基于不同骨架UNet++网络的建筑物提取*
2022-07-06古煜民阎福礼
古煜民,阎福礼
(1 中国科学院空天信息创新研究院, 北京 100094; 2 中国科学院大学资源与环境学院, 北京 100190)
建筑物是城市数字化、城市变化检测和快速制图的重要目标,是城市规划、防灾减灾应用的核心承灾体,研究如何利用高新技术精确识别、快速提取和高频次监测建筑物变化信息,不仅具有重要的科学意义,也具有重要的应用价值[1]。随着遥感传感器技术的飞速发展,越来越多的航空、航天高分辨率数据不断涌现。如美国Worldview数据达到0.3 m,中国GF-2号数据达到1 m,中国科学院遥感飞机的ADS-80达到0.5 m,无人机航拍数据可达到0.05 m。高分辨率影像能够精细刻画包括建筑物在内的地物目标的光谱、几何、纹理特征,为高精度建筑物提取提供了可能[2]。但是高分辨率遥感数据的建筑物提取,存在存储数据量大、人工解译工作量大,传统的建筑物提取算法误差大的特点,基于遥感手段的快速、准确、高频次地建筑物自动提取逐渐成为研究的热点。
传统的高分影像建筑物自动提取主要分为4大类:一是多尺度分割提取方法[3-5],最常见的多尺度分割算法为eCongnition的分形网络演化算法(fractal net evolution approach,FNEA)算法[6];二是边缘和焦点检测与匹配的提取方法[7-8],依据影像中不同区域边界灰度级变化,从而检测建筑物边缘实现分割;三是区域分割提取方法[9],有区域生长法、四叉树法和分水岭法等;四是基于数学工具、新理论及多种方法结合的提取方法[10-11]。传统方法在建立模型时往往以人为主观性为主,不能自动地提取建筑物深层特性。
随着计算机图像技术发展,能够主动提取图像深层特征的深度神经网络出现了。比较有代表的深度卷积神经网络有VGG_Net[12],GoogLeNet[13]和ResNet[14]等。随着基于卷积神经网络的目标识别技术在传统图像领域的发展,使得深度学习开始小规模在遥感领域进行应用。Mnih[15]将深度卷积神经网络应用于建筑物目标自动提取,并引入条件随机场对分类结果后期处理,总精度达76.38%;Saito等[16]在深度卷积神经网络的基础上,将分类器由softmax替换为通道抑制多分类器(channel-wise inhibited softmax),提取总精度为80.87%。卷积计算的平滑效应造成了有用信息的损失,导致对于建筑物边缘的识别精度较低。2015年全卷积神经网络(fully convolutional networks,FCN)[17]发布,FCN是第一个端对端的图像语义分割网络,此后卷积神经网络模型开始大规模在遥感分类领域应用。刘文涛等[18]基于FCN网络进行微调,对建筑物屋顶进行提取,总精度达到92.39%。刘浩等[19]基于UNet网络,添加特征激活层,对建筑物进行提取,总精度达到94.72%。但由于模型结构较为基础,对于复杂建筑物的识别能力受到限制,仍具有可提升的空间。
遥感建筑物提取应用涉及大场景的真实遥感图像,包含大量类似建筑物的复杂场景,如花坛、大棚、水泥地面。本文针对高分辨率影像建筑物自动提取,引入深度学习特征功能模块和传统遥感应用技术验证环节,形成多种不同骨架模块、UNet++网络和真实性检验的建筑物遥感提取功能模块嵌合的深度学习业务化应用技术体系,在UNet++网络的基础上,将经典的卷积神经网络的VGG系列[12]、ResNet系列[14]和InceptionNet系列[13,20-22]作为骨架对其进行改造,分别在模型深度和广度不同层面对模型进行强化,提升性能,使模型可以更好地学习建筑物轮廓深度信息。加入批量归一化层(batch normalization-layer,BN层)[22],设置DropOut系数[23],使之能取得更好的提取效果,同时针对二分类和数据的特性选择Dice系数[24]结合cross-entropy作为损失函数,平衡训练数据。通过真实性检验验证算法的有效性、适用性,展示完整的遥感应用技术链条。与传统的非全卷积网络模型和全卷积网络模型相比,本文方法在建筑物提取精度上拥有显著的优势。
1 实验方法
本节主要阐述建筑物提取应用的基本流程。首先介绍实验所采用的基础实验原理,然后描述相关基础网络特性及其如何发挥网络优势。为了适应二分类应用任务训练,损失函数采用Dice系数和交叉熵结合的损失函数,并结合传统图像分割和遥感分类相关精度评价表。总体应用流程图以InceptionV3-UNet++模型为例,如图1所示。
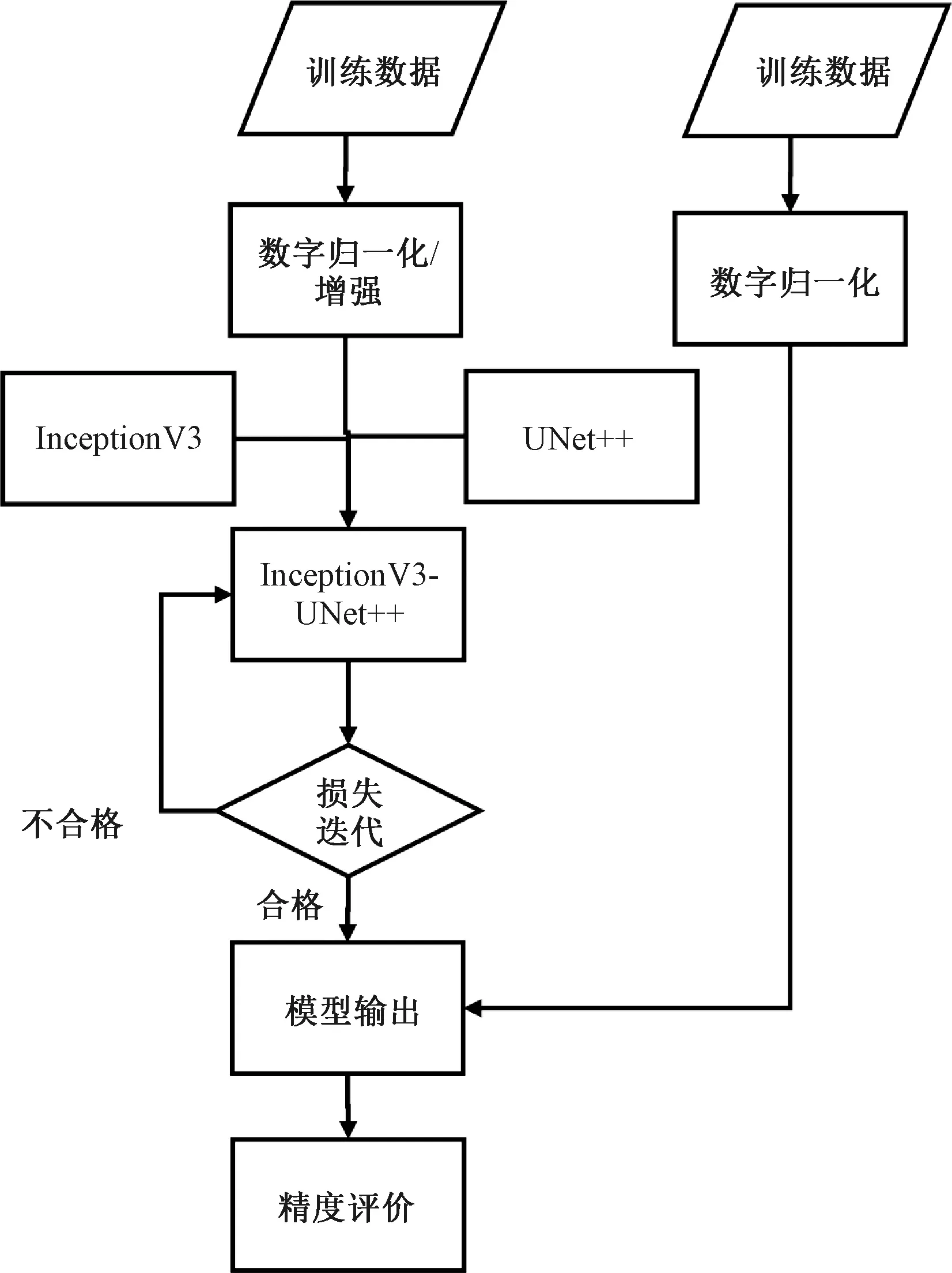
图1 建筑物提取流程图
1.1 不同骨架UNet++模型
UNet模型[25]以编码器-解码器(encoder-decoder)[26]结构为基础,基本结构如图2(a)所示。UNet++模型[27]在UNet模型的基础上,结合DenseNet[28]和深度监督[29]原理,其主要结构如图2(b)所示。和UNet相比,它主要在残差链接部分增加了一些解码器单元并采用残差链接的方法连接起来。其中,每一个单元的计算结构大致如下所示:
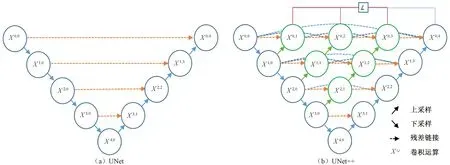
图2 UNet/UNet++网络结构[27]
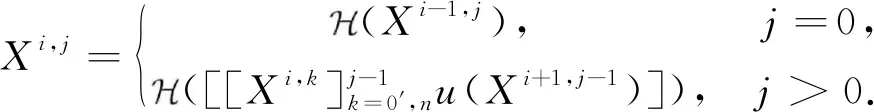
(1)
基础的UNet++模型简洁有效地解决了参数回传的问题,但直接将其应用于建筑物提取任务,精度较低。为了提高它的分类精度,本研究选择将不同的深度学习模型作为骨架(backbone)来改造UNet++基础模型。分别选用了VGG16,Resnet50和InceptionV3,对UNet和UNet++进行改造。
ResNet模型[14]结构可以加速神经网络训练,其主要思想是在网络中增加直连通道,即Highway Network的思想。此前的网络结构是线性输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出,允许原始输入信息直接传到后面的层中。残差网络的具体结构如图3所示。
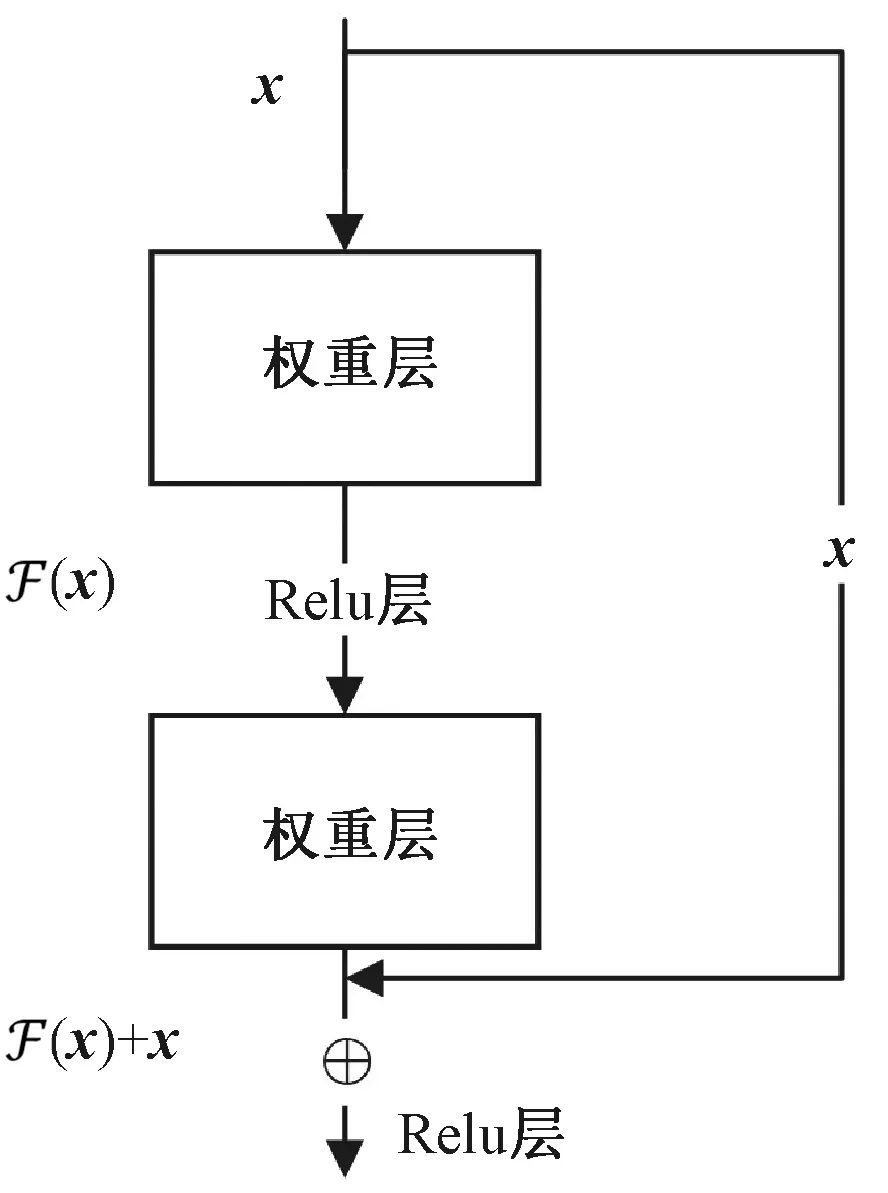
图3 残差结构[14]
由两个子单元组成,它的表达式如下:
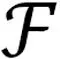
(2)
(3)
式中:σ代表ReLU层,然后通过短链接和第2个ReLU层得到输出y。
Inception网络模块中,除常见的3×3和5×5卷积网络之外,引入额外的1×1卷积层,以此限制输入信道的数量,信道数的减少可以有效地降低计算成本,同时不改变计算的结果。最终经过多个版本的迭代,Inception网络模型发展到了V4版本,本文选取V3版本对UNet++网络进行改造。其中3个子模块结构分别如图4(a)、4(b)、4(c)所示。
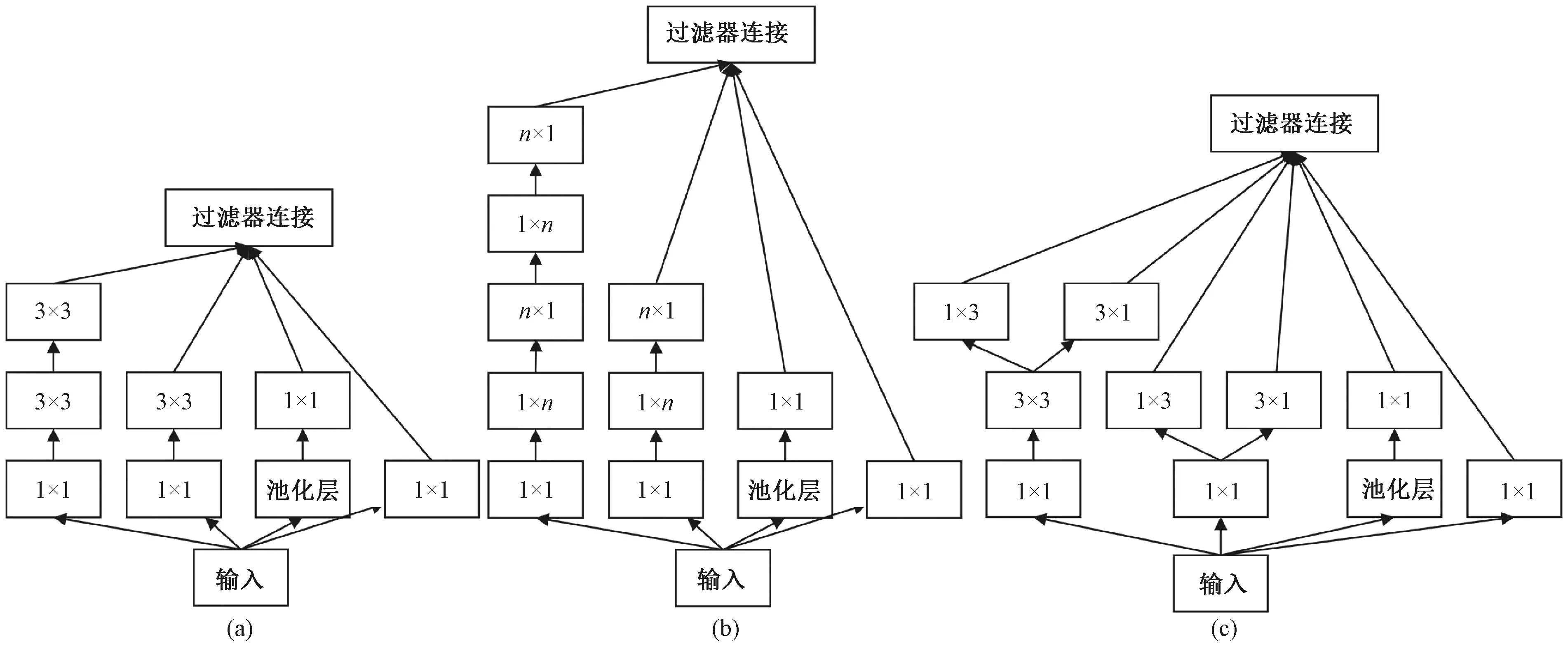
图4 3种Inception结构[13]
本文将3种基础网络的编码器部分按照表1分割为5个部分,分别将Conv1~5作为跳跃链接层,替换原始UNet++模型编码器中的各个卷积模块,然后在各模块中加入Dropout层和BN层进一步提升收敛速度和鲁棒性。基于InceptionV3的UNet/UNet++模型在模型深度增加的前提下,计算量增加并不明显,可以有效提高模型的运行和计算效率。

表1 VGG16、ResNet50、InceptionV3模型结构表(编码器)
1.2 Dice系数与交叉熵混合损失函数
Dice系数是一种集合相似度函数,常用于计算样本的相似度,其表达式如下
(4)
其中:∣X∩Y∣为两集之间的交集,∣X∣和∣Y∣分别表示X和Y的元素个数。将Dice系数作为损失函数应用于二分类场景,使得两种类别的相似度最小,因此用Dice系数取相反数就可以得到Dice损失函数。
为了保留交叉熵收敛效能,本文将二元交叉熵(binary cross-entropy)和Dice loss两种损失函数进行叠加组合,按式(4)的损失值分配到每一个层次的输出,以此进行反向传播运算。
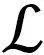
(5)
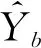
1.3 精度评价体系
在测试模型的性能时,考虑到传统图像分割领域和遥感分类领域精度评价标准差异,使用每个类别的生产者精度(producer accuracy)、用户精度(user accuracy)、临界成功指数(critical success index,CSI)、F1分数以及Kappa系数为评价标准。其中生产者精度、用户精度和Kappa系数是遥感分类中最为常用的精度评价指标,CSI常见于气象学科的分类中,F1分数能综合体现生产精度和用户精度分类效果,是计算机图像领域中最为常用的分类指标。这几个指标的表达式分别表示如下:
(6)
(7)
(8)
(9)
(10)
式中:Users表示用户精度,Producers表示生产者精度;TP表示预测正确实际也正确的像元数量,FP表示预测为正确像元但实际是错误像元的数量,TN表示预测为错误实际也分类错误的像元数量,FN表示预测为错误但实际为正确像元的数量;po是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度;pe是所有类别分别对应的实际与预测数量的乘积的总和,除以样本总数的平方。
2 实验数据及处理
2.1 数据源介绍
马萨诸塞州建筑物数据集(Mnih Massachusetts building dataset)由马萨诸塞州波士顿地区的151张航拍图像组成,空间分辨率为1 m,每幅图像的大小为1 500像素×1 500像素,面积为2.25 km2。因此,整个数据集大约覆盖340 km2。整个数据集由Mnih创建,他通过栅格化OpenStreetMap项目获得的建筑轮廓线来获取精确的建筑物轮廓。此数据仅保留平均遗漏噪声水平小于或等于5%的区域。波士顿地区为OpenStreetMap项目贡献了整个城市的建筑分布数据,所以可以收集到大量高质量的建筑物提取数据。我们将数据随机分为137个图像的训练集,10个图像的测试集和4个图像的验证集。航空影像数据和标签数据如图5(a)、5(b)所示。标签数据中建筑物轮廓以房屋屋顶为标准,并将其在标签数据中标记为1,其余像素都标记为0。为了充分利用GPU显存,同时确保实验进行,本研究采用滑动裁剪将影像裁剪为512像素×512像素大小,每张原始影像被裁剪为25张小影像,每张影像的重叠度为50%。
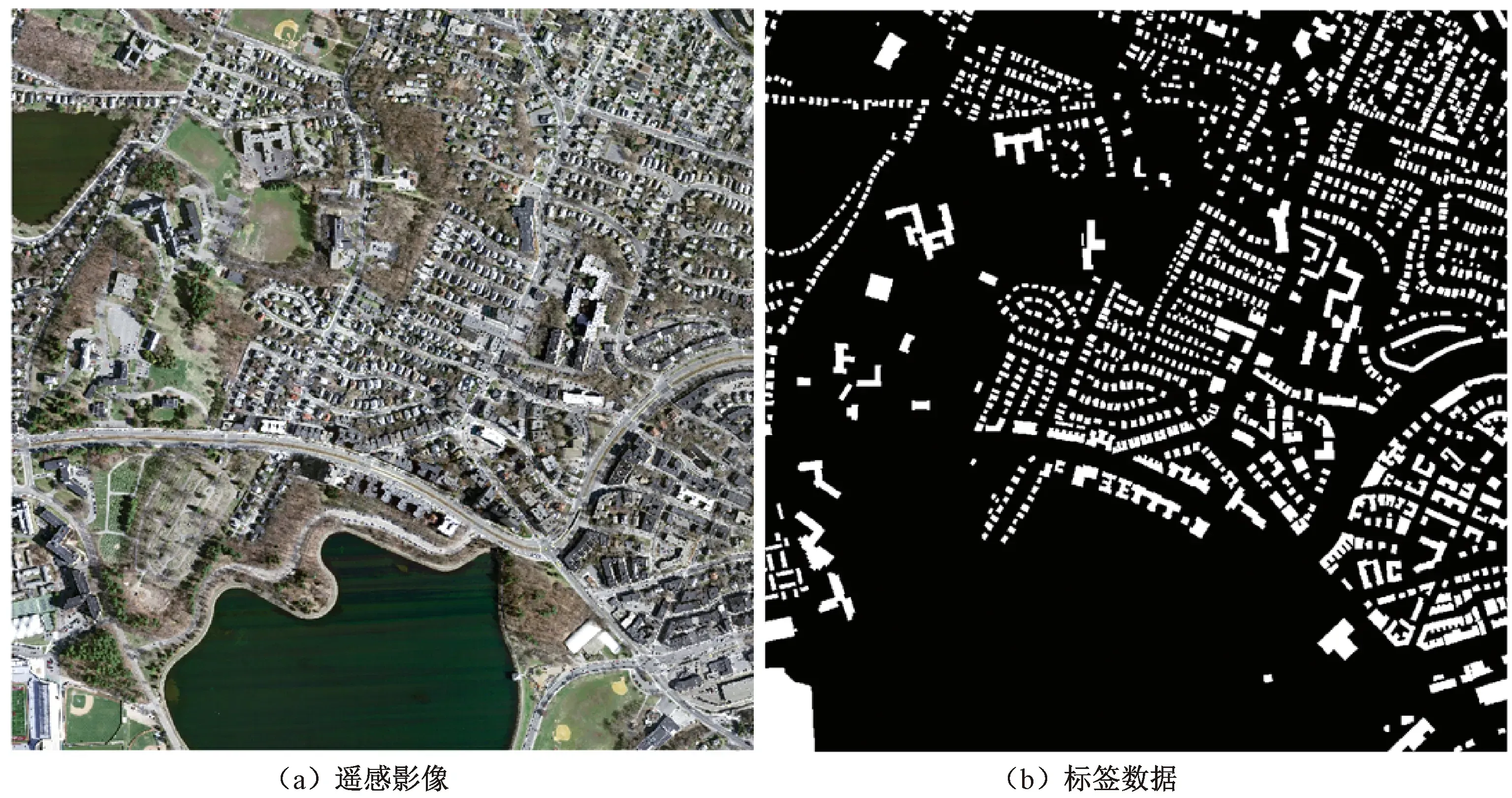
图5 马萨诸塞州建筑物数据集示例
2.2 数据预处理与增强
我们在获取到原始的深度学习数据集后,不会马上将数据投入训练,往往还要经过数据的预处理和增强处理。数据预处理和增强主要为了扩充数据集样本数量,一般而言,数据量越大,模型能够更好地学习数据集的特性,提高泛化能力,同时增加一定的噪声数据,保障更好的鲁棒性能。数据预处理首先对基础的数据集进行切割,得到模型适用的输入尺寸大小的新数据集,在新数据集的基础上对数据进行增强。数据增强常用的方法有:翻转、旋转、缩放、裁切、平移、添加噪声等。我们对马萨诸塞州建筑物数据集进行预处理得到3 425个训练样本,然后对训练样本进行增强,得到50 000个训练样本组成的训练集用于模型的训练。
2.3 模型实现与训练
采用Keras+Tensorflow作为学习框架。Tensorflow是Google Brain推出的基于数据流编程的深度学习框架,被广泛应用于学术和工业界,具有很高的可操作性。Keras是一种以Tensorflow为后端的高级神经网络API,采用python开发。
卷积神经网络在训练过程中会不断迭代自身的网络参数,但是为了使模型迭代更快,得到更好的训练效果,常常需要人为设置一些超参数。这里主要设置的参数有批处理的大小(batch size)、损失函数的优化器、迭代轮数(epoch)、初始学习率、初始权重以及Dropout层的比例等。经过多次的实验和经验,同时考虑服务器处理能力,设置batch size大小为8,优化器为自适应学习率Adam函数[30],初始学习率为0.01,权重衰减参数为10-7,epoch大小为100次并辅以早停设置,采用ImageNet数据集上训练好的权重参数作为初始权重。Dropout层比例设置为0.5。本实验采用2块英伟达Tesla P100的Linux服务器进行训练。
3 结果与讨论
3.1 Mnih建筑物数据集提取应用
除了对本文涉及的网络进行精度对比分析之外,还对Mnih[15],Saito等[16]以及刘文涛等[18]提出的方法对同实验数据的实验结果进行对比,这里主要参考了他们的总精度。本文实验了基于VGG16、ResNet50、InceptionV3为骨架的UNet++和UNet网络,同时也对基础的UNet++和UNet网络进行了实验,主要评价指标有生产者精度、用户精度、CSI、F1分数、Kappa系数以及总精度,结果如表2所示。
表2 不同模型精度分析表
Mnih和Satio主要采用非全卷积网络,在解码器部分采用全连接层和最后的分类器结构,他们的总精度相较于效果最差的标准的UNet而言分别低了10.88%和6.39%,这说明全卷积网络结构在高分辨率影像建筑物提取应用上相较于普通的卷积网络而言有着非常大的优势。与标准的UNet和UNet++网络对比,UNet++网络各项精度评价指标都要优于UNet网络,这说明在一定程度上,UNet++网络结构在高分辨率建筑物提取任务上要优于UNet网络。同时由表2可得,两种标准网络提取结果在生产者精度上都表现较差,用户精度表现稍好,但其他精度评价指标上表现较差。再分析本文提出的采用不同骨架改造的UNet/UNet++网络,从表2和图6可以发现通过改造后的网络分类结果要明显好于标准模型,和同为全卷积网络的刘文涛等[18]和刘浩等[19]提出的网络模型相比总精度也有一定优势。选取5幅提取结果进行分析,其中图6(1)列以小型建筑物独立别墅分布为主,图6(2)、6(3)列为各种大小建筑混合分布,图6(4)列以中大型建筑分布为主,图6(3)、6(4)列存在一定的高层建筑,形成了较大的建筑物阴影。
首先比较以VGG16为骨架的两种网络,从精度评价参数上看,VGG16-UNet++网络的生产者精度要好于VGG16-UNet,而用户精度要略差,但是其他评价指标都要更优,最终总精度也略好。对图6提取结果进行分析可以发现,对于中大型建筑物,如图6.ef(3)和6.ef(4)列中,VGG16-UNet的正确率要高于VGG16-UNet++,VGG16-UNet++存在一定漏检和误检率,而对于独栋建筑小型建筑,从图6.ef(1)和6.ef(2)列中可以发现VGG16-UNet++的精度要更高,同时对于高层建筑造成的阴影,如图6.ef(3)和6.ef(4)列中,VGG16-UNet++的误检率也要更低。VGG16骨架模型相较于标准模型改动不大,主要区别体现在BN层和DropOut层的引入,由此可以发现,BN层和DropOut层可以明显提高模型的分类效果。
两种以ResNet50为骨架的模型,从评价指标上来看,ResNet50-UNet++模型的各项指数都要明显优于ResNet50-UNet模型,横向与基于VGG16的模型进行比较,可以发现基于ResNet50的两种模型整体也更加优秀。说明一定程度上提升网络模型的深度可以明显提升模型的性能。但是不可忽视的是,随着模型深度的提升,计算量也随之增大。具体分析提取结果,从图6.gh(4)列中可以发现,在大型建筑物检测上,ResNet50-UNet++模型的误检率和漏检率都要优于ResNet50-UNet模型,对于小型建筑物分类效果,两种模型相差不大,从图6.gh(3)列发现,对于多阴影的高层建筑物,ResNet50-UNet++模型受到的干扰较小,但对于边缘的大型建筑仍存在一定的漏检现象。
两种基于InceptionV3的网络,通过与VGG16和ResNet50两种模型进行对比分析可以发现,通过增加网络模型的广度,也可以提升模型的分类效率。ResNet50-UNet和InceptionV3-UNet两者性能相近,InceptionV3-UNet模型的生产者精度、CSI、F1分数都略差于ResNet-UNet模型,用户精度和总精度则要略有优势。而Inception-UNet++模型的各项参数则要优于ResNet-UNet++模型。具体分析分类结果,对于大型建筑而言,从图6.ij(3)列所示,InceptionV3-UNet++虽然还存在一定的漏检率,但误检率已明显好于其他模型,对于阴影与建筑物本体的区分度也表现更优秀。由图6.ij(1)列,小型建筑上Inception-UNet++也有一定的优势。

(a)原始影像(b)标签数据(c)Standard-UNet提取结果(d)Standard-UNet++提取结果(e)VGG16-UNet提取结果(f)VGG16-UNet++提取结果(g)ResNet50-UNet提取结果(h)ResNet50-UNet++提取结果(i)InceptionV3-UNet提取结果(j)InceptionV3-UNet++提取结果绿色表示正确分类的建筑物;红色表示误检的建筑物;蓝色表示漏检的建筑物
通过对各模型提取结果进行分析,从图6可以看出,对标准的UNet++模型的骨架进行改造,使得各个模型相较于标准网络和非全卷积网络可以取得更好的分类效果。随着影像分辨率的提高,建筑物在影像上表现的形式越来越具体,越来越复杂,要使得模型可以充分学习建筑物在高分辨率影像中的各种特性,需要的网络模型的复杂程度也越高。通过引入BN层和DropOut层,一定程度增加模型的深度和广度,都可以更好地让模型学习到更具表达能力的深层特征,以此提高模型的学习能力。本文验证了UNet++为代表的图像分割网络模型,在经过不同骨架的改造后,可以适用于复杂的拥有大量现存训练标注样本集的建筑物提取任务。
3.2 WHU建筑物数据集迁移学习
为了进一步验证模型在其他数据集的适用性,验证其鲁棒性能,本文选用InceptionV3-UNet++在Mnih数据集上训练得到的模型,在WHU(卫星影像Ⅰ)数据集[31]上进行迁移学习,WHU数据集包含了从0.3~2.5空间分辨率的ZY-3、IKONOS和WorldView系列等多种卫星影像数据制成的建筑物轮廓数据集,影像涵盖全球十多个不同城市,非常适合测试建筑物提取算法的鲁棒性。该模型对WHU数据集的验证集提取结果如表3所示,提取结果示例如图7所示。

表3 WHU验证集提取结果精度分析表

图7 WHU数据集提取结果可视化示例
经过简单的迁移学习,InceptionV3-UNet++模型取得了较好的建筑物提取效果,总精度达到94.34%,Kappa系数达到0.843 9,这证明该模型具有良好的鲁棒性能。具体分析提取结果示例可以发现,对于小型建筑物提取效果较好,建筑物边界较为清晰,但由于底层建筑物可能存在部分树木遮挡,造成了一定的漏检,同时误检部分主要为靠近建筑物的规则裸露空地。
4 总结
本文针对高空间分辨率遥感影像的建筑物提取问题,以3种不同传统卷积神经网络VGG16、ResNet50和InceptionV3为骨架对标准UNet++进行改造,得到多种强化网络,以马萨诸塞州建筑物数据集进行训练,然后进行对比分析,得出以下结论:
1)比较VGG16-UNet++模型与标准UNet/UNet++模型不同的网络特性和实验结果发现,通过增加BN层和DropOut层等一系列参数层和操作可以有效提升建筑物提取的精度,并一定程度提升模型的收敛效率,总提取精度提升6.17%和5.07%。
2)比较ResNet50-UNet++模型与标准UNet/UNet++模型不同的网络特性和实验结果发现,在计算机能力允许的情况下,适当增加模型深度,虽然模型复杂度提高,计算量提升,但可以有效地提升模型提取建筑物的效果。
3)比较InceptionV3-UNet++模型与标准UNet/UNet++模型不同的网络特性和实验结果发现,在模型深度有限的情况下,提升卷积模块的广度也可以有效提升模型建筑物提取的效果,Inception模块虽然使模型复杂度提升,但计算量增加不大,有效提升了模型的运行效率。
4)通过对标准模型进行改造,使得模型对建筑物的提取精度提升明显,特别是基于InceptionV3骨架的UNet++网络,在马萨诸塞州建筑物数据集的实验结果在生产者精度、用户精度、CSI、F1分数、Kappa系数和总精度上分别达到85.14%、90.50%、0.781 6、0.877 4、0.850 4和95.57%,相较于传统的非全卷积网络模型和全卷积网络模型,各项参数均有明显优势。
5)通过对InceptionV3-UNet++模型进行迁移学习,在WHU数据集上取得较好的分类精度,证明该模型具有良好的鲁棒性能。
本文基于不同骨架的UNet++在马萨诸塞州建筑物数据集取得了很好的分类结果,但仍然有一定的改进空间:
1)通过提升模型的卷积深度提升了建筑物提取效果,但没有探究模型深度提升与建筑物提取效果的具体关系,随着模型深度的增加,虽然可以使模型复杂度提升,但是也使得计算量增加,而对于建筑物提取而言复杂度和提取效果是否存在一定关系,后续可以探究以ResNet34、ResNet50、ResNet101以及ResNet152为骨架不同深度的模型对建筑物提取的精度影响。
2)使用VGG16、ReNet50和InceptionV3为骨架改造UNet++,其中的InceptionV3-UNet++骨架模型为建筑物提取取得了很好的效果,随着卷积神经网络在图像领域的发展,很多新的模型不断被提出,可以继续探讨不同基础卷积网络为骨架对建筑物提取效果的影响。
3)在模型输出分类结果后,没有进一步对提取结果进行后处理,后续可以探讨通过适当后处理方法优化提升提取结果。
4)仅采用马萨诸塞州建筑物公开数据集进行实验,并用WHU数据集进行了迁移学习验证,下一步可以探讨在更小样本情况下在其他数据集上的适用性,提升模型的应用能力。
