井下无人驾驶电机车行驶场景中多目标检测研究
2022-07-07郭永存童佳乐王爽
郭永存, 童佳乐, 王爽
(1. 安徽理工大学 深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001;2. 安徽理工大学 矿山智能装备与技术安徽省重点实验室,安徽 淮南 232001;3. 矿山智能技术与装备省部共建协同创新中心,安徽 淮南 232001;4. 安徽理工大学 机械工程学院,安徽 淮南 232001)
0 引言
煤炭作为能源的重要组成部分,是我国经济持续发展的重要基础[1-2]。目前,我国正着力发展智能矿用机械,以提高煤矿智能化发展水平,为煤炭工业高质量发展提供核心技术支撑[3-4]。煤矿井下有轨电机车是一种煤矿辅助运输设备,承担着运输井下煤炭、矸石、设备和人员等任务,具有运行频繁、运输量大、运行距离长等特点。现阶段,我国煤矿井下有轨电机车均采用人工驾驶方式,由于井下巷道狭窄、光照不充分、司机疲劳驾驶和技术保障手段缺乏等原因,存在电机车超速、闯红灯、追尾、碰撞行人等安全问题[5-6]。研究煤矿辅助运输电机车无人驾驶技术,可减少井下作业人员数量,降低煤矿安全事故发生概率,对保障煤矿安全高效生产具有重要意义[7]。
近年来,快速发展的计算机技术为目标智能检测识别提供了坚实的软硬件基础,基于机器视觉的障碍物识别技术得到了广泛关注和应用。卷积神经网络(Convolutional Neural Network,CNN)为基于深度学习的智能目标检测算法提供了技术支撑,已被应用于自动驾驶、行人检测等诸多场景。基于深度学习的智能目标检测方法分为单阶段目标检测和双阶段目标检测2类:① 单阶段目标检测方法以YOLO(You Only Look Once)[8]、单阶段多框检测器(Single Shot MultiBox Detector,SSD)[9]为代表,直接对输入图像进行检测,输出目标类别及边界框。该类方法检测速度较快,但对小目标物体的检测精度较低,无法识别出轨道中的石块及其他小型障碍物,且对于重叠目标,易造成漏检,无法满足电机车无人驾驶需求。② 双阶段目标检测方法以区域CNN(R-CNN)[10]、快速R-CNN(Fast R-CNN)[11]、更快速R-CNN(Faster R-CNN)[12]、掩码R-CNN(Mask R-CNN)[13]为代表,通过感兴趣区域(Region of Interest,RoI)提取候选框,针对每个候选框进行独立预测输出。该类方法检测精度高,但检测速度较慢。
在轨道交通检测领域,由于轨道目标在图像中所占比例较大且检测出的轨道边界框与轨道掩码之间存在一定间隙,通过边界框重叠与否不能准确判定目标是否为障碍物。因此,为获取轨道掩码,有效判定目标是否为障碍物,可采用实例分割方法在目标检测的同时获得目标掩码。Mask R-CNN模型在Faster R-CNN的基础上增加掩码预测并行分支,可在实现目标识别分类的同时,分割出同一类目标的不同实例。此外,Mask R-CNN采用感兴趣区域对齐网络(RoI Align)层代替Faster R-CNN中的RoI Pooling(感兴趣区域池化)层,利用双线性插值代替量化操作,解决了区域像素不匹配的问题,具有更高的识别与分割精度[14]。但Mask R-CNN模型仍存在检测速度较慢、小目标检测精度低等问题。针对该问题,本文提出一种基于Mask R-CNN的改进模型-SE-HDC-Mask R-CNN,该模型通过压缩-激励(Squeezeand-Excitation,SE)模块和混合空洞卷积(Hybrid Dilated Convolution,HDC)提升目标检测速度、小目标检测精度及掩码分割精度,可在目标检测的同时进行像素级分割,提取轨道及其他目标掩码,为后续确定目标障碍物提供基础。
1 Mask R-CNN模型架构
Mask R-CNN模型架构如图1所示,主要由4个部分组成:① 骨干网络 (Backbone):包括主干特征提取网络ResNet50/101和特征金字塔网络(Feature Pyramid Networks,FPN),结合2个网络对输入图像进行特征提取,生成特征图(Feature Maps)。② 候选框区域生成网络(Region Proposal Network,RPN):通过滑动窗口扫描特征图,寻找目标所在区域,经前景、背景分类和边框回归生成候选区域(Proposals)。③ RoI Align:候选区域在RoI Align中进行匹配,完成特征图特征聚集并池化为固定大小。④ 三分支预测网络(Three Branches):将目标分类信息、边界框回归信息及语义信息相融合,得到目标类别、定位边界框和掩码分割图像。
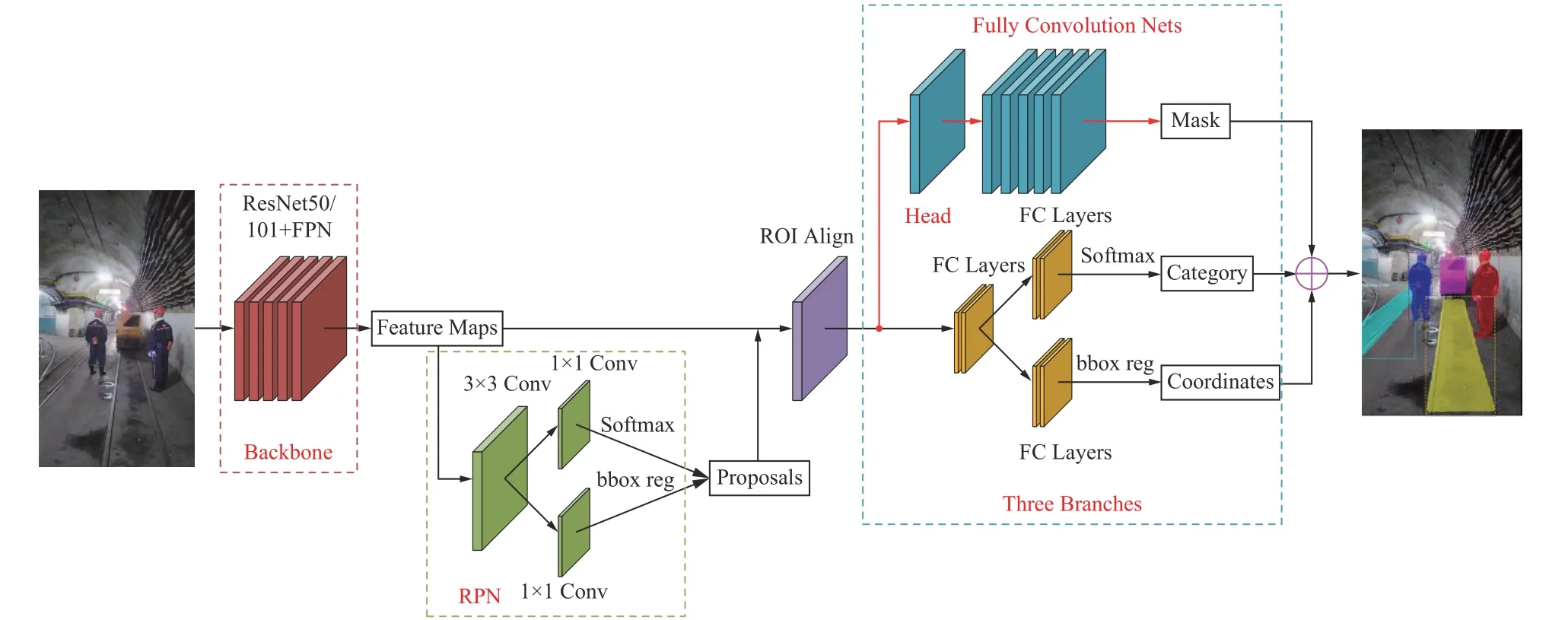
图1 Mask R-CNN模型架构Fig. 1 Architecture of Mask R-CNN model
2 SE-HDC-Mask R-CNN模型
SE-HDC-Mask R-CNN模型对Mask R-CNN模型的主干特征提取网络ResNet进行2点改进:① 在ResNet网络中嵌入SE模块。② 将ResNet中的标准卷积替换成HDC。
2.1 SE模块
ResNet采用残差结构使模型具备较好的特征提取能力,但在特征提取时未能充分利用图像信息,尤其是图像通道信息。SE模块可增强模型对特征的选择和捕获能力,通过学习各个通道的重要程度和相互联系,对重要特征信息赋予较大权重,对次要特征信息赋予较小权重,从而提高特征提取效果,加快网络训练速度[15]。
SE模块包括3个部分:① Squeeze操作:通过全局平均池化(Global Average Pooling)操作将电机车运行特征图维度H×W×C(高×宽×通道数)压缩成1×1× C。② Excitation操作:通过第1个全连接层(Fully Connected)将特征图的通道数压缩为C/S(S为缩放参数,本文取S=16),并通过ReLU函数激活;再经过1个全连接层后由Sigmoid函数激活,将通道数恢复到原大小,得到不同特征通道的权重。③ Reweight操作:将各通道权重与对应的特征图通过Scale尺度化操作相乘,在通道维度上实现对初始特征权重的重标定,抑制对当前任务作用不大的特征通道信息,突出有用的特征通道信息。
2.2 HDC
在图像分割领域,图像特征提取常采用池化层与上采样层相结合的方式,先减小图像尺寸,增大感受野,再通过上采样恢复至原始图像大小进行预测。在图像尺寸减小、增大过程中损失了许多细节信息,使得一些细节信息无法重建。空洞卷积可在一定程度上避免细节信息丢失现象[16]。但空洞卷积存在以下问题:① 叠加多个相同扩张率的空洞卷积时会导致感受野中许多像素未利用,出现大量空洞,即网格效应。② 空洞卷积的设计目的是获得较大感受野,提升模型对大目标物体的分割能力,但小目标物体本身不需要较大的感受野,不适合采用具有较大扩张率的空洞卷积。针对上述问题,本文提出能兼顾大目标和小目标检测需求的HDC。
应用HDC时应满足以下要求:① 叠加卷积的扩张率不能有大于1的公约数,否则仍会出现网格效应。② 扩张率应设计成锯齿状结构,如[1,2,5,1,2,5],以便同时满足小目标和大目标的检测分割要求。③ 2个非零像素之间的最大距离Mi需满足以下条件:

式中:ri为空洞卷积第i层的扩张率;n为空洞卷积的总层数。
假设卷积核尺寸为K×K,则式(1)的设计目标是M2≤K。
2.3 改进ResNet网络结构
为提高模型对特征的利用率,提高对小目标物体的检测精度,扩大特征图感受野,增强信息关联性,在ResNet内的每个残差块Conv block和Identity block中嵌入1个SE模块,并将其3×3的标准卷积替换成扩张率为[1,2,5,1,2,5]的HDC。优化后的Conv block结构如图2所示,Identity block与Conv block结构类似,仅缺少Shortcut块。
改进ResNet网络结构如图3所示,包括5个阶段(Stage1-Stage5),除Stage1外,其余4个阶段均包含残差块。

图3 改进ResNet网络结构Fig. 3 Structure of improved ResNet network
3 井下无人驾驶电机车多目标检测技术构架
井下无人驾驶电机车多目标检测技术构架如图4所示。首先,通过电机车车载相机获取前方巷道视频信息,利用OpenCV将视频分帧并输入SEHDC-Mask R-CNN模型中。然后,模型输出目标掩码及标定目标类别,通过掩码是否重叠判断目标是否为障碍物,并计算障碍物距离。最后,对电机车发出鸣笛、减速和刹车等指令。考虑到井下电机车行驶速度较慢,且视频中每帧图像之间具有信息连续性[17],采用视频分帧的方式提取图像,该方法可在一定程度上满足实时检测需要,提高目标检测效率。
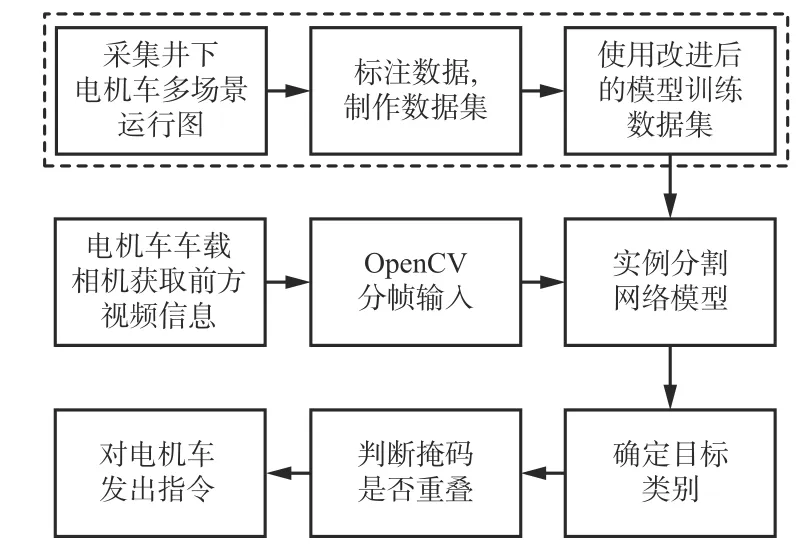
图4 井下无人驾驶电机车多目标检测技术构架Fig. 4 Multi-object detection technology framework for underground unmanned electric locomotive
4 实验分析
4.1 实验环境
井下无人驾驶电机车多目标检测实验硬件参数见表1。主要软件环境为python3.6,tensorflowgpu1.10.1,keras=2.2.0,CUDA9.0 with cudnns,实验类别包含轨道、电机车、信号灯、行人、石块及背景6类,设置学习率为0.001,权重衰减系数为0.000 1,动量为0.9。

表1 井下无人驾驶电机车多目标检测实验硬件参数Table 1 Experimental hardware parameters of multi-object detection of underground unmanned electric locomotive
4.2 数据采集与预处理
实验数据来源于安徽省某煤矿井下电机车运行环境的实地拍摄,通过防爆相机等设备采集360张电机车多场景运行图像(不同光照条件、不同拍摄角度、不同目标种类及数量),图像像素大小为1 080×1 920。通过改变图像的亮度、色度、锐度、对比度及旋转、平移和拉伸等方法对数据样本进行扩充。数据样本扩充后,共有1 600张电机车运行图像,按7∶2∶1比例划分训练集、验证集和测试集,得到训练集图像1 120张、验证集图像320张、测试集图像160张。使用图像标注工具VIA对数据集中的目标进行标注并创建目标区域,得到相应json文件。
4.3 评价指标
本文设置的检测目标包括轨道、电机车、信号灯、行人及石块,为全面、客观评价网络模型对设定目标的检测性能和分割效果,选择平均准确率(Average Precision,AP)、平均准确率均值(mean Average Precision,mAP)、交并比(Intersection over Union,IoU)作为评价指标,其中IoU包含边界框交并比IoUbox和掩码交并比IoUmask。
AP为预测单个目标类别的平均准确率,等于准确率和召回率曲线(P-R曲线)与坐标轴所围面积,即P-R曲线的积分。准确率是指模型分类为正样本的集合中分类正确的比例。召回率是指分类正确的样本数占所有正样本数的比例。mAP等于所有类别AP的平均值。准确率P和召回率R的计算公式分别为
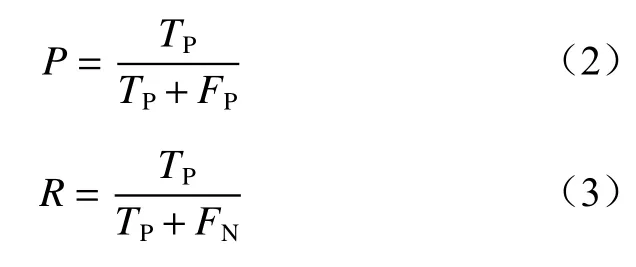
式中:TP为被正确识别成目标的正样本个数;FP为被错误识别成目标的负样本个数;FN为目标未被正确识别的样本个数。
计算AP时需设定IoU阈值,本文设IoU=0.5,当IoU>0.5时设定测试样本为正样本。
采用IoUmask评价掩码分割质量,如图5所示,左侧真实区域A表示目标真实掩码,右侧预测区域B表示目标预测掩码。将区域A与区域B之间的交集与并集的比值作为掩码质量高低的评价标准,从而衡量目标掩码的定位精度。IoUmask计算公式为

图5 掩码分割质量评价Fig. 5 Evaluation of mask segmentation quality
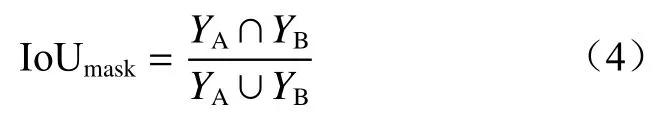
式中YA,YB分别为目标真实掩码和预测掩码。
4.4 基线选择
目前Mask R-CNN主流的主干特征提取网络有ResNet50和ResNet101两种,其主要区别体现在网络深度不同。网络深度越大,则网络复杂程度越高,网络计算量越大。因此,为平衡网络模型的训练效果和训练时长,需要选择合适的网络深度。在训练集和验证集中对采用ResNet50和ResNet101的Mask R-CNN模型进行训练,结果如图6所示。定性分析结果见表2,其中mIoUmask和mIoUbox分别为平均掩码交并比和平均边界框交并比。
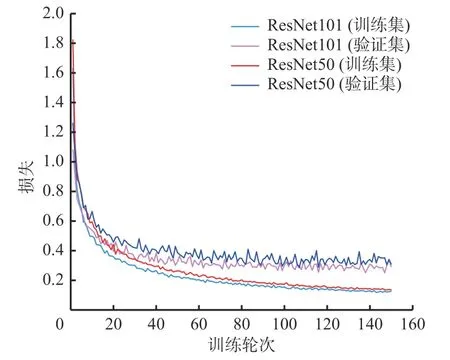
图6 ResNet50/101网络下的模型损失Fig. 6 Model loss under ResNet50/101 network
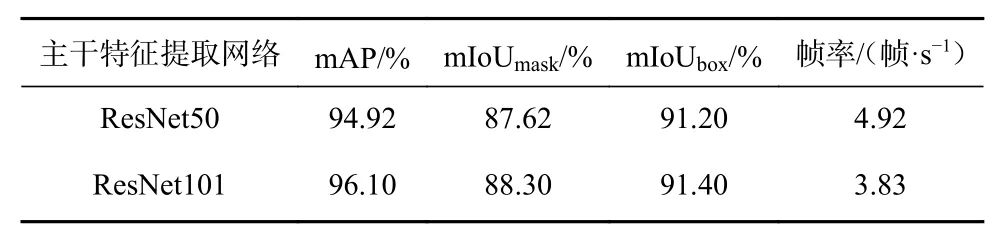
表2 ResNet50/101网络下的定性分析Table 2 Qualitative analysis under ResNet50/101 network
由图6可知,训练至140次左右时模型达到拟合状态,且2种主干特征提取网络下模型的训练集损失和验证集损失最终相差不大,但ResNet101相较于ResNet50具有更低的损失值,故ResNet101作为主干特征提取网络时模型的性能较好。由表2可知,ResNet101作为主干特征提取网络时模型的mAP、mIoUmask和mIoUmask这3个指标表现较好,但采用ResNet50时模型的性能指标和其相近,且帧率更高,意味着其检测速度更快。综合考虑网络模型的训练效果、模型复杂度及检测速度,选择ResNet50作为Mask R-CNN模型主干特征提取网络。视频分帧时,每秒读取6帧图像输入网络模型。
4.5 SE-HDC-Mask R-CNN模型性能验证
为验证SE-HDC-Mask R-CNN模型的可行性及有效性,利用原始数据集对其进行训练,模型参数与Mask R-CNN模型一致,对比分析结果见表3。由表3可知:与Mask R-CNN模型相比,SE-HDC-Mask R-CNN模型对轨道和行人(大目标)的检测精度及掩码分割精度略低,但也具有较高精度;对信号灯和石块(小目标)的检测精度分别提升了0.7%和4.1%,IoUbox分别提升了0.3%和2.4%,对石块的掩码分割精度提升了3.0%。

表3 SE-HDC-Mask R-CNN模型与Mask R-CNN50模型对比结果Table 3 Comparison results between SE-HDC-Mask R-CNN model and Mask R-CNN50 model %
SE-HDC-Mask R-CNN模 型 及 YOLOV2,YOLOV3-Tiny,SSD,Faster R-CNN,Mask R-CNN等模型在同一数据集下的目标识别结果综合评价见表4。由表4可知:相较于YOLOV2,YOLOV3-Tiny,SSD,Faster R-CNN等模型,SE-HDC-Mask R-CNN模型的mAP和mIoUbox均有较大提升;相较于Mask R-CNN模型,mAP,mIoUmask,mIoUbox均提升了0.5%。
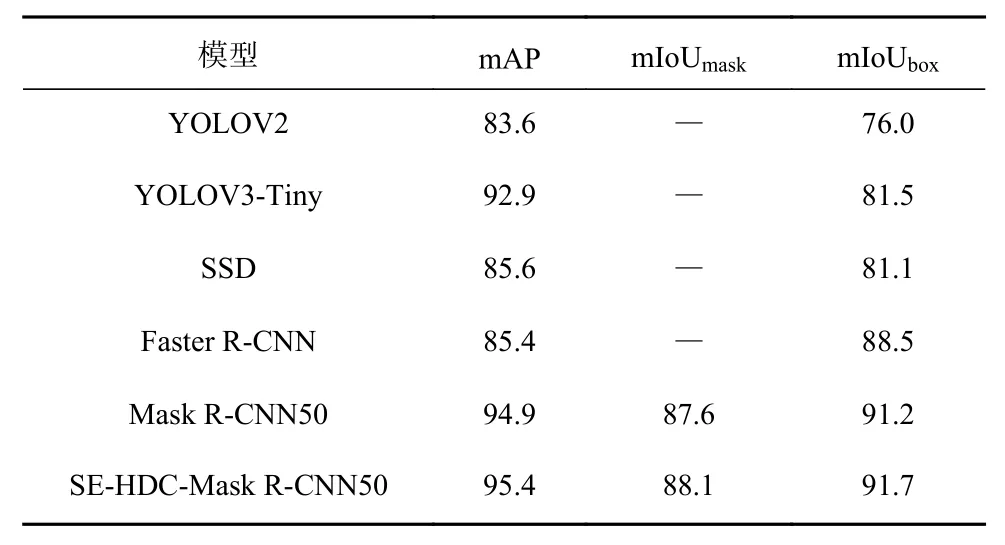
表4 不同网络模型的评价结果Table 4 Evaluation results of different network models %
采用不同网络模型进行目标检测及分割,结果如图7所示。由图7(a)-图7(c)可明显看出,SE-HDC-Mask R-CNN50模型可有效检测出短轨道且目标掩码更接近于原始掩码。由图7(b)-图7(e)、图7(g)可看出,SE-HDC-Mask R-CNN模型对石块和远处信号灯的检测准确度高于其他模型。由图7(f)可知,YOLOV3-Tiny模型虽能识别石块和信号灯等小目标,但检测精度低于SE-HDC-Mask R-CNN模型。
结合表4及图7可知,与其他模型相比,SE-HDCMask R-CNN模型能对井下轨道、石块及其他小型障碍物进行检测,有效解决小目标漏检问题,且提取的目标掩码更接近于原始掩码。

图7 井下电机车行驶场景中不同网络模型的目标检测及分割结果Fig. 7 Object detection and segmentation results of different network models in underground electric locomotive driving scene
4.6 SE-HDC-Mask R-CNN模型泛化表现
考虑到煤矿井下巷道环境恶劣,为验证模型能否适应电机车行驶的不同场景,在煤巷直轨、弯轨、黑暗环境、多目标重叠等不同场景下进行模型测试,结果如图8所示。由图8可知,SE-HDC-Mask R-CNN模型在多种场景下均可有效实现目标检测。

图8 SE-HDC-Mask R-CNN模型在不同场景下的目标检测结果Fig. 8 Object detection results of SE-HDC-Mask R-CNN model in different scenarios
综上,虽然煤矿井下巷道环境恶劣,但SE-HDCMask R-CNN模型可有效检测前方目标,可为后续目标障碍物的识别奠定基础,该模型具有一定泛化能力及较高鲁棒性,基本满足电机车无人驾驶障碍物检测需求。
5 结论
(1) 嵌有SE模块和HDC的主干特征提取网络可提高Mask R-CNN模型对特征的利用率,增强信息关联性,提高对小目标物体的检测精度。视频间隔分帧方式可在一定程度上满足煤矿巷道中电机车的实时检测需求。
(2) SE-HDC-Mask R-CNN模型可有效识别井下电机车行驶场景中的目标,降低目标漏检、误检概率,提高掩码分割精度。改进后的模型具有较高目标识别精度,与Mask R-CNN模型相比,mAP,mIoUmask,mIoUbox均提升了0.5%,综合性能优于YOLOV2,YOLOV3-Tiny,SSD,Faster R-CNN等模型。
(3) 不同场景下的测试结果表明,SE-HDCMask R-CNN模型在煤巷直轨、弯轨、黑暗环境、多目标重叠等场景下均可有效实现目标检测,具有一定的泛化能力及较高的鲁棒性,基本满足电机车无人驾驶障碍物检测需求。
