面向CNN的区块链可信隐私服务计算模型
2022-07-02李海生钟琼慧田明宇
丁 毅,沈 薇,李海生,钟琼慧,田明宇,李 洁
(1. 北京物资学院信息学院,北京 101149;2. 北京工商大学农产品质量安全追溯技术及应用国家工程实验室,北京 100048;3. 北京工商大学计算机学院,北京 100048)
1 引言
当前,人类社会已经步入了移动互联网时代,智能计算、移动便捷以及隐私安全成为重要的发展趋势. 如何能在保护用户隐私信息的前提下,加强移动终端的计算能力,提高高智能计算服务体验,是一个亟待解决的问题.
在这种背景下,利用云服务来完成人工智能计算的模式出现了,它既可解决边缘设备计算力不足的问题,又可发挥移动特性. 以基于卷积神经网络(Convolu⁃tional Neural Network,CNN)的图像分类为场景,探索新模式应用的关键技术,目前面临着以下两个方面的挑战.
(1)用户隐私保护是应用的重要前提.2018年欧盟制定的《通用数据保护条例》[1](General Data Protection Regulation,GDPR)提出加强对个人数据在隐私和安全方面的保护. 用户终端数据涉及大量用户信息,将其直接发送到云端缺乏安全保障,具有泄露风险. 云服务商也容易过度使用这些数据或私自销售,谋取利益[2]. 用户数据隐私保护是安全计算外包模式的基本要求[3].
(2)传统云服务是由云供应商控制和维护的,包括服务和权益规则,以及交易和服务数据,缺乏有效的共同参与和管理机制,约束力和透明度不足,出现纠纷难于追责. 同时,容易产生大的云服务商垄断、小的云服务商难以生存的现象,不利于市场良性发展和资源的有效整合.
为了应对上述挑战,本文研究面向CNN 的区块链可信隐私服务计算模型. 以典型应用为场景,利用同态加密技术,在保护用户隐私的前提下,有效利用计算资源为边缘设备提供算力服务,智能合约和区块链可加强服务权益管理的公开透明.
2 相关工作
本节从同态计算、云计算隐私保护、卷积神经网络隐私保护等方面展开分析.
(1)同态加密技术
1978年Rivest首次提出同态加密的概念,即对密文进行运算的结果与对明文进行相应运算的结果是等效的. 无需解密,通过处理密文即可获得需要的计算结果,这是数据隐私保护的重要手段,具有重要意义[4~6].
2009 年Gentry[7]提出了基于理想格的全同态加密方案,复杂度高的限制造成密文数据扩张问题不能有效解决,影响实际应用.Van Dijk 等人[8]使用基本的模运算设计了同态加密方案(Dijk Gentry Halevi Vaiku⁃tanathan,DGHV),该方案是对文献[7]整数上的全同态加密算法的改进,使计算复杂度降低、效率提高、易于实现,一次加密1 bit的数据,其公钥加密方案的安全性依赖“近似最大公约数”问题.
Coron 等人[9]针对DGHV 方案公钥尺寸过大的问题,提出一种基于平方公钥压缩的CMNT(Coron Man⁃dal Naccache Tibouchi)公钥优化方案. 其思想是使用公钥集合中非初始元素的2k个公钥可生成k2个公钥,压缩公钥尺寸. 首先将2k个公钥平均分成两组,然后分别从两组公钥中随机选择一个公钥对应相乘,再乘以随机数,并运算处理生成新的公钥,进而完成加密操作.
另外,文献[10]改进了文献[8]的方案,使其一次可以加密2 bit 的数据. 孙霓刚等人[11]进一步改进了DGHV 算法,将明文空间由1 bit 扩展到nbit,提出一次可以加密nbit数据的方案,降低了加密次数. 为了清晰说明,本文将这种算法称为N-DGHV. N-DGHV 算法通用性强,适合服务计算隐私保护场景,但仍存在公钥存储空间过多的问题. 因此,本文在N-DGHV 算法的基础上,对公钥进行压缩优化,并加以实现.
(2)云计算隐私保护研究
传统的云计算模式中,终端数据以明文的形式传输到云端进行计算,用户隐私无法得到保障,存在安全隐患[12].
云计算的数据隐私保护解决方案主要有访问控制、数据加密、安全外包、安全多方计算等[13],都是基于数据加密理论展开的. 蒋瀚等人[14]提出了安全多方计算方法来解决云计算隐私保护问题,该方法需要多方参与计算,且通信频繁,不适合本文客户端资源有限的应用场景. 文献[15]使用基于混淆方法的隐私管理器来管理云端和用户终端的数据,保护数据隐私,但重在加密管理,未深入研究密文的智能计算等工作.
在云计算场景中,随着数据量的增大,频繁的加解密操作会造成计算资源的浪费,能够直接对密文进行计算操作显得尤为重要.
同态加密技术以其良好的密文可操作性,成为解决云计算隐私保护问题的重要技术,也成为重要发展和应用方向[16,17]. 而文献[18]也提出同态加密技术在处理大量数据时效率不高. 本文正是致力于探索该技术适合智能计算应用场景的解决方案.
(3)卷积神经网络数据隐私保护相关研究
卷积神经网络是深度学习的重要分支,计算复杂度高,被广泛应用于人脸识别、语音识别等领域[19]. 卷积神经网络的隐私保护工作可在不同阶段进行,分别是训练阶段和预测阶段. 在训练阶段,需要各参与方提供各自的数据来完成模型训练工作,这些数据可能包含隐私信息. 在预测阶段,终端用户待预测数据、服务器端训练好的特征模型都有隐私保护的需求. 本文主要针对卷积神经网络的预测阶段展开工作,使用同态加密技术.
Dowlin 等人[20]于2016 年提出CryptoNets 神经网络模型,使用同态加密算法实现卷积神经网络预测阶段的隐私数据保护. 为了保证同态加密的正确性,此方案化简了预测方法,使用平方函数实现激活层. Cha⁃banne 等人[21]使用低次多项式逼近激活函数来加强同态加密计算效率. 文献[22]在CryptoNets 基础上优化,同时提出云端双服务器协同模式使加同态算法支持CNN 各层模型,提高效率. 文献[23,24]则提出将两方计算技术(混淆电路)与同态加密相结合的解决方案,同态加密处理CNN 线性部分,而两方计算则处理非线性部分.
目前,这一领域并不成熟,仍旧存在加密计算开销大、智能算法不适用、管理模式不清晰等问题,还远不能被广泛应用,需要更多实践去探索应用方法和模式.
(4)其他相关研究
区块链具有分布式管理、难以篡改的特点[25],可被广泛应用于医疗、交通、农业等多个领域. 智能合约通常是运行于区块链上的公开透明的计算代码. 本文利用区块链存储服务数据,并设计智能合约权益评估模型,公开透明并自动执行,加强交易的可信度.
联邦学习技术是2016 年被提出的,该技术在保证数据隐私安全的前提下,用来完成高效智能计算工作.联邦学习的过程是将用户数据在本地计算,并将结果传输到服务器参与聚合计算,从而起到保护隐私数据的目的[26]. 然而,联邦学习模式数据提供者在本地进行模型训练,对终端环境的算力要求较高. 因此,本文依据应用场景,选取同态加密方法展开研究工作.
3 可信隐私服务计算模型
为了提高云服务环境下卷积神经网络预测服务质量,本文从安全、隐私和可信3个方面考虑,研究可信隐私服务计算模型. 该模型使用非对称的公钥加密、私钥解密机制来加强数据的安全性,避免被恶意截取;同时,通过密文传输,利用同态加密的特点在服务端进行密文计算,将密文结果反馈用户,整个计算过程全密态,保护数据提供者隐私信息;最后使用区块链和智能合约技术完成云服务计算过程的记录,并进行自动权益分配,保证服务过程不可篡改,公开透明,从而增强服务计算模型的可信度.
3.1 可信隐私服务计算架构
可信隐私服务计算架构如图1所示,主要可分为用户端、模型提供端、云服务器端3 类角色,围绕计算、加密、可信权益等工作运转.
(1)用户端
用户端是服务计算的使用者,拥有数据以及公私钥生成器. 用户端要向云服务端提出需求,请求服务,并取得相应权限(如认证、开通账户),进而开始整个服务流程. 首先,用户端生成公私钥,并将公钥发送给云服务端,如图1中①所示;其次,在本地将数据通过公钥加密,密文上传云服务端,如图1 中④所示;再次,用户端得到云服务端提供的密文运算结果及分类标签,如图1中⑤所示,并在本地通过私钥解密进而得到最终结果;最后,用户端收到云服务端的权益分配结果,并提交服务费用,如图1中⑥所示.
(2)模型提供端
首先,模型提供端需要从云服务端获取加密公钥(由用户端提供给云服务端),如图1中②所示;其次,模型提供端将训练好的预测模型使用公钥加密后提供给云服务端,同时需要提供分类标签(无须加密,各个分类在结果向量中的顺序),如图1 中③所示;最后,计算服务完成后,模型提供端获得权益分配结果,取得相应费用,如图1中⑦所示.
(3)云服务端
云服务端提供强大的计算资源和模型服务,完成用户端的请求. 首先,云服务端接收用户端公钥,并将其发送给模型提供端加密预测模型,如图1中①与②所示. 其次,若使用云服务端自有的预测模型,则直接加密. 否则,云服务端接收模型提供端的加密模型以及用户端提供的加密数据,如图1 中③和④所示,进行密文的卷积神经网络计算,将密文结果返回给用户端. 隐私服务计算过程完毕. 此外,在计算过程中,云服务端计算资源使用及服务提供情况,连同云提供商信息提交区块链存证,并使用区块链智能合约实现权益计算模型并自动执行,分配云服务端、用户端、模型提供端各自的费用和收益. 通常是用户端付费,云服务端和模型提供端获利.
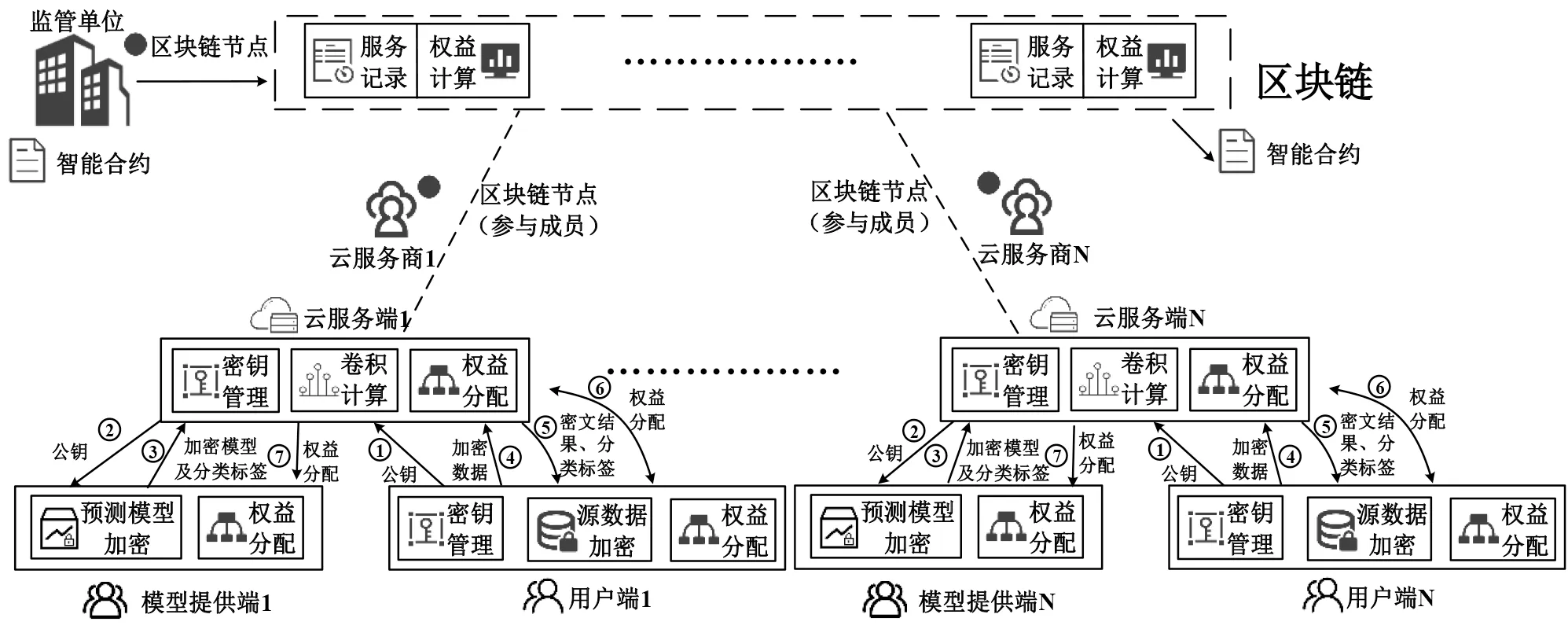
图1 可信隐私服务计算架构图
如图1 所示,实际中存在多个云服务商,提供不同的模型和服务. 数据拥有者计算资源不足,选择合适的云服务商并借助其算力获得预测结果,但又要保护数据隐私. 模型提供者(也可以是云服务商)在保护模型内容的前提下分享模型并获利,同态加密技术在此流程中起到保护数据和模型隐私的作用. 另外,这种模式下,可信的运行环境和权益管理机制是破除垄断、提高服务质量的重要保证,区块链和智能合约技术恰能发挥作用. 计算资源使用、服务提供情况以及云服务商信息都存证区块链系统,不可篡改,智能合约计算权益分配的规则透明公开、自动执行,并且可查询、追责. 另外,模型提供者参与计算过程同样存证区块链系统. 这样,可达到模型权属清晰、服务权责透明、权益公平可信的效果. 同时,还存在一个监管单位的角色,监管单位可查看全部存证数据和使用规则,有效约束不良行为.
3.2 预测服务隐私计算模型
在此应用场景中,系统和用户可根据需求选择不同的同态加密算法. 本文同态加密是通过改进NDGHV 算法来实现的,这里称为ON-DGHV(Optimized N-DGHV)算法. DGHV 算法的明文空间是{0,1}(二进制表示). N-DGHV 算法通过将加密算法的随机数乘2变换为乘2n,解密算法的模2 变成模2n,实现明文空间由1 bit 扩大到nbit,减少了加密次数. 进一步,ONDGHV使用平方公钥压缩方法缩减公钥尺寸,减少公钥的存储空间. 此算法是面向整数的同态加密算法,将明文加密进行密文计算,会给智能计算的性能、精度乃至正确性带来挑战. 该模型努力探索适合该同态算法的CNN预测方法,运行流程如图2所示.

图2 卷积神经网络预测服务计算模型流程图
模型数据包括用户端提供的数据矩阵D和模型提供端提供的模型M(模型M包括卷积核K、卷积偏移量b1、全连接矩阵W和全连接偏移量b2).
模型组件可分为4个功能模块,具体如下.
(1)同态加密模块:对用户端的原始数据矩阵D使用公钥进行加密得到D′,对模型提供端提供的模型M使用公钥进行加密得到M′(加密后的模型M′包括卷积核K′、卷积偏移量b1′、全连接矩阵W′及全连接偏移量b2′).
(2)卷积神经网络预测模块:加密后的模型M′和同态加密后的数据矩阵D′成为卷积神经网络预测模块的输入. 进一步,卷积神经网络预测模块各层次的关系和功能操作如图3 所示. 卷积核K′和数据矩阵D′作为卷积层的输入,在卷积层利用卷积核K′对数据矩阵D′进行卷积计算,得到一组线性输出conv;conv在激活层使用激活函数完成非线性映射操作,为了适应同态密文要求,这里激活函数使用平方函数进行计算,生成密文数据acti;然后将acti 通过池化层进行加和池化[20],完成数据压缩,减少数据量,以简化计算的复杂度,进而输出数据pool;最后将数据pool 和全连接矩阵W′放入全连接层进行矩阵乘法,将上层的特征映射到样本空间来实现分类,所有类别中值最大的一类即为CNN的识别结果,表现为密文结果C. 为了保护数据模型的隐私性,该模型根据需求可增加一个保护机制. 那就是将密文C中各个元素都加上一个随机数r的密文态(r尽量选取较小的数,使用同一加密算法),随机数的密文可表示为Cr,加和之后得到C′(也就是Lock(C)函数),即C′=Cr+C,随后将C′连同分类标签(各个分类在结果向量中的顺序)发送给用户端.
从图3中可知,卷积层、激活层和池化层、全连接层各层之间存在前后级联关系,前一层的输出作为后一层的输入,是一个有机整体,共同完成密文数据的计算,有效提取数据特征,完成预测功能.
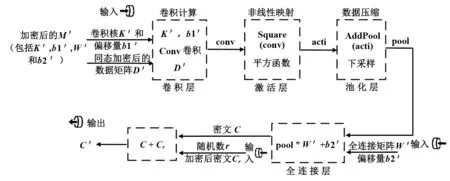
图3 卷积神经网络预测模块各层次关系示意图
(3)解密模块:用户利用私钥对获得的密文结果C′进行解密得到T′,根据分类标签获得max(T′)对应的分类结果,max(T′)是分类标签中的最大值,即预测结果.由于加密算法满足加法同态性,且最终是根据结果向量中元素的数值大小判断分类结果,因此即使卷积神经网络预测模块的结果加了Cr随机数,对最终的分类结果没有影响. 然而,这样会影响分类概率,云端可根据需求设置,解密模块同样对于密文C适用.
另外,如图2 所示,该模型还存在一个可信权益管理模型,在模型提供端提供模型后用智能合约进行存证;记录云服务端的服务明细;根据权益评估模型对用户端、模型提供端和云服务端进行权益分配. 整个流程主要由数据和模型的数据流以及权益交易流两个信息流组成,相辅相成,涉及模型各个环节,协同工作.
模型输入输出及算法涉及各个模块,具体如下.
(1)同态加密模块
同态加密模块输入:用户端的原始数据矩阵D. 模型提供端提供的模型M.
同态加密模块输出:原始数据矩阵D加密后的密文矩阵D′及加密后的模型M′(分别在用户端和模型提供端).
同态加密模块涉及的核心函数描述如下.
(a)GenKey(·):密钥生成函数. 输出用户的私钥SK,公钥集合PK={pkf,pk0,pk1,…,pk2k-1},下标k为正整数.
(b)Encrypt(PK,D),Encrypt(PK,M):加密函数.输入公钥集合PK,将PK 中的非初始的2k(即pk0,pk1,…,pk2k-1)个公钥平均分成两组,然后分别从两组公钥中各随机选择一个公钥相乘,重复这个过程a(0 (2)卷积神经网络预测模块 卷积神经网络预测模块输入:加密后的数据矩阵D′和加密后的模型M′. 卷积神经网络预测模块输出:返回给用户端的结果矩阵C′=[c′1,c′2,…,c′i]和分类标签l={l1,l2,…,li}. 卷积神经网络预测模块涉及的算法描述如下. (b)激活层 Activate(conv):平方函数. 激活层的作用是为CNN提供非线性特征,常用的激活函数(如ReLU,Sigmoid等)需要最大值、除法、指数等运算,不适合使用同态加密方法密文的加和乘法实现. 本文选用CryptoNets[20]使用的平方函数方法加以取代,计算结果为acti. (c)池化层 Pooling(acti):池化层主要的作用是下采样,对输入的特征图进行压缩,进一步减少参数数量,简化网络计算复杂度,提取主要特征. 池化的方法很多,为了更好的支持同态加密计算,这里采用加和池化的方法[20],得到结果pool. (d)全连接层 Connect(pool,W′):全连接层作用是将上层的特征映射到样本空间,从而实现分类.W′为全连接矩阵,将池化层的输出pool 矩阵转换成向量,即可把全连接层视为矩阵乘法,从而计算C=W′*pool+b2 得到结果向量C.C中的值代表分类标签l={l1,l2,…,li}中对应类别的数值(数值越高,则预测结果是该类别的可能性越大),为密文. (e)安全处理 Lock(C):生成随机数r(选择尽量小的数),加密得到密文形成Cr,利用Cr对全连接得到的结果向量C进行加密得到C′再发送给用户,从而使用户不会得到原始的模型输出结果,减少模型参数泄露的风险. 云端可根据实际需求设置输出原始结果,这一部分为可选项. (3)解密模块 解密模块输入:云服务端返回的密文结果向量C′(C同样适用)和分类标签l. 解密模块输出:卷积神经网络预测分类结果T. 解密模块涉及的算法描述如下. (a)Decrypt(C′,SK):解密函数.C′=[c′1,c′2,…,c′i]为云服务端返回的密文结果向量. 利用私钥SK 进行解密得到明文结果向量T′=[t′1,t′2,…,t′i]. (b)T=p(max(T′),l):max(T′)为集合T′中的最大值,即分类结果的数值. 分类标签l和向量T′存在一一映射的关系,T=p(max(T′),l)代表max(T′)在l中的映射,即为卷积神经网络的预测分类结果. 传统服务计算的权益规则由云供应商(云服务端)制定,缺乏透明度和公共约束力,这样,云供应商的权利过大,服务使用者(用户端和模型提供端)的权益得不到有效保证,进而不愿意参与云端服务计算. 因此,本模型设计基于智能合约的权益计算模型来进行权益分配,此过程由区块链智能合约自动执行并进行数据的存储. 一方面,在模型提供端提供模型时,智能合约对模型的所属权进行记录存证,保证模型提供端的权益. 另一方面,智能合约计算权益分配,模型提供端和云服务端根据权益分配的结果获取相应的收益,而用户端通常向云服务端提供相应的费用,收益规则公开透明,保证过程可追溯、权益评估真实可信. 以卷积神经网络的图像分类场景为例,结合传统云服务的计费思路,可设计智能合约的基础权益分配方法,如表1 所示. 从模型、资源使用、数据角度考虑,具体参数包括模型准确度、使用时长、服务费、存储容量、收益等. 表1 权益评估计算参数表 (1)模型提供端 模型提供端的收益依赖其提供的模型的准确度,分为3 个标准,即小于80%、80%~95%、大于95%,能够获得的收益分别为x1,x2,x3.(x1 (2)云服务端 上述的卷积神经网络预测计算模型是以ONDGHV算法为加解密基础的,这里重点描述该算法的设计与实现. 为了表述清晰,部分符号表达和前文概述有所调整. (1)同态加密模块 这一模块的工作是生成密钥对、加密明文m. 生成私钥SK 时,需要保证|m+2nr′ | 算法1 生成密钥对输入:明文m,m的比特(位)数n,正整数k(公钥包含的元素个数为2k+1)输出:私钥SK,加密公钥PK 1.function GenKey(m,n,k)2. generate random positive integer numberr′3. do 4.generate random large prime number x 5. while|m+2nr′|≥x/2 6. SK ←x 7. generate random positive odd number qf 8. pkf=qf×SK 9. put pkf into PK 10. for i from 0 to 1 step 1 11.for j from 0 to k-1 step 1 12.do 13.generate random positive integer number ri,j 14.while ri,j ≤r′15.do 16.generate random integer number qi,j 17.while qi,j<0 or qi,j ≥qf 18.pki,j ←ri,j+SK×qi,j 19.put pki.j into PK 20.end for 21. end for 22. return SK,PK 23.end function 得到公钥后,下面以明文为正整数或零为例对加解密过程进行描述,负整数的处理方法类似,只是需要依据求模操作在不同编程语言中的具体含义来加以处理. 加密过程是首先将PK 中的非初始元素的2k个公钥平均分成两组,每组元素个数为k,然后分别从两组公钥中各随机选择一个公钥相乘,重复进行a(0 算法2 数据加密输入:明文m,位数为n,公钥PK,正整数k(公钥包含的元素个数为2k+1)输出:加密密文c 1.function Encrypt(PK,m,k)2. do 3.generate random positive integer number a 4. while a>k2 5.sum ←0 6. for i from 0 to a-1 step 1 7.do 8.generate random positive integer number e1 9.generate random positive integer number e2 10.while e1>k or e2>k 11. generate random positive integer number b 12. sum ←sum+PK[0][e1]*PK[1][e2]*b 13. end for 14. generate random positive integer number r 15. c=(m+2n×r+2n×sum)mod pkf 16. return c 17.end function (2)解密模块 对于正整数的密文结果c,用户可使用私钥SK 对c根据T=(cmod SK)mod 2n公式进行解密得到明文结果T. 负整数密文解密的处理方法类似. 另外,关于基于同态加密的CNN 智能计算,不管是加密过程还是密文计算过程,都会涉及大量的循环计算,因此可以使用并行化提高效率,推动密文计算的实际应用. 本节对隐私服务计算模型进行实验分析,主要分为算法对比和密文预测分析两部分. 实验环境是使用Dell PowerEdge R740 服务器,CPU 是Intel Xeon Silver 4116@2,内存64 GB,固态硬盘960 GB,机械硬盘3.6 TB,使用Python语言开发. 实验主要将本文使用的ON-DGHV 算法与NDGHV 算法以及CMNT 算法(1 bit)进行比较.3 种算法都使用非对称同态加密,实验从加密数据的个数和位数两个方面展开工作. (1)加解密数据个数相同,位数不同 实验对象为10 000 个数据,设定为常见的十进制数,改变数据位数,分别设计为1,4,7 和10 位,测试指标是加密和解密时间. 不同位数的10 000个数(数据是随机生成的)要进行50 次实验并将测试指标的平均值作为结果,见图4 和图5. 为了清晰表述,两个图均分为(a)和(b)两个子图,子图(a)是三种算法的变化对比,而子图(b)则是两类DGHV 算法的时间对比. 随着数据位数的增多,ON-DGHV 和N-DGHV 算法的加/解密时间变化幅度都较小,基本保持不变,且当横坐标(位数)大于等于4 时,加/解密的时间明显小于CMNT 算法.ONDGHV 和N-DGHV 算法一次可以加/解密nbit 数据(实际应用中需要预处理得到n),可直接对十进制数(nbit)进行一次加/解密处理,而CMNT 算法一次只能加/解密1 bit数据(只支持0 与1 的加密),需将十进制数据转化为二进制,然后逐位进行加/解密操作,因此当数据位数较多时耗时更明显. 也就是说,CMNT加/解密时间依赖数据位数,呈类线性关系. 图4 加密时间随数据位数变化对比图 图5 解密时间随数据位数变化对比图 另外,ON-DGHV 是在N-DGHV 算法的基础上,使用了平方公钥压缩方法对公钥空间进行缩减,因此ONDGHV比N-DGHV加密算法耗时会增多,但是通过实验可得知区别不是很大,是可以接受的. (2)加解密数据位数相同,个数不同 设定数据位数不变,都是5 位的十进制数,加密数据个数(随机生成)分别是1000,10 000,100 000 和1 000 000,经过50 次实验求得测试指标的平均值. 测试指标仍旧是加/解密时间. 实验结果如图6 和图7 所示,同样,为了清晰展示,两图又分别划分为(a)和(b)两个子图,用来表示三种算法以及两类DGHV 算法的对比. 可以看出,三种算法的加/解密时间都随加密数据个数的增加而增加,但是ON-DGHV 和N-DGHV 算法增长相对缓慢,CMNT算法增长明显. 图6 加密时间随数据个数变化对比图 图7 解密时间随数据个数变化对比图 对ON-DGHV 与N-DGHV、CMNT 算法进行比较,总结如表2 所示,可知ON-DGHV 算法由于支持多位(bit)加密,加/解密的效率较高,同时使用公钥压缩方法使公钥空间减少,占据存储资源少,符合本文隐私保护服务应用场景. 表2 同态加密算法对比表 本节基于numpy 库[27]实现前文提到的卷积神经网络计算模型,可分为以下8 个部分:图像加密、模型加密、卷积层、激活层、池化层、全连接层、加随机数、解密. 这里使用ON-DGHV 加密算法进行实验,并选用常见的MNIST 手写数据测试集[28]. 该数据集是用于识别手写数字(图像分类)的,每个图片大小是28×28×1,即尺寸为28×28 的灰度图,卷积核个数为6,步长为1.这里首先通过MNIST测试集中的60 000张图片训练模型,然后对10 000 张样本图片进行预测操作,分别完成明文及密文预测(设置好支持预测图片数值的加密位数参数n)两类计算,再求各个图片预测准确度的平均值,得到明文是98.25%,密文是98.16%,密文对图片分类准确度的影响较小. 进而分析明文和密文关于CNN各层的执行时间占比平均值,如表3 所示,可以看出,密文计算对卷积层和全连接层的影响较为明显. 表3 明密文CNN各层执行时间占比对比表 进一步,分析密文计算整体各部分的执行情况,如图8 所示,最后两步操作,加随机数和解密,由于时间占比过小,在图中合并为一类. 分析实验结果,密文计算增加的功能,即图像加密、模型加密、加随机数和解密占比41.9%. 其中,模型加密耗时最多,为38.4%,是对卷积层和全连接层参数的加密操作. 密文计算各层共占比58.1%,其中卷积层和全连接层则占比达到54.4%. 从上述分析可知,卷积层和全连接层对密文计算效率影响大,这是后续应用中性能优化的重点部分. 图8 密文卷积预测模型各部分时间占比图 本文研究面向CNN 的区块链可信隐私服务计算模型,使用ON-DGHV 同态加密算法和区块链技术,以求加强服务计算中数据的安全、隐私保护和可信性,具有以下特点. (1)提供了一套服务计算的解决方案,改善了服务计算和数据隐私保护之间的矛盾,在享受云服务计算便捷性的同时,保护用户隐私安全,有助于资源、数据的有效整合,以及推动新技术的应用和发展. (2)探索同态加密和密文智能计算方法,并进行实践,寻求隐私服务计算的应用可行性. (3)区块链和智能合约技术贯穿业务全过程,加强服务和交易的可信性. 模型共享、服务等过程上链存证,权益评估智能合约化,可增加规则透明度,权责可追溯,权益可保障,增强隐私计算服务的实用性. 同时,数据隐私保护技术也可增强区块链和智能合约的安全性,扩展其应用范围. 本研究还在初步探索阶段,主要针对基础的同态加密算法、CNN 模型及数据集展开工作,后续还需要研究更多的加密和智能计算模型,实践更多的场景,根据场景研究提高准确度和效率的方法,并进一步挖掘区块链技术的融合机制,以求推动更深入、更广泛的应用.

3.3 预测服务权益评估模型



3.4 实现方法


4 实验与分析
4.1 算法对比实验

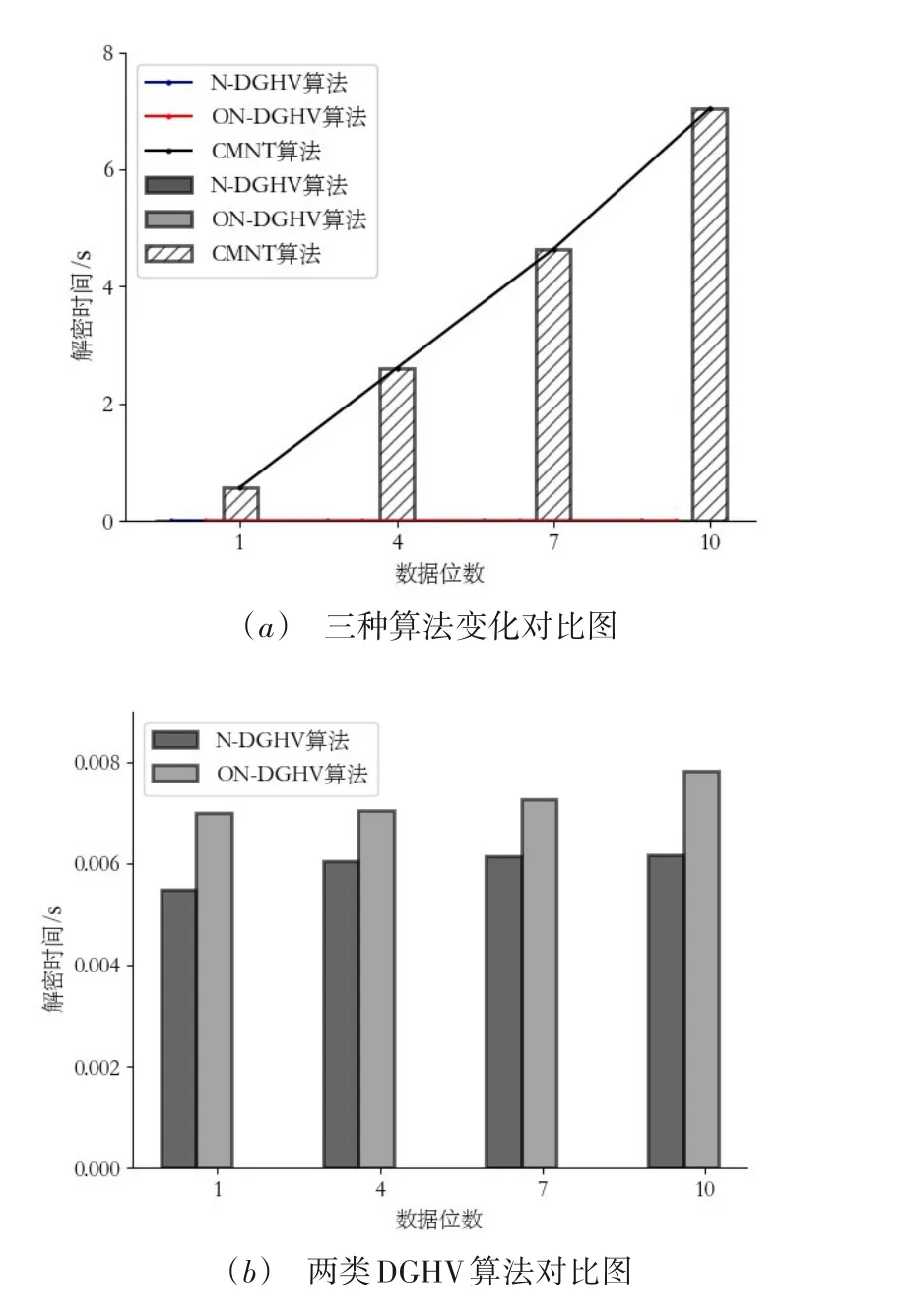



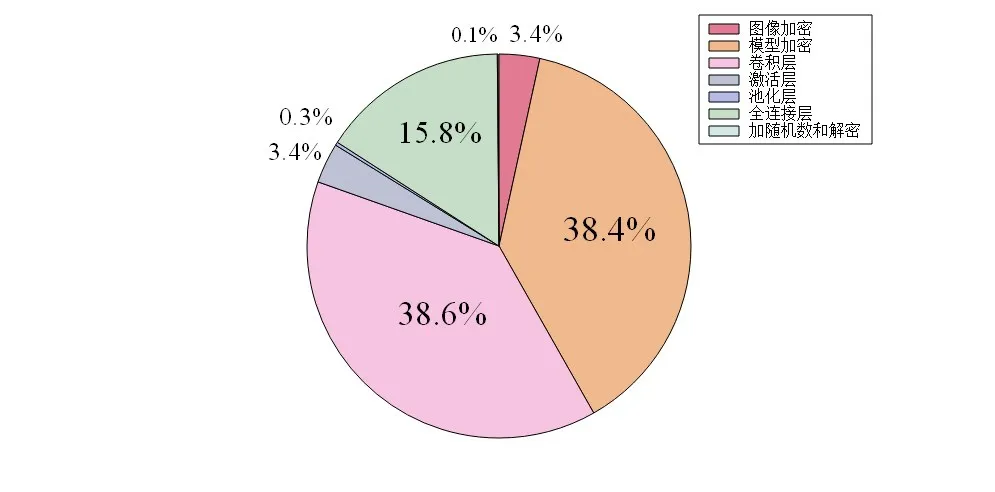
4.2 密文预测分析实验

5 结论
