基于互信息的鲁棒跨域推荐系统
2022-07-11刘昱康于学军
刘昱康,于学军
(北京工业大学 信息学部,北京 100124)
为了解决大数据时代的数据过载问题,推荐系统在近些年已经被学术界广泛关注而且也在现实生活中获得了大量的部署。为了更好给新用户推荐新产品(即解决推荐系统中的冷启动问题)[1],研究者们提出了跨域推荐系统使用多用户领域(一般称为源域)的数据去解决少用户领域(一般称为目标域)的推荐问题[2-3]。现有的跨域推荐系统主要分为两种类型[4]:第一种类型通过将来自多个域的数据集以通用的格式(例如,一个通用的评分矩阵[5])组合起来去聚合知识,他们会假设“用户-产品”的数据格式是固定的[2,6-9];第二种类型通过迁移的知识来链接领域,这一系列研究仅限于基于矩阵分解的协同过滤方法,因为在不同域跨域共享的一个潜在因素允许知识转移[10-12]。无论是以上哪一种跨域推荐系统,他们都假设源域中的知识是正确的,不含有任何错误信息的。然而这个假设在现实推荐场景中很难被满足。假设源域的数据来自于用户点击记录,如果用户勿点击了一个产品,那么该用户点击记录数据中就存在了错误信息,继而打破了现有方法的假设,导致现有方法的效果出现了大幅下降。
本文发现这种错误信息会极大得降低跨域推荐系统的性能,使其无法在现实场景中使用。为了解决这个问题,本文提出了一个基于互信息的鲁棒跨域推荐系统——互信息鲁棒域分离网络。在该系统中,一个基于互信息的风险函数被提出来去自动过滤数据中存在的错误标注。该风险函数是香农互信息的广义版本,它保留了香农互信息的所有属性,包括非负性、对称性和信息单调性,并且还具有相对不变性。使用该风险函数所训练出的跨域推荐系统可以很好地处理训练数据中存在的错误信息。同时,本文采用了真实的数据集验证了互信息鲁棒域分离网络的有效性。结果表明,当源域含有错误信息时,该网络依然可以很好地解决推荐系统中的冷启动问题。
1 跨域推荐系统的定义与所用符号
在跨域推荐系统中,有两个基础空间,它们分别是特征空间X以及标签空间Y,其中X是d维欧式空间的一个子集,而Y是由标签1,2,…,L组成。不同的标签代表被推荐的不同产品,而空间X中元素x则代表了用户。在跨域推荐系统中,有两个不同的数据集,分别是源域S及目标域T:
其中,n和m分别表示源域的样本数及目标域的样本数。
由于被研究的问题属于跨域推荐系统范畴,因此,源域和目标域是由不同的分布生成的。另外,在现实的应用中,得到充足的源域真实标签也是一件极其困难的事。一般来说,在源域数据的标签中会混入噪音标签(错误标签)。因此,在标签噪音跨域推荐系统中,仅有带噪音的源域数据Sn是可得的:
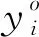
标签噪音跨域推荐系统的主要目标是仅使用带噪音的源域数据Sn和目标域数据T构建一个基于目标域的推荐系统。
2 模型介绍
本文提出了一个新的模型去解决标签噪音跨域推荐系统问题。本文提出的方法被命名为互信息鲁棒域分离网络(mutual information robust domain separation networks,MIRDSN)。MIRDSN 是基于两个基础模块:第一个模块是被称作域分离网络(domain separation networks,DSN),DSN的主要目的是解决源域及目标域的域差异问题;第二个模块被称做互信息鲁棒风险(mutual information robust risk,MIRR),MIRR的主要目的是缓解源域里标签噪音所引起的分类误差。
2.1 域分离网络
本文使用DSN去缓解源域和目标域之间的分布差异。DSN的主要思想旨在利用神经网络构造一个特征变换,使得经过变换后的源域及目标域有相似的域分布。图1展示了MIRDSN的基本框架。DSN由五个基础神经网络组成,它们分别是编码器E(x,α)、源域编码器S(x,β)、目标域编码T(x,γ)、解码器D(x,μ)以及分类器h(x,σ)。其中,α,β,γ,μ,σ代表了神经网络的参数。令
为了保证由编码器和解码器生成的样本与原样本尽可能一致,本文使用了样本重构风险[13]:
其中,ld表示坐标值全为1的d维向量。为了保障不同编码器能从不同的角度观测数据,本文也使用了最大差异风险[13-14]:
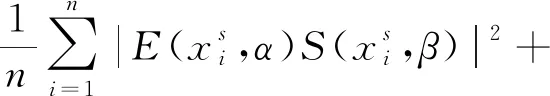
同时为了尽可能地减小源域和目标域的分布差异,本文使用了两种不同的策略去衡量分布差异。
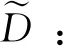
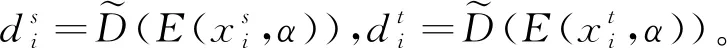
第二种策略的基本思想是使用最大平均差异(maximum mean discrepancy, MMD)[16]去衡量源域和目标域的差异,之后优化神经网络使得源域和目标域的最大平均差异最小。令κ(·,·)为核函数[17],那么MMD风险Rm为:
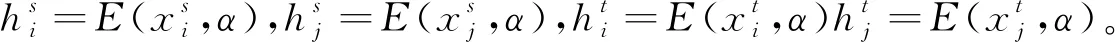
注意到以上所有公式未用到源域的任何标签,所以本节并未用到源域的真实标签。
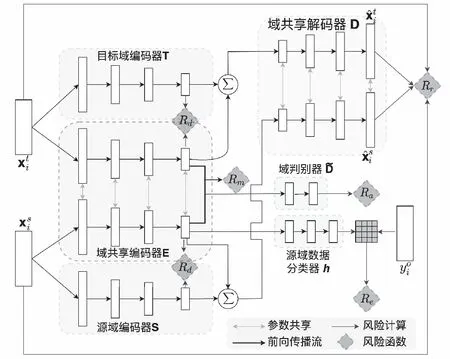
图1 互信息鲁棒域分离网络Fig.1 Mutual information robust domain separation networks
2.2 互信息鲁棒风险
由于源域数据的标签存在噪音,仅使用经典的经验风险极小化(empirical risk minimization,ERM)是不可行的,因为对于几乎所有经典的损失函数l(Loss Function),例如交叉熵函数,都会有以下式子成立:
其中,h为分类器(输出为L维向量。一般选择坐标值最大的坐标作为预测标签),H是由部分分类器组成的集合,也被称作假设空间。本节的主要目的是构造合适的经验风险使得在恰当的条件下,使用带噪音的源域数据Sn和使用无噪音的源域数据S能得到相似的结果。令经验风险为Re,分类器为h,假设函数空间H(H是由部分分类器组成的集合),

A(h,Sn)=[acl(h,Sn)]
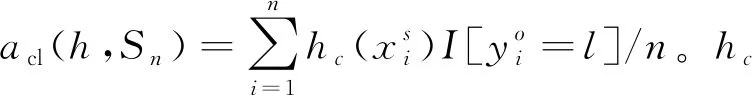
本文使用h(E(x,α),σ)作为分类函数。基于文献[16]中的定理4.1,在合适的条件下,以下的等式不难得到
最后为了方便,本文定义
Re=-log|detA(h(E(·,α),σ),Sn)|
2.3 最终的优化函数
经由2.1及2.2节介绍,本文考虑如下优化问题:
令α*,β*,γ*,μ*,σ*作为最终被优化后的参数,那么函数h(E(x,α*),σ*)就是最终本文希望求得的推荐系统。对于任何一位用户x,该用户被推荐的产品将由以下公式得到
其中,hc表示h的第c个坐标的值。
3 试验结果与分析
3.1 数据集介绍
本文选取了两个来自于雅虎的数据集作为本次试验的数据。两个数据集分别为视频点播服务(VIDEO)和新闻阅读(NEWS)的浏览日志。而试验的主要目的就是向从未使用过VIDEO和NEWS的用户进行推荐。
在VIDEO数据集中,每个数据的特征为一个用户的历史观看记录,每个数据的标签为该用户最新观看的视频;在NEWS数据集中,有用户的历史阅读记录,但没有每个用户的视频观看记录。即VIDEO数据集是一个被标注过的源域;NEWS数据集是一个为被标注过的目标域。为了测试所提出的模型的效果,本文找到了38 250个同时点播过视频或浏览过新闻的用户,即有了一个有标签的目标域用于测试本文所提出的推荐系统。VIDEO和NEWS数据集各含有约1 000万条数据。在VIDEO和NEWS数据集中,它们都含有一些文本特征。在VIDEO数据集中,本文使用标题、分类、简介和演员信息作为额外特征,在NEWS数据集中,标题和分类被当作额外特征。由于VIDEO和NEWS数据集中没有指出哪些数据是完全正确的,为了模仿噪音环境,本文采用对称噪音的生成方式来生成在噪音环境下的VIDEO数据。
3.2 对比方法
本文选择了其它4种推荐算法作为对比算法,来印证本文所提出的方法是否具有更优秀的性能。最受欢迎法(most popular item,POP)直接推荐了训练数据中被观看最多的视频,和POP方法比较,可以知道MIRDSN是否做到了个性化的推荐。DSN为经典迁移学习方法。跨域矩阵分解法(cross-domain matrix factorization,CdMF)为经典协同过滤方法,本次试验将VIDEO-NEWS数据集转化为用户-视频的点击矩阵,然后输入该矩阵给CdMF方法来获得推荐结果。神经网络(neural networks,NN)为非迁移方法,NN只会最小化经验风险和样本重构风险而不考虑最小化域之间的分布差异。
3.3 试验设置
MIRDSN网络中的各个模块(图1)均采用全联接神经网络。其中,所有的编码器都是4层神经网络(256->128->128-> 64),解码器是4层神经网络(64->128->128->256),源域数据分类器是5层神经网络(64->256->256->256->256)。所有网络的激活函数为exponential linear unit(ELU)[19]。在训练时,MIRDSN会开启暂退法(dropout),对于编码器,暂退率设置为0.25,对于解码器,暂退率为0.5。ADAM优化器被用来优化所有网络的参数(学习率设置为10-3)。MIRDSN采用L2正则来约束参数空间,L2正则项对应的惩罚参数从{10-1,10-2,10-3,10-4}选择。本文采用D@M作为所有方法的评估指标,D@M是一种用于衡量排序质量的指标,也经常用于评估推荐算法的有效性[14]。当正确的视频在建议视频列表中排名较高时,D@M会给出更高的分数。具体计算公式为:

3.4 试验结果与分析
图2表现了在D@10时各种方法在不同噪音环境下的性能比较。选取D@10代表只推荐10个产品给用户时的D@M的值,根据文献[14]中对D@M的用法,当给用户推荐的产品为10个时,在推荐方法的性能评估上,既避免了数据过大导致推荐的结果具有较大偶然性而不具说服力,也防止了数据过小使推荐结果过于单一的情况,所以,选取D@10作为评判指标最能体现推荐方法的性能,使对结果的分析和判断更具有准确性,本文同时也还选取了D@1,D@50和D@100进行试验,增加说服力,将在后文进行展示。在图2中,纵轴作为D@10指标,横轴作为噪音率ρ,从图2中可以看出,随着噪音率的增大,现有几种方法的D@10值都有较大幅度的下降,而本文提出MIRDSN的D@10值更趋于平均,虽然也可以看出有一定程度的下降,但相比其它几种方法,下降幅度小。图2可以印证前文提出的问题,即如果源域数据中出现了错误信息会极大降低推荐方法的性能,现有的推荐方法都基于假设源于数据并无错误这一条件进行推荐,而这在现实中几乎是不可能的条件,所以这些方法在真实情况下并不适用,而本文提出的方法则一定程度上解决了这一问题,在真实情况下将会是更好的选择,下面给出详细的试验结果和分析。
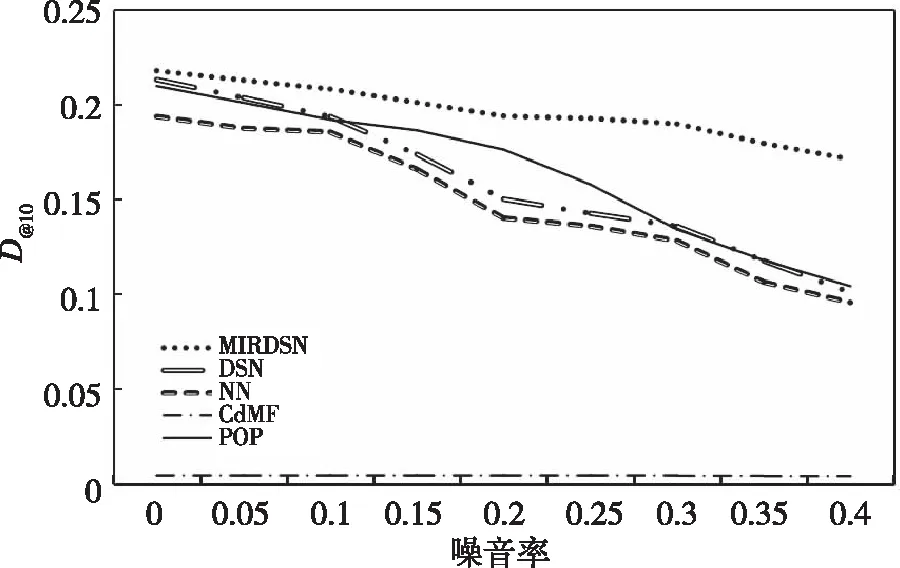
图2 D@10时跨域推荐系统在不同噪音下的表现Fig.2 Performance of cross-domain recommendation system at D@10under different noises

表1 跨域推荐系统在噪音率为0.3时下的表现Tab.1 Performance of cross-domain recommendation system at noise rate of 0.3
表1表现了各种方法在噪音率为0.3时的推荐效果。可以看出MIRDSN的推荐成功率比其他方法高很多。这表明,在噪音存在的环境下,MIRDSN可以很好地抵抗噪音的影响并获得不错的结果。随着M值的增加,MIRDSN方法的预测效果越来越优异,这表明了随着推荐产品数量的增加,可能包含了更多的错误标签,而本文提出的MIRDSN能在这样的情况下更好地预测到用户的喜好。相比于POP,MIRDSN也有很好的表现,说明其能做到提高推荐效果的同时,也做到个性化的推荐。相比于DSN,MIRDSN的优异表现说明MIRDSN确实很好地处理了数据中的噪音。CdMF表现很差是因为用户-视频的点击矩阵丢失了很多用户和视频(新闻)的基本信息。

表2 D@10时跨域推荐系统在不同噪音下的表现Tab.2 Performance of cross-domain recommendation system at D@10 under different noises
表2表现了当D@10时,各种方法在不同噪音率下的表现。从表中可以看出当噪音率ρ从0增加到0.4时,DSN、NN和POP三种方法的D@10指标都有0.1左右的下降,而本文提出MIRDSN方法的D@10指标只有0.04的下降,说明了MIRDSN方法具有更好的鲁棒性,在噪音环境下,MIRDSN方法总是能作出更准确的预测。虽然CdMF方法也具有良好的鲁棒性,但是可以看出从噪音率为0到噪音率为0.4,其方法本身的预测精度比较差,与MIRDSN方法相差甚远,因此,认为MIRDSN方法仍然是性能更优异的方法。
4 结束语
本文考虑了标签噪音跨域推荐系统问题。该问题主要解决了推荐系统中的两个核心问题:1)推荐系统中测试数据集和训练数据集来自不同分布;2)推荐系统中训练数据集包含了错误标签。为了解决标签噪音跨域推荐系统问题,本文提出了互信息鲁棒域分离网络模型。该模型主要由两部分组成:域分离网络和互信息鲁棒风险。域分离网络解决了测试数据集和训练数据集分布差异的问题。互信息鲁棒风险缓解了训练数据集中的标签噪音问题。本文通过试验验证了所提模型的有效性。试验表明,互信息鲁棒域分离网络在噪音环境下可以很好地达到理想的推荐效果。
