Research on Automatic Diagnostic Technology of Soybean Leaf Diseases Based on Improved Transfer Learning
2022-06-25YuXiaoJingYongdongandZhengLulu
Yu Xiao, Jing Yong-dong, and Zheng Lu-lu
1 College of Electrical and Information, Northeast Agricultural University, Harbin 150030, China
2 School of Computer Science and Technology, Shandong University of Technology, Zibo 255049, Shandong, China
Abstract: Soybean diseases and insect pests are important factors that affect the output and quality of the soybean, thus, it is necessary to do correct inspection and diagnosis on them. For this reason, based on improved transfer learning, a classification method of the soybean leaf diseases was proposed in this paper. In detail, this method first removed the complicated background in images and cut apart leaves from the entire image; second, the data-augmented method was applied to amplify the separated leaf disease image dataset to reduce overfitting; at last, the automatically fine-tuning convolutional neural network (AutoTun) was adopted to classify the soybean leaf diseases. The proposed method respectively reached 94.23%, 93.51% and 94.91% of validation accuracy rates on VGG-16, ResNet-34 and DenseNet-121, and it was compared with the traditional fine-tuning method of transfer learning. The results indicated that the proposed method had superior to the traditional transfer learning method.
Key words: transfer learning, deep convolutional neural network, classification recognition, soybean disease
Introduction
Nowadays, soybeans are one of the leading seed soybean plants in the world. It is the primary source of edible oils. The soybean soil accounts for 25% of the total edible oils. At the same time, it is the main component in poultry and fish formula fodders, occupying 60%of worldwide livestock fodders (Agarwalet al., 2013).Besides, with the comprehensive soybean nutrition and abundant content, it is contributed to preventing heart disease and diabetics. In today's society, China is the 4th soybean producing country in the world, next only to the USA, Brazil and Argentina. The cultivation and plantation of soybeans can be traced back to the agricultural era of China. Meanwhile, the northeast is the leading soybean planting area of China. Different prevalent diseases and insect pests will take place every year. More severely, it will result in more than 30% of the output loss (Niuet al., 2019). The insufficient soybean plant protection procedure, the increase of fungus virus pathogen categories and poor cultivation methods are causes for increasing the damage degree of soybean plant diseases and insect pests. The categories of the soybean leaf diseases were studied, which could be divided into multiple types,including anthracnose, bacterial blight, bacterial leaf spot, soybean mosaic virus, copper poison disease,charcoal rot, frogeye, leaf blight, wind blight, downy mildew, powdery mildew, rust disease and tan disease(Wanget al., 2014).
At present, recognition of the soybean leaf diseases is based on human eye recognition, but it will be influenced by a subjective explanation of crop disease professionals, resulting in misjudgment (Barbedo and Arnal, 2016). Moreover, for most small and mediumsized farmers, it is difficult to contact professionals,leading to some delay in finding out the reasons for the leaf disease symptoms and preventive solutions. This severely affects the quality and output of soybeans.As a result, an automatic and reliable computer-assisted system is needed to solve the efficiency issue of soybean leaf disease detection and recognition. At present, establishing accurate technology to identify soybean leaf diseases is the key to prevent soybean leaf diseases and insect pests. The detection of plant diseases needs lots of researchers to apply the image processing technology to remit such a difficult task.Researchers put forward multiple recognition and detection technologies of multiple plant diseases and insect pests and reviewed the traditional detection technologies and innovative detection technologies from multiple aspects (Bagdeet al., 2015; Rastogiet al.,2015; Prasadet al., 2016; Khirade and Patil, 2015;Martinelliet al., 2015; Sankaranet al., 2010).
In current days, the traditional detection technologies get involved in molecules, serology and DNA,while the innovative detection technologies include volatile organic compounds, spectrum technology and convolutional neural network (CNN), etc. A digital picture processing technique (Shrivastava and Hooda, 2014) detects and classifies the tan disease and frogeye. In detail, the recognition accuracy rates of the tan disease and frogeye respectively reach 70%and 80%. However, the above-mentioned methods show some limitations. Firstly, the researches only consider two kinds of soybean diseases and insect pests. Secondly, the recognition accuracy rate in the current research field is not enough. A soybean left disease and insect pest detection method based on salient regions extracts disease areas from soybean leaf disease images (Guiet al., 2015). However,such a method fails to detect the soybean disease types and the recognition accuracy rate. A semiautomatic soybean disease and insect pest recognition system based on the K-means algorithm identifies three diseases including downy mildew, frogeye and leaf blight (Kauret al., 2018). The average maximum accuracy rate reaches 90%, which cannot satisfy the high recognition accuracy rate in today's research fields. A digital picture processing technology (Araujo and Peixoto, 2019) combined with the color moments,local binary pattern (LBP) and bag-of-visual-words(BoVw) recognizes eight kinds of leaf diseases, including bacterial blight, rust disease, copper poison disease,soybean mosaic virus, target leaf spot, downy mildew,powdery mildew and tan disease, showing the classification accuracy rate of 75.8%.
For this reason, the follow-up study can pay much attention to analyzing how to improve recognition accuracy rate, while identifying multiple types of soybean leaf diseases. As a modern image processing and data analysis method, deep learning is equipped with a good image analysis effect and huge development potential. With the successful application of deep learning in each field, it is gradually applied in the agricultural field (Kamilaris and Prenafeta, 2018). In the past several years, deep learning gains extremely excellent performance, especially for the deep neural network (DNN) (Lecunet al., 2015). In the image recognition field, the CNN is rapidly developing, which can extract key features from lots of input images.Through the CNN, researchers can accurately classify the soybean leaf diseases, but the CNN needs lots of calculation resources and time, as well as huge datasets or plenty of input images. To cope with the abovemention shortcomings of the CNN, transfer learning becomes in general use. The utilization of transfer learning uses the pre-trained DNN on the super-large scale datasets to solve specific model training tasks with limited data (Tanet al., 2018). This research regarded the automatically fine-tuning convolutional neural network (AutoTun) as the skeleton and put forward a soybean disease recognition system, which was composed of two modules, including the image processing module and classification module (Bashaet al., 2021). The image processing module aimed to extract the leaf area from the leaf image with the complicated background or the entire image removal background. The classification module used AutoTun to fine-tuning pre-trained CNN on the soybean leaf disease datasets, thus the classification model trained in the original datasets showed excellent performance on the target dataset. In other words, more complicated features could be learned from the soybean leaf disease datasets, to improve the leaf disease recognition accuracy rate. The proposed recognition system results were compared with the traditional fine-tuning methods of transfer learning. Such methods and our method used the same dataset. The experimental and comparative analysis indicated that the proposed method showed excellent performance, namely, relatively unapparent and more detailed leaf structure features were successfully learned, while getting the higher classification accuracy rate in the validation set.
Materials and Methods
Dataset
The soybean leaf disease image data used in this research were gained from the digipathos plant dataset images provided by Embrapa (Brazil), including 459 images and 11 types, which were subdivided into bacterial leaf spot, southern blight, target leaf spot, rust disease, powdery mildew, downy mildew,copper poison disease, grey speck disease, soybean mosaic virus, healthy and unknown diseases. During the model training process, 80% of images were used for training, while 20% of images were applied for validation. Table 1 showed each leaf disease's image quantity in the training stage and validation stage in the original dataset. Fig. 1 showed the sample image of soybean diseases.
Due to the small dataset, transfer learning was trained under the small-scale dataset. Meanwhile, the data-augmented technology was applied to amplify the dataset to reduce overfitting and underfitting.In the computer vision field, each dataset of image classification issues needed to use the specific dataaugmented strategy to gain the best classification effect.A high-efficient automatic data-augmented method based on the search algorithm, AutoAugment (Cubuket al.,2018), was applied. Data augmentation in the field of image recognition was generally applied in equalization,flip horizontal, cutting and rotation. The data-augmented scheme was composed of multiple strategies, while each strategy included two different image processing methods(equalization, flip horizontal, cutting and rotation),as well as the use sequence and probability for each image processing method. The genetic algorithm(Schulmanet al., 2017) was chosen to find out the best data-augmented scheme in the search space.

Table 1 Image quantity in training sets and verification sets

Fig. 1 Soybean leaf disease sample
Image processing module
By observing the sample images in Fig. 1, it was found that the leaf area was strongly less than the background area. Before the image input classifier, leaves in the entire image were separated, thus the classifier accurately extracted features relating to leaf diseases to do accurate leaf disease recognition. The image processing module constituted of four submodules,with the components and output images in Fig. 2.
The first submodule converted the RGB color space image intoL*a*bcolor space, which was the 3D real space.Lrepresented luminance,astood for the component from green to red, andbwas the component from blue to yellow. Among them, the output ofbchannel component was the input of the second submodule, as shown in Fig. 2. The second submodule applied the K-means (Hartigan and Wong, 1979) clustering algorithm to cutbchannel components' images into two clusters (k=2). One cluster corresponded to the leaf area (the interested area), while another cluster corresponded to the background area excluding leaves. In detail, white (the pixel 255) was used to represent the foreground(the leaf area), while black (the pixel 0) was applied to represent the background.Landachannels did not get excellent output in the image segmentation,thus components ofLandachannels did not participate in the K-means cluster. However, after the K-means clustering algorithm cut soybean leaves, the image background area still had some non-leaf areas. In other words, the K-means clustering algorithm cut some areas in the background into the foreground, as shown in Fig. 2.
Beyond that, the third submodule applied the K-means clustering output images as the images after improved input segmentation. The main purpose of the third submodule was to find out and cut out the maximum connected domain or the soybean leaf area.The images contained multiply connected domains which meant that the images contained the same pixel and stayed in the image area composed of foreground pixels with the adjacent position, including the leaf area and connected domains that were cut into the foreground without the demand or correlation. The connected domain label algorithm (Cabaret, 2010) was adopted to gain the number of connected domains in input images and different connected domains applied different colors for marking, as shown in Fig. 2. Besides,the maximum connected domain or a pair of binary images could be extracted from the marked connected domains. Pixel 1 with data normalization represented the leaf area, while pixel 0 meant the background area.At last, binary images were mapped to the original input RGB images, gaining RGB images with the leaf areas. As the input of the 4th submodule, the mapping algorithm converted the normalized binary images into the three-channel images and then multiplied the original input RGB images.
The 4th submodule converted the binary processing of input images into the single-channel, as shown in Fig. 2. Two lists were set up to do the simple iterative algorithm. The horizontal list conducted traversal inx-axis of input images, while the vertical list conducted traversal iny-axis of input images. Coordinate points with the pixels of 254 were added to the list. The minimum of the horizontal list was the left boundary,while the maximum was the right boundary. The minimum of the vertical list was the bottom boundary,while the maximum was the top boundary. The leaf area images were cut on the corresponding interval, as shown in Fig. 2.
The above-mentioned image processing module was applied to all the images of the dataset, but only left the leaf area, removing the irrelevant background.With a tiny minority, this module cut the leaf area into the background, while the background area was cut into the foreground. The sum of pixels after cutting and clipping all the image leaf areas was not the same,and the image size was too large (4 128*3 096*3 pixels), thus the image size was reset as 224*224*3(pixels) as a whole.

Fig. 2 Image processing module
AutoTun
In recent years, deep learning had the remarkable achievements in target detection, computer vision,natural language processing, automatic speech recognition and semantic analysis (Zhouet al.,2017). Compared with the shallow algorithm model of traditional machine learning, deep learning showed remarkable superiority in feature extraction and modeling. At present, the CNN was one of the primary forms in deep learning, featured with the local connection, weight sharing, pooling operation and multi-layer structure. It was suitable for the image classification field. Models with the excellent performance included VGG-16 (Simonyan and Zisserman, 2014), ResNet-34 (Heet al., 2016),Inception (Szegedyet al., 2015), DenseNet (Huanget al., 2016) and Xception (Chollet, 2016). They generally needed lots of training data and calculation resources to gain excellent performance. However, it was a pity that the new research field did not have sufficient data to support such models. Facing to the abovementioned challenges, transfer learning was a common solution and could provide favorable performance in small-scale datasets. Transfer learning used the CNN advantages and conducted fine-tuning on the pretrained CNN in the source tasks on the target dataset to satisfy the demands of target tasks (Zhuang, 2015).However, in actual applications, relative to the source dataset, the target dataset had a limited scale so that the model overestimated the overfitting caused by the feature capacity of target tasks. Based on the improved transfer learning, Bayesian optimization was applied to do fine-tuning for the pre-trained CNN, to fit for the soybean disease classification task. This section focused on discussing the experimental method. Fig. 3 showed the improved strategies for the training of the CNN and traditional transfer learning.
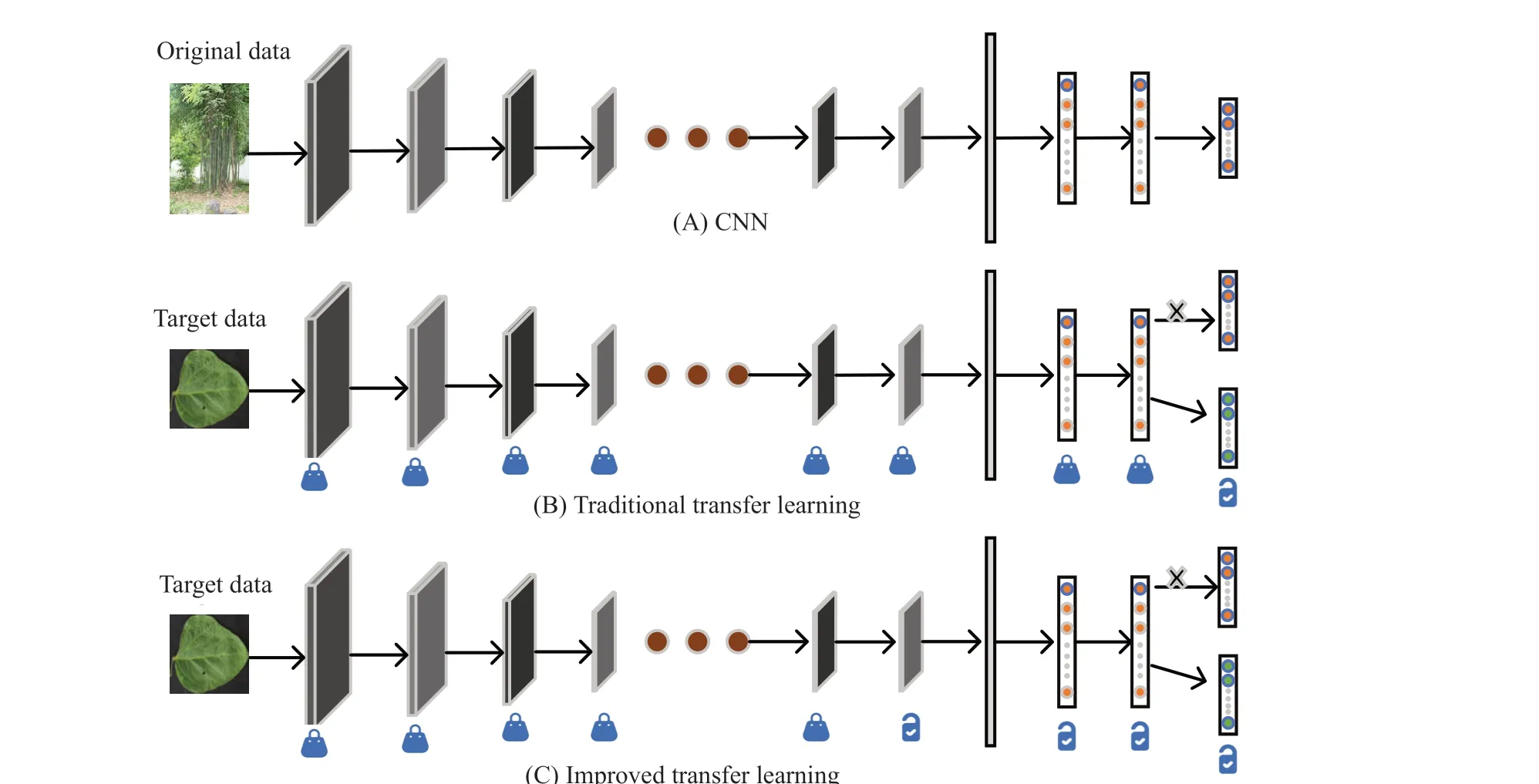
Fig. 3 Transfer learning comparison
AutoTun method was applied so that hyperparameter search space would not be limited to the last fixed layer or several layers. This method first removed the pre-trained CNN softmax layer and used a new softmax layer for replacement. The number of nerve cells was equal to the category of the target dataset. Meanwhile, Bayesian optimization was used to automatically adjust the CNN layer. The layer in front of the CNN represented the general original features, such as the margin and spot. These features were general to most tasks. The exclusive features of target tasks were extracted from several last layers.As a result, this method adjusted the CNN layers from right to left (from the last layer to the initial layer).As shown in Fig. 3 (C), the locking symbol meant to freeze this layer, while the unblocking symbol referred to conduct fine-tuning on this layer. The TPE algorithm used the pre-trained CNN model, hyperparameter search space, training set, validation set,number of training cycles as input, and selected gaussian mixed model (GMM) as the prior distribution of the objective function. The program constantly updated the posterior distribution of the objective functionFwith the iteration of the hyperparameter search space, selected the maximum value for the next iteration each time, and finally outputed an improved CNN model suitable for the target dataset.
In this paper, the hyper-parameter search space involved in different CNN layers was discussed.VGG-16, ResNet-34 and DenseNet-121 were applied.Such networks were gained by pre-training in the Imagenet (Denget al., 2009) dataset. AutoTun was applied to conduct fine-tuning on the soybean leaf disease dataset to gain better performance.Hyper-parameter search space of fine-tuning was illustrated in Table 2, involved in six operations of the convolutional layer and pooling layer. The fullyconnected hyper-parameter included the number of layers and nerve cells. Dropout was adopted on the fully-connected layer and dense layer. Dropout was a mainstream regularization with the factor to be adjusted in the range of [0, 1]. The offset was 0.1,namely the Dropout factor value was {0, 0.1, 0.2, 0.3,0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1}.
In the entire experimental process, unmodified pretrained CNN connectivity made the model suitable for the soybean leaf disease dataset. Two operators including 1*1 convolution and upper sampling operation were used to respectively solve the unmatched issue of tensors in deep and spatial dimensions.
Bayesian optimization
On the target dataset, the pre-trained CNN conducted the automatic fine-tuning and it was regarded as a black box optimization issue. In other words, target functions were not directly accessed. Bayesian optimization was applied to do fine-tuning for the CNN.Fwas set up as the target function with the mathematical form as (1):
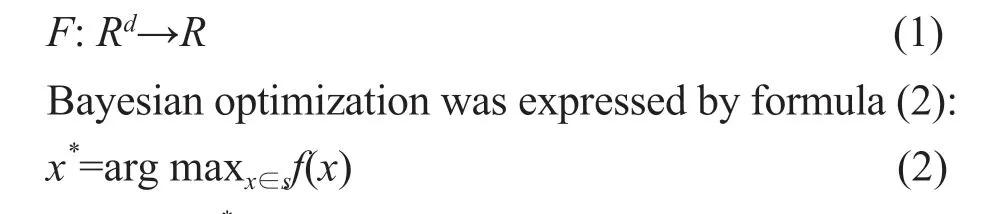
Where,x*was used as the input. In formula (2),Srepresented the hyper-parameter search space, as shown in Table 2.

Table 2 Relevant hyper-parameter search space
Any points in search space were used to solve the value consumption calculation resource of the target functionF, which was gained by conducting finetuning (re-training) for the original CNN layer on the target dataset.x*represented the optimal estimation of relevant hyper-parameter in the CNN layer after finetuning.
Bayesian optimization was composed of the agent model and gathering function (Pelikanet al., 2005).The agent model was a Bayesian statistical model and Gaussian process (GP) regression was used to establish the approximation of the target functionF. It was assumed that GP was used as the prior distribution of the target functionF. The gathering function used the formula (2) to find out the global maximum of the target functionF.
Results
This research was applied for the classification and identification of bacterial leaf spot, southern blight,target leaf spot, rust disease, powdery mildew, downy mildew, copper poison disease, grey speck disease and soybean mosaic virus.
The image processing module output of the soybean leaf disease recognition system used in this research is illustrated in Fig. 2. The experimental results indicated that such a method was effective for the soybean leaf disease images to do background segmentation. The interested areas or leaf areas were separated from the complicated background. The separated leaf images reserved the features of the infected disease and insect pest parts, thus the output images of the image processing module were suitable for the classification module to do feature extraction.
After gaining the leaf images without the complicated background, AutoAugment technology was used for data augment. The 80% of images were used as the training set at random, while 20% of images were selected as the validation set to verify the accuracy rate of the classifier. The accuracy rate was defined as formula (3):
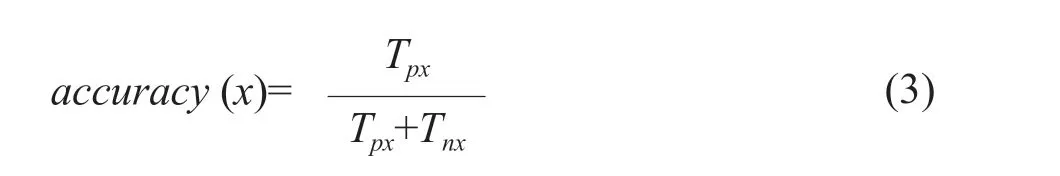
Where,xrepresented the leaf disease type,TpxandTnx,respectively represented the time of success and failure to identify the leaf diseasexin the entire system or the average classification accuracy rate of each leaf disease in the entire system.
The classifier AutoTun was used to fit for the soybean leaf dataset's CNN structure through algorithm 1 learning to improve the training transfer learning.Bayesian optimization algorithm conducted automatic fine-tuning for the CNN to gain different layer structures and optimal configurations of relevant hyperparameters in Table 3. In the soybean leaf disease dataset, the VGG-16 network (pre-training on ImageNet dataset) was conducted fine-tuning to gain 92.55% of validation accuracy rate in the experiment, overlapping a fully connected layer with 1 024 nerve cells. In detail, the Dropout factor with the originally connected layer was 0.6, overlapping the maximum pooling layer. The filter size was 3*3 to do fine-tuning for the ResNet-34 network. The Dropout factor including the originally connected layer was 0.3. The filter size of the last two convolutional layers was 3*3, respectively including 512 and 256 pieces. Through fine-tuning on the DenseNet-121 network, 92.29% of the validation accuracy rate was gained in the experiment, overlapping a new fully-connected layer with 1 024 nerve cells.The Dropout factor with the originally connected layer was 0.4. The filter size of the last two convolutional layers respectively reached 5*5 and 2*2, including 512 and 128 pieces. The fully-connected layer listed and parameters excluded the fully connected layer of output because of the number of nerve cells in the output category. Table 3 indicated that the three CNN structures obtained by Bayesian optimization gained excellent performance on the soybean leaf disease dataset.
Table 4 showed the accuracy rate from the traditional fine-tuning method of transfer learning and AutoTun in the research in the VGG-16, ResNet-34 and DenseNet-121 structures for the soybean leaf disease dataset. To prove the AutoTun improvement on transfer learning, the layers of the traditional finetuning method remained consistent with the layers gained by automatic fine-tuning of AutoTun. The findings indicated that compared with the traditional fine-tuning method of transfer learning, the AutoTun significantly improved the performance (validation set's accuracy rate) or the number of trained parameters was relatively reduced. For the pre-trained VGG-16 model, the traditional fine-tuning gained 85.52% of the validation accuracy rate on the soybean leaf disease dataset, requiring 1.33 million parameters relating to the three layers. The AutoTun method conducted automatic fine-tuning for the pre-trained VGG-16 model, gaining 94.23% of the validation accuracy rate on the soybean leaf disease dataset. The trained parameters only used 823 000, which was reduced by 38% compared with the traditional fine-tuning method.The AutoTun method could conduct fine-tuning for the pre-trained ResNet-34 and DenseNet-121 models on the soybean leaf disease dataset, finding that the trained parameters were slightly higher than the traditional fine-tuning method of transfer learning, because the extra fully-connected layer was considered in the parameter search space. Such a method respectively gained 93.51% and 94.91% of the validation accuracy rates on the soybean leaf disease dataset, while the traditional fine-tuning method respectively gained 87.13% and 87.74% of the validation accuracy rates.Through the comparison, it was proven that the extra fully-connected layer could improve the performance of the validation data.
In addition to the comparative analysis between Tables 3 and 4, the AutoTun method and traditional fine-tuning method used the same source dataset(ImageNet dataset) and target dataset (the soybean leaf disease dataset) for the VGG-16, ResNet-34 and DenseNet-121 networks for fine-tuning. At the same time, the number of fine-tuning layers in the traditional fine-tuning method remained the same with the layers gained by automatic fine-tuning from the AutoTun method. The analysis for the trained parameters and validation accuracy rate gained from the contrast experiment proved that the AutoTun method could show excellent performance in the soybean leaf disease dataset, indicating that the AutoTun method owned excellent generalization ability for the CNN with different structures.

Table 3 Optimal hyper-parameter configuration

Table 4 Classification performance comparison
Discussion
The quality and quantity of soybeans were affected by diseases and insect pests. In this paper, the identification method for the nine kinds of leaf diseases including bacterial leaf spot, southern blight, target leaf spot, rust disease, powdery mildew, downy mildew, copper poison disease, and soybean mosaic virus, as well as healthy leaves, and unknown leaf diseases was proposed, while improving the traditional transfer learning method to identify soybean diseases and insect pests.
The image segmentation method was applied to remove the complicated background and cut it into the leaf areas with the AutoAugment technology to augment data and reduce overfitting. Relevant findings indicated that the current research method of conducting background segmentation for soybean leaf disease images was effective. The interested areas or leaf areas were separated from the complicated background. The segmented leaf images reserved the features of diseases and insect pests. The AutoTun method improved transfer learning. On the soybean leaf disease dataset, the VGG-16, ResNet-34 and DenseNet-121 network models (ImageNet pre-training)were conducted automatic fine-tuning. The findings indicated that the available methods respectively got 94.23%, 93.51% and 94.91% validation accuracy rates on the VGG-16, ResNet-34 and DenseNet-121 networks showing better performance than the traditional fine-tuning method of transfer learning and fewer trained parameters. Future researches will consider how to use the existing soybean leaf disease database to train and test the AutoTun method, to verify the method's generalization ability on different datasets.
Conclusions
In this paper, a new methodology was presented for identification of nine soybean diseases. The proposed methodology consisted of extraction of color features by using the color moments technique, extraction of the texture features by the K-means clustering algorithm.Classification was performed using AutoTun to finetuning pre-trained CNN. The proposed methodology identified a single disease per leaf, and the experimental and comparative analysis indicated that the proposed methodology showed excellent performance. If there were multiple diseases, the system would classify only one of them, namely, that with the greatest prominence in the leaf image. In addition, if a disease was observed that was not included in the nine diseases investigated in this study, the system's output would indicate the disease that had been used for training and that was most similar to the new disease being considered.
杂志排行

Journal of Northeast Agricultural University(English Edition)的其它文章
- Study on Antibacterial Effects of Purple, Yellow and White-skinned Onions
- Effects of Different Ventilation Modes and Outlet Height on Nursery Piggery Environment
- Measurement of Grain Production Efficiency in Main Grain-producing Areas and Analysis of Inter-provincial Differences
—— A Study Based on Super-SBM Model and Malmquist Index - Effects of Planting Density and Cutting Time on Hay Yield and Nutritional Value of Forage Soybean HN389
- Effects of Encapsulated Enzyme and Yeast Products on in Vitro Rumen Fermentation
- Attribution of Antioxidation of Quercetin in Vitro and Arbor Acre Broilers