基于CNN-LSTM模型及小样本数据的水库二氧化碳通量预测
2022-06-24欧阳常悦
秦 宇, 欧阳常悦,方 鹏
(1. 重庆交通大学 河海学院,重庆 400074; 2. 重庆交通大学 机电与车辆工程学院,重庆 400074)
0 引 言
水电长期被认为是清洁能源而得到大规模发展,但近年来大量研究表明,水库温室气体并不是传统认为的零排放。当水库建成后,大量植被淹没和流域输入的有机质沉积导致的微生物降解过程会产生CO2、CH4等温室气体,并通过水气界面释放到大气中[1],其排放强度与水库的地理位置、气候条件、淹没的土壤与植被类型等因素有关[2-3],占全球温室气体排放增温潜力的1%~28%[4]。水库的温室气体排放量以及对全球碳循环的影响日益受到关注,人工水库的温室气体产生、释放及其通量的研究逐渐引起学术界的重视。然而,传统的通量监测技术存在一定的局限性,存在采样周期长、人力成本高、采样费用大、受瞬时流速和风速影响较大等问题。目前越来越多的研究致力于精确地预测碳通量,现有关于碳通量的预测研究集中在水稻田[5]、草原[6]、森林[7]和毛竹林[8]等陆地碳源汇问题上,而关于水库水气界面CO2通量的预测极其少见。
深度学习(deep learning)是机器学习(machine learning)领域中一个新的研究方向,通过算法使机器学习样本数据的内在规律和表示层次,最终让机器能够像人一样具有分析学习能力。深度学习在数据挖掘、机器学习、机器翻译、自然语言处理、多媒体学习、语音、推荐、个性化技术以及其他相关领域都取得了很多成果[9]。笔者采用深度学习中的CNN神经网络和LSTM神经网络分别对万峰湖水库水质参数进行数据特征提取,并使用DNN神经网络(全连接神经网络)进行CO2通量回归,构建该数据集下水库CO2通量预测的CNN-LSTM模型,同时分别建立CNN神经网络模型、LSTM神经网络模型和DNN神经网络模型与之对照,实验最后,CNN-LSTM模型取得了最好的预测结果。
1 数据处理与分析
1.1 研究区域
万峰湖位于黔、滇、桂三省结合部的贵州省兴义市,由国家重点工程——天生桥一级电站大坝截南盘江而形成的典型高原喀斯特深水水库。而贵州喀斯特面积广阔,岩溶分布广泛,就碳酸盐岩石出露面积便占了全省总面积的73%[10]。该背景下的水库、湖泊势必会受其地理环境的影响。该水库地势西北高、东南低,海拔高度为650~1 000 m之间。积水后,正常水位海拔为780 m,主航道长约128 km,最宽处20 km,沿主航道水深约100 m,形成了全长144 km、总面积176 km2、储水1.026×1010m3、年入库总流量1.93× 1010m3、年输出量1.424×1010m3的人工湖[11-12]。该区域的气候属于亚热带季风气候,季节变化较为明显,夏季高温多雨、冬季温和少雨,热量充足,年气温变化较小,研究区地形平坦,水流流速缓慢,湖泊周围植被生长茂盛[13]。
1.2 数据处理
笔者整合了万峰湖水库2016年—2017年的表层水体的p(CO2)及其对应时刻的T、pH、ALK、TDS、ORP和Cond共6个水质参数。共计47组实测数据均来源于参考文献[13]~文献[15]上的公开数据。由于通量计算过程中可选择的经验公式较多,为了精准预测碳通量,笔者以下述方式统一计算水-气界面CO2交换通量。
水-气界面CO2交换通量主要受水体CO2与大气p(CO2)的分压差和气体交换系数的影响,可由式(1)计算[16-17]:
F=[p(CO2)w-p(CO2)g]×KH×k
(1)
式中:F为水气界面扩散通量,mmol/(m2·d),F>0表示水体向大气中释放CO2,F<0表示水体吸收CO2;p(CO2)为表层水体CO2分压p(CO2)g为水-气界面CO2平衡时水中CO2的分压(38 Pa);KH为亨利系数,可由式(2)计算[18]。
KH=58.093 1+90.506 9×(100/T)+22.294×
ln(T/100)
(2)
k为气体交换系数,主要受到风速、温度、流速等多种因素的影响,因此,k计算方式较多,笔者参照N.SOUMIS等[17]的经验式(3)计算:
k=2.07+0.215U1.7
(3)
式中:U为检测地区地平均风速,所有参考文献中风速均为0.9 m/s。
1.3 相关性分析
采用origin9.0软件对CO2通量和各水质参数进行线性拟合和相关性分析(图1)。 结果表明:万峰湖水库夏季水-气界面CO2通量与和ORP有较显著的相关性,R2分别为0.90和0.39,而冬季与T、pH、ALK、TDS和Cond均有较显著的相关性,分别为0.46、0.92、0.29、0.50和0.43。因此万峰湖水库在一个完整的水文年内,6个水质指标均为水-气界面CO2通量的影响因素,均可作为CO2通量预测模型的输入特征。
2 模型结构
2.1 CNN模型
CNN通过卷积操作,能够自适应地提取数据中的特征。CNN进行卷积操作后进行非线性激活函数的激活,通过多层卷积、激活操作使CNN能够拟合非常复杂的非线性函数。因而,笔者采用一维CNN对万峰湖水库47组样本数据进行特征提取。每个卷积层采用64个卷积核,同时对由水质指标构成的特征向量进行特征再提取,每个卷积核独立提取特征,在输入特征不变的前提下增加特征提取的通道数,最后,再将卷积核提取的特征再进行融合(图2)。
2.2 LSTM时序特征提取模型
LSTM是为了解决循环神经网络(RNN)中“梯度消失”和“梯度爆炸”问题而提出。通过增加一个“遗忘门”,让神经网络“忘记”一些不重要的信息,从而能够“记住”更长时间范围内的信息。其在自然语言处理与时序预测等研究方向取得显著的效果。其网络单元如图3。
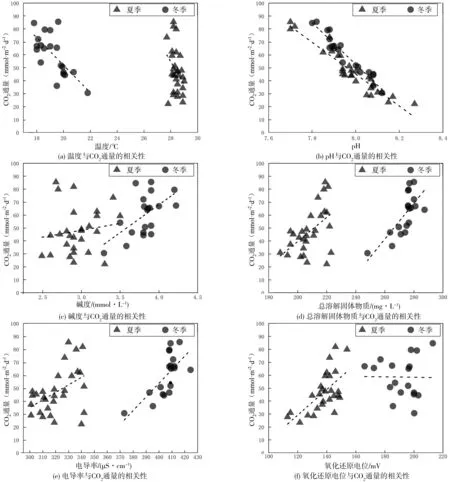
图1 万峰湖水库水-气界面CO2通量与水质指标的相关性分析Fig. 1 Correlation analysis of CO2 flux and physicochemical properties in the Wanfeng Lake Reservoir

图2 一维卷积示意Fig. 2 One-dimensional convolution diagram
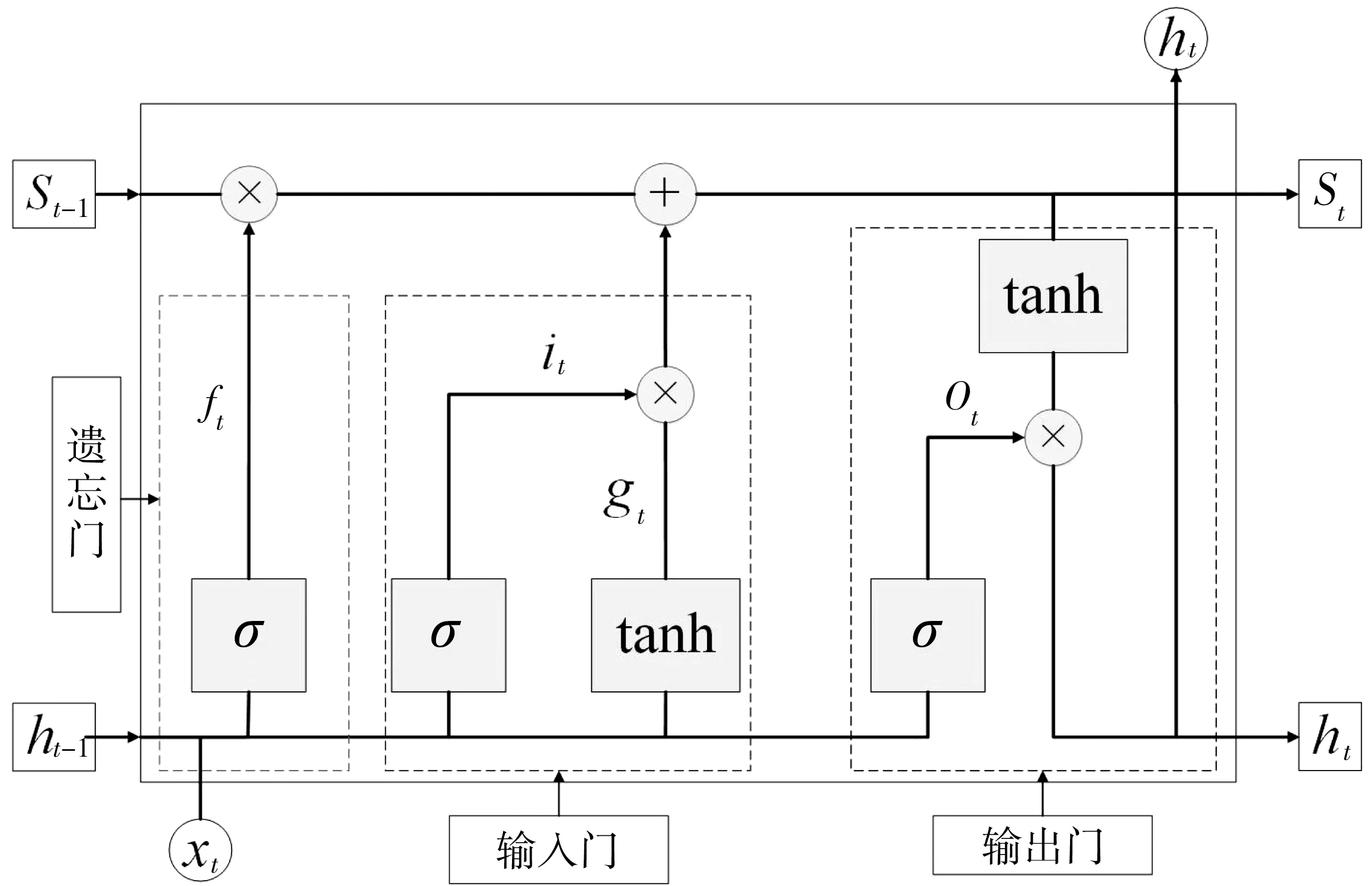
图3 LSTM神经网络的单元结构Fig. 3 Unit structure of LSTM network
LSTM神经网络的基本单元包括输入门,输出门及遗忘门[19]。遗忘门通过查看输入xt,与隐藏状态ht-1信息来输出一个0~1之间的向量,通过该向量里面的0~1值来决定细胞状态St-1中哪些信息需要保留与遗忘,遗忘门如式(4)。输入门中的xt与隐藏状态ht-1分别经过sigmoid和tanh函数变化后共同决定候选细胞信息gt中哪些信息会被更新到细胞信息中,输入门如式(5)和式(6)。新的细胞信息St由旧的细胞信息St-1经过遗忘门与输入门共同决定,表达如式(7)。更新细胞状态后根据xt与ht-1来决定输出细胞的哪些状态特征,输出门如式(8)和式(9)。
ft=σ(Wfxt+Wfht-1+bf)
(4)
it=σ(Wixt+Wiht-1+bi)
(5)
gt=tanh(Wgxt+Wght-1+bg)
(6)
St=gt⊗it+St-1⊗ft
(7)
Ot=σ(WOxt+WOht-1+bO)
(8)
ht=tanh(St)⊗Ot
(9)
式中:Wf、Wi、Wg、WO分别为相应门与输入xt和隐藏状态ht-1相乘的矩阵权重;bf、bi、bg与bO分别为相应门的偏置项;⊗为sigmoid激活函数;tanh为激活函数。
2.3 模型结构
为了减小模型复杂度,加快模型训练,先对47组原始数据进行数据预处理。提取水质指标作为训练数据,CO2通量值作为监督学习的标签。为了保证模型的训练速度和泛化能力,对提取的水质指标特征数据及标签数据进行标准化处理。
CNN-LSTM模型主要由3部分组成,如图4。CNN神经网络,LSTM神经网络与DNN神经网络、CNN神经网络设计有2层一维卷积层(Conv1D),每1层卷积核数目皆为64,卷积核大小为1×N,N是输入数据的纬度,移动步长为1,激活函数选择Relu函数。通过2层卷积对特征进行提取再融合为1×64的融合特征。走航过程中所测数据是随时间而变化,因此需要提取数据间的时序特征。笔者采用2层LSTM提取水质指标中的时序特征,每层的神经细胞(cell)数量都为64,激活函数为Relu函数,每个神经细胞处理完后都输出一个隐藏状态量,经LSTM神经网络处理后的输出为1×64的向量。最后经过4层DNN神经网络映射到CO2通量。DNN神经网络的神经元节点数分别为64、32、16和1,激活函数采用tanh函数,最后输出的数据经过反标准化后即为每次的预测值。构建绝对均值(MAE)作为模型损失函数,采用Adam优化算法寻找损失函数最优值,通过逐层训练,优化每一层权值与偏置值,直到损失函数收敛到稳定为止。本模型采用一组水质指标数据预测一个CO2通量。

图4 CNN-LSTM模型结构Fig. 4 CNN-LSTM model structure
为了更好的评估模型的预测性能,笔者采用绝对均值误差(MAE)、均方根误差(RMSE)作为模型的评价指标。预测值与实测值的相关性(R2)由origin9.0软件计算并绘制。MAE和RMSE如式(10)~式(11):
(10)
(11)
式中:n为预测的总次数;Yact(i)和Ypred(i)分别为CO2通量的真实值和预测值。
2.4 训练方法
CNN-LSTM预测模型的训练流程如图5。
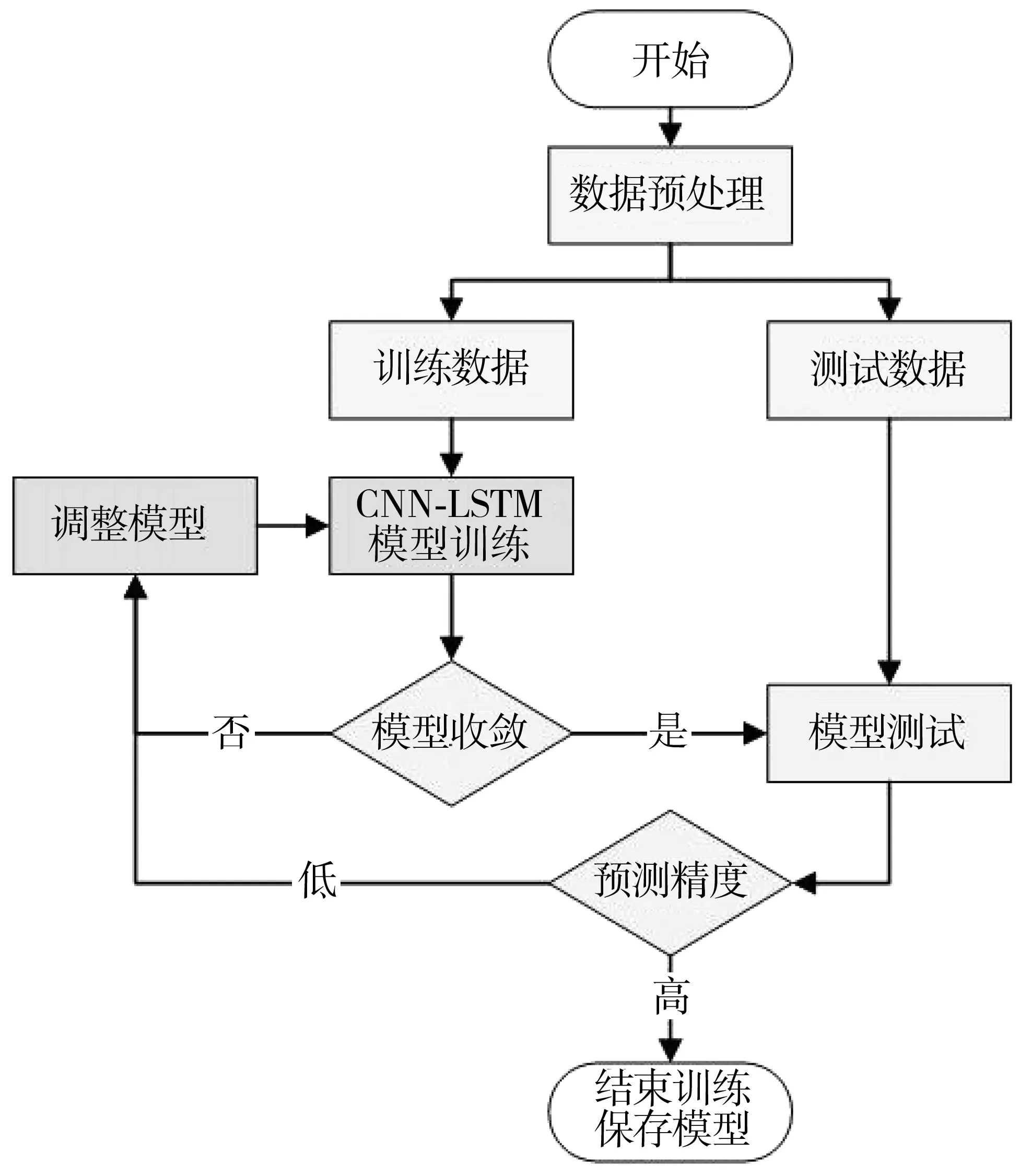
图5 CNN-LSTM模型预测流程Fig. 5 CNN-LSTM model prediction flow chart
其具体流程为:
1)数据预处理。以水质参数:TDS、pH、ORP、T、Cond、ALK作为训练数据,将CO2通量作为标签。为了加快模型收敛速度,消除数据之间的量纲和取值范围差异的影响,对输入数据进行最大最小标准化处理,使数据缩放到(-0.5~0.5)的范围,最大最小标准化公式如式(12):
(12)
式中:z为原始值;z*为标准化后的值;zmax与zmin分别为样本数据中的最大值与最小值。
2)CNN-LSTM模型训练。随机选取所有数据的80%作为模型的训练集,其余20%的数据作为测试集。采用监督学习的训练方式对模型进行反向传播优化权值与偏置值。优化算法采用Adam算法,损失函数采用绝对均值(MAE)。对模型进行分批次训练,更新权值与偏置值。每批次训练数据设置为6,经过1 000轮训练,当损失函数收敛稳定时视为模型训练完成。保存训练好的模型,用于测试。
3)模型预测。加载训练好的模型,将20%的测试数据输入模型进行评估。计算预测结果的MAE、RMSE和R2作为模型的评价指标。
3 试验结果与分析
3.1 试验条件
笔者选取2016年—2017年云贵高原岩溶深水水库——万峰湖水库的47组数据作为训练数据,通过数据训练结果检验模型的有效性。建模使用的处理软件为python3.6,软件框架为基于Keras深度学习工具的Tensorflow框架。
3.2 试验设计
为了验证笔者提出的CNN-LSTM模型在CO2通量预测上效果的有效性及精确性,笔者设计如下几组模型试验:
1)CNN-LSTM模型(文中模型):先输入2层CNN神经网络进行特征提取,然后输入2层LSTM神经网络进行时序特征提取,最后进入4层DNN回归层进行线性映射得到CO2通量。
2)CNN模型(对照模型1):通过2层CNN神经网络层与4层DNN神经网络进行预测。
3)LSTM模型(对照模型2):通过2层LSTM神经网络和4层DNN神经网络进行预测。
4)DNN模型(对照模型3):直接把未特征提取水质指标特征数据经过4层DNN神经网络进行预测。
3.3 试验结果分析
为了保证试验对比结果的有效性,各模型以相同的80%训练集与20%测试集进行训练,数据预处理方法一致,CNN与LSTM模型参数与文中模型对应部分相同。每个模型训练至损失函数收敛。所有模型的评价指标都为绝对均值(MAE)、均方根值(RMSE),通过对比不同模型间的评价指标评价模型预测结果的准确性。各模型的评价指标RMSE和MAE如表1,各模型预测值与实测值的相关性(R2)如图6。
试验结果表明4种模型均能在一定程度上对CO2通量进行预测,且预测值与实测值的相关性均较高(R2>0.90)。CNN模型直接对数据进行特征提取后输入全连接进行回归预测,取得一定的效果。LSTM模型虽能够有效的提取时序数据间的时序特征,但未对水质参数进行高纬度的特征提取,所以预测精度小于CNN模型。DNN模型直接输入未提取特征的数据进行预测,因而所得预测值误差最大。
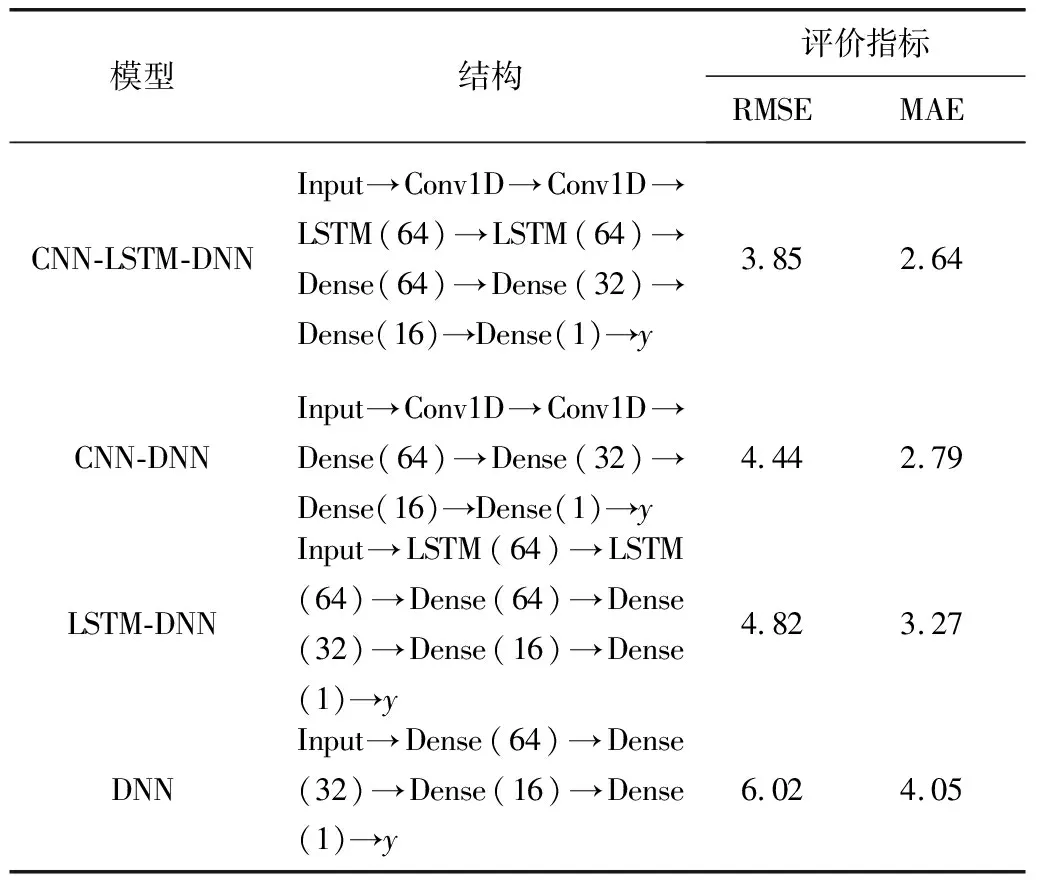
表1 各模型指标对比Table 1 Comparison of various model indicators
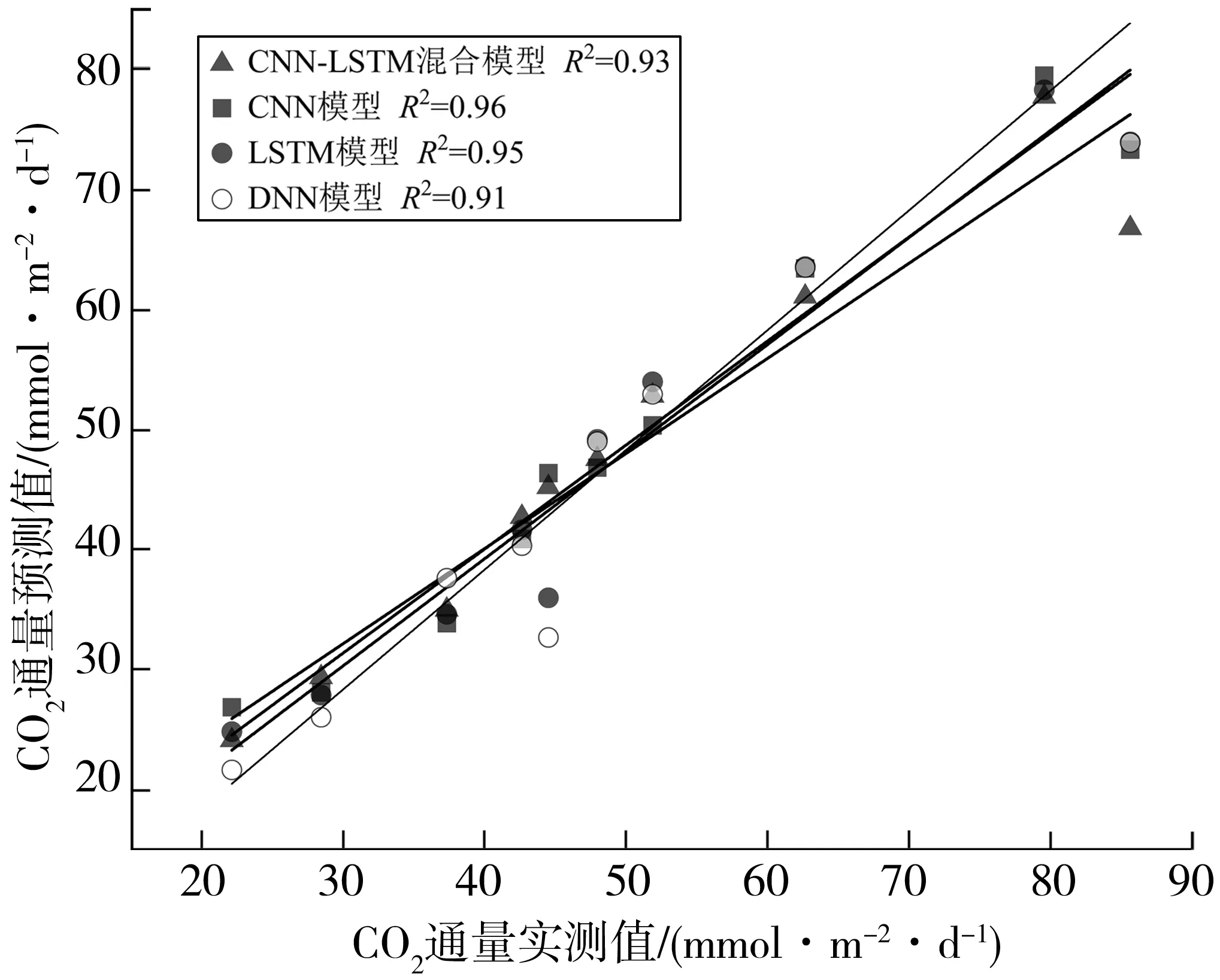
图6 4种模型预测值与实测值相关性分析Fig. 6 Correlation analysis between the predicted and the measured values of four models
从表1及图6可以看出,4个模型都能较为准确地预测CO2通量,但是CNN-LSTM模型的预测效果显然最好,预测误差比独立的CNN、LSTM和DNN小,说明CNN-LSTM模型能够更加有效地对特征进行提取融合,进而提高预测效果。
由于样本数据量较小,在训练基于数据驱动的CO2通量预测模型时能够在小样本数据中有效拟合非线性映射函数是准确预测的关键。相较于CNN模型、LSTM模型、DNN模型而言,笔者提出的CNN-LSTM模型一方面能有效减少训练参数;另外一方面,模型能够较为全面提取数据中的高维度特征及数据间的时序特征;同时,模型中加入激活函数能够更好的构建最优特征与CO2通量之间的非线性映射关系,达到最优的预测效果。
笔者建模的原始数据仅有47组,每组包含6项水质参数及一项CO2通量。提出的CNN-LSTM模型由于能够有效地自适应提取小样本数据中的高维度特征从而较精准预测。但相对其他大数据建模而言原始数据量较小,属于小样本数据下的建模研究,预测精度有待进一步提高。
本课题团队后期将致力于采集更多的数据,提升模型收敛程度和预测指数。同时,通过对长江流域水库安装水质指标传感器,以5G通信的方式实现水质数据的实时监测,收集长江流域水质大数据,构建CO2通量实时预测模型。随着数据积累量不断增加、监测范围不断扩大,可为长江流域碳足迹进行全方位预估,补充全球水电项目碳足迹数据库,为长江上下游水电工程的建设和管理提供辅助决策意见。
4 结 论
1)万峰湖水库夏季水-气界面CO2通量仅与pH和ORP有较显著的相关性,而冬季CO2通量与T、pH、ALK、TDS和Cond均有较显著的相关性。在一个完整的水文年内,6项水质指标均可作为CO2通量的重要影响因素。
2)比较4种模型的MAE和RMSE,笔者提出的CNN-LSTM模型约为2.64、和3.85 mmol/(m2·d),低于CNN模型、LSTM模型和DNN模型,相比之下CNN-LSTM模型能更加有效地进行特征提取从而减小预测误差。在模型预测值与实测值的相关性方面,4种模型相关性均高于0.90。
3)神经网络模型具有强大的非线性拟合能力,目前已广泛地应用在人工智能领域。虽然目前深度学习在环境领域应用较少,但其可以很好地解决环境预测问题,随着大数据时代的到来,深度学习必将在传统环境领域内大有所为。
