基于深度学习激光熔覆层树枝晶的形貌识别
2022-07-05郭士锐王凯祥崔陆军李晓磊陈永骞
郭士锐,王凯祥,崔陆军,李晓磊,郑 博,陈永骞
(中原工学院 机电学院,河南 郑州 450007)
引言
激光熔覆技术是将高功率密度的激光束的能量,通过非接触方式使粉末材料加热并熔化,熔化后的粉末材料快速冷却与微观结构的形成,使得表面具有与基体材料本身不同的新性能[1-4]。在激光熔覆过程中,急冷急热的能量变化过程会对微观组织的形成产生极大的影响,而最终形成的微观组织与材料的性能有着紧密的联系[5-6]。在熔覆层凝固结晶时,最常见的是以树枝状生长的枝晶,且枝晶不同的形貌参数与其性能有着一定的对应关系[7]。因此,实现自动识别枝晶形貌,对研究熔覆层性能具有十分重要的价值。基于上述背景分析,本文提出了一种从复杂的金相图中识别并分割出枝晶形貌的深度学习算法。
近些年,基于深度学习的计算机视觉检测在不同工况均展现了其优异的能力[8-10]。特别是用于像素级别分类的语义分割更是在工业、医学等领域得到了大量的应用[11-12]。Li等人利用收发声信号技术监测激光熔覆过程,并通过深度学习神经网络提取特征向量,从而分析熔覆状态以及是否存在产生裂纹的迹象[13],该研究表明可以利用深度学习技术分析熔覆层状态及微观形貌。张海军等人基于遗传算法、二维最大类间方差提出双阈值分割法[14],根据区域极大值初步确定阈值,并对金相图像进行分割,分割结果反馈调整阈值,实现了对不同金相组织的分割。为本文实现在复杂背景中分割出枝晶形貌提供了一种新思路。熔覆层金相图中树枝晶与不规则晶、胞状晶等混杂在一起[15],不利于对树枝晶形貌进行观察研究。将树枝晶形貌识别视为二分类问题,通过语义分割的方法把树枝晶从复杂的金相图中分割出来,便于后续研究枝晶形貌与熔覆层性能的具体联系。
针对复杂背景的二分类问题,本文对原Unet网络加以改进,引入串行放置的通道注意力机制、空间注意力机制和批量标准化(Batch Normalization,BN)层,并部署在下采样和上采样过程,建立了BNC-Unet(BN+CBAM-Unet)(convolutional block attention module,CBAM)即枝晶形貌分割网络模型。本网络模型用于树枝晶形貌的识别分割,在观测树枝晶形貌时排除其他晶粒的干扰,有效地促进了树枝晶形貌对熔覆层性能影响的研究。
1 树枝晶形貌识别网络
语义分割是深度学习三大应用之一,其特点是效率和精度高[16-17]。搭建适于识别并分割样本特征的深度学习模型,建立训练集及测试集,用以训练、测试模型,并根据网络反馈优化参数,最终可以快速、准确得到分割结果,节省大量的时间。本研究以U-net网络模型为基础,U-net网络本身是为了解决医学影响的细胞分割而提出,便于辅助医护人员客观、准确地分析病理,为做出准确的医学诊断提供支撑数据[18]。由于其出色完成了在复杂背景下分割样本目标而得到了众多领域专家的青睐[19]。针对样本背景复杂问题,在原来的U-net网络基础上,部署串行注意力模型和BN层,并调整2种模型的部署位置,使得本次改进的BNCUnet模型能更好地胜任树枝晶形貌分割任务,取得较为满意的分割结果。
1.1 总体网络架构
本次设计的树枝晶形貌识别网络主要分为2个部分,其结构如图1所示。一是用于提取特征的下采样部分,即编码区;二是得到更加准确特征信息的上采样部分,即解码区。树枝晶识别网络整体架构呈现字母U型,接下来依次介绍2个区域。
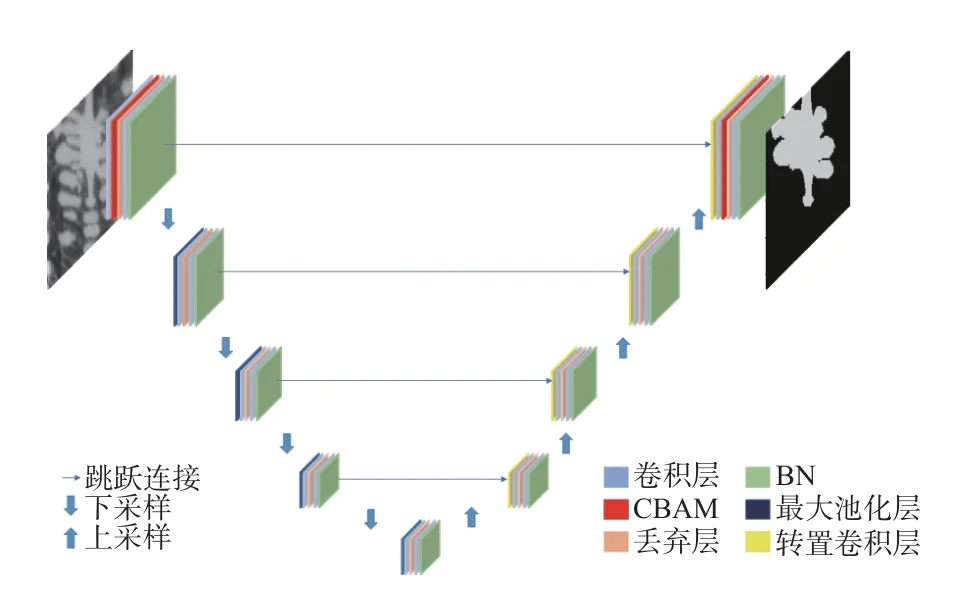
图1 BNC-Unet网络结构图Fig.1 Structure diagram of BNC-Unet network
第1部分是模型的编码部分,用于提取金相特征,该部分的各子过程大体包括了2个卷积层(其中卷积核为3×3)、防止模型过拟合的丢弃层、用于对每层数据标准化处理的BN层、elu激活函数层、最大池化层。在该部分的第一阶段引入CBAM,使得提取到的特征更加精准。将3通道128像素×128像素的原始图像输入编码区,经过卷积等操作生成4组通道数与大小不同的特征图,其通道数和大小如表1所示。这些特征图用于与解码区中相同通道数、相同大小的特征图进行跳跃融合。经编码区最后一次处理得到256通道8像素×8像素的特征图,并传递至解码区。

表1 特征图指标Table 1 Feature map indexes
第2部分是凝练特征信息的解码部分,该部分的每个阶段大体包括了用于扩大图像尺寸的ConvTranspose2d逆卷积层(卷积核为2×2、步长为2)、特征融合(解码区内的特征图与编码区内的特征图通道数、尺寸大小对应相等)、2个卷积层(其中卷积核为3×3)、丢弃层、BN层、elu激活函数层。在该部分的最后一个阶段引入CBAM,细化特征,调整权重。由编码区传递的256通道8像素×8像素的特征图经过上采样过程,最终生成单通道128像素×128像素的灰度图像。
1.2 串行注意力机制原理
串行注意力机制,即将输入的特征图先经过通道注意力模块,然后将该模块的输出结果加权传递至空间注意模块,经过这2个模块的作用,最终将结果输出作为下一过程的输入。这种注意力机制模型在2018年由Woo[20]提出,并对比了单独使用这2个模块和空间注意模块加通道注意力模块的布局,结果表明先通道后空间得到的特征信息最为准确,其对目标特征的识别覆盖最广。串行注意力模型结构如图2所示,通道注意力模型与空间注意力模型串行放置,使得提取特征更为准确。
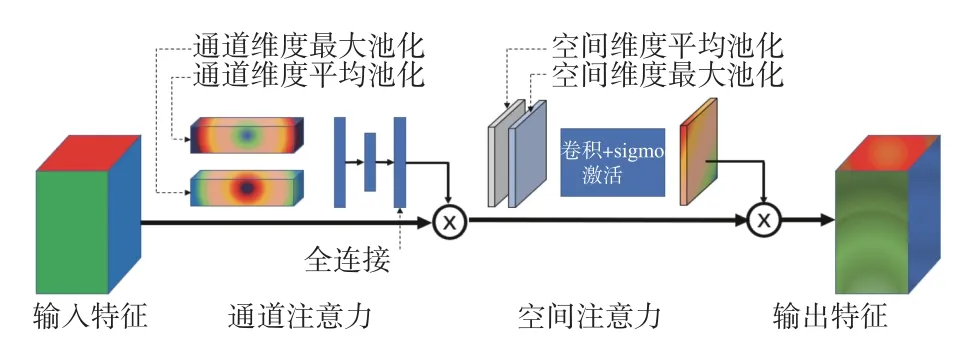
图2 串行注意力模型结构图Fig.2 Structure diagram of serial attention model
在通道注意力模型内,焦点在于通道维度,特征图的每个通道即为各通道包含的特征。提取通道的池化参数,再经过同一个多层感知机(Multilayer Perceptron, MLP),输出值相加后经过归一化处理得出最终权重,得到的权重与特征图的乘积即为通道注意力模型输出的加权特征图。
在空间注意力模型内,焦点在于特征图中每个像素的权重。与通道注意力模型类似,在空间注意力模型中,提取不同通道的同一平面空间点的池化参数,经卷积和归一化处理得出最终权重,得到的权重与空间特征的乘积即为空间注意力模型输出的加权特征图。
特征图经过串行注意力模型后,特征权重得到进一步调整处理,有利于提高网络对样本特征学习、提取的能力,从而提高网络的性能。
1.3 网络参数的选取
网络参数的选择主要是Batch Size的确定、优化器的选取和损失函数的选取。
1.3.1 Batch Size的确定和优化器的选取
Batch Size的大小对网络的训练速度和梯度具有一定的影响,其优点在于可以有效地防止内存爆炸,加速收敛,避免局部最优。梯度方差如(1)式所示:
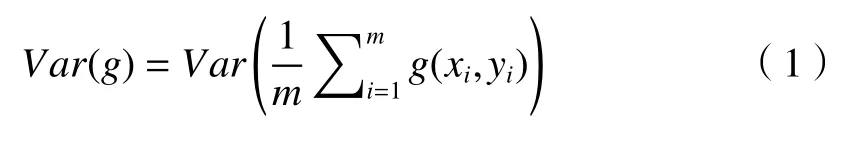
式中:m为Batch Size。因为样本数量固定且随机,所以各样本方差相同,(1)式可简化为
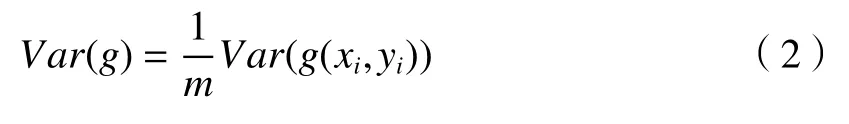
由(2)式可以看出,梯度方差与批量大小成反比,一般Batch Size取值范围在2~32之间[21],本次实验取Batch Size大小为14,epoch设置为75。
学习率对于神经网络训练起到非常重要的作用,本次选用Adam优化算法。该算法整合了AdaGrad和RMSProp两种算法的优势[22],与单独使用这2种算法相比,使用Adam算法收敛最快。该算法属于自适应学习率算法,其算法策略如下:

式中:mt为 一阶动量项;为修正值;根据经验设定β1为0.9。
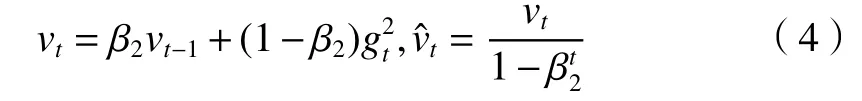
式中:vt为二阶动量项为修正值;根据经验设定β2为0.999。
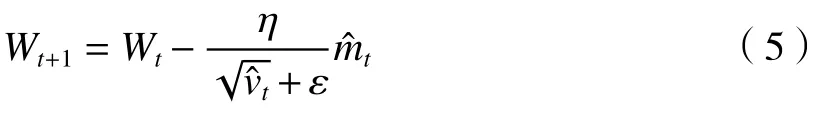
式中:Wt为迭代模型参数;取 ε值为10-8。Adam优化器在收敛速度和准确率方面表现优秀,故本网络模型选择Adam优化器。
1.3.2 损失函数的选取
本次分割任务属于二分类问题,故Loss损失函数选用二进制交叉熵。由于树枝晶特征与其背景中其余晶粒特征相差不大,故本次设计的网络模型的输出层激活函数选用Sigmoid函数,其函数原理如(6)式所示:

从(6)式可以看出,该函数可以把数值控制在0~1区间,故能良好地应用于二分类问题。
二元交叉熵损失函数如(7)式所示:
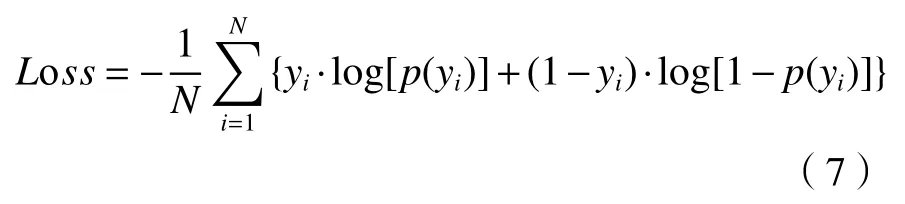
式中:p(yi)是 标签 yi(0或1)出现的概率; N 为样本数。故该文采用binary cross entropy作为损失函数,且搭配Sigmoid使用。
2 实验结果与讨论
为了检验本次设计的基于语义分割树枝晶形貌识别网络的分割能力,进行了激光熔覆实验,并采集了训练网络所需的样本。本次的训练集和测试集均是由课题组激光熔覆样块在光学显微镜下捕获所得,光学显微镜型号为DM2700M(leica microsystems,GmbH)。使用型号为LDP6000-60(laserline,GmbH)大功率光纤激光器进行熔覆实验,将熔覆样块进行线切割、镶块处理,经打磨抛光和王水腐蚀后在光学显微镜下捕获金相图像,至此激光熔覆实验结束,后续需要在计算机上进行下一阶段实验。利用Labelme软件为金相图制作标签后,建立金相数据集,其中包括420张训练图像和20张测试图像,原金相图和标签如图3所示。
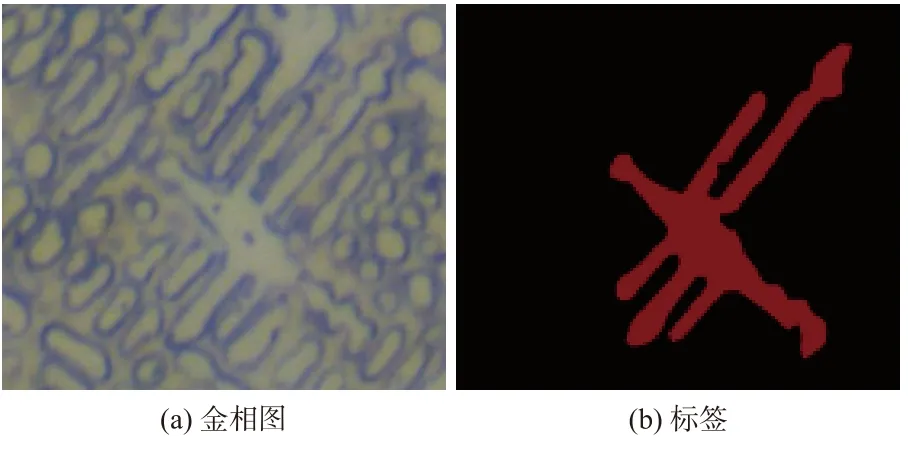
图3 数据集Fig.3 Data set
本次研究使用的计算机操作系统为Windows 10,CPU为Intel®Core™i5-10200H,RAM为8.00 GB,GPU为GTX1650Ti。网络搭建、运行、调试选用Tensorflow框架,选择基于网页版编译器Jupyter notebook和Python语言编译开发,该编译器可以直接在网页上调试代码,程序结果直接在网页中显示,便于直接观察。为了防止网络模型训练时出现过拟合现象,本设计引入用于提前终止训练的Early Stopping命令,并设置耐心值为20步,即训练过程中Loss值出现连续20步无下降现象,模型训练停止。
实验结果的评价指标选用交并比(intersection over union,IoU),其表达了网络分割像素与标签像素总数上的比值。通常以混淆矩阵作为基础,再计算评价指标数值。混淆矩阵如图4所示,A为真实值,B为预测值。预测与标记相同为True;相反为False。预测值为树枝晶像素记Positive;反之为Negative。
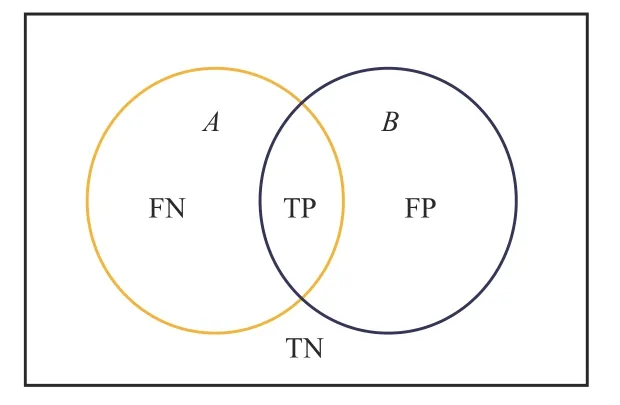
图4 混淆矩阵示意图Fig.4 Schematic diagram of confusion matrix
IoU计算方式为
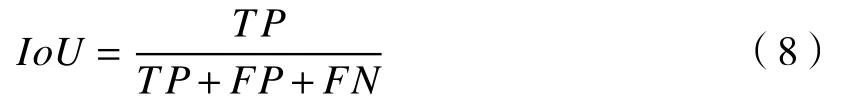
本网络共训练了378张图片,验证了42张图片,并做了3组对比试验,其结果如表2所示。设定相同参数,对比了Unet、BN-Unet、CBAM-Unet、BNC-Unet输出结果如图5所示。从表2可以看出本次针对树枝晶特征设计的BNC-Unet模型结果最好,其IoU值为84.20%,比原Unet模型结果提高了8.97%。从图5中的分割结果看,BNC-Unet自动分割的树枝晶结果最为精确。
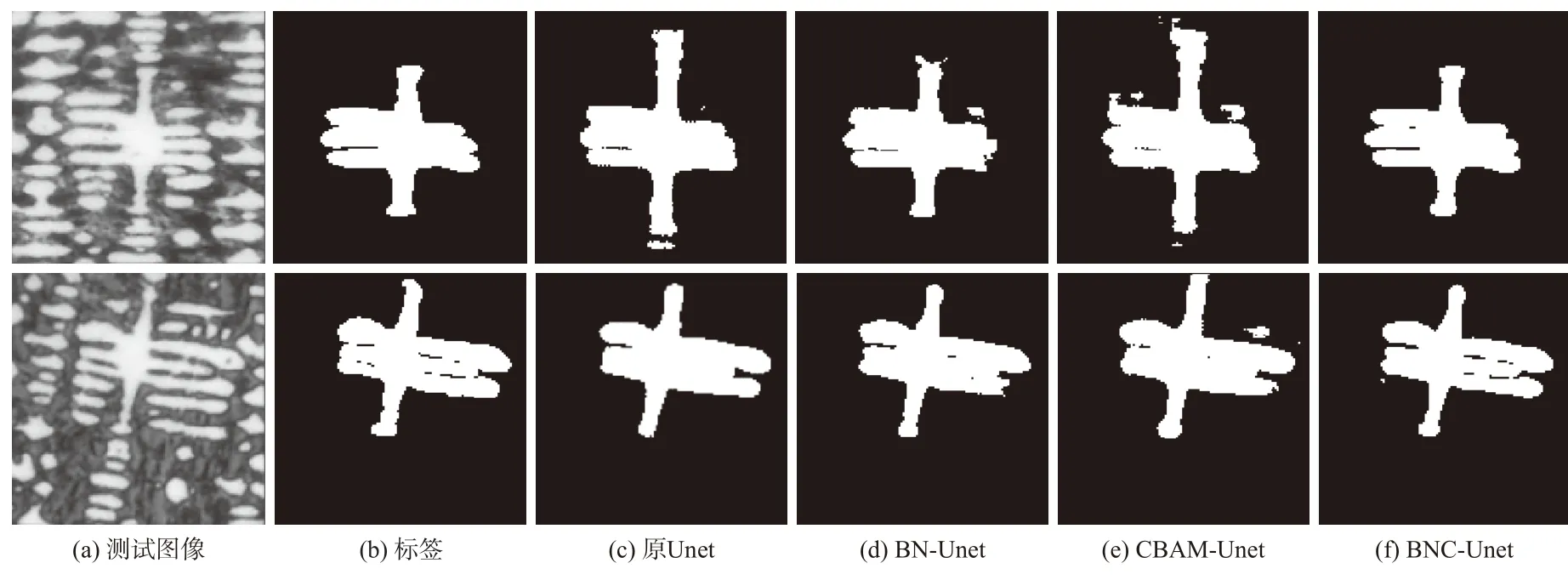
图5 各网络输出对比图Fig.5 Comparison graphics of each network output
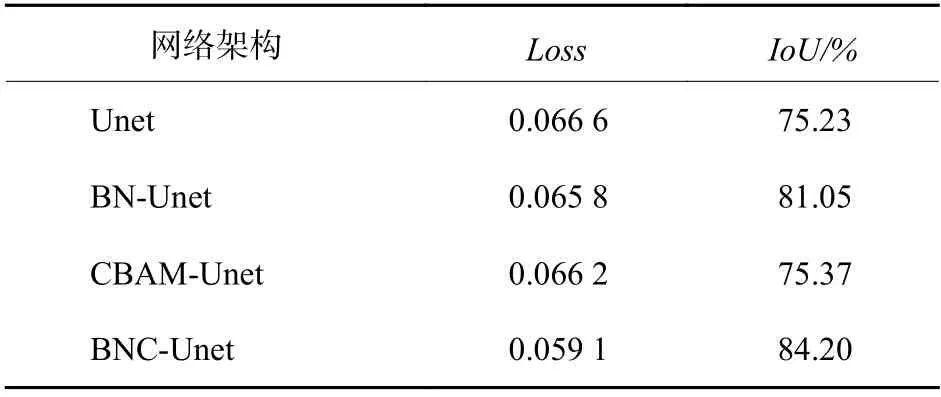
表2 不同改进方式的网络结果Loss、IoU对比Table 2 Comparison of Loss and IoU network results of different improved methods
3 结论
本实验基于U-net网络引入注意力模型和BN层,搭建了针对分割树枝晶的BNC-Unet网络,建立了用于训练网络和测试网络的数据集,将交并比IoU作为本次网络的评价指标,并对比了原Unet网络、BN-Unet网络、CBAM-Unet网络的分割结果。其对比结果表明BNC-Unet网络能够较为准确自动标记树枝晶形貌,BNC-Unet网络分割准确率为84.2%,比原Unet网络结果提高了8.97%。注意力机制在浅层和深层对称部署一次可以在实现较好的特征提取结果的基础上而不增加网络训练时间,实现自动标记树枝晶形貌,便于在进行激光熔覆试验后,为自动分析熔覆层性能提供参考。
