基于加权协同表示的人脸识别方法
2022-06-23杨章静王镜宇张凡龙
杨章静,王镜宇,黄 璞,张凡龙
(1.南京审计大学 信息工程学院,江苏 南京 211815;2.南京审计大学 江苏省审计信息工程重点实验室,江苏 南京 211815)
0 引 言
过去几十年,研究者提出了诸多的人脸识别方法[1],其中基于表示学习的分类方法被提出并广泛应用于人脸识别。常见的分类器有稀疏表示分类器(sparse representation based classification,SRC)、线性回归分类器(linear regression based classification,LRC)、协同表示分类器(collaborative representation classification,CRC)。近些年,基于上述方法,研究者提出多种改进方法,并广泛应用于图像分类。如KCRC[2]、TCRC[3]、CCRC[4]、WDCCR[5]、Pro-CRC[6]、Bags CRC[7]均在图像分类时取得较好的效果。
通过研究上述基础分类和改进算法后,发现SRC在求解最优化问题时,需要基于L1范数,求解过程较为复杂,所耗费时间较长。LRC是假定待识别图像可由某类样本线性表示而成,其特征表达能力与每类样本的数目相关。CRC在利用全体训练图像线性表示待识别图像时,也没有考虑不同类别样本之间的差异性,导致特征表达能力较弱,识别能力同样受到影响。
针对以上问题,本文将待识别图像线性表示成全体训练图像的线性组合,同时将待识别图像与每类样本的距离信息作为先验信息引入到特征表示函数中,提出了加权协同表示(weighted collaborative representation classification,WCRC),在Yale B、CMU PIE及AR人脸库上的实验结果表明,WCRC较其它算法取得了更好的识别效果。
1 协同表示分类器
首先假设每幅图像的大小为w×h, 训练样本来自c个图像类,每类的样本数量为n0, 训练样本表示为xi∈D, 其中D=w×h, 训练集样本表示为X=[x1,x2……xn], 将待识别样本表示为y, 其中n表示人脸图像训练样本数n=n0×c。
根据协同表示分类器的思想,待识别样本可以表示为全体样本的线性组合
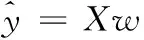
(1)
目标函数如下
(2)
式中:w=[w11,w12,…,w21,…wcn0]T∈n×1为线性重构系数,wab表示第a类的第b个样本的表示系数。使用最小二乘法来求解w,其中λ为正则项参数
(3)
利用拉格朗日乘子法求解并化简目标函数如下

(4)
式中:P=(XTX+λ·I)XT, 每个样本的重构系数残差为
(5)
待测试样本归类为第k类
γk=argminiγk
(6)
2 加权协同表示分类器
CRC使用全体训练样本作为字典集协同表示待识别样本,将所有训练样本不加区别地利用,该算法没有考虑到样本间的区别性,同时算法引入了正则项系数,使得识别率不稳定,对含有遮挡的数据缺乏鲁棒性。受CRC启发,将待测试样本与训练样本间的距离作为权重引入到协同表示过程中,提出了基于加权的协同表示方法。
2.1 算法思想
通过研究协同表示的多个改进算法[3-7]和稀疏表示原理[8,9]后,发现对协作表示系数的约束和加权是增强模型表示能力的简单而有效的方法,通过引入权重增强样本间区别性[10-13]。为克服正则项参数敏感问题,使用Bootstrap抽样生成不同的样本集,采用多分类器投票产生结果[14],文献[6,7]从增强样本间的竞争角度出发,利用样本的区别性提高识别率。为了增加样本间差异性,同时减少正则项参数对结果的影响,加强模型对各种数据的鲁棒性,提出基于加权的协同表示算法。算法首先对数据进行特征提取(PCA、LDA、LPP);然后利用最小二乘法求解表示系数,并基于L2范数求解最优化问题,将距离作为先验信息引入到目标函数构造中,使得模型表征能力增强;最后根据待识别图像与每类训练图像的重构残差大小判断待识别图像的类别。
考虑到类别间的区别度,通过引入距离作为权重的有效性验证,根据样本与类别间的距离远近来弱化或增强对应类别在协同表示中的权重,假设待测试样本y∈Xi, 其它样本Xo, 目标函数可写成
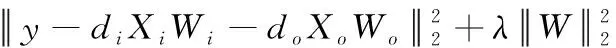
(7)
当di增加,do减小时,Xi在回归中所占比重增加,Xo所占比重减小,导致Wi能以更小的变化,Wo需要更大的变化对协同表示结果产生影响,使得最后协同表示的结果更偏向于在距离上较近的分类。以Yale B数据库为例,对比WCRC与CRC在同一类待识别样本随训练样本数目递增情况下的平均重构残差,计算公式如下
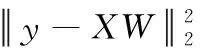
(8)
式中:y为待识别样本,X为训练样本,W为重构系数,如图1所示。
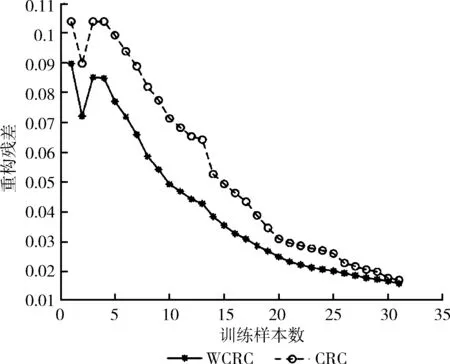
图1 待测试样本在CRC和WCRC算法下的重构残差
由图1可知,WCRC重构残差整体保持在CRC的下方,随着训练样本数增加,其对图像的表示能力逐渐接近。因此引入距离作为加权可以明显增强模型的表示能力,使得重构后的图像与待测试图像之间的残差更小,可见将距离作为先验信息可以增强模型的表示能力。
为了进一步验证引入距离信息作为权重对分类结果有效,根据文献[5]引入相似系数
Similar Corr(y,XiWi)=yTXiWi
(9)
式中:y为待识别图像,Xi为第i类的训练图像,Wi为第i类的表示系数,待测试图像与某一类线性表示结果越相似,则相似系数越大。以Yale B数据库为例,图2(a)、图2(b)展示了CRC与WCRC对某类样本的平均重构残差和相似系数,其中实线代表重构残差,虚线代表相似系数。
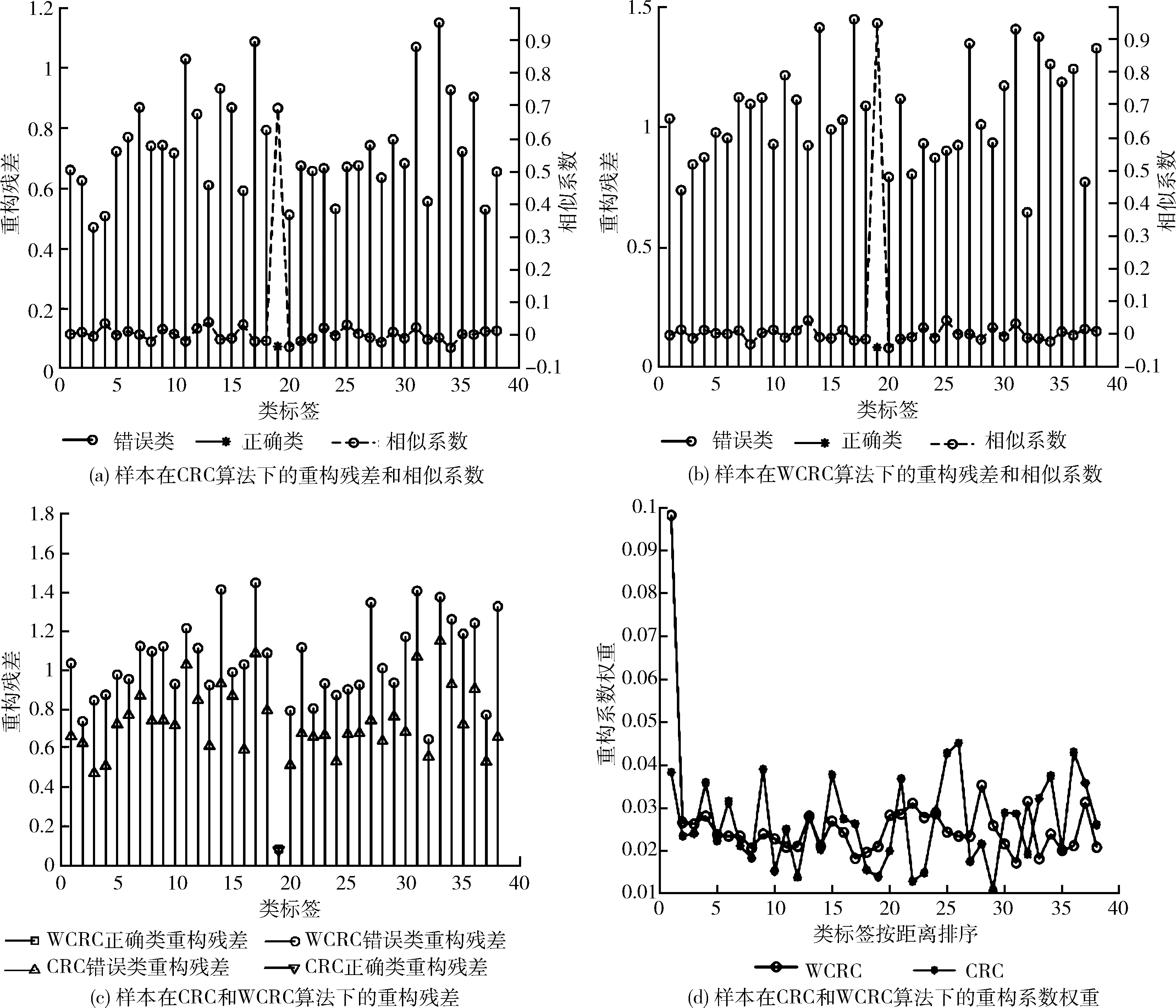
图2 样本在CRC和WCRC算法下的重构残差和相似系数
从图2中可以看出相似系数和重构残差成反比关系,Gou等指出错误分类往往是由于错误类与正确类存在较大相关性所致[5],对于这种问题解决办法是增强类别间的竞争性,因此可通过引入样本间的先验信息,进而增强类别间的竞争性,从而使得正确类别能在协同表示中更具优势。图2(c)展示了CRC与WCRC对某类样本的重构残差对比情况,其中正三角代表CRC中错误的类别重构残差,倒三角代表正确类别的重构残差,圆形代表WCRC中错误类别的重构残差,方形代表正确类别的重构残差,从图2(a)~图2(c)可以看出WCRC算法在略微增加正确类别重构残差的情况下,大幅增加错误类别的重构残差,同时使正确类别的相似系数更大,增强了类别间的竞争性。图2(d)展示了将不同类按距离从近到远排序后,对某样本不同类所占的重构系数比重。星形代表CRC的重构系数权重,圆形代表WCRC的重构系数权重,由图2可知,引入距离作为先验信息可以显著增强协同表示下不同类的差异性,使距离较近的类样本在重构系数中的权重增强,提高模型的协同表示能力,提高了最终识别率。
2.2 算法描述
设每幅图像的大小为w×h, 训练样本来自c个图像类,每类的样本数量为n0,将训练样本表示为xi∈D, 其中D=w×h, 将训练集样本表示为X=[x1,x2,…,xn], 将待识别样本表示为y,其中n表示人脸图像训练样本数n=n0×c。
(1)令di表示待识别样本y与第i类样本距离,则di计算式为
(10)

(2)令W=[w1,w2,…,w3]T∈Rn×1表示线性组合系数向量,其中wi表示训练样本xi对重构y的表示系数。根据样本类别,可将W表示为W=[W1,W2,…,Wc]T∈Rn×1。 结合待识别样本与每类样本之间的距离信息,对于待识别样本y可由全体训练样本协同表示为
(11)
式中:Λ为对角矩阵,对角线上的元素Xi(i=1,2,…,c) 为第i类样本的集合且Xi=[X1,X2,…,Xc]。
(3)根据最小二乘法,线性重构向量W可通过求解以下目标函数获得
(12)
式中:ε>0表示重构残差。
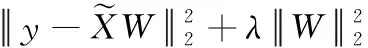
(13)
求W偏导数,并将其设置为0,进一步化简可得
(14)
式中:I∈Rn×n为单位矩阵。
(5)构造待识别样本的类标判别规则,判断待识别样本类别,待识别样本y与第i类样本的重构残差为
(15)

γk=argminiγi(i=1,2,…,c)
(16)
则可将待识别样本y归为第k类。
3 实验结果与分析
本章节通过实验验证WCRC算法的有效性和可靠性,主要采用识别率作为评判标准验证算法性能,对比算法有NNC、SRC、MDC、LRC、CRC。在Yale B、CMU PIE人脸库上分别设置5组和3组实验,用于检验WCRC对于不同光照条件和表情变化的分类性能;在CMU PIE人脸库上设置1组运行时间对照实验;在AR人脸库上设置4组实验,用于检验WCRC对于大幅表情变化的分类性能;同时设置2组关于正则项参数的实验来检验正则项对WCRC识别率的影响。所有实验均在MATLAB(2020a)环境下运行。
3.1 Yale B数据库实验
Yale B人脸库包含38人的64种不同姿态和光照条件下的2432幅图像,其中的姿态和光照变化图像都在严格控制条件下采集的,Yale B数据库上的部分人脸图像如图3所示。

图3 Yale B数据库上的部分人脸图像
实验时按顺序选取前l(=8,12,16,20,24) 个样本作为训练样本,剩余的作为测试样本。所有样本归一化处理后,统一经过PCA降维处理,特征维数取值从80到150间隔为10,SRC、CRC和WCRC中的参数λ=0.01。实验结果如图4(a)~图4(e)所示,表1为Yale B数据库上几种方法取得的最高准确率。
由表1可知,在大部分情况下,WCRC识别率都高于其它算法,且在训练样本较少时,相较于SRC与LRC,算法优势明显,证明了协同表示的有效性;相较于CRC,识别率也有一定幅度的提升。WCRC引入距离作为先验信息增强模型的特征表示能力,有效地提高了识别率,算法识别性能随样本数和维数提升稳定,说明WCRC对于不同光照条件下的人脸具有较好的分类和表示能力。
3.2 CMU PIE数据库实验
CMU PIE人脸库C29部分包含68人,每人24幅,共1632幅图像,均为像素的灰度图片,CMU PIE数据库上的部分人脸图像如图5所示。
实验选取前l(=4,6,8) 个样本作为训练集,剩余的训练样本作为测试集。所有样本归一化处理后,统一经过PCA降维处理,特征维数取值从80到150间隔为10,SRC、CRC和WCRC中的参数λ=0.01。实验结果如图6(a)~图6(c)所示,表2、表3分别显示CMU PIE数据库上各算法的最高识别率及耗时。
CMU PIE数据库的人脸图像有强烈的明暗对比,且有一定的偏转角度,WCRC在以上各种情况下都取得了较高的识别率,在l=8时识别率相较于CRC算法显著增加。由表2可知,LRC和SRC的识别率依赖于样本数量,这进一步说明在训练数据较少情况下协同表示的有效性,以及WCRC在不同光照条件下的鲁棒性。由表3可知,由于WCRC基于L2范数求解,相较于SRC,其运行时间大幅减少,但由于增加了测试样本与训练样本的距离运算,所以相较于CRC运算稍慢。
3.3 AR数据库实验
AR人脸库有3276幅图像,包含126人,包含不同表情、光照、角度、遮挡等情况,每人26张,分两部分,前后各13张,间隔14天采集。实验中的图像经过预处理采用不含遮挡的数据库,一共120个类别,每个类别14幅图像,一共1680个样本,AR数据库上的部分人脸图像如图7 所示。
实验时选取前l(=3,5,7,9) 幅图像作为训练样本,剩余的作为测试样本,所有样本经过归一化处理后,特征维数取值从80到150间隔为10,SRC、CRC和WCRC中的参数λ=0.01,实验结果如图8(a)~图8(d)所示,表4为AR数据库上几种方法的实验对比结果。
由表4可知,WCRC表现出较好的分类性能,在各个训练样本数下,均取得最高识别率;并且在维数和样本数较低时,相较于其它分类算法优势明显,且在l=5时,识别率相较于CRC算法显著增加,可见WCRC算法对于表情变化具有较强的鲁棒性。
3.4 图像遮挡实验
本节主要探究WCRC算法在图像存在遮挡时的有效性以及含有遮挡数据的鲁棒性。实验以AR人脸数据库中无遮
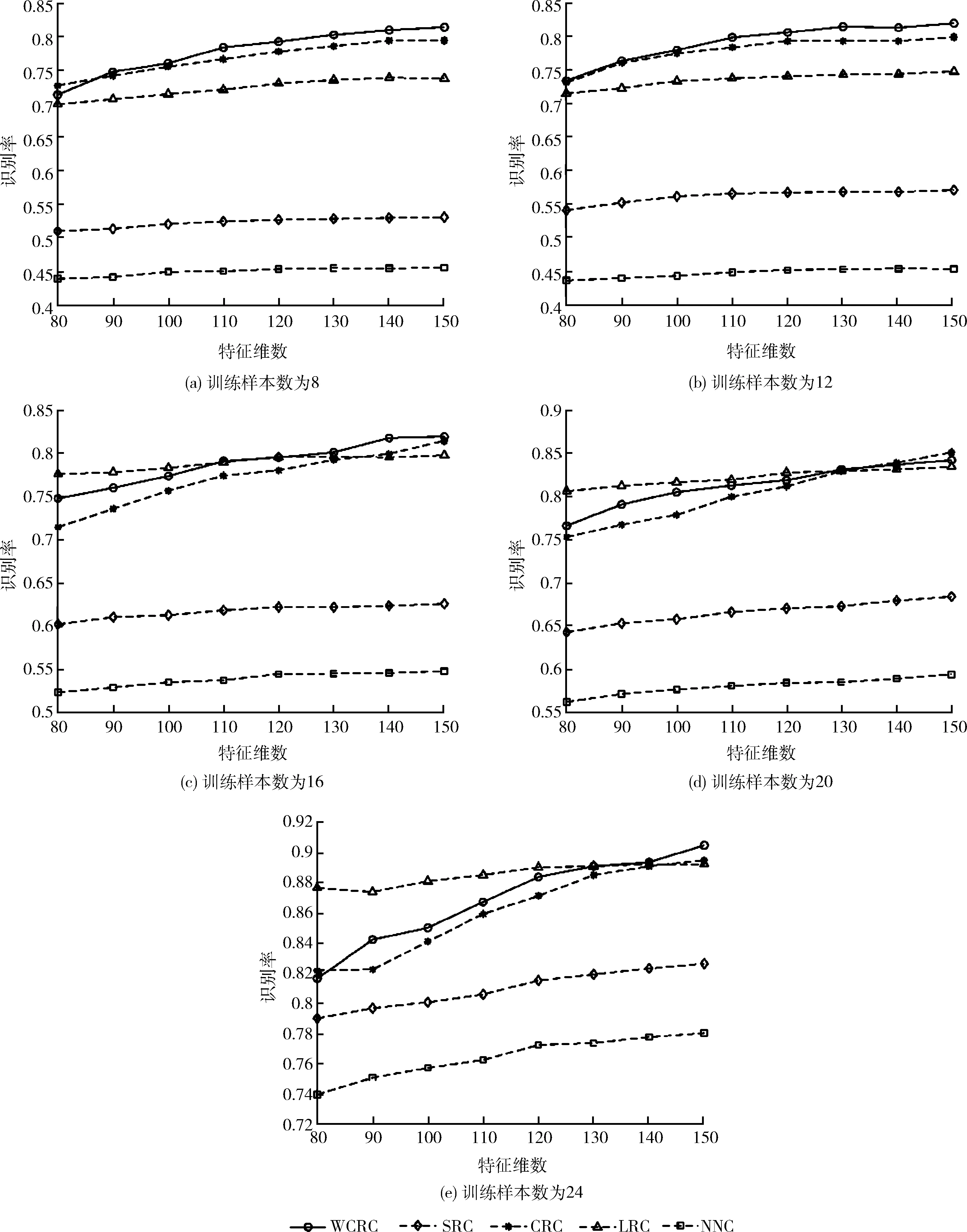
图4 Yale B数据库上各算法在不同训练样本数下识别率变化情况
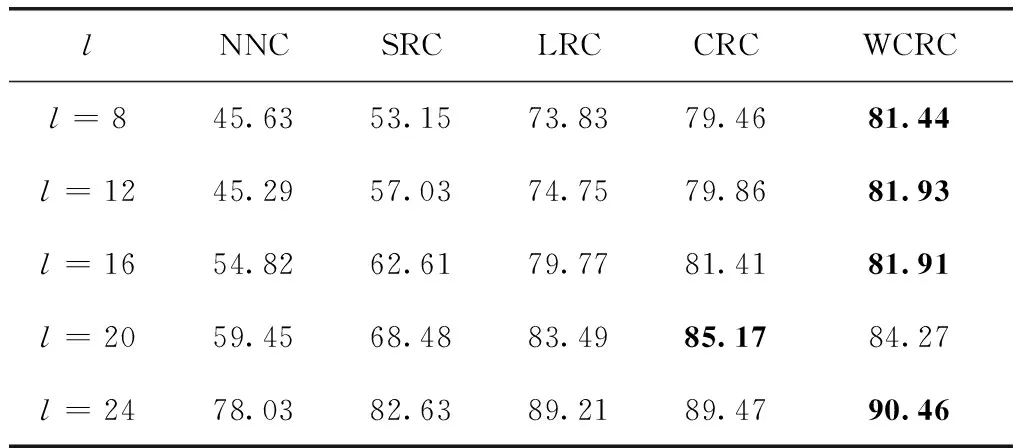
表1 Yale B数据库上WCRC与其它算法识别率比较/%

图5 CMU PIE数据库上的部分人脸图像
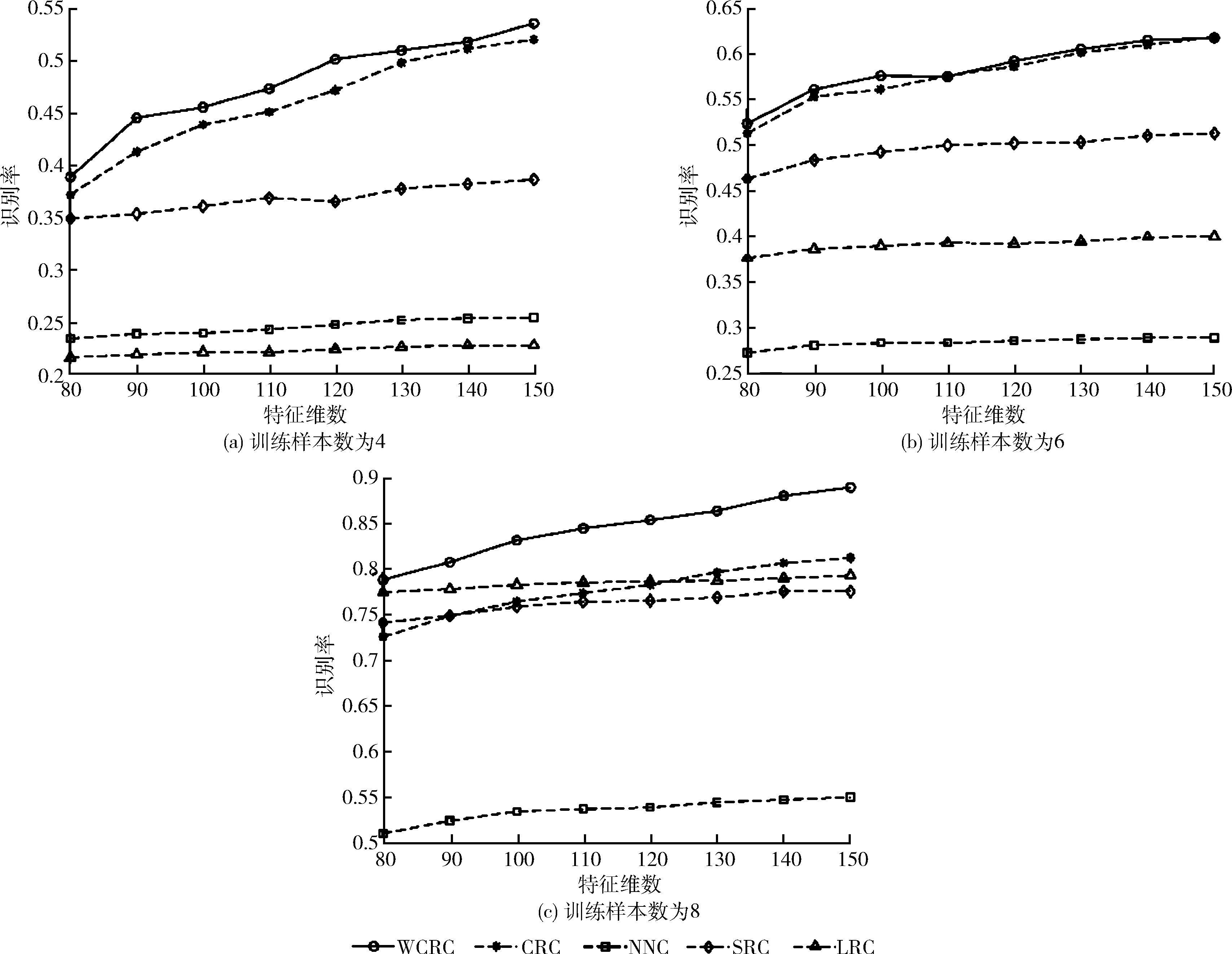
图6 CMU PIE数据库上各算法在不同训练样本数下识别率变化情况

表2 CMU PIE数据库上WCRC与其它算法 识别率比较/%

表3 CMU PIE数据库上各算法耗时比较/s

图7 AR数据库上的部分人脸图像
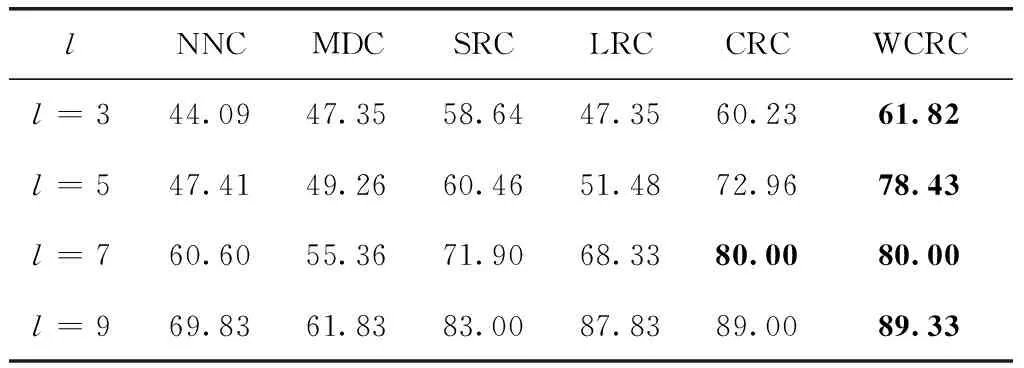
表4 AR数据库上WCRC与其它算法识别率比较/%
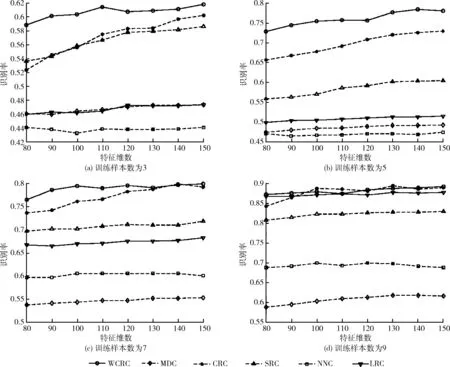
图8 AR数据库上各算法在不同训练样本数下识别率变化情况

图9 AR数据集上的遮挡图像
挡的前l(=14)幅图像作为训练样本,将含遮挡的图像按遮挡类型分两部分,作为两组测试样本。所有图像均经过归一化后使用PCA提取特征并保留特征维数到150,数据集上的遮挡图像如图9所示,包含墨镜和围巾两部分,实验结果如图10所示。
由图10(a)可知,在墨镜遮挡情况下所有算法均取得了相似的识别效果,且都保持在90%以上;由图10(b)可知,在围巾遮挡情况下体现了协同表示算法的有效性,SRC、LRC、NNC的识别率均在40%以下,协同表示算法的识别率均在45%以上。其中WCRC算法相较于CRC算法表现出更鲁棒和有效的结果。究其原因,墨镜对人脸保留了绝大部分特征,所以识别率没有受到太大影响。对于围巾遮挡情况,由于嘴部及脸部的灰度轮廓是重要的识别特征[15],被遮挡后导致大部分特征丢失,无法有效辨别正确的类,所以识别率较低。WCRC引入了距离作为权重系数,增强了类别间的区别度,一定程度上强化了部分特征,所以取得了更好的分类性能,使得算法对含有存在遮挡的数据更具有鲁棒性。
3.5 正则项参数实验
本节主要探究所提算法选取不同的正则项参数对于识别率的影响,实验以AR数据库在训练样本数为9时举例,具体设置两组实验,第1组按顺序选取样本,正则项参数λ从0到10之间等间距取50个值;第2组实验随机选取训练样本,剩余的样本作为测试样本,正则项参数λ从0到1之间等间距取20个值,实验结果如图11所示。
由图11(a)可知,随着正则项增加,识别率先升后降,在λ=0时CRC与WCRC均失效。CRC与WCRC均在λ=0.02附近取得最高识别率。相较于CRC,WCRC随着正则项增加,识别率衰减较缓慢;由图11(b)可知在随机选择训练样本和测试样本情况下,λ取值在10-5到1之间时,WCRC识别率保持稳定,且识别率在不同样本下具有相同的变化趋势,这表明WCRC对于不同数据的选择具有鲁棒性。
3.6 实验结果分析
根据实验结果,可得结论如下:
(1)在训练数据较少时,协同表示算法利用全部训练样本作为字典集表示待识别样本,算法识别率较高。WCRC引入距离信息作为权重构造目标函数,增加了类别间的区分度,提高了正确分类的概率,使得引入距离作为先验信息,有效提高了算法的准确率。在CMU PIE数据库上的训练样本从l=6到l=8和在AR数据库上的训练样本从l=3到l=5,相比CRC,WCRC识别率有了大幅提高,随后与CRC相近,这是由于WCRC随着训练样本数增加,样本内均值更具代表性,引入距离作为权重,使得WCRC在较少样本数时便能取得高识别率,随后样本继续增加,样本的内均值趋于稳定,识别率变化相对较小。
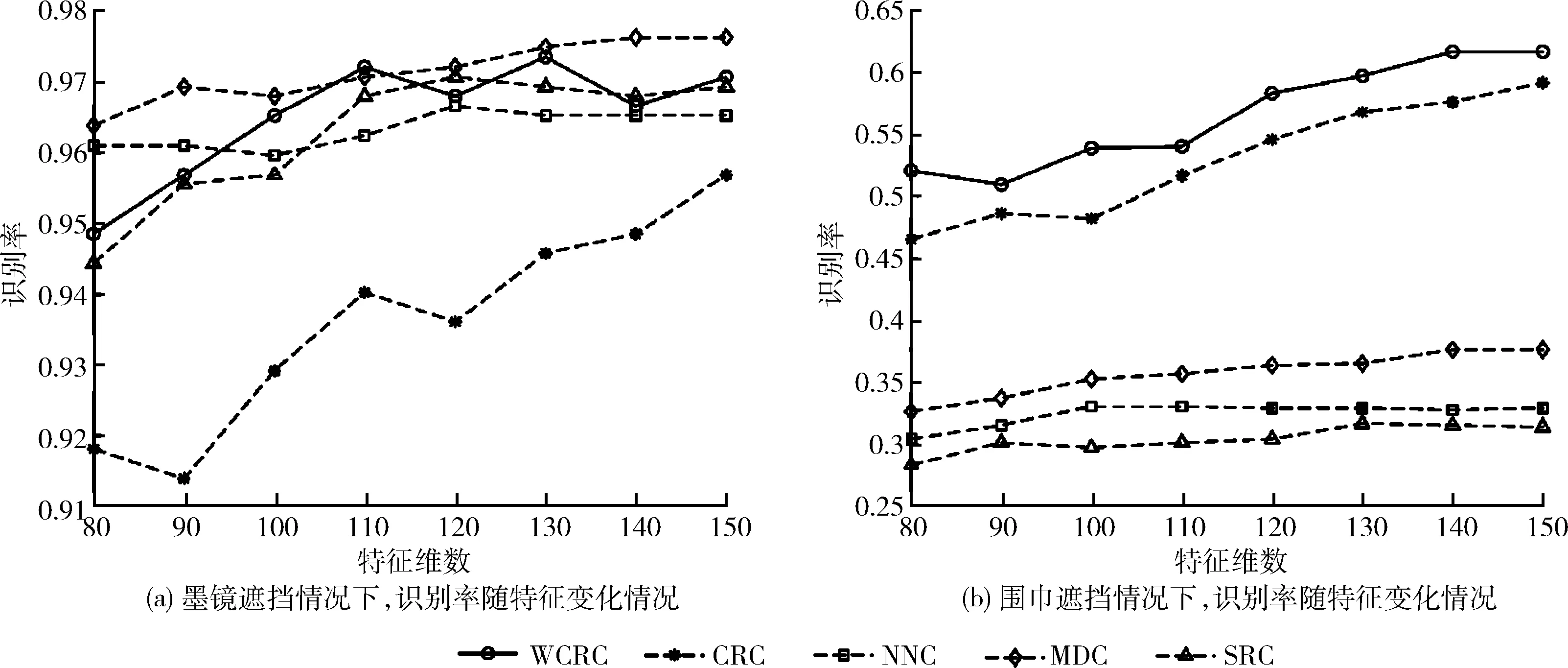
图10 图像遮挡情况下识别率变化情况
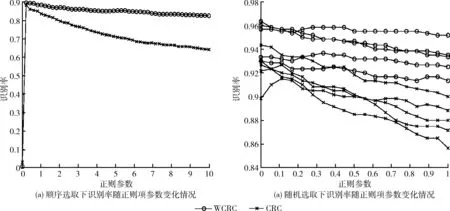
图11 识别率随正则项参数变化情况
(2)WCRC进一步优化SRC的L1范数求解,采用L2范数作为约束条件,所以相较于SRC,算法复杂度大幅降低,求解过程简单,计算速度较快。由于增加了对于样本间距离信息的处理,需要计算待识别样本与其它测试样本间的距离,所以相较于CRC,有一定的复杂度提升,耗时稍长。
(3)对比其它算法,WCRC对含有遮挡的数据具有更强的辨别能力。由于考虑到样本间的距离信息,使得算法对于结果更倾向于选择距离较近图像的特征,从而增强了算法对含有遮挡数据集的识别率。
(4)对于算法中可调节正则项参数λ,其取值对算法识别率有一定的影响。但WCRC引入距离作为权重信息参与目标函数的构建,使得目标函数中λ作用相对减弱,WCRC对正则项参数的取值相对不那么敏感。
(5)WCRC在CRC基础上提出,由上述实验结果可知,在3种人脸库上,相较于CRC,WCRC取得较好的识别效果,这主要是由于WCRC考虑了样本间的距离信息。
(6)由表1、表2、表4可知,WCRC在3种人脸库上,相较于其它算法,均取得了较好的识别效果,这进一步验证了所提算法的有效性。
4 结束语
针对SRC和CRC在处理人脸识别时存在的缺陷,提出基于加权协同表示的人脸识别方法(WCRC)。WCRC利用样本间的距离作为先验信息引入到目标函数中,突出了样本之间的区别度,使得模型的协同表示能力和识别能力增强,同时算法采用L2范数作为稀疏解的约束条件,放宽了重构系数的稀疏性要求,在面对人脸图像的光照、表情、姿态等变化时,算法特征表达能力较强,在降低算法复杂度同时,均可取得较好的人脸识别效果。
在实验时发现不同的预处理方法会影响最终识别的结果,究其原因是不同处理方法会导致类别间的距离发生一定程度上的改变,因此如何进一步优化预处理,寻找一种稳定、有效的类别间距离表示方式是接下来研究和优化的主要工作。
