概念漂移检测算法综述
2022-07-06崔瑞华
崔瑞华,林 玲
(伊犁师范大学网络安全与信息技术学院,新疆伊宁 835000)
0 引言
信息技术的迅速发展促进了工商业的现代化进程,数据源生成数据的速度越来越快,这种快速连续的数据流中蕴含了大量有用信息,称之为流式数据[1].流数据呈现出快速持续到达、可变性强、无限等特性,隐含在其中的概念漂移是其最典型的特征.概念漂移描述了流式数据分布随统计时间而发生不可预见的变化.研究概念漂移检测,有助于提高实际生活中决策和管理模型的预知性,预测和预警模型的准确度.
在移动互联网时代,大量的流式数据涌入人们的生活,不同于传统的静态数据,流式数据具有数据量大,实时可变性强的特点.流式数据分为稳定的数据流和动态的数据流,稳定的数据流独立同分布,而动态数据流不独立同分布,容易出现概念漂移.因此迫切需要高效的数据分析和机器学习技术支持我们作出预测和决策.随着产品的更新发展,市场的激烈竞争,顾客需求的改变,就不可避免地出现概念漂移问题.若出现概念漂移,历史数据的归纳模式可能与新数据不相关,预测和决策结果的准确度就会大大降低.概念漂移现象被认为是数据驱动信息模型、预警模型和决策支持模型效率下降的根本原因.在不断变化的大数据环境中,如何提供更可信有效的数据驱动预测和决策工具已成为一个不可或缺的问题.以在线商城为例,在线商城顾客行为可能会随着时间的推移而发生变化.卖家通过观察顾客一段时间的搜索购买等数据来获得一个销售预测模型,前期买家可以得到一个有效的工作模型,由于顾客的行为是动态的,会随着时间的推移而发生不可预计的改变,就会使得模型的预测结果越来越不精确,即发生了概念漂移现象.导致卖家销售预测模型发生概念漂移的因素有很多,例如季度的变化,夏季避暑产品的销售额会比冬季高,冬季保暖物品的销售额会比夏季高等.
1986年,Schlimmer 和Granger[2]提出概念漂移的概念,自此有关概念漂移的研究层出不穷.许冠英等人详细阐述了集成分类器中的概念漂移问题[3],对比算法和实验数据集区分了不同集成算法的优缺点,但并未从检测概念漂移角度对集成算法进行描述;杜诗语等人对概念漂移数据流集成分类算法进行了介绍[4],指出现阶段概念漂移数据流集成分类算法迫切需要解决的问题;翟婷婷等人描述了在线学习方法对流数据分类的研究现状[5],描述了在演化流数据上处理“概念漂移”问题;贾涛等人分别从单分类器和集成分类器两个角度对数据流决策树进行综述[6],分别介绍了快速决策树、变异决策树、概念漂移决策树以及其他决策树算法.基于上述研究,本文从多个角度对概念漂移检测算法进行归纳和总结,分析了不同角度概念漂移研究方法和技术的最新进展,并且提出了进一步的研究方向.
1 概念漂移的定义、来源和类型
1.1 概念漂移的定义
概念漂移是指预测模型目标变量的性质随统计时间的推移发生无法预计的改变[7].机器学习领域,首先要构建预测模型,指输入特征与其对应输出目标之间的映射函数.在给定时间范围[0,t]中,样本表示为S0,t={d0,…,dt} ,其中di=(Xi,yi)是对于概念的一次观察,Xi指特征向量,yi表示标签,S0,t服从一个确定分布F0,t(X,y).如p0,t(X,y)≠pt+1,∞(X,y),则称在t+1时刻发生概念漂移,记为pt(X,y)≠pt+1(X,y).
1.2 概念漂移的来源
依据贝叶斯学习理论,联合概率可表示为pt(X,y)≠pt(X)pt+1(X,y),从概率论的角度来解析产生概念漂移原因,观察数据分布是否变化并且是否改变决策边界,概念漂移主要有以下3个来源来触发:
(1)虚假概念漂移(virtual concept drift):是指输入的数据分布pt(X)变化,但不会使pt(y/X)改变,对决策边界无影响,即当pt(X)≠pt+1(X)时,pt(y/X)=pt+1(y/X),如图1(a)所示.
(2)真实概念漂移(real concept drift):pt(X)不变,pt(y/X)改变,影响决策边界,为真实的概念漂移,即当pt(X)=pt+1(X)时,pt(y/X)≠pt+1(y/X).只有真实的概念漂移才会影响决策边界发生改变,那么之前的决策模型就会过时,如图1(b)所示.
(3)以上2种漂移的结合:pt(X)和pt(y/X)两者都发生了变化,即pt(X)≠pt+1(X),pt(y/X)≠pt+1(y/X),如图1(c)所示.

图1 3种触发类型的概念漂移
1.3 概念漂移的类型
根据其形式不同可分为4种:
(1)突变型:数据分布或概念在较短的时间内可能突然从一个概念转向另一个不可逆又迅速的变化.对于此类概念漂移,要求模型必须有较高的数据敏感度,能够迅速发现概念漂移,及时修正或更新模型,用以适应新的数据分布或模型,如图2(a)所示.
(2)渐进型:一个新的概念不会突然出现,不停地回到原来概念.重点是数据分布变化发生的较为缓慢,如图2(b)所示.
(3)增量型:增量中包含许多中间的概念,强调概念随时间发生改变,如图2(c)所示.
(4)重复型:指一个概念或是数据分布经过一段时间后再次出现,如图2(d)所示.
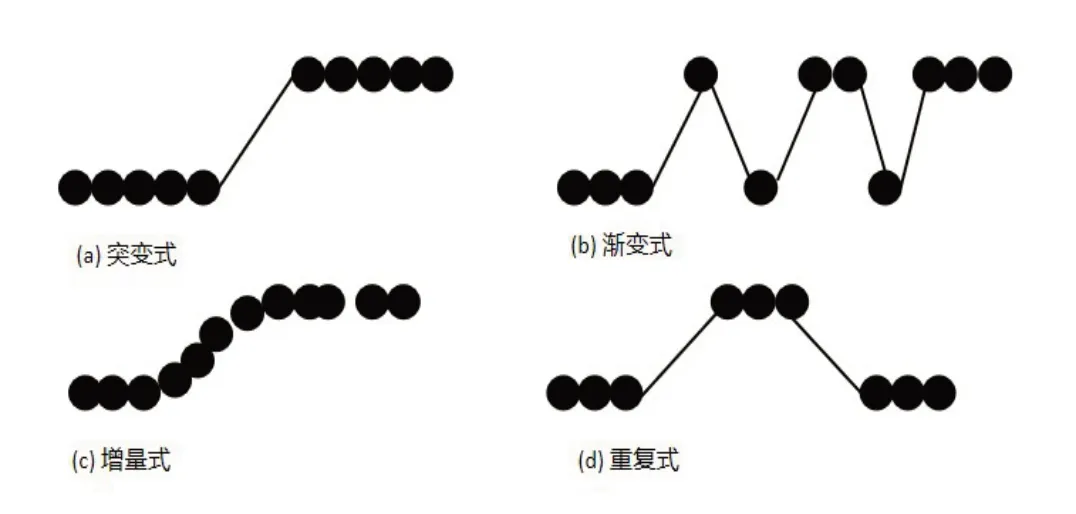
图2 概念漂移的4种类型
依据概念漂移形式不同,发现概念漂移检测可以从两个方面入手:(a)(d)型中对概念漂移检测强调的是发生的迅速,可以看到具体发生的时间点,相比之下,(b)(c)型漂移的研究强调发生的缓慢,不是立刻发生,是缓慢逐渐地发生.
2 概念漂移检测
2.1 漂移检测的一般框架
漂移检测是指通过改变时间间隔或者识别位置变化点来表征和量化概念漂移的技术和机制.漂移检测的一般过程包含4个阶段[8],如图3所示.

图3 漂移检测框架
第一阶段:数据检索(Data Retrieval).检索数据流中的数据块.由于单个数据实例携带的信息不足以推断总体分布.因此,如何将单个数据实例组织起来以形成有意义的模式或知识,在数据流的分析任务中是至关重要的.
第二阶段:数据建模(Data Modeling).在检索到的数据中,抽取其中蕴含数据信息的关键特征,即若出现概念漂移,则该特征对系统的影响最大.此阶段是可进行选择的,因为它主要取决于降维或者减少样本大小,用以实现在线速度和存储要求.
第三阶段:统计计算测试(Test Statistics Calculation).统计计算值,测量差异、距离估计以及漂移量.漂移的严重程度被表征和量化,并为假设检验给出了检验统计前提.漂移检测第三阶段被看作是最具挑战性的部分.因此,如何定义精准稳固的差异度量仍然是一个久悬不决的问题.
第四阶段:假设检验(Hypothesis Test).采用特定的假设检验评估在第三阶段观测到的改变是否有意义,以此证明在第三阶段提出的测试统计量统计边界可以用以确定漂移检测精度.如果第四阶段不存在,那么在第三阶段获得的测试统计量就没有任何意义.
2.2 概念漂移检测算法
依据概念漂移类型,处理概念漂移问题可从两个方面入手:主动检测方法如图4(a),对于急促的分布改变,需要精确地检测概念漂移是否发生以及发生的具体时间点,并且迅速作出判断,重点强调数据分布是否发生变化,主动检测方法主要有基于数据分布、基于窗口,以及假设检验的方法.被动适应方法也叫自适应方法如图4(b),不关注输入数据分布如何改变,不断更新分类器来适应数据分布的变化,主要有基于模型、决策树和集成的方法.

图4 主动检测方法与被动适应方法
2.3 主动检测方法
2.3.1 基于数据分布的概念漂移检测
在现实的环境中,数据并不是静止不变的,而是通过数据流的形式到达,数据是随着时间产生的,随着时间的变化它隐含的概率分布也可能会改变.基于数据分布概念漂移检测算法的核心是通过计算样本集之间概率分布的距离是否超出阈值来判断概念漂移是否发生.其主要是依据观察数据集自身统计信息来发现数据分布的变化,如图5所示,主要原理是根据检测的数据信息分布判断是否发生变化,如变化就发生概念漂移,修正或更新模型.这类算法使用距离函数或度量来表征和量化新数据和历史数据分布之间的差异.如果差异性在统计上有显著不同,系统将触发学习模型更新过程.
图5 基于数据分布的概念检测
Kifer提出了数据流中变化检测的第一个形式化处理方法[9],该算法是数据流变化检测表征和量化迈出的第一步.文献中假设数据点是由某种潜在概率分布按顺序独立生成的,不对生成的分布做任何假设.目标是检测这种分布何时发生改变,并量化和描述这种变化.文献将变化检测算法建立在一个双窗口范式之上.算法将某些“参考窗口”中的数据与当前窗口中的数据进行比较.这两个窗口都包含了固定数量的连续数据点.当前窗口随每个传入数据点向前滑动,每当检测到更改时,将更新参考窗口.并且引入一种新的距离度量,该度量是针对寻找分布变化而定制的,同时提供了小样本量强统计保证.该算法实际上是并行运行k个独立的算法,每个参数都包含在一个三维数组中(m1,i,m2,i,αi)算法需要一个函数d,它测量2个样本之间的差异,以及一组三元组{(m1,1,m2,2,α1),...,(m1,k,m2,k,αk)},m1,i和m2,i是窗口(Xi,Yi)的大小.窗口Xi是一个“界标”窗口,它包含在上次检测到更改后数据流的第一个m1,i点.每个窗口Yi都是一个滑动窗口,其中包含数据流中最新的m2,i项.在检测到变化后,它立即控制m2,i滑动到窗口Xi.每当数据流中出现新数据时,就会向前滑动窗口.在每次这样的更新后,检查d(Xi,Yi>αi).当距离大于αi时,报告一个更改,然后重复整个过程,Xi包含第一个m1,i及更改后的点.
Bu、Cesare等人提出了一种新的概率密度函数自由变化检测测试(LSDD-CDT)[10],该测试基于最小二乘密度差估计方法(LSDD),并在线操作多维输入.该测试不需要任何关于底层数据分布的假设,并且能够采用储层采样机制进行配置后立即运行.一旦应用程序设计器设置了误报率,将自动导出检测更改请求的阈值.
2.3.2 基于窗口的概念漂移检测算法
基于流式数据的特点,在概念漂移检测中也广泛采用窗口机制.随着数据到来,窗口不断滑动,就可以完成不断处理数据流中一个区间的数据,此区间包括数据流中最新数据的信息.窗口的主要功能有:(1)通过统计不同子窗口的数据信息用以检测概念是否发生变化;(2)决定哪些实例需要“遗忘”,以此来根据最新的训练实例更新统计信息;(3)当数据流中概念发生改变时,可以采用窗口中的数据信息,以及时对模型作出修正或更新.基于窗口机制的概念漂移检测方法大概可分为3种:界标窗口(Landmark Window)、滑动窗口(Sliding Window)和自适应窗口(Adaptive Window).
在界标窗口模型中,有2个端点,起始端点也称“界标”是固定不动的,随着数据流新实例的到来,终点不断向前滑动,如图6(a)所示.随着数据流的不断涌入窗口,使得窗口的规模不断增加,由此可见界标窗口内保存了较为完整的数据信息,每当一个新的界标到达时,清除前一个数据块中的所有实例,再以新的数据信息来训练新的模型,该模型可以很好地适应渐进式概念漂移.DDM、EDDM在第一阶段都是基于界标窗口机制实现的[11-12].
滑动窗口模型也含有起点和终点2个端点,与界标窗口模型有所不同,滑动窗口模型起点和终点2个端点同时不断向前移动,如图6(b)所示.滑动窗口不断地用新涌入的数据信息来替换已经过时的历史数据,采用“先进先出”的策略,用以不断地消除历史数据对模型的影响.滑动窗口采用“遗忘”机制.郭虎升等人提出的基于时序窗口的概念漂移类别检测(concept drift class detection based on time window,CD-TW)方法和上文中基于数据分布的算法都是基于滑动窗口机制的[13],它们均采用2个滑动窗口,在新的滑动数据窗口滑动时,历史时间窗口固定.因此,在使用滑动窗口训练数据建立模型时,选择合适的窗口大小是决定模型性能好坏的关键.若窗口设置太小,模型虽然可以很快地进行反应,但可能会在概念或数据分布缓慢变化时使得模型预测准确率降低,甚至可能会导致过拟合(Overfitting).但如若选择过大的窗口尺寸,虽然在一定程度上会提升在概念或数据分布缓慢变化时的预测准确率,但可能会由于同一窗口内同时包含的概念太多,从而使得无法迅速响应概念漂移.因此,在数据流不断发生改变的环境中,窗口的大小应该伴随时间和数据分布的改变而进行自适应改变,由此发展出自适应窗口的概念.
自适应窗口模型是随着数据流中概念或者数据分布发生变化时,不断改变窗口的大小,如图6(c)所示.代表算法是Bifet 提出的自适应滑动窗口算法(ADaptive sliding WINdow,ADWIN)[14],在初始化时,算法会首先确定一个大窗口W,通过比较2个子窗口W0、W1中的统计值即均值、方差等的差异是否大于某一阈值来判断是否发生概念漂移.当未发生概念漂移时,数据流的分布未发生变化,窗口大小也不发生改变;当发生概念漂移时,确定窗口内数据分布已经发生改变,窗口缩小至W0、W1中较小的窗口.

图6 基于窗口机制图
另一典型算法是等概率检测统计测试.等概率检测(STEPD)统计测试是用相等比例的统计检验,通过比较最近的时间窗口和总体时间窗口来检测错误率的变化[15].系统中有2个时间窗口,如图7所示.新窗口的大小必须由用户定义.通过公式(1)计算以下统计数据,比较其值与标准正态分布的百分比,得到观察到的显著性水平.

图7 等概率检测统计测试
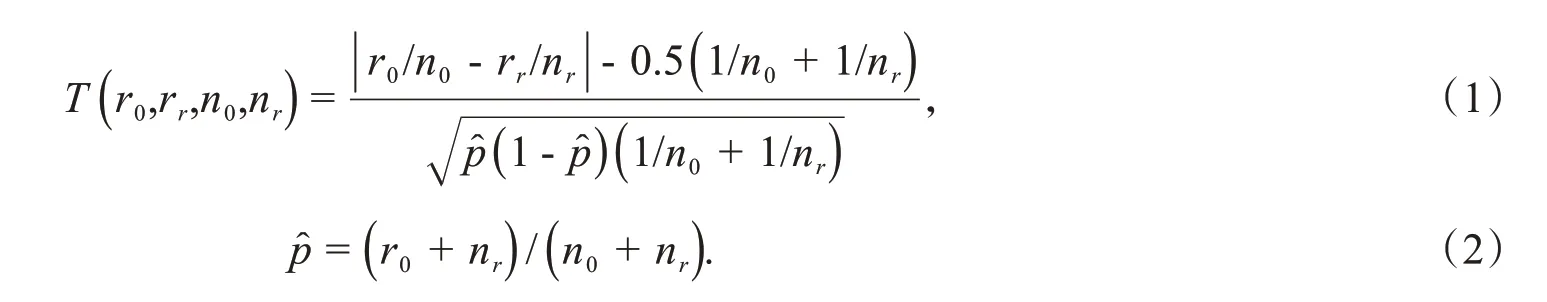
其中,r0表示除了最近的W窗口之外的数据在所有的例子中正确分类的数量,n0表示总体时间窗口,rr是W=nr示例中的正确分类数,如果p,小于显著性水平,即概念漂移已经被发现.STEPD算法可以很容易地计算出警告阈值和漂移阈值.Tin Mar Myint等人[16]也提出了一种基于自适应加窗方法的精度更新集成算法(A-AUE2),该方法使用Brier-Skill分数作为突变和渐变检测器.此外,采用基于K-最近邻(KNN)的噪声滤波方法来消除每个自适应窗口中的噪声样本,以提高集成学习方法的有效性.
2.3.3 基于假设检验的概念漂移检测算法
除了以上方法外,近年来也出现了一种新的漂移检测方法——多假设检验漂移检测方法,多假设检验漂移检测方法的新颖之处在于它们使用多个假设检验以不同的方式检测概念漂移.这类算法可分为并行多重假设检验和分层多假设检验.
(1)并行多重假设检验
Just-In-Time 自适应分类器(JIT)是第一个设置多个漂移检测假设的算法[17].JIT 的核心思想是扩展CUSUM图表,即基于计算智能的CUSUM测试(CI-CUSUM),用来检测学习系统感兴趣特征的平均变化.
另一种并行多假设漂移检测算法是基于信息值和Jaccard相似性(IV-Jac)的三层漂移检测[18].IV-Jac的目标是分别解决标签漂移第一层、特征空间漂移第二层和决策边界漂移第三层.算法从可用数据中提取权重(WoE)和信息值(IV),然后通过测量特征值对标签的贡献来检测从中提取的WoE和IV之间是否存在显著变化.
(2)分层多假设检验
分层漂移检测是一个新兴的漂移检测类别,具有多个验证模式.该类别中的算法通常使用现有的方法,称为检测层用于漂移检测,验证层应用额外的假设检验,以分层的方式对第二次检测到的漂移进行验证.
层次变化检测测试(HCDTs)[19]第一次尝试使用层次结构来解决概念漂移问题.该检测层可以是任何现有的漂移延迟率较低、计算负担较低的漂移检测方法.验证层将根据检测层返回的结果来激活和停用验证层.文献给出了设计验证层的2种策略:1)通过最大化似然来估计测试统计量的分布;2)适应现有的假设检验方案,如KS检验或Cramer-VonMises检验.
分层线性四速率Hierarchical Linear Four Rates(HLFR)是最近提出的另一种分层漂移检测算法[20].将漂移检测算法LFR(Linear Four Rates)作为检测层,一旦检测层确认了漂移,验证层将被触发.HLFR的验证层只是有序序列测试分割上的0-1损失函数,表示为E.如果估计的0-1损失函数超过预定义的阈值,验证层将确认漂移并向学习系统报告,以触发模型升级过程.
2.4 被动适应方法
2.4.1 基于模型的概念漂移检测
基于模型的概念检测主要是根据模型输出特征的改变来量化漂移,其主要原理是不关注数据,直接更新模型,如图8所示,主要代表是基于分类错误率的概念漂移检测算法.

图8 基于模型的概念漂移检测
基于分类错误率,如若概念漂移发生,数据分布会发生变化,使得模型性能降低.因此模型性能的下降成为衡量概念漂移发生的关键标志.基于分类错误率的漂移检测算法是概念漂移检测中最主要的算法类别.这些算法的关键是观察基本分类器在线错误率的变化.如果可以证明错误率的增加或减少具有统计学意义,则将触发升级过程或者报告漂移.
漂移检测法Drift Detection Method(DDM)是第一个定义概念漂移检测警告级别和漂移级别的算法.当一个新的数据实例可以用来评估时,DDM检测界标时间窗口内的总体在线错误率是否显著增加.DDM设置2个错误率阀值,一个是warning,另一个是drift.当样本数据中输入第w个数据时,如果观察到错误率的变化达到了warning值时,说明样本概率分布有改变的预兆,DDM开始建立一个新的学习器,同时使用旧的学习器进行预测,如图9所示.如果继续输入的数据没有降低错误率,在第d个数据输入时错误率达到了drift值,则样本概率分布发生确定变化,旧学习器将被新学习器取代,以完成进一步的预测任务.为了获得在线错误率,DDM需要一个分类器来进行预测.这个过程将训练数据转换为学习模型,该模型被认为是第二阶段(数据建模).第三阶段的测试统计构成在线错误率.第四阶段假设检验估计在线错误率的分布.虽然在突然变化的类型中,DDM算法有很好的表现,但是当遇到变得非常缓慢的渐变时,算法在检测概念漂移上就变得有困难.在这种情况下,样本会被存储得非常久,漂移将会花太多的时间来触发,导致样本存储空间会超出界限.
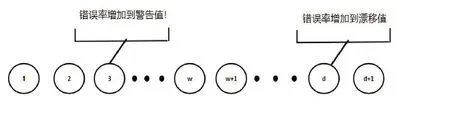
图9 DDM算法
Baena-Garc M 等人在DDM 基础上提出了早期漂移检测方法(EDDM),EDDM(Early Drift detection method)依据DDM算法进行优化提升,基本思想是考虑2个错误分类的变化率,而不只是考虑错误率.该方法用于提升缓慢渐变概念漂移条件下的检测精度,同时在突然漂移的条件下也有很好的表现.当算法学习时,它会提高其预测结果精度,而且2个错误之间的距离会变大.算法计算2个错误的概率和其标准差之间的距离.在达到最大值时,算法会存储和的值.因此,值就表示错误距离分布最大值的点.在到达该点时,就会建立一个新的模型,新的模型能够很好地估计数据集中当前概念的分布.文献中定义2个阈值:(1)warning.当值达到该warning时,训练样本被预先存储到内存中,以防止样本概率分布可能发生变化,然后报告一个警告.(2)drift:当达到这个drift时,就认为真正的概念漂移已经发生了,原来的模型就会被一个新的模型取代,新模型是用之前在触发warning时存储的样本重新训练出来的,和的值也会被重置.当实际值与最大值之间接近度上升超过warning时,存储的样本会被移出,检测方法会回归正常.EDDM方法在面对缓慢的渐变的概念漂移情况非常有效.但对于噪声很大的情况中,该算法表现却不是很好.
2.4.2 基于决策树的概念漂移检测方法
Hulten 等人提出了概念自适应的快速决策树CVFDT(Concept adaptive VFDT)算法[21].该算法在基于VFDT算法的基础上做了一个提升,算法集成了固定大小的滑动窗口,使其能够检测流式数据中概念漂移的问题,并且具有较高的分类精度和迅速响应的优点.算法的核心思想是在VFDT算法上加入滑动窗口,不断更新决策树.假定W为窗口的大小,在任意时间点n,滑动窗口的查询范围表示为{max(0,n-w+1)}.以当前流入数据建立临时子树,然后再用新流入的数据不断改进建好的决策树.因此CVFDT处理概念漂移问题效果很好.但在检测旧的概念时,CVFDT算法的效率较低.其次,CVFDT算法也不能主动检测概念漂移的发生.因此在此基础上CVFDT 出现了一系列的延伸算法.Li 等人提出了概念漂移随机决策树(CDRDT)算法[22],该算法使用随机决策树的集成模型来区别不同类型的概念漂移与噪声数据流,使用可以变化的小数据块来逐步生成随机决策树,同时还引入了Hoffding 不等式和统计控制原理用以检测不同类型的概念漂移和噪声数据流,实验验证了CDRDT算法可高效地检测来自噪音数据流中的概念漂移.针对非正态分布类型数据流特性,张剑等人提出了基于Hoeffding不等式的自适应分级滑动窗口决策树(AGSW-DT)算法[23],该算法检测概念漂移依据节点信息增益率,不断调整各个窗口大小,以此完成对不同类型概念漂移的自适应分类和决策树更新.
2.4.3 基于集成的概念漂移检测算法
在概念漂移检测中,单个的分类器已经不能够适用于复杂可变的流式数据,将多个基分类器组合起来形成集成分类器比单分类器算法效果更好.因此出现了一种新的集成方法来处理概念漂移问题.集成算法根据其处理数据流的输入形式可以分为2大类:基于数据块的集成方式和在线集成方式.
(1)基于数据块的集成概念漂移检测
基于数据块的集成分类方式是不断地在最新数据块上训练并产生称为候选分类器的基分类器,添加到集成分类器中用以代替性能最差的分类器,最终集成的预测结果采用加权投票等方式,以此应对流式数据分布变化的特性.
W Nick Street等人提出利用集成方法解决概念漂移问题的SEA算法[24],该算法利用丰富的数据,在连续的数据块上建立了独立的分类器,使用启发式替换策略将这些分类器组合成一个固定大小的集成.该算法是一个大规模的快速算法,它的分类是建立在所有数据上的单一决策树,需要具有恒定的内存,并迅速检测到概念漂移.该算法中,相对较小的数据子集构建成单个分类器,顺序按块读取.组件分类器被组合成一个固定大小的集合,若集成满了,只有当新的分类器满足一些标准的时候,它们才能根据其估计的能力来提高集成的性能.因此,现有的分类器必须被删除,来保持集成的恒定大小.它提供了一个自然的机制来估计模型在任何给定阶段的泛化精度.该方法易于实现,而且独立于底层分类器.
Haixun Wan 等人提出AWE(Accuracy Weighted Ensemble)算法对SEA 进行改进[25],基分类器被赋予权重,根据基分类器对当前数据块的准确率进行加权,权值大的代替权值小的基分类器进行模型更新,最后各弱分类器的预测结果通过加权投票的方式进行整合.首先,计算基分类器Ck在最新数据块bi上的误差率:


其中,p(y)表示类别y的后验概率.最后,计算权值:

式中,ω(Ck)表示权值.数据块大小对性能影响很大,并且该算法也不能很好地适应突变式概念漂移.
在AWE算法弱分类器权重计算方式的基础上,Dariusz Brzezi nski和JerzyStefanowski提出了AUE(Accuracy Updated Ensemble)算法[26],与AWE 算法不同的是基分类器权重的计算方式不同.AUE 算法并不删除旧基分类器,而是每次从全部基分类器中选出最好的k个组成集成分类器.Dariusz Brzezinski 和Jerzy Stefanowski在AUE的基础上又提出了AUE2集成算法[27],使用VFDT作为基分类器,在到达新数据块后,首先AUE2基分类器的权重被更新,其次用新基分类器替换准确率最低的旧基分类器,最终将所有旧基分类器进行增量训练.
(2)基于在线集成的概念漂移检测
基于在线集成的概念漂移检测是在t时刻根据已获得的实例序列建立分类器,并对新到的实例进行测试,按照分类结果来修正已有分类器,当分类器完成更新后,对下一个接收到的实例实施分类.如此循环不断进行下去.与基于数据块的集成概念漂移检测方法相比,在线集成每次只检测单个实例.因此这种方式能及时应对突变式概念漂移,比创建一个新的模型付出的代价要小得多.
WMA算法是最先被提出的在线集成分类算法[28],它组合子分类器的预测值,在子分类器出现错误预测时,该子分类器的权重就被更新.最终,依据组件权重对样本的类型投票表决.另一个应用较为广泛的在线集成分类算法是Online Bagging[29],该算法是基于传统的集成方法Bagging 算法的一个延展.与Bagging 算法采用有放回随机抽样获得训练子集有所不同,它采用增量式分类器作为组件,并通过修改输入样本集的分布使得各个子分类器产生区别,从而适应概念漂移.
另一种是康月波提出的基于漂移检测的在线集成分类算法[30].算法使用Hoeffding Adaptive Tree构建基分类器,每个节点上多了一棵训练好的替代子树.DDM检测器被嵌入到集成模型中,DDM对新的数据块进行漂移检测.如果检测出概念漂移,就在该样本处将数据块断开;如果没有检测出概念漂移,就只用最新数据块更新原有基分类器的权重,新的模型不再被构建,有效地降低了时间成本.
3 总结与展望
本文描述了概念漂移的定义、来源、类型,概念漂移检测的一般框架,从主动检测和被动适应两方面分别介绍了基于不同类型的概念漂移检测方法,分析了不同研究方法的适用场景以及优缺点.随着大数据时代到来,人工智能飞速发展,从现有研究可以看出,概念漂移问题已经引起了学术界的广泛关注,也有了代表性的研究成果,但仍然存在如下几个方面的研究挑战:
1)现在概念漂移检测算法大部分都是以通过检测分类器性能或数据流的特征分布来确定数据流的稳定性,当判断发生概念漂移时触发概念漂移处理机制来适应新环境的主动检测方法为主,主动检测方法通常具有更好的概念漂移适应能力,但也往往具有更高的时间和空间复杂度.因此通过不断对数据或者模型进行更新以适应新环境的被动适应方法还有待进一步研究.
2)流数据不同于静态数据,无法实现完整的持续存储.因此数据标记将是影响流数据分类的突出问题之一.概念漂移问题研究以来,算法都是以检测单标签为主,对于多标签概念漂移问题还不能很好地适应,在此方面还需要进一步研究以适应多个标签的概念漂移问题.
3)近年来的概念漂移算法大多都只针对突变式概念漂移或是渐变式概念漂移问题,现有概念漂移算法不能很好地适应多种类型的概念漂移,如何能同时检测出多种类型的概念漂移也是一个值得思考的问题.
