内河无人船的驾驶行为决策模型
2022-07-11张庆年吴绩伟
杨 娇 张庆年 杨 杰 阮 军 吴绩伟 凌 强
(武汉理工大学交通与物流工程学院1) 武汉 430063) (武汉理工大学信息工程学院2) 武汉 430070)
(上海国际港务(集团)股份有限公司3) 上海 200135)
0 引 言
随着无人驾驶技术的推广应用,无人船已成为继无人机、无人车后新的研究热点,并且某些领域有逐步取代普通有人驾驶船的趋势.
目前,对无人船驾驶行为决策的研究较少,且大多基于知识规则库和学习的方法研究[1],而基于知识规则库[2]的方法常难以应用于复杂、不确定的场景.基于学习的深度强化学习方法,近年被广泛用于无人驾驶决策问题.其中,DDPG因其简化了求解过程而被广泛运用[3],但其对超参数敏感,总导致策略次优[4],针对其缺点进行改进后得TD3算法,其性能等远超过DDPG.
近几年,无人船的避碰决策及避碰路径规划是驾驶行为决策的研究热点.Zhang等[5]提出了一种基于层次深度强化学习的自主导航决策模型,结果表明改进的DRL算法可提高导航安全性和避免碰撞.Wang等[6]为实现未知环境下USV的智能避碰和路径规划,建立了基于强化学习的路径规划算法模型.Guo等[7]提出了将DDPG与人工势场相结合获得改进的DRL来实现无人船的自主路径规划,结果证明此方法可以更好的实现自主路径,但文中未考虑船舶的运动模型和实际验证环境.Liu等[8]为解决多船避碰问题,建立了目标船舶避碰风险度分级的交互界面以提高船员的决策速度.但因碰撞风险的相对性和不确定性,船舶会遇时无法快速、准确地获得统一的碰撞风险评估.Jie等[9]提出一种智能船舶类人决策识别模型和一种新的机动决策因素标准化原则.但其需数据驱动,模型的准则也过于粗略,不具有实际操作意义.
文中基于TD3算法,结合《内河避碰规则》(以下简称《内规》)和驾驶经验,建立内河无人船的驾驶行为决策模型.
1 TD3算法
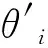
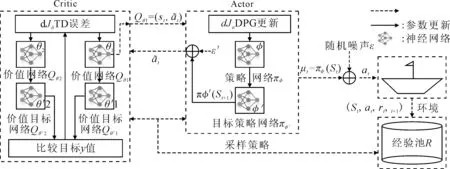
图1 基于TD3算法的无人船自主决策学习过程
步骤1初始化价值网络Qθ1,Qθ2和策略网络πφ的参数θ1,θ2,φ.

步骤3初始化经验池R.
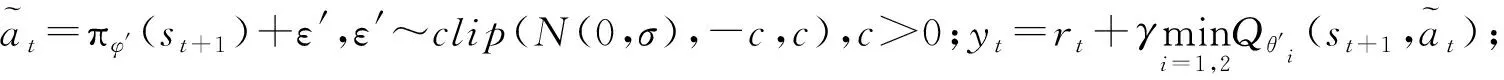
步骤5直到无人船到达终点状态或周期数达到设计值.
2 无人驾驶船舶的驾驶行为决策模型
2.1 内河避碰规则
当无人船自主决策时,其自身为“本船”(OS),而其他船舶,即避碰的目标船视为“碍航船”(TSs).根据《内规》第10~12条的规定,将会遇船分别定义为直行船和让路船.为保证安全,OS作为直行船时也保持警惕,随时进行避让.图2为以OS为中心会遇态势.具体场景的航行规则见表1,图3为部分会遇态势的图示.
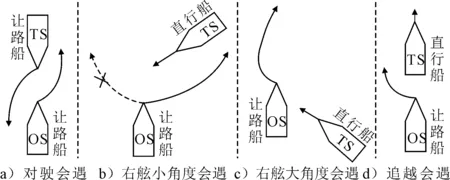
图3 不同会遇态势下的行为决策示意图
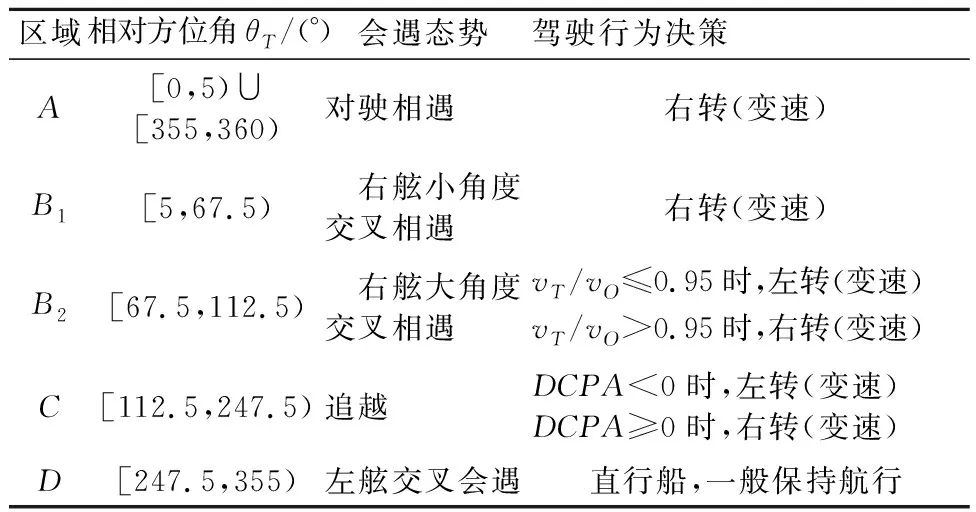
表1 内河船舶航行规则
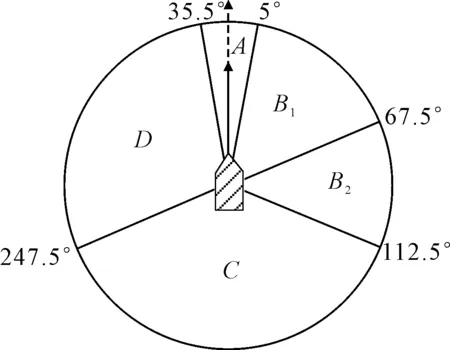
图2 船舶会遇态势
2.2 船舶领域
选取彭延领[10]对船舶领域定义的航行领域和碰域来衡量碰撞危险度.据文献[11]选取适用的参数,得四种领域的相对位置关系图(见图4),得出航行领域和碰域的表达式,分别为
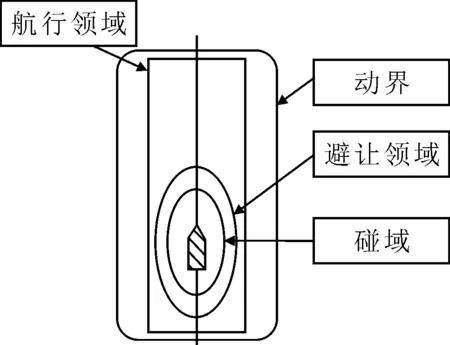
图4 船舶的四种领域相对位置图
(1)
式中:vo为实际航速;vA为平均速度;d+d′为水线面以下深度的最大值;d为最大吃水;d′为富裕水深;h+h′为水线面以上高度的最大值;h为船舶的净空高;h′为高度安全余量.
(2)
参数解释同式(1).
2.3 算法要素设计
2.3.1状态空间设置
假设本研究中的OS及其周围检测范围内的一切碍航物及水域情况等信息,均可获得.将状态s定义为智能体 (Agent) 在给定的单位时间步长t接收到的环境信息.状态空间为s((x0,y0),v0,φ0,(xT,yT),vT,φT).其中,(x0,y0)为OS的位置[19];v0为OS的航速;φ0为航向;(xT,yT)、vT、φT为TS对应的量.这些指标也作为神经网络的输入.其相关的量均可根据计算公式由以上四个量得到,其表示的几何意义见图5.
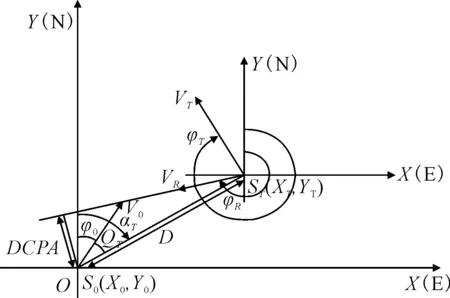
vR-两船的相对速度;φR-相对速度方向;D-两船的相对距离;aT-TS相对于OS的真方位;QT-TS相对于OS的舷角;DCPA-最近会遇距离.
2.3.2动作空间
在避碰时,Agent通过更改航向和(或)速度来确保在复杂水域中的航行安全,同时需结合专家经验和内河避碰规则等进行最终决策.在自主决策系统中,无人船需经过充分的训练才能自主决策.定义无人船右转时,取其航向的改变量at为正值;当左转时取负值.定义其决策动作空间的范围为[-Δφ,Δφ],Δφ为在给定的单位时间t内无人船的航向改变量.
2.3.3励函数设计
奖励函数由三部分组成:安全性奖励函数、经济性奖励函数和协调性奖励函数,见式 (3).奖惩值由查阅文献后,放入模型进行仿真,采用效果最佳的值.
R=ηRc+(1-η)RD+Rg
(3)
式中:Rc为安全性奖励函数;RD为经济性奖励函数;Rg为协调性奖励函数;η为调节安全性奖励函数和经济性奖励函数的比例参数.本文经调整后取0.8.
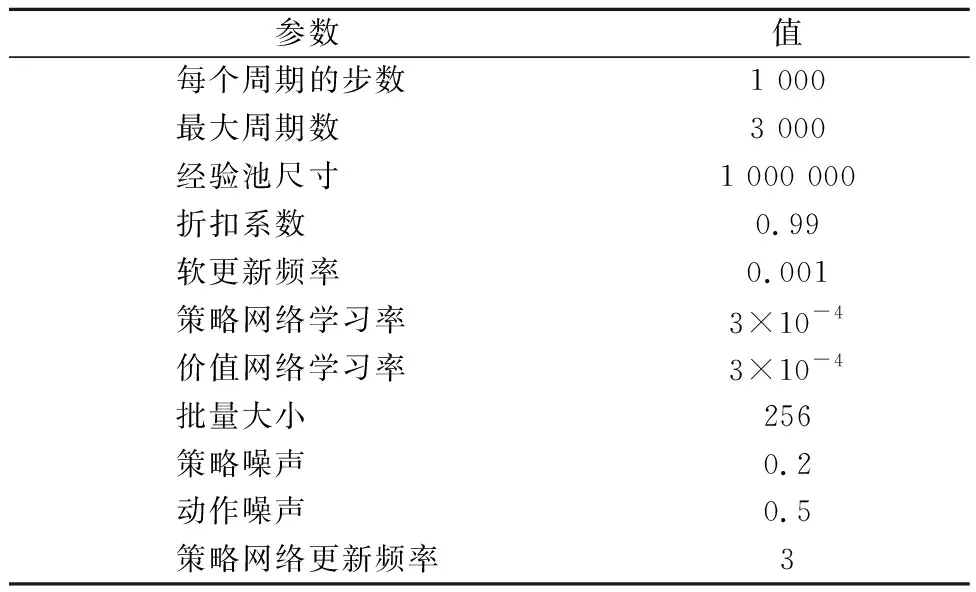
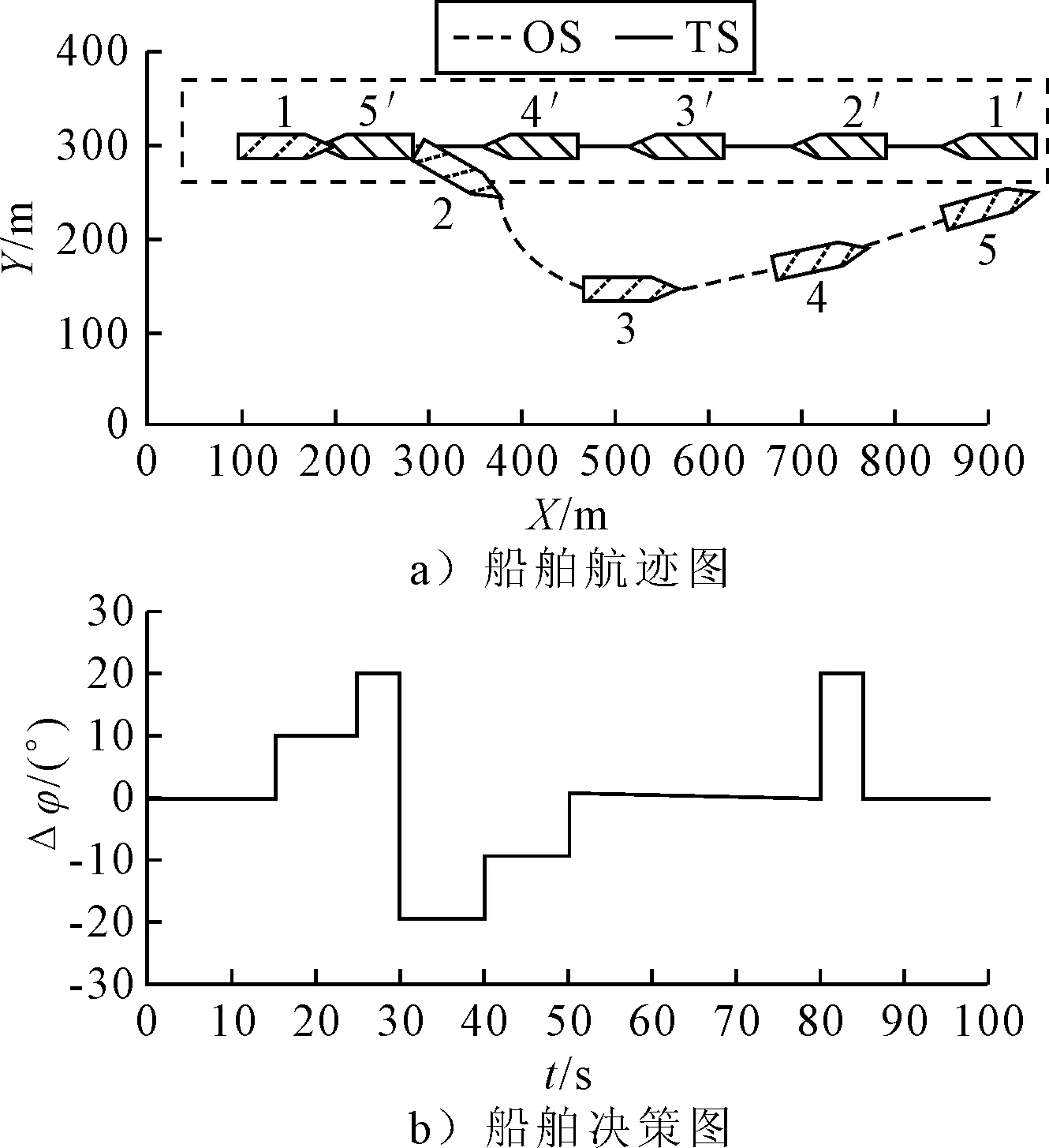
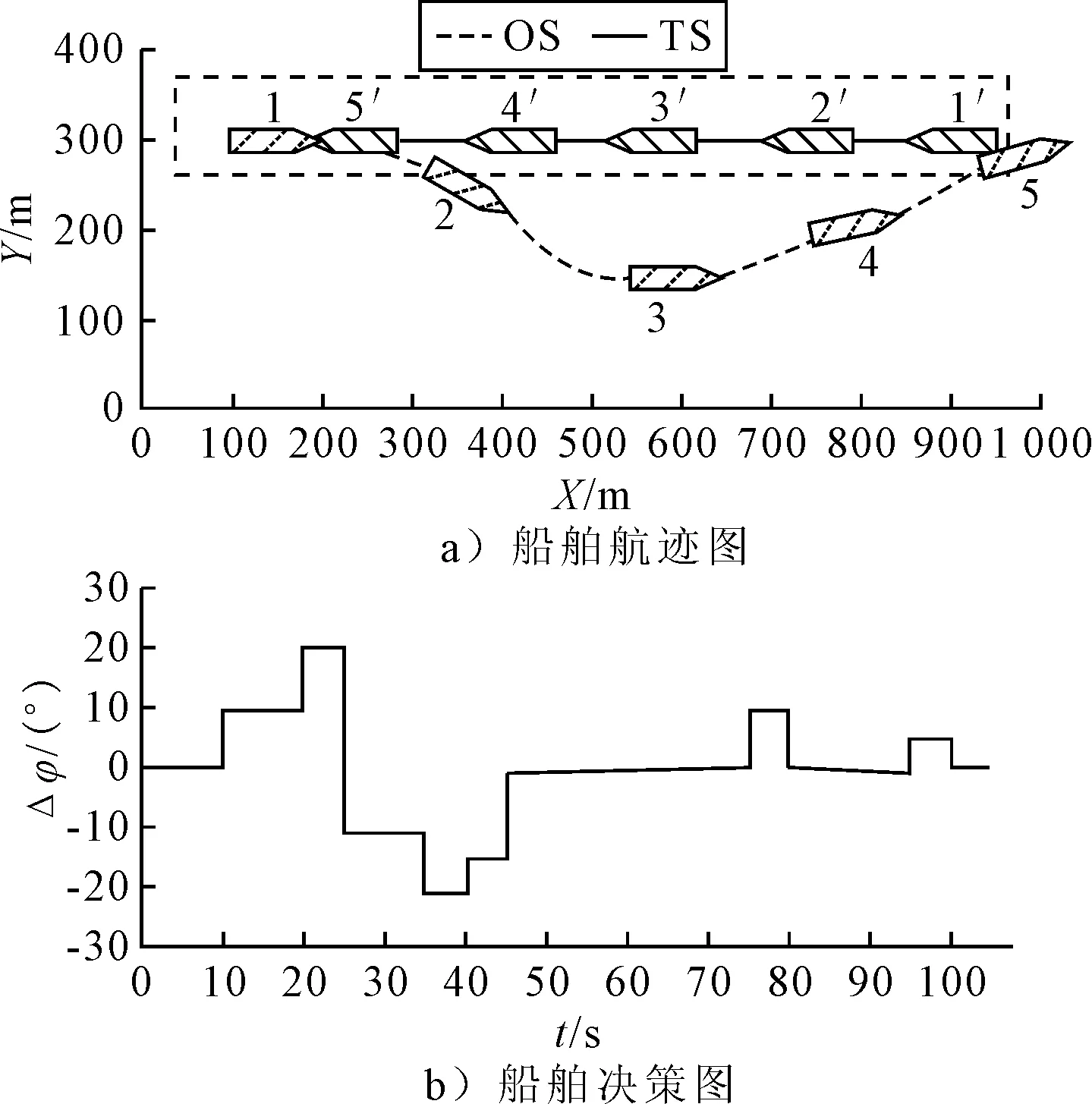
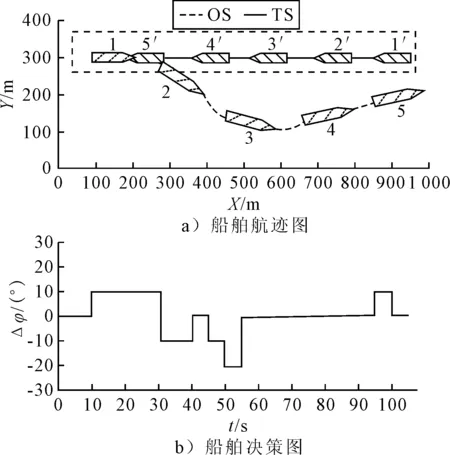
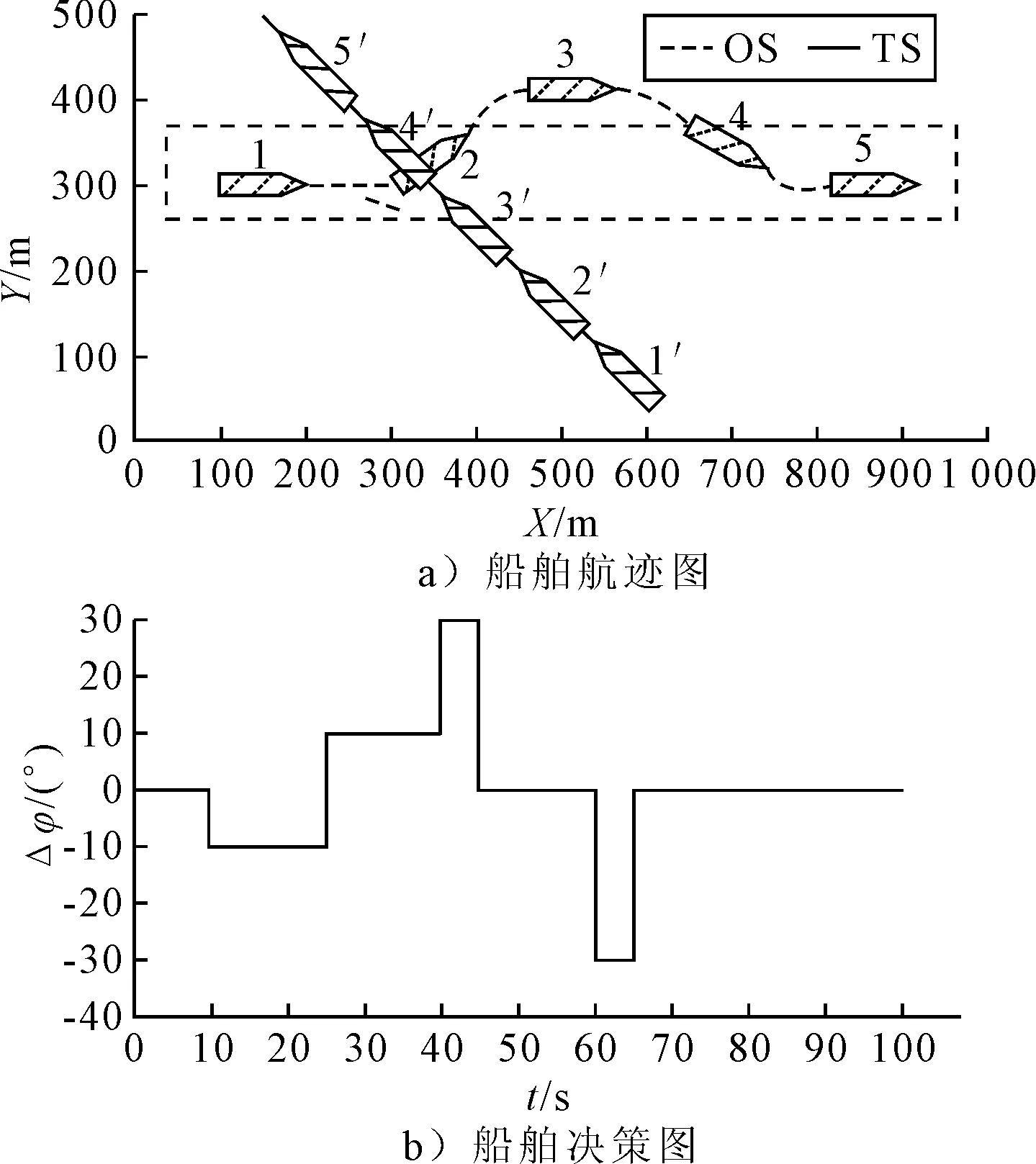
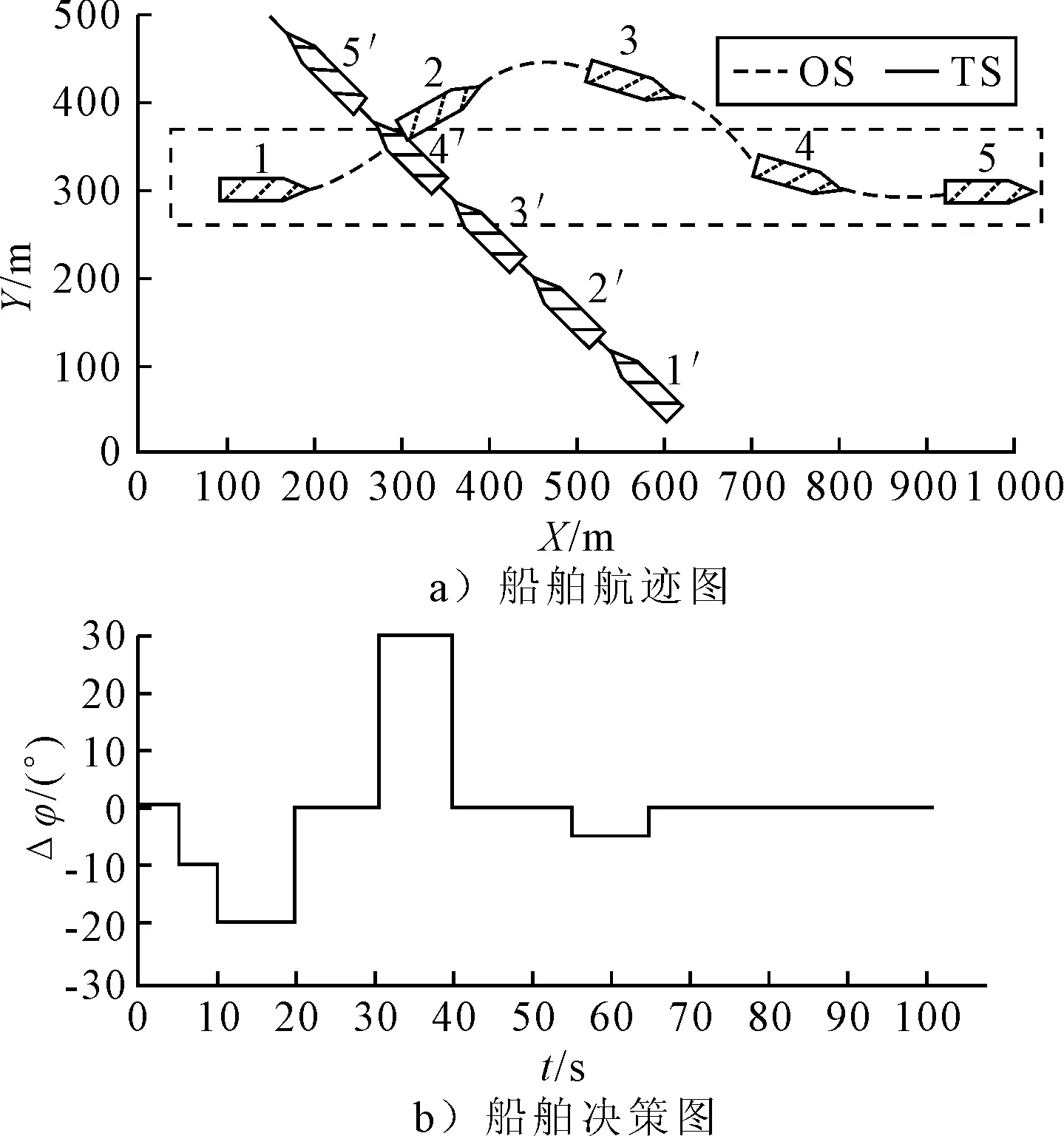
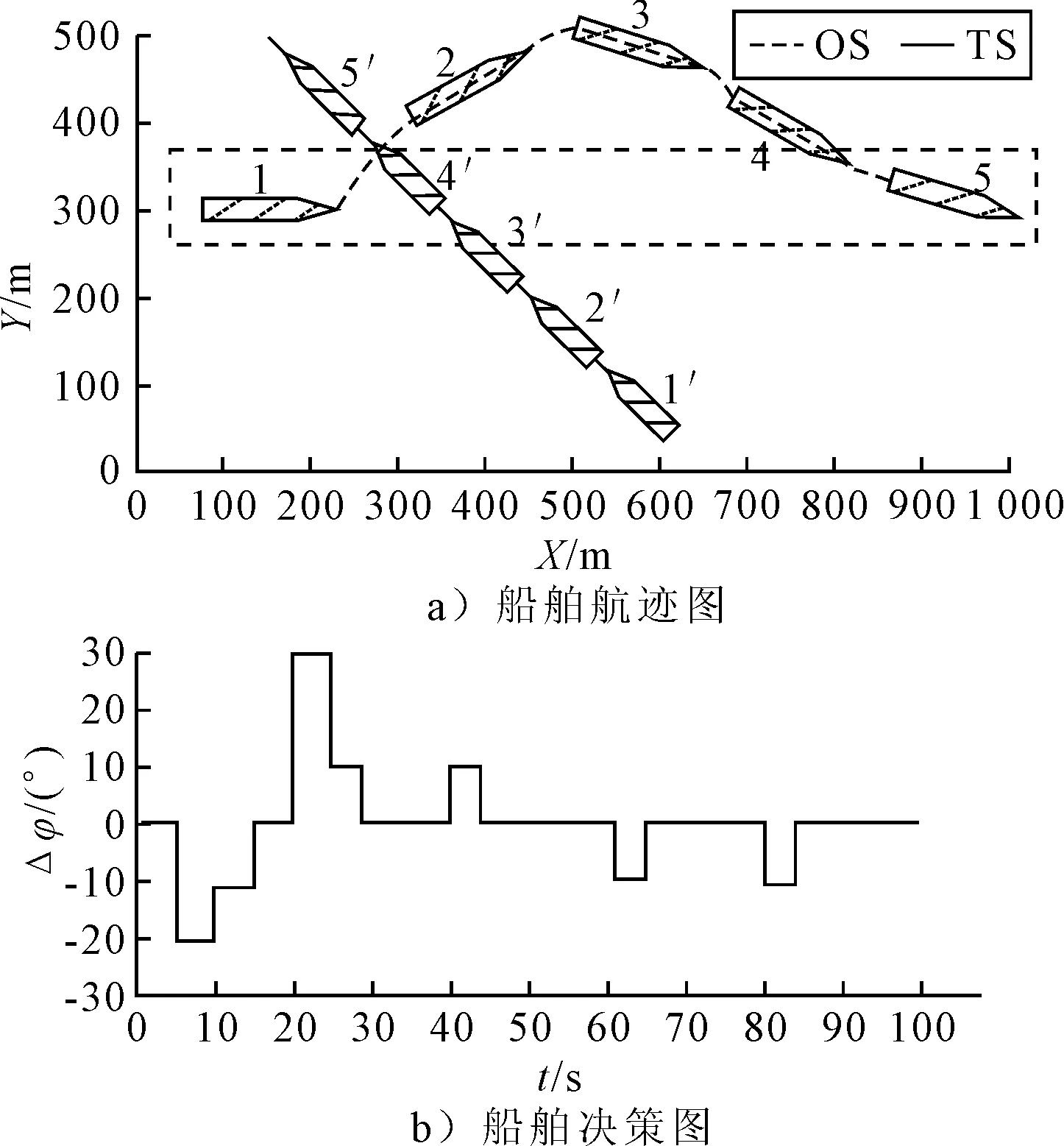
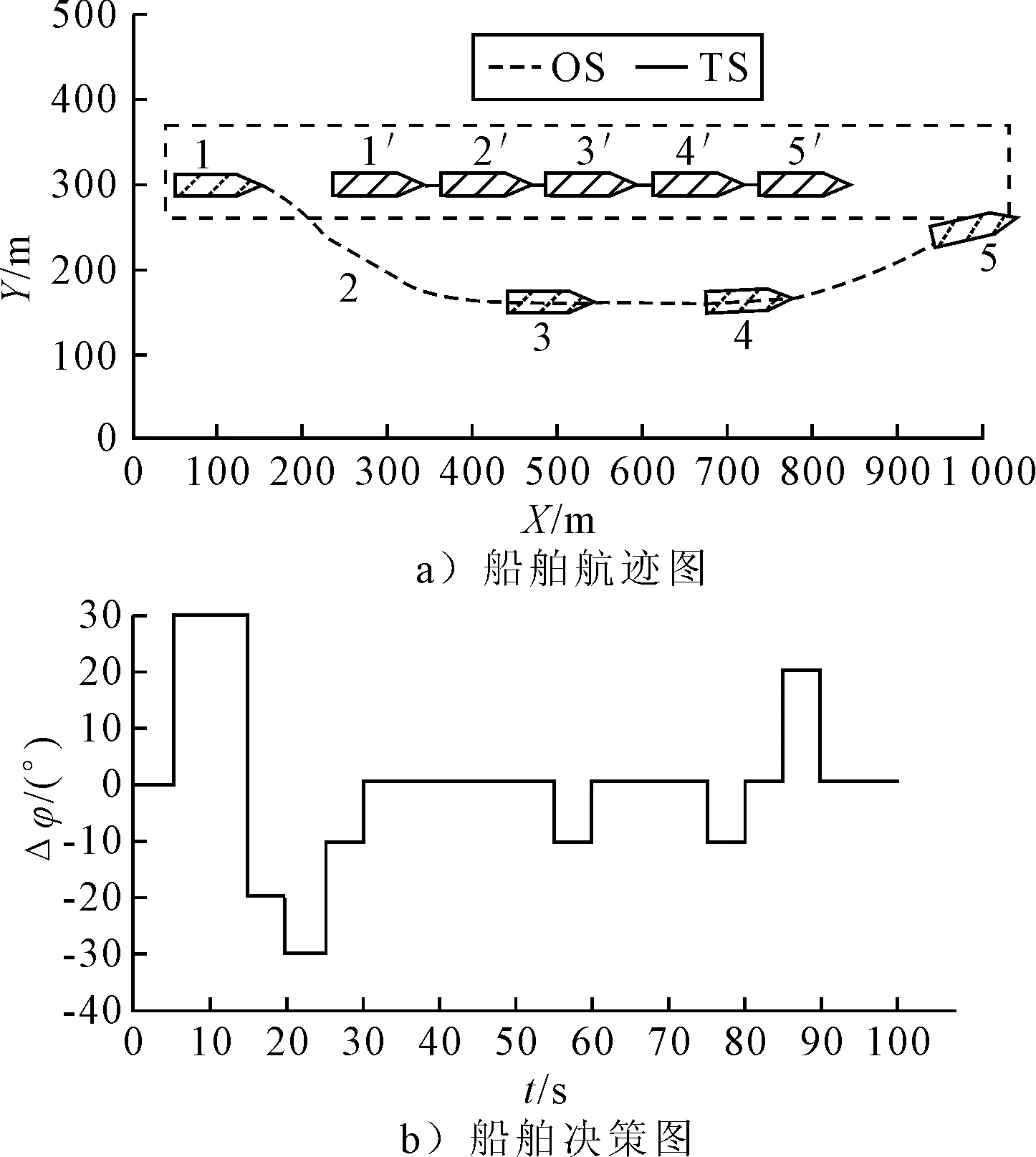
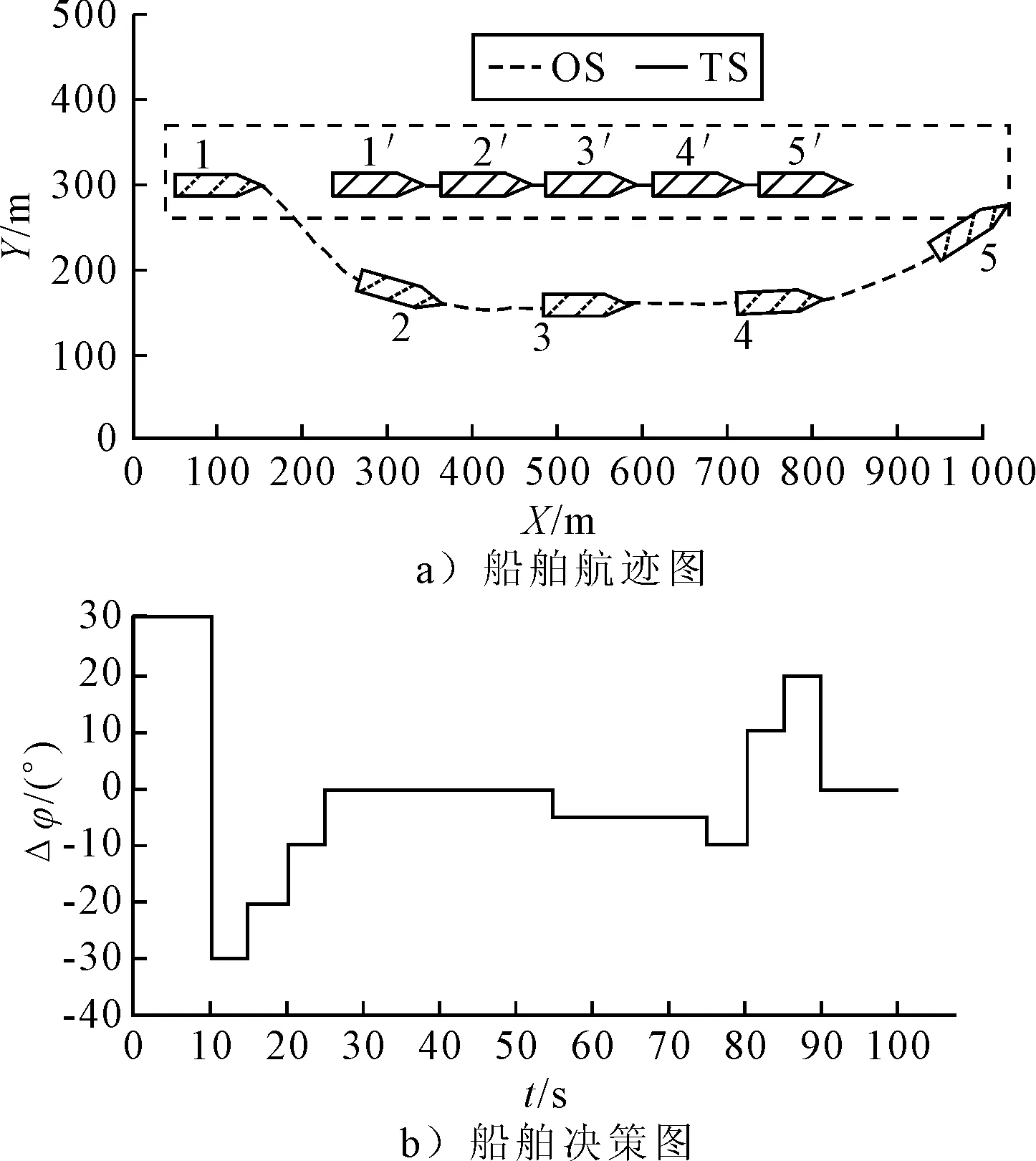
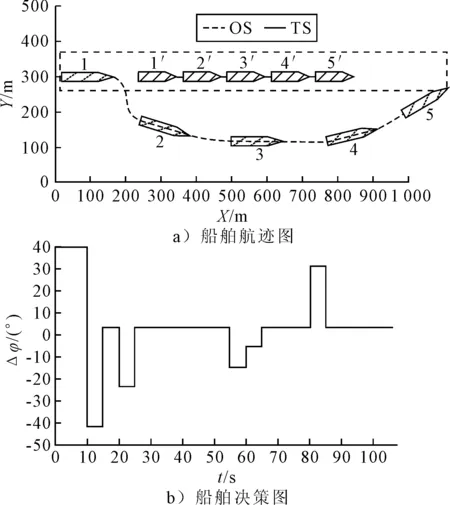
1) 安全性奖励函数 采用OS与TS(s)之间的距离D的变化来定义安全性奖励函数,见式 (4).当D(t)>D(t-1)时,给奖励值20;当D(t) (4) 2) 经济性奖励函数 采用船舶与目的地的距离L和与航线中心线的距离C的变化来定义经济性奖励函数,见式(5).在避碰过程中,当L(t) (5) 3) 协调性奖励函数 协调性奖励函数是针对OS避让时采取的避碰动作来设计,见式 (6).无人船在满足规则的策略中进行动作选择,如果采取的动作符合内河避碰规则和驾驶经验知识为T,给奖励值5;反之,不符合时为F,给较大的惩罚值-100. (6) 3.1.1无人驾驶决策仿真设置 在Window10系统下,搭建Anaconda3的python3.7编译环境,用于对无人驾驶船舶的驾驶决策的各模型进行编码,并用tensorflow1.13深度学习框架搭建神经网络.调用pyglet模块来实现仿真结果的可视化,它可视化的模拟环境包括船、碍航物和生成的路径等.表2为程序中相关参数的设置,在所有模拟情况下,都使用相同的参数设置,且指定无人驾驶船舶以避碰并以最佳路径收敛到其预定航域,最后到达目的地. 表2 TD3算法用于驾驶行为决策时的参数 3.1.2无人驾驶决策模型训练 构造一段天然内河河道为无人驾驶船舶驾驶决策模型的训练环境,设宽度800 m,直线长度2 000 m,设置有障碍物.设置OS的长度L为106 m、型宽B为17.1 m、型深H为8.3 m、满载吃水T为5.8 m,船舶初始速度为18 kn,平均航速设置为15 kn,由此可计算出避让领域中比例系数k和碰域边界等其他参数的值.将OS置于搭建的仿真环境中,设置其目的地为(1 600,600),完成任务时即结束一个episode.定义TS的速度为16 kn,给定OS确定的初始位置、随机的航向,若OS与TS发生碰撞,则让其退后到事故发生前距离为Dd的某一位置,Dd为L.而TS在每个episode中,位置、航向都随机.训练结束时,训练得出的数据以文件的形式保存,后续可继续训练(为了对模型的性能提出更高的要求,故文中设定的仿真航速大于内河通常航速,因航速越大避碰难度越大). 图6为经过一段时间训练的效果图.由图6可知:其碰撞次数从开始的五千多次,波动下降到训练最后的几十次,波动是无人船学习时在利用与探索之间平衡导致的.图7为TD3算法与DDPG算法的结果对比图,TD3的平均奖励值约为3 500,而DDPG的约为2 000;且TD3的收敛速度也更快,故综合而言,前者明显优于后者. 图6 无人驾驶船舶决策训练碰撞次数趋势图 图7 算法效果对比图 3.2.1对驶会遇 在对驶会遇时,模拟目标是让OS自主决策,让其在遵守内河避碰规则和良好驾驶经验的情况下避免与TS发生碰撞,同时遵循预定路径并达到目的地.在此任务中,使用TD3算法训练DRL智能体程序来避免TS.令点(150,300)为OS的初始坐标,航向为90(,令点(1 800,300)为目的地坐标.TS的船长也为106 m,航速为16 kn,航向为270(,点(900,300)为TS的初始坐标,目的地坐标为(200,300).仿真后结果见图8.进一步改变OS的航速为20 kn,其余保持不变,进行仿真,结果见图9.然后,改变OS的船长为146 m,再进行仿真,得到结果见图10. 图8 对驶会遇场景仿真结果图 图9 改变航速后的对驶会遇仿真结果图 图10 改变船长后的对驶会遇仿真结果图 图8a)为无人驾驶船舶在对驶会遇时的船舶决策航迹,这种场景下,OS与TS均为让路船,但是文中只是单船的自主决策,所以采用了TS状态不变,OS避让的措施.深色为TS航迹,浅色为OS,而虚线框为OS的假设预定航行区域.由图8a)可知:OS右转变速避让,但船舶之间恢复安全距离后,OS并没有直接大幅度转向回到预定航线上,而是决策出一条较优的回归路径.由图8b)可知:在15 s时,OS进入避碰决策状态,右转10°,在30 s时,预测判断不需要再左转之后,采取了右转20°,然后进一步判断无碰撞危险时,在40 s采取小幅度左转10°.当驶近预定航行区域时才右转20(回到预定路径驶向目的地.由上可知,无人驾驶船舶可以进行正确判断会遇态势,并据内河避碰规则以及驾驶经验进行自主决策,且当TS不采取措施时,OS能决策出安全的航线,最终完成给定任务.同理分析改变航速和改变船型之后的仿真结果图9~10.由图8~9可知:船舶提前进入避碰决策,且保持的船间安全距离更大;且因船舶初速度较大,在避碰过程中其采取大幅度转向避碰.由图8和图10可知:船舶因为船长变大,所以计算出安全距离更大,提前采取措施避碰.在避碰时,因考虑到船长较大,所以没有直接采取大幅度转向,而是连续小幅度转向开始避碰;在避碰过程中保持的安全距离也更大. 3.2.2交叉会遇 令点(150,300)为OS的起始位置,点(1 600,300)为目的地位置,航向为90°.TS的船长船速保持不变,航向为300°,起始坐标为(580,50),目的地坐标为(150,500).此时是右舷大角度会遇,而vT/vO≤0.95,应左转向避让,见图11.进一步改变OS的航速为20 kn,其余保持不变,进行仿真,结果见图12.改变OS的船长为146 m后进行仿真,结果见图13. 图11 交叉相遇场景仿真图 图12 改变航速后的交叉相遇场景仿真图 图13 改变船长后的交叉相遇场景仿真图 由图11a)可知:无人船正确辨识会遇态势为右舷大角度会遇,为避让船;同时根据TS与OS的航速比决策出应左转向避让.在采取转向避让后,为尽快解除碰撞危险,对船舶进行了加速.由图11b)可知:船舶采取小角度转向避让,结合变速,在保证船舶安全的情况下,是一个良好的避碰决策.而在判断船舶解除碰撞危险后,为了避免船舶偏离航线太远,在40 s进行右转30°,然后保持航行到接近航域时,左转回到预定航线并驶向目的地.同理可分析图12~13,同对驶相遇情况一样,通过改变航速与船长之后进行仿真结果的比较,船舶依然可以很好的进行避碰,且可根据航速、船长等的改变调整避碰措施. 3.2.3追越场景 令点(100,300)为OS的起始位置,点(1 600,300) 为目的地,航向为90°.TS的船长保持不变,船速为12 kn,航向为90°,起始坐标为(280,300),目的地坐标为(1 600,300).此时是右舷大角度会遇,而DCPA>0,应右转向避让,见图14.然后改变OS的航速为20 kn,其余保持不变,进行仿真,结果见图15.改变OS的船长为146 m后进行仿真,结果见图16. 图14 追越场景仿真图 图15 改变航速后的追越场景仿真图 图16 改变船长后的追越场景仿真图 由图14~16可知:无人船在初始航速、船长变大之后,在避碰决策时均相应增大安全距离.在航速与船长变化后,采取的转角措施有变化,在初始航速和船长变大时,其更早地采取转角,角度也更大.再对比对驶和交叉会遇场景的仿真分析可以看出,追越场景对两船的航速差要求大,且对追越地理位置的要求更高,同时,为避免船吸、浪损等现象的危害,保持较大的安全距离.无人船可很好的识别会遇态势并做出准确及时的决策,此算法可行性、鲁棒性、时效性、泛化性等均较好. 1) 内河避碰规则和驾驶经验可用于基于TD3算法的无人驾驶行为决策中. 2) 基于TD3算法的无人驾驶决策模型可很好的判别各种会遇态势,并采取正确决策. 3) 通过改变船舶的初速度和船长,对比仿真结果分析可知,无人船均可灵敏准确决策,且在不同航速及不同船长之间保持的安全距离,及开始采取措施时间的不同,可为衡量船舶碰撞危险度提供参考. 4) 通过对无人驾驶船舶的综合训练仿真结果,可为有人船的驾驶提供驾驶决策策略库.3 模型训练仿真
3.1 训练仿真准备

3.2 决策模型仿真
4 结 论
