Modeling and Verification of a Sentiment Analysis System Using Aspect-Oriented Petri Nets
2022-07-08ShuHungYangYiNanLinChengYingYangMingKuenChenVictorShenYuWeiLin
Shu-Hung Yang | Yi-Nan Lin | Cheng-Ying Yang | Ming-Kuen Chen | Victor R.L.Shen | Yu-Wei Lin
Abstract—An increasing number of social media and networking platforms have been widely used.People usually post the online comments to share their own opinions on the networking platforms with social media.Business companies are increasingly seeking effective ways to mine what people think and feel regarding their products and services.How to correctly understand the online customers’ reviews becomes an important issue.This study aims to propose a method with the aspect-oriented Petri nets (AOPN) to improve the examination correctness without changing any process and program.We collect those comments from the online reviews with Scrapy tools, perform sentiment analysis using SnowNLP, and examine the analysis results to improve the correctness.In this paper, we apply our method for a case of the online movie comments.The experimental results have shown that AOPN is helpful for the sentiment analysis and verifying its correctness.
1.lntroduction
The era of big data is now coming up with the thriving technology applications, booming social media, and rapid development of web platforms.Posting comments on products, news, and services has become a popular activity in social media or web platforms[1].Hence, there are social platforms, such as Facebook and Twitter, and functions for posting comments on products or transactions.So, it is able to express or search the ideas on hot news, products, and even daily lives via the Internet.To follow up this trend, more and more companies and media try their best to mine data on these social media.For example, Twitratr (twitr-ratr.com),Tweetfeel (www.tweetfeel.com), and Social Mention (www.socialmention.com)[2]afford their commercial services based on the sentiment analysis on Twitter.Thus, it is obvious that this trend indicates the great commercial values based on the sentiment analysis.
1.1.Research Background
The sentiment analysis includes different language version, such as Chinese and English versions.To conduct the sentiment analysis, there are many common ways, like Word2Vec and Doc2Vec developed by Google, neural networks,K-nearest neighbors (KNN), Bayes, and support vector machine (SVM).No matter in which ways, the problems always contain insufficient extraction of keywords, failure of further artificial examinations, and lack of 100% full assurance of data quality.
With the rapid development of social media and platforms in these years, people start to express more ideas via the Internet, and here comes out “popular terms”.Popular terms are not an official vocabulary or a sentence.Sometimes they even mean more than the literal meaning.There are many new popular terms created every year, for example, “蓝瘦香菇” that means a feeling of sorrow and being tearful instead of the literal meaning: A blue and skinny mushroom.People now frequently use popular terms when commenting,yet machines can only tell their literal meaning, which results in the wrong sentiment analysis results.It is not proper to continuously update the lexicon and algorithms since the language structure is very complex and the machine itself cannot sense a word as humans do.
If we want to put sentiment analysis methods into practice, it is necessary to ensure the correctness of analysis results.There are more than one meaning in a word, and different contexts and moods can lead to different meanings, so algorithms may make errors.A machine, however, is not only unable to accurately tell word meanings according to moods or contexts, but also unable to keep the database up to date, or to conduct further examinations.Therefore, the goal of this research is to overcome these and improve the correctness of sentiment analysis results.
1.2.Research Motivation
Social media provide people with a platform to share their ideas and sentiment status.Some scientists collect news and use the sentiment analysis to discover the public sentiment status, as a decision reference to products or services in the future[3].Taking stocks as an example, the comments may put a great influence on the financial market[4].To get investors’ sentiment, it is valuable to create the sentimental index[5].And the Twitter data items can predict the crimes of the future[6].
The most common way to analyze the favor in comments is to make use of sentiment analysis.Sentiment analysis can sense the sentiment degrees of sentences and vocabularies, and tell people’s favorites.In other words, the sentiment analysis can obtain the comprehension of people’s feedback on products or services.
1.3.Research Purpose
This study aims to propose a method to ensure the correctness of analysis results without modifying the sentiment analysis process.The sentiment analysis inaccuracy is caused by many problems.A machine is often unable to tell word meaning correctly.For example, Tweets (the message on Twitter) are usually composed of incomplete sentences[7], so it fails to provide a valuable reference to future products or services.But to solve the decision problems, it is very important to improve the correctness of sentiment analysis results.
Petri nets (PN) models have four advantages, namely, the formal semantics, visualization, rich expression, and analysis capability[8].A PN model is even good at describing and dealing with processes,which are beneficial to our sentiment analysis.The processes of sentiment analysis mostly access comments from the Internet, and then analyze the sentimental degree through classifiers.Thus, we can use the sentimental degree to capture the feedback on products or services.
This study is based on aspect-oriented Petri nets (AOPN) to conduct a dynamic check, so that it can attach the check requirements directly without modifying the raw model.By using the colored Petri nets(CPN)[9]tool to simulate the sentiment analysis process, the goal is to find the errors, correct them, and verify the results before jumping to the conclusion.
2.Literature Review
In Section 2, the sentiment analysis methods, Scrapy tool, SnowNLP tool, and AOPN are presented.
The first step of sentiment analysis in this study is to make use of the Scrapy tool in Python to save the Internet comments.In this research, SnowNLP is adopted, because these two tools are common and free to be downloaded from the Internet.We apply the online comments captured by SnowNLP to the sentiment analysis.Then, the sentimental values of comments are obtained.With those values, the standard is set up,so that the online comments can be judged as positive or negative.
2.1.Sentiment Analysis Method
Currently, the common methods of sentiment analysis include SVM, Bayes’ theorem, and KNN, which are presented in the following.
2.1.1.SVM
SVM is a widely used supervised learning model and an associated learning algorithm for analyzing data in classification and regression.
The main idea of SVM is to make a perfect plane for training an example vector divided into two categories: Positive and negative, and to maximize the plane’s boundary.The middle distance between two dotted lines is a margin, which means the SVM algorithm tries to maximize the target.The dots near two dotted lines are support vectors, and only support vectors in the intensive training can affect the whole model’s results[10].
By applying the SVM tool to identify the noun group, the results are regarded as the eigenvalues for the SVM classifier, and then the noun group of the context is obtained[11].
2.1.2.Bayes’Theorem
The Bayes classifier is a simple way to build a classifier.The classifier model assigns class tags presented by eigenvalues to the questions and examples.A class tag is obtained from a finite set.For example, if fruits are yellow, round, and approximately 3 inches in diameter, then the fruits can be viewed as apples.The Bayes classifier assumes the existence of a specific feature is independent of the existence of other features[12].However, the Bayes classifier considers these properties to be independent in determining the probability distribution: Whether the fruit is an apple or not.Among many applications, the estimation of Bayesian model parameters employs the maximum likelihood[13].
2.1.3.KNN
KNN is a simple and effective way to classify data.It searches the nearest neighbors to classify the targets[14], and assigns data with similar features to the space formed by their features.As a result, to identify the category of unknown data, we need to get the features first, and to calculate the distance between the features of training data.We identify whether the category of training data and that of close dots are the same or not[15].
Although several kinds of algorithms are described, in fact, the sentimental values calculated with every algorithm are actually inaccurate.The main reasons include the relationship between Chinese and English leading to errors, too few keywords, no further artificial examination, and no 100% assurance of data quality.If we would like to put sentiment analysis methods into practice, it is critical to improve the correctness of analysis results.The sentimental values cannot be kept up to date every moment or be further examined.We try to improve the sentiment analysis results with SnowNLP.The comparison of sentiment analysis methods,including SVM, Bayes’ theorem, and KNN is shown inTable 1.
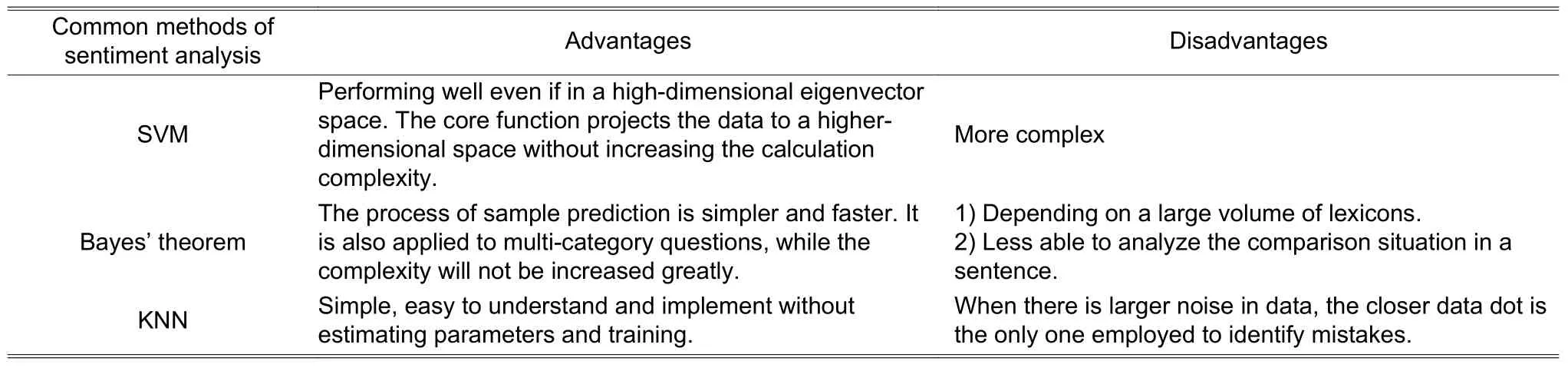
Table 1: Comparisons of sentiment analysis methods
2.2.Scrapy Tool
Scrapy is a free-of-charge, open-source, and web-based crawler framework, designed in Python.The initial design is for web-based exploration, and is also available for application program interface (API) or common web-based crawlers to get data.Scrapy’s structure is based on the spider with a capture tool in [16]and [17].
2.3.SnowNLP
SnowNLP is designed by Python’s database focusing on Chinese contexts, and is inspired by TextBlob(https://github.com/sloria/TextBlob).Because most natural language databases are not designed for Chinese,here it comes out a database system easy to deal with Chinese.Different from TextBlob, NLTK is not employed here.All calculations are completed by themselves along with a good-training lexicon[18].
2.4.PN
PN is a mathematical model applied for discrete and parallel systems[19],[20].There are triggering conditions and nodes inside.The simple procedure of PN is shown in Fig.1.The symbols and mathematical expression of a PN model are shown inTables 2and3.

Table 2: PN symbols
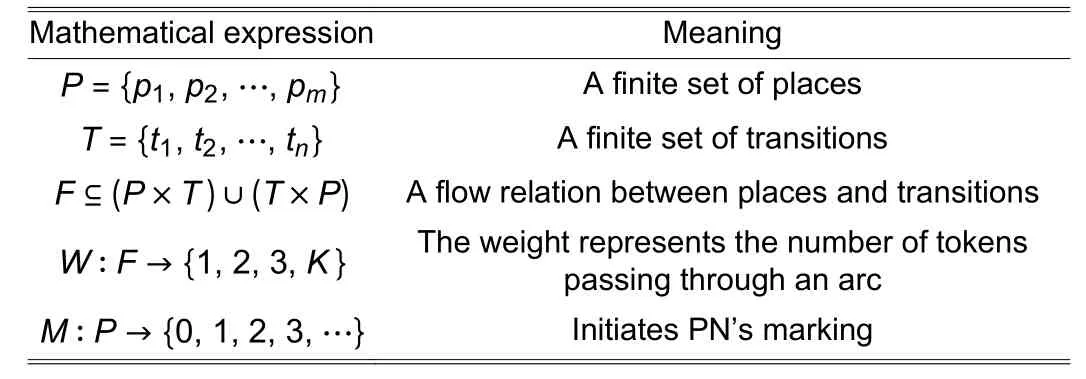
Table 3: PN mathematical expression
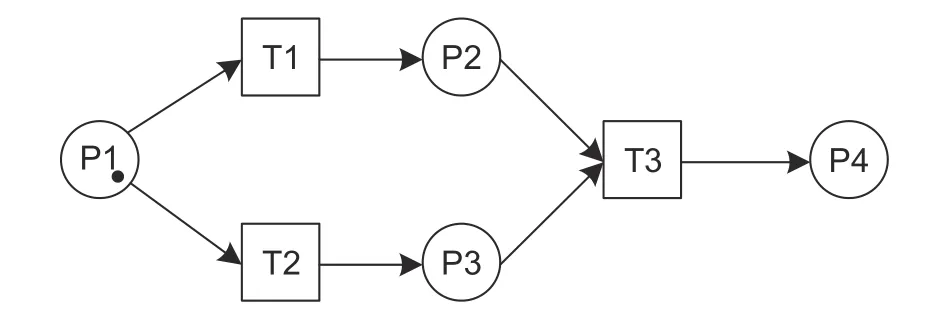
Fig.1.Simple procedure of a PN model.
2.4.1.AOPN
Aspect-oriented programming is designed for cross-cutting concern.If the cross-cutting concern is written in the software process directly, the cost for program maintenance becomes higher[21],[22].For example, if one wants to modify a function in an object or to delete the service, then one has to modify all program codes and recompile them.On the other hand, the object’s logic or program becomes more complex to write because of the cross-cutting concern.
The basic concepts of aspect-oriented are the advice, join point, pointcut, and introduction.Here are the introductions of four basic concepts:
1) Advice: It is an aspect’s practice.
2) Join point: It is the moment to call advice in an application.The moment may be called and returned by some methods, or both of them included, or certain exception occurring.
3) Pointcut: It is a definition and an applicable method.The definition can assign a certain aspect to a certain join point to be employed by applications.
4) Introduction: Introduction is in the current category.It can add a behavior to the current category, and dynamically add some methods or behaviors into the complete category, when running the programs, without increasing or reducing the codes in this category.
Here are the advantages of the aspect-oriented concept:
1) It is more flexible to design a system.
2) Compared with the object-oriented method which can only modify the program codes statically, the aspect-oriented is able to modify the program codes dynamically without changing the original model[23].
3.Proposed Approach
This section focuses on the simulation tool, which is able to edit, simulate, and analyze the colored PN(CPN)[23].CPN is employed in this study to simulate the AOPN-based sentiment analysis system.
3.1.AOPN-Based Sentiment Analysis System Design
As shown inFig.2, we capture those comments and the scores from the online review with the Scrapy tool, and perform the sentiment analysis using SnowNLP.Then, if the check step detects the result which is the same as the proposed standard interval, it will pass and output the result; if not,modify it as the proposed standard interval and output the result.Repeat these steps until all comments are analyzed by the system.
3.2.Sentiment Analysis
This study has made a comparison among the existing sentiment analysis methods.In each method, there are some sentiment analysis problems mainly resulting from the lack of the artificial examination.Fig.3is a flow chart of general sentiment analysis.It shows that when a comment is entered, the results come out directly after analysis without any check step.
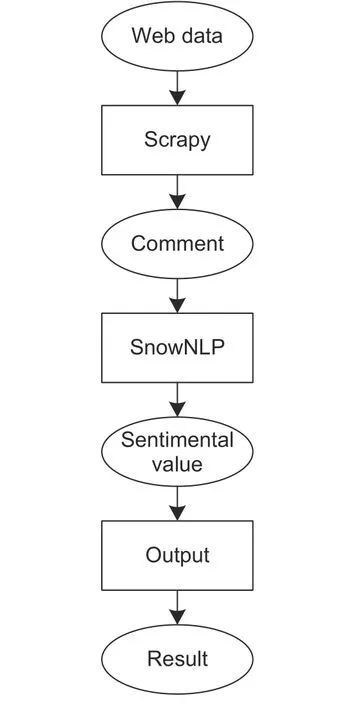
Fig.3.Flow chart of general sentiment analysis.
3.3.AOPN-Based Sentiment Analysis Concept
This study adopts the transition pointcut in AOPNs as stated in subsection 2.4.1 along with the safety detection step.“Sentimental value” and“output” are the pointcuts in this process.The safety check step is inserted between “sentimental value”and “output” to apply for applications.Then the check rules are introduced, which are extracted from the artificial examination.The score inFig.4is part of the artificial examination, which is obtained from the online comments.
For example, the movie is entitled “Fantastic Beasts and Where to Find Them”.
CommentExample.The comment title is: Doctor strange lost[24], as shown inFig.5.By translating Chinese into English, we obtain the result, as shown inFig.6.

Fig.4.Check step introduced.

Fig.5.Comment example.
3.4.Sentiment Standard lnterval
To efficiently illustrate the improvement of employing the method in this study, the normal distribution is conducted based on the sentimental values after analyzing and scoring.Because the scores of the examples on the YAHOO movie range from one to five stars, here we are going to score the results by 5 stars.The general standard intervals are shown inTable 4.The proposed sentimental value is divided into five intervals, as shown inTable 5.

Table 5: Proposed standard intervals

Fig.6.Score obtained from the online comment.

Table 4: General standard intervals
3.5.AOPN-Based Sentiment Analysis System
The CPN tools are employed to simulate the workflow in this study.Fig.7shows the entire workflow,which illustrates that the check step is introduced.It is unnecessary to rebuild the architecture after the original model is added.This approach also provides the requirement check, by adding the introduction,between “Sentimental value” and “Output” in the original model, which makes it accessible to pass the transition results only meeting the attached requirements.

Fig.7.AOPN for sentiment analysis.
Before outputting the sentimental value, it must pass the check rules.In the check step, the system compares the “sentimental value” with the “score”.As shown inTable 5, if they are identical, it will pass and get a recommendation level; if not, here comes the proposed standard interval.The proposed standard interval step re-compares the “sentimental value” with the “score” based on the standard intervals inTable 5to obtain the last recommendation level.
4.System Verification and lllustrative Examples
This section verifies the proposed approach and puts it into practice.To prove that it does help us ensure the correctness of sentimental analysis results, the first step is to analyze a fictitious comment, and to make a comparison of results between before and after employing the proposed approach.Next, we put our approach into practice, and the selected movie is entitled “Fantastic Beasts and Where to Find Them”.The test comments are obtained from the YAHOO movie.
4.1.System Verification
The check step in this study aims to make a comparison between “sentimental value” and “scoring”.The comment example is shown inFig.8.By translating Chinese into English, we obtain that:
Comment example.The plot in this movie is loose, and the length is shorter, but it is still worth a watch.
After analyzing the comment, here comes out the sentimental value.After going throughTable 5in the check step for a comparison, the “normal” result is given at the end.
If we output the result directly without going through the check step, as the model shown inFig.9,then the sentimental values will be associated with the recommendation levels inTable 4.The result under this condition turns out to be “highly unrecommended”.The mistaken result is caused by “deadlock”.
The mistaken results from the ignorance of “worth a watch” at the end of the comment and its five-star rate.It results in a lower sentimental value only because there are more negative words in the comment.
While we have the comment going through the check step, here it comes out “normal”.Compared with the previous one, “highly unrecommended”, it is obvious that the correctness is improved successfully, getting closer to the actual meaning of this comment.

Fig.8.Comment example.
Fig.9.Deadlock.
4.2.lllustrative Examples
To verify that the proposed approach can help us improve its correctness, this study randomly picks up ten comments on the movie entitled “Fantastic Beasts and Where to Find Them” by screenshot.The screenshot can help us identify the recommendation level of comments and examine the results more easily.All translation results are given by machine translation.
Example1.
By translating Chinese shown inFig.10into English, we obtain that:
Comment1.Doctor strange lost[24].
By using the classifiers in SnowNLP, we obtain the results shown inFig.11.
Example2.
Comment 2 is shown inFig.12, by translating the Chinese into English, the results are shown as:

Fig.10.Comment 1.

Fig.11.Analysis results from Comment 1.
Comment2.The movie is empty but I think it was great[24].
By using the classifiers in SnowNLP, we obtain the results, as shown inFig.13.

Fig.12.Comment 2.

Fig.13.Analysis results from Comment 2.
Example3.
By translating Comment 3 shown inFig.14, we obtain:
Comment 3: The movie was not more entertaining than Harry Potter[24].
Using the classifiers in SnowNLP, the results are shown inFig.15.

Fig.14.Comment 3.

Fig.15.Analysis results from Comment 3.
Example4.
Comment 4 is shown inFig.16, by translating we obtain:
Comment4.Not bad.Suggestions to watch 3D[24].
By using the classifiers in SnowNLP, we obtain the results, as shown inFig.17.

Fig.16.Comment 4.

Fig.17.Analysis results from Comment 4.
Example5.
By translating Comment 5 shown inFig.18, we obtain:
Comment5.The story is boring.Finally, it beats the BOSS in 30 seconds[24].
Using the classifiers in SnowNLP, the results are shown inFig.19.

Fig.18.Comment 5.

Fig.19.Analysis results from Comment 5.
Example6.
Comment 6 is shown inFig.20, by translating we obtain:
Comment6.The actor did a great job.No wonder…[24].
By using the classifiers in SnowNLP, we obtain the results, as shown inFig.21.

Fig.20.Comment 6.

Fig.21.Analysis results from Comment 6.
Example7.
By translating the Chinese comment (seeFig.22) into English, we obtain the results:
Comment7.It is an action film and has shown the dark sides of humanity[24].
By using the classifiers in SnowNLP, we obtain the results, as shown inFig.23.

Fig.22.Comment 7.

Fig.23.Analysis results from Comment 7.
Example8.
By translating Comment 8 shown inFig.24, we obtain the results:
Comment8.Harry Potter fans love it with a great plot[24].
By using the classifiers in SnowNLP, we obtain the results, as shown inFig.25.

Fig.24.Comment 8.

Fig.25.Analysis results from Comment 8.
Example9.
By translating the Chinese shown inFig.26into English, we obtain the results that as Comment 9.
Comment9.J.K.Rowling’s imagination of the magic world is richer than Harry Potter’s.The movie was worth waiting for.However, the plot was very predictable and there was no punch line.I have been watching the shadow of the Danish Girl.At the beginning of the film, the main actor did not act well, but by the end of the movie, he improved[24].
The results of the classifiers in SnowNLP are shown inFig.27.

Fig.26.Comment 9.

Fig.27.Analysis results from Comment 9.
Example10.
By translating the Chinese shown inFig.28into English, the results can be shown as follows:

Fig.28.Comment 10.
Comment10.That film was fantastic! Let me remember Harry Potter! I expect the sequel[24].
Using the classifiers in SnowNLP, the results are shown asFig.29.

Fig.29.Analysis results from Comment 10.
The comments are transformed into the analysis results, as shown inTable 6.To get the accurate results of some comments, it is necessary to know its contexts, like Example 1 and Example 2.However, by employing the proposed approach in this study, even if the contexts are unknown, one can still get an accurate recommendation level of comments easily.
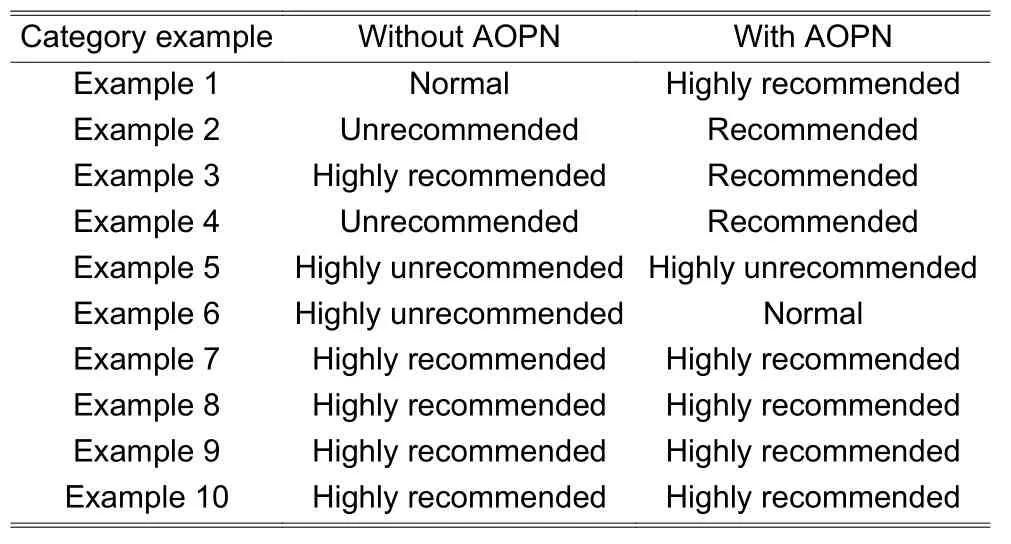
Table 6: Recommendation levels
4.3.Comparison of Analysis Results
To verify that the effectiveness of the proposed approach, this study compares the proposed approach with the other two systems, Tencent Natural Language Process (Tencent NLP) and NLPIR.
4.3.1.TencentNLP
This is an open platform based on the parallel computing system and distributed crawler.It can satisfy one-stop needs of Chinese semantic analysis, including NLP, transcoding, extraction, and whole network data capture.Users can use API provided by the platform to realize applications, including the analysis of keywords, sentiment, and text clustering[25].
4.3.2.NLPIR
The NLPIR segmentation system is developed by ICTCLAS.Its main functions include Chinese segmentation, parts of speech (POS) tagging, named entity recognition, user dictionary, and keywords identification[26].
To efficiently illustrate the recommendation level of employing the proposed approach, the normal distribution is conducted according to the sentimental values after analyzing and scoring criteria.Because the score of the system ranges from 0 to 100, the recommendation level is shown inTable 7.

Table 7: Recommendation levels
We adopt Example 1 to Example 10 as stated in subsection 4.2, analyze them by using Tencent NLP and NLPIR, and obtain the analysis results, as shown inTable 8.
We compare the proposed approach with the other two systems based on recommendation levels,as shown inTable 9, and compare the proposed approach with the other two systems based on the functional results, as shown inTable 10.
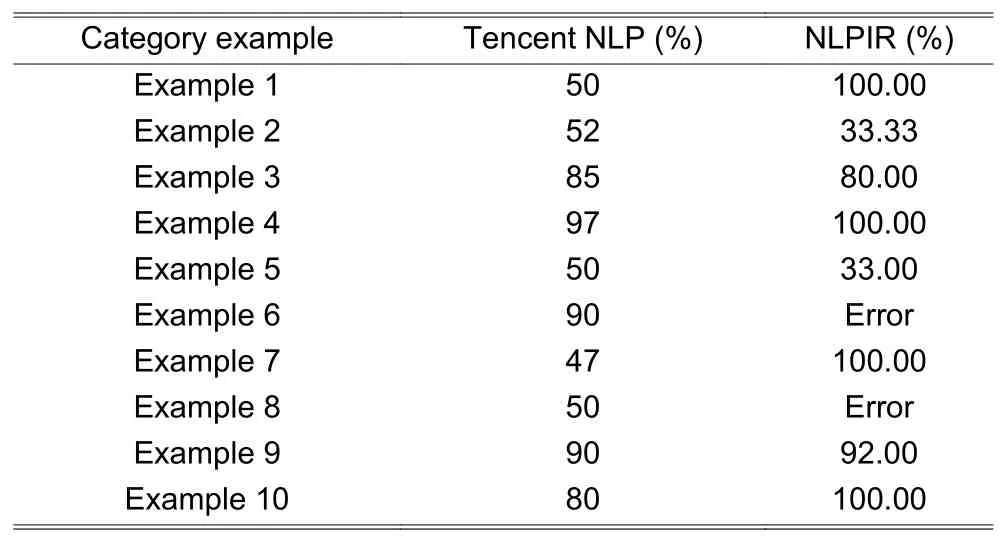
Table 8: Probability of the positive sentiment
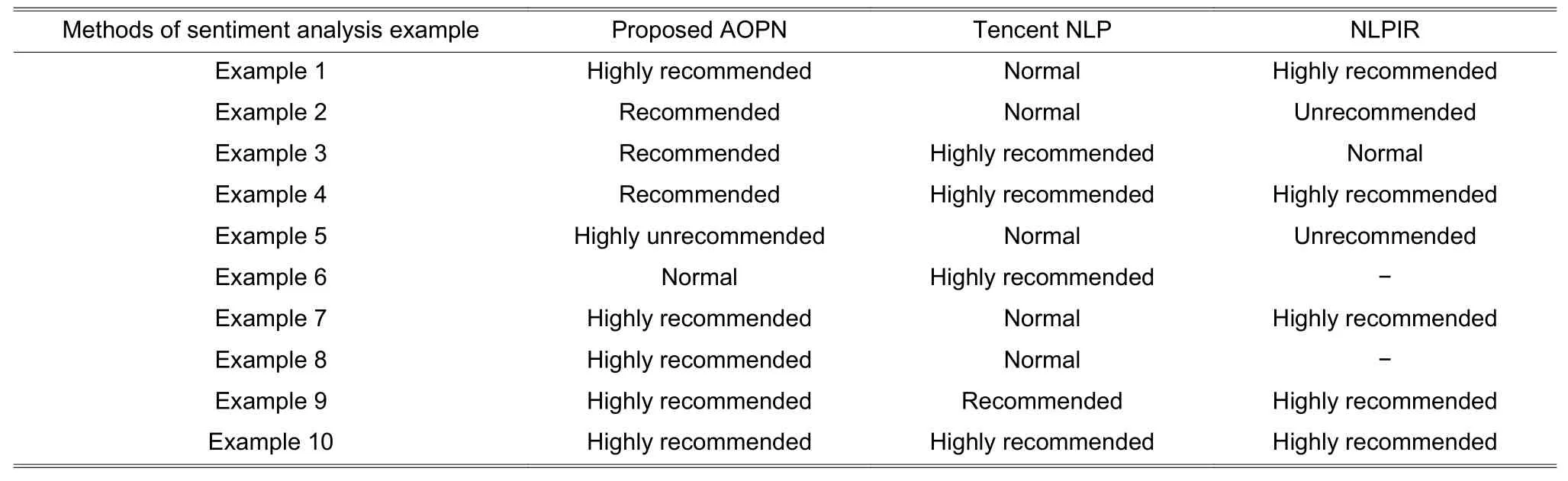
Table 9: Recommendation level comparisons

Table 10: Functional comparisons
According to the comparison results, the proposed approach is getting closer to what this comment actually means than the other two systems.For instance, in Example 3, using Tencent NLP and NLPIR, the analysis results and sentence meaning are inaccurate.If the length of a sentence is too short or the sentence lacks keywords, this sentence is unable to be analyzed for NLPIR, such as, Examples 6 and 8.
5.Conclusion and Future Work
The era of big data has come.It is more and more important to capture the commercial values from the text messages on the Internet.Correct sentiment analysis can improve the quality of products or services of the business company and its future development.The sentiment analysis problem is caused by the fact that the machine mainly lacks the artificial examination and the only way for the machine to judge a sentence of comments is using its algorithm or lexicon.
The contributions of this paper are presented as follows:
1) It resolves the sentiment analysis problems caused by the lack of artificial examination.
2) It is more effective in capturing the useful advice to improve the quality of products or services.
3) Even though the machine cannot infer comments based on tone (e.g., sarcasm and warnings), context information (such as the Internet buzzword), and other reviews, the proposed method can still efficiently improve the correctness of analysis results.
The proposed method for sentiment analysis can be used to commodity or service improvement.In the future, it can also analyze the sentences in bad news, and some things of regret or crime could be avoided somewhat by using it.
Acknowledgment
The authors are very grateful to the anonymous reviewers for their constructive comments which have improved the quality of this paper.
Disclosures
The authors declare no conflicts of interest.
杂志排行

Journal of Electronic Science and Technology的其它文章
- Journal of Electronic Science and Technology Information for Authors
- Investigating the Relevance of Arabic Text Classification Datasets Based on Supervised Learning
- Knowledge Graph and Knowledge Reasoning:A Systematic Review
- Memristor-Based Genetic Algorithm for lmage Restoration
- Coherent Optical Frequency Combs: From Principles to Applications
- Salp Swarm Algorithm for Solving Optimal Power Flow Problem with Thyristor-Controlled Series Capacitor