基于深度学习的命名实体识别研究
2022-07-07冀振燕孔德焱桑艳娟
冀振燕,孔德焱,刘 伟,董 为,桑艳娟
(1.北京交通大学 软件学院,北京 100044; 2.中国科学院 软件研究所,北京 100190; 3.中科蓝智(武汉)科技有限公司,湖北 武汉 430079)
0 引言
随着先进制造业领域的高速发展,制造业复杂产品的全流程数据呈指数级增长,如何在海量的制造全流程数据中挖掘出有价值的信息成为制造业领域的一个热点研究问题,而命名实体识别(Named Entity Recognition, NER)[1]技术是先进制造业领域文本挖掘的关键环节。先进制造业领域中可以很容易获取语料,然而由于从业人员在技术背景、专业知识、工作经验等方面各不相同,对同一实体对象的描述以及同一业务活动的理解、描述不尽相同。目前在工程建设方面已经积累了大量的宝贵经验、知识素材和知识原料,而且这些知识原料还在不断更新和迭代,特别是随着一些领域的迅速发展,会出现海量非标准化表达的新词和热词,使得知识的应用效果大打折扣,无法有效支撑专业人员进行有效的知识搜索与应用。因此,如何有效地发现新实体,如何在有限的带标签数据的情况下实现高准确率、高覆盖率的NER,如何有效解决知识原料产生者与使用者之间对同一实体理解与描述的偏差,在先进制造业领域仍然是亟待解决的问题。
NER是信息抽取、知识图谱构建等领域的核心环节,旨在从复杂的结构化、非结构化和半结构化数据中抽取特定类型的实体,如人名、地名、组织机构名等,并对这些具有特定意义的实体进行归类。命名实体[1]这一术语首次在第六届信息理解会议(Message Understanding Conference 6, MUC-6)上被提出,用于识别文本中的组织名称、人员名称和地理位置,以及货币、时间和百分比表达式。自MUC-6以来,人们对NER的兴趣日益浓厚,各种国际评测会议(如CoNLL03,ACET,REC Entity Track)都对该主题进行了大量研究。
在NER中应用的技术主要有基于规则的方法、基于统计学习的方法和基于深度学习的方法3类。基于规则的NER方法需要领域专家根据语义和语法规则等构造出实体识别规则模板,规则可以基于特定领域的词典[2-10]和语法—词汇模式设计[11],但是由领域专家定义,因此面对复杂且不规则的文本,不同构造规则之间会产生冲突,领域之间很难进行复用。基于统计学习的方法是在大数据的基础上将统计学习方法应用到机器学习中,并通过人工精心挑选和设计的特征来表示每个训练示例,从而识别出隐藏在数据中的相似模式。特征提取在有监督的NER系统中至关重要,良好的人工特征可以有效提高NER效果。基于特征的机器学习算法已广泛用于NER,包括隐马尔科夫模型(Hidden Markov Model, HMM)[12]、最大熵(Maximum Entropy, ME)模型[13]、支持向量机(Support Vector Machine, SVM)[14-15]、决策树(Decision Tree, DT)[16]和条件随机场(Conditional Random Fields, CRF)[17-24]。
基于深度学习的NER方法[25]是以端到端的方式从原始输入中自动发现隐藏特征,不依赖人工构造的特征。现有基于深度学习的NER方法的相关综述主要分析总结了基于卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Network, RNN)及其变体的NER方法,未体现基于其他深度神经网络的NER方法,本文通过分析最新的高引用文献,对基于CNN、RNN、预训练语言模型、Transformer、图神经网络(Graph Neural Networks, GNN)以及其他联合抽取框架的NER方法进行了全面总结分析,并从分布式输入表示、上下文编码和标签解码器3个步骤进行阐述。
1 基于深度神经网络的命名实体识别方法
深度神经网络[25]可以通过非线性变换从数据中自动发现隐藏特征,其因不依赖人工构造的特征而节省了成本。目前,基于深度学习的方法已成为NER领域的主流,主要分为分布式输入表示、上下文编码和标签解码器3个步骤[26]。分布式输入表示旨在自动学习文本,获得单词的语义和句法特征,为上下文编码器提供低维实值密集向量输入;文本上下文编码采用CNN,RNN,Transformer,GNN等提取上下文依赖关系;标签解码器是对上下文编码输出的向量进一步解码,从而获取最佳标签序列,常见的标签解码器有CRF、RNN、指针网络等。基于深度神经网络的NER基本框架如图1所示。
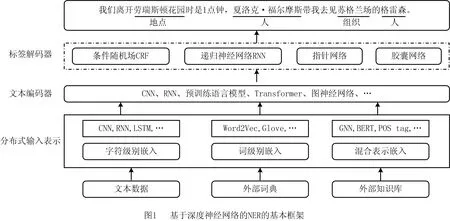
1.1 分布式输入表示
分布式输入表示代表低维实值密集向量中的单词,其中每个维度表示一个潜在特征。分布式输入表示从文本中自动学习,捕获单词的语义和句法属性。主流的分布式输入表示分为词级别向量表示、字符级别向量表示以及融合两种方式和词典信息的混合向量表示。
1.1.1 词级别表示
有监督的NER模型训练需要大量人工标记数据,数据标注成本较高,可通过无监督算法预训练大量未标记数据,学习到单词表示来提高小型领域数据集上的有监督NER模型的训练效率。常见的词向量表示模型有Skip-gram模型[27]、连续词袋模型(Continuous Bag of Words, CBOW)[27]、Word2Vec[28]、Glove[29]、fastText[30]。
这些预训练词向量嵌入方法十分有效。LAMPLE等[31]提出的NER的神经体系结构采用skip-n-gram[32]预训练的词向量初始化查找表,与随机初始化词嵌入相比效果提升显著;MALIK[33]采用CBOW模型训练乌尔都语单词向量用于乌尔都语NER和分类,显著提升了识别和分类效果;KANWAL等[34]分别采用Word2Vec,Glove,fastText 3种方式生成乌尔都语词向量,实验表明Word2Vec的表现优于fastText和Glove;CETOLI等[35]提出的基于图卷积网络的NER方法,将Glove词向量、词性标签POS(part-of-speech tagging)、文本形态信息嵌入特征向量,避免出现仅用词嵌入无法有效处理词汇表外单词的情况;RONRAN等[36]研究了Glove,fastText词向量嵌入对提高NER性能的影响,实验表明,在CoNLL2003数据集上采用Glove词向量嵌入方式对实体识别性能的提升效果更佳。另外,fastText[37],Word2Vec[38]也广泛用于领域NER任务。
1.1.2 字符级别表示
对比词级别的向量表示,字符级别的向量表示可推断词表外的单词表示,有效解决词汇量限制问题,并可提供单词形态信息,如前缀、后缀、时态等,还可提高模型训练速度。缺点在于缺少词级别语义信息和边界信息,如字符“吉”和词“吉他”,显然词“吉他”可为模型提供更好的先验知识,另外变长的输入序列会降低计算速度。
目前,字符级别表示提取的模型主要有基于CNN的模型(如图2)和基于RNN的模型(如图3)两类。KIM等[39]提出字符级CNN模型,利用子词信息消除对形态标记或人工特征的需要,并可生成新单词;MA等[40]提出的双向LSTM-CNNs-CRF模型和RONRAN等[36]提出的基于单词和字符特征的两层双向LSTM-CRF模型,采用CNN卷积层对分类后的字符特征编码,然后采用最大池化层获得单词特征表示。研究表明,CNN可从单词字符中有效提取形态信息(如单词前缀或后缀),并将其编码成向量表示。
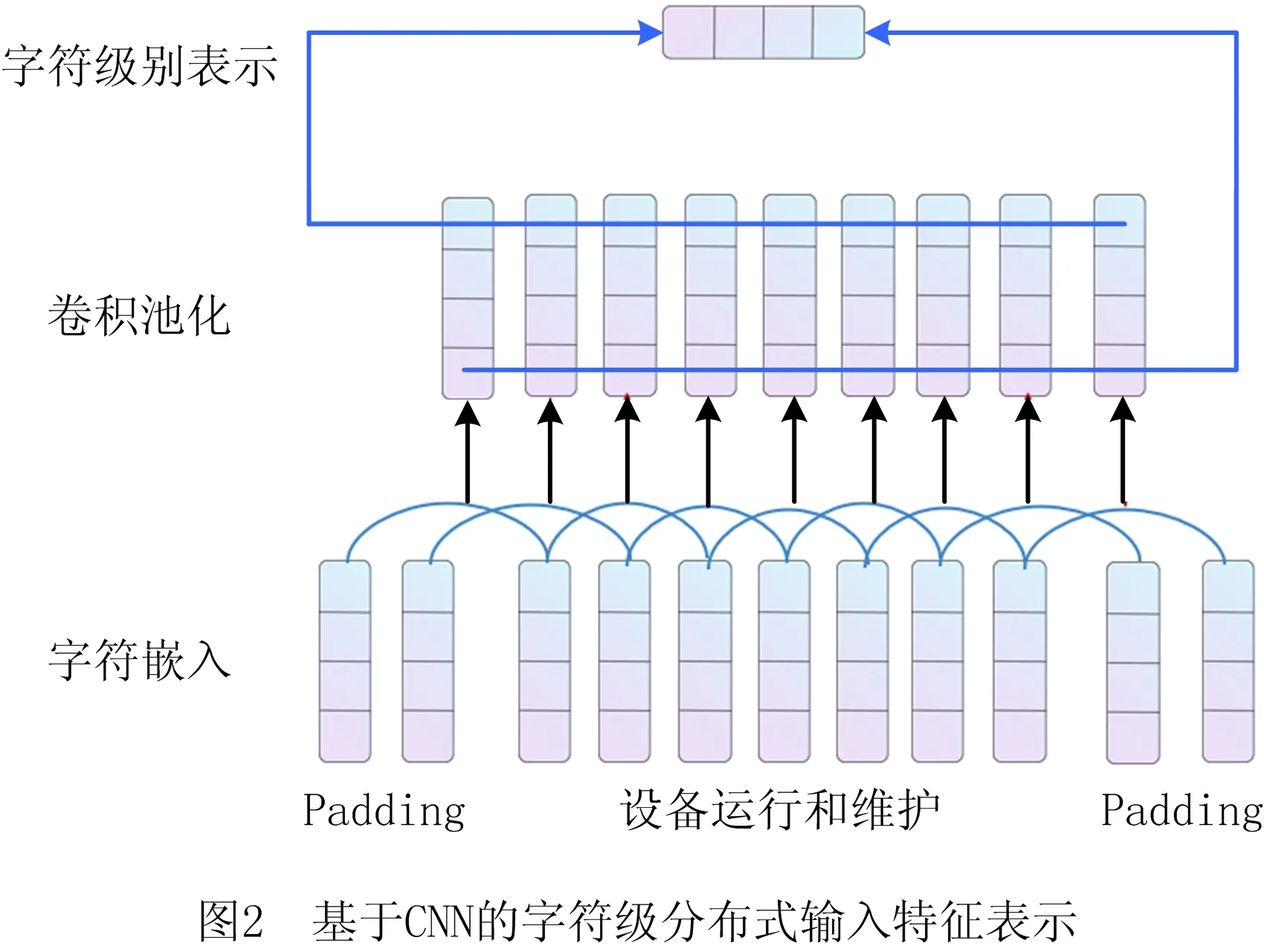
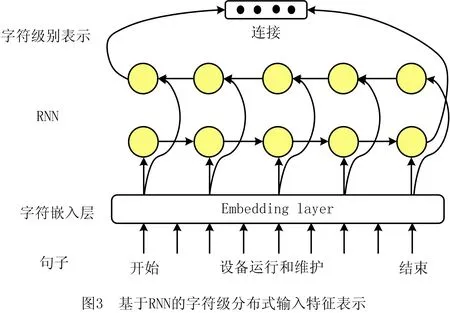
为了更好地捕获上下文信息,LAMPLE等[31]和SUI等[41]通过双向长短期记忆(Long Short-Term Memory, LSTM)网络连接从左到右和从右到左的LSTM隐式状态,获得上下文表示;REI等[42]采用门控机制将字符级表示与词嵌入结合,动态确定使用嵌入向量中的信息量;TRAN等[43]提出具有堆叠残差LSTM和可训练偏置解码的NER模型,通过词级和字符级RNN提取词特征。
1.1.3 混合表示
字符级NER方法的准确率不但高于单词级NER方法,而且还有很大提升空间。因此,很多学者对字符特征向量表示进行改进,添加单词信息特征、字典信息特征、部首特征、词汇相似性等附加特征,以增强文本中命名实体间的相关性,提高模型效率(如图4)。
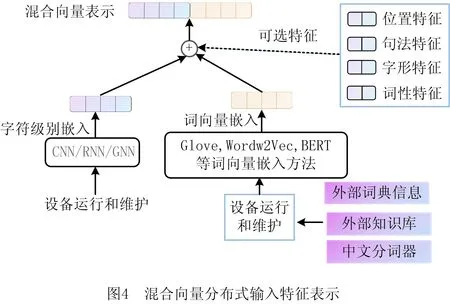
ZHANG等[44]提出Lattice LSTM方法,首次将词典和词向量信息引入字符级LSTM模型,有效提升了识别性能,但是存在信息损失、可迁移性差和不能并行化的问题;GUI等[45]提出LR-CNN模型,采用CNN替代RNN解决不能并行计算的问题,同时采用rethinking机制增加feedback layer调整词汇信息权值,并引入注意力机制以更好融入词汇信息,提高了模型效率;MA等[46]提出一种将词汇信息融入字符向量表示的简洁有效方法,与其他引入词汇信息方法相比性能更好、推理速度更快,且便于迁移到其他序列标注框架。
LIU等[47]提出一种单词字符LSTM模型,将单词信息附加到其相关字符上,获取单词边界信息并减轻分词错误的影响。由于一个字符可能对应多个词,设计4种编码策略将不同的词嵌入映射到一个固定长度向量中用于批量训练。为了获取更多词汇语义和边界特征,HU等[48]提出一个基于二阶词典知识(Second-order Lexicon Knowledge,SLK)的模型,基于全局语境挖掘更多的可识别词汇信息,通过注意力机制融合词汇知识缓解词边界冲突问题。TANG等[49]提出一种单词—字符图卷积网络来充分利用隐藏在中文NER外部词典中的单词信息,将双向单词—字符有向无环图作为模型输入,提高了训练速度。SETI等[50]提出一种基于图卷积网络的体育领域NER方法,其中两层图卷积网络用于提取文本中命名实体的字符特征和内部结构信息,输入特征表示层将字符信息与单词向量信息结合,有效挖掘了体育文本的深层抽象特征和全局语义信息。
汉字是象形文字,不同字符中的相同语言成分通常具有相同的含义。MENG等[51]提出基于汉字表示的字形向量Glyce,将汉字视为图像,采用CNN提取字符语义,并将字形嵌入向量表示与BERT(bidirectional encoder representation from transformers)嵌入向量表示融合在一起,作为中文NER的输入表示。融合后的输入表示赋予了模型字形信息和大规模预训练信息。类似地,LEE等[52]集成了从部首、字符到单词级别不同粒度的多个嵌入,以扩展字符表示;AKBIK等[53]提出一种上下文字符串嵌入方法,利用预训练的字符级语言模型提取每个单词的开头和结尾字符位置的隐藏状态,以在句子上下文中嵌入任何字符串。然而,由于没有上下文的少见字符串难以有意义地嵌入,AKBIK等[54]进一步提出可以动态聚合每个唯一字符串的上下文嵌入方法,即Pooled Contextualized Embeddings,有效解决了该问题。
1.2 上下文编码
目前,NER上下文编码器有CNN、RNN、预训练语言模型、Transformer和图神经网络。
1.2.1 卷积神经网络
基于CNN的NER模型可自动提取单词上下文的局部特征,并行计算效率高,然而存在难以处理长距离依赖问题,以及优先考虑文本局部特征导致大量信息丢失的问题。因此,很多学者对CNN结构进行改进,以捕获更多的上下文信息。ZHAO等[55]将NER转换为简单的词级别多分类任务,提出一种基于多标签卷积神经网络(Multiple label Convolutional Neural Network, MCNN)的疾病NER方法;STRUBELL等[56]提出基于迭代空洞卷积的、快速准确的实体识别方法,以损失部分信息为代价扩大卷积核的感受野,使模型捕获更多上下文信息,同时提高了计算效率。
针对CNN难以捕获序列中长距离上下文信息的问题,CHEN等[57]提出一个基于CNN的门控关系网络(Gated Relation Network, GRN),与CNN相比具有更强大的捕获全局上下文信息的能力,而且可在整个句子中执行并行计算;YAN等[58]应用门控机制构建了一个基于Resnet和扩张残差网络(Dilated Residual Networks, DRN)的混合堆叠深度神经块,以更宽的视野捕捉更多局部特征。
1.2.2 循环神经网络
基于RNN的模型在序列数据建模方面表现出色,特别是双向RNN可有效利用特定时间范围内的信息。因为采用线性序列结构编码导致无法进行并行计算,大量非实体词信息参与实体识别过程也阻碍了重要实体特征信息的获取,所以很多学者通过改进RNN变体[59](LSTM/GRU(gated recurrent unit))的结构或添加注意力机制[60]来缓解上述问题。PEI等[61]在双向LSTM-CRF框架中添加注意力机制,以增强文本中关键特征的权重;RONRAN等[36]提出两层双向LSTM-CRF模型,在不使用任何词典的情况下,在综合评价指标F值(F-measure)上取得了91.10%的成绩。类似地,SETI等[50]采用双向LSTM作为上下文编码层,采用自注意力机制模型捕获文本的全局语义信息,减少层与层之间语义信息传递的累积误差,增强文本中命名实体之间的相关性;DENG等[62]提出一种基于自注意的双向门控递归单元(BiGRU)和胶囊网络(CapsNet),在不依赖外部字典信息的情况下具有更好的性能;ALSAARAN等[63]提出一种基于BERT-BGRU的阿拉伯NER方法,该方法在ANERCorp数据集和合并的ANERCorp和AQMAR数据集上表现最优。
1.2.3 神经语言模型
前述深度学习方法依赖大量的标注数据训练,成本高且易出现人为错误,而神经语言模型采用无监督学习进行预训练,有效解决了标注数据缺乏的问题。
PARVEZ等[64]构建了一个基于LSTM-base的语言模型,通过将其分解为两个实体类型模型和实体复合模型来学习候选词的概率分布;PETERS等[65]提出一种语言模型增强序列标记器,采用预训练的神经语言模型扩充序列标签模型中的标记表示,并嵌入CRF-biLSTM模型;LIU等[66]提出基于知识增强的语言模型(Knowledge-Augmented Language Model, KALM),利用知识库中可用信息和门控机制增强传统语言模型,通过模型中隐藏的实体类型信息,以完全无监督的方式识别命名实体。
1.2.4 Transformer
预训练语言模型适用于NER,如BERT[67]及其变体RoBERTa[68],ALBERT[69],T5[70],是基于双向Transformer架构的大规模神经网络,其以无监督方式采用开放数据集进行训练。SUN等[71]提出一个大规模预处理的中文自然语言处理模型ChineseBERT,该模型利用汉字的字形和拼音信息来增强文本的语义信息,从表面字符形式中捕捉上下文语义并消除汉语复音字符歧义;ZHU等[72]将词典信息融合到中文BERT中,提出一种Lex-BERT模型,采用特殊标记识别句子中单词的边界,修改后的句子将由BERT直接编码。
LI等[73]提出以BERT为主干的统一的机器阅读理解(Machine Reading Comprehension, MRC)NER框架,通过微调模型即可处理重叠或嵌套的实体;LIANG等[74]提出BERT辅助的远程监督开放域NER方法,首次利用预训练的语言模型(ELMo[75],BERT[67],XLnet[76])实现远程监督的开放域NER;XUE等[77]提出一个NER特有的从粗到细实体知识增强(Coarse-to-Fine Entity knowledge Enhanced, CoFEE)的预训练框架,将从粗到细自动挖掘的实体知识注入BERT预训练模型。该框架分为3个阶段,即通过实体跨度识别任务预热模型、利用基于地名录的远程监督策略训练模型提取粗粒度实体类型、通过聚类挖掘细粒度的命名实体知识。LI等[78]引入一个平面点阵Transformer(Flat-Lattice-Transformer, FLAT)来融合中文NER的词汇信息,将点阵结构转换成一组跨度,引入特定位置的编码,避免了词汇信息损失并提高了性能。
1.2.5 图神经网络
基于图神经网络的NER模型适合处理图结构数据,如文档间的结构信息、层次分类和依赖树。
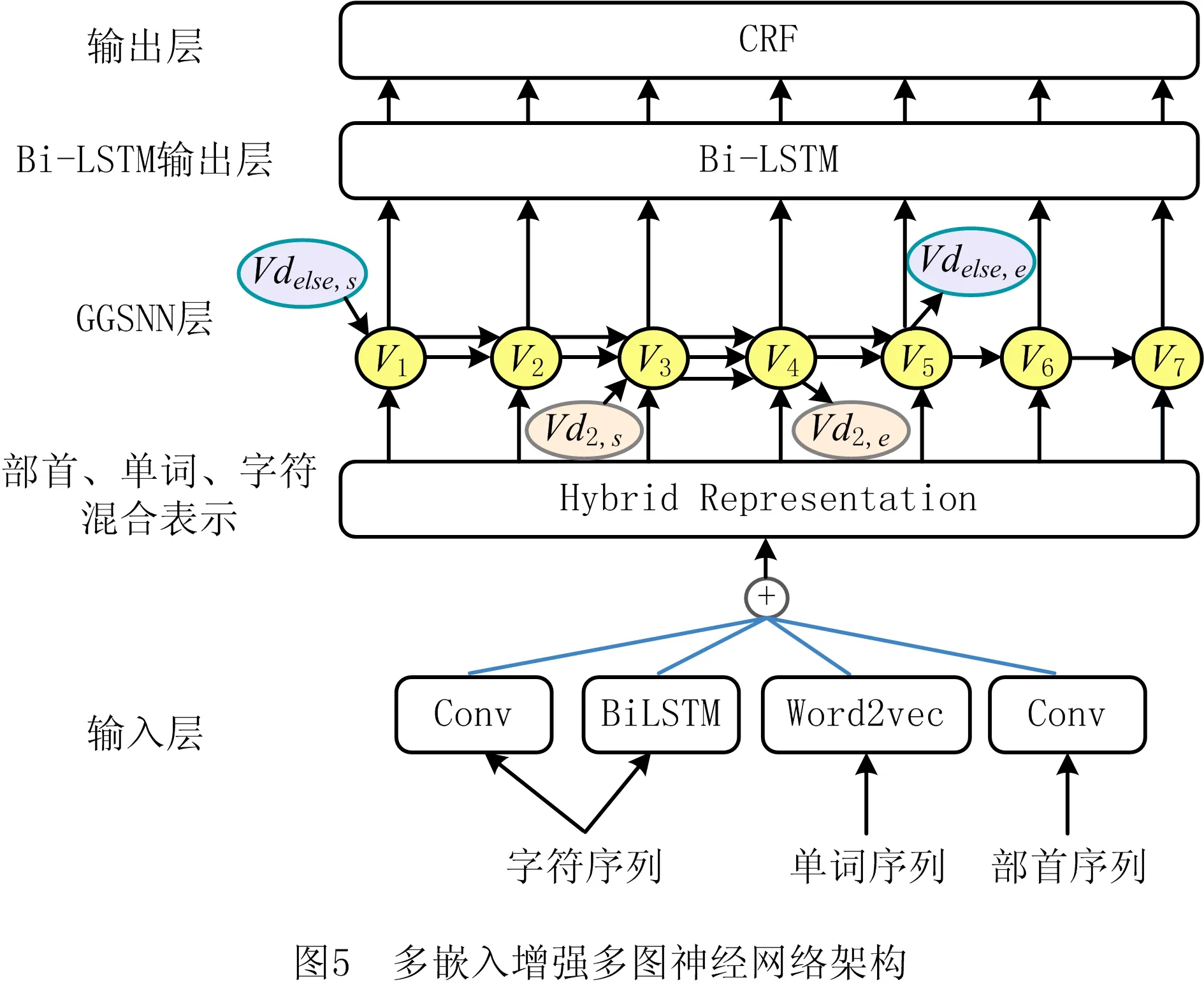
GUI等[79]提出具有全局语义的基于词典的图神经网络(Lexicon-based Graph Neural network, LGN),其将词典知识与相关字符连接来捕获局部特征,用全局中继节点捕获全局句子语义和长距离依赖,可有效解决中文词歧义问题;CETOLI等[35]提出基于图卷积网络的NER方法,采用双向图卷积网络(Graph Convolutional Network, GCN)提升双向LSTM的性能;TANG等[49]提出单词—字符GCN,采用交叉GCN块同时处理两个方向的单词—字符有向无环图,并结合自注意力网络排除图中的琐碎信息,其操作可在所有节点上并行。针对中文NER缺乏实体边界分隔空间的问题,LEE等[52]提出基于多嵌入增强多图神经网络的NER方法,通过集成不同粒度的多个嵌入来扩展字符表示,并将其输入到多个门控图序列神经网络(Gated Graph Sequence Neural Networks, GGSNN)来识别命名实体。如图5所示为多嵌入增强多图神经网络架构,模型核心为自适应GGSNN,GGSNN通过使用带有GRU的神经网络生成有意义的输出或学习节点表示,其更擅长捕获中文NER任务的局部文本特征。
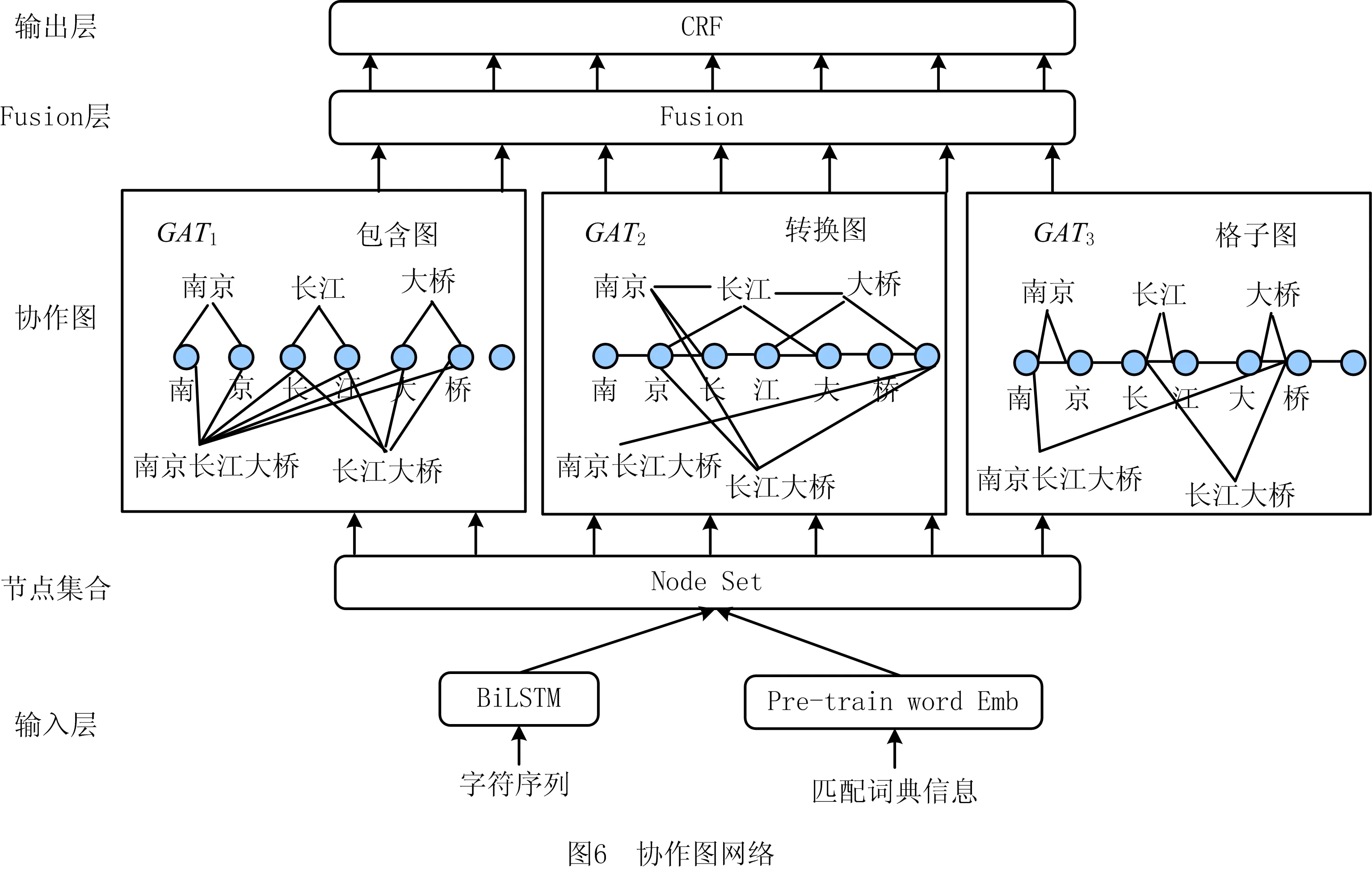
SUI等[41]提出一种基于字符的协作图网络,如图6所示,图层中有3个单词字符交互图:①包含图(C-graph),对字符和自匹配词汇之间的联系进行建模;②转换图(T-graph),在字符和最近上下文匹配词之间建立直接连接;③格子图(L-graph),通过多跳隐式捕获自匹配词汇和最近上下文词汇的部分信息。该网络在大部分中文NER数据集上具有最佳性能。LUO等[80]提出一种二分平图网络(Bipartite FlatGraph network,BiFlaG)模型用于嵌套NER。
1.3 标签解码器
标签解码器处于NER模型的最后阶段。目前,标签解码器架构可分为二元分类器Softmax、CRF、递归神经网络、指针网络(pointer network)和胶囊网络(capsule network)。
1.3.1 二元分类器Softmax
早期的NER模型[39,81]多采用多层感知机(Multi-Layer Perceptron, MLP)+Softmax作为标签解码器。XIA等[82]提出一个多粒度命名实体模型,用两层全连接神经网络将候选实体分为预定义的类别;LI等[73]采用两个Softmax,一个预测每个标记是否为起始索引,另一个标记每个令牌是否为结束索引,为给定上下文和特定查询输出多个开始索引和多个结束索引,缓解实体重叠问题。
1.3.2 条件随机场
CRF是一个以观察序列为条件的全局随机场,已广泛用于基于特征的监督学习。目前,大部分基于深度学习的NER模型均选择CRF层作为标签解码器,从训练数据集中学习约束,以确保最终预测的实体标签序列有效。目前,已有很多工作选择CRF层作为标签解码器应用在双向LSTM层之后47]、CNN层之后[58]以及GCN层之后[35,49-50]。
1.3.3 指针网络
指针网络是VINYALS等[83]提出的用于学习输出序列条件概率的神经网络模型,其中元素是与输入序列中的位置相对应的离散标记。指针网络将注意力作为指针,选择输入序列元素作为输出,解决可变大小的输出词典问题。ZHAI等[84]采用指针网络作为标签解码器,在分割和标记方面均取得较好的效果。
1.3.4 胶囊网络
胶囊网络是SABOUR等[85]首次提出的一种具有更强解释性的新网络,不同于CNN模型中的标量值,其输入输出均为向量形式的神经元,神经元中的每个值表示一个属性,如姿态、形变、颜色等;ZHAO等[86]提出用于文本分类的CapsNet,提高了分类性能。在NER领域中,DENG等[62]用CapsNet作为标签解码器,胶囊表示实体标签,胶囊向量的模长度表示实体标签预测概率,胶囊向量的方向表示实体属性。因为胶囊网络用胶囊向量表示代替标量表示,所以具有更强的实体信息表达能力。
2 其他应用深度学习的命名实体识别方法
前面概述了基于深度神经网络架构的NER方法,本章将简述基于其他深度学习技术的NER方法。
深度神经网络模型无需人工特征,但需要大规模标记数据集进行训练,人工标注成本较高。领域自适应是解决该问题最有效的途径,其用来自相关源领域的丰富标记数据增强基于目标领域模型的泛化能力。LEE等[87]在实体抽取中引入迁移学习,将预训练好的实体抽取模型迁移到其他场景,效果良好;ALSAARAN等[63]通过微调预训练的BERT模型识别和分类阿拉伯命名实体,有效提高了模型训练效率;YANG等[88]提出多任务跨语言的联合训练模型,在任务和语言间共享网络架构和模型参数,提高了模型性能;JIA等[89]研究了用于多任务学习的多细胞合成LSTM结构,用单独的细胞状态对每个实体类型进行建模,借助实体类型单元,可以在实体类型级别进行跨领域知识转移。然而,基于迁移学习的方法仍存在局限性:①当源域和目标域文本特征分布差别过大时,通过迁移学习进行微调可能导致过拟合;②特定领域的信息通常被忽略。因此,HAO等[90]提出一个半监督的可迁移NER框架,将领域不变的潜在变量和领域特定的潜在变量分开,其在跨域和跨语言的NER表现最佳。
LAI等[91]提出基于图注意力网络的实体关系联合抽取模型(joint Entity-Relations Extraction via Improved Graph Attention networks,ERIGAT),可有效提取多跳节点信息;CARBONELL等[92]提出利用图神经网络实现半结构化文档中的NER和关系预测的方法,可从半结构化文档中提取结构化信息;LUO等[93]提出无监督的神经网络识别模型,其仅从预训练的单词嵌入中获取信息,并结合基于强化学习的实例选择器区分阳性句子和有噪声句子,然后对粗粒度标注进行细化,实验表明在不使用标注词典或语料库的情况下性能显著。针对NER的过拟合问题,WANG等[94]提出一种用于NER的对抗训练LSTM-CNN方法。
MUIS等[95]提出可处理重叠和不连续实体的超图模型,WANG等[96]用LSTM扩展了超图模型,XIANG等[97]提出一种基于迁移的非连续神经模型,这些NER模型可有效排除重叠或不连续实体;LI等[98]提出基于跨度的联合模型,以端到端的方式识别重叠和不连续的实体,人工干预少且可并行计算;ZHANG等[99]提出统一的多模态图融合方法(Unified Multi-modal Graph Fusion, UMGF),可以为NER捕获多模态语义单元之间的各种语义关系。
3 基于深度学习的命名实体识别方法对比
目前,NER模型的研究主要侧重于输入表示和文本上下文编码模型的设计与改进,标签解码器主要采用CRF,其在捕获标签转换依赖关系方面非常强大。
分布式输入表示是影响NER性能的首要环节,其可混合多种特征,包括字特征、词特征、词性特征、句法特征、位置特征、部首信息特征、拼音特征、领域字典等信息,也可将外部知识库作为字符特征信息的补充。领域词汇增强可显著提高NER性能,然而构建领域词典的经济成本高,而且整合外部词典会对端到端学习产生不利影响,降低了模型的泛化性。
表1总结了各种输入表示的特点,并对比了其优缺点。混合多特征的输入表示性能明显优于基于单词或基于字符级别的输入表示,其中词向量嵌入、基于CNN字符嵌入和上下文嵌入均为比较常用的方法,用GCN、图注意力网络(Graph Attention network, GAT)、BERT等挖掘文本深层次的抽象特征是目前研究的热点。
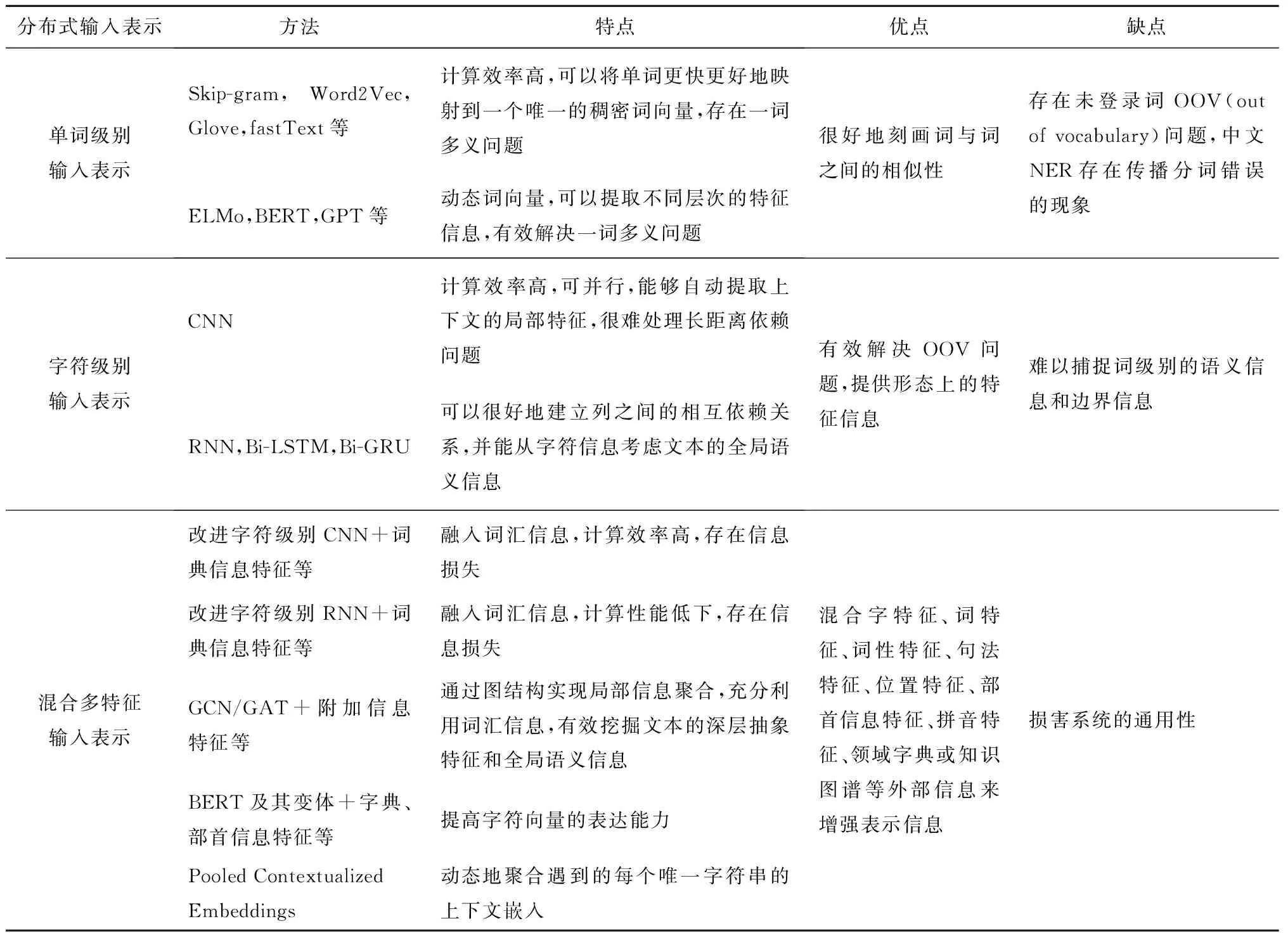
表1 分布式输入表示对比
表2总结了文本上下文编码模型,从捕获长距离依赖、局部上下文信息、并行性、信息损失程度、可迁移性等方面对模型进行了对比。根据每个上下文编码模型的结构及其相关文献表明,基于CNN,GNN等相关的NER模型在捕获局部上下文信息、并行性等能力方面显著优于基于RNN和Transformer的相关模型,在捕获局部上下文信息和并行性方面评级为高。然而,因为RNN采用线性序列结构编码,使其在捕获长距离依赖方面表现出色,很难并行化,所以在捕获长距离依赖方面评级为高,在并行性方面评级为低。Transformer架构的堆叠自注意力模块可有效捕获全局上下文信息,评级为高。上下文编码模型均有一定信息损失,ID-CNN[56]是以损失部分信息为代价扩大卷积核的感受野,Lattice LSTM[44]为了引进词典构建的模型也会损失大量信息,在信息损失程度方面评级为高。相比之下,基于图神经网络的NER模型、FLAT[78]、Simplify the Usage of Lexicon[47]最大程度避免了词汇信息损失,评级为低。在准确度方面,上下文编码模型在CoNLL03数据集中的F值超过92%,在MSRA数据集中的F值超过94%,评级为高,其他评级为一般。

表2 上下文编码
文本上下文编码采用深度学习网络捕获上下文依赖关系,用于上下文编码的深度学习模型各有优缺点,适用于不同场景。对于实时性要求高的场景,CNN改进模型和BERT模型均可实现并行计算,但BERT模型复杂度较高,在计算速度和推理速度方面低于CNN模型,最新的FLAT模型在推断速度和词汇信息损失方面表现优异。微调预训练模型虽然适用于领域样本匮乏的小样本学习场景,但是在一些领域的性能并不好,因为预训练的语料库具有强命名规律、高提及覆盖率和充足的上下文多样性,会破坏模型的泛化能力。近期研究虽然通过迁移学习、多任务联合学习、半监督学习、强化学习、对抗训练、多模态等方法来缓解领域样本匮乏问题,但是仍然面临巨大挑战。领域中实体嵌套多的场景适用BiFlaG、超图模型和基于跨度的联合模型。
4 结束语
NER对于在海量工业制造全流程数据中挖掘出有价值的信息意义重大,本文综述了传统NER方法和基于深度学习的NER方法,对近年主流的基于深度学习的NER技术从分布式输入表示、上下文编码、标签解码器3个方面进行了阐述和分析,并对比了分布式输入方法和上下文编码模型的性能和优缺点。未来NER领域仍需应对大规模高质量标注数据缺乏、跨域NER、嵌套实体抽取、新实体的有效识别、NER的高准确率和高覆盖率等挑战,如何面向多模态数据进行多模态实体识别将成为领域研究的热点。
