基于Transformer网络的机载雷达多目标跟踪方法
2022-07-01李文娜张顺生王文钦
李文娜 张顺生* 王文钦
①(电子科技大学电子科学技术研究院 成都 611731)
②(电子科技大学信息与通信工程学院 成都 611731)
1 引言
数据关联是多目标跟踪技术的关键部分,它在侦察和监视任务中起着至关重要的作用。数据关联一直是机载雷达界的一个重要研究课题,因为它具有提升机载雷达系统多目标跟踪性能的潜力。传统的多目标跟踪数据关联算法可以分为两类:一类是基于极大似然的数据关联算法;另一类是基于贝叶斯的数据关联算法[1]。
基于极大似然的数据关联算法通过计算目标与量测的相关似然函数值,寻求目标与量测匹配的最佳方式。数据关联是组合优化问题的一个例子,而多目标跟踪问题被视为二维分配问题[2]。匈牙利算法(Hungarian Algorithm,HA)是解决分配问题的算法之一,它通过最大化对数似然函数的总和来最小化目标的估计分配成本[3]。由于所有量测都与所有预测状态进行比较,因此该算法也称为全局最近邻算法。但在复杂场景中,尤其有噪声干扰时,HA的效果并不理想。
常用的基于贝叶斯的数据关联算法包括多假设跟踪器(Multiple Hypothesis Tracker,MHT)和联合概率数据关联滤波器:它们是通过生成一组假设或目标与量测的关联概率来解决数据关联问题。MHT通过使用贝叶斯极大后验估计给假设赋值[4],但MHT生成假设的数量会随着目标数和雷达扫描数呈指数增长。概率数据关联滤波器采用贝叶斯方法通过后验概率密度函数找到量测与目标的分配概率来解决数据关联问题[5]。然而,概率数据关联算法仅有效处理杂波背景下的单目标数据关联问题[6]。联合概率数据关联算法(Joint Probabilistic Data Association,JPDA)可以解决多目标数据关联中量测同时落入多个跟踪波门的问题[7]。JPDA采用穷举法计算互联事件发生的概率,但随着目标数量的增加,联合事件数目呈指数增长,导致算法的计算量巨大甚至出现组合爆炸的情况[8,9],因此该算法在实际工程中不易实现。
目前的许多研究表明神经网络可以解决匹配问题[10]。神经网络并不需要计算复杂的概率分布,而是通过学习训练样本,优化隐藏参数,使其最准确地拟合训练集,从而本质上逼近所需的函数。Lee等人[11]提出使用深度神经网络来解决分配问题,但仅适用于分配问题受到1-1约束的情况。Milan等人[12]提出了基于循环神经网络的算法来解决旅行商问题,但该算法没有考虑传感器存在杂波和漏检的情况。对于雷达领域的多目标跟踪问题,Liu等人[13]的研究表明,基于LSTM的模型比JPDA和HA等经典模型具有更好的关联性能,但是该模型只考虑了简单杂波环境下的数据关联问题。Verma等人[14]提出基于双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)的算法用于解决数据关联问题,并表明Bi-LSTM在高效训练和性能方面优于基于LSTM的模型,但是该算法仅考虑了无漏检情况下的数据关联问题。Vaswani等人[15]提出Transformer模型,并在自然语言处理领域和计算机视觉领域得到广泛应用,例如问答系统[16]、文本摘要[17]、语音识别[18]和视觉跟踪[19–21]等。
针对传感器存在漏检及虚警情况下的数据关联问题,本文提出了一种基于Transformer网络的多目标跟踪数据关联(Data Association,DA)算法(Transformer-DA)。为了使网络适用于量测数未知的情况,本文提出了一种掩蔽交叉熵损失与重叠度损失相结合的损失函数(Masked Cross entropy and Dice,MCD)用于模型训练。此外,所提算法是基于数据驱动的深度学习网络算法,不需要事先知道目标运动模型和杂波密度等先验信息。
2 数据关联模型
假设跟踪n个目标,雷达扫描开始时间为t1,结束时间为t2,在此期间进行N次扫描,第k次扫描的量测集Z(k),k=1,2,...,N定义如下:
为了更好地表示传感器的漏检和虚警,引入了虚拟量测[22]的概念,通过向每个集合Z(k)添加一个索引为i=0的虚拟测量来重新定义式(1)。

其中,代 表虚拟量测,mk代 表k时刻量测的数目。目标的状态估计集Γ(k),k=1,2,...,N定义如下:
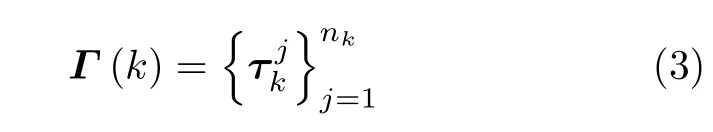
在本节中,我们处理有检测歧义的情况。具体而言,做出以下假设:一是在每次扫描中传感器可能存在漏检;二是传感器可能会产生虚警。假设意味着每次扫描中量测的数量是变化的并且不等于目标的数量。这看似简单但对有检测歧义的情况下开发模型至关重要。通过引入定义数据关联的决策变量来构建Transformer-DA模型,首先定义了决策变量,然后开发了一个目标函数来量化数据关联问题的解决方案,最后提供了目标函数的约束条件。
2.1 决策变量
在跟踪过程中处理航迹和量测的关联问题时,会出现量测落入不同目标跟踪波门重叠区域的情况,这时候需要综合分析每个量测的来源情况。我们引入二进制变量并定义如下:

2.2 目标函数
在本节中,定义了一个目标函数,用于衡量数据关联问题解决方案的质量。定义表示在k时刻目标的估计量测位置,其中F(·)为状态转移函数,H(·)为 量测函数。在k时刻分配给目标j的 量测给 出,因此在k时刻目标j的 估计质量由式(5)给出

因此,多目标数据关联的分配成本C(ω)由式(6)给出
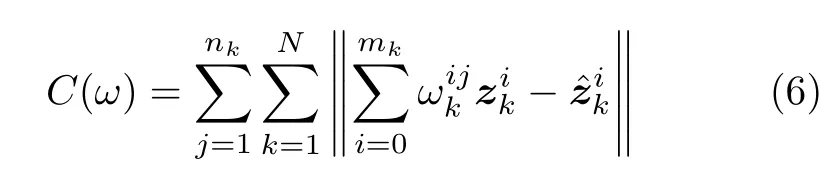
为了找到使得成本最低的分配,我们需要在所有分配中最小化成本C(ω)。可以分析得知,当所有量测与所有航迹一一正确关联时,可得到最小的C(ω)。
2.3 约束条件
一个量测最多分配给一个目标,若量测没有与目标关联,则为杂波,此约束如式(7)所示:
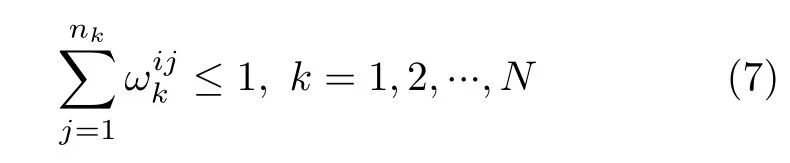
一个目标最多只被分配一个量测,若目标没有与任何量测关联,即为漏检,此约束如式(8)所示:
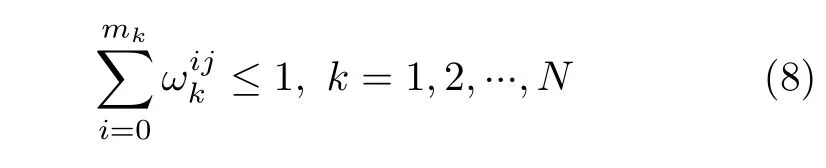
将上述目标函数和约束条件合并,即可得到用于存在杂波和漏检情况的数据关联模型,表示如下:
最小化:

本文将上述数据关联问题制定为在尽可能多的目标上执行的分类任务。对于不同的目标采用整体网络架构。我们的目标是找到与目标相对应的量测。量测来源的不确定性和传感器存在漏检的可能性,使得数据关联问题复杂化。对此,我们使用Transformer网络来解决这个问题。
3 Transformer-DA网络
在上文中介绍了存在漏检和杂波情况下的数据关联模型。接下来,我们将原始多航迹与多量测的关联问题重新表述为多个分类子问题。
每个目标与所有量测的匹配如图1所示。输入S是目标j的4个历史状态,Z为k时刻的所有量测,在预测每个目标的量测分配中,网络将输出一个匹配向量,它是目标与在时间k的所有量测的分配概率,漏检的目标与虚拟量测关联,即图1中紫色目标关联到虚拟量测。接下来,我们将介绍图1中的Network结构。
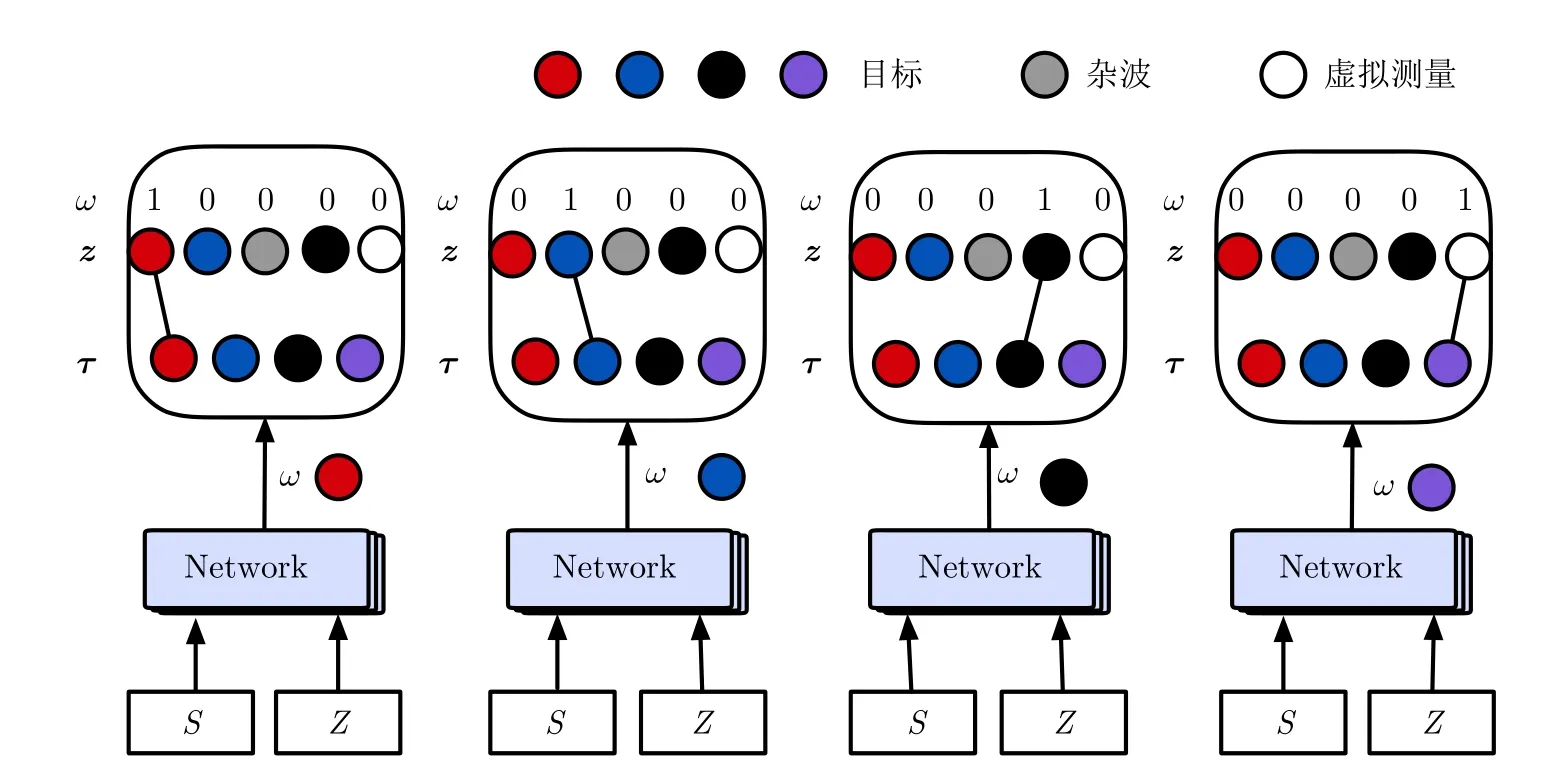
图1 每个目标与所有量测的匹配关系示意图Fig.1 A diagram of the matching relationship between each target and all measurements
3.1 嵌入注意力机制的Transformer-DA结构
作为一种特殊的查询键机制,Transformer很大程度上依赖注意力机制来处理所提取的深度特征。假定一组序列对〈X,Y〉,Transformer的结构可以通过调整参数去拟合序列对的映射关系。注意力机制和所提Transformer-DA网络结构如图2所示。图2(a)所示为注意力计算部分,其中,Query和Key先进行矩阵相乘,然后通过Scale缩放到0和1之间,再通过Softmax得到注意力分数,最后与Value相乘得到最终输出。图2(b)是所提出的Transformer-DA网络结构,网络结构可分为两部分,左边为网络的编码器结构,右边为网络的解码器结构。在编码器的前端加入了全连接层用于特征提取,并在解码器的输出加入了多层感知机用于类别预测。输入序列通过全连接层和位置编码后进入多层编码器中,其中每一层由多头注意力机制、层正则化和前向传播模块组成,同时加入了残差连接可防止梯度消失。
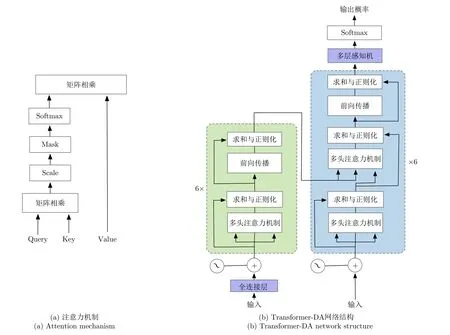
图2 注意力机制与Transformer-DA网络结构Fig.2 Attention mechanism and Transformer-DA network structure
量测隐式地表示在解码器查询中,这些查询是解码器用于输出关联概率的嵌入。解码器在两种类型的注意之间交替:一是对所有查询的自我注意力机制,它允许对所有量测进行联合推理;二是编码器-解码器注意力机制,这使得查询可以全局访问编码器中的信息。Transformer的置换不变性要求对网络的输入加上位置编码。
3.2 基于Transformer-DA网络的多目标跟踪方法
我们设计了基于Transformer-DA网络的多目标跟踪框架,如图3所示。考虑到航迹与量测的正确匹配与目标的运动学特征有重要关系,使用了每个目标前4个历史状态,即目标k-4,k-3,k-2,k-1时刻的估计状态;然后对每个目标的4个历史状态进行Flatten操作后作为输入,n个目标就得到了编码器的输入序列;然后将k时刻的所有量测输入到Transformer-DA解码器中得到量测与航迹的关联概率;最后将关联概率输入到卡尔曼滤波器中以输出多个目标在k时刻的估计状态。
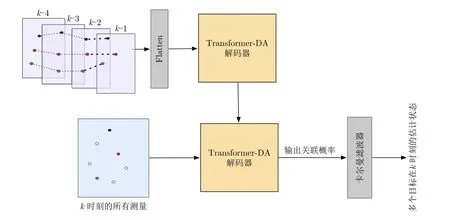
图3 基于Transformer-DA的多目标跟踪框架Fig.3 Multitarget-tracking framework based on Transformer-DA
3.3 MCD损失函数
我们设置了Transformer-DA解码器输入的最大量测数,当k时刻的量测数目没有达到最大量测数时,将会对k时刻的量测使用0值填充,并使用1标记真实量测,0标记填充的量测,然后将标记组成mask向量。为了避免填充量测对损失的计算造成影响,在交叉熵损失函数的基础上做了改进得到Lossmask。由于多目标场景中存在杂波数比目标的真实量测多的情况,这样会导致样本的不均衡,为了推动模型更加关注学习目标与正确量测的关联概率,引入Dice损失 Lossdice。最终使用的MCD损失函数为上述两种损失之和,用式(11)表示:

其中,pi表 示预测关联概率,yi表示真实关联概率,γ为平滑项,取值为1防止损失上溢。
4 实验分析
4.1 网络参数及评估指标
本文基于Ubuntu16.04系统进行实验,使用深度学习的框架是Tensorflow。实验的硬件配置:CPU为Intel(R)i5-10400F,GPU为GeForce RTX 3080 Ti,内存为16GB,使用CUDA11.1调用GPU进行训练加速。训练过程中,使用Adam优化器进行参数更新,实验设置的初始学习率为0.001,模型采用从头训练的方式,训练的batch size取256。
本文的多目标跟踪算法中使用的是基于匀速运动模型的卡尔曼滤波算法,Transformer-DA使用的目标状态特征为:[t,x,vx,y,vy],其中t,x,vx,y,vy分 别表示时间间隔、在x轴 方向的位置、在x轴方向的速度、在y轴方向的位置、在y轴方向的速度;网络使用的量测特征为[t,R,α,θ],其中R,α,θ分别代表径向距离、方位角、俯仰角。Transformer-DA网络的参数如表1所示。
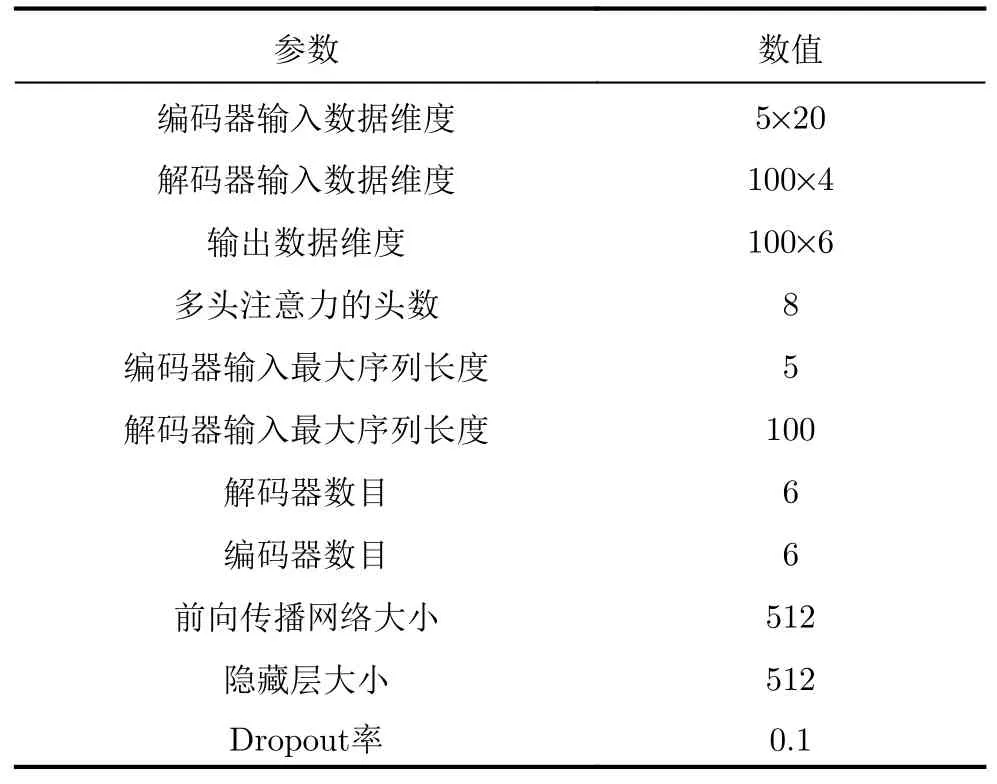
表1 Transformer-DA网络参数Tab.1 Transformer-DA network parameters
本文在实验中使用最优子模式分配[23](Optimal Sub-Pattern Assignment,OSPA)距离指标来评估不同算法的跟踪性能。均方根误差的前提是所有估计的点迹之间存在着一一对应关系,但是在大多数的多目标场景中,跟踪算法往往做不到在每个时刻建立这种对应关系。
多个目标的真实状态集Φ={φ1,φ2,...,φm},其中φi={φi1,φi2,...,φiN};多个目标估计状态集其 中m和n分别表示实际目标数和估计目标数,N表示扫描次数是两个集合中所包含的元素,分别表示在一定探测时间内目标的真实状态和估计状态是两个集合中包含的元素,分别表示目标i在时间j ∈[1,N]时的真实状态和估计状态。OSPA的计算如下:

其中,Πn表 示从集合中取m个元素的所有排列组合,排列组合数‖·‖表 示2范数表示所有目标的真实点迹与估计点迹之间距离相差最小的一组,c和p分别为距离敏感性参数和关联敏感性参数。
4.2 仿真数据实验
4.2.1 训练数据及参数设置
在仿真实验中,我们分别仿真了多种运动模式的轨迹共1000条,每5条轨迹形成一个多目标场景,总计仿真了200个多目标场景,其中60%用于训练,20%用于验证和20%用于测试。通过在轨迹数据上加入均值µ=0、方差δR=100 m,δα=0.5°,δθ=0.5°的高斯噪声坐标转换到空间直角标系下模拟目标的量测,并加入均匀分布的杂波点来模拟环境的干扰。杂波在目标运动场景内服从均匀分布,杂波数服从密度为λ的泊松分布[24]。杂波数的期望定义为:Eλ=λ(xmax-xmin)(ymax-ymin),其中xmax和xmin分别代表运动范围内x坐标的最大值和最小值,ymax和ymin分别代表运动范围内y坐标最大值和最小值。
4.2.2 仿真场景
为了更好地展示目标的跟踪结果和比较不同算法的跟踪性能,将所有量测通过坐标转换统一使用笛卡儿坐标系显示。图4为杂波数的期望Eλ=80,检测概率pd=0.99时的仿真轨迹与量测图。在图4所示场景中,每种颜色的量测点对应同一颜色的目标,5个目标在观测范围内沿不同方向匀速直线运动,采样间隔为1 s,总采样次数为47。4个目标在第17到第23采样时间范围内发生了第1次交叉,2个目标在第38到第40采样时间范围内发生了第2次交叉。
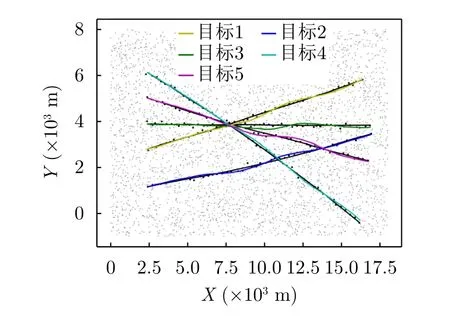
图4 E λ=80,p d=0.99时的仿真轨迹与量测Fig.4 Simulation trajectory and measurement when Eλ=80,pd=0.99
4.2.3 实验结果与分析
图5展示Eλ=80,pd=0.99时不同算法的跟踪结果,图6显示了4种算法的OSPA距离对比,其中OSPA的参数为p=2,c=500 。在k=10之前存在Transformer-DA算法的OSPA距离高于JPDA算法和Bi-LSTM算法的情况,这是由于不同算法确定的量测不相同,会影响协方差的更新和滤波增益,进而影响跟踪结果。在第1次目标交叉中,多个目标的相互靠近产生了较为复杂的数据关联问题,可以定性地分析得到,HA算法的OSPA距离最大。在目标发生数据关联后,JPDA,Bi-LSTM的OSPA距离呈上升趋势。HA在两次交叉中的OSPA距离都会明显增大。然而,本文所提出的Transformer-DA算法的OSPA距离总体来说最小。

图5 E λ=80,p d=0.99时不同算法的跟踪结果(使用仿真数据)Fig.5 Tracking results of different algorithms when E λ=80,p d=0.99 (using simulation data)

图6 E λ=80,p d=0.99下不同算法的OSPA距离(使用仿真数据)Fig.6 OSPA distance of different algorithms when Eλ=80, p d=0.99 (using simulation data)
不同检测概率下的OSPA距离如表2所示,通过分析可以得到,HA算法受检测概率的影响较大,Bi-LSTM算法受到检测概率的影响较小,本文所提出的Transformer-DA算法在不同检测概率下的OSPA距离都最小。
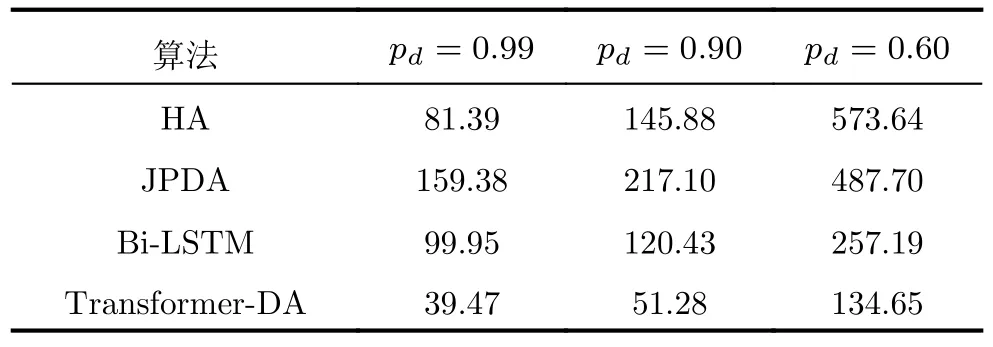
表2 使用仿真数据时算法在不同检测概率下的OSPA对比Tab.2 OSPA comparison of the algorithm under different detection probabilities when using simulation data
4.3 真实轨迹数据实验
为了进一步评估所提多目标跟踪算法的有效性,我们使用了实际的目标轨迹进行实验,由于缺少真实量测数据,通过使用4.2节中加高斯噪声的方法模拟量测。本节实验使用的实际轨迹共750条,每5条轨迹形成一个多目标场景,总计150个多目标场景,其中60%用于训练,20%用于验证和20%用于测试。
机载雷达工作在X频段,信号带宽为20 MHz,脉冲重复频率为1000 Hz。跟踪的目标为空中目标,均作变速运动,其中目标4的轨迹存在机动转弯。
4.3.1 真实场景
Eλ=80,pd=0.99时的真实轨迹与仿真量测如图7所示。在第55到第80扫描时间范围内,目标2和目标4会产生数据关联问题,将会导致量测同时落入两个目标的跟踪波门内。
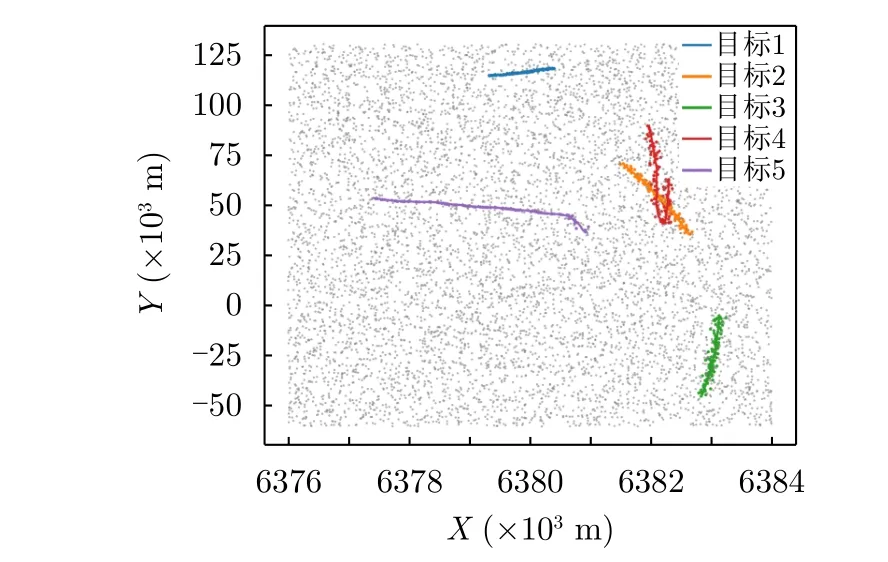
图7 E λ=80, p d=0.99时的真实轨迹与仿真量测Fig.7 Real trajectory and simulation measurements when Eλ=80,pd=0.99
4.3.2 实验结果与分析
图8展示了参数为Eλ=80,pd=0.99下不同算法的跟踪结果,图9显示了4种算法的OSPA距离对比,其中OSPA的参数为p=2,c=2000。在第55到第80扫描时间范围内,目标的相互靠近产生了较为复杂的数据关联问题,可以定性地分析得到,HA,JPDA和Bi-LSTM算法的OSPA距离都会增大,其中,HA算法受到的影响最大。然而,本文所提出的Transformer-DA算法的OSPA距离总体来说最小。

图8 E λ=80,p d=0.99时不同算法的跟踪结果(使用实际数据)Fig.8 Tracking results of different algorithms when E λ=80,p d=0.99 (using actual data)
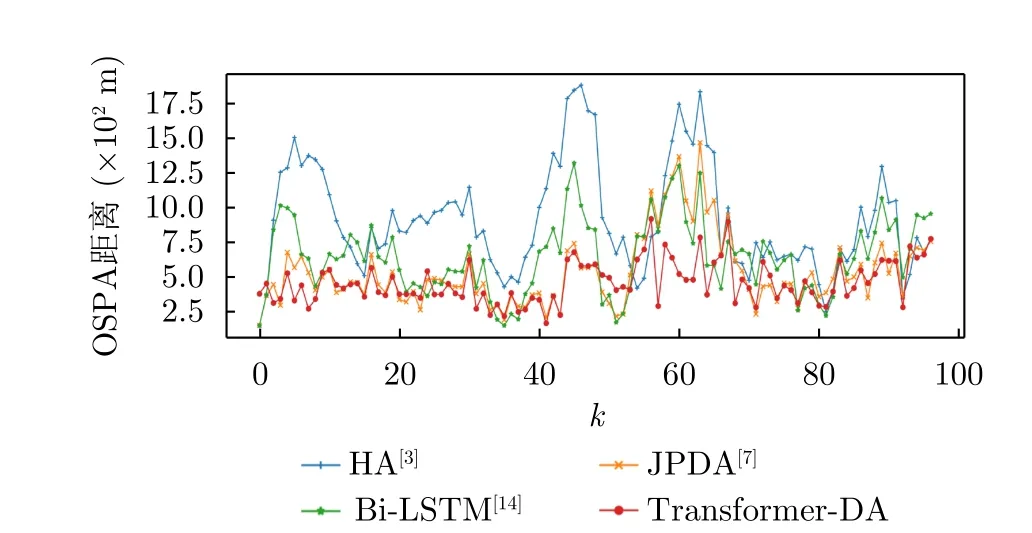
图9 E λ=80,p d=0.99时不同算法的OSPA距离(使用实际数据)Fig.9 OSPA distance of different algorithms when Eλ=80,p d=0.99 (using actual data)
不同检测概率下的OSPA距离如表3所示,通过分析可以得到,HA算法受检测概率的影响较大,Bi-LSTM算法受到检测概率的影响较小,JPDA在检测概率较高时的OSPA距离比HA和Bi-LSTM算法小,本文所提出的Transformer-DA算法在不同检测概率下的OSPA距离都最小。

表3 使用实际数据时算法在不同检测概率下的OSPA对比Tab.3 OSPA comparison of the algorithm under different detection probabilities when using actual data
本文通过引入虚拟量测这一概念,使得Transformer-DA算法可以适用于目标漏检的情况。对4.2节和本节实验的数据分析可以得到在不同检测概率条件下所提Transformer-DA算法识别漏检目标的准确率,如表4所示。

表4 不同检测概率下所提算法识别漏检目标的准确率(%)Tab.4 The accuracy of the proposed algorithm to identify missed targets under different detection probabilities (%)
4.4 算法复杂度对比分析
JPDA算法的运算复杂度为O(mn+MM+NM+Nn+NF+nMN),其中M为落入跟踪波门的量测数,N为可行联合事件数,F为杂波数;H A算法的运算复杂度为O(mn);Bi-LSTM算法的运算复杂度为O(nd2),其中d为隐藏状态大小;本文所提算法的运算复杂度为O(n2d+m2d)。当目标数和量测数较多时,JPDA算法产生的可行联合事件数N的值会很大,此时JPDA算法的计算复杂度最大。在所有算法中,HA算法的复杂度最低,本文所提算法比Bi-LSTM算法的运算复杂度大。
5 结论
本文提出了一种基于Transformer的数据关联网络,可以在没有目标运动模型和杂波密度等先验信息的情况下,从训练样本中学习目标与量测的匹配关系。所提网络可以提取目标的运动特征信息并学习轨迹与量测之间的数据关联,从而预测输出分类矩阵得到目标与量测之间的关联概率。通过对比实验可以发现,提出的网络具有以下优点:当多个目标交叉时,提出的网络可以解决多目标和多量测的匹配问题;在一定的噪声干扰环境下,提出的网络具有更好的跟踪鲁棒性;在不同检测概率条件下,所提Transformer-DA算法的OSPA距离最小,因而能够提升多目标的跟踪性能。
