求解多目标混合流水车间调度的改进NSGA-Ⅱ
2022-07-07宋存利
宋存利
(1.大连交通大学 软件学院,辽宁 大连 116052;2.人工智能四川省重点实验室,四川 自贡 643000)
0 引言
制造业的发展在给人们生活带来极大便利的同时也引发了新的问题,如环境污染、全球变暖、能源枯竭等。为实现人类社会的可持续发展,国际社会于2015年签订《巴黎协定》,根据该协定的内在逻辑,在资本市场上,全球投资偏好未来将进一步向绿色能源、低碳经济、环境治理等领域倾斜。同时,绿色制造已经成为“中国制造2025”重大战略方向之一,绿色调度则是企业在现有资源环境下实现绿色制造的重要一环。另一方面,竞争的加剧也要求企业不断提高生产效率,抢占市场先机,因此追求最小化最大完工时间也是制造企业生产的另一重要目标。鉴于此,针对以最小化能耗和最小化最大完工时间为目标的生产调度问题展开研究具有重要意义。
针对面向节能的绿色生产调度问题,学者们提出许多优化算法。针对柔性作业车间调度问题,WU等[1]为了同时最小化最大完工时间、最大能耗和开关机次数,考虑设备开关机能耗、设备不同转速能耗提出解决该问题的基于非支配排序的遗传算法;WANG等[2]提出节约能源的两阶段优化方法,该方法考虑了工件加工工艺和能量消耗的不同;孟磊磊等[3]将工艺规划和车间调度两者有机集成,提出提高车间生产效率、降低能源消耗的混合整数规划模型。针对混合流水车间的节能问题,任彩乐等[4]在考虑加工能耗、待机能耗和开关机能耗等的基础上,提出一种混合整数线性规划模型,并采用候鸟优化算法求解问题。
针对以最小化最大加工时间为目标的车间调度文献较多,其中针对混合流水车间调度问题(Hybrid Flow Shop Scheduling Problem, HFSP),宋存利[5]提出一种贪婪遗传算法;崔琪等[6]提出一种改进的混合变邻域搜索遗传算法;时维国等[7]提出一种改进的灰狼算法;LOW[8]提出模拟退火算法;ESKANDARI等[9]和LI等[10]提出变邻域算法;王圣尧等[11]提出分布估算算法;PAN等[12]提出离散人工蜂群算法;ZANDIEH等[13]针对带有序相关设置时间的HFSP,提出一种免疫遗传算法;JAVADIAN等[14]则在考虑工件加工时间需要滞后和序相关设置时间等因素的基础上,提出解决该问题的免疫算法。
近年来,研究多目标车间调度问题的文献逐渐增多,如文献[15-27],其中以最小化完工时间和最小能耗为目标的车间调度文献有:WU等[21]对柔性作业车间问题进行研究,提出改进的带精英策略的快速非支配排序遗传算法(fast elitist Non-dominated Sorting Genetic Algorithm, NSGA-Ⅱ);YANG等[22]对流水车间调度问题进行研究,提出一种多目标混合粒子群算法;LU等[23]对置换流水车间调度问题进行研究,提出一种多目标回溯算法。而针对加工时间可控的不相关并行机调度问题,DAI等[24]提出一种混合遗传算法和模拟退火算法的多目标优化算法;TANG等[25]则对HFSP,在考虑工件动态达到的情况下,提出一种改进的粒子群优化(Particle Swarm Optimization, PSO)算法(称作NIW-PSO);LI等[26]提出能源感知的多目标优化算法(Energy-Aware Multi-objective Optimization Algorithm, EA-MOA),该算法采用设备优先分配向量和工件加工顺序向量两个向量对问题进行编码,采用所提的多种解码规则来解码染色体,算法在混合多种交叉、变异操作的基础上,同时对每个染色体辅以深度探索和深度开发,最大限度寻找问题的Pareto前沿解,并通过实验证明了算法的有效性。
总之,考虑减少能量消耗的生产调度多目标问题越来越多地被企业重视,而针对带有不相关并行机的HFSP,以研究最小化总完工时间和最小能耗为目标的文献不是很多。因此,本文在考虑设备加工能耗、待机能耗和开关机能耗的基础上,建立了带有不相关并行机HFSP的数学模型,提出了解决该问题的改进NSGA-Ⅱ,并验证了算法的有效性。
1 问题描述与建模
带有不相关并行机的HFSP可描述为:N个工件以相同顺序流经S个加工阶段进行加工,各加工阶段有1到多台不相关并行设备;同一阶段的不同设备均可完成相应工件的加工,只是加工同一工件的时间和能耗不同;同一加工阶段,工件只有一道工序需要加工;已知工件在每台设备上的加工时间、加工单位能耗,以及每台设备的单位待机能耗和开关机能耗,确定工件在每个加工阶段的加工设备、加工顺序,以及设备在空闲时刻是关机还是待机等问题,从而使任务加工完成的总完工时间和能耗最小。为了方便描述问题,定义文中用到的数学符号:
N为加工工件总数;
S为加工阶段总数或工序总数;
i为工件编号,且i=1,2,…,N;
j为加工阶段编号,且j=1,2,…,S;
l为某台设备上加工任务的编号,且0≤l≤N;
mj为每一阶段的设备总数,且mj≥1;
k为某一阶段的加工设备编号,k=1,2,…,mj;
Ti,j,k为工件i在第j个加工阶段第k台设备上的加工时间;
PEi,j,k为工件i在第j个加工阶段第k台设备上的加工单位能耗;
sbj,k为j阶段第k台设备的单位待机能耗;
swj,k为j阶段第k台设备的一次开关机能耗;
Xi,j,k表示工件i在阶段j的加工是否分配给设备k,Xi,j,k=1为是,Xi,j,k=0为否;
Pi,j为工件i在阶段j的加工结束时间;
Bj,k,l为j阶段第k台设备第l个工件的加工开始时间;
Cj,k,l为j阶段第k台设备第l个工件的加工结束时间;
Jnumberj,k为j阶段第k台设备上分配的工件个数;
Jobj,k,l为j阶段第k台设备上分配的第l个任务的工件号,l=1,2,…,Jnumberj,k;
Ftimej,k,l为j阶段第k台设备上第l个工件与其前驱工件之间的空闲时间,l=2,…,Jnumberj,k;
switchj,k,l表示j个阶段设备k第l个工件之前的空闲阶段是否关机重启,switchj,k,l=1为是,switchj,k,l=0为否;
Cmax为所有工件的最大完成时间;
Energy为加工完所有工件的总能耗;
ProcessE为加工完所有工件的加工总能耗;
StandbyE为加工完所有工件的待机能耗;
SwitchE为加工完所有工件的开关机能耗;
π表示一个调度方案。
该问题的约束为:第一个加工工件到达设备时,设备均处于关机可用状态;一个工件在加工过程中不允许其他工件抢占;工件必须严格按照工艺路线加工;同一时刻一个工件最多只能在一台设备上加工;一台设备同一时刻最多只能加工一个工件;工件可在同一阶段的任意一台设备上完成该阶段工序的加工;不同加工阶段间无缓冲限制。根据上述描述与假设,建立问题模型如下:
问题的目标函数:
Cmax=min{Cmax(π*)|π*∈π};
(1)
Energy=min{energy(π*)|π*∈π}。
(2)
对任意一个调度结果π,满足约束:
(3)
Bj,k,l=
(4)
Cj,k,l=Bj,k,l+TJobj,k,l,j,k;
(5)
Pi,j=Cj,k,l=Bj,k,l+Ti,j,k,i=Jobj,k,l;
(6)
Cmax(π)=max{Pi,S|∀i∈π中工件序号};
(7)
Energy=ProcessE+StandbyE+SwitchE;
(8)
(9)
Ftimej,k,l·switchj,k,l;
(10)
(11)
switchj,k,l=
(12)
Ftimej,k,l=Bj,k,l-Cj,k,l-1,
l=2,…,Jnumberj,k;
(13)
Xi,j,k=
(14)
(15)
其中:式(1)为最小化最大完工时间;式(2)为求解最小化能量消耗;式(3)限定了工件i在加工阶段j只能分配在该阶段其中某一台设备上;式(4)计算加工阶段j第k台设备上第l个工件的开始加工时间;式(5)计算加工阶段j第k台设备上第l个工件的加工结束时间;式(6)计算工件i在加工阶段j的完工时间;式(7)为一个调度方案的最大完工时间;式(8)为一个调度方案的总能量消耗;式(9)为所有工件加工完成的总加工能耗;式(10)计算总待机能耗;式(11)计算设备的开关机能耗;式(12)为开关决策变量的决策依据;式(13)计算加工设备在加工任务间隙的空闲时间,式(14)为工件i在加工阶段j的加工设备上的分配情况;式(15)说明j阶段所有加工设备共同分担该阶段的加工任务。
2 改进的NSGA-Ⅱ
2.1 问题编码及种群初始化
求解HFSP的智能优化算法,目前主要的编码有:
(1)首阶段工件加工顺序码 即n个工件的一个排列,工件在队列的位置表明工件第一道工序的加工顺序,后续阶段则按照工件到达时间的非降序排列确定工件的加工顺序,而工件加工设备一般用相应的启发式规则确定,文献[4,5-7,9-13]均采用这种编码方法。实验证明,这种编码方法针对单目标问题,可在有效缩小解空间规模的同时最大限度地找到问题的近优解,提高算法收敛速度,缺点是不能表达整个解空间,解码时需要设计设备分配的启发式规则。启发式规则往往带有一定偏好性,因此只设计单一的启发式规则不适合求解多目标问题,多目标文献一般通过提供多种设备分配的启发式规则来解决该问题。
(2)矩阵编码 该编码方法采用S×N的工件加工顺序矩阵和S×N的设备分配矩阵表达解,可表达全部解空间,解码简单。缺点是解空间庞大,影响算法搜索效率;同时可能存在一些不可行解,需要在解码过程中进行修正。文献[25,27]采用这种编码方法,文献[26]则采用首阶段工件加工顺序码和每阶段设备分配优先级向量相结合的方式,每次分配设备时,在同等条件下优先分配优先级高的加工设备。
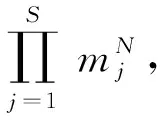
以5个工件3个加工阶段,前两个加工阶段配有2台设备,第3个加工阶段有3台设备的HFSP为例。染色体{3,2,5,4,1|1,2,2,1,1|2,2,1,1,1|3,2,1,1,2}说明5个工件在第1加工阶段的加工顺序为3-2-5-4-1。在第1加工阶段,工件3-4-1按照顺序在设备1上加工,工件2-5按照顺序在设备2上加工。假如第2加工阶段工件的到达顺序为2-3-4-5-1,则工件2-3将在设备2上按顺序加工,工件4-5-1将在设备1上按顺序加工。同理可以确定第3阶段的加工顺序和设备分配情况。
鉴于初始种群的优劣对算法收敛速度和解的质量有一定影响,本文算法初始种群的50%完全随机产生;25%先随机生成工件加工顺序码,再根据2.2节的解码规则(2)生成设备码;剩余25%先随机生成工件加工顺序码,再根据2.2节的解码规则(3)生成设备码。
2.2 解码方案
为了最大限度地确保算法找到Pareto前沿解,从而有效引导算法搜索空间,本文提出3种解码方案,其中工件的加工顺序均采用工件顺序码确定第1阶段工件的加工顺序,其他阶段采用工件先到达先分配方案,将工件尽可能早地安排在相关设备加工。不同点在于加工设备的选择方案不同,具体规则如下:
(1)基于染色体的设备分配方案(AllocateMachine according Chromosome, AMC) 该解码方法完全按照染色体后S×N个向量确定对应工件的加工设备,没有偏向性,可以确保多目标的求解。
(2)最早结束优先分配方案(First end First allocation, FF)[5]该方案不考虑染色体中的设备分配码,首阶段按照工件顺序码确定加工顺序,其他阶段根据先到达先分配原则安排工件加工,加工设备的分配则优先选择能最早完成工件加工的设备,如果两个设备能以相同时间完成加工,则优先选择加工能耗较小的设备,该解码方案优先从完工时间的角度进行解码,对最小化最大完工时间这一目标具有一定导向性。
(3)基于最小加工能耗的分配方案(AllocateMachine based minimal Energy consumption,AME) 与FF类似,该解码方案只是分配加工设备时优先选择加工能耗最小的设备。当同时有两台以上设备以相同的加工能耗完成工件的加工任务时,优先选择最早完工的加工设备,该方案对最小能耗这一目标具有一定导向性。
为不影响后代的操作,在采用AME和FF解码的过程中需同时在染色体中记录设备分配方案,以保证染色体的完整性,这种解码相当于对原有染色体进行了导向性修改。
2.3 解码结果的移动策略
2.2节的解码策略确定了每阶段工件的加工设备、加工顺序及工件的开完工时间,解码时未考虑设备的待机能耗和开关机能耗。对于一个调度方案,设备空闲时间的状态是待机还是关机重启可根据式(12)进行决策。考虑工件加工过程中,除了关键路径上的工件开完工时间没有浮动时间外,非关键路径上的工件加工总有一定的浮动时间,因此从节约能量的角度提出一种移动策略,该策略在不改变加工任务总完工时间的情况下,将工件在其浮动时间内移动来减少设备关机重启次数、延长关机重启间隔或减少待机时长,以达到减少能耗的目的。该策略分两阶段进行:
(1)右移策略 该策略从最后一个阶段依次向前递推到第2阶段,将每台设备上的工件右移。方法是对一具体设备,从该设备上倒数第2个加工工件开始依次尽最大努力右移,具体移动距离则根据式(16)计算。假设当前要移动j阶段设备k上的第l个加工工件,该工件的右移时间距离设为dj,k,l,则
dj,k,l=
(16)
通过右移操作,每台设备的加工任务除最后一个加工任务外,其他任务尽量最晚开工,从而在一定程度缩短设备待机时长或减少关机重启次数或延长某次开关间隔,达到节约能耗的目的。
(2)左移策略 右移将每个工件在设备上的加工尽量推后,左移的目的则是在保证每台设备首工件开工时间和末工件完工时间不变的情况下,尽量利用加工设备上中间非关键工件的浮动时间来进一步减少能耗。具体是从第2加工阶段依次到倒数第2阶段,对加工任务数大于2的设备上的中间工件块有条件左移,达到延长设备关机重启间隔、缩短待机或完全挤掉待机时间的效果。左移策略以块为单位,假设当前要移动j阶段设备k上的某块,该块的最后一个工件为该设备上的第l个工件,该块长度为block。设块的开始加工时间与其前驱工件的完工时间间隔为A1,块可左移的最大时间间隔为A2,块的加工结束时间与其后继工件的开始加工时间间隔为BD,设备开关的最小时间间隔为LT,则有:
(17)
(18)
(19)
LT=swj,k/sbj,k。
(20)
当A2=0时,该块不能左移;当A2>0时,根据以下规则判断是否左移当前块:
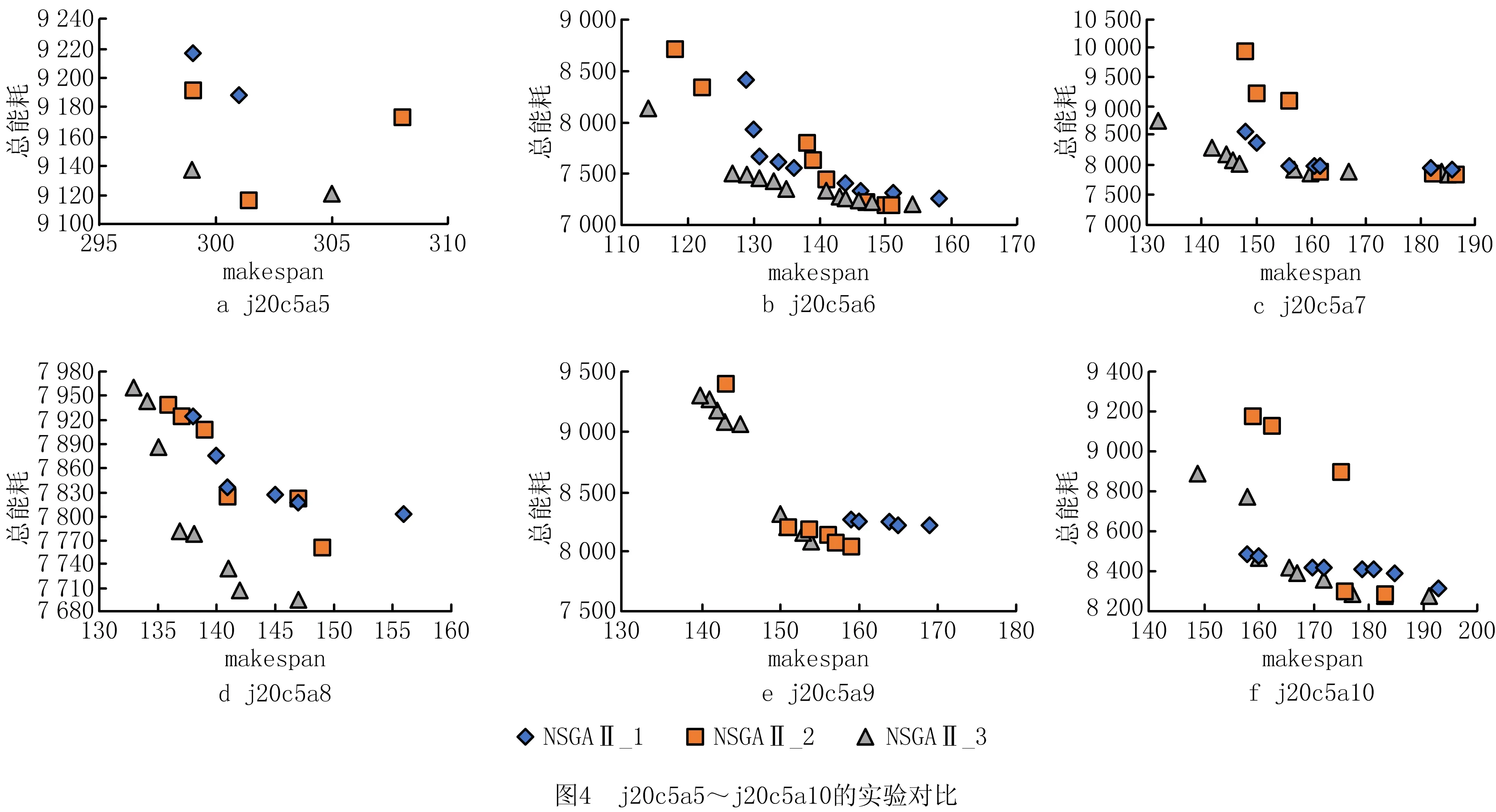
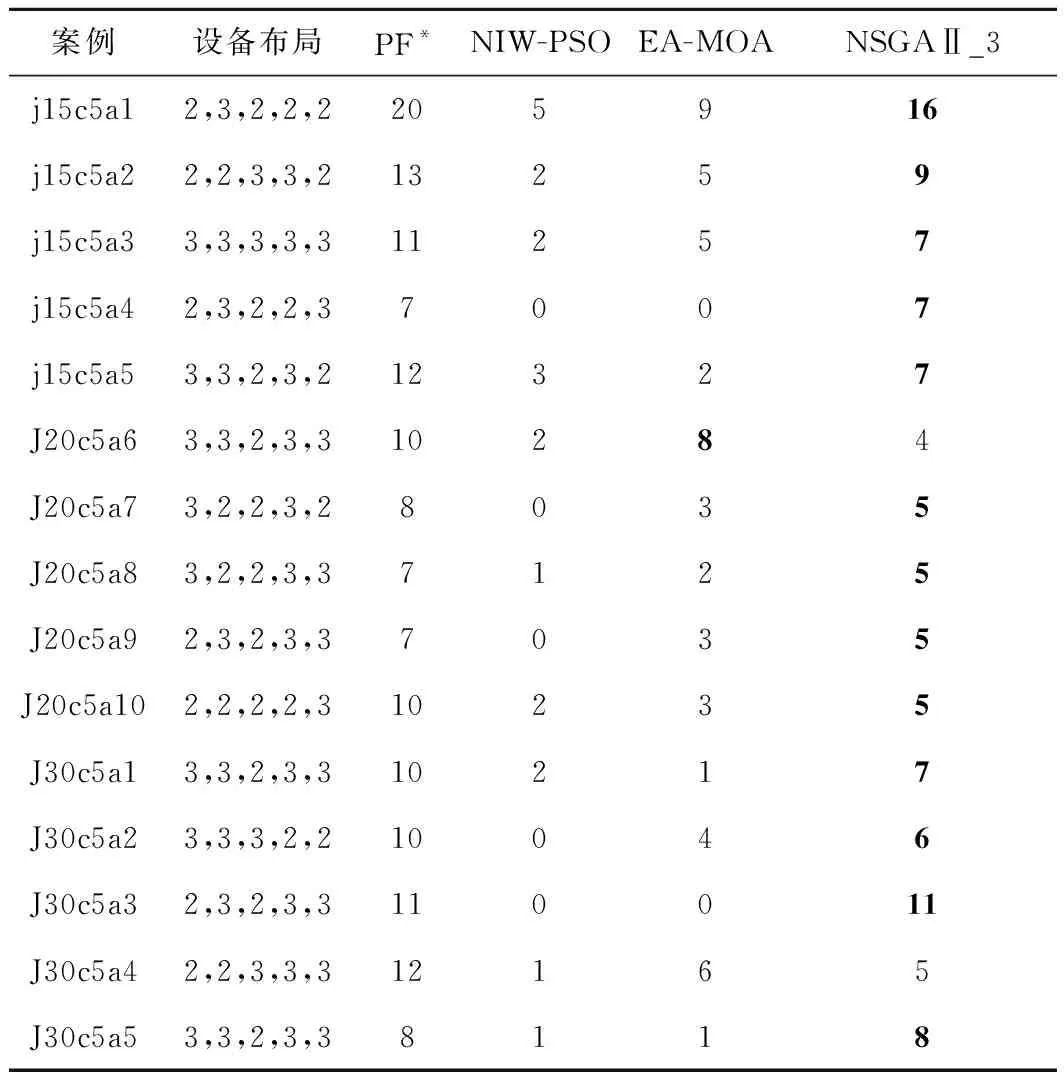
(1)当A1 (2)当A1>LT且BD (3)当A1>LT且BD>LT时,块前和块后的设备空闲时间均为关机重启,将块左移A2个时间单位,达到延长块后关机重启时间,缩短块前空闲时间,甚至挤掉空闲时间的效果来节能。 图1所示为一个左移决策案例,在第2加工阶段,以工件4和工件11组成块为例。该块的块长block=2,变量BD等于工件18的开工时间减去工件11的完工时间,即BD=2;变量A1等于工件4的开工时间减去工件7的完工时间,即A1=18。根据式(18),变量A2则是A1、块内工件4的开始加工时间减去其在第1阶段完工时间的值12,以及块内工件11的开始加工时间减去其在第1阶段完工时间的值1,这3个数值的最小值,因此A2=1。变量LT根据具体案例确定为LT=8,根据规则(2)判断,该块不左移。 因为染色体编码由首阶段工件加工顺序码和全部阶段的设备分配码两部分组成,所以两部分的交叉操作规则不同。具体方法为:随机生成两个1~(S+1)×N之间的随机整数h1和h2,若h1,h2≤N,则交叉操作仅发生在工件顺序码上,这部分交叉操作任选文献[5]的3种交叉算子之一进行,而设备码部分则原样遗传给子代染色体;若h1,h2>N,则交叉操作仅发生在设备码部分,直接交换两个父代设备码中两随机数之间的基因对,子代其余位置基因原样拷贝父代对应位置的基因即可;若h1 void crossOperator(染色体p1,染色体p2) {令h1=int(rand()×(s+1)×n)+1; 令h2=int(rand()×(s+1)×n)+1; 将较小的整数放入h1,较大的整数放入h2; if(h1>N) 执行染色体p1和p2对应设备码的交叉操作规则,产生两个子代染色体Child1和Child2; elseif(h2<=N) 执行染色体p1和p2工件码的交叉操作规则,产生两个子代染色体Child1和Child2; else {将两父代染色体p1和p2工件码从h1到N位置进行交叉操作, 产生子代Child1和Child2的工件加工顺序码; 将两父代染色体p1和p2的设备码从N+1到h2位置进行交叉操作, 产生两子代Child1和Child2的设备分配码; } 输出两子代染色体; } 本文中贪婪变异的目的是增加解的多样性和增强算法的邻域搜索能力。具体的染色体变异操作也有两种策略,对工件顺序码的变异方法任选文献[5]的3种变异算子之一进行。针对设备分配码的变异操作,设计了两种不同的变异方法。一种是对每一个设备基因码采用变异概率30%进行变异操作;另一种是随机生成两个随机数,将这两个随机数之间的设备码进行变异,具体是随机选择该阶段一台不同的加工设备号替换原有加工设备。 贪恋变异操作的思想是对选择发生变异的染色体,最多循环50次令其发生变异,若某次变异中生成的染色体适应值对其原有染色体的适应值形成了支配关系,则用变异后的染色体替换原有染色体,结束循环。若变异后染色体和原染色体互不支配,则将变异后的染色体与种群中其他染色体对比,观察有无染色体对其形成支配关系,有则直接放弃,继续变异操作;否则将其放入孩子染色体集合中,等待选择操作,结束变异。伪代码如下: void greedymutate(染色体p) { int i=0; 定义染色体变量pnew; while(i<=50) { p发生变异操作产生新染色体pnew; 解码新染色体pnew; if(pnew支配p) { p=pnew; break; } elseif(pnew和p互不支配) {if(pnew支配种群中某个染色体吗?) {替代被它支配的染色体; break;} elseif(种群中染色体支配pnew吗?) {放弃pnew;} else{放入孩子群体中,等待选择;break;} } i=i+1; } } 为了保证不丢失优良个体,同时避免早熟收敛,保持种群的多样性,本文提出一种改进的精英保留选择算子,步骤如下: 步骤1初始化下代种群NextPop为空集,将父代种群fatherPop和遗传操作产生的子代种群childPop合并为一个集合R0。 步骤2计算集合R0中每个染色体的非支配排序等级,非支配等级为0的染色体进入集合R1,非支配等级为1的染色体进入R2集合,以此类推,直到R0中的每个染色体都进入一个相应等级的集合中。 步骤3对步骤2得到的集合Ri(i≥1)按顺序执行如下操作,直至得到下一代指定规模的种群: (1)计算当前集合中每个染色体的拥挤度距离,按照该距离由大到小对染色体进行排序。 (2)对于拥挤度为0的染色体,说明在该集合中至少有3个适应值与其相同的染色体,以90%的概率从集合中删除这样的染色体,该过程称为除冗余。 (3)计算该集合中剩余染色体的个数,若将其全部并入集合NextPop时不超出种群规模,则将该集合中的所有染色体直接并入NextPop,对下一个等级的染色体集合重复步骤3;若将某个非支配排序等级的集合并入NextPop时超出种群规模,则根据该集合中每个染色体的拥挤度距离,采用轮盘赌策略选择进入集合NextPop的染色体,直到NextPop达到种群规模,结束步骤3。 步骤4如果执行步骤3时集合NextPop中的染色体没有达到种群规模,则随机生成新的染色体进入NextPop集合,直至达到相应的种群规模。 具体伪代码如下: void choiceNext() { 令NextPop=∅;Pnumber=0; 令R=fatherPop+childPop; 非支配排序R,将其划分进不同支配等级的集合S[0],S[1],…中,令Pnumber为集合个数; 令rank=0; While(rank<=Pnumber) {计算集合S[rank]中染色体的拥挤度; 根据拥挤度由大到小排序S[rank]中的染色体; 令number为S[rank]集合中染色体的个数; while(S[rank][number]的拥挤度为0?)//循环删除冗余染色体 { if(rand()<0.9) {删除染色体S[rank][number];} number=number-1; //下一染色体位置 } N1= S[rank]//为剩余染色体个数 If(Pnumber+N1<=Psize)//染色体进入下一代种群 { NextPop= NextPop+ S[rank];//两个集合并运算 Pnumber=Pnumber+N1; rank=rank+1; } else {以轮盘赌选择策略选择放入S[rank]中的Psize-Pnumber个染色体进入NextPop ; break;} } While(Pnumber { Prand=init();//随机算法产生一个染色体; Prand放入NextPop; } } 本文算法采用VC++6.0编写,计算机配置为:操作系统采用WIN 10,内存为16 GB,主频为1.99 GHz。本文案例均采用j*c*a*命名,其中*表示一个整型数字,例如案例j15c5a1表示15个加工工件在加工阶段为5的车间加工,a1为该类案例的第一个案例。所有加工数据随机产生,其中工件的加工时间在[10~30]之间,每阶段加工设备在[1~3]之间,设备加工单位能耗数据在[5~10]之间,设备单位待机能耗在[1~5]之间,单次开关机能耗在[20~30]之间。案例规模有15工件、20工件和30工件,其中案例j20c5a1~j20c5a5既有加工阶段只有1台加工设备的情况,又有加工阶段有2~3台设备的情况。其他案例每阶段设备数至少在2台以上。 本文改进算法命名为NSGAⅡ_3,为了验证其有效性,设计了3种比较算法:①基本NSGAⅡ_1算法(传统NSGAⅡ),该算法采用AMC的解码方案,选择操作采用传统的精英保留策略;②NSGAⅡ_2,该算法解码采用3种解码方案的混合解码方法,并采用贪婪变异操作,其他设计同NSGAⅡ_1;③NSGAⅡ_3,该算法在NSGAⅡ_2基础上,选择操作采用2.6节提出的改进的选择算子。 为了验证本文所提移动策略的有效性,以案例j20c5a2为例,该案例的设备配置特点为1-2-3-1-2。图2所示为该案例的3种调度结果,其中横坐标为完工时间,纵坐标为加工设备。其某个调度结果甘特图如图2a所示。为了使不同加工阶段调度结果看起来更加明显,相邻阶段采用不同灰度间隔。图2a为解码结果,其完工时间为293,能量消耗为9 542。图2b为对图2a的调度结果执行右移之后的结果,如两图虚线框框出部分所示。从图2b可见,后两个阶段加工设备上的中间空闲时间被完全挤压掉,第3和第2加工阶段的部分设备待机时间减少或完全被挤压掉,部分设备的开关时间被挤压掉或缩短为待机状态。图2b调度能耗减少为9 294,相比图2a共降低了248个能耗,而完工时间不变。图2c是针对图2b的调度结果左移之后的结果,如图2b图和图2c深色虚线框出部分所示。显然,图2c调度的总完工时间不变,但加工能耗为9 278,相比图2b节约16个能耗。通过本文先右移再左移的移动策略,案例j20c5a2的调度结果共降低264个能耗,证明了本文调度调整方案的有效性,因此所提算法均采用该策略对调度方案进行调整。 表1统计了本文20个案例的Pareto前沿解在右移后能量消耗相对原始调度的平均能耗节约率(用RR表示),以及左移后相对右移结果能耗的平均节约率(用LR表示)。由表1可见,相对原始调度,右移策略能够100%节约能耗。本文20个案例右移后再左移,其中有7个案例在左移后能耗不变化,剩余13个案例在左移后能节约一定能耗,进一步证明了移动策略的有效性。 表1 移动策略实现的能源节约率 在NSGAⅡ_2中,采用3种解码方案的混合策略,为了验证不同解码方案对算法的影响,以及解码策略在该算法中的设置比例,给出3种解码策略的6种不同设置比例,具体如表2所示。其中编号1,2,3为3种解码算法的混合,编号4,5,6只采用其中一种解码算法,编号4采用AMC解码,编号5采用FF解码,编号6采用AME解码。从案例j15c5a1~j15c5a5,j20c5a1~j20c5a5,j20c5a6~j20c5a10的每组案例中随机选其中两组,经过正交实验确定算法种群规模、迭代次数、交叉概率和变异概率分别为40,2 000,0.75,1。每个算例运行1次,利用相关案例的Pareto前沿解分布图展示结果,具体如图3所示,其中横坐标makespan表示最大完工时间。 表2 各种解码算法的分配比例 观察图3中6个案例的Pareto前沿解分布图,编号4对应的AMC解码实验结果,其前5个案例Pareto前沿解的分布性较好,但收敛性差,只有图3f的收敛性稍好一些;编号5采用FF解码,其导向性是最小化最大完工时间,6个案例中,图3a、图3b、图3e和图3f的实验结果较靠近Pareto前沿解,但主要集中在完工时间较小、能耗较大的区间,证明单独采用FF解码不太合适求解多目标,解的分布性较差;编号6采用AME解码,该解码以最小能耗为准则选择设备分配,6个案例中,图3a、图3b、图3e和图3f的Pareto前沿解集中在能量消耗较少但完工时间较大的区间,同样说明单独的导向性明显的AME解码算法同样不适合多目标问题。编号1,2,3均采用3种解码算法混合策略,只是比例不同。编号1解码策略中具有导向性的解码规则FF和AME占比较高,均达到25%,从Pareto前沿解的分布看,解的分布大多集中在两端,分布不均。具体原因是由于受导向性解码规则FF和AME指引过于强烈,从而使算法结果集中在两头,中间没有或很少,具体如图3a、图3b、图3e和图3f所示;从采用编号2的解码策略的实验结果看,6个案例的Pareto前沿解的收敛性和分布性均比编号1的实验结果好;从采用编号3的解码策略的实验结果看,图3的6个实验案例中,除了图3e的分布性相对差一些外,其他5案例的实验结果无论解的分布性还是收敛性,均好于采用解码策略1~6的实验结果。因此,本文的混合解码比例将采用编号3的设置。 为了验证本文混合解码策略的有效性,将NSGAⅡ_1和NSGAⅡ_2进行实验对比;为了验证改进的选择策略的有效性,将NSGAⅡ_3和NSGAⅡ_2进行验证对比;最后对比NSGAⅡ_3和NSGAⅡ_1的实验结果,以证明本文算法的有效性。3种算法种群规模、交叉变异概率的设置同3.2节,NSGAⅡ_2和NSGAⅡ_3的解码算法比例设置采用3.2节的实验结论(0.9,0.05,0.05),采用中等规模的j20c5a5~j20c5a10案例进行实验。图4所示为6个案例相应算法的Pareto前沿解的分布。表3所示为图4中3种算法针对每个案例的Pareto前沿解中两个端点的结果,即一组是最小完工时间和能耗,一组是最小能耗和完工时间。其中:cmin为实验的最小完工时间,e为对应的能耗,emin为实验结果的最小能耗,c为其对应的完工时间,加粗的数据为前沿解在不同方面的最好解。 首先,对比NSGAⅡ_1与NSGAⅡ_2的实验结果,验证混合解码策略对多目标问题的有效性。从图4中6个案例的Pareto前沿解的分布看,在案例j20c5a7上,NSGAⅡ_1的Pareto前沿解的分布性和收敛性优于NSGAⅡ_2;对于案例j20c5a5,j20c5a8,j20c5a9,NSGAⅡ_2的Pareto前沿解的分布性和收敛性优于NSGAⅡ_1;在案例j20c5a6和j20c5a10上,两种算法的前沿解形成了交叉。该实验说明,采用混合解码算法的NSGAⅡ_2与单独采用AMC解码的NSGAⅡ_1相比,具有一定优势,表3的统计结果也支持了该结论。 表3 6个案例的实验结果 其次,比较NSGAⅡ_3和NSGAⅡ_2,验证2.6节所提改进选择算子的有效性。在图4中,NSGAⅡ_3在6个案例上实验所得的Pareto前沿解,无论收敛性还是多样性均优于NSGAⅡ_2,说明了本文所提改进选择算子的有效性,其在一定程度上能够保证种群的多样性,避免算法早熟。从表3可见,在6个案例的12组解中,NSGAⅡ_3取得其中10个较好解,占83.3%,而NSGAⅡ_2仅在案例J20c5a10和J20c5a7上关于(c,emin)取得解的质量好于NSGAⅡ_3,仅占到16.7%。进一步说明了本文改进选择算子的有效性。 对比NSGAⅡ_3与NAGAⅡ_1,NSGAⅡ_3在6个案例上实验的Parteto前沿解的分布性和收敛性均优于NAGAⅡ_1,说明在将3种解码策略有机混合的同时结合保证种群多样性的选择算子对NSGAⅡ_3产生了积极的影响。一方面,带有引导性的解码算法FF和AME能够有效引导算法搜索解空间;另一方面,改进的选择算子又可以根据拥挤度以较大概率淘汰某一区间过度密集的解,从而有效提高种群多样性,避免算法陷入局部最优。这为以后设计多目标算法提出了新的思路。 将本文改进的NSGAⅡ_3与一种改进的粒子群优化算法NIW-PSO[25]和EA-MOA[26]在3组案例j15c5a1~j15c5a5,j20c5a1~j20c5a10,j30c5a1~j30c5a5上进行实验对比,公平起见,将限制算法迭代次数改为每种算法的运行时间均不超过5 min,并将本文所提移动策略应用于每个算法,NIW-PSO和EA-MOA的其他参数均遵循原有算法设置。将3种算法针对每个案例所求的Pareto前沿解合并进行非支配排序,求出被支配等级为0的非支配解,记作理想Pareto前沿解PF*,分别统计3种算法的Pareto前沿解出现在PF*中的个数,具体统计结果如表4所示。 表4 3种算法的实验结果统计 从表4可见,15个案例中,本文算法在14个案例上求解的Pareto前沿解出现在PF*中的个数均大于其他两种算法,其中在算例j15c5a4,J30c5a3,J30c5a5三个案例上,本文算法NSGAⅡ_3求出的前沿解和PF*完全相同。算法EA-MOA在案例J20c5a6上的求解结果较好,算法NIW-PSO的表现最差,说明了本文算法的有效性。 本文以最小化最大完工时间和最小能耗为目标对HFSP进行研究,提出该问题的混合整数规划模型,在此基础上提出解决该问题的一种改进的NSGAⅡ。首先,该算法染色体编码能够保证算法在问题的整个解空间中搜索Pareto前沿解集,有效避免了针对HFSP的常用染色体编码存在的弊端。混合解码策略将带有明显偏向性的解码算法应用于多目标问题,从而有效引导算法种群进化,实验证明了该策略的有效性,为多目标问题的求解提供了一条新的设计思路。为了避免带有导向性的解码策略使算法陷入局部最优,出现早熟问题,提出一种改进的选择算子,该算子在采用精英保留策略的基础上,大概率淘汰拥挤度为0的染色体,从而保证Pareto前沿解的收敛性和分布性,最后通过实验验证了本文所提算法的有效性。 未来的研究方向为:①对多约束车间调度问题进一步展开研究,以提升研究成果的应用价值;②进一步研究多目标车间调度的解决方法。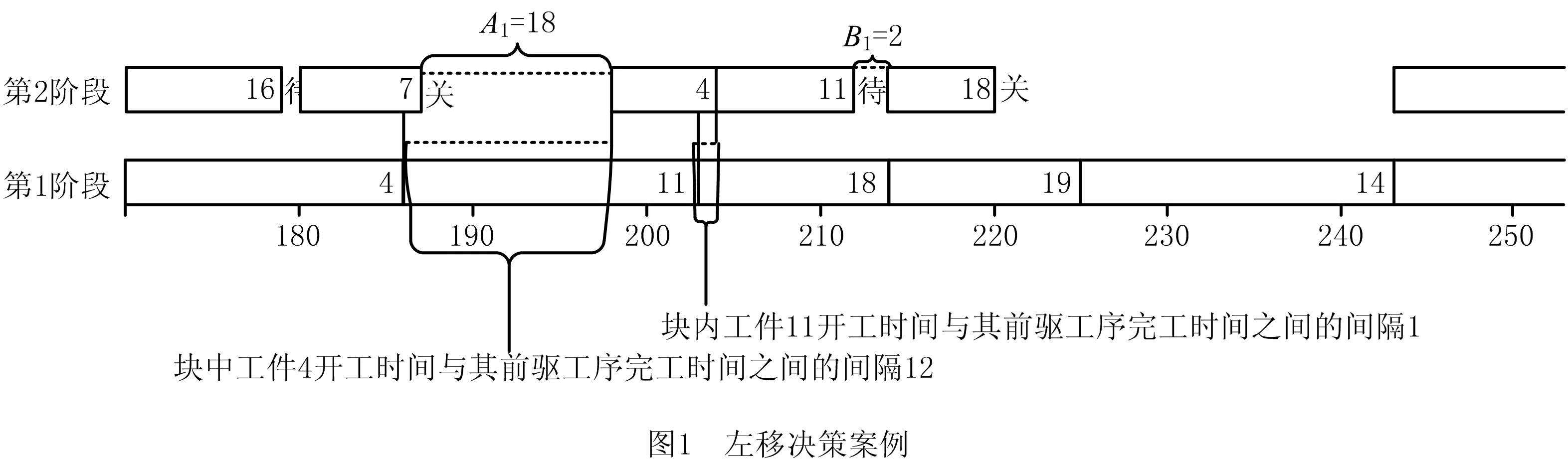
2.4 交叉算子
2.5 贪婪变异算子
2.6 改进选择算子
3 实验分析
3.1 移动策略的有效性验证


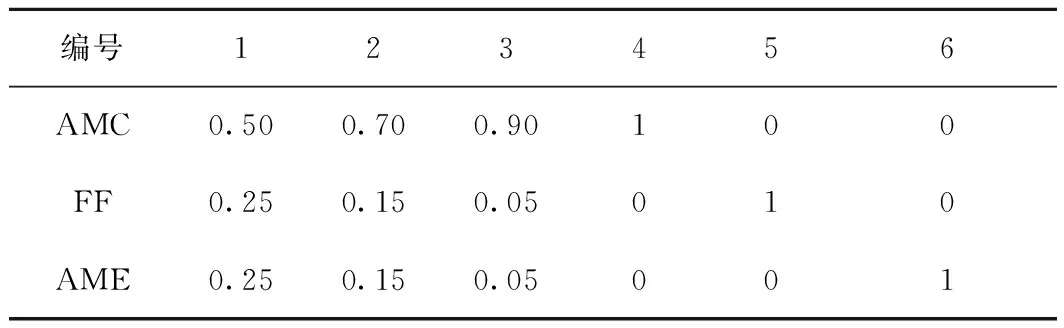
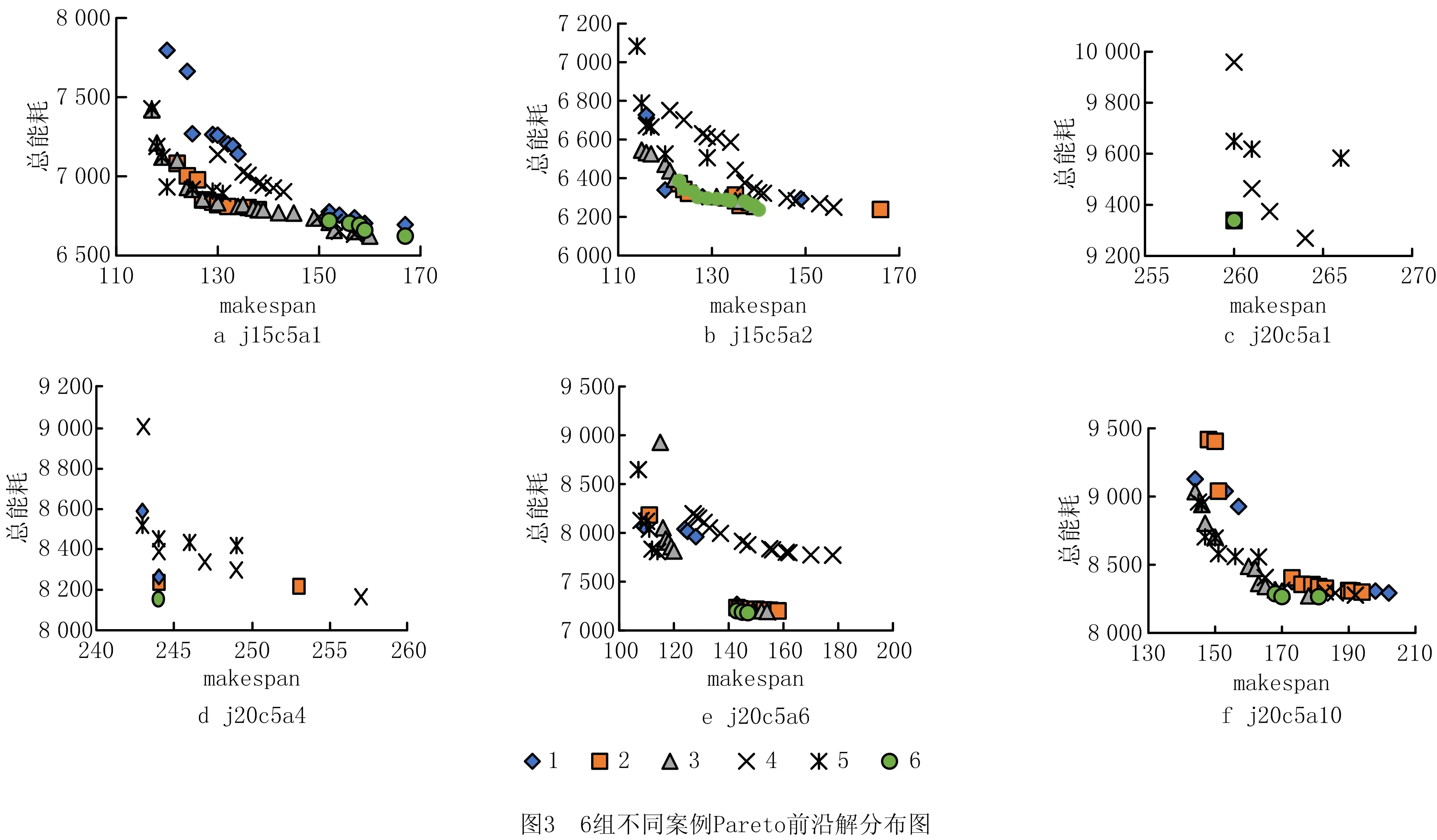
3.2 3种解码算法混合比例校验
3.3 混合解码算法及选择算子有效性验证

3.4 与已有算法的实验对比
4 结束语
