提升了方言语种识别率。
5 结语
针对汉语方言易混淆且识别率低的问题,本文首先应用CNN网络搭建方言语种识别系统,对比了不同输入特征对方言语种识别率的影响,选取了LogFbank特征融合基音特征F0作为最佳输入特征;其次,针对方言数据集不均衡且易混淆的问题,使用焦点损失函数代替交叉熵损失函数,为难易方言种类分配不同的权重对模型进行优化,经过不同参数对比,最终选择权重因子α=0.5和调制因子γ=2作为焦点损失函数的最终参数;再次,对比了不同模型对不同时长方言语种的识别率,实验结果表明,本文所提模型CNN-BiLSTM-MFA-FL相比其他模型对方言语种的识别效果更好,能够更有效地提升方言语种识别的准确率,相比于基线系统,本文所提方法准确率提升了4.09%;最后,使用语音增强的方式对方言数据进行扩增,提高模型的泛化能力和鲁棒性,仿真显示,采用数据增强的方式对方言数据进行扩充,能提升模型泛化能力和不同时长方言的识别率。
