面向信息精准服务的档案大数据采集技术研究
2022-06-30重庆工贸职业技术学院谭红英
文/重庆工贸职业技术学院 谭红英
精准服务是当前档案机构服务升级的重要途径,而档案大数据采集是档案信息服务精准化实现首要解决的问题,并最终影响着档案精准服务的质量。数字化档案信息技术、云计算技术、大数据技术、深度学习技术等为主的档案信息精准服务目前颇受学者青睐。学者王顺指出,在大数据环境下的档案信息资源建设不足,档案信息服务理念相对落后,服务提供相对粗放,信息服务缺少对用户需求研究的精细性与针对性等问题。大数据时代下档案数字化转型而来的数字档案、电子档案、多媒体档案等呈现出了大数据的Variety(类型多样)、Value(价值密度低)、Volume(容量大)、Velocity(速度快)等特征。然而从档案信息精准服务角度出发,针对多源异构档案大数据进行安全高效采集目前尚无相关研究。因此,本文从当前档案数据采集中存在的问题出发,进一步提出了改进档案大数据采集的技术策略,以提升档案信息精准服务的质量。
一、档案大数据采集技术的现状
(一)现有信息采集技术存在局限性。数据采集技术是档案信息精准服务的基础,通过多种方式从数据原始生产环境来抓取数据并进行数据抽取、转换和清洗等一系列技术。目前主流常用的大数据采集技术有日志文件采集技术、网络爬虫技术、社交网络媒体交互技术等,由于档案数据是大数据生态圈与档案行业渗透融合应用的实时新数据,因此呈现出碎片化、非结构化及无序化状态等,现有数据采集技术难以采集到精准服务的个性化数据。随着数据采集工具的快速发展,致使档案数据采集出现存储格式不统一、多样采集工具同步采集而来的数据记录重复而形成冗余信息,甚至由于重要数据采集设备缺失而使档案数据采集遗漏现象等大量问题出现。与此同时,数据采集设备日新月异,传统的数据采集技术不能够支撑数据采集设备的高传输速度、高读取速度及并行吞吐等的要求,因此目前数据采集技术在面向精准服务的基础数据采集时面临一些局限性。
利用大数据环境信息共享便利进行信息采集也面临着访问权限、数据保护及数据安全问题。一方面,档案数据采集时访问权限的正当性、合规性及合法性等;另一方面,档案大数据采集是通过互联网、档案信息系统及各种传感设备等,然而随着网络安全与数据安全的警惕性提高,一些网络站点针对网站信息智能爬取的信息采集技术构筑了反爬虫机制与技术防御措施,给档案数据采集造成了一定的困难。同时,档案由于具有秘密属性,当档案大数据采集归档后,其档案数据隐私属性就已经构成,档案信息就面临数据脱敏处理问题,并且数据采集后在存储、分析、利用等过程中也存在着档案数据丢失、泄露、篡改等数据安全风险问题。
(二)采集数据的多源异构性影响档案归档。档案大数据采集后,档案数据面临着数据重复、多源性和异构性等问题。当前档案行业的数据采集缺乏统一标准,各个档案机构采集数据内容不标准、电子存储格式不一致、采集数据重复严重、数据碎片化程度高以及档案数据采集遗漏现象等,导致现有数据采集技术的信息来源由于没有统一的档案管理系统,从而产生采集数据来源的广泛性、数据结构的多样性及存储格式不统一等多源异构问题,同时也存在对传统档案进行数字化转型的采集处理过程中,各个档案机构将有价值的纸质档案转化为可进行快捷查询利用的电子档案时,出现永久电子保存格式不统一的情况,使得难以实现对上述档案大数据集成到同一个数据处理平台进行精准数据筛选,采集数据后的多源异构性给档案集成归档带来了较大的困扰。
二、面向信息精准服务的档案大数据采集技术创新
(一)基于大数据平台集群的档案数据采集技术。大数据平台集群架构为档案信息精准服务提供了技术基础,大数据采集技术赋予了档案数据资源的获取精确度、集成归档完整性与档案利用的高效性。由于档案数据呈现多源异构、数据重复性、数据格式不统一、数据传输不畅及数据“信息孤岛”等问题,目前的数据采集技术难以应对教育档案信息精准服务的数据的实时采集,本文探索基于大数据Hadoop平台集群架构上搭建Cloudera公司的Flume与Apache软件基金会的开源软件Kafka组成的数据采集系统,即HDFS+Flume+Kafka的数据采集技术,其实现数据采集、传输及聚合。Flume+Kafka进行数据采集后,存储于HDFS(分布式文件存储系统),此采集技术线上线下按照预设采集规则爬取广泛的档案信息平台系统的档案数据,并对采集的异构档案数据分门别类地进行存储与数据类型解析,自动进行采集主题相关信息筛选,以此提取采集主题高度相关的元数据及档案信息数据,达到信息个性化需求的档案大数据精准化采集目标。
(二)档案大数据采集流程。档案大数据精准采集不仅需要进行大量数据采集,还要能够对采集到的数据进行精准筛选,其流程由数据获取、数据传输、数据筛选和数据加载四个环节组成,如图1所示。在采集过程中,首先要在大数据平台集群下通过配置数据采集网关,实现对档案大数据的实时智能化采集,然后开放接口使采集数据传输交互和共享,与此同时,以精准服务信息需求为导向对实时采集到的数据进行筛选,最后将筛选后的档案数据加载到大数据集市中,达到档案大数据采集驱动档案信息精准服务的目的。
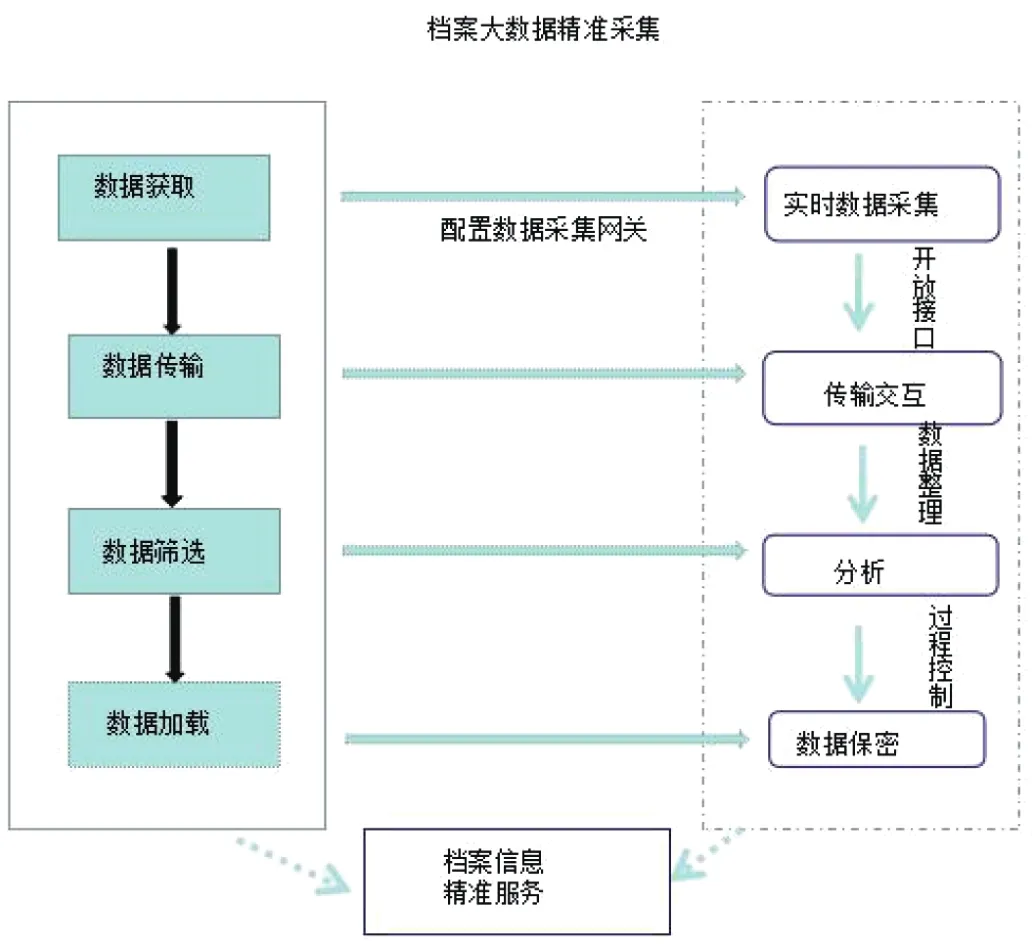
图1 教育档案大数据采集流程
(三)改进档案大数据采集技术策略。档案大数据采集目标是为获得教育个性化需求的信息,提供精准的档案信息服务。我们在采集技术策略上不断改进,如通过自然语言处理技术来调整档案大数据采集系统的关键信息、调整档案大数据实时性的伴随式采集方式等。一是调整档案大数据采集系统的关键信息,精准描述用户采集需求。我们对采集需求的关键信息通过自然语言处理技术从语义层面上进行提取,找出用户采集需求的关键内容与采集系统之间的相互关联,使系统能准确地把握用户采集意图。通常从档案用户需求的语义分析入手,挖掘关键语义后,借助人工智能技术的机器学习等,提取关键信息的限制与关联关系,在采集系统中以正则表达式的方式输入上述限定与关键信息,从而对用户采集需求实现精准表达。同时对信息采集规则以明确、简单的方式进行设置,采集条件不宜过多,描述词短小以获取满意的采集结果。二是调整档案大数据采集方式,由集中式变为具有实时性的伴随式采集和控制访问次数的分散式采集。集中式采集能够统一获取数据,然而集中式造成在一定时间里大量频繁地并发访问采集目标系统,采集目标网站服务器会出现网络拥堵,服务器数据并发处理压力过大致使被采集信息系统频繁出现宕机。因此,需要注重保护采集系统在同一时刻被大量频繁访问,通过控制访问次数的采集方式来保护采集目标。
(四)采用多种采集技术手段降低反爬技术的影响。以多种采集技术手段应对目前网站反爬虫技术对现有采集技术的影响。首先,扩大信息采集的广泛性和来源范围。这里值得注意的是,我们在进行档案大数据采集时,前提是我们必须明确档案数据采集的访问权限及允许范围,在访问权限内合规地采集档案数据。目前常用的信息采集手段之一是网络信息爬虫技术,然而安全警惕性高的网络站点针对信息采集技术对网站信息的智能爬取,采取了反爬虫技术与措施,因此需要从多种技术手段上进行网站反爬虫措施的应对,降低反爬技术对现有采集信息技术的影响。如可以通过采集时间间隔的实时调整、采取机器深度学习的识别验证码解析平台、基于代理IP形式、利用爬虫代替用户去运行浏览器,并执行相关的操作来获取异步数据等技术来处理与应对反爬网站数据技术。
三、利用大数据ETL技术实现多源异构采集数据集成归档
档案大数据的集成归档是采集数据进入档案化的阶段,“归档”后的档案信息处理、分析后应满足档案用户需求的信息精准服务。采集档案数据由于冗杂性和离散性,其集成归档是对档案数据提取、转换、加载的过程。ETL技术是档案数据集成归档的一个主要手段,它将多源异构档案数据源中抽取出所需整合的数据,经过数据清洗技术中间层后进行转换,按照预先定义好的数据仓库模型,最后将数据加载到数据集市中去。对于采集后档案数据中的不规则文本数据、档案系统著录结构化数据等,需要借助自然语言处理技术进行智能化简单提炼,对于半结构化数据、非结构化档案数据等,需要进行转换为后续数据分析处理的结构化数据,从而集成这些离散性、多源性、异构性的档案采集数据,再从预处理的数据中抽取数据利用文本挖掘、精准化服务数据抓取操作。综上,利用ETL技术(即数据抽取、数据转换、数据清洗、数据装载技术进行重复数据、错误数据、无用数据等进行清除与校正)后,提取高质量数据,最后集成于数据仓库中,从而实现档案大数据集成归档。
四、结语
海量异构的档案大数据采集是开展信息精准服务的基础与前提,档案机构在采集数据获取、整合、分析后可以准确掌握用户个性化的利用需求,创新档案大数据采集技术是开展信息精准服务的关键,涉及大数据平台集群的搭建、大数据采集技术的流程设计、应对网站数据采集反爬虫技术的采集策略优化等,基于大数据平台集群的档案数据采集技术是重点,多源异构性采集数据的转换和清洗是数据集成归档的保障。这些海量的档案大数据集成归档后,档案数据保密属性就已经构成,值得注意的是,需要进行数据脱敏和保护档案数据安全,使档案信息服务向精准化方向升级。
