神经网络的声场景自动分类方法∗
2022-07-07姜文宗刘宝弟王延江
梁 腾 姜文宗 王 立 刘宝弟 王延江
(1 中国石油大学(华东)海洋与空间信息学院 青岛 266580)
(2 中国石油大学(华东)控制科学与工程学院 青岛 266580)
0 引言
声场景是指人们的日常环境和周围发生的各种物理事件所产生的声音。如,繁忙的街道上产生的嘈杂声和汽车鸣笛声,以及各种施工工地上产生的机器轰鸣声等。而利用计算机来自动提取这些声场景并对其进行分类具有重要的应用价值,如,场景声频监控[1]、设计助听器[2]、构建智能房间[3]和制造智能汽车等。
目前,对真实环境中的声场景即声事件进行精准的自动分类,还存在较大的困难。因为在真实的声场景中,通常会同时出现多种声事件,这导致某类声事件会受到其他背景声的干扰,从而使机器自动识别变得困难。因此,声场景分类具有重要的研究价值。近些年随着卷积神经网络(Convolutional neural network,CNN)的发展,出现了许多基于CNN 的声场景分类方法,其中时频卷积神经网络(Temporal-spectral convolutional neural network,TS-CNN)提出了时频注意力模块[4],是目前声场景分类效果最好的网络之一,但是由于其结构复杂且层数较多,导致其运算效率较低,推理开销大。为了提高性能,当前网络都是朝着更重、更复杂的方向发展,但是大型网络对搭载设备要求高,且运算速度慢,不利于实际应用。因此如何能够在不增加推理计算量的情况下提高网络的声场景分类能力,成为一大难题。
在不提高网络参数量的前提下,已有的提高深度卷积神经网络性能的方法包括协同学习(Collaborative learning)[5]、多任务学习[6]和知识蒸馏[7]等。其中,协同学习是在网络的中间层连接额外的分类器对中间层进行直接监督。多任务学习是把多个相关任务放在一起学习,通过设计多个损失函数同时学习多个任务。而知识蒸馏是将已经训练好的大型教师网络中包含的知识,蒸馏提取到小型的学生网络。2015年,Hinton等[7]提出了知识蒸馏的方法,成功实现了网络与网络之间的知识转移,但是知识蒸馏方法存在多网络训练,且设计复杂的缺点。2016年,Søgaard 等[8]证明了多任务学习的性能取决于多个相关任务的相似性,而在声场景分类中难以找到合适的相似任务。2018年,Song等[5]对协同学习中辅助分支的设计和不同引入中间层位置的选择进行了研究,研究证明简单的添加辅助分类器并不能提高网络的性能,而经过对辅助分支的结构进行设计和选择恰当的引入中间层位置可以有效提高网络性能。所以本文采用协同学习来对网络进行改进。
本文提出了一种基于协同学习的时频卷积神经网络模型(TSCNN-CL),能够在保持推理计算量不变的前提下,有效提高网络的声场景分类性能。本文的主要贡献包括:(1) 提出了在网络靠前的中间层上附加辅助监管分支,这些辅助监管分支可以起到一个鉴别中间层提取特征图的质量的作用。(2) 设计了一种同构分支结构,该结构可以提高主干网络的声场景分类性能。(3) 设计了一种基于KL散度的协同损失函数,在主干网络与辅助监管分支之间实现了成对知识交流,从而起到了正则化的作用,提高了网络的鲁棒性。(4) 采用了一种基于协同学习的测试策略,在测试时将辅助监管分支屏蔽,保持推理量不变,使模型便于工业部署中的实际应用。本文将所提出的模型在ESC-50、ESC-10 和UrbanSound8k 三个常用声音分类数据集上进行了实验验证,实验结果表明所提出的TSCNN-CL模型的平均分类准确率分别为84.6%、93.5%和84.5%,相比于在TS-CNN 模型上的实验结果分别提升了1.2%、1.5%和1.0%。
1 声场景的特征提取
由于所需识别的声事件常常被背景噪声所掩盖,因此准确地提取其特征是声场景分类的关键。目前常用声音特征提取方法有短时傅里叶变换(Short-time Fourier transform,STFT)、小波谱图和Mel 谱图。其中,STFT 的方法是采用一个窗口函数,将声信号分割成许多小的时间间隔,然后对每一个时间间隔做傅里叶变换,以确定该时间间隔的频率;小波谱图是通过对声信号进行多尺度分解,将声信号分解到不同尺度上进行表示[9],从而得到声信号的时频表达;而Mel 谱图是基于人类听觉系统对不同频率尺度的感知,在STFT 基础上进一步提取具有不同频率成分的特征信息,与STFT和小波变换相比,它提供更集中的声音频谱表示。由于这些时频表达方法得到的频谱图可以看成一幅图像,因此也可以采用图像处理的方法对其特征进行进一步描述,常用的方法如局部二进制模式(Local binary patterns,LPB)或方向梯度直方图(Histogram of oriented gradient,HOG)等[10]。
上述声音特征提取方法只适合对特定领域的声信号进行表达。而对数梅尔谱图法(Log-Mel) 通过对梅尔谱图取对数,压缩了频率的尺度,使特征变化更加平稳。同时避免了梅尔谱图因频率相差过高而导致的数据计算困难、低频率数据容易被忽视等问题,能够对不同领域的声信号进行更准确的表达。为此,本文选择Log-Mel谱图对声音特征进行表达。图1展示了一段烟火声的Log-Mel谱图。

图1 烟火的对数梅尔谱图示例Fig.1 Example of Log-Mel of pyrotechnics
2 时频卷积神经网络
时频卷积神经网络(TS-CNN)是由Wang等[4]提出的用于声场景分类的CNN,弥补了此前网络在提取深层特征时没有充分利用声音特有的频率和时间特征的缺陷。TS-CNN 在CNN 中引入时间—频率平行注意力机制,通过根据不同时间帧和频带的重要性进行加权对时间和频谱特征进行有选择的学习,同时平行分支构造可以分别应用时间注意力和频谱注意力,有效避免了噪声干扰。
TS-CNN 的网络结构如图2所示。它由4 个时频卷积模块(TFblock)组成,分别具有64、128、256和512 个输出通道。其中每个卷积模块包含2 个卷积层,卷积核大小为3×3,提取的对数梅尔谱图先通过时频注意力模块进行提取特征,然后经过平均池化层进行下采样,最后连接全局池化层和全连接层。在每个卷积层后都采用批量归一化层[11]和ReLU[12]激活函数。4 个卷积层模块依次相连,使用Softmax分类器进行分类。

图2 TS-CNN 结构框图Fig.2 TS-CNN model framework
TS-CNN 可充分利用声音固有的频率和时间特征,能够有效降低噪声的干扰,但由于TS-CNN网络层数较深,且在训练时采用非凸优化算法,导致网络在训练的时候,容易陷入局部最优值,并且伴随着梯度消失和梯度爆炸的现象,因此达不到最优效果。为了解决这一问题,在不增加推理量的前提下提高性能,本文在TS-CNN 的基础上引入了协同学习,提出了TSCNN-CL网络。
3 协同时频卷积神经网络
协同时频卷积神经网络(TSCNN-CL)是在TSCNN 基础上引入了协同学习的方法,通过增加两个协同分支以使得网络训练更加充分。增加CNN 的深度虽然可以一定程度上提高网络的表征能力,但随着深度加深,会逐渐出现神经网络难以训练的情况,其中就包括像梯度消失和梯度爆炸等现象。为此,TSCNN-CL 在神经网络的中间层引入辅助的分支分类器,辅助分支分类器能够判别中间层提取的特征图质量的好坏,并且为中间层提供直接的监督,而不是CNN 通常采用的仅在输出层提供监督,然后将此监督传播回早期层的标准方法。并且为每个分支设计了基于KL 散度的辅助损失函数,使分支和主干之间进行信息交互,提高了网络的泛化能力。
3.1 网络结构
TSCNN-CL 的模型结构如图3所示。具体地,先将TF 模块1、TF 模块2 和TF 模块3 的输出分别标记为C、B、A位,然后从C位和B位分别引出两条同构分支,在分支之间进行KL 散度计算作为协同损失函数。其中,同构分支的网络结构与主干网络的网络结构完全相同。

图3 TSCNN-CL 模型结构图Fig.3 TSCNN-CL model framework
3.2 协同损失函数
在TSCNN-CL 中,两个协同分支采用交叉熵作为损失函数。而为了实现不同分类器之间的知识协同,在不同分支之间设计了一种基于KL 散度的协同损失函数,使得连接到主干网络的所有分支之间可以进行信息交流,进一步优化网络性能。
设D={(xi,yi|1 ≤i≤N}为包含N个样本的数据集,其中xi是第i个训练样本,yi是对应的真实标签。此外,设f(W,xi)为CNN的输出向量。对于只在网络的最后一层增加监督的标准训练方案,优化目标可表示为

其中,L1为默认损失,R为正则化项,λ是正则化系数。在公式(1)中,L1由式(2)计算:

其中,H( )是交叉熵损失函数,定义为
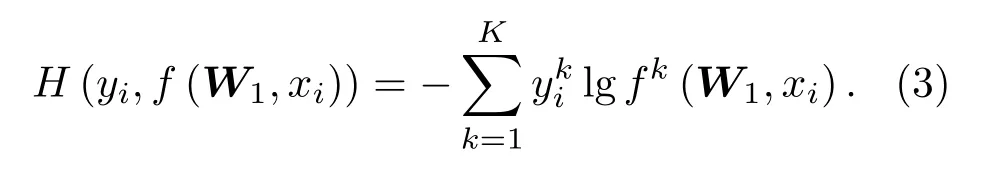
对于TSCNN-CL,因为分别在B 位、C 位引出了协同分支,所以模型的优化目标为

其中,WB、WC分别为分支B、C的输出向量,LAUX为辅助损失函数。LAUX可表示为
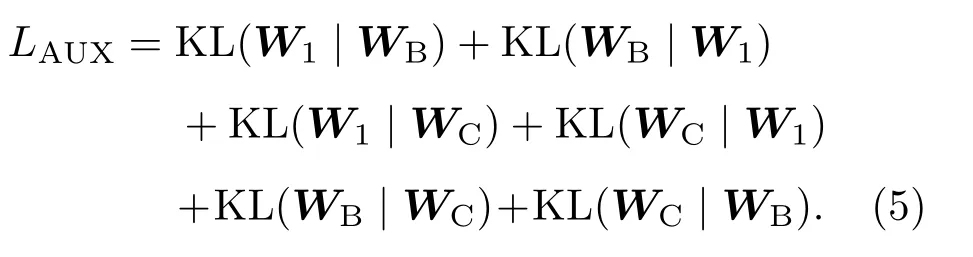
因为KL 散度不具有交换性,TSCNN-CL 的3条支路两两交互,因此设计了6个KL散度来组成辅助损失函数LAUX。
4 实验结果与分析
为验证所提TSCNN-CL 网络模型的有效性,本文在ESC-10、ESC-50 和UrbanSound8k 三个常用基准声音数据集上进行了分类实验验证。
4.1 数据库
(1) ESC-50/ESC-10[13]:ESC-50 数据集是由2000 个环境音频记录的集合,是一个适用于声场景分类的基准数据集。数据集中每个记录由5 s 长的录音组成,分为50 个小语义类(每个类有40 个样本)。其中声频的采样频率为44.1 kHz。所有数据集被分为5 个子集进行交叉验证,本文中将采用交叉验证结果的平均对网络性能进行评估。而ESC-10数据集是ESC-50 数据集的一个子集,包含10 个类别,每类40个例子。ESC-10数据集的所有其他特征都与ESC-50数据集相同。
(2) UrbanSound8k[14]:Urbansound8k 是目前应用最为广泛的公共数据集,主要用于自动城市环境声分类研究。UrbanSound8k 数据集由8732 个声频片段组成,一共分为10 类:“空调”“汽车喇叭”“儿童玩耍”“狗叫”“钻孔”“发动机空转”“枪声”“风钻”“警笛”“街头音乐”。每个类的总声频时长是不均衡的,且每个声频样本的时长可变,最长是4 s,最短是2 s。样本采样频率从16 kHz到48 kHz不等。实验使用官方的10 个交叉验证数据集进行模型性能评价。
4.2 数据预处理
本文首先将所有的原始声频样本重新采至44.1 kHz,并且通过零填充将声频补充到同一长度:ESC-10 和ESC-50 扩充到5 s,UrbanSound8k 扩充到4 s。然后采用STFT 提取声频样本的谱图,设定的窗口大小为40 ms,跳跃大小为20 ms。最后通过梅尔滤波器得到对数梅尔频谱图。
4.3 网络训练
在进行网络训练时,本文选择Adam 算法作为优化器,使用默认参数,初始学习率设置为0.03,指数衰减率为0.99。协同分支在训练时与主干网络一同训练,在推理时将其屏蔽,不增加额外推理代价。该网络由PyTorch 实现,并且在Tesla V100 上进行训练。图4为网络训练过程中的损失函数变化曲线。

图4 TSCNN-CL 与TS-CNN 的训练过程中损失函数变化曲线对比Fig.4 Comparison of loss changes in TSCNN-CL and TS-CNN models during the training process
由图4可以看出,在TSCNN-CL 训练过程中,在迭代10 Epoch 之前训练集和验证集的损失值从0.14 迅速下降,在10 Epoch 和30 Epoch 之间损失函数缓慢下降,40 Epoch 之后的损失值逐渐趋于平稳,且稳定在0.015。由于采用的验证集数据样本和训练集样本不同,两个模型在验证时损失值在20 Epoch 左右存在震荡。此外,在与TSCNN 的比较中可以看出,TSCNN-CL的损失函数曲线变化更加平滑,收敛更加迅速。
4.4 单分支与多分支比较
为验证多分支协同学习的有效性,本文分别在A位、B位和C 位引出同构协同分支进行测试。图5分别展示了对应3 个位点的网络结构。不同位点分支实验结果的分类正确率如表1所示。从表1可以看出,分支位点的位置越靠前,网络的性能越好。这是因为在网络的训练过程中随着迭代次数的增加,CNN 早期层的卷积核参数的变化会趋于平缓。但这并不意味着早期层输出的特征图已经达到了最好的效果,而只是达到了一个局部最优。换言之,整体网络的性能由于早期层的卷积核没有得到充分的训练,而导致最终的分类效果没有得到提升。TSCNN-CL 则通过对早期的卷积层添加协同分支,使其继续进行训练,从而提高了其输出的特征图质量,因此增强了网络的分类性能。

表1 不同分支之间的实验结果比较Table 1 Comparison of experimental results among different branches(单位: %)

图5 不同分支的框架Fig.5 The frameworks of different branches
4.5 实验结果比较与分析
为了验证TSCNN-CL 模型的性能,本文将其与当前主流方法进行了比较。通过交叉验证,实验结果表明所提出的TSCNN-CL 的平均分类准确率在ESC-50、ESC-10 和UrbanSound8k 上分别为84.6%、93.5%和84.5%,在TS-CNN 实验结果的基础上分别提升了1.2%、1.5%和1.0%。其中TS-CNN的结果是按照作者给出的代码在相同实验环境下进行复现得到的。声场景分类的主流方法中,按照对声信号的与处理方式,可以分为两大类,分别是人工设计特征和原始声信号。人工设计特征是指声场分类任务从原始声信号中提取人工设计的特征,比如:时频图、梅尔图、梅尔倒谱系数作为神经网络的输入进行训练。2017年,谷歌将GoogLeNet[15]应用到了声场分类中,其采用梅尔图与梅尔倒谱系数相结合的方式对声信号进行预处理,取得了良好的分类效果。但在实际声场景中,声信号与语声和音乐信号不同,面临着录制条件复杂、噪声较多等问题,人工设计的特征无法对声信号的特征进行自适应的表示。而原始声信号方案可以利用神经网络强大的特征提取能力,从声信号中提取出自适应的特征,同时也省去了复杂的人工设计特征过程。鉴于此优势,一些基于原始声信号的研究相继出现。2017年,Tokozum等[16]提出了一种称为EnvNet的一维体系结构,它使用原始声信号作为输入进行端到端的训练,在当时达到了最好的分类效果。2019年,Abdoli 等[15]提出了Gammatone 1D-CNN,模拟Gammatone 滤波器组进行网络初始化,有效提高了网络的分类性能。尽管原始声信号方案与人工设计特征方案相比存在优势,但是由于一维的声信号比手工设计特征包含更多的噪声信息,并且神经网络需要大量的声音数据用于训练,而声音数据的获取难度要高于图像和文本数据,所以目前的主流方案还是人工设计特征方案。
此外,GoogLeNet 在UrbanSound8k 上的测试并没有按照标准划分10个子集进行交叉验证,而是采用了5个随机划分的交叉验证集。而Gammatone 1D-CNN 虽然在UrbanSound8k 分类效果较好,但主要是对声音特征进行了重叠提取,提取的相邻特征信息之间存在50%的重叠,相当于对数据进行了增强,且测试集里包含了训练集的样本,因而提升了分类效果。TSCNN-CL 与其他主流方法相比,采用了时频注意力模块对声信号的时间和频率特征进行加权学习,不仅能够有效避免噪声的干扰,而且通过引入协同学习,能最大程度地挖掘网络潜力,进一步增强了网络的分类性能。表2显示了TSCNN-CL和其他主流方法的性能比较,结果表明,本文提出的协同学习的方法能够显著提高网络的分类效果。

表2 TSCNN-CL 模 型 在ESC-10、ESC-50 和UrbanSound8k 上与其他声场景分类模型的对比Table 2 Comparisons between TSCNN-CL model and other environmental sound classification models on ESC-10,ESC-50,and UrbanSound8k datasets(单位: %)
5 结论与展望
本文提出了一种基于协同学习的时频卷积神经网络(TSCNN-CL)用于声场景自动分类。TSCNN-CL 通过协同学习的方法,在不增加推理量的前提下,提高了网络的分类性能。首先在TSCNN 的中间层引入两条协同分支,这两条协同分支能够辅助监督中间层训练。其次在主干与分支之间设计了相应的辅助损失函数,使得主干和分支可以进行信息交互,提高了网络的泛化能力,并且为协同分支之间也设计了协同损失函数,实现了分支之间的成对知识匹配。最后,在推理的时候将分支屏蔽,保持推理运算量不变,使模型便于工业部署。在声场识别常用数据集ESC-10、ESC-50 和Urban-Sound8k 上的实验结果表明所提出的TSCNN-CL网络模型的分类效果较TS-CNN 模型有较大提升,且优于当前大部分的主流方法。
