基于SSD-MobilenetV3模型的车辆检测*
2022-06-28廖慕钦周永军汤小红蒋淑霞李宇琼
廖慕钦, 周永军, 汤小红, 蒋淑霞, 李宇琼
(中南林业科技大学 机电工程学院,湖南 长沙 410000)
0 引 言
在自动驾驶中,车辆检测作为一个必不可少的部分而广受关注[1]。计算机视觉车辆检测算法主要有两种,传统目标检测算法和基于深度学习的方法。
传统机器视觉算法的优劣取决于特征提取的效果。崔江等人针对车辆侧面检测提出一种基于图像滤波与匹配技术的方法[2]。针对车辆重叠现象,朱世松等人使用背景差分法利用车辆轮廓的特征点实现了车辆检测[3]。Jheng Y J等人利用Sobel边缘检测的方法,对图片中车道线与阴影部分进行感兴趣区域提取,并和车辆目标进行匹配,以此定位车辆目标[4]。Coifman B等人针对车辆部分遮挡问题,提出利用角点特征实现多车辆跟踪[5]。这些算法依赖手工调参,特征表达能力不强,所以准确度与检测速度均不理想。
近年来,深度学习发展迅速,基于深度学习的车辆检测渐渐成为主流。赵馄等人改进 Fast-RCNN ,在其中融入边缘信息,以此实现快速、准确的车辆检测[6]。Chabot F等人提出Deep MANTA检测算法,利用卷积神经网络(covolutional neural networks,CNN)对图像中的车辆进行多任务分析,同时实现了车辆检测、零部件定位、汽车3D尺寸估计等目标[7]。Chen X等人对Faster-RCNN进行改进,将激光雷达点云特征与局部图像特征融合,直接回归车辆的3D信息[8]。Tang T等人对数据集进行增强,利用一阶段回归算法YOLO检测车辆,提高了检测模型的泛化能力和检测速度,但相对准确率较低[9]。这些方法虽然准确率较传统方法有所上升,但模型参数量较大,不适用于嵌入式平台。
由于深度卷积神经网络的层级较多,参数量相对较大,难以部署到移动端,如何在保证检测精准度的前提下尽量减少模型参数量是研究重点方向。SSD是2016年Liu W等人[10]提出的优秀算法,其检测准确率与速度均有较好的表现。MobilenetV3是2019年Google在前两代的基础上得到的轻量化模型,检测准确率较高的同时占用内存少。SSD算法的基础网络为VGG16,模型参数量大不适用于嵌入式平台。
本文针对此问题结合MobilenetV3占用内存小的优点,将SSD的基础网络替换为MobilenetV3,同时加入迁移学习思想,对MobilenetV3进行预训练,使其在精度与参数量上都有更好的表现。
1 基于SSD-MobilenetV3的车辆检测
1.1 SSD卷积神经网络
SSD的设计理念有以下三点:1)检测采用大小不同的特征图;2)特征提取直接由卷积完成,融合不同卷积层特征图以增强表达能力;3)设置多个大小不同的先验框,以先验框为基础对回归框(bounding boxes)进行预测。SSD使用VGG16作为主网络,修改最后两个全连接层为卷积层,在末尾添加4个卷积层扩充网络结构。图1为SSD网络主要结构。

图1 SSD算法结构
SSD的算法流程如图2所示。

图2 SSD的算法流程图
SSD的损失函数采用一种“multibox loss”计算方法,将定位损失与置信度损失相加得到总损失值,计算公式为
(1)
式中L为总损失;x为第i个预测框(prior box)匹配到第j个真实框(ground truth box)是否为p类别,匹配时x=1,若不匹配则x=0;c为所选框属于类别p的置信度;l为预测值;g为真实值;N为匹配到GT(ground truth)的prior box数量;Lconf为置信度损失,Lloc为定位损失。
1.2 MobilenetV3卷积神经网络


(2)
MobilenetV3是在前两代的基础上,由神经结构搜索(NAS)和NetAdapt算法改进而成,其核心技术为:1)使用5×5卷积代替部分3×3卷积,实验表明能提高网络性能;2)模型的整体结构基于NAS实现的MnasNet模型,其核心为(squeeze and excitation,SE)结构的轻量级注意力模型;3)继承自MobilenetV1的深度可分离卷积和MobilenetV2的倒残差结构和线性瓶颈结构;4)修改激活函数,使用改进的H-Swish代替部分ReLU6函数。H-swish函数是从Swish函数改进而来,实验表明Swish激活函数能有效提高模型识别准确率,但是Swish函数计算量太大,所以对其进行了优化,具体变化如下所示
swish(x)=x·σ(x)
(3)
(4)
在网络模型结构上,MobilenetV3在MobilenetV2的基础上重新设计最后阶段,使其在不损失准确率的情况下减少计算量,具体改动如图3所示。

图3 改进前、后最后阶段网络结构
1.3 SSD-MobilenetV3网络模型
SSD-MobilenetV3结合SSD检测速度快和MobilenetV3占用内存小的优点,使用MobilenetV3替换VGG16。模型一共由29层组成,其中前17层为MobilenetV3特征提取网络,剩下的12层网络负责为SSD网络提供不同的特征图,与经典SSD模型一致。SSD网络总计需要6个不同的尺度特征,第14层和17层提供前2个尺度,后12层提供后4个尺度。前17层特征提取部分网络具体结构如表1所示,其中,Operator代表特征层将进行的Block操作;BNeck是瓶颈层(bottleneck layers),其中的每一层都代表一个MobileBlock,整个网络由多个这样的模块组成;Exp size为膨胀参数,是BNeck内倒残差结构上升后的通道数;# Out为输入到BNeck时特征层的通道数;SE为Squeeze-and-Excite结构,0表示不含有,1表示含有;NL为Non-Linearity,也就是激活函数,HS表示H-Swish函数,RE表示ReLU函数;s表示每一次Block结构的步长。
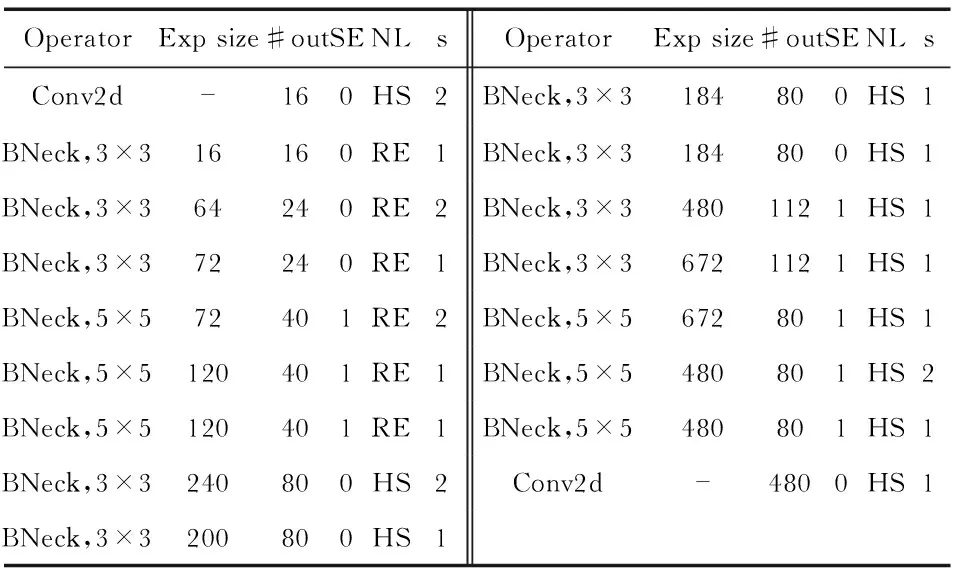
表1 特征提取部分网络结构
1.4 基于SSD-MobilenetV3模型的迁移学习方法
迁移学习就是将模型在大型数据集上预训练出模型参数,然后将其应用到新环境加速其收敛速度。本文在大型数据集COCO上对MobilenetV3进行预训练,将模型初始化之后,只需对最后一层全连接层进行重训练,就能快速得到效果较好的网络模型。将预训练好的模型放进网络中并使用汽车数据集对SSD-MobilenetV3网络第17层重新训练,将训练结果输入到SSD分类器中,具体训练流程如图4所示。

图4 SSD-MobilenetV3预训练流程
2 模型训练与结果分析
2.1 训练环境
本次训练的深度学习框架为Tensorflow,编程语言为Python,集成开发环境为Pycharm,程序运行平台为Windows10系统搭载GeForce RTX 2080显卡,具体环境设置Python为3.6.8版;Tensorflow-GPU为1.13.1版;CUDA为10.0版;Cudnn为10.0版。
2.2 数据集
本文数据集由KITTI与BIT-Vehicle合并而成。数据集总计17 331张图片,挑选其中90 %为训练集,共15 597张,取训练集中2 340张作为验证集,测试集占10 %,共1 734张。数据集包括不同大小、不同光照、不同路况等各个场景的车辆。本文主要目的是车辆定位检测,不需要将车辆分类,所以在标签中将car,van,truck,tram等类型的车辆合并成car一类,同时去除车辆以外的图片以及标签,部分未标注图片采用Labellmg进行手动标注。
2.3 模型训练
超参数根据经验选择,本次训练Batchsize选择64,训练40 000步。学习率的设置采用WarmUp预热学习率的方法,如图5所示。训练开始时选用小的学习率0.13进行训练,每2 000步增大一次,最终达到初始设定学习率0.4,随后逐渐衰减,40 000步后学习率衰减为0.000 013。这样可以使模型训练更加稳定,有助于模型收敛,效果更好。结果显示平均每一步训练时长大约为0.25 s,总损失在15 000步左右趋于平稳,最后总损失在0.5左右,如图6所示。

图5 学习率变化曲线
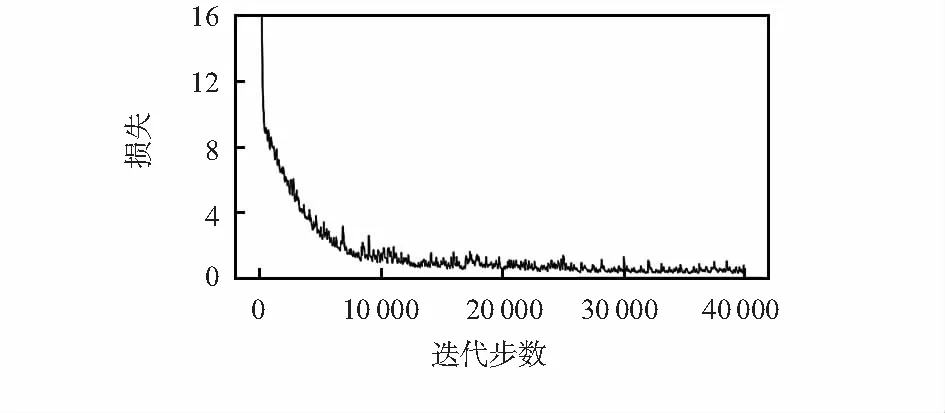
图6 损失值收敛曲线
2.4 模型效果分析
模型训练好之后使用测试集测试,部分测试结果如图7所示。

图7 模型检测效果
由图7(a)可以看出模型检测率较高,在复杂路况也能准确的检测出车辆回归框位置,但对小目标检测准确率不高;从图7(b),(d),(f)可知在环境与路况简单情况下,模型检测准确率非常高,达到90 %以上;图7(c)显示在环境复杂,但路况简单的情况下,检测准确率在80 %以上;从图7(e)可知在环境复杂,车辆较多,且车辆较为杂乱的情况下会出现漏检与误检现象,且检测准确率明显下降。
2.5 常用模型对比
使用检测准确率与模型大小对模型性能进行分析评估。在同样环境下,将本文模型与经典模型SSD,Faster-RCNN,YOLO进行对比,具体数值如表2所示。

表2 常用模型检测性能对比
从表2中可以看出,本文算法准确率对比原SSD与YOLO均有提升,略低于Faster-RCNN,参数量相对各经典模型均大幅减少。本文算法效果比经典模型效果好的原因主要有以下两点:1)使用迁移学习的方法,用COCO数据集进行预训练,有效的对网络进行了初始化,同时使用Warmup学习率设置方法,使网络平稳快速收敛;2)将基础模型从传统的VGG替换成性能较好的MobilenetV3,所以融合网络准确率有小幅提升,网络模型参数量大幅减少,本文模型相对于原SSD参数量减少了83.1 %,更适合嵌入式平台使用。
3 结束语
本文提出的融合网络模型SSD-MobilenetV3结合SSD网络检测速度快和MobilenetV3网络参数量少的特点,将SSD的主网络替换成MobilenetV3,并结合迁移学习的方法对MobilenetV3进行预训练,在提高准确率的同时减少参数量,更适用于自动驾驶嵌入式平台。实验结果表明:本文提出的SSD-MobilenetV3模型检测准确率为85.6 %,相对原SSD提高了3.1 %,同时模型参数量减少了83.1 %。模型的不足之处在于对复杂路况的检测效果不理想,出现重复检测和漏检测现象,还需在下一步的研究工作中提高模型对复杂路况的检测能力。
