旋转机械故障诊断模型的泛化性能研究与改进
2022-06-24张晓锋郝如江夏晗铎段泽森
张晓锋, 郝如江, 夏晗铎, 段泽森, 程 旺
(石家庄铁道大学 机械工程学院,河北 石家庄 050043)
0 引言
旋转机械的负载变化在工作中很常见,在负载变化时传感器采集到的信号也会发生改变,使得信号的特征分布变得更加分散。故障类型在不同负载下的信号特征分布不同,幅值大小与周期波动也不同[1],这样的特征分布问题会使网络模型在故障分类时产生分类误差,影响网络模型的故障诊断性能。而负载变化在工业条件下是不可避免的,所以优秀的故障诊断模型需要在负载不断变化的情况下也能够保持良好的故障诊断性能[2]。这要求网络模型具有良好的泛化能力[3],能够在不同负载造成的差异数据集中保持优秀的学习能力与测试能力[4]。
1 网络结构改进
1.1 首层卷积核尺度
卷积神经网络的首层卷积核尺寸对网络的性能影响较大,因为振动信号是周期信号,每个输入到网络的数据信号的相位值不同。首层卷积层相当于一组带通滤波器,滤波器的频带范围直观地影响故障特征提取,所以神经网络对首层卷积层十分敏感。首层卷积核的尺寸越大,频带范围越大,此时提取的信号特征较多,但是包含负载变化产生的冗余信息也多;首层卷积和尺寸越小,此时提取的信号特征较少,但是包含的负载变化产生的冗余信息也少。所以为了寻求到最合适的首层卷积核尺寸,拟采用多种尺度大小的首层卷积核来测试相同的实验数据,通过对比找到最适合变负载下齿轮箱故障诊断的首层卷积核尺寸。选取1×3、1×9、1×64、1×128、1×256、1×512共6种不同的首层卷积核尺寸。

图1 不同首层卷积核尺寸验证对比
使用美国凯斯西储大学(Case Western Reserve University, CWRU)[5]的数据来验证不同负载下的故障诊断准确率。数据负载分别为750、1 500、2 250 W 3种状态,每种状态都包含10种故障类型。分别在750、1 500、2 250 W以及无负载状态下测试上述6种首层卷积核尺度。为了形象直观,计算每种类型卷积核的平均准确率,绘成柱状图,见图1。
可以发现当首层卷积核尺度为1×128的时候,平均故障分类准确率最高。说明在数据集下,此尺度下提取的信号特征最为合适,因此,选用尺度为1×128作为改进网络首层卷积核尺度。
1.2 随机失活
随机失活(Dropout)是Krizhevsky et al[6]提出的,在网络层数较深时,训练后会出现过拟合现象,可以通过影响特征检测器来抑制过拟合现象。Dropout可以在神经网络的前向传播过程中,在dense层之前使每个批次以一定的概率P来忽略一部分特征检测器,让某个神经元的激活值以P的概率停止工作,从而使网络不会太过于依赖某些局部的特征,同时减少了网络的计算参量,使模型泛化性更强[7]。
使用Dropout的神经网络训练过程如图2所示。首先,临时随机删除网络中一定数目的隐藏神经元,据Srivastava et al[8]所提出的理论与多次实验论证,失活概率采用0.5。图2中虚线为临时删除的神经元,同时输入输出的神经元保持不变;然后,把输入x通过随机失活后的网络进行前向传播,把得到的损失结果通过随机失活后的网络进行反向传播,一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b);最后,恢复被删掉的神经元,此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新,不断更新没有被删除的那一部分参数,删除的神经元参数保持不变;不断重复这一过程。
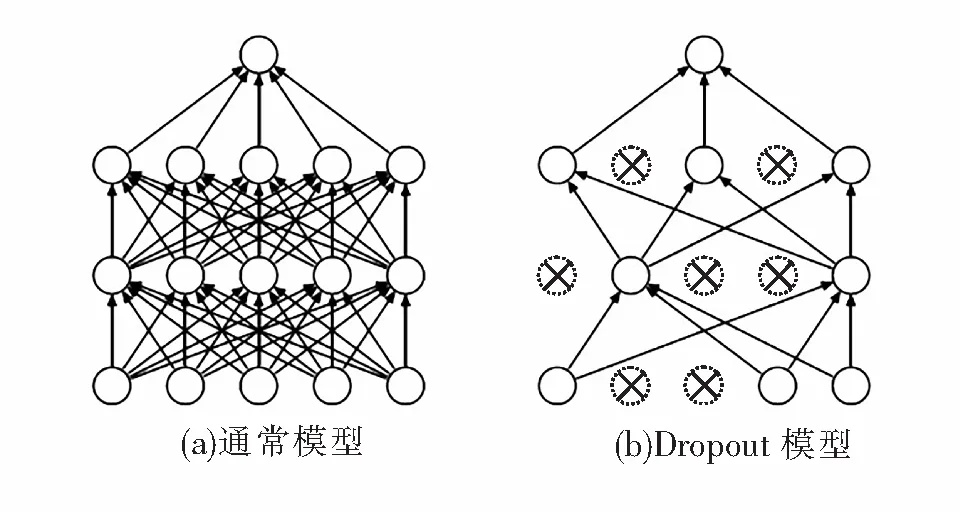
图2 网络模型对比
整个Dropout过程就相当于对很多个不同的神经网络取平均,同时减少权重使得网络对丢失特定神经元连接的鲁棒性也得到了提高,从而使得网络在整体上达到减少过拟合的目的。
1.3 测试分析
为了验证基于多尺度特征融合与深度残差收缩网络的泛化能力,现采用3种负载下的数据来进行训练验证实验。具体操作为使用其中一种负载训练网络模型,将网络模型保存后对其余2种负载进行准确率测试,以此来验证网络的泛化能力。使用负载为750 W的数据集来训练网络模型,将模型保存后对负载为1 500、2 250 W的数据集进行测试,将其准确率分别记录下来,然后依次进行负载为1 500、2 250 W的模型训练与之后的交叉测试。其测试结果如表1所示。
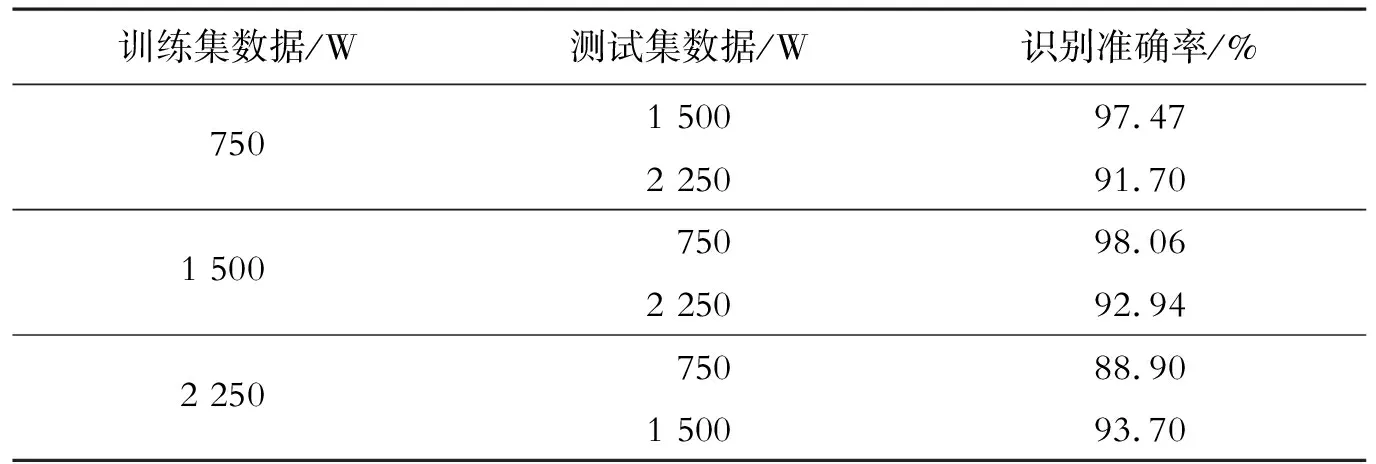
表1 泛化能力测试结果
可以发现在2 250 W数据集下训练的网络模型对750 W数据集的故障识别正确率最低,为88.91%,当使用1 500 W下数据集来训练网络模型时,对其余2种数据集进行故障识别,此时的故障识别准确率最为稳定且精度较高。以上结果表明,改进网络的跨负载领域自适应能力很强,为适应多变的工作环境提供了合理性。
2 优化算法改进
网络模型在训练过程中,学习初期迭代很快,训练效果很好,而且没有发生训练变化异常等现象;结合表1发现,虽然训练的模型故障诊断效果良好,但是在测试时的故障诊断准确率不太理想,为此使用数据降维来分析此想象的具体原因并采用优化算法来增强泛化能力。
2.1 t-SNE数据降维
为了查出使用750 W数据集训练模型来测试 2 250 W数据集与使用2 250 W数据集训练模型来测试750 W数据集正确率偏低的原因,采用t-SNE[9]进行数据降维,t-SNE图中不同的颜色代表不同的故障类型(见图3)。选用750 W数据集训练模型来测试2 250 W数据集来进行降维,其最后一层隐含层的分类结果如图3(a)所示,可以发现在测试2 250 W数据集有3种故障存在明显的混叠现象[10],因为此3种故障分布具有相似性,使得网络模型在分类故障时造成错误分类,这是导致准确率较低的主要原因。而训练网络模型过程中的降维分布如图3(b)所示。
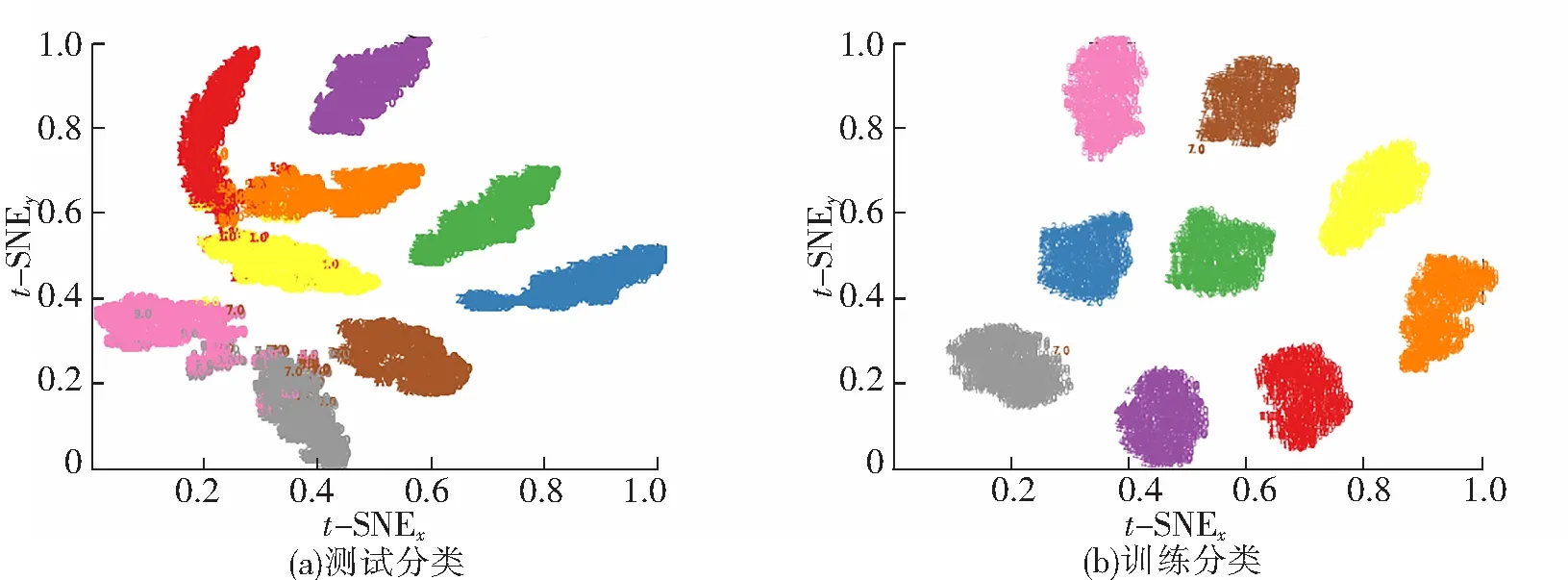
图3 特征分布对比图
可以发现,网络模型虽然在750 W训练数据集中具有良好的可分性,但是将模型应用到2 250 W时却发生少许的分布不一致现象,说明当训练模型的数据集与测试模型的数据集相差较大时会使得网络性能下降,故障分类正确率受到影响。为此拟采用AdaBN算法来解决这一问题,提高网络的泛化能力。
2.2 AdaBN优化算法
AdaBN算法是Lu et al[11]针对训练集与测试集特征分布相差较多时对BN(Batch Normalization)进行改进的一种算法,以此来缓解神经网络性能退化这一问题,一般用于图像识别领域[12]。该算法在网络的每一次批量归一化过程中将训练集(目标域)在BN层的均值与方差一并记录,在遇到训练集的特征分布与测试集的特征分布不一致时,将测试集数据输入到改进网络中,此时网络不再进行反向传播只进行正向传播。此时可以用之前记录下来的训练集方差与均值来代替测试集在进行BN时的均值与方差,其工作过程如图4所示。
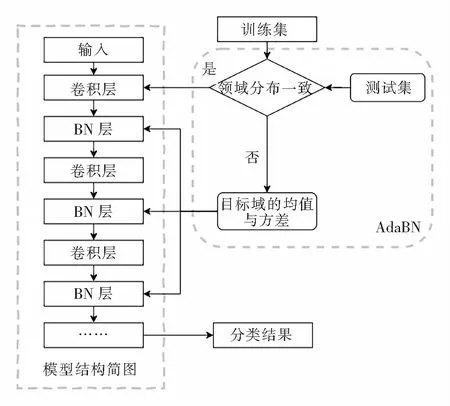
图4 AdaBN算法工作流程

(1)
(2)
之后网络将参数输入到后续网络,其他参数不再变化,由此,神经网络可以使源领域与目标领域的特征分布近似一致,从而达到缓解网络性能退化的目的,计算BN层的输出
(3)
(4)
在神经网络中添加AdaBN优化算法,重复实验,结果如表2所示。
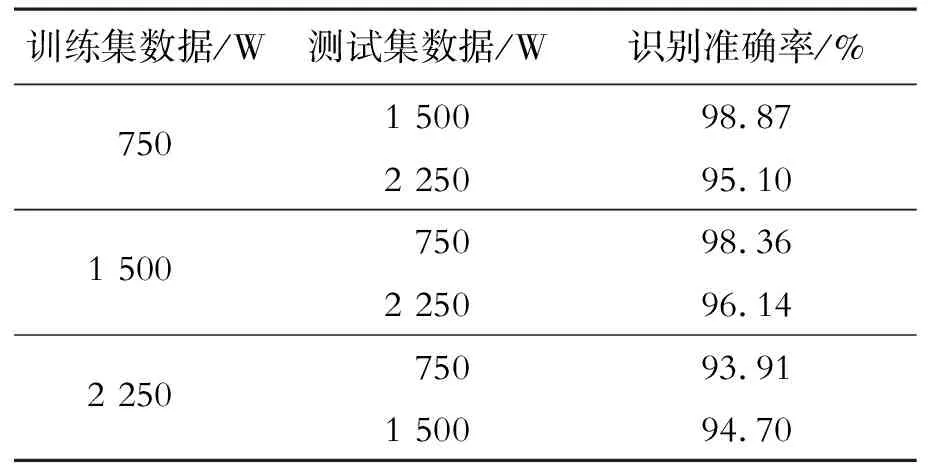
表2 使用AdaBN优化算法测试结果
其中在负载为750 W的情况下训练时的正确率与损失的变化如图5所示。
图5 实验测试结果图
可以发现使用AdaBN优化算法后,将训练集在BN层的均值与方差代替测试集的均值与方差时,通过不同负载下的交叉训练验证,表明此种改进能提高网络模型泛化能力。可以发现网络模型的故障诊断正确率明显提高,在使用750、2 250 W的数据集进行交叉训练与验证时正确率提升最为明显,正确率分别上升3.4%、5.0%。通过使用AdaBN优化算法,可以使网络模型在训练时750 W数据集与2 250 W数据集的特征分布基本吻合,故而模型可以很好地进行分类。综上所述,AdaBN优化算法可以很好地提升网络在不同负载下的故障诊断性能,使得基于多尺度特征融合与残差收缩网络具有优良的泛化能力。
3 结论
在凯斯西储大学的数据基础上进行测试之后得到以下结论:
(1)选择合适的首层卷积核的尺寸可以提高网络模型的故障诊断正确率,而且利用随机失活能够使得网络模型的泛化能力得到很大提升,这对提升网络的故障诊断性能提供了支持。
(2)AdaBN优化算法可以很好地提升网络在不同负载下的故障诊断性能,使得网络模型具有优良的泛化能力,实现了一种负载下训练好的网络模型对另一种负载的数据集进行故障诊断这一需求,满足在不同负载下进行旋转机械的故障诊断研究。
(3)为了验证网络更广泛的适应能力,对网络模型及其算法参数进行改进,使其满足负载差距更大的交叉验证诊断要求,同时探究网络在其他类型故障诊断的应用及改进。
