基于随机森林算法的轨道站点短期客流预测
2022-07-11许文星
许文星 章 玉
(重庆交通大学交通运输学院1) 重庆 400074) (中铁长江交通设计集团有限公司2) 重庆 401147)
0 引 言
客流量是轨道运营单位开展运力配置、列车运营计划编制和站点工作人员配备的基础,是对未来城市轨道交通开展可行性评估的重要依据[1].准确的客流量预测有助于轨道交通运营部门制定合理的列车行车计划,保障市民的出行需求,尤其是在重大节假日和重要活动举行期间,提前对站点客流进行预测,有助于确保轨道交通运行顺畅.
国内外学者对轨道交通客流预测方法研究较为深入,多种理论和算法如灰色理论、Kalman模型、小波理论、深度学习、时间序列、遗传算法,以及组合模型等被用于轨道客流预测研究中.Zhang等[2]提出了一种基于支持向量回归的混合预测模型,该模型利用随机森林选择信息量最大的特征子集,并利用混沌特性的遗传算法来识别最优预测模型参数,以此来提高短时交通流预测的准确性.Liu等[3]将深度学习的建模技巧和交通领域的相关知识应用到地铁乘客流量的预测中,提出了深度客流(DeepPF)预测模型,该模型预测精度较高且能适应交通运输中的多种条件.Liu等[4]针对假期轨道客流特性,提出了最小二乘支持向量机(LSSVM)预测模型,并用改进的粒子群优化(IPSO)算法来优化参数,用假期间的轨道客流数据对其有效性进行了验证.Chen等[5]构建了基于经验模式分解(EMD)和长期短期记忆(LSTM)的EMD-LSTM混合预测模型,并用于轨道站点进站客流预测.秦利南等[6]在自回归滑动平均算法(ARMA)算法和神经网络(RBF)神经网络算法的基础上,提出了ARMA-RBF组合算法,此算法可对由时间序列构成客流数据集进行变点处理,再利用小波变化对变点数据集去噪,以此来提高站点进站客流预测的精度.杨静等[7]针对轨道交通客流存在非线性分布的特征,提出了包含小波变化和变点模型的小波ARMA组合模型,结果表明其计算速度和结果都优于单一同类型预测模型.李兆丰等[8]以长短期记忆循环神经网络(LSTM)神经网络为基础,建立多特征融合组合的客流预测模型,在客流预测时考虑时间特征、空间特征和其他因子等因素,其预测精度优于ARIMA模型和LSTM模型.李丽辉等[9]构建了基于随机森林回归算法的短期客流预测模拟,研究影响高速铁路客流生成的因素及其重要程度.
目前国内外学者在研究轨道交通短期客流量预测方法时,多将深度学习方法和计算机语言结合来建立恰当的短期客流量预测方法,其中线性理论、非线性理论和组合理论是研究轨道交通短期客流量预测的常见理论方法[10],此类方法利用大量历史客流出行数据对提出的预测模型进行训练,从而得出客流量生成规律,以此来预测轨道交通短期客流量,但未考虑站点自身属性和其他客观因素.随机森林算法是Breiman在基于优化决策树和组合机器学习而提出的一种机器学习算法,这种算法主要用于解决分类问题和回归问题.在分析影响轨道站点客流生成因素的基础上,文中提出了一种基于随机森林回归算法的轨道站点短期客流预测模型,并用重庆轨道交通3号线客流AFC刷卡数据对该模型的预测结果进行验证.
1 轨道交通站点客流特征分析
不同类型的轨道交通站点周围用地性质存在差异,用地性质对其影响主要包括使用模式或建筑环境、交通可达性、区域经济发展现状、周边人口密度等因素,由此产生的客流在时间和空间上存在分布不均,站点客流潮汐现象较为明显.根据重庆轨道交通3号线AFC刷卡数据统计分析,不同的轨道交通站点特征属性不同,站点客流量也存在明显的差异,大部分站点的进出站客流量呈现波动变化,客流量高峰和潮汐现象明显,轨道站点周围的用地性质对客流出行影响较大.
1.1 站点客流变化
选取四种类型的轨道交通站点在某1个月内站客流量变化规律见图1.因站点周围用地性质和站点功能不同,导致站点客流量变化差异性较大.对于临近商业用地的轨道交通站点客流量变化较大,且非工作日的客流量大于工作日的客流量;临近办公和居住用地及为换乘站点的轨道交通站点客流量变化较小,但临近居住用地的轨道交通站点工作日客流量略大于非工作日客流量;该月最后1 d临近节假日,所有类型站点的客流量都明显增加,因此节假日因素对进出站点的客流量影响较大.
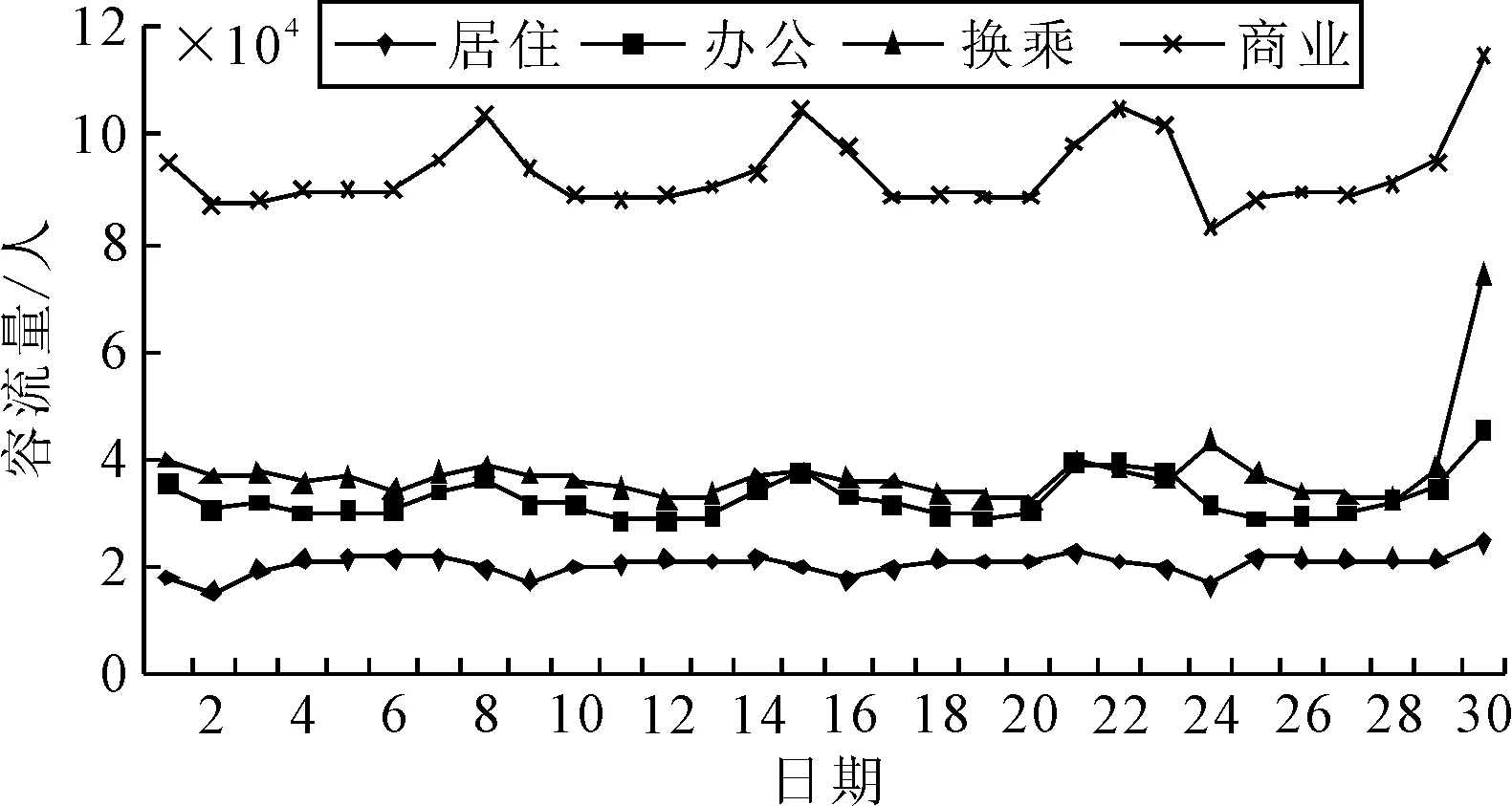
图1 轨道站点客流量
1.2 站点客流高峰时段变化
选取四种类型的轨道交通站点在1 d内小时客流量变化见图2.不同轨道交通站点工作日客流量早高峰主要集中在08:00—09:00,晚高峰主要集中在18:00—19:00,非工作日客流量早高峰主要集中在09:00—10:00,晚高峰主要集中在19:00—20:00,高峰时段期间的站点客流量较其他时段增加明显,其他时段期间站点客流量变化平稳,但商业用地附近的站点受周边商业影响,站点整体客流量较大,居住用地附近的站点客流量高峰现象最明显,换乘站点的客流量变化最小.

图2 轨道站点小时客流量
1.3 轨道站点客流潮汐现象
选取四种类型的轨道交通站点在某1周内站点客流量潮汐现象变化见图3.对于站点附近用地性质为居住用地的轨道交通站点,在早高峰时期进站客流远大于出站客流,因此其早高峰潮汐比较大,而换乘站点和商业用地附近的站点潮汐比变化最小,居住和办公用地附近的站点早晚高峰的潮汐现象比较明显,且四类站点的第五个工作日潮汐变化最明显.

图3 轨道站点潮汐性
2 基于随机森林回归算法的短期客流预测模型
2.1 建立样本迭代集
根据统计学原理建立一个总体样本容量为N的轨道站点进出站客流量集,通过有放回地随机抽取n个样本作为预测模型的训练集P(X,Y).其中:X={x1,x2,…,xn}作为模型训练过程中的样本集,xi(i≤n)是样本集中的第i个样本;Y={y1,y2,…,yp}是影响客流预测的标准化值,每一个样本均对应一组标准化值,yj∈{α1,α2, …,αz}是第j个样本的标准化值;剩余未被抽中的数据则作为样本测试集(X*,Y*),它们在统计学上被称为袋外数据(OOB).
2.2 构建回归决策树
在建立单棵回归决策树时,由于每棵决策树都有自己的特征值且相互独立无约束,故在分枝节点处的所有特征值中随机抽取特征值作为分枝的依据.为提升预测速度和准确性,决策树在分枝时是根据最小信息化原则,依据各个子节点的基尼不纯度平均减小值来确定最优分类特征,并进行下一个子节点的分枝过程,形成没有约束的回归树模型.假设单棵回归树生长有M个节点,则单棵回归树的基尼指数为
(1)
式中:(Xi,Yj)为第i个样本对应的第j个特征值(i=1,2,…,n;j=1,2,…,O);m为单棵树的节点序号(m=1,2,…,M).
当第m个节点分枝成两个节点后,两个节点处的基尼指数将趋向最小化,并将该特征值对应的基尼指数作为m节点处的确切基尼指数:
|Gini(m),v|=min{Gini(s)|s∈m}
(2)
式中:v为节点m的分枝层数.
为提升运算效率,需要对决策树的大小进行控制,控制的方式主要有2种:①停止分裂;②对决策树进行剪枝.
2.3 构建随机森林决策树
需要在基于建立好的单棵决策树基础上进一步建立整个随机森林决策树.①将抽取的n个样本集建立的单棵决策树作为训练集进行循环深度学习训练,袋外数据作为最终建立的预测模型的预测集;②从含有n个样本集的迭代集中选取t(t≤n)个需要进行分枝的样本作为备选分枝样本,再按照构建单棵树的方法寻找每棵树的最优分枝点并进行分枝;③每棵决策树在分枝时都是自上而下和逐层分枝的,随机森林法可以根据分枝后节点的大小而控制决策树的生长,可以人为的控制决策树的分枝次数,也可有限制地让决策树自由生长再寻求最优单棵决策树;④经过多次循环学习训练得到t棵最优决策树,再生成整体误差最小的随机森林模型B={h(Q,θt)|t=1,2,…,n}.其中:θt为第t棵回归树;Q为影响客流量生成的因素对应的特征值集合;h(Q,θt)为第t棵回归树的预测值.由于生成的随机森林是多元非线性回归分析模型,因此随机森林预测值是t棵回归决策树预测值的平均值.
2.4 模型误差分析
用构建的随机森林模型进行预测后,需要建立恰当的评价指标来验证模型的准确性.在模型验证时,可以用均方根误差(RMSE)来验证最终预测结果和预测集中原始数据的误差大小,值越低则误差越小;可用取值范围为0~1的拟合优度(R2)来验证预测结果的拟合程度,值越高则表明最终预测结果和预测集拟合程度越好;平均相对误差(MRE)则反映了最终预测结果和原始数据偏离的大小,计算值越低模型的预测准确性越高.三个评价指标RMSE、R2、MRE的表达公式为
(3)
(4)
(5)

3 案例分析
3.1 数据来源
选取重庆轨道3号线中的4类站点为研究对象,站点0附近的用地性质为居住用地,站点1附近的用地性质为办公和教育用地,站点2为换乘站点并与交通枢纽站相连,站点3附近的用地性质为商业用地.从轨道交通AFC刷卡数据中提取2017年4月1日—2018年12月27日四个站点每日的进出站点客流量作为实验样本数据,用构建的随机森林回归算法模型对四个站点的进出站客流量进行预测,并用误差评价指标RMSE、R2、MRE对预测结果的准确性进行验证.
3.2 参数设置
在利用构建的模型进行轨道站点短期客流预测时,需要根据模型适用条件和外界因素对模型设置参数,见表1.为提升模型的准确性和运行速度,将前626组数据集作为训练集,后10组数据集作为测试集,每组数据集中都包含影响客流生成的七个影响因素,并将影响因素进行标准化;随机森林棵数设置为100,因每个站点的属性不同,所以每个站点对应的随机森林树分枝层数不同,为提升预测准确度,随机森林树的最终分枝层数由预测误差最小时对应的分枝层数确定.

表1 特征值标准化处理对照表
3.3 预测结果及误差分析
用建立好的随机森林回归算法模型对测试集数据进行测试,对四个轨道交通站点的日进出站点客流量进行预测,其预测结果和分析误差见图4和表2.

图4 进出轨道站点客流量预测值

表2 误差分析表
由图4可知:进出站点客流量预测值和实际客流量值相差较小,但12月24—25日2 d的客流量预测值和客流量实际值相差略大,主要受交通管理部门对某些轨道交通站点进行管控的影响,此客流变化规律也可为应对站点发生大客流时提供参考;由表2可知:在进站客流量预测中,站点1的拟合程度略低,主要受学生出行的影响,在出站客流量预测中,站点3的拟合程度略低,主要受附近商业吸引的出行人数和交通管控的影响,因此在非工作日期间应对此类站点做好引导工作,避免出现客流长时间拥挤现象;进出站的平均相对误差分别为3.91%和2.73%.从整个预测结果和误差分析而言,该模型的预测准确性较高,可用于轨道站点短期客流量预测.
4 结 束 语
分析影响站点客流生成的因素,将随机森林理论应用于轨道交通站点短期客流量预测方法研究中,构建出基于随机森林回归算法的轨道站点短期客流预测模型,并通过相关数据验证.结果表明:模型用于预测轨道交通站点的短期进出站客流量准确性较高.后续研究将在确保该模型应用过程中准确性的基础上确定随机森林决策树的数量展开.
