高光谱数据截断加权核范数稀疏解混
2022-07-06李璠张绍泉曹晶晶梁炳堃李军刘凯邓承志汪胜前
李璠,张绍泉,曹晶晶,梁炳堃,李军,刘凯,邓承志,汪胜前
1.南昌工程学院江西省水信息协同感知与智能处理重点实验室,南昌 330099;
2.中山大学地理科学与规划学院,广州 510275
1 引言
高光谱遥感是综合对地观测的重要组成部分(张兵,2016)。成像光谱仪将地物光谱与空间影像相结合,不仅可以获取丰富的空间信息,还可以采集更加精细的光谱信息,使图像中每个像元对应一条完整连续的光谱曲线(刘银年,2021)。高光谱遥感图像具有足够的光谱分辨率,能够区分出具有诊断性光谱特征的地物,在植被调查、矿物勘探、环境监测等领域有广泛应用(童庆禧等,2016)。
由于成像光谱仪空间分辨率有限,而地物空间分布复杂多样,大量混合像元存在于高光谱遥感图像,成为制约高光谱遥感图像高精度解译的瓶颈问题(张良培和李家艺,2016)。光谱解混旨在将像元观测光谱分解为多种纯端元光谱,并估计每种端元所占的丰度分数(Keshava 和Mustard,2002)。假设参与组成混合像元的端元光谱均包含于先验光谱库,则光谱解混可简化为丰度估计问题。光谱库中光谱特征数一般远多于每个像元中实际存在的端元数,相应的丰度矩阵自然具有稀疏特性,因此,这类解混方法称为稀疏解混。
近年来,稀疏解混成为高光谱图像解混的热点研究方向,大量基于丰度矩阵稀疏诱导的解混算法被提出。例如,变量分裂增广拉格朗日稀疏解混算法SUnSAL(Sparse Unmixing algorithm via variable Splitting and Augmented Lagrangian)采用L1范数诱导单个像元丰度向量稀疏(Iordache 等,2011);协同SUnSAL算法CLSUnSAL(Collaborative SUnSAL)采用L2,1范数诱导丰度向量联合稀疏(Iordache 等,2014)。这些算法虽然有效规避了光谱解混中纯净像元缺失和端元估计两个瓶颈问题,但对丰度的稀疏性度量不够,没有充分利用高光谱图像丰富的空间信息。为增强丰度的稀疏性,迭代加权策略被用于重新构造稀疏正则项(Candès 等,2008)。例如,双重加权稀疏解混算法DRSU(Double Reweighted Sparse Unmixing)通过双重加权的L1范数同时增强光谱域和空间域丰度分数的稀疏性(Wang 等,2016);空谱加权稀疏解混算法S2WSU(Spectral-Spatial Weighted Sparse Unmixing)构建L1稀疏正则化框架下的光谱—空间加权因子,有效融合图像的光谱和空间信息,并通过邻域系统挖掘图像的空间相关性(Zhang 等,2018)。在空间信息利用方面,SUnSAL-TV 算法通过全变差TV(Total Variation)正则项融入图像的空间上下文信息(Iordache 等,2012);基于TV 模型的加权协同稀疏解混算法WCSU-TV(Weighted Collaborative Sparse Unmixing via TV Model)将TV 正则项与加权L2,1范数组合,促进全体像元的联合稀疏性和相邻像元的高相关性(Wang 等,2021);SUnSAL-4DTV 算法提出四方向全变差4DTV (Four-Directional Total Variation)正则项,挖掘图像中每个像元水平、垂直、对角和斜对角4个方向的空间上下文信息(Ahmad 等,2020);非局部稀疏解混算法NLSU(Non-Local Sparse Unmixing)通过非局部均值方法开发图像中的相似结构,融合图像的非局部空间信息(Zhong 等,2014)。以上算法主要考虑丰度矩阵的稀疏结构,忽略了高光谱图像内在的低维结构。
高光谱图像像元之间具有空间相关性,即邻近像元通常是相同端元的相同或相近比例的组合,其丰度向量是相似的,因此丰度矩阵具有低秩或近似低秩的结构特性(Eches 等,2011;Qu 等,2014)。同时考虑丰度的低秩性和稀疏性,可以更好地捕捉图像的空间数据结构。因此,一系列利用丰度低秩先验的稀疏解混算法被提出,如交替方向稀疏低秩解混算法ADSpLRU (Alternating Direction Sparse and Low-Rank Unmixing)(Giampouras等,2016),联合稀疏块低秩解混算法JSpBLRU(Joint-Sparse-Blocks and Low-Rank Unmixing)(Huang等,2019),基于低秩约束的两步迭代行稀疏高光谱解混算法TRSUnLR(Two-Step Iterative Row-Sparsity Hyperspectral Unmixing via a Low-Rank Constraint)(Zhang 等,2021),这些算法在稀疏解混框架中加入低秩约束项,利用丰度矩阵的低秩逼近,促使像元共享相同或相近的端元集合和丰度系数。
矩阵秩最小化问题的求解是NP (Nondeterministic Polynomial)难问题,因此,常用秩函数的凸包,即核范数,代替目标函数中的秩函数,转而求解核范数最小化NNM (Nuclear Norm Minimization)问题。为解决这一凸优化问题,奇异值阈值SVT(Singular Value Thresholding)对矩阵的每一个奇异值运用相同的收缩算子做软阈值处理,使部分奇异值缩减到零(Cai 等,2010);截断核范数正则化TNNR(Truncated Nuclear Norm Regularization)将最小的若干个奇异值置零,其他奇异值保持不变(Zhang 等,2012);加权核范数最小化WNNM(Weighted Nuclear Norm Minimization)自适应地为每个奇异值赋予不同的权重,对较小的奇异值施以较大的惩罚,而对较大的奇异值惩罚较小(Gu等,2017)。实际应用中,不同奇异值所对应的信息不同,图像的主要信息集中在较大的奇异值上。SVT未利用这种先验知识,无差异地处理每个奇异值,限制了其保留主要数据分量的能力。TNNR 只截取较大的奇异值,而忽略了与其他奇异值相关的有效图像信息。WNNM 对包含丰富图像信息的较大奇异值也施以惩罚,不利于保护图像细节结构,并且缺少对矩阵本质秩属性的保护。为更好地实现矩阵的降秩逼近,Zheng等(2020)提出截断重加权范数最小化TRNM(Truncated Reweighting Norm Minimization)。该方法对矩阵的奇异值向量分段采用截断核范数和加权核范数方式处理,有效保护了矩阵的本质秩属性,在矩阵补全、子空间聚类等方面取得了良好的应用效果。
本文首次在稀疏解混中引入截断重加权范数,提出高光谱数据截断加权核范数稀疏解混算法TWNNSU(Truncated Weighted Nuclear Norm Sparse Unmixing)。该算法一方面在稀疏约束项中引入空间权重,促进图像像元空间连续,另一方面将截断加权核范数作为低秩正则项,促进图像的空间一致性。在丰度估计过程中,截断加权核范数既可以有效保护较大的奇异值,更完整地保留丰度图像的细节信息,又差异化缩减较小的奇异值,减轻噪声对丰度估计的干扰。在应用方面,本文从无人机载高光谱成像系统采集到的红树林高光谱数据中提取常见的红树林树种光谱曲线,构建了红树林树种端元光谱库。基于该光谱库,采用稀疏解混技术自动识别红树林冠层种类并同步反演各树种的丰度,通过真实数据实验验证了本文所提算法的有效性。
2 截断加权核范数稀疏解混
2.1 稀疏解混

给定场景中实际端元的种类一般远少于光谱库中的端元数,因此丰度矩阵X是稀疏的。在丰度稀疏性、ANC 和ASC 驱动下,线性稀疏回归算法自动从光谱库中筛选最优端元子集。直观上,可采用L0范数度量丰度的稀疏度,但包含L0范数的目标函数优化求解是NP 难问题。在满足限制等距性RIP(Restricted Isometric Property)条件下,L0范数与L1范数优化问题具有相同的稀疏解(Candes 和Tao,2005,2006),稀疏解混模型可表示为
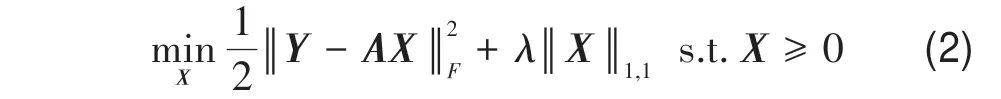
2.2 低秩稀疏解混
丰度矩阵具有低秩性,低秩表示模型可以捕获这种数据结构特性。由于秩函数是零模与奇异值向量的复合,其优化问题是NP 难问题,而核范数是秩函数的最紧凸代理,因此可以通过求解核范数最小化问题实现低秩矩阵近似(Fazel 等,2001;Pan 和Wen,2020)。基于此,得到低秩稀疏解混目标函数如下:
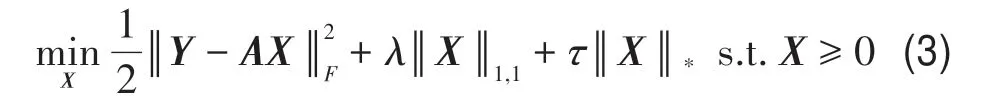
式(3)联合了L1范数和核范数挖掘丰度矩阵内在的稀疏低秩结构,缩小了丰度估计问题的解空间,有利于丰度解的唯一性。对于式(3)中核范数最小化问题,TRSUnLR 算法采用了SVT 方法近似求解,ADSpLRU 和JSpBLRU 算法则用加权核范数取代标准核范数。
2.3 截断加权核范数稀疏解混
为减少式(3)模型中丰度矩阵低秩逼近所导致的偏差,并促进像元之间的相关性,本文提出截断加权核范数稀疏解混模型(TWNNSU),表示如下:
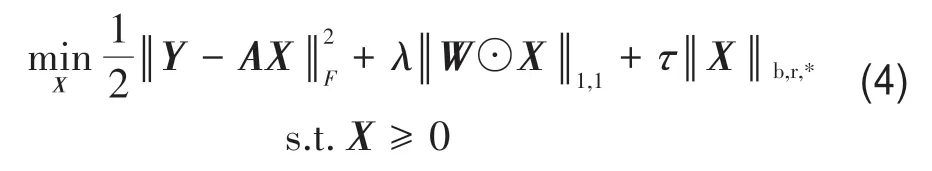
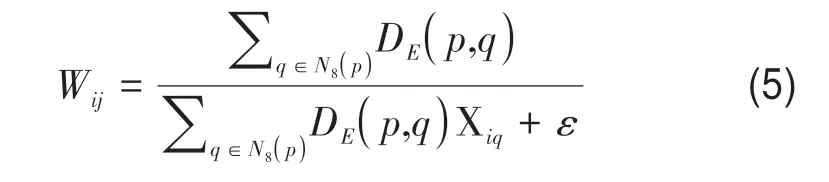
式中,Wij是W中第i行第j列元素,表示丰度矩阵中元素Xij的权值,p是Xij所对应的像元,N8(p)表示像元p的8-邻域空间,q为N8(p)内任一像元,DE(p,q)表示像元p和像元q的欧氏距离,Xiq表示像元q的丰度向量中第i个元素,ε>0 是为了避免奇异点而加入的一个小值常量。权重矩阵W迭代更新,第t+ 1 次迭代时,的计算采用第t次迭代时丰度矩阵的值。由式(5)可知,任一像元的空间权值与其8-邻域空间内其他像元丰度向量的加权均值成反比,即一个像元其邻域像元的丰度系数越小,该像元的空间权值越高,在迭代过程中,为使目标函数最小化,该像元的丰度系数趋于减小,进而使丰度矩阵中出现更多零值,提升丰度矩阵的稀疏性。表示丰度矩阵X的截断加权核范数,计算公式如下:

式中,σi(X)是丰度矩阵X的第i个奇异值,注意X的奇异值按照从大到小排序,b为奇异值权重向量,bi为其中第i个元素,,r是目标秩。同样采取迭代方式更新。由式(6)可知,截断加权核范数保持丰度矩阵X的前r个奇异值不变以保护丰度矩阵的本质秩属性,更好地保留丰度矩阵的原始数据信息和细节结构;对其他奇异值采取自适应加权方式予以缩减,越小的奇异值,其奇异值权重越高,缩减越快,进而促进奇异值向量稀疏,实现丰度矩阵的降秩逼近。由于较小的奇异值大多是由噪声引起,在降秩逼近过程中去除小的奇异值,可以有效抑制噪声的影响(Zheng等,2019)。
2.4 模型求解
受Zhang 等(2018)启发,采用内外双循环方案迭代求解模型(4),外循环按照式(5)更新空间权重矩阵W,内循环采用交替方向乘子法ADMM(Alternating Direction Method of Multipliers)更新丰度矩阵X,具体过程如下。
引入辅助变量U,V1,V2,V3,V4,将式(4)改写为如下形式:
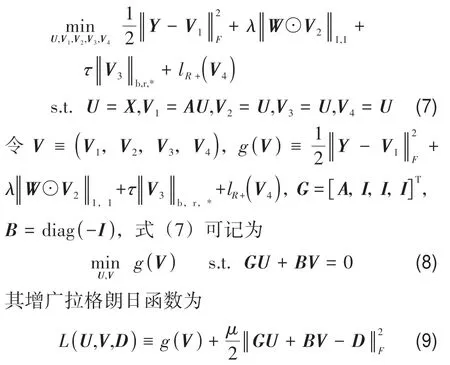
式中,μ>0为罚参数,为约束条件GU+BV= 0相关的拉格朗日乘子。
根据ADMM 求解变量U和变量V的优化子问题,并更新拉格朗日乘子D:
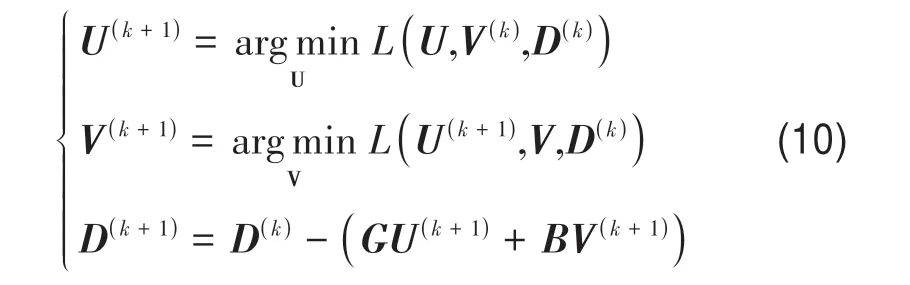
对式(10)中U,V1,V2,V3,V4依次求偏导,得到各个变量的迭代更新公式。
综上,TWNNSU算法流程如下:
输入:高光谱数据Y,光谱库A
输出:丰度矩阵U
步骤1初始化:设t,k,s= 0,λ,τ,μ,ε>0,

步骤2循环:
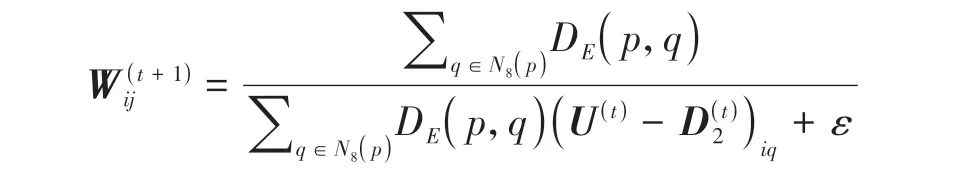
步骤3循环:

步骤4更新拉格朗日乘子:

返回步骤3,直到满足循环中止条件

返回步骤2,直到满足循环中止条件


3 实验结果与分析
为证明本文所提算法的有效性,本节利用1组模拟数据和2组真实数据进行实验。模拟数据的端元光谱和真实丰度已知,以定量分析为主,真实数据分别使用了Cuprite 数据和红树林数据,以定性分析为主。实验选取的对比算法有:SUnSAL 算法(Iordache 等,2011)、SUnSAL-TV 算法(Iordache等,2012)、DRSU算法(Wang等,2016)、S2WSU算法(Zhang 等,2018)、加权L1稀疏正则化与WNNM 结合的ADSpLRU 算法(Giampouras 等,2016)、分块L2,1稀疏正则化与WNNM 结合的JSpBLRU 算法(Huang 等,2019)。此外,为验证截断加权核范数低秩约束的有效性,模拟数据实验中还对比了加权核范数稀疏解混(WNNMSU)算法,该算法稀疏正则项的构造与TWNNSU 算法相同,但低秩约束采用了加权核范数,与ADSpLRU 和JSpBLRU 算法相同。为公平起见,参照各算法的原始文献,并针对本文实验所采用的数据集进行算法调优,确保所选取的正则化参数使各算法性能均达到最优,最大迭代次数均设置为500。
实验采用均方根误差RMSE (Root Mean Square Error)和信号与重建误差比SRE(Signal Reconstruction Error)定量评价算法的解混精度。SRE用分贝(dB)来衡量,定义如下:

3.1 模拟数据实验
模拟数据实验使用的端元光谱库源于美国地质勘探局USGS (United States Geological Survey)发布的地物光谱库。端元光谱库A1由USGS光谱库中随机选取的222条地物光谱曲线组成(光谱波段数为221),即A1∈R221×222。实验使用的丰度图像利用分形技术生成,大小为100 × 100,该数据结构较好地模拟了自然界中常见的空间模式,并纳入了ANC 和ASC 约束。根据线性光谱混合模型模拟生成高光谱数据立方体,随后在数据中加入信噪比SNR(Signal-to-Noise Ratio)分别为20 dB、30 dB 和40 dB 的高斯白噪声,形成3 组模拟数据集。图1 显示了模拟数据中9 种端元的真实丰度图及光谱曲线。

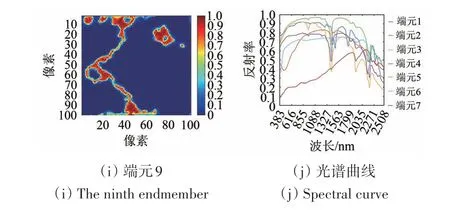
图1 模拟数据9种端元的真实丰度图像及光谱曲线Fig.1 True fractional abundances and spectral curve of the endmembers in the simulated data
表1 展示了不同算法对模拟数据解混得到的RMSE、SRE(dB)和ps值(取10 次平均值),以及相应的正则化参数设置。可以看出,在所有情况下,所提TWNNSU 算法的解混精度均为最高。特别是SNR=20 dB 时,TWNNSU 算法的SRE 和ps值显著高于所有对比的算法,ps值接近于1,表现出明显的性能优势。与WNNMSU 算法相比,TWNNSU 算法在低信噪比下能稳定地获得较高的解混精度,证实截断加权核范数最小化约束在解混过程中有效减轻了噪声的不利影响。

表1 各种算法对模拟数据集解混结果的RMSE、SRE和ps值以及相应的正则化参数设置Table 1 RMSE,SRE(dB)and ps values obtained by applying different unmixing algorithms to the simulated data according to the regularization parameter settings listed
为更加直观地进行对比,图2展示了各算法对信噪比为20 dB 的模拟数据集解混得到的估计丰度图。为使视觉效果更加清晰,图2 只随机选择了500 个像元进行展示。图中彩色线条表示丰度矩阵中的非零行,反映了从光谱库中选中的参与组成图像的端元。可以看出,TWNNSU 算法筛选出的端元与实际端元基本一致,丰度图中没有出现明显的代表错误端元的异常线条。对比算法的估计丰度图中不同程度地存在异常线,这意味着解混过程中出现了端元错配问题。与S2WSU 算法相比,TWNNSU算法和WNNMSU算法得到的估计丰度图中异常线显著减少,证明低秩约束可以增强算法从光谱库中识别实际端元的能力。WNNMSU算法的丰度图中仍存在少量具有较小值的异常线,TWNNSU算法的丰度图更加干净,证明截断加权核范数低秩约束在提升算法端元识别能力方面效果更好。
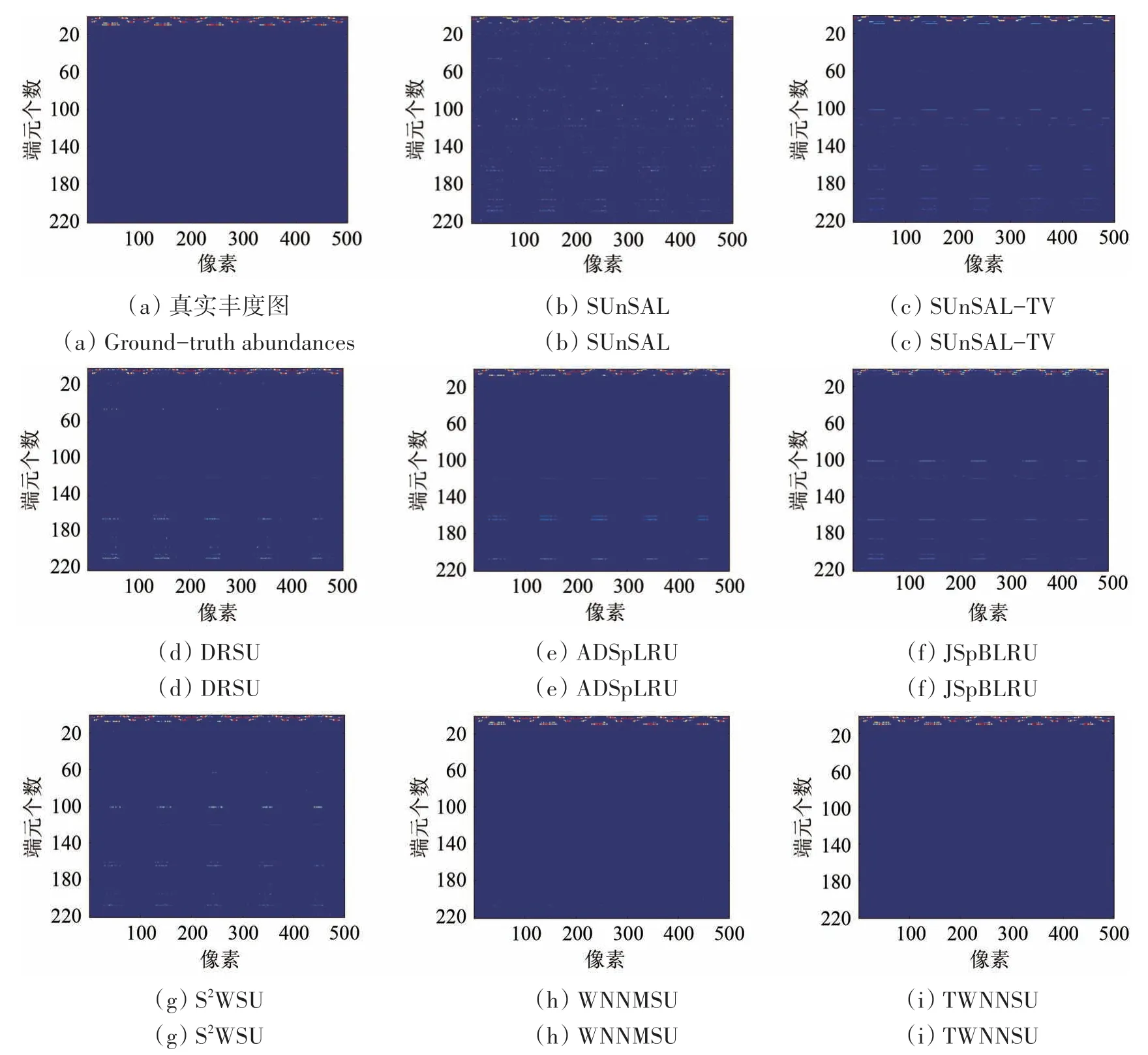
图2 真实丰度图和不同算法对模拟数据集(SNR=20 dB)解混得到的估计丰度图Fig.2 Ground-truth and estimated abundances obtained by applying different unmixing algorithms to the simulated data with SNR=20 dB
进一步比较各算法对信噪比为20 dB 的模拟数据集中各端元的丰度估算结果。所有算法均识别出端元1、端元2、端元3、端元6 和端元8,但不同算法丰度估计的准确性有明显差异。图3 以端元2为例展示各算法解混得到的端元丰度分布图和丰度差值图。从丰度差值图可以看出,TWNNSU算法的丰度估计结果最接近真实丰度,SUnSAL 和SUnSAL-TV 算法的估计结果与真实值差异较大。从丰度分布图中可以看出,DRSU 算法得到的丰度分布图出现了大量异常丰度值,而引入了空间加权因子的S2WSU 算法有明显改善。ADSpLRU 和JSpBLRU 算法由于加入了低秩约束,受噪声影响的程度减轻,但两者的丰度图中仍存在较多的异常丰度值。TWNNSU 和WNNMSU 算法的丰度图像中异常点明显减少,表现出较好的空间连续性,证明空间加权策略有效促进图像的空间连续性,减轻噪声对解混的干扰。此外,TWNNSU 算法更好地保留了图像的细节信息。
对比算法在其他端元识别方面存在的问题如下:JSpBLRU 算法混淆了端元4 与端元5 的丰度分布(如图4所示);DRSU 和JSpBLRU 算法未能识别端元7;对于端元9,只有本文所提TWNNSU 算法能够稳定选择该端元参与建模图像,WNNMSU算法有一定概率无法选中该端元,稳定性不足。
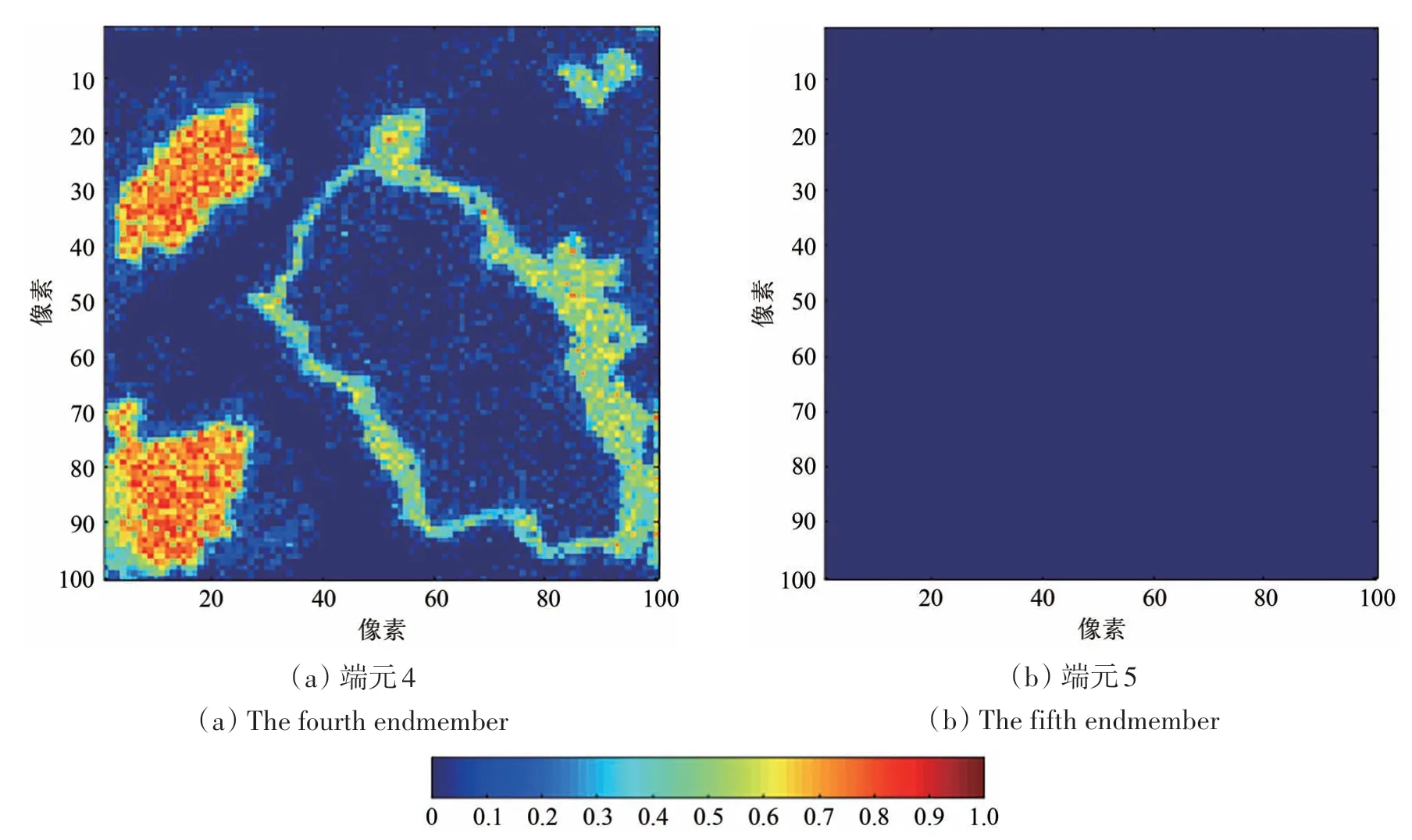
图4 JSpBLRU算法对模拟数据集(SNR=20 dB)解混得到端元4和端元5的丰度分布图Fig.4 Abundance maps of the fourth and fifth endmembers obtained by JSpBLRU form the simulated data with SNR=20 dB
总体来看,TWNNSU 算法中空间加权稀疏正则项有利于促进丰度图像空间连续,而截断加权低秩约束项有利于消除噪声干扰,显著提升低信噪比条件下算法识别端元的能力,两者的结合提高了算法的精确度和稳定性。
TWNNSU 算法包括两个正则化参数λ和μ,分别调节稀疏约束项和低秩约束项对算法的影响。图5展示了信噪比为30 dB时,TWNNSU算法得到的估计丰度的SRE值随正则化参数λ和μ变化的关系。从图5可以看出,参数λ在[5 × 10-5,1 × 10-3]之间寻找最优或次优值,参数μ的取值在[1,7]之间寻优。
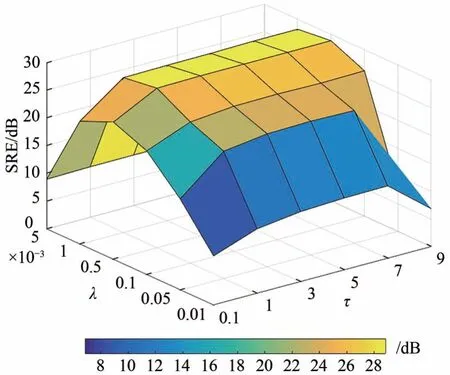
图5 TWNNSU算法正则化参数分析(SNR=30 dB)Fig.5 Regularization parameters analysis of TWNNSU(SNR=30 dB)
对于目标秩r的取值,通过噪声子空间投影算法NSP(Noise Subspace Projection)(Chang 和Du,2004)或最小误差高光谱信号识别算法HySime(Hyperspectral Signal identification by minimum error)(Bioucas-Dias 和Nascimento,2008)估算高光谱数据中端元的数量,并将目标秩r的值设置为估计端元数。此外,为了分析目标秩r的不同取值对TWNNSU 算法结果产生的影响,图6 以信噪比为20 dB的模拟数据集为例(通过HySime算法估计出的值应设r= 9,与该数据的实际端元数,即丰度矩阵的本质秩一致),展示了TWNNSU 算法解混得到估计丰度的SRE(dB)值与目标秩r之间的关系。从图6可以看出,目标秩r在[7,11]范围内取值时,估计丰度的SRE(dB)值在r= 9时最高,在其他情况下也能获得较理想的值。因此,当r的值等于或接近真实端元数时,TWNNSU 算法可以保持良好的解混性能。

图6 r取不同的值时TWNNSU算法解混得到估计丰度的SRE(dB)值(SNR=20 dB)Fig.6 When r takes distinct values,SRE(dB)of estimated abundances obtained by TWNNSU algorithm(SNR=20 dB)
表2 展示了各算法处理信噪比为20dB 的模拟数据集所用的时间。测试均在一台配备英特尔酷睿i7-7700四核中央处理器和32 GB RAM 内存的台式计算机上进行,使用了MATLAB R2016a 软件。从表2可以看出,ADSpLRU、JSpBLRU、WNNMSU和TWNNSU 算法的速度快于SUnSAL-TV。但由于模型的复杂性增加,它们都比SUnSAL 和DRSU 算法慢。与考虑低秩约束的ADSpLRU 和JSpBLRU 算法相比,本文提出的TWNNSU 算法略慢于ADSpLRU 和JSpBLRU 算法,但这3 种算法的计算时间大致接近。

表2 各种算法对模拟数据集(SNR=20 dB)解混的运行时间Table 2 Runtime for different unmixing algorithms to process the simulated data(SNR=20 dB)
3.2 真实数据实验
3.2.1 真实数据集1实验
本实验采用的真实数据是著名的AVIRIS Cuprite 矿区数据集。它已广泛应用于验证高光谱解混算法的性能。Cuprite 数据集的光谱波段数为224 个,覆盖的波长范围为0.4—2.5 μm,光谱分辨率为10 nm。实验中剔除了低信噪比和低吸水率波段(1—2、105—115、150—170 和223—224 波段),剩下188 个波段数。实验所使用的端元光谱库选自USGS 光谱库,包含240 条不同的矿物光谱曲线,并保留相应的188个波段。由于没有Cuprite 数据集的真实丰度图,本文使用Tricorder 软件(Clark 等,2003)制作的分类图(图7)为参考来定性分析各解混算法的性能。实验采用最大迭代次数以保证不同解混算法收敛。
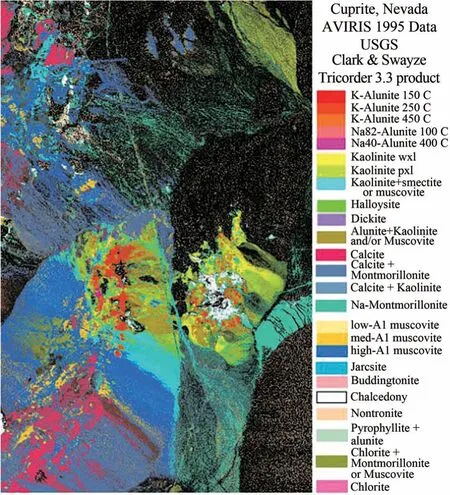
图7 USGS获得的内华达州Cuprite矿区数据Fig.7 USGS map showing the Cuprite mining district in Nevada
在此实验中,SUnSAL、DRSU 和S2WSU 算法所涉及的正则化参数经验性地分别设置为λ=0.001,λ=0.0001,λ=0.0002。SUnSAL-TV、ADSpLRU、JSpBLRU 和TWNNSU 这4种算法所涉及的正则化参数经验性地分别设置为(λ=0.001;λTV=0.001),(λ=0.0005;τ=0.001),(λ=0.05;τ=0.2)和(λ=0.0005;τ=0.03)。图8 以明矾石(Alunite)、水铵长石(Buddingtonite)、玉髓(Chalcedony)和白云母(Muscovite)4 种典型矿物为例展示了不同算法对Cuprite数据集进行解混得到的丰度图。
从图8可以看出,所有算法解混得到的矿物丰度图基本相似,但所提TWNNSU 算法估计的每种矿物的丰度分数通常高于其他算法或与其他算法相当。SUnSAL-TV 算法得到的丰度图(如Alunite和Buddingtonite)存在较明显的过平滑现象;DRSU 算法估计出的丰度图(如Chalcedony)空间一致性较差。与S2WSU 算法相比,TWNNSU 算法估计出的Alunite 矿物丰度图包含更少的噪声。此外,与考虑了低秩约束的ADSpLRU 和JSpBLRU 算法相比,TWNNSU 算法具有更好的空间一致性(如Chalcedony),估计出的丰度图包含更少的噪声(如Alunite、Buddingtonite 和Muscovite),更接近于Tricorder 分类图。综上,可以得出TWNNSU 算法能有效处理该真实数据,能够提高解混精度。
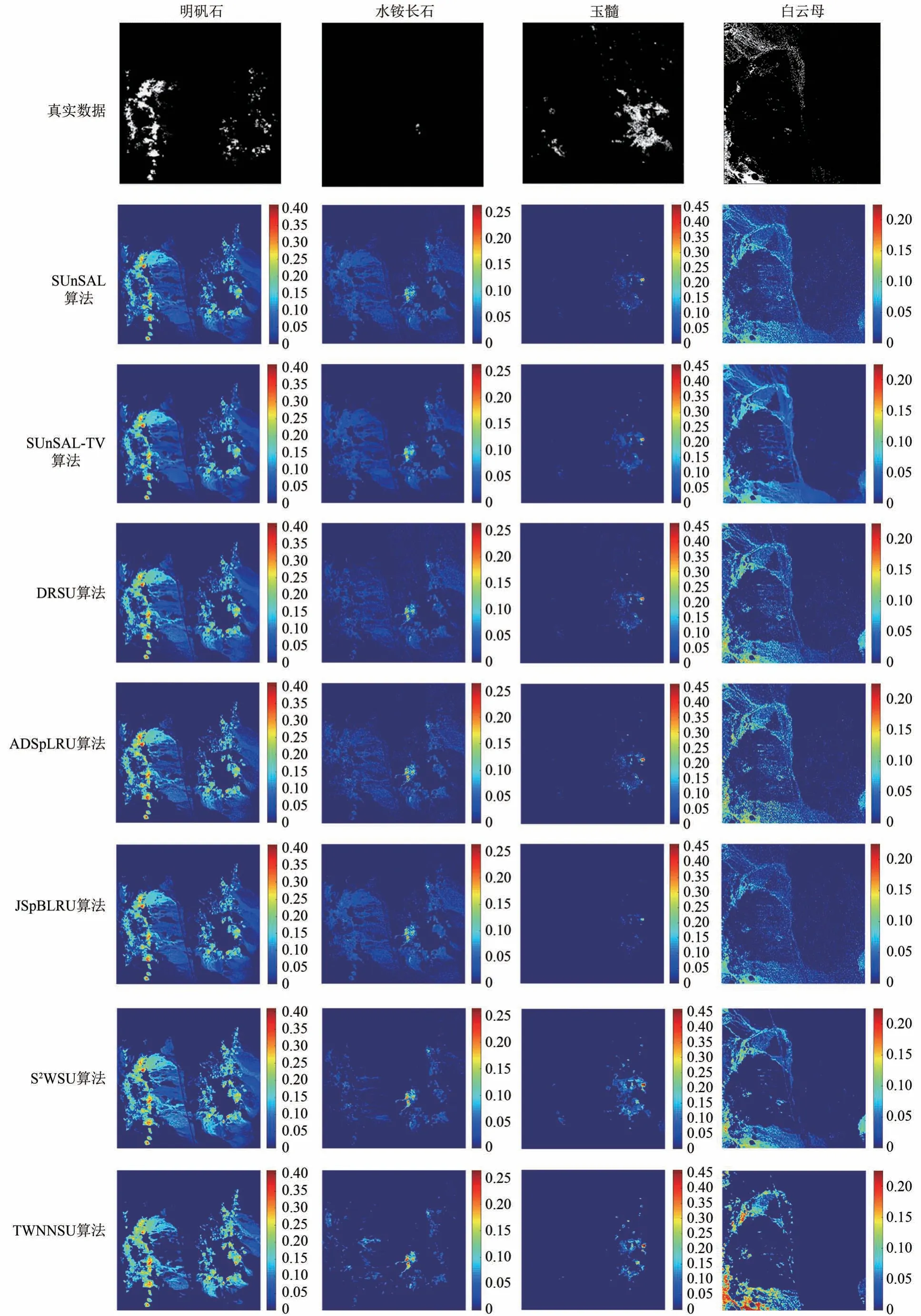
图8 各解混算法对真实数据Cuprite解混得到的丰度图Fig.8 Fractional abundance maps estimated by different unmixing algorithms for a subset of AVIRIS Cuprite scene
3.2.2 真实数据集2实验
本实验采用的真实数据源于无人机载高光谱影像,该数据已在复杂环境下红树林树种精细识别中得到有效验证(Cao等,2018a;He等,2020)。数据采集区域位于广东省珠海市淇澳岛红树林自然保护区,该区是国内红树植物种类最多的红树林之一,也是珠海市目前红树林保存最完整且林分最集中的区域(牛安逸等,2016;唐焕丽等,2015)。基于无人机载Cubert UHD185 高光谱成像系统获取覆盖实验区域的高光谱影像如图9所示。数据采集时间为2016年10月15日,由无人机飞行一个架次获取。实验场景由1878 像素×1877 像素组成,波长范围为450—950 nm,光谱分辨率为4 nm,光谱波段数为125个。实验数据影像覆盖红树林区域面积约3 ha,影像经过预处理后重采样为空间分辨率0.02 m。
图9 UHD185无人机高光谱影像Fig.9 The UHD185 hyperspectral image
根据文献资料(Cao 等,2018a,2018b),本实验区域内分布的红树林树种主要包括秋茄KC(K.candel)、卤蕨AA(A.aureum)、桐花树AC(A.corniculatum)、无瓣海桑SA(S.apetala)、老鼠簕AI(A.ilicifolius)和银叶树HL(H.littoralis)。此外,还包括芦苇PA(P.australis)、河涌以及木栈道。受成像时光照条件的影响,无人机高光谱影像存在一些阴影,在实验过程研究中它们也被认为是一类端元。对于稀疏解混算法,因缺乏针对该数据的端元光谱库,为此,本文选择构建面向该数据的端元光谱库。经野外实地考察后,首先在空间上均匀地圈选出每类树种所在的明显同质的区域,近似认为该区域是纯像元区域,然后对无人机高光谱数据中相应区域的光谱反射率按波段求取平均值,作为该树种的端元光谱,对各类红树林树种以及芦苇、河涌、木栈道做同样处理,最终构建端元光谱库。图10 展示了光谱库A3中7 种典型植被的光谱曲线,可以看出,各类植被的光谱曲线比较接近,给解混带来较大困难。本实验以Cao 等(2018a)采用基于支持向量机(SVM)方法获得的实验区域红树林树种分类图(图11)为参考数据,定性分析各算法针对红树林高光谱数据的解混性能。
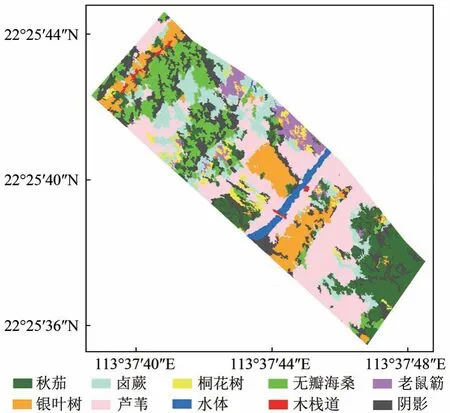
图11 红树林树种分类图Fig.11 Classification map of plant species
实验中SUnSAL、DRSU 和S2WSU 算法相关的正则化参数经验性地分别设置为λ= 0.0001,λ=0.00008 和λ= 0.0001。SUnSAL-TV、ADSpLRU、JSpBLRU 和TWNNSU 等算法相关的正则化参数经验性地分别设置为(λ=0.001;λTV=0.001),(λ=0.00001;τ=0.0003),(λ=0.001;τ=0.0001)和(λ=0.0001;τ=0.0008)。图12 以秋茄(KC)、银叶树(HL)、卤蕨(AA)、无瓣海桑(SA)、芦苇(PA)、桐花树(AC)和老鼠簕(AI)7 种典型植被为例展示不同算法对该数据集解混得到的丰度图,图中像元丰度值大于零的地方表明该类植物存在。从图12 可以看出,SUnSAL、SUnSAL-TV、DRSU、ADSpLRU、JSpBLRU、S2WSU、TWNNSU这7种稀疏解混算法获得的结果与参考分类图有较吻合的地方,证明稀疏解混算法能有效分离该红树林数据中不同的端元。尽管难以定量评价各算法的解混结果,但从图12 中可以定性观察出所提TWNNSU 算法得到每种端元的丰度图均能较好地接近参考分类图,可以较清晰地反映出各类植被的分布情况,并更好地保留了丰度图像的细节信息(例如植被PA),表明TWNNSU 算法在处理红树林数据方面具有一定优势。

图12 各解混算法对红树林高光谱数据解混得到的丰度图Fig.12 Fractional abundance maps estimated by different unmixing algorithms for mangrove hyperspectral data
4 结论
为充分利用高光谱图像像元之间的相关性,本文以低秩稀疏解混模型为基础,提出一种截断加权核范数稀疏解混算法(TWNNSU)以增强对高光谱数据的解译。TWNNSU 算法兼顾高光谱图像多种空间结构特征,联合空间加权稀疏约束与截断加权核范数约束,解混过程中能够保留图像更多的细节信息,达到低信噪比条件下仍能有效识别端元的目的。此外,通过基于ADMM 的内外双层循环方法对模型进行求解加快了算法的收敛速度。模拟数据、Cuprite 真实数据和红树林高光谱数据实验表明,本文提出的TWNNSU 算法对噪声具有较好的鲁棒性,能够获得稳定和精确的解混结果。
