基于机器学习建模的DGA恶意域名检测*
2022-07-12罗鹏宇
王 伟,罗鹏宇
(1.中国电子科技网络信息安全有限公司,四川 成都 610041;2.中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
随着互联网应用的持续发展和终端用户数量的爆炸式增长,网络化的生活和虚拟化的资产使得互联网已成为人们日常生活中必不可少的一部分。域名系统(Domain Name System,DNS)[1]是网络中最常见的基础设施,但由于存在缺陷常常被僵尸网络[2]、钓鱼网站[3]等恶意网络行为利用。攻击者会按照目标定位、侦查跟踪、武器构造、载荷投递、漏洞利用等常规的杀伤链[4]步骤进行攻击,并执行远程命令与服务器进行连接来完成“C2控制”,期间攻击者会使用一种名叫domain-flux[5]的技术。domain-flux技术主要通过不同的算子生成大量不同域名生成算法(Domain Deneration Algorithm,DGA)家族[6]的原始域名,被感染主机会查询大量的DGA恶意域名并仅和攻击者注册的少部分有效域名建立连接,攻击者通过这种方式访问远程服务器以达到躲避安全检测的目的。由于DGA域名数量巨大且恶意网络难以被识别,因此精确检测与封堵DGA域名意义重大,且随着《中华人民共和国网络安全法》[7]的颁布,网络安全[8]的保障工作早已迫在眉睫。
为了检测DGA域名,蒋鸿玲等人[9]提出了基于多层感知器训练算法模型来检测恶意域名,通过6个维度构造算法特征,并通过对比各个不同模型结果的ROC曲线面积(Area Under Curve,AUC)值来找出最优的分类算法,此方法具有较好的特征提取思路,但特征略微单一,无法稳定地检测和识别恶意域名。Yadav等人[5]提出了通过jaccard[10]距离来比较恶意域名与正常域名之间的bigram集,并使用可编辑距离来衡量一个恶意域名转换为正常域名所需的字符更改数,此方法对于字符混杂性高的恶意域名具有很高的区分度,但无法区别字符混杂度较低的恶意域名。裴兰珍等人[11]提出了一种面向字符的采用卷积神经网络(Convolutional Neural Networks,CNN)深度学习的DGA域名检测模型,该模型由字符嵌入层、特征检测层和分类预测层组成,在对历史沉淀数据的检测中具有简洁高效的特点,但无法应对智能化域名生成机制所产生的DGA域名。
为了对抗智能化DGA域名生成机制,Woodbridge等人[12]提出了基于长短期记忆网络(Long Short-Term Memory,LSTM)的DGA域名检测方式,该方法避免了手工创造特征的繁琐,通过智能化网络的方式快速提炼数据之间的关系和训练算法模型,且能够快速地检测DGA域名,但该方法无法深度刻画DGA域名特征和识别后发的恶意域名。罗赟骞等人[13]提出一种融合深度学习中CNN模型和循环神经网络(Recurrent Neural Network,RNN)模型的集成模型检测方法,该集成检测方式通过对输入字符进行自动编码后,分别从空间和时间的角度提取字符特征,具有较好的耦合性,但由于模型体量太大且时间复杂度较高,无法做到实时检测。
为了解决实时检测的问题,Sharifnya等人[14]提出了一个用于检测DGA僵尸网络的新型信誉系统,该系统通过计算可疑矩阵来评估主机的可疑分值,对分值较低的主机进行恶意标识。该方法具有较高的检测率且能做到实时检测,但无法识别domain-flux技术生成的变种DGA域名。赵科军等人[15]使用基于word-hashing的深度模型检测DGA僵尸网络,首先基于word-hashing技术将域名转为二元语法字符串,其次利用词袋模型把域名映射到高维向量空间,最后利用神经网络训练分类模型。该方法具有新颖的特征提取思路,并能从数据集中发现抽象化的特征,但由于训练样本太少导致模型不具备代表性。Yu等人[16]提出了一种基于深度学习的DGA检测方式,通过收集19个家族的DGA数据,将每一个家族的数据进行清洗过滤后,分别训练不同的算法模型,通过对比不同算法模型的训练结果来抉择不同DGA家族最适宜的分类模型。该方法提供了较好的分类思路,对于不同的DGA家族可以采用不同的算法检测模型,且同一家族可以采用多种不同的分类算法来提高检测性能。袁辰[17]提出了一种基于对抗网络的恶意域名检测方法,通过训练生成式对抗网络(Generative Adversarial Networks,GAN)模拟domain-flux技术来生成域名字符向量,并借鉴one-hot和n-gram的思想给出域名序列以用于LSTM训练检测模型。该方法通过模拟DGA恶意域名的生成对DGA恶意域名进行预测和检测,具有较新颖的设计思路,但通过GAN网络生成的DGA域名具有较大的不确定性,导致用于训练LSTM模型的DGA域名和实际的检测场景可能会有较大的差异。
为了解决数据波动的问题,Dahal等人[18]提出了一种基于自动编码器模型的DGA域名识别方法,模型由37层的输入层、16层的编码层和2层的输出层构成,通过输入收集的alexa[19]白样本数据以及标注的11个黑样本家族DGA域名数据来训练编码器模型。该方法的有效检测率能达到88%,且相较于LSTM模型,对于未标注的DGA恶意域名具有较好的检测能力,但由于模型复杂性较高且随着数据量的增加,模型的体量呈几何级数增长,使得该模型不具备可移植性。王震[20]提出了一种基于支持向量机(Support Vector Mac,SVM)算法的DGA域名检测模型,通过机器学习的方式提取域名长度、域名熵、元音字母比例、连续辅音字母比例、数字比例5个维度的特征来区分DGA域名和正常域名,并在此基础上增加隐马尔科夫特征来进一步识别长度较短的DGA域名。此方法具有较高的检测率和较好的检测思维,但由于黑样本数据集太少且特征覆盖面不足的原因,无法检测变种度较高的DGA恶意域名。
DGA域名的检测是一个复杂且重要的问题,相对其他恶意程序,由DGA域名引发的僵尸网络危害程度更高、防御难度更大,因此僵尸网络已成为安全领域学术研究和讨论的热点问题,而现有的DGA域名检测技术在时间性上无法及时检测DGA域名,在延伸性上无法有效识别后发的DGA域名,在精确性上也无法准确识别恶意变种的DGA域名。针对以上问题,本文提出一种基于机器学习算法建模的DGA恶意域名检测方法,通过数据标注、数据预处理、特征提炼和算法建模等流程来训练DGA检测模型。该算法模型体量轻、耦合性高,能对未知的域名做自动评估与自动归类,并能准确地检测与识别DGA域名。
1 数据集
数据集是一堆数据的集合,覆盖了模型所需的所有数据,数据集的质量决定了算法模型的上限,丰富的数据集能涵盖较多的样本集,有助于特征工程提取有价值的特征用于模型训练。本文数据集由Alexa数据集、DGA家族数据集、中文拼音[21]数据集3部分构成,如表1所示。Alexa数据集是Alexa官方发布的包含几十亿网站链接的全世界网站排名数据,该数据集具有一定的权威性,DGA数据集包含bamital、cryptolocker、emotet、rovnix、tinba等在内的50个DGA家族数据,由于不少域名如链家官网(cd.lianjia.com)、安居客官网(chengdu.anjuke.com)等是按照汉语拼音来构造的,因此加入了中文拼音数据集以全量覆盖样本集。
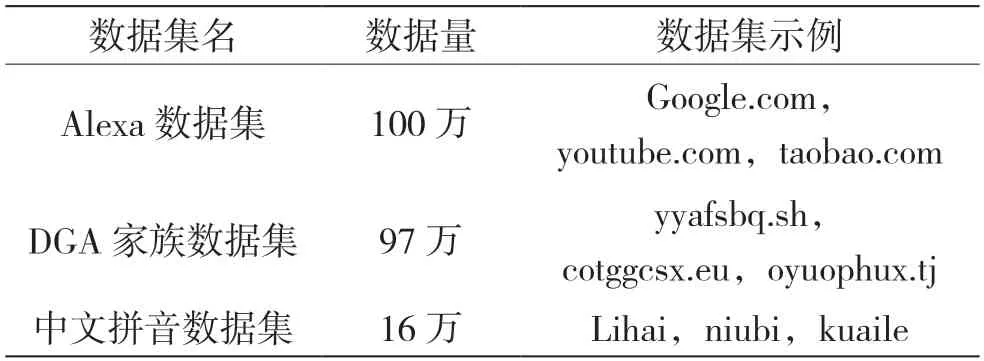
表1 模型使用的数据集
2 域名实体抽取
域名是具有一定意义的字符串,同IP地址一样用于在互联网上标识不同的单位、机构或机器,域名通常由域名前缀、域名主体、域名后缀3部分构成。域名后缀是指代表一个域名类型的符号,不同的域名后缀有不同的含义,如“.cn”代表中国,“.jp”代表日本,“.com”代表公司等。域名主体和域名后缀组合在一起如“qq.com”即为一级域名,域名前缀和一级域名组合在一起如“www.qq.com”和“mail.qq.com”就为二级域名。域名主体通常由企业名称构成,两个不同的一级域名如“taobao.com”和“taobao.cn”的域名主体相同,代表着相同的域名关键信息。由于域名前缀和域名后缀种类繁多,且攻击者会变换不同的域名前缀和域名后缀来改变域名以达到迷惑攻击的目的,导致过多的域名前缀和域名后缀对关键信息提取有较大的干扰作用,故仅保留单个域名的域名主体作为信息输出。
本文使用Python编程语言的tldextract第三方包来提取单个域名的域名主体,tldextract有一个公共后缀列表用以匹配所有的域名,使得tldextract可以准确地从域名和子域名中分离出其顶级域名和域名主体。
3 特征工程
特征工程是指将数据集进行数据规约、数据加工、数据转化的一个数据处理过程。特征工程是嫁接数据预处理输出和算法模型输入之间的中间桥梁,具有“承上启下”的作用。特征工程作为数据预处理的输出,能对有限的数据集进行关键信息概括和重要信息提取,同时特征工程作为算法建模的输入,能将低维度特征的文字信息通过多个算子处理和转换为机器可识别的高维度特征。特征工程的信息提取精度决定了算法模型的性能瓶颈和上限,好的特征工程能极大地提升模型的精度上限,有效减少模型的训练时长和降低模型的体量载荷。本文分别从语义性、连贯性和可读性上来构建算法特征,包括字符特征、字符序列特征、隐马尔科夫链特征、可读性特征和语音特征5大类特征。
3.1 字符特征
图1展示了字符特征的子特征分类。字符特征总共由9个子类构成:
(1)域名字符长度;
(2)域名中元音字母的占比;
(3)域名中辅音字母的占比;
(4)域名中数字的占比;
(5)域名中重复字母的占比;
(6)域名中连续数字的占比;
(7)域名中连续辅音字母的占比;
(8)域名中连续两字符为一元音和一辅音的字符占比;
(9)域名信息熵。
域名的信息熵计算公式为:


式中:p(xi)为随机事件为xi的概率。信息量是一个具体事件发生所带来的信息,信息熵为该随机变量所有可能的取值情况,熵越大,对应的信息量越大。
图1为字符特征的子特征分类。

图1 字符特征分类
3.2 字符序列特征
字符序列特征是一种基于统计语言模型的特征,其基本思想是将文本里面的内容按照字符大小为N的滑动窗口进行分割,形成长度为N的字符序列,并对所有的字符序列进行频率统计,以此计算出整个域名数据集的N元字符序列集。基于马尔科夫链[22]假设,当前字符的频率p(wi)只与其前N-1个字符有关,即得到链式规则为:
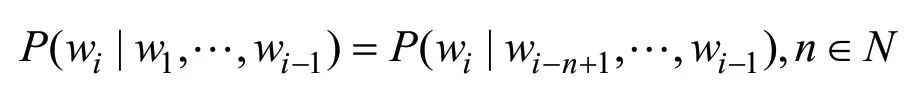
基于对N元字符序列集的统计分析,合法域名的N元序列频率较高,DGA域名由于字符组合奇异等原因其N元序列频率相对较低,同时结合时间复杂性和空间占用率等因素分析,发现2元字符序列和3元字符序列区分性较强,2元字符序列和3元字符序列公式为:
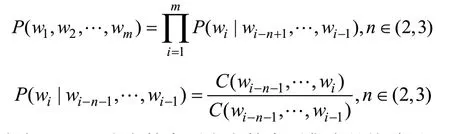
式中:C(wi)为字符序列在字符序列集中的统计量。
将求得的2元序列向量和3元序列向量进行求和平均等函数计算,把多元向量化为一元向量作为特征属性值,以此来体现合法域名和DGA域名之间的差异性。
3.3 隐马尔科夫特征
隐马尔科夫[23]是一种关于时序的概率模型,含有未知参数的马尔科夫链会生成不可观测的状态随机序列,隐马尔科夫模型则用于观测和描述这个状态随机序列的生成过程。隐马尔科夫模型中,S={s1,s2,…,sn}是所有可能的状态集合,O={o1,o2,…,om}是所有可能的观测状态集合。
将域名中出现的字符视为长度为T的状态序列I={i1,i2,…,iT},Q={q1,q2,…,qT}是其对应的观测序列,即可计算出域名中字符Ai到Ai+1的概率隐含状态转移概率矩阵为:
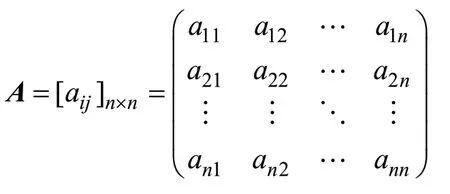
式中:aij为在时刻t处于状态si条件下,下一时刻t+1转移到状态sj的概率。以域名的字符为例,abw为当前位置字符为b而下一位置字符为w的概率,其表达式为:
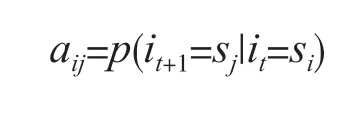
B为可观测值转移概率矩阵,其表达式为:

式中:bij为在时刻t处于状态si的条件下生成观测值oj的概率。以域名字符为例,bq1为当前这一字符为q,但这个字符串为DGA域名的概率,其表达式为:
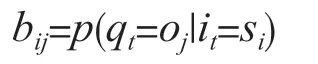
π是初始状态概率向量:
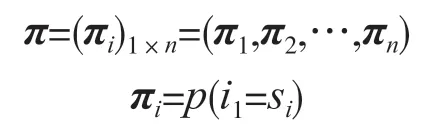
式中:πi为在时刻t=1处于状态si的概率,以域名字符为例,πb为域名初始首字符为b的概率。
所以隐马尔科夫模型可以由隐含状态转移概率矩阵A、可观测值转移矩阵B和初始状态概率向量π表示为λ=(A,B,π)。
结合时序性和空间性来生成的隐马尔科夫特征对域名具有很强的分辨能力,常规普通域名由于字符之间往往具有可循的规律,其隐马尔科夫特征值较高,而DGA域名的混杂程度和突发性较强,其隐马尔科夫特征值对比常规域名具有较大的偏差。
3.4 Gibberish特征
Gibberish特征[24]是通过单词之间的逻辑语义性来检测一句话是可读的人类语言还是由机器随机生成的,使用这个特征是基于DGA域名相较于正常域名而言其可读性较差的经验。首先统计一篇足够长的训练语料中字母之间的出现次数来算得频数方阵C:

由频数方阵来计算出条件概率方阵P:
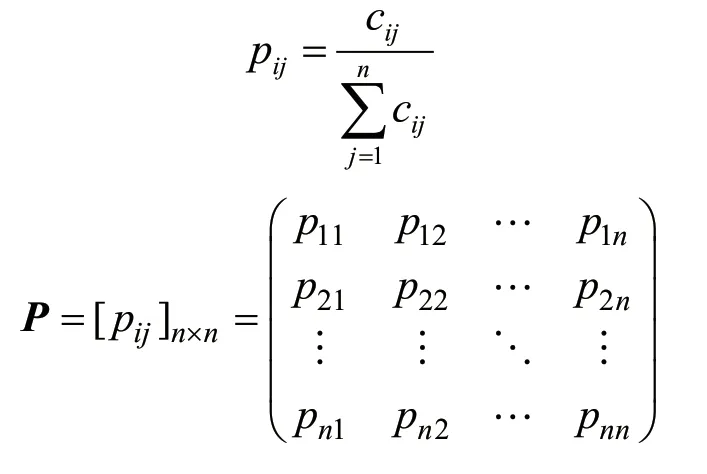
对于需要判断的文本,将其拆解为2-gram词组:
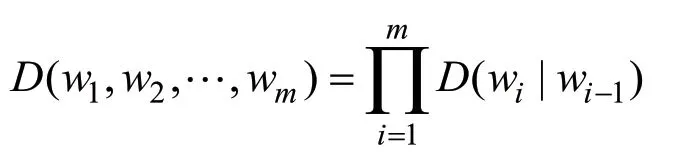
对于每个词组,在条件概率方阵中查找其对应的条件概率,并得出整个文本的概率平均值G为:
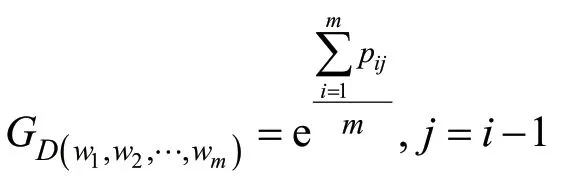
将此概率平均值作为这个词组的Gibberish特征值,若此Gibberish特征值较低,则说明该词组字符间的次序性与概率分布有偏差,可能为随机生成的DGA域名。
3.5 语音特征
语音匹配算法[25]常用于搜索超大文本语料库和修正拼写错误,主要思路是以一个关键词作为算法输入,然后输出一个经过语音算法处理的语音字符串,这个语音字符串用于表示关键词的语音特征和语音信息,语音相似的输入单词其对应输出的语音字符串也相似。在DGA域名识别领域引入语音特征,将域名作为关键词输入,借助语音算法简洁高效的特性来对域名进行编码和抽象化,高度抽象化的常规域名和DGA域名在结构上具有明显的不同。图2为语音算法逻辑。

图2 语音算法逻辑
4 算法建模
算法建模步骤会把特征工程产出的高纬度特征和算法模型进行结合,并通过算法计算来得出最终的输出结果。本文采用梯度提升树(Gradient Boosting Decision Tree,GDBT)来进行算法建模。GBDT的核心思想是在迭代过程中拟合每棵子树的残差来降低树的损失函数。在迭代过程中每棵子树通过计算平方误差来判别其最佳划分点,并把当前子树的残差值作为下一个迭代目标,以此迭代,直到残差接近或达到某个阈值时停止迭代。对于训练数据集D={(x1,y1),(x2,y2),…,(xn,yn)},二元GBDT分类算法的损失函数L为:

式中:f(x)为单个回归树(Regression Tree,CART)的输出结果。CART树的初始值f0(x)为:
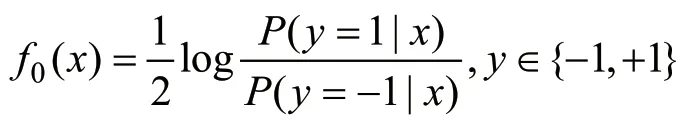
对每一轮迭代t、训练样本i对应的负梯度误差为:

式中:∂为单个回归树输出结果的偏导数。
对于所有的概率残差{(x1,Et1),…,(x2,Eti)}拟合一棵分类树,并计算各个叶子节点的最佳负梯度拟合值:

式中:Rtj为第t轮迭代树的叶节点区域;J为分类树t的叶子节点个数;c为常量函数。使用近似值替代最佳负梯度拟合值,则有:
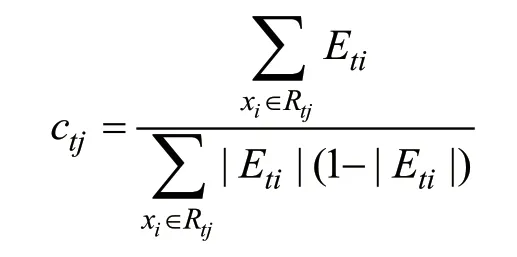
用本轮的拟合函数更新强学习器ft(x)为:

以此迭代,得到最终的强学习器f(x)为:
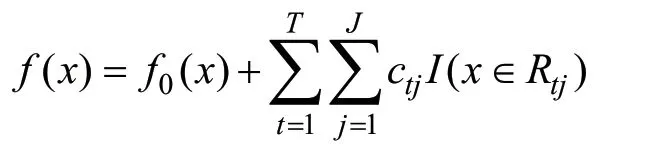
f(x)是由预测概率值和真实概率值的差值来拟合的函数,最后将预测概率值转换为对应的类别,则有:
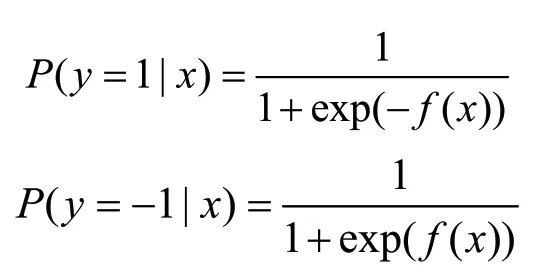
GBDT算法可以灵活处理各种类型的数据,相较于支持向量机等算法而言,GBDT仅用较少的调参就可以达到较好的预测效果,且算法的容错性高,异常波动数据对算法的影响较小,图3为GBDT和整个算法框架流程。
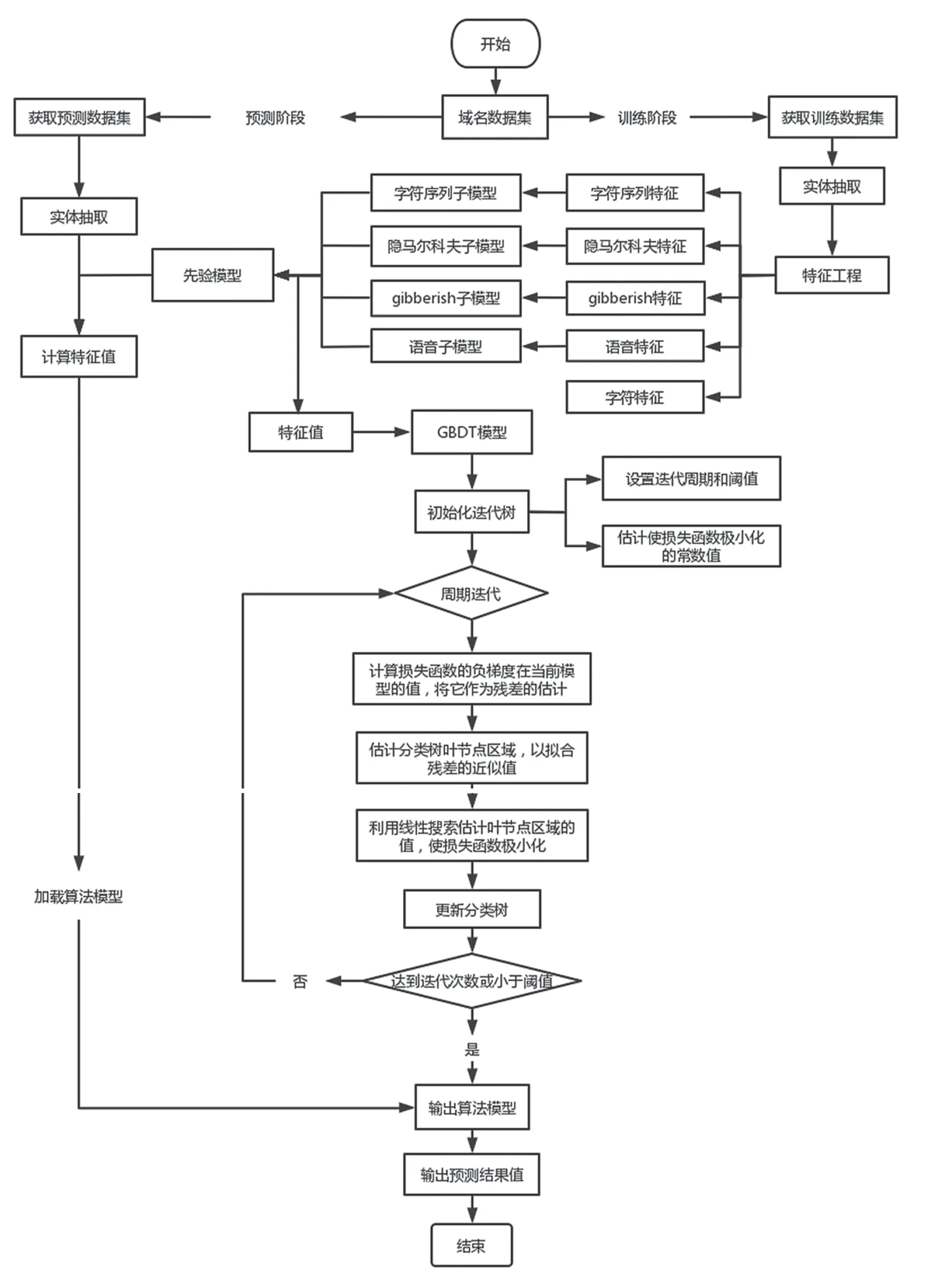
图3 算法框架流程
5 性能测试与分析
测试数据集来源于网上开源黑样本数据集、流量日志抓包还原后并经过安全专家分析的数据集和行业安全公司提供的权威数据集共3部分。测试数据集经过实体抽取、特征值计算后,加载算法模型进行预测评估,结合混淆矩阵评价指标得到表2的测试结果。

表2 不同测试集的测试结果
算法模型在3个不同来源的数据集上的检测效果均较好,同时为了避免数据偏差和数据耦合性,使用random_data数据集随机抽取部分数据并测试,测试结果表明检测性能稳定在7 000条每秒,召回率稳定在97%上下,准确率稳定在98%左右,此检测方式的测试结果与其他评估方法的对比如表3所示。
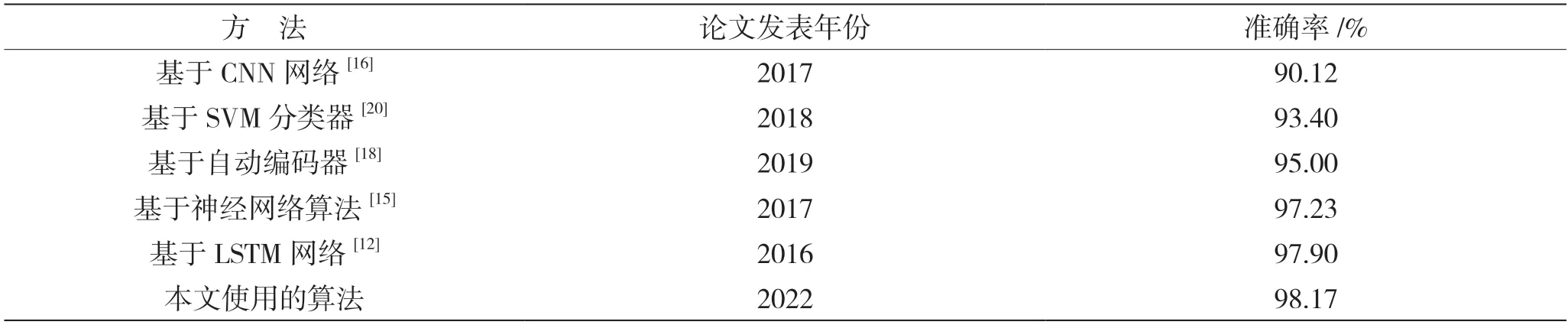
表3 不同评估方法的准确率对比
综上所述,基于机器学习建模的DGA域名检测方法具有较好的检测率,且相较于其他评估方法,此模型克服了DGA域名更替速度快而导致的数据偏差的问题,解决了不同的DGA家族域名繁杂、模型数据波动的问题,同时此模型使用了自然语言处理的特征思维,具有较强的可解释性,且易于更新与部署,适应网络安全业务与算法的融合。
6 结语
本文研究了基于机器学习建模的DGA恶意域名检测模型,实现了对DGA域名的自动化智能检测,通过分析现有DGA域名检测方法的不足,提出了一种基于机器学习建模的检测方式。此方式融合了自然语言特征和机器学习检测思想,同时结合了域名实体提取技术,使得模型具有以下优点:在及时性上,模型能及时响应与发现网络异常并准确识别与拦截DGA恶意域名;在可解释性上,模型融合了字符特征和时序特征,能形象概括字符间的共性和差异;在准确性上,模型准确刻画与提炼每个DGA家族的特征行为,兼顾对每个家族域名的准确检测。此智能检测方式有效地减轻了人工劳动的同时,实现了对DGA域名的精准封堵,并利用机器学习技术对DGA域名进行高纬识别,有利于机器学习算法在网络安全领域的应用,并对网络安全的防御起到引导作用。
