基于轻量化人工神经网络的PCB板缺陷检测
2022-07-02王淑青鲁东林刘逸凡要若天
王淑青,鲁 濠,鲁东林,刘逸凡,要若天
(1.湖北工业大学电气与电子工程学院,湖北武汉 430068;2.华中科技大学武汉光电国家研究中心,湖北武汉 430074; 3.武汉大学电气与自动化学院,湖北武汉 430072)
0 引言
印制电路板(printed circuit board)简称PCB板[1],是一种重要的电子部件,作为元器件电气连接的载体,在电子设备中应用十分广泛。PCB板在生产校验过程中,其表面缺陷是大部分PCB板质量问题的来源[2]。常见的PCB板分为裸板与组装板两类,检测方法通常采用半自动化的人工检测方法,由于PCB裸板线路复杂,人工检测极易导致漏检、错检等情况,往往需要重复工序来保证合格度,检测效率低,人工成本高。主要检测方法包括在线测试、功能测试等,通过电气性质进行验证测试,这些方法虽然能够精准地检测出缺陷,然而测试流程不能复用、测试器具成本高、编写功能复杂等因素导致其应用受到限制。
随着深度学习以及神经网络的发展[3-4],使用机器视觉进行PCB板缺陷检测被广泛地研究,这种非接触式的自动化检测方法容易检测出微小模糊的缺陷,提升整个质检环节的效率。王涛等人提出一种改进的粒子群算法对PCB板进行检测,提高了收敛率与抗噪性能,然而检测结果依然受噪声影响较大[5];董静毅等人对图像分割方法以及机器学习检测方法在PCB板检测的应用进行了对比讨论,表明了人工神经网络在缺陷检测的优越性[6];J SHEN等人提出一种轻量级的检测模型完成对PCB板的缺陷检测以及字符识别等功能,结果表明对小目标的检测精度高,有良好的鲁棒性[7]。
在上述研究基础之上,为满足人工神经网络在移动端以及低成本微小型计算机上部署的需求,选择在目前检测精度较高的YOLOv5网络上进行改进,将其应用在PCB板表面缺陷检测中[8]。在主干网络中应用轻量化模型ShuffleNetV2结构,以减少网络计算参数,剔除冗余的特征图,在保证识别精度的情况下,大幅降低计算成本与内存占用。改进FPN模块,在增加有限计算量的情况下,增加上下文信息传递。使用PReLU函数代替ReLU激活函数,解决过大梯度流过时引发的神经元崩坏问题,提高模型的收敛性[9]。在扩充包含多个小缺陷的PCB裸板数据集上进行验证,实验结果表明,该方法训练速度快、模型结构和参数压缩、检测精度与效率较高。
1 系统总体方案与检测框架
1.1 系统方案设计
PCB板生产过程中制作环节极容易产生缺陷,会对后面的加工环节产生较大影响。目前PCB裸板的缺陷主要可分为开孔缺失、开路缺陷、短路缺陷、线路缺损、毛刺以及铜缺六大类,缺陷多为小目标缺陷,且背景与缺陷分离不明显[10]。基于企业检测需求,需要简化检测模型,提升小目标检测精度,在保证检测速度的情况下满足工业检测高精度的要求。
系统整体设计构架为:首先为保证获取PCB裸板图片的分辨率高,不缺失检测目标,采用分区域式图像采集。将PCB板划分为4个区域,使用相机平移和垂直移动进行拍摄,相邻区域有一定重合,这样既能规避因图像低分辨率而导致小目标缺陷未能识别,同时也能避免因图像边缘失真导致缺陷不完整。其次在服务器上用标注好的PCB板数据集对模型进行有监督的学习训练,调整参数获得最优权重。将训练好的模型移植到工业小型计算机中,适配PCB裸板缺陷检测,由机械臂或自动化分拣工具挑选出有缺陷的电路板。
1.2 YOLOv5算法框架
近年来,深度学习作为一项热门技术,可以通过提取对象深层次的特征来识别和定位目标,在工业检测领域得到越来越多的应用。目前主流的目标检测框架分为one-stage检测框架,如YOLO、SSD等[11];two-stage检测框架,如Fast-RCNN、Faster-RCNN等。one-stage算法的主要特征是直接通过主干网络来给出目标分类与位置信息,不使用RPN网络(区域推荐网络),速度更快,但由于候选区域未进行筛选,存在冗余信息,因此精确度比two-stage算法低。two-stage算法的主要特征是先提取感兴趣的CNN卷积特征,第一步训练RPN网络,第二步训练检测的网络,这样操作准确度更高,但速度比one-stage的算法稍慢。本文采用的YOLOv5网络构架如图1所示,主要分为Input,Backbone,Neck以及Output四个部分。
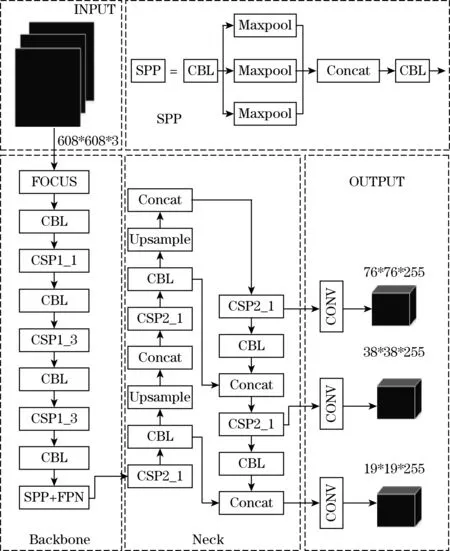
图1 YOLOv5s网络结构
(1)Input:内嵌数据增强,采用与YOLOv4同样的处理,对于小目标检测实现随机裁剪、缩放、排列的形式进行图片拼接。其次增加自适应锚框计算,在不同的数据集自适应地选择最合适的锚点值来初始化锚框。采用自适应图片缩放,针对不匹配的图片进行合适的裁剪填充,将尺寸归一化,提高网络的推理速度。
(2)Backbone:提出了Focus结构,对图片和特征图进行切片操作,分隔像素值进行采样来保持图片的原始信息。提取高度和宽度信息到Channels,使得Input channels提升为原来的4倍,再将新的图片进行卷积操作,得到无损失信息的二倍采样图。采用两种CSPNet结构,将梯度的变化融入到特征图内,增强梯度表现的同时减少计算量。
(3)Neck:采用SPP模块,自上而下,通过上采样得到的高、低特征层拼接,实现特征融合并得到新的特征图,而后通过PAN(路径融合网络)自下而上由弱到强传递特征,使得特征层实现更多的特征融合。
(4)Output:采用GIOU_Loss作为Bounding box的损失函数,相比较YOLOv4采用的CIOU_Loss,优化了非极大值抑制效果。
1.3 主干网络改进
近些年,人工深度神经网络的研究越来越成熟,在目标识别、图像分类、目标检测方面取得了很大的进展。一些主干网络例如ResNet和VGG等已经能够获取比较精准的图像分类,然而人工神经网络的网络层、参数量以及配置及要求不断增加[12-13]。复杂的网络模型通常包含大量参数量以及计算复杂度,其适用于成本高、即时性要求低的应用场景。而特定的场景,需要达到低延迟、高速率、低成本的要求,例如将深度神经网络模型应用在移动设备端或者微型计算机上,完成准确且快速的实时检测[14]。为了满足需求,一些轻量级的网络模型如MobileNet、ShuffleNet、GostNet等相继提出。ShuffleNet2针对内存消耗依旧过大等问题,在许多方面进行了适应性的改进,以满足更快更准确的要求,ShuffleNet2与ShuffleNet1的改进对比如图2所示。
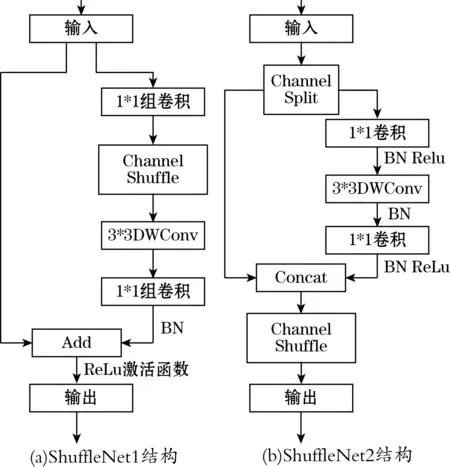
图2 ShuffleNet2与ShuffleNet1结构对比
ShuffleNet2主要根据4个重要指标对网络进行优化:
(1)ShuffleNet2的输入与输出通道设置为相同数量,使得内存消耗为最少。假定特征图大小为h×w,输入与输出的通道的数量分别为C1与C2,以宽和高的卷积为1*1为例。根据FLOPs和MAC计算公式:
B=h·w(C1*(1*1)*C2)=h·w·C1·C2
(1)
MAC=h·w·C1+h·w·C2+(1*1)*C1*C2=h·w(C1+C2)+C1·C2
(2)
由均值不等式
(3)
从而
(4)
式中:B为FLOPs(每s浮点运算次数);w、h分别为特征图宽和高;MAC为网络层内存访问及读写消耗成本。
故当C1=C2,即输入通道与输出通道相等时,内存消耗量最小。
(2)ShuffleNet2减少了分组卷积的使用。虽然分组卷积在神经网络的应用能够减少参数量,然而单方面的参数量减小并不能直接提升模型速度,大量使用分组卷积会显著增加MAC。同样假定特征图大小为h×w,输入与输出的通道的数量分别为C1与C2,以宽和高的卷积为1*1为例,分组数为g。每个卷积核会单独与C1/g个Channel内包含的特征进行卷积操作,此时FLOPs和MAC计算公式为:
(5)
(6)
MAC与FLOPs的关系为:
(7)
可以看出在FLOPs不变的情况下,分组越多,内存访问消耗成本就会越大。
(3)ShuffleNet2减少了网络分支的数量。通常来讲,网络的结构与参数量共同影响计算速度,分支加量比层数加量更加影响推理速度。
(4)ShuffleNet2减少了能够增加内存消耗的Element-wise(基本元素操作),这些操作包含Add、Relu、short cut等。虽然元素操作只增加少量FLOPs,然而其映射到MAC上就会造成一定量的内存损耗与时间损耗,因此其造成的内存消耗也不容忽视,减少元素操作的比重可以减小内存消耗。
ShuffleNet2引入一种新的运算方式channel split,特征图输入时将通道平均分为2个分支,2个分支做同等映射操作,分别都包含3个连续的卷积;将输入通道与输出通道设置为相同,同时不再采用组卷积;2个分支在分成2个组后,其有相对独立的特性,组合方式由concat(连接)代替Add(相加),满足式(5)和式(6)中提及的不增加分支数量以及减小Element-wise操作。在完成不同分值特征提取后,对2个分支连接起来的结果采取channel shuffle(通道随机洗牌),保证2个通道的特征能够交错从而不会丢失特征信息,这样操作使得网络不需要通过大量地concat来保证特征信息的完整性。下采样过程中,每个分支直接保留输入的信息,随后将这些分支连接在一起,最终使得特征图的空间减小为一半,而通道数翻倍。
根据ShuffleNet2的特点,在YOLOv5s网络的基础上,将主干网络部分原始卷积Conv与C3模块替换为Inverted Residual卷积模块,同时根据式(1)原则设置主干网络的输入输出通道数相等,经过优化后的主干网络在最后输出层前保留SPP模块,有利于整合输出尺寸与多尺度特征融合,改进的主干网络结构如图3所示。

图3 改进backbone结构对比
1.4 特征金字塔模块改进
在PCB板的检测中,缺陷大多为小目标,因此需要增强网络对于小目标的特征提取能力。ShuffleNet2添加小卷积核来提取对于小目标的检测,然而模型在堆积更多的卷积层后,由于不同大小的感受野之间缺乏交流,模型的特征表达能力不足,容易引发特征分辨率与感受野冲突,无法将两者有效结合[15]。
目标检测中,为确保高分辨率输入特征接收完整,通常采取的累积卷积层操作会增加网络结构的复杂度。因此在不堆叠网络结构的基础上,提出在FPN模块的基础上添加2个新的模块CEM(上下文抽取模块)和AM(注意力引导模块),结构如图4所示。
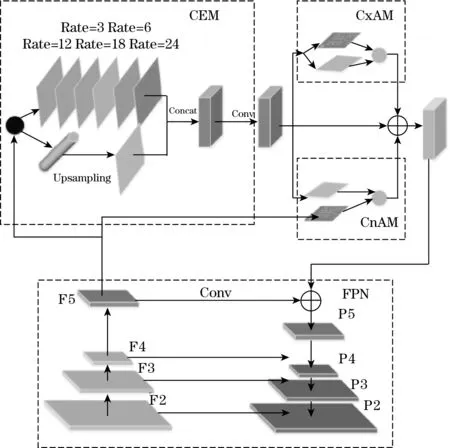
图4 改进的FPN模块
CEM接收自下而上通道采集的特征信息,通过不同比率的多路径扩展卷积,使上下文的信息表达丰富。可分离的卷积层使获取的特征图来自于不同的感受野,在不同比率路径中使用可变卷积,提高了空间变换建模的能力,将不同维度学习的特征归一化。连接方式采用密集连接,将每个扩展层的输入输出相连,共同传递到下一个扩展层,有效地整合多尺度特征信息,从而加强上下层之间的特征强传递。
AM由CxAM和CnAM两个部分组成,主要为了剔除CEM接收的感受野中冗余的信息,消除在语义与位置间传递的错误信息。
CxAM(上下文注意力模块)可以获取不同子区域之间的语义依赖,当包含多尺度感受野的特征信息传递进来时,CxAM通过提炼各个子区域之间的相关性,使得输出特征语义更加清晰。
CnAM(内容注意模块)会捕捉更为精准的目标位置信息,使用卷积层对特定特征映射进行转换,消除因可变卷积操作导致的图像位置偏移与几何信息损坏。
1.5 激活函数改进
主干网络采用的ShuffleNet2结构,其卷积层激活函数为ReLu激活函数,为非饱和激活函数,也是目前人工神经网络比较常见的激活函数,其计算公式为:

(8)
ReLu的两大优势为克服了梯度消失问题以及提升了训练速度[16]。然而使用ReLu激活函数也有缺点:训练时当负值或非常大的梯度流过神经元时,会造成ReLu神经元“死亡”,无论之后怎样更新参数,神经元的梯度为0,同时ReLu的输出为非负数,梯度更新的随机性差。为了解决上述不足,采用其变体函数PReLu激活函数来代替ReLu,其结构对比见图5。
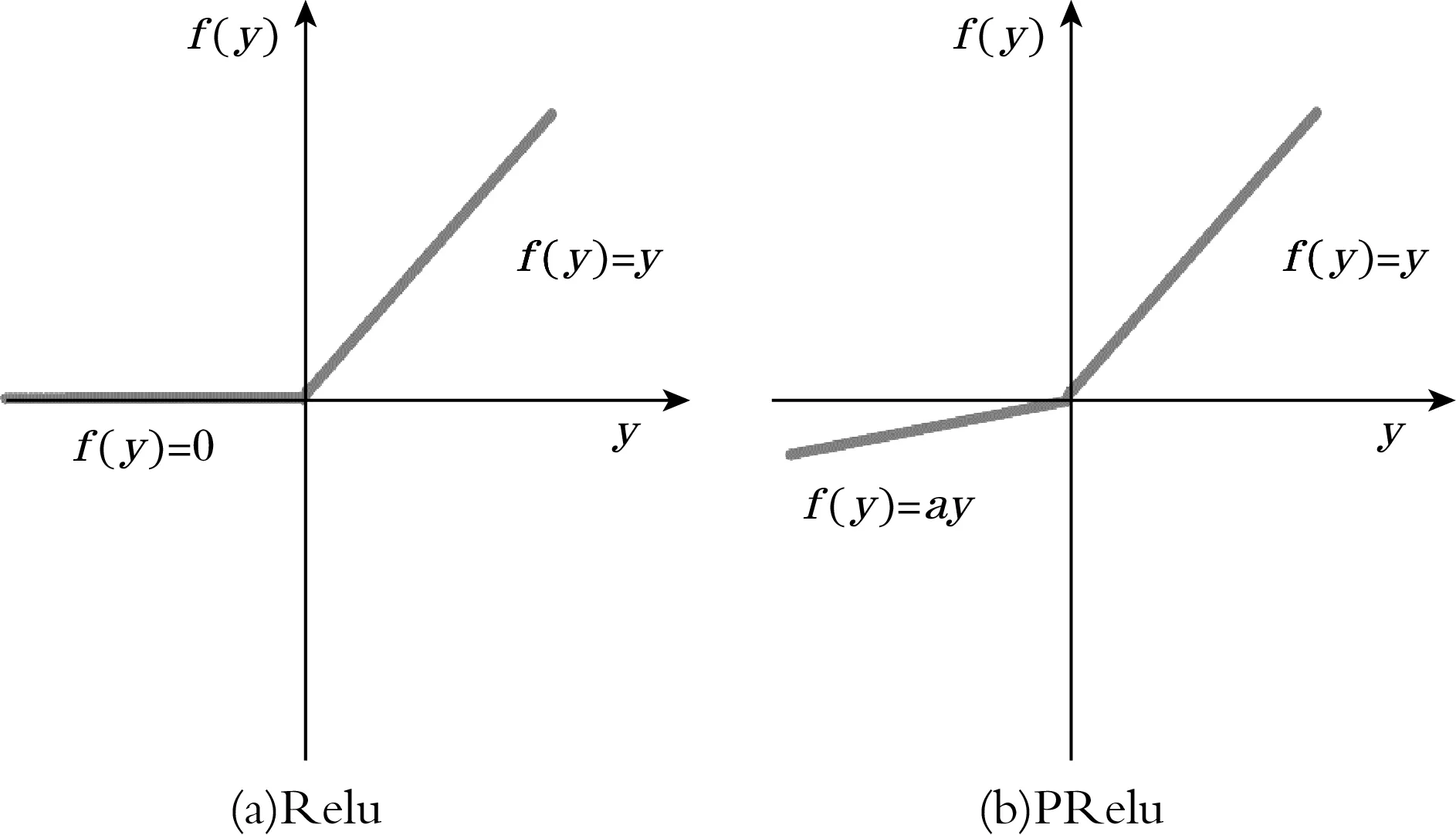
图5 激活函数结构对比
PReLu在ReLu以及Leaky ReL的基础上进行了优化,不仅解决了ReLu的两大缺点,同时也解决了Leaky ReLu无法学习导致对于正负结果预测不一致的缺点,其计算公式为:
(9)
式中:α为0到1正态分布的随机数;i为不同的通道。
PReLu在反向传播的过程中,当激活函数值小于0时,仍可以给出一个非零的计算梯度,在模型只增加极少参数的情况下解决了反向神经元崩坏的问题。并且随机学习动量因子α满足0到1的正态分布,在反向传播过程中增加了梯度的随机性,提高参数的泛化性,避免陷入局部最优。
2 算法实验与测试
2.1 数据图像采集及预处理
训练数据图片部分来源于公开PCB板缺陷数据集,由于缺陷种类及数量不足,可能影响模型泛化性,因此在原图片集基础上,通过工厂实际拍摄扩充图片,并将部分无缺陷样本采取人工合成缺陷的方式加工为包含多种缺陷的样本。采取随机翻转、加噪等方式对差异大、数量少的缺陷扩充样本容量[17]。最后得到4 000张图片,采集的缺陷种类如图6所示,将图片数量按照9:1划分训练集与测试集。
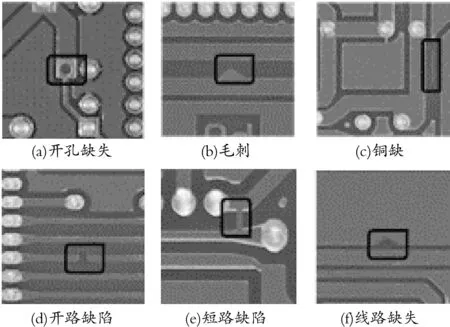
图6 PCB板缺陷种类
2.2 模型配置及训练
本实验环境为Ubuntu16.04操作系统,采用pytorch框架,GPU为GeForce RTX 2070 SUPER,内存为16 GB,加速库为CUDA 11.1.96。
采用Labelmg标注工具对数据集进行标注。划分为6种缺陷。选择预训练模型为改进后的YOLOV5s模型。训练优化采用Adam算法,Batch-size设置为16;总迭代次数设置为800次;动量因子值为0.9;权重衰减系数设置为0.000 5;采用预热重启更新学习率,初始学习速率设置为0.001。本文选取的评价指标为精准度(Precision)、召回率(Recall),经过平滑后的训练结果曲线如图7所示。

图7 改进算法的精准度与召回率曲线
在训练集上对改进后的算法模型与原算法模型分别进行对比实验,两种算法的模型性能参数对比如表1所示。

表1 算法性能参数对比

从图7可以看出轻量化后的模型训练效果较好,精准率与召回率迭代至550轮左右趋于稳定,数值较高且较快地收敛,符合轻量化目标检测模型在小型计算机平台上的检测精度与速度要求[18]。精确率P和召回率R的计算公式如式(10)所示:
(10)
式中:TP为正类预测为正类的数量;FN为正类预测为负类的数量;FP为负类预测为正类的数量。
2.3 检测效果及算法性能分析
在测试集对PCB裸板缺陷进行测试。测试图片包含600个缺陷样本,查准率为98.3%,误检率为3.2%,漏检率为0.6%。验证结果如图8所示。
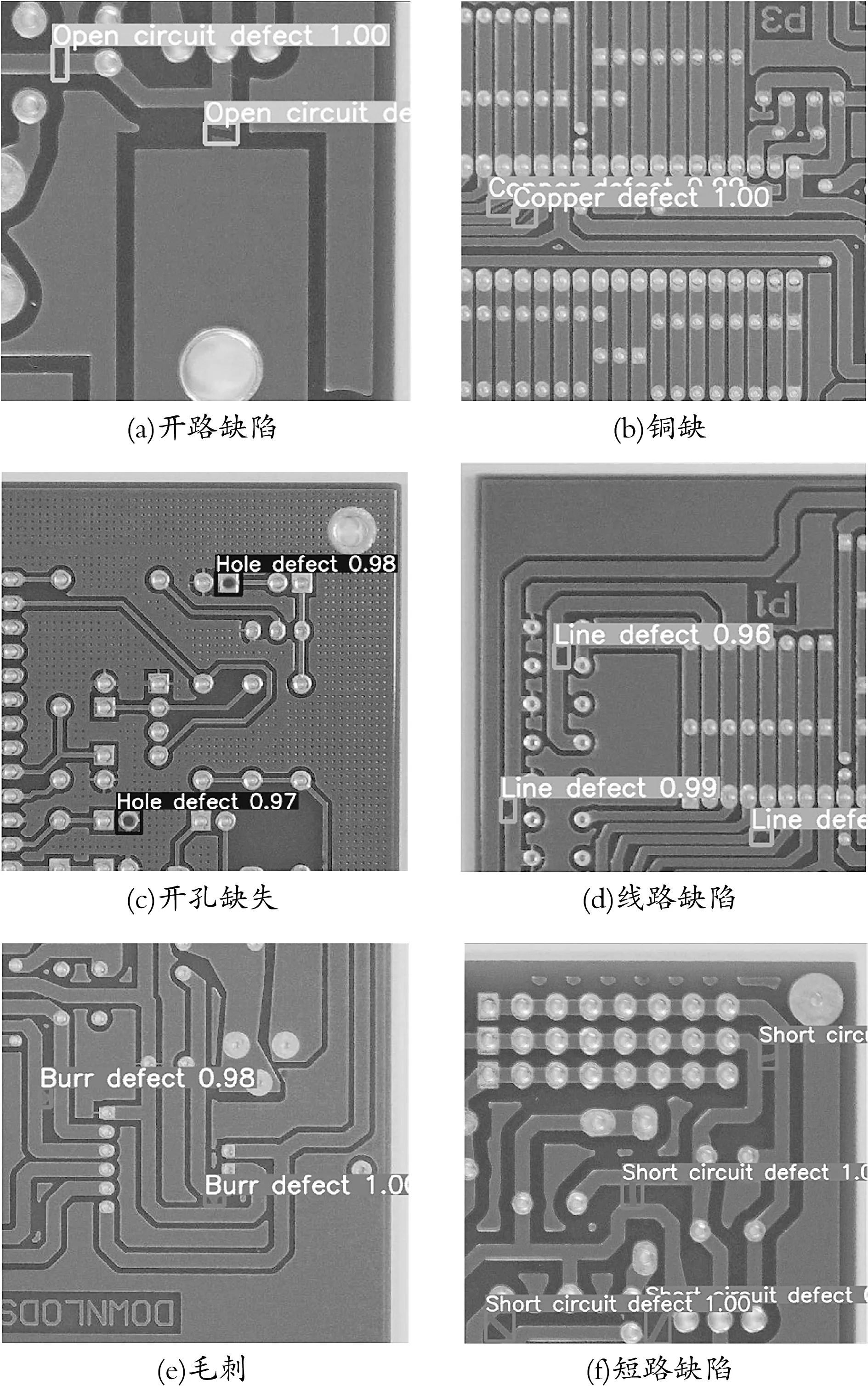
图8 测试集PCB板缺陷检测效果
图8中检测框上的数值表示置信度,即判定该缺陷属于这类缺陷的概率,最高为1。在查准的情况下,置信度越高,代表检测效果越可靠;在误检的情况下,置信度通常较低,表明检测目标无缺陷或误检为其他种类缺陷[19]。
由于线路开路与铜缺等类型的缺陷与少量PCB板正常纹路接近,模型提取这类缺陷特征时存在干扰,会造成误检的情况,生产中通常设置一定置信度阈值将误检样本进行筛除。总体上检测精度较高,置信度均值在90%以上,可以将该算法应用于PCB板质量检测中。
将改进后的网络算法与原网络算法、Faster RCNN、YOLOv4三种算法进行对比,在硬件平台相同的情况下,尽量保证适合每种算法最优的输入图像尺寸与训练批次。测试结果如表2所示。
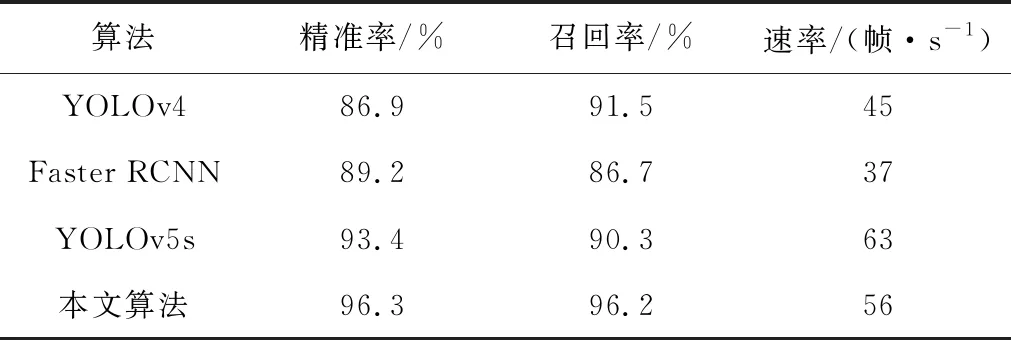
表2 4种算法性能指标对比
由表2可知,本文算法在精准率提高的同时,检测速率也进行了优化;与YOLOv4、Faster RCNN、YOLOv5s相比,精准度分别提升了9.4%、8.1%和2.9%,召回率分别提升了4.7%、9.5%和5.9%。在检测速度上,由于运行内存占量的大幅下降,改进后的算法比原网络稍低,但也达到了56帧/s的检测速率,完全能够满足生产线实时检测的要求[20-21]。
3 结束语
本文针对人工PCB板缺陷检测效果较差、传统人工神经网络参数多、计算力要求高、无法在小型计算机上部署的问题,提出优化YOLOv5s算法,使用ShuffleNet2轻量化模块改进主干网络,大幅降低了参数量与计算力。在FPN模块添加上下文抽取和注意力机制来增强上下文表达和特征信息传递。在神经元上使用PreLu激活函数来解决训练中神经元崩坏的问题。
改进后的算法检测精度提高,同时压缩模型,降低硬件要求,能够实现工业小型计算机系统对PCB板实时检测需求。由于样本容量有限,一些缺陷类别训练样本较少,存在少量正常线路误检的问题,后续将会扩展缺陷样本、继续优化算法,完善对更多小目标缺陷的检测识别。
