基于BP_Adaboost 的农机行驶轨迹状态识别
2022-07-07李亚硕伏伟浩贾晓峰苏仁忠徐名汉庞在溪张悦如
李亚硕, 伏伟浩, 贾晓峰, 赵 博, 苏仁忠, 徐名汉, 庞在溪, 张悦如
(1. 中国农业机械化科学研究院集团有限公司,北京 100083; 2. 土壤植物机器系统技术国家重点实验室,北京 100083;3. 中机建工有限公司,北京 100083; 4. 湖北省农业机械化技术推广总站,湖北 武汉 430017)
0 引言
随着农业机械化作业水平提升,深松、植保、播种、收获等农业全过程已经基本实现机械化,但由于农机种类多、作业范围广而带来的作业质量难以监管、作业效率难以评估等问题日益突出。目前,农机信息化技术系统已经能够实现农机作业的定位、追踪与远程监控,可以利用农机位置信息提取行驶轨迹,并根据物联网信息进行任务分配、作业评估和补贴结算等[1-4]。农机行驶轨迹分为道路行驶轨迹和田间作业轨迹,由于农机手作业不规范或传感器自身问题,在平台上不能有效区分农机行驶过程中的道路转移轨迹和田间作业轨迹,从而影响作业效率评估。目前,轨迹点数据处理多采用聚类算法,可利用田间作业轨迹点密集,道路行驶轨迹点稀疏的特点,通过DBSCAN 聚类的方法区分田间作业和道路行驶轨迹,能够达到较好的识别效果[5-6]。由于不同农机、不同地形作业轨迹相差较大,聚类方法依赖的邻域半径和邻域点数不好确定,并且聚类方法时间复杂度高。有研究人员利用时空信息对轨迹进行密度聚类,由于轨迹点具有时序性,将时间作为聚类信息对准确率的提升帮助不大[7-8]。利用空间索引和网格密度聚类,可有效提升运行速度,但网格大小和密度阈值参数敏感[9-10]。尽管聚类方法对农机田间作业轨迹识别效果较好,但对道路转移行驶轨迹容易误识别,单纯依靠聚类方法,很难提升农机轨迹点识别准确率。
本研究结合农机空间运行轨迹的特点,采集农机行驶轨迹点经纬度、速度、近邻点相互关系等作为特征,利用BP_Adaboost 方法对轨迹点进行训练和识别。通过大量数据分析发现,道路和田间交界处的轨迹点容易将道路行驶轨迹误识别为田间作业轨迹,因此在BP_Adaboost做出识别后,将田间与道路交界处附近轨迹点标记为道路行驶轨迹并添加到训练样本中重复训练,直至训练样本无新增。此方法可有效解决不同地块轨迹差异大、田间道路交界处轨迹点易误识别等问题。
1 农机行驶轨迹状态识别
农机行驶轨迹状态主要分为田间作业状态、道路行驶状态、停车状态(农机故障、休息)等,一般通过安装在农机上的北斗定位接收装置自动记录农机运行全过程轨迹,获取农机经纬度位置信息、速度信息等。田间作业时通常采用直线往复作业方式,运动速度慢,运行轨迹点相对密集;道路行驶时移动速度偏快,运动轨迹呈单向的线性分布;当农机处于停车状态时,农机轨迹的特征表现为一个簇点,簇点的分布范围很小,且比较散乱。利用这些特点,挖掘农机轨迹点之间的相互关系,对农机运行状态进行有效识别。
1.1 数据预处理
农机坐标和速度是轨迹点的主要特征。当农机停车时,车载北斗定位接收装置继续接收信息,由于定位精度原因,轨迹点位置与农机位置有小幅偏差,散落在农机位置小范围内,称为农机停车散点。特殊情况下,由于定位偏差过大,会造成连续两点之间间隔很远,称为轨迹点漂移。农机停车散点及漂移点如图1 所示。
有效轨迹点是正常行驶过程中的连续点,农机停车散点和行驶过程中的漂移点属于无效轨迹点,而无效轨迹点会影响平均速度和轨迹间距的计算,在数据处理前应该去除。本研究中,为保持轨迹连续性和完整性,停车散点和漂移点依然保留,归为道路行驶点,但数据处理时不在计算之内。
由于轨迹点采集的误差,农机停车时轨迹点会集中在一个小的范围内,因此速度为零或一个很小值。为防止将田间作业过程中临时停车轨迹点误删除,判断条件设置为连续多点的速度小于某一阈值。
由于北斗定位接收装置故障、断电或者定位偏差,会造成连续两点之间间隔很远。当某一点与前一点距离比较大,而与下一点间隔正常时,认为两点之间存在断点,将上一点作为前段轨迹终点,该点作为下段轨迹起点;若某一点与前后两点距离都较大,认为该点为漂移点,将该点去除,上一点作为前段轨迹终点,下一点作为下段轨迹起点。
1.2 特征选取
农机轨迹点包含时间、经纬度、速度等信息,农机田间作业轨迹和道路行驶轨迹交叉,用聚类和分类的方法根据轨迹点信息对轨迹点状态进行识别,可以得到一定的效果。以速度为特征和以轨迹点到近邻20 个点距离均值为特征的轨迹识别结果如图2 所示。
图2 中,往复行驶且密集的点代表田间作业轨迹,单行行驶点代表道路行驶轨迹,选用两种特征分别作为判断依据都具有一定的效果。利用速度判断农机轨迹状态时,阈值为平均速度,但由于不同速度采集到的田间作业点数和道路行驶轨迹点数差别比较大,而且在实际行驶过程中由于农机速度不均匀,尤其是道路中减速情况,田间突然加速导致采集数据不稳定,因此单纯依靠速度区分轨迹点状态效果不太好。利用轨迹点与近邻点的距离关系时,田间轨迹点与近邻点间距小且紧凑,道路轨迹点与近邻点距离远;且随着近邻点选取数量的增加,道路轨迹点与近邻点的距离增加更多;但由于道路行驶过程中可能出现减速和往返,田间作业轨迹也可能出现跨垄作业等导致轨迹间距变大,都会导致田间有误识别成道路的轨迹点,道路中也有误识别成田间的轨迹点。

图2 以不同特征分别识别轨迹效果Fig. 2 Track effects recognized by different features
应尽量丰富农机轨迹点的有用信息,农机田间作业是往返作业,田间作业轨迹点密度大于路上轨迹点的密度。可用信息包括速度V、一定半径内近邻点数量m、与近邻点的平均距离Aved等。农机轨迹点在由上述3 个特征组成三维空间中的分布效果如图3 所示。

图3 在三维空间V、m、Aved 中农机轨迹点分布效果Fig. 3 Effect drawing of track point distribution of agricultural machinery in three-dimensional space V, m and Aved
图3 中,“*”代表田间作业轨迹点,“•”代表道路行驶轨迹点。其中近邻点的选取范围为每日轨迹点平均距离的3 倍。从图3 可以看出,两类轨迹点在三维特征空间虽然有区分性,但是也有重叠难以区分的部分。因此,利用以上特征,轨迹点有一定的区分性,说明选取的特征有效,但只依靠这几个特征阈值不能完全区分轨迹点。综上所述,本文选取的特征包括经纬度、速度、近邻点数量、近邻点平均距离、n个近邻点距离等。
1.3 BP_Adaboost 算法
将特征矩阵输入基于AdaBoost 的BP 分类算法中进行训练。AdaBoost 算法的思想是对给定的特征集通过训练一定数量的弱分类器组成一个强分类器,而在BP_Adaboost 中弱分类器即BP 神经网络[11-12]。
BP 神经网络由输入层、隐含层和输出层构成,是一种从输入到输出的映射,通过用已知的模式对网络进行训练,得到一个能反映输入到输出之间精确映射关系的网络,特点是信号前向传播,误差反向传播[13-15]。根据映射网络存在定理:一个3 层前馈网络能以任意精度逼近任意的连续函数。建模过程中,初始学习率设置为0.000 1,既可以保证快速顺利找到损失函数的最小值,又不至于过大反复振荡。
输入层为轨迹点特征,包括轨迹点经纬度、速度、半径r内邻近轨迹点个数、与邻近点平均距离和到邻近点的距离。由于各输入变量的单位不一致且数值范围相差较大,提前依据最大最小原则进行归一化[16]。

式中 ξi,j−输入变量i的第j个值
ξi,min−输入变量i的最小值
ξi,max−输入变量i的最大值
输出层包含2 个神经元,分别对应轨迹点状态。输出层中某神经元输出为1 时,代表农机在田间作业,输出为−1 时代表农机在道路行驶。
隐含层神经元个数可由式(2)确定为8 个。

式中h−隐含层神经元个数
n1−输入层神经元个数
n2−神经元个数
a−可变系数
输入层和隐含层中,每个神经元的激活函数均采用tanh 函数

具体步骤:首先对各弱分类器设定一个初始权值,然后根据各弱分类器对特征集的误差更新权值,误差大的分类器权值提高,误差小的分类器权值降低,循环多次后将最后得到的权值和对应的弱分类器组合起来,得到强分类器。BP_Adaboost 算法由n个BP 神经网络组成,每个BP 神经网络为一个弱分类器,n个BP 网络组成一个强分类器,处理流程如图4 所示。

图4 基于 BP_Adaboost 模型的分类算法流程Fig. 4 Flow chart of classification algorithm based on BP_AdaBoost model
2 试验及结果
试验采用50 台农机2020 年10 月15−26 日的作业数据作为数据集。在农机上安装北斗定位接收装置,每5 s 采集一次作业点数据,总轨迹点数为5 196 782,通过无线发送至后端服务器。每个轨迹点包含农机作业点经纬度、车辆行驶速度等信息。试验选用经纬度、速度、3 倍平均距离内近邻点数量、轨迹点周围20 个点距离及平均距离作为特征,利用BP_Adaboost 算法训练模型,识别农机轨迹点状态。由于道路行驶轨迹点和田间作业轨迹点交界处容易识别错,且常将道路行驶轨迹点识别为田间作业轨迹点,因此将这部分点标记为道路行驶轨迹点标记并放入训练样本重新训练,直至训练样本无新增。
2.1 试验步骤
(1)将采集的数据点做预处理,不计算停车散点和异常漂移点。
(2)标记田间作业轨迹点为1,道路行驶轨迹点为−1,选取每天轨迹点80%为训练样本,当日所有轨迹点为测试样本。
(3)利用BP_Adaboost 训练数据集,并对测试样本进行运行状态识别。
(4)将标记发生变化的轨迹点及前后n个轨迹点标记为−1,并将这n+1 个轨迹点放入训练样本中。
(5)重复步骤3、4,直至训练样本数量不发生变化。
2.2 试验结果
根据上述试验步骤对农机轨迹点状态进行识别,其中一台农机一天的轨迹点状态识别效果如图5 所示。
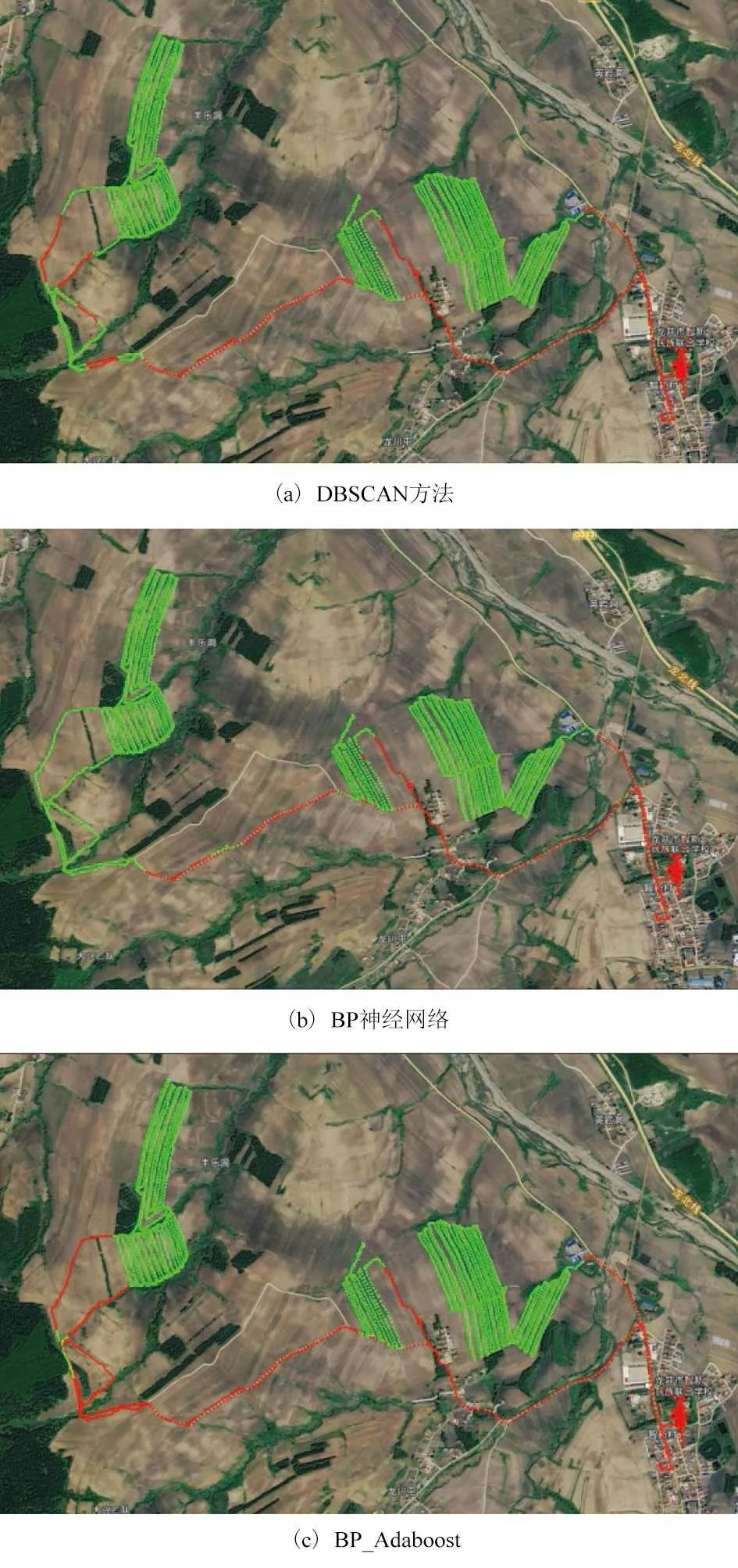
图5 各方法识别效果Fig. 5 Identification effect of each method
图5 中利用DBSCAN 对农机轨迹点进行聚类,核心点周围点数为6,半径为平均距离的3 倍。图5a 左下角处由于道路中有往返行驶和转向的区段,导致该处区域轨迹点密集被误识为田间作业轨迹。利用单BP神经网络训练,错误率较高,多处道路行驶轨迹识别为田间作业轨迹。本文方法选20 个BP 神经网络,利用BP_Adaboost 方法训练,将标记发生改变的轨迹点及附近点标记为道路轨迹点,放入训练样本重新训练,能够解决部分道路轨迹往返和田间道路交界处识别错误的问题,但仍有部分区域识别错误。3 种方法对所有轨迹点进行状态识别,准确率如表1 所示。

表1 各方法识别准确率Tab. 1 Recognition accuracy of each method
轨迹点特征中近邻点数量记为ft_n,轨迹点标记变化点及前后选取点数记为fg_n。ft_n选取范围3~18,fg_n选取范围7~25,分别进行试验,结果如图6 所示。

图6 ft_n 与fg_n 不同取值识别效果Fig. 6 Identification effect drawing of different values of ft_n and fg_n
试验结果表明,总体趋势上随着轨迹点特征中选取近邻点数量ft_n的增加,分类准确率也会提升,当ft_n超过7 后准确率反而开始下降。BP_Adaboost 进行测试时,随着重新训练的标记变化轨迹点前后数量fg_n的增加,分类准确率也会提升,当fg_n超过17 时,准确率反而下降。主要原因如下。
(1)农机田间作业轨迹点较聚集,道路行驶轨迹点一般是单行,比较离散。以轨迹点附近点的紧密程度作为特征训练,当邻近点数量ft_n增加时,样本信息更丰富,训练效果更好,当ft_n增加过多时,道路行驶点附近点数量也随着增加,与田间作业轨迹点的差异性反而减小,进而导致分类准确率开始下降。
(2)BP- adaboost 对测试样本进行识别时,错误多出现在行驶轨迹点标记发生变化的地方,道路行驶点被识别为田间作业轨迹点。将标记发生变化的轨迹点前后邻近点标记为道路行驶点,放入训练样本中重新训练,并再次对测试样本进行分类,既可以丰富训练样本,也可以对容易分错的轨迹点重点训练。因此随着反复训练测试,分类准确率会有提升。当前后近邻点数量fg_n增加时,训练速度更快,样本数量更多,准确率也相应提升。若fg_n过大,容易将田间作业轨迹点错标为道路行驶轨迹点,增加的错误训练样本会影响训练模型,进而影响识别准确度。在个别农机作业中,fg_n选取过大,甚至会使识别准确率降到70%以下。
3 结束语
农机运行轨迹状态识别可以有效评估农机作业效率,本文选取农机轨迹点经纬度、速度、邻近点关系等作为特征,利用BP_Adaboost 方法建立训练模型对农机轨迹点进行识别。通过分析结果,将容易误识的道路和田间交界处附近轨迹点标记为道路行驶轨迹,并添加到训练样本中重复训练,直至训练样本不再增加。该方法识别准确率达到96.89%,有效区分田间作业轨迹和道路行驶轨迹后,可以对田间作业轨迹更好的按地块划分,进而评估每个地块的作业效率。特别是一些按地块补贴的农机作业,地块的划分和有效的作业质量评估,可使作业监管更加高效精准。虽然准确率较DBSCAN 聚类算法和单独BP 神经网络方法有提升,但特征中邻近点数量和标记变化前后点数选取会影响结果,并且对样本标记耗时耗力。因此寻找稳定的分类方法和减少标记工作量是今后研究的重点。
