Knowledge Graph and Knowledge Reasoning:A Systematic Review
2022-07-08LingTianXueZhouYanPingWuWangTaoZhouJinHaoZhangTianShuZhang
Ling Tian | Xue Zhou | Yan-Ping Wu | Wang-Tao Zhou | Jin-Hao Zhang | Tian-Shu Zhang
Abstract—The knowledge graph (KG) that represents structural relations among entities has become an increasingly important research field for knowledge-driven artificial intelligence.In this survey, a comprehensive review of KG and KG reasoning is provided.It introduces an overview of KGs, including representation, storage, and essential technologies.Specifically, it summarizes several types of knowledge reasoning approaches, including logic rules-based, representation-based, and neural network-based methods.Moreover, this paper analyzes the representation methods of knowledge hypergraphs.To effectively model hyper-relational data and improve the performance of knowledge reasoning, a three-layer knowledge hypergraph model is proposed.Finally, it analyzes the advantages of three-layer knowledge hypergraphs through reasoning and update algorithms which could facilitate future research.
1.lntroduction
The knowledge graph (KG) describes the objective world’s concepts, entities, and their relationships in the form of graphs.It can organize, manage, and understand massive information in a way close to human cognitive thinking.In that case, KG plays an important role in a variety of downstream applications, such as semantic search, intelligent recommendation, and question answering.
KG reasoning, which is essential for the KG applications, improves the completeness of KG by inferring new knowledge.However, there is little research that systematically summarizes and analyzes KG reasoning.Furthermore, KG reasoning has attracted wide attention and a series of advanced approaches have emerged in recent years.Hence, a comprehensive review of KG reasoning is necessary and could promote the development of related research.
The main contributions of this paper include: First, it summarizes the representation, storage, and essential technologies of KG.Second, it gives a fine-grained classification of KG reasoning, and analyzes the typical methods, solutions, and advantages and shortcomings of each category in detail.Third, it summarizes the research of knowledge hypergraphs.Finally, it proposes a three-layer framework of knowledge hypergraphs, which can greatly improve the ability and efficiency of reasoning as well as updating.
2.KG Overview
Since Feigenbaum worked with Stanford University proposed expert systems in 1965[1], artificial intelligence (AI) research has changed from traditional reasoning algorithms to knowledge-driven algorithms.And in 1968, Quillian proposed the knowledge expression model of semantic networks[2].The establishment of the knowledge base (KB) and knowledge representation (KR) methods had fueled a wave of hot research topics.Then in 1977, Feigenbaum proposed the concept of knowledge engineering[3], demonstrating how to represent knowledge using the principles, methods, and technology of AI.Later, in 1989, Berners-Lee invented the World Wide Web (WWW)[4].The Semantic Web concept, which combined traditional AI with WWW, was proposed in 1998[5].
In 2012, Google proposed KG which was defined as KB[6].KG uses semantic retrieval methods to collect information from multiple sources to improve the quality of searches.In essence, KG is a semantic network composed of various entities, concepts, and relationships[7].This section mainly introduces the KG architecture, KR, storage, and essential technology.And the technology application framework of KG is shown inFig.1.It has 5 main components: KR learning (KRL), knowledge storage (KS), KG construction(KGC), knowledge updating (KU), and knowledge reasoning.Besides, KGC includes knowledge extraction(KE), knowledge fusion (KF), and knowledge processing (KP).The KG technology is the basis of knowledge reasoning and KG applications.
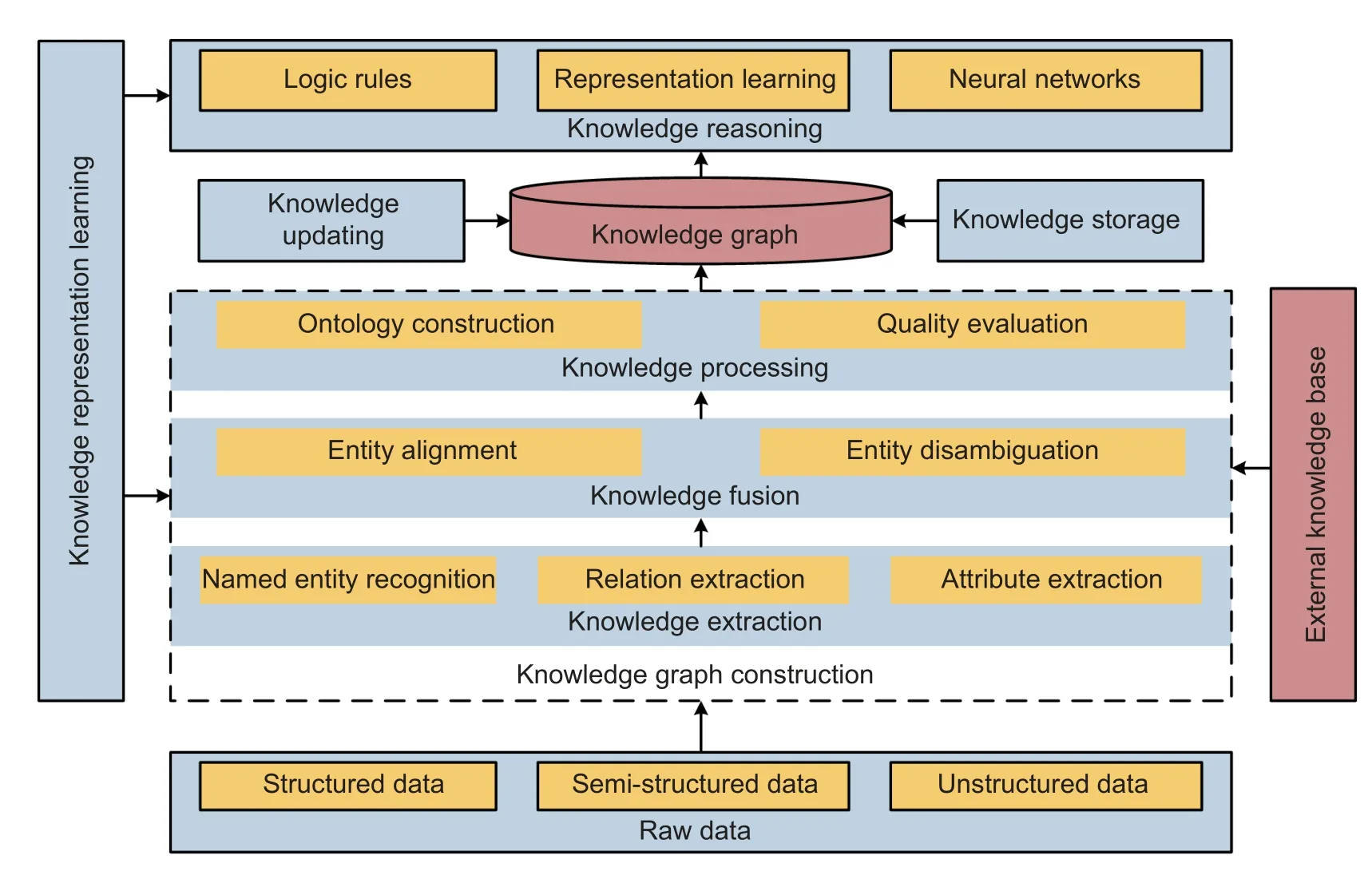
Fig.1.Technology application framework of KG.
2.1.Architecture of KG
KG, which can be divided into a pattern layer and a data layer, needs certain constraints and norms to form a logical architecture.The pattern layer represents the data structure of knowledge, the hierarchical structure, and definitions of knowledge classes, such as the entity, relation, and attribute.It restricts the specific knowledge form of the data layer.The knowledge triples in the data layer are viewed as units to store specific data information.Thus, KG can be generally expressed in the form of triplesG={E,R,F}.Among them,Erepresents the set of entities {e1,e2,…,ei} .Entityeis the basic element in KG.It refers to things that exist objectively and can be distinguished from each other, including people, things, or abstract concepts.Rrepresents the set of relationships {r1,r2,…,rj}.And the relationshiprrepresents the edge of a certain connection between two different entities in KG.Frepresents the set of facts {f1,f2,…,fk} and each fact is defined as a triple (h,r,t)∈F, whereh,r, andtrepresent the head entity, relationship, and tail entity,respectively.For example, basic types of facts can be expressed as triples (Entity, Relation, Entity), (Entity,Attribute, Value), etc.
As shown inFig.2, the knowledge triple can be expressed through directed graph structures.The oneway arrow indicates the asymmetric relationship “Starring”, while the two-way arrow indicates the symmetric relationship “Co-star”.

Fig.2.Triple example.
2.2.KR and KS
KR and KS are the bases of the construction, management, and application of KG.Modern KGs are based on a massive amount of Internet data.Its growing scale poses a new challenge of the effective representation and storage of knowledge.
2.2.1.KR
KR refers to a method of knowledge descriptions.It could transform massive amounts of information in the real world into structured data by using information technology.Early KR methods include the first-order logic,Horn logic, semantic networks, production systems, and frame systems.With the development of the Internet and the Semantic Web, WWW Consortium (W3C) proposed the resource description framework (RDF), RDF schema (RDFS), and web ontology language (OWL) description languages.However, these traditional KR methods are based on symbolic logic, which are unable to represent a large amount of the real-world data.And it is also difficult to mine and analyze the semantic relationships between knowledge entities.In recent years, KRL based on deep learning has attracted extensive attention in the fields of speech recognition,image analysis, and natural language processing (NLP).KRL can calculate complex semantic relationships among entities efficiently through projecting the semantic information (such as triples) into a dense lowdimensional vector space.And it can be easily integrated with deep learning models to realize knowledge reasoning.We will introduce the details of knowledge reasoning based on KRL in Section 3.
2.2.2.KS
The purpose of KS is to find a reasonable and efficient approach for storing KGs.In existing research,most KGs are based on graph data structures.And there are three main storage methods of KS: RDF databases, relational databases (RDBs), and graph databases (GDBs).Nowadays, the main open-source RDF databases in academia include Jena[8]、RDF4J[9], and gStore[10].RDBs include PostgreSQL[11]and MySQL[12].Typical GDBs include Neo4j[13], JanusGraph[14], and HugeGraph[15].
2.3.Essential Technology
It requires a variety of efficient KG essential technologies to build large-scale, high-quality general KGs or domain KGs.Through the technologies, including KE, KF, KP, and KU, accurate extraction and rapid aggregation of knowledge can be achieved.
2.3.1.KE
KE is the basic and primary task of KG.Different entities, relationships, and attributes are extracted from raw data through automatic or semi-automatic KE, to support the construction of KGs.Early KE is mainly based on the expert rules.Through pre-defined KE rules, triple information can be extracted from the text.However, the traditional method relies on experts with domain knowledge to manually define the rules.When the amount of data increases, the rule-based method takes a long time and has poor portability, which is unable to support the construction of large-scale KGs.
Compared with rule-based KE, neural network-based KE can discover the entity, relationship, and attribute features automatically.And it is suitable for processing large-scale knowledge.The three main tasks of KE include named entity recognition (NER), relation extraction (RE), and attribute extraction (AE).
NER accurately extracts named entity information, such as people, locations, and organizations, from massive amounts of raw data (such as text).The main neural network-based methods for NER include the convolutional neural network (CNN)[16],[17]and recurrent neural network (RNN)[18],[19].
RE is a hot research topic in the field of KGs and also the core of KE.By obtaining semantic relationships or relationship categories among entities, RE can automatically recognize the triples formed by entity pairs and the relationship between two entities.Neural network-based RE methods include CNN[20]-[22], RNN[23]-[25],attention mechanisms[26]-[29], graph convolutional network (GCN)[30]-[32], adversarial training (AT)[33]-[35], and reinforcement learning (RL)[36]-[38].In recent years, some researchers have proposed methods for joint entity and RE[39]-[42], which allows the models to incorporate the semantic relevance between entities and relationships.It can solve the problem of overlapping relationships, effectively improving KE.
AE extracts the attribute names and values of the entities from different information sources, constructs the attribute lists of entities, and achieves comprehensive descriptions of the entities.AE is generally divided into traditional supervised models (hidden Markov model, conditional random fields, etc.), unsupervised models[43],[44], neural network-based models[45], and other types of AE models (such as meta-patterns[46]and multimodal[47]).
2.3.2.KF
KF involves the fusion of the same entity in different KBs, different KGs, multi-source heterogeneous external knowledge, etc.It determines equivalent instances, classes, and attributes in KGs, to facilitate the update of existing KG.The main tasks of KF consist of entity alignment (EA) and entity disambiguation (ED).
EA constitutes the majority of the work in the KF stage, aiming to discover entities that represent the same semantics in different KGs.EA methods can be classified into traditional probability models (conditional random fields, Markov logic networks, latent Dirichlet allocation, etc.), machine learning models (decision tree, support vector machine, etc.), and neural networks (embedding-based CNN, RNN, etc.).
ED eliminates the ambiguity of entities in different text according to the certain text, and maps them to actual entities that they refer to.Based on the target KB, ED includes named entity clustering disambiguation and named entity linking disambiguation.
2.3.3.KP
KP processes basic facts and forms a structured knowledge system with high-quality knowledge based on KE and KF, to realize the unification of knowledge.KP includes ontology construction (OC) and quality evaluation (QE).
OC refers to the construction of conceptual entities of knowledge in the pattern layer based on the architecture of KG.It standardizes the description of the concepts and relationship between two concepts in a specified field, including concept extraction and inter-concept relationship extraction.According to the extent of automation in the construction process, widely used OC methods include manual construction, semiautomatic construction, and automatic construction.
QE is usually used in KE or the fusion stage, to improve the quality of knowledge extracted from raw data and enhance the effectiveness of KE.And it is able to obtain high-quality and high-confidence knowledge through QE.
2.3.4.KU
KU refers to the update of KG and increase of new knowledge, to ensure the validity of knowledge.As shown inTable 1, KU includes the pattern layer update, data layer update, comprehensive update, and incremental update.

Table 1: Content of KU
2.4.Category of KG
As shown inTable 2, categories of KG include early KB, open KG, common sense KG, and domainspecific KG.

Table 2: Categories of KG
Early KB is based on expert systems, which is applied to information retrieval and question answering systems.Open KG allows anyone to access, use, and share with the rule of open-source licenses.Common sense KG is significant to many NLP tasks.
Domain-specific KG has a wide range of application scenarios.For example, medical KG can provide correct and efficient retrieval and scientific interpretation, which benefits from medical knowledge question and answer, intelligent diagnosis and treatment, medical quality control and disease risk assessment, etc.Transportation KG can execute traffic volume modeling, air traffic management, and public transport data mining.KGs in finance can save massive amounts of financial data, including entities, relationships, and attributes, allowing for the predictions of hidden risks in complex information and promoting financial upgrading and transformation.
3.Knowledge Reasoning Methods
Due to the limitations of KG construction and the rapid change in real-world data, KGs usually suffer from missing knowledge triples.Moreover, the performance of downstream tasks can also be severely degraded.Therefore, knowledge reasoning, to predict the missing relationships in KGs, is of great research and application value.This section introduces the details of knowledge reasoning methods based on logic rules,representation learning, and neural networks.
3.1.KG Reasoning Based on Logic Rules
Knowledge reasoning based on logic rules refers to using simple rules and features in KGs to discover new facts.These methods can make good use of symbolic representations of knowledge.In that case, they can perform with high accuracy and provide explicit explanations for reasoning results.This subsection introduces three types of KG reasoning approaches based on logic rules, specifically logic-based reasoning,statistics-based reasoning, and graph structure-based reasoning.
3.1.1.ReasoningBasedonLogic
Logic-based knowledge reasoning refers to directly using first-order logic (FOL) and description logic to express the rules formulated by experts.According to the representation methods of rules, logic-based reasoning methods can be classified into reasoning based on FOL and reasoning based on description logic.
Knowledge reasoning based on FOL means that it adopts FOL to represent rules defined by experts, and then performs reasoning tasks by using propositions as basic units.Since it is conducted in a way that is close to natural human language, FOL-based reasoning achieves good interpretability and high accuracy for small-scale KGs.
Propositions are comprised of two parts, individuals and predicates.Individuals and predicates correspond to entities and relations in KG separately.As shown inFig.3, the user “Carl” likes the director “Roland Emmerich”, and the movie “The Day after Tomorrow” is directed by the director “Roland Emmerich”.It is possible that there is a relation “Like” between “Carl” and “The Day after Tomorrow”.Therefore, a FOL rule can be obtained:

where Λ means the conjunction operator, forming a Boolean-valued function, returning true only if all propositions are true.
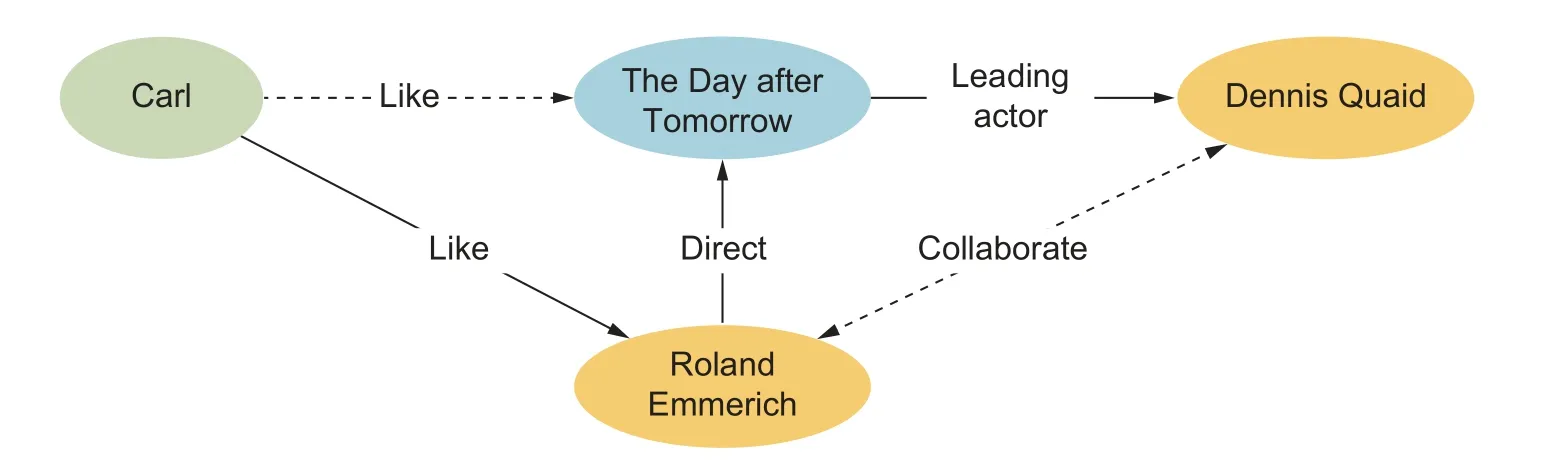
Fig.3.Example of knowledge reasoning methods based on logic rules.
Reasoning based on description logic aims to transform the complex entity and relation reasoning into a consistency detection problem.This method effectively reduces the reasoning complexity over KGs and achieves the tradeoff between the expressing ability and reasoning complexity.Specifically, KG represented by description logic is composed of terminological axioms (TBoxes) and assertional sets (ABoxes)[55].TBoxes contain a series of axioms describing concepts and relations, and ABoxes contain examples of concepts in TBoxes.This method conducts reasoning by judging whether a description satisfies logical consistency.
3.1.2.ReasoningBasedonStatistics
Knowledge reasoning based on statistics applies machine learning approaches to automatically extract hidden logic rules from KGs, and conducts reasoning using these rules.Those methods do not depend on expert-defined rules and can interpret the results of the reasoning with automatically extracted logic rules.Statistics-based reasoning methods can be further divided into two subcategories, which are based on inductive logic programming (ILP) and association rule mining, separately.
Reasoning based on ILP refers to using the machine learning and logic programming technology to automatically summarize abstract rule sets.This method abandons the usage of manually defined rules and achieves good reasoning ability over small-scale KGs.
The key idea of reasoning based on association rule mining is to automatically extract high-confidence rules, and then employ these rules in reasoning.Compared with traditional ILP methods, reasoning based on association rule mining is faster and can handle more complex and larger scale KGs.
3.1.3.Reasoning Basedon Graph Structure
Graph structure-based reasoning refers to using the structure of the graph as the feature to conduct reasoning.The most typical structure in KG is the paths between entities, which play an important role in KG reasoning.Reasoning based on the graph structure is efficient and interpretable.For example, inFig.3,starting from the node “Roland Emmerich”, based on the relation path “Direct→Leading actor”, it can be inferred that the entity “Roland Emmerich” and the entity “Dennis Quaid” may have the relation “Collaborate”.According to the granularity of features, graph structure-based reasoning methods can be divided into global structure-based and local structure-based models.
The essence of global structure-based reasoning is to extract paths of entire KG and use these paths as features to determine the existence of a target relation.
Reasoning with the local structure performs KG reasoning by using the local graph structure that is highly related to the reasoning as features.Compared with reasoning based on the global structure, this method focuses on the finer granularity of features and has a lower computational cost.
Table 3shows the current research of knowledge reasoning methods based on logic rules.

Table 3: Comparison of knowledge reasoning methods based on logic rules

Table 3 (continued): Comparison of knowledge reasoning methods based on logic rules
3.2.KG Reasoning Based on Representation Learning
In the field of machine learning, representation learning is a particularly important technique, which transforms complicated data structures into vectors.The traditional one-hot embedding of relational information faces the challenge of feature sparsity under the circumstance of large-scale data.Due to the limited accuracy of knowledge reasoning, semantic information is not incorporated in the representations of entities and relation types in this scenario.Thus, representations with more semantic information are needed for better reasoning quality.Through KRL, the semantic relationships between entities and relation types are well captured, and contained in the learned distributed embeddings, which guarantees a fixed semantic space.These distributed embeddings with abundant semantic information could facilitate expressive modeling of relations and boost the performance of knowledge reasoning tasks.By mapping hidden relational information in graphs into the low-dimensional space, KRL makes previously obscure correlations in graphs apparent.
Representation learning shows a great advantage over many other approaches.Thus, KG reasoning based on representation learning has been extensively studied in recent years.This subsection introduces and compares three types of KG reasoning approaches based on representation learning, including the tensor decomposition approach, distance model, and semantic matching model.
3.2.1.TensorDecompositionApproach
Tensor decomposition-based KG reasoning refers to decomposing the relation tensor of KG into multiple matrices, which can be used to construct a low-dimensional embedding of KG.Existing basic tensor decomposition algorithms are modified and applied to train a distributed representation of KG in a fast and efficient way.
RESCAL[77],[78]is currently the most widely used KG reasoning approach based on tensor decomposition.This model represents KG as a three-way tensor, which models the three-way interactions of entity-relationentity.RESCAL obtains representations of the entities and relation types by solving a simple tensor decomposition problem.The low-dimensional embedding calculated by RESCAL reflects the similarity of neighborhood structures of the entities and relation types in original KG.
A relational graph is shown inFig.4, which is a small part of large KG.The movies “2012” and “The Day after Tomorrow” are both directed by “Roland Emmerich” and written by “Harald Kloser”, but have different leading actors, namely “John Cusack” and “Dennis Quaid”, respectively.The neighborhood structure of“2012” is similar to that of “The Day after Tomorrow”, causing the two movies with similar embeddings.As a result, given that the movie “The Day after Tomorrow” belongs to the type “Science fiction”, RESCAL can determine that “2012” also belongs to the type “Science fiction”.

Fig.4.Example of knowledge reasoning problem.
RESCAL is a classic tensor decomposition model for representation learning.However, RESCAL is too simple and lacks interpretability, it cannot be directly applied in complex scenarios.Hence, numerous tensor decomposition models are developed to enhance the performance of representation learning.Nickeletal.[79],Rendleetal.[80], and Jenattonetal.[81]proposed three other KG representation learning approaches aiming at more complicated application situations.Table 4shows the details.

Table 4 (continued): Comparison of knowledge reasoning methods based on representation learning
3.2.2.DistanceModel
The distance model considers any relations in KG as a translational transformation from the subject embedding to the object embedding.By minimizing the transformation error, this type of models learns lowdimensional embeddings of all the entities and relation types in KG.
The representative distance model is TransE[82]and its derivatives.TransE, a well-known translational model, learns distributed representations of all entities and relation types by imposingh+r=tfor all relation triples in KG, whereh,t, andrdenote the embedding of the subject entity, the object entity, and the corresponding relation type, respectively.
Fig.5illustrates the mechanism of TransE with the previously given example.In order to find out whether “2012” and “Science fiction” share the relationship “Type”, as indicated by the dashed line,TransE projects all entities onto a low-dimensional space.“2012” and “Science fiction” are two existing entities, which are projected to Point A and Point B,respectively.Two other entities named “Mr.Bean”and “Comedy” are then projected to Point C and Point D, respectively.Since they already have the relation “Type”, the relation type “Type” can then be projected onto the embedding space asα, that is, the translation vector between the embedding point of “Mr.Bean” (Point C) and the embedding point of “Comedy” (Point D).Once all these embeddings are obtained,the existence of relation (2012, Type, Science fiction) can be determined by checking whether the embedding of “2012” (Point A) can be translated to the embedding of “Science fiction” (Point B) via the embedding of“Type” (α).If and only if this condition is satisfied, the relation (2012, Type, Science fiction) holds.
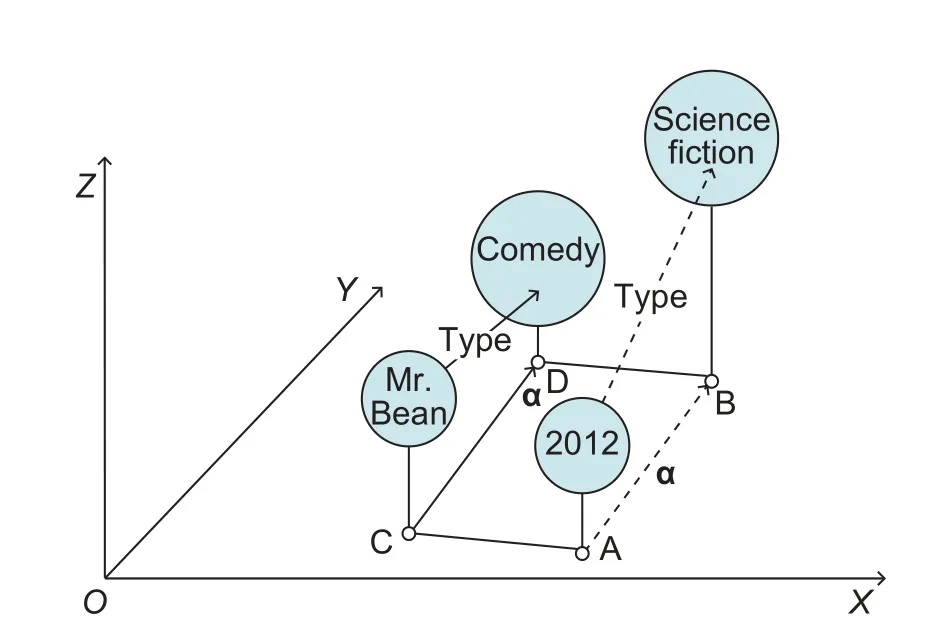
Fig.5.Example of entity and relation mapping of TransE.
TransE achieves good interpretability by formulating the problem in a straightforward way.Nevertheless,TransE has two limitations.One limitation is that the translation rule is too strict, which affects its flexibility and robustness.Thus, a number of relaxed translational models[83]-[87]are proposed to tackle noise in practical data.The other limitation has to do with the fact that TransE is not suitable for processing 1-to-N,N-to-1, orN-to-Nrelations, which largely limits its usage in practice.Some works[88]-[91]aim to solve this problem by separating the entity space and relation space to model their interactions in a projection space.Apart from these two types of derivatives, there are works focusing on other problems, including stochastic distance models[92],[93], rotation models[94], and other distance models[95].SeeTable 4for details of distance models.
3.2.3.Semantic Matching Model
The semantic matching model measures the validity of relation triples by matching hidden semantics among different entities and relation types in the low-dimensional space, using a scoring function.These models consider relations presented in KG similar, and those not in KG dissimilar.
Currently, the most widely used semantic matching models, e.g., two- and three-way embedding combination (TATEC)[96], mainly focus on matching two-way and three-way semantics in KG.Specifically, the validity of relations is evaluated using a linear scoring function.
Given a relational graph as shown inFig.4, TATEC first defines a scoring function for three-way relations,such as (Roland Emmerich, Direct, The Day after Tomorrow).For two-way relations, such as (Roland Emmerich, Directs), (Direct, The Day after Tomorrow), and (Roland Emmerich, The Day after Tomorrow),TATEC defines scoring functions in a similar way to evaluate their validity.For example, the three-way score of (Roland Emmerich, Direct, The Day after Tomorrow) is 0.35, and the two-way scores of (Roland Emmerich,Directs), (Direct, The Day after Tomorrow), and (Roland Emmerich, The Day after Tomorrow) are 0.25, 0.12,and 0.18, respectively.Then the total score for the triple (Roland Emmerich, Direct, The Day after Tomorrow)should be 0.90.The training process maximizes scores of the three-way and two-way relations presented in KG.When determining whether “2012” and “Science fiction” have the relation “Type”, TATEC simply calculates the score of the triple (2012, Type, Science fiction), and establishes the relation if the score is greater than an empirical threshold, such as 0.75.
TATEC suffers from high computational complexity due to a large number of parameters.Hence, a series of linear and bilinear models[97]-[101]try to balance its performance and complexity.
In order to better capture non-linear patterns of relations, numerous neural network-based representation learning models[102]-[105]based on semantic matching have been proposed.These models calculate scores of relations through deep neural networks.
The representation learning-based methods of knowledge reasoning are summarized and compared inTable 4.
3.3.KG Reasoning Based on Neural Network
Though more and more KG reasoning methods have been proposed, it still remains an open issue on complex and multi-hop relation reasoning.To analyze such relations, the neural network could be a more powerful tool than other reasoning methods based on logic rules or representation learning.After representation learning based on neural networks like CNN or RNN, the accurate understanding of knowledge semantics could benefit the subsequent reasoning process based on the fully connected layer and softmax layer.Moreover, such methods could realize automatical reasoning on KG without logical inference or theoretical modeling.Due to the generality of structures and the convenience of reasoning, KG reasoning methods based on neural networks emerge endlessly.Therefore, this subsection introduces the knowledge reasoning methods based on CNN, RNN, the graph neural network (GNN), and deep reinforcement learning(DRL) in detail.
Considering the knowledge subgraph shown inFig.6, RNN chooses the red, blue, and green paths as the input to reasoning the target relation between “Spider-Man” and “Life Story”.For the red path, RNN pays attention to the words like “hope” and “background” and keeps them in memory cells to increase the probability of the “main character” relation.For the blue path, since the participation of “Captain America” in“Vietnam War”, RNN notices the role of “Captain America” in “Life Story” and reasonings the friendship between “Spider-Man” and “Captain America”.For the green path, RNN forgets the “create” relation to some extent because all the relations are the same.At last, RNN synthesizes all the information in the three paths and obtains a high probability of the “main character” relation between the “Life Story” entity and the “Spider-Man” entity.Based on the final reasoning result of the friendship of “Spider-Man” and “Captain America” in“Life Story”, RNN decides to add a new triple (Life Story, main character, Spider-Man) to the knowledge subgraph.

Fig.6.Example of KG reasoning methods based on RNN.
CNN, which is capable of capturing the local characteristics of KG, is one of the earliest neural networks applied for knowledge reasoning.First, the knowledge triples could be an ideal learning object.With a twodimensional convolution on a two-dimensional entity relation embedding matrix, ConvE achieves the effective capture of interactive features between entities and relations[106].Besides, entity text descriptions provide more information for the entities in the knowledge triples.The most typical example is description-embodied knowledge representation learning (DKRL)[107],[108], which utilizes continuous bag-of-words (CBOW) and CNN to learn the unordered features and word-order features of text descriptions separately.After that, the fused feature achieves effective discovery of new entities.
Additionally, only focusing on single knowledge triples would limit the reasoning scope.Many studies seek to explore a wider reasoning scope, focusing on using RNN to analyze the knowledge path that is alternately composed of entities and relations[109]-[112].This research could effectively combine different representations of knowledge paths.Moreover, RNNs could also be used to analyze entity text descriptions.As a typical method, the learning knowledge graph embedding with entity descriptions based on long short-term memory(LSTM) networks (KGDL)[113]utilizes LSTM to encode related text descriptions, then uses triples to encode entity descriptions, and realizes the prediction of missing knowledge.
Since KG is based on the graph structure, GNN[114]has been widely explored for knowledge reasoning in recent years.It enlarges the learning scope from a single triple in CNN or knowledge path in RNN to knowledge subgraphs in GNN.For instance, the structure aware convolutional network (SACN)[115]utilizes one weighted GCN as an encoder and a convolution network Conv-TransE as a decoder.As a result, SACN realizes the adaptive learning of semantic information in the node’s neighborhood structure.While GCN has the powerful subgraph learning ability, it simply models a one-way relation as a two-way relation and suffers from the modeling error of relation direction.However, the graph attention network (GAT) explicitly distinguishes the bidirectionality of edges.As an improvement, ReInceptionE[116]combines ConvE and KBGAT to achieve deep understanding of KG structural information.
In terms of interactive modeling ideas, DRL[117]provides a new perspective for knowledge reasoning.As the most typical model, Deeppath[118]treats the knowledge entities as the state space and wanders between entities by choosing relations.If it reaches the correct answer entity, Deeppath will receive a reward.In essence, this kind of method establishes a reasoning plan based on relation path exploration.As a result,DRL methods could significantly improve the effectiveness and diversity of knowledge reasoning.
Table 5lists the details and comparison of reasoning methods based on neural network models.

Table 5: Comparison of knowledge reasoning methods based on neural network models

Table 5 (continued): Comparison of knowledge reasoning methods based on neural network models
4.Knowledge Hypergraph Theory
Despite KG being universally adopted, representation methods based on triples often oversimplify the complexity of the data stored in KG, especially for hyper-relational data.In hyper-relational data, each fact contains multiple relations and entities.To understand the characteristics of knowledge hypergraphs more clearly,Table 6shows the definitions of knowledge hypergraphs and related graphs.
Table 7gives the comparison of knowledge hypergraph representation methods which mainly include soft rules-based, translation-based, tensor decomposition-based, and neural networks-based methods.To realize reasoning, the soft rules-based method considers relation and node as predicate and variable separately.Then it sets the logic rules and constraints for relational reasoning.The translation-based method aims to model the relation as a transformation operation between entities.The tensor decomposition-based method represents a hyper-relational fact as ann-order tensor (nis the number of entities in a hyperrelational fact).Then it learns the embedding of entities through tensor decomposition.The neural networksbased method can learn the interaction information between entities, the topological structure information of the graph, etc.
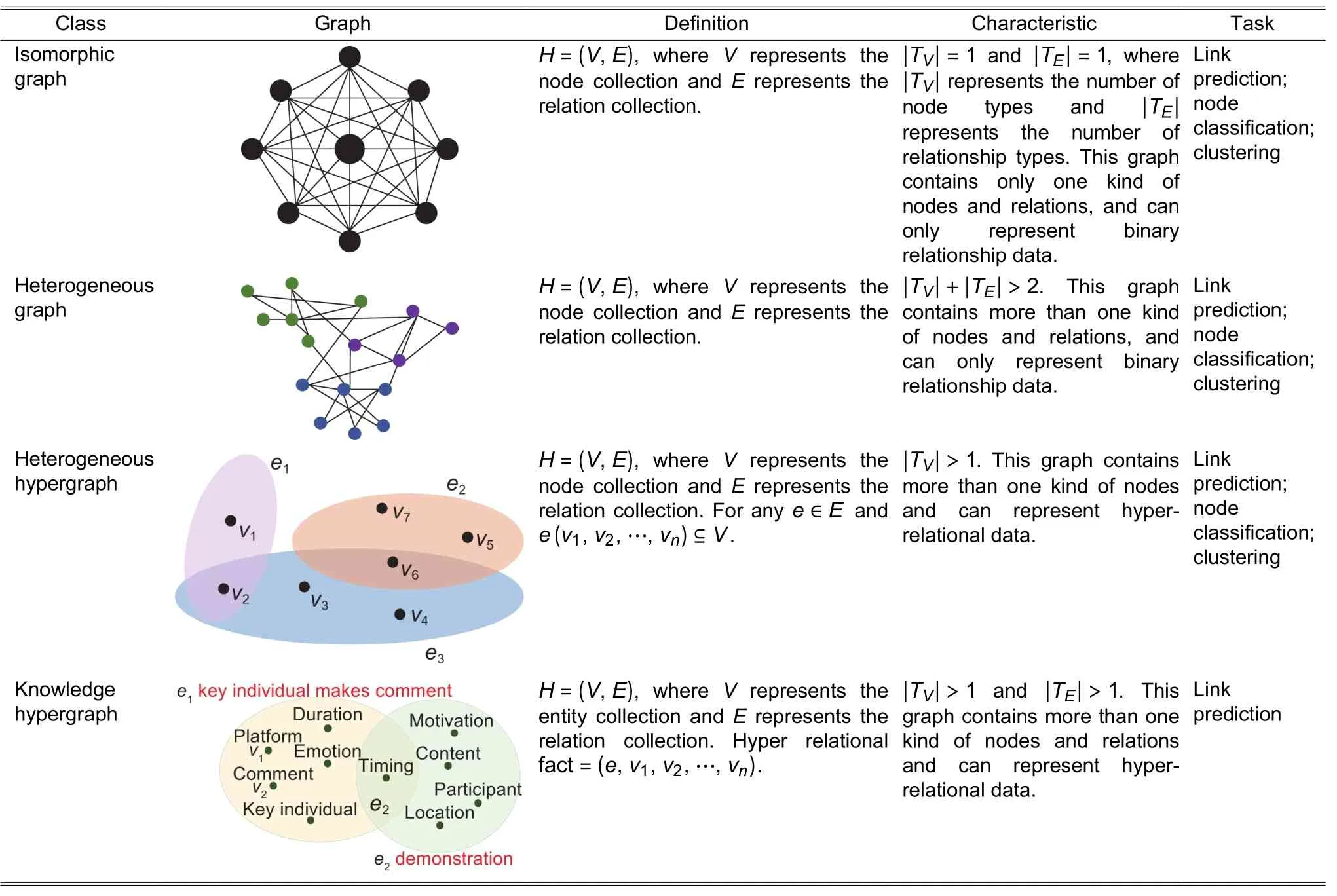
Table 6: Definitions of knowledge hypergraph and related graphs

Table 7: Comparison of knowledge hypergraph representation methods
The knowledge hypergraph adopts a flat structure to organize knowledge and lacks the ability to explicitly leverage temporal and spatial knowledge, it may lead to vague spatio-temporal relations, slow update, and reasoning speed.As shown inFig.7, a three-layer knowledge hypergraph (TLKH) is proposed to combine the event layer, concept layer, and instance layer.Compared with the existing knowledge hypergraph, TLKH has the following three advantages: Explicit spatio-temporal relations, fast knowledge update, and fast knowledge reasoning.

Fig.7.Structure of three-layer knowledge hypergraph.
TLKH is represented asG={L1,L2,L3,R}, whereR={R(L1,L2),R(L2,L3)} represents the collection of crosslayer relations.The first layer is the event layer, defined asL1={EL1,RL1}, whereEL1andRL1are the sets of event entities and logical relations between entities separately.The second layer is the concept layer, defined asL2={EL2,RL2}, whereEL2andRL2are the sets of concept entities and hyperedges separately.The third layer is the instance layer, defined asL3={EL3,RL3}, whereEL3andRL3are the sets of instance entities and hyperedges separately.
Fig.7shows the structure of TLKH which organizes the instance, concept, and event knowledge hierarchically.It includes the related entities and relations in the scenario of the highest-grossing movies.Entities in the event layer are abstracted events.For example, “Hig_grossing” can represent multiple specific Hig_grossing events, such as the highest-grossing Hollywood film and the highest-grossing Chinese film.The edges between event entities are logical relations which have various types in different application scenarios.This paper adopts the four main relations which include “Condition”, “Compose”, “Succeed”, and “Cause”.For example, “Political”, “Nature”, “Pub_opinion”, “Economic”, and “Social” cause “Hig_grossing”.
The entity in the concept layer represents a group of different instances sharing common properties, such as “Country”.The edge between concept entities is a hyperedge, such as the hyperedge “Fil_grossing” which connects (Company, Actor, Movie, Timing, Duration, Box_office).This hyperedge can clearly express the relevance between concept entities.
The entity in the instance layer is concrete entities that describe the real world, such as “American”.The edge between instance entities is hyperedges, such as the hyperedge “Fil_grossing” connecting (Fox, Quaid,DAT, 2004/5/28, 40_days, $0.6B).
The cross-layer relation between the event layer and the concept layer is the relation between the event entity and the concept hyperedge.For example, the event entity “Hig_grossing” corresponds to the concept hyperedge “Fil_grossing”.The relation between the concept layer and the instance layer is the mapping relation between the concept entity and the instance entity.For example, the concept entity “Country”corresponds to the instance entity “American”.
Timing and duration are proposed to represent the spatio-temporal characteristics of knowledge hypergraphs.Timing is an attribute entity, which represents the entity or hyperedge generated or occurred at a specific time.For example, “Timing” is in the concept layer and “2004/5/20” is in the instance layer.Duration is another attribute entity, which means that the entity or hyperedge is valid within a period, such as“Duration” at the concept layer and “140_days” at the instance layer.
According to TLKH inFig.7, the reasoning process is shown in Algorithm 1 (Table 8).According to the entitiess1(2004/5/20) ands2(2004/5/28), there is a “Cause” relation between “Social” and “Hig_grossing” in the event layer.Algorithm 2 (Table 9) shows the update process of TLKH.Inputting a new event entitye1and its related concept and instance entities, these entities can be easily added to the right places quickly.

Table 8: Algorithm 1

Table 9: Algorithm 2
To reason the implicit relations between event entities, the normal knowledge hypergraph needs to find the implicit relation between any entity pairs by reasoning (ne+nc+ns)2times, wherene,nc, andnsare the numbers of entities in the event, concept, and instance layers.According to Algorithm 1, TLKH needs to find the implicit relation between any instance entity pairs by reasoningtimes.Implicit relations in the concept and instance layers can be found through cross-layer relations.Through the knowledge complementarity between layers and the spatio-temporal characteristics, the query space of reasoning can be reduced, and the speed of knowledge reasoning can be accelerated dramatically.
To update an event {e1, {c1,c2,…,ci}, {s1,s2,…,sj}}, the normal knowledge hypergraph needs to calculate the similarity between {e1, {c1,c2,…,ci},{s1,s2,…,sj}} and all existing entities withne+inc+jnstimes, whereiandjare the numbers of concept and instance entities related to evente1.According to Algorithm 2, TLKH needs to calculate the similarity betweene1and other event entities bynetimes.Related entities {{c1,c2,…,ci}, {s1,s2,…,sj}} can be located through cross-layer relations.It shows that TLKH is highly efficient, which can greatly accelerate the update process.
Based on the above analysis, the advantages of TLKH are obvious.The hierarchical knowledge hypergraph is powerful when it comes to organizing the domain-specific knowledge.It can learn implicit spatio-temporal relations and greatly accelerate the speed of knowledge update and reasoning.Moreover,TLKH can facilitate the future research of large-scale KG by utilizing hierarchical organization and spatiotemporal characteristics.
5.Conclusion
This paper introduces KG and summarizes knowledge reasoning and knowledge hypergraph.Especially,this paper focuses on the reasoning methods, because of the important role of knowledge reasoning in the practical application of KG, based on logic rules, representation learning, and neural networks.And it is beneficial to downstream tasks, such as the link prediction.For effective and efficient reasoning and updating of KG, this paper proposes TLKH, which could express the spatio-temporal relations and make the knowledge reasoning and updating faster.
KG changes the traditional KS and usage approaches, providing a solid knowledge foundation for the development of knowledge-driven artificial intelligence.In the future, KG could influence cognitive intelligence,and knowledge reasoning could be applied and extended to other aspects.
Disclosures
The authors declare no conflicts of interest.
杂志排行

Journal of Electronic Science and Technology的其它文章
- Journal of Electronic Science and Technology Information for Authors
- Modeling and Verification of a Sentiment Analysis System Using Aspect-Oriented Petri Nets
- Investigating the Relevance of Arabic Text Classification Datasets Based on Supervised Learning
- Memristor-Based Genetic Algorithm for lmage Restoration
- Coherent Optical Frequency Combs: From Principles to Applications
- Salp Swarm Algorithm for Solving Optimal Power Flow Problem with Thyristor-Controlled Series Capacitor