基于多任务深度学习的关键词生成方法
2022-06-23朱浩翔张宇翔
朱浩翔,张宇翔
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
循环神经网络(recurrent neural network,RNN)和序列到序列模型的提出与应用,给文本关键词的预测带来了更多的可行性。在序列到序列模型的基础上加入注意力机制[1],利用编码器和解码器进行对齐,能有效地关注文档的不同位置。根据统计,文档题目中的单词成为关键词的概率远远高于文档摘要。这说明标题确实包含了高度总结性和有价值的关键信息。合理地利用文档标题的这一特性有助于提升关键词预测的效果。最近的关键词生成方法通常将文档的标题与文档无差别拼接[2],作为预测模型的输入,没有体现文档标题的特殊性。本文以双任务序列到序列模型[3]为基础,将关键词短语的生成作为主要任务,将标题生成作为辅助任务,设计了双任务的注意力联合训练模型Joint-MT。与一般的双任务模型不同,根据注意力机制能衡量输入文本中所有单词对当前关键词生成的重要性的特点,在模型训练的过程当中加入一致性损失,计算两个任务注意力矩阵部分向量之间的相对熵,增强了两个任务之间注意力机制的相关性,使模型能够利用关键词和题目特殊关系提升关键词预测的效果。实验结果表明,相较于基础的生成模型和常用的无监督和有监督提取模型,Joint-MT的预测结果都优于对比实验。
1 关键词预测
随着文本数据数量的快速增长,如何自动地给文本设定恰当而且精准的关键词就成为了自然语言处理领域之中亟待解决的基础问题和研究热点[4]。文本关键词预测的方法可以分成提取与生成两种。提取方法是在文档之中抽取合适的单词或者短语作为对文档的关键词。对于有监督的方法来说,这常常是一种二分类模型,也可以作为多分类模型,比如Alzaidy等[5]和Zhou等[6]利用条件随机场将关键词提取任务作为一种序列标注任务,找出文档中所有可能的关键词。关键词提取方法只能预测在文档中出现的关键词(文内关键词)。生成模型在预测关键词的时候,是从词表当中挑选合适的单词组成关键词,不管这些单词是否出现在文档中[7]。Meng等将序列到序列模型应用到了关键词预测的领域当中,并设计了CopyRNN[2]模型。在此之上,Chan等利用强化学习增强模型的预测结果[8]。这种有监督模型依赖于大量有标记数据。为了解决这个问题,Ye等提出了一种半监督关键词生成模型[3,9],该模型使用有限的标记数据和大量未标记数据和半监督的方法训练关键词生成模型。在文档标题信息的使用上,这两个基于RNN的方法都把文章的摘要和标题无差别地拼接起来作为模型的输入,忽略了文档标题在文本总结当中的重要作用。Chen等提出了Title-Guided[10]模型,加入了模型对文档标题信息的关注。
注意力机制是一种软对齐方法,可以在处理文本的时候,评估文档中不同位置的词语的重要性。如果生成模型只使用固定的词表,总是存在OOV问题。复制机制利用注意力机制[11,12],通过对当前输入文档中的每个单词打分,计算出文本中每个单词在某个时刻成为关键词的概率,解决OOV问题。从表1中可以看出,在KP20K验证集当中,文档题目中的单词成为关键词的概率为24.35%,文档摘要的单词成为关键词的概率为7.37%,而且有相当比例的关键词短语完全地包含于题目。文档标题的关键信息密度高于文档摘要,这是因为文档标题是作者对文档全部主旨内容的最精炼表述。本文的模型受到了Wang等和Chen等[13,14]的启发,采用一致性学习,使多任务模型得到更有效的embedding向量和注意力,强化各任务之间注意力机制的相关性,提高主要任务的效果[15]。
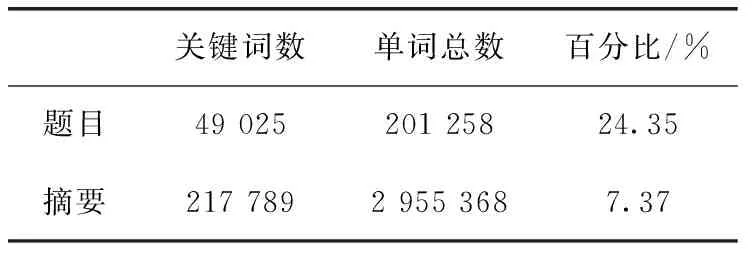
表1 KP20K验证集中文档题目和摘要词语中关键词占比
2 多任务深度关键词生模型
2.1 问题定义
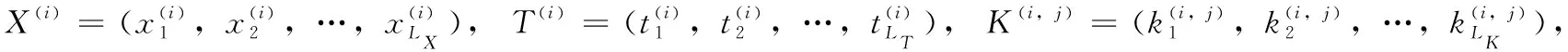
2.2 序列到序列模型
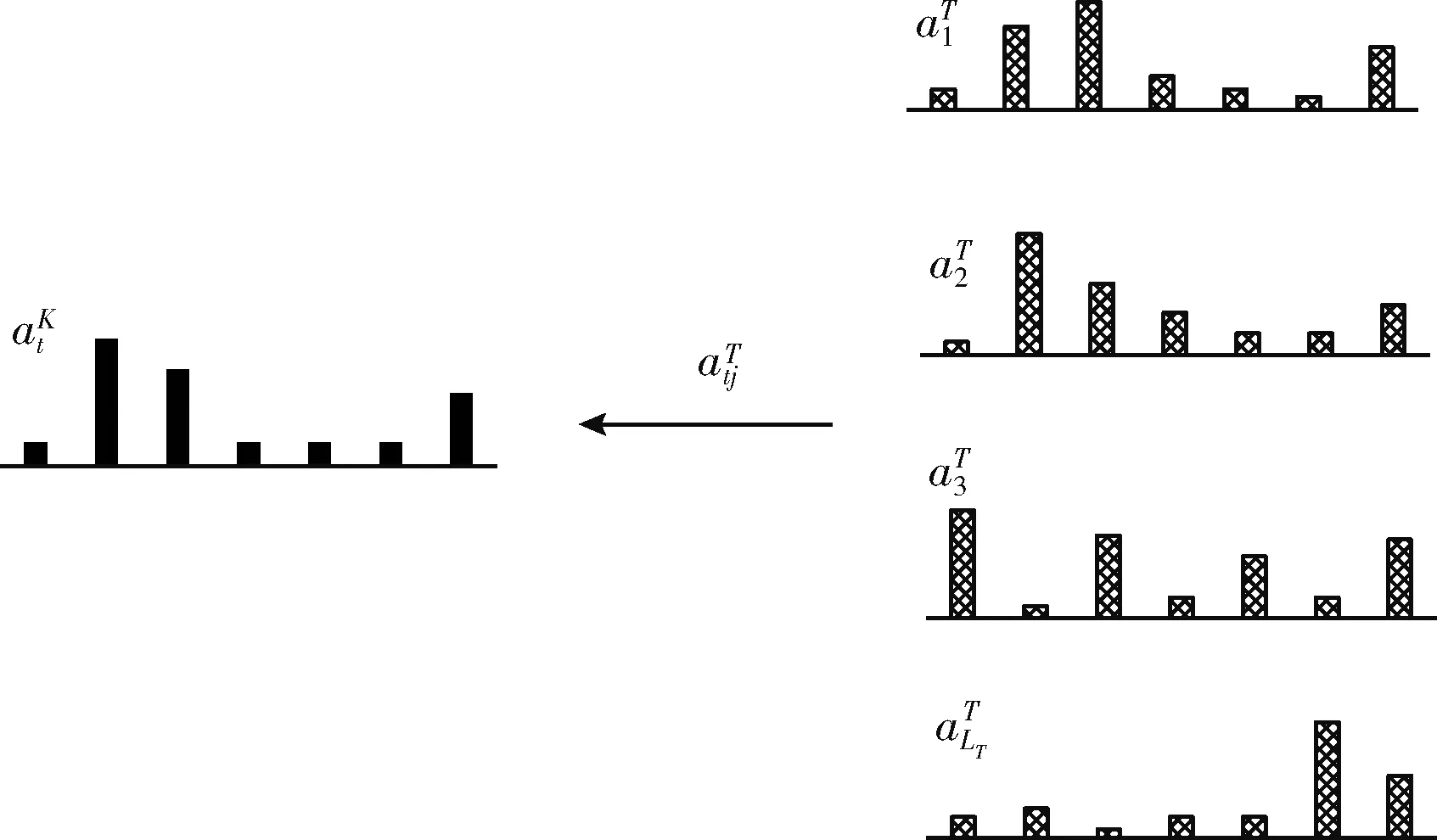
本文使用的多任务深度关键词生成模型由一个编码器和两个解码器组成。编码器将输入文本压缩成为源文本的表示,然后传入解码器中。一个解码器用于生成关键词,另一个解码器用于生成标题。两个解码器共享编码器中的参数,在神经网络前向回馈的过程中对其进行优化,并且加入了一致性约束,模型的流程如图1所示。编码器和解码器都使用了长短期记忆网络LSTM(long short term memory)。长短期记忆网络可以学习上下文信息,同时还可以应对RNN模型可能会出现的长期依赖问题。
在序列到序列模型之中,编码器的目的是将输入的有序文本转化成一个稠密的向量h。本文采用双向LSTM作为模型的编码器,它既编码t时刻之前的文本,也编码t时刻之后的文本,可以更好融合上下文的信息。编码器中编码过程的计算公式为
(1)
(2)
(3)

St=LSTM(yt-1,St-1)
(4)
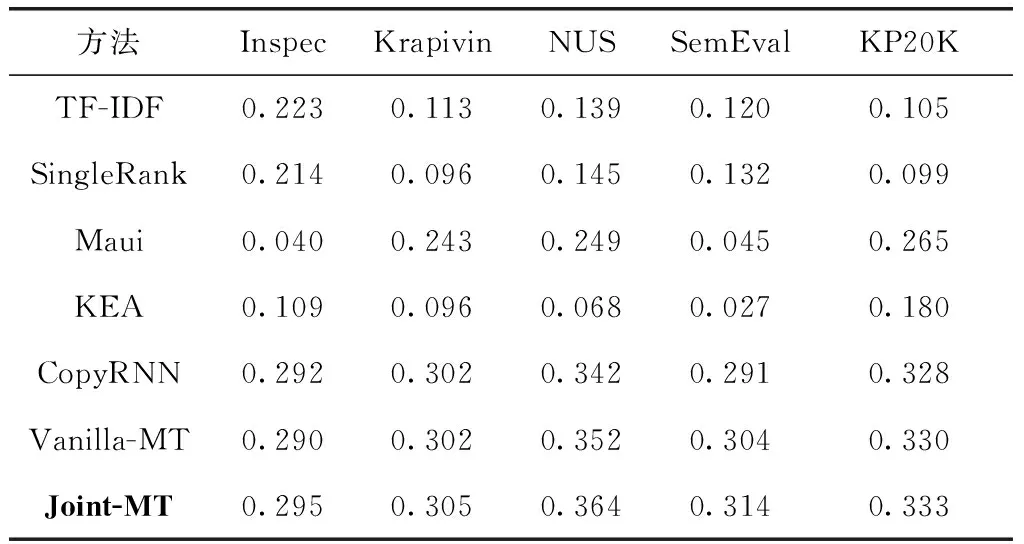
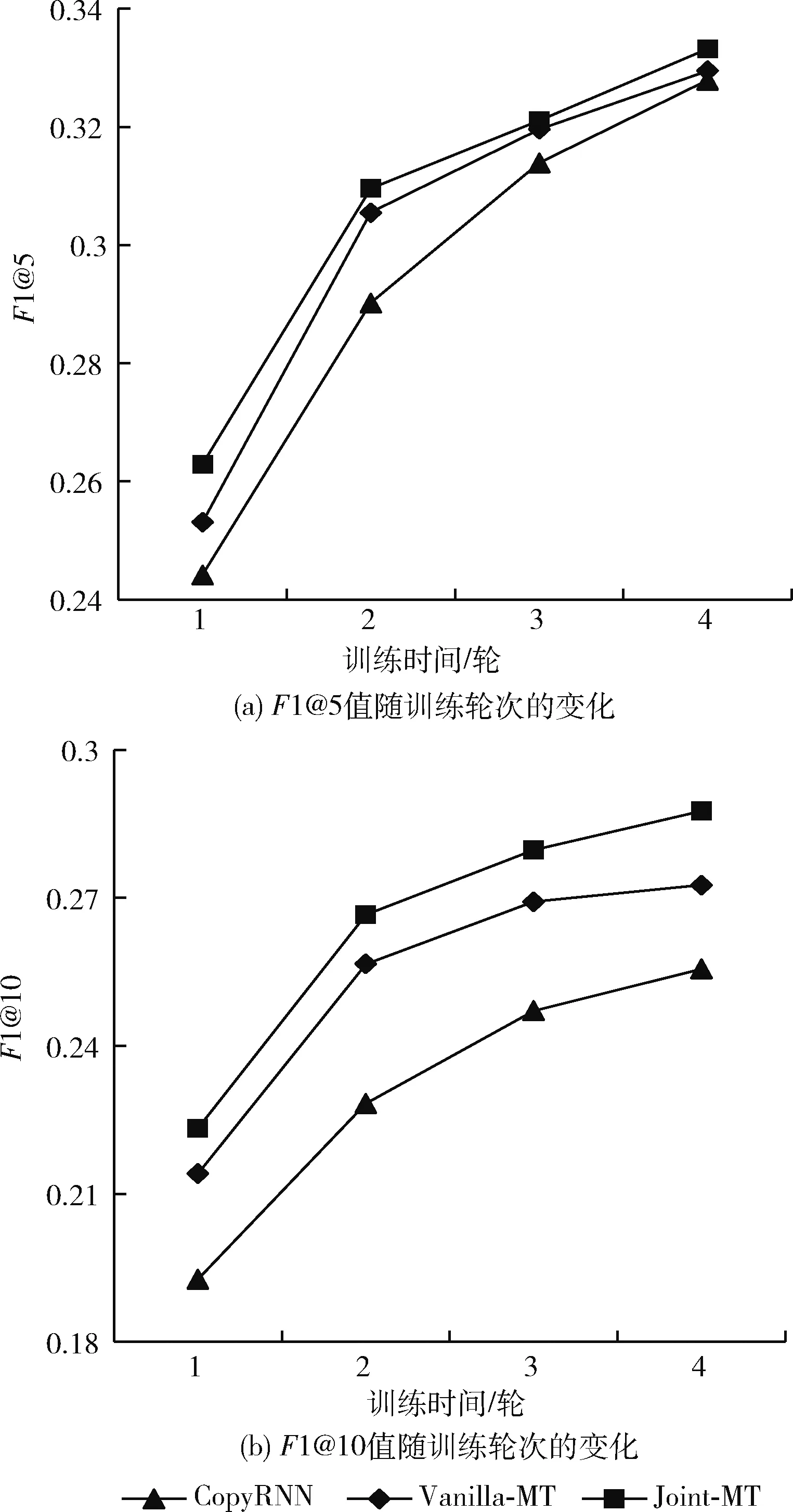
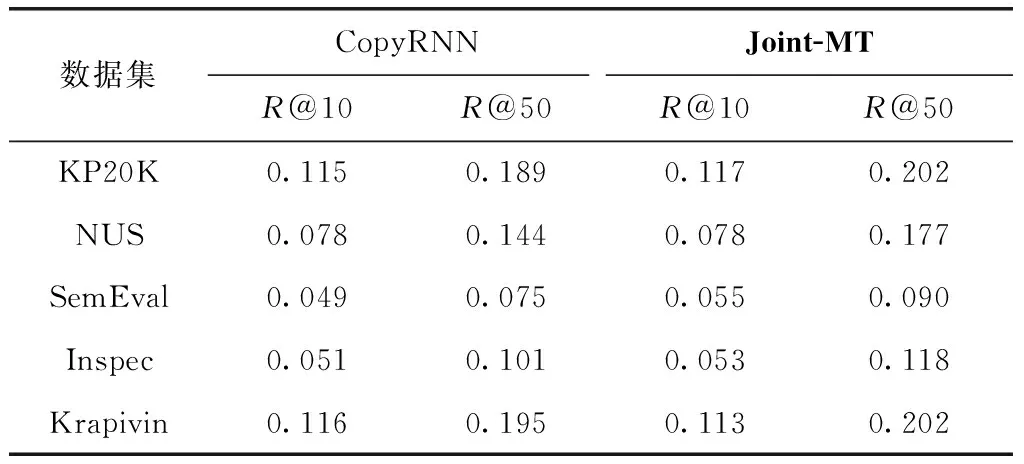
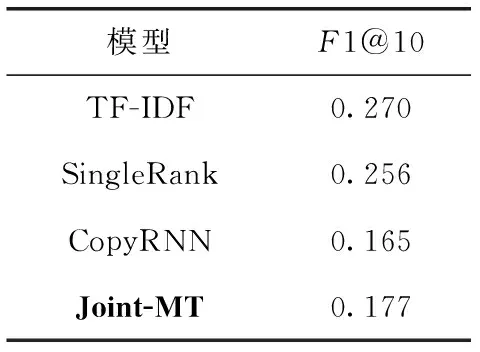
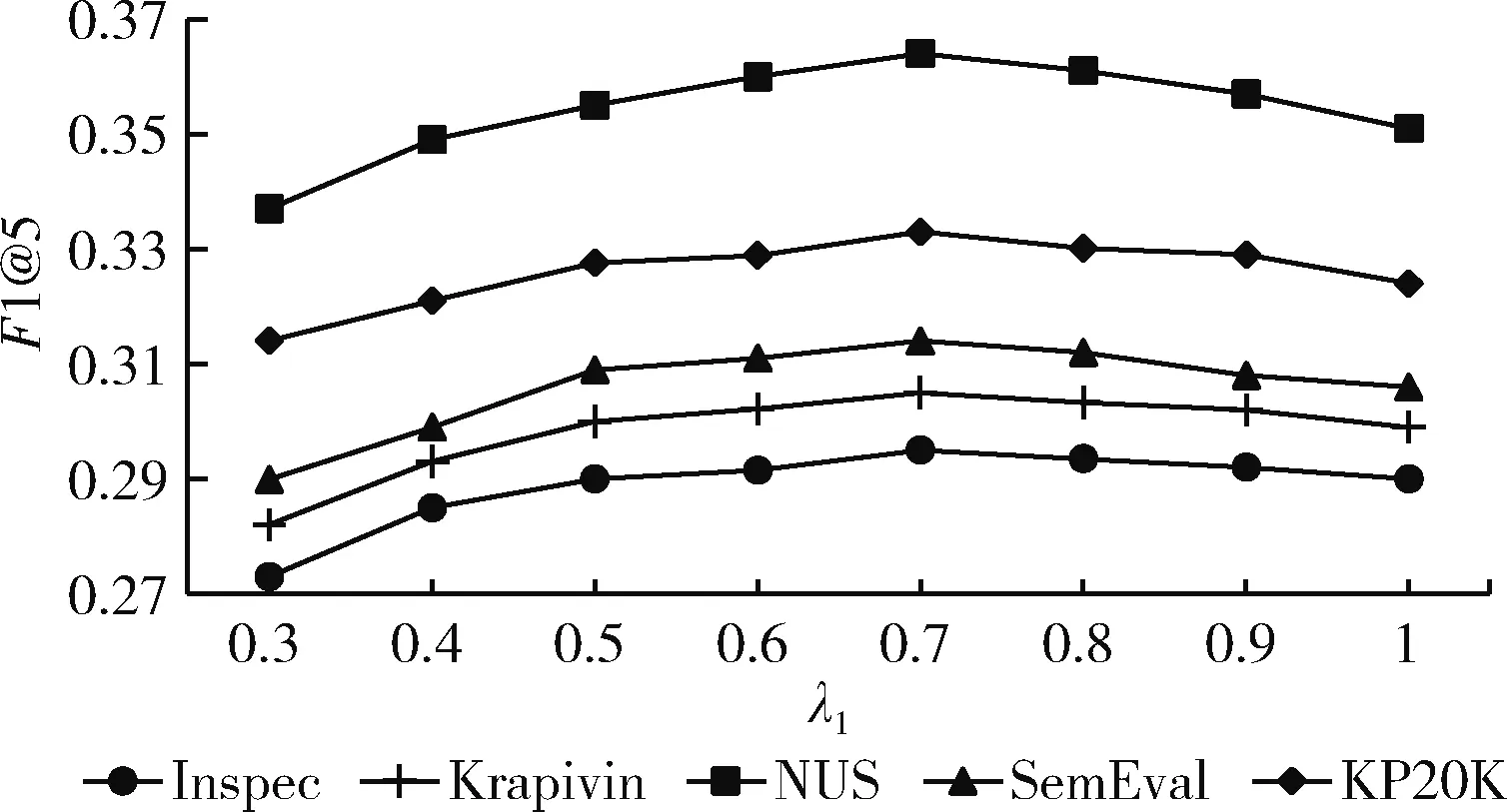
p(yt|y (5) 其中,yt-1表示t-1时刻模型预测的单词,St表示t时刻解码器的隐藏状态。g(·)表示包含注意力机制的非线性可学习函数。p表示t时刻模型预测单词概率分布,表示选取V中单词作为t时刻模型输出的概率。V是模型的单词表,里面包含了训练集中出现频率最高的n个单词(本文n设为50 000)。 在模型训练的过程中,将最小化模型的损失,提高预测正确目标序列的概率。在模型测试时,采用束搜索方法生成关键词,得到关键词短语候选集,在适量的短语上对模型的预测效果进行评价。 关键词生成任务与翻译任务类似,都是根据输入的源文本预测可变长的目标文本。序列到序列的翻译模型中,注意力机制使得模型能够动态的专注于输入文本的重要部分,根据不同的输入文本,给文本中不同位置的信息赋予不同的权重。关键词生成模型之中加入注意力机制能够更好地理解和融合输入文本潜在的语义信息,提高关键词预测的效果。在解码的过程中添加注意力机制计算t时刻生成概率的分布 p(yt|y (6) (7) (8) (9) 其中,a(·)是一种软对齐函数,它衡量了St和hk之间的相似度,Wa是可学习的参数矩阵。 应对生成模型中的OOV问题,使用了复制机制。传统的生成模型在生成关键词的时候,只能预测词表V当中的词语,词表的长度有限,不能包含数据集中的所有单词。然而,文档中会含有不在词表V中的单词,这些单词也有可能是文档的关键词。这种情况下,生成模型就不能预测出这个词表外的关键词。复制机制可以应对这个问题。复制机制和注意力机制的处理相似,它度量源文本中每一个单词在t时刻成为关键词的概率,无论这个词是否存在于词表V中。 与式(7)的处理一样,复制机制计算出衡量源文本单词重要性的向量Ct。最后通过映射的方式得到复制概率pc,也就是在预测关键词的时候,直接从源文本复制这个单词的概率 pc(yt|y (10) 复制概率pc分布在源文本中的所有单词上,这些单词既有词表V中的单词,也可能含有不在词表V中的单词。最终,整个模型在t时刻的预测概率由生成概率pg与复制概率pc相加得到。相加后计算出词表V和源文本的所有单词成为关键词的概率 p(yt|y (11) 在模型训练的过程中,以关键词生成为主要的任务,题目生成为辅助任务。两个任务在训练的过程中的损失(目标)函数可以分别表示为 (12) (13) 只把两个任务的损失相加作为模型的损失(目标)函数,不能将多任务模型的优点发挥到最大。尤其是本文希望模型在预测关键词的时候更加关注文档题目中的单词,因为这些单词更有可能成为关键词。所以本文采用一致性学习(agreement-based learning)[15]的方法。模型中的两个解码器对输入文本有着不同的注意力分布AK和AT,表示解码时对源文本不同位置的关注。本文在模型中添加额外的损失函数对这个两个注意力分布进行约束,使两个解码器在处理重要单词时具有一致性。由于文档的关键词和题目的长度不一样,在计算损失之前需要对齐,如式(14)所示 (14) 图2 对齐联合训练一致性损失 (15) 最后,联合训练的多任务模型的损失函数如式(16)所示,其中包含3个超参数λ1、λ2和λ3 Ltotal=λ1L1+λ2L2+λ3Lagree (16) 本文采用了Meng等[2]从各种在线库中收集的大约57万条数据集样本,选取其中约53万条数据作为模型的训练集,两万条数据作为验证集,两万条数据作为测试集,也就是KP20K。除此之外还在4个被广泛使用的科学领域文档数据集:Inspec、Krapivin、NUS和SemEval,一个新闻领域文档测试集DUC上进行了测试。 根据关键词预测任务的分类,选取了其中具有代表性的模型方法作为对比实验。在文内关键词预测的对比实验中包含了两个无监督的提取方法:TF-IDF方法和SingleRank方法[2],两个有监督的提取方法:Maui和Kea[2],两个有监督的序列到序列生成模型:CopyRNN模型和Vanilla-MT[3]模型。在缺失关键词预测和其它领域文档数据集的关键词预测中,采用CopyRNN作为对比实验。 模型训练时,采用一对一模式,输入文档,模型将输出一个关键词短语。为了满足模型训练的条件在数据预处理时,将KP20K数据集中<文本,多关键词短语,题目>的一对多格式数据转变成<文本,单个关键词短语,题目>的一对一格式。将文本当中所有的数字用 在模型的超参数方面,经过测试和调整,式(16)中的3个超参数λ1、λ2和λ3分别设置为0.7、0.3和0.3。采用维度为150的embedding,初始化在[-0.1,0.1]的随机均匀分布中,所有的LSTM隐藏层向量的维度设置为512,其中包括一个双向的LSTM编码器和两个单向的LSTM解码器。选取训练集中出现频率最高的50 000个单词作为词表V。样本中出现的不在词表里的词作为OOV。每个样本有自己独立的OOV。在模型训练的过程中使用了导师驱动模式。模型使用Adam方法作为模型训练的优化器,学习率为0.001。梯度裁剪为0.1,dropout为0.5。训练时的批处理的大小为96,因为每一篇文章有多个关键词,在每一次批处理的时候,选取的数据对的数量会小于等于96,一篇文章的关键词不会在不同批次进行训练。在预测关键词时使用束搜索方法而不是贪心算法,beam size为200,最大预测长度为6。一旦在验证数据集上确定了收敛性(连续多次验证,评价指标没有提升),模型将停止训练。 一般采用准确率、召回率和F1值作为关键词预测结果的评价指标,为了能够对比模型的效果,我们也同样采用了这些指标评价我们的模型 (17) 式中:#c表示预测正确的数量,#p表示用于评估的预测关键词的数量,#l表示了作者标注的关键词的数量。和CopyRNN和Vanilla-MT模型一样采用了top-N宏平均F1值来评价文内关键词预测,R值来评价缺失关键词预测。例如,F1@5表示取预测结果的前5个关键词短语作为模型的预测结果进行F1值评价,R@50表示取预测结果的前50个关键词短语作为模型预测结果进行R值评价。 3.5.1 文内关键词预测结果 文内关键词的预测结果见表2和表3,使用序列到序列模型CopyRNN,Vanilla-MT和Joint-MT模型在文内关键词预测评价指标F1@5和F1@10上都比无监督的关键词提取方法TF-IDF和SingleRank和有监督的关键词提取方法Maui和KEA都有了明显的提升。在CopyRNN,Vanilla-MT和Joint-MT模型每一轮训练结束后,都采用验证集对模型的关键词预测效果进行验证。结果如图3所示,Joint-MT在训练的速度和最终的结果上都要优于CopyRNN、Vanilla-MT模型。相对于单任务的模型,双任务模型的预测效果更好。例如,在NUS数据集上,Vanilla-MT和Joint-MT模型的F1@5值达到35.2%和36.4%,都高于CopyRNN的34.2%。说明多任务模型共享编码器的参数,提升模型的预测效果。对比于Vanilla-MT模型,Joint-MT模型在5个数据集上的表现都优于Vanilla-MT,验证在损失函数的部分加上关键词生成和题目生成任务之间的相互约束,能够提升模型关键词预测的结果,使模型能充分利用文本题目的信息。 表2 不同模型在5个数据集上的文内 关键词的F1@5预测结果 表3 不同模型在5个数据集上的文内 关键词的F1@10预测结果 图3 模型训练过程中F1的值变化 3.5.2 缺失关键词预测结果 关键词生成方法与提取方法最大的区别就是生成的方法可以预测出缺失关键词。所以和同样是关键词生成方法的CopyRNN进行了对比。由于缺失预测的准确率非常的低,所以选取了合适的召回率R@10和R@50作为对比实验的评价指标。从表4可以看出,在5个数据集上Joint-MT的模型都比CopyRNN模型表现得好。例如,在Inspec数据集上,Joint-MT模型的R@50值达到11.8%,高于CopyRNN的10.1%。说明添加了联合训练的题目生成的辅助任务能够帮助模型更好理解文本深层语义信息。 表4 CopyRNN和Joint-MT模型在缺失 关键词上的预测结果 3.5.3 其它领域的数据测试 Joint-MT模型在KP20K训练集上训练,然后在非科技论文测试集上对比这两个模型的效果,非科技领域的数据使用了常用的一个新闻文章数据集DUC。DUC数据集中包含了308篇新闻文章和2488个人工标注的关键词。 从表5中可以看出,在F1@10的指标中,相比于无监督的IF-IDF和SingleRank方法,Joint-MT模型和CopyRNN模型都远低于它的27.0%。但是与同是经过大量科技文章数据集训练过的CopyRNN的模型Joint-MT的预测结果从16.5%提升到了17.7%。说明Joint-MT即使应用在交叉领域,相比于基础模型可理解更多文本深层的语义。 表5 Joint-MT模型在DUC上的关键词预测效果 3.5.4 超参数的影响 本文的双任务联合训练模型的损失函数中包含了3个超参数λ1、λ2和λ3。本文也对这3个超参数值的设定进行了研究,通过实验调整得到最适合模型的超参数值。首先,在λ1与λ2的设定上,令λ1+λ2=1,不添加一致性损失的情况下(λ3=0),λ1在[0.1,1]中每隔0.1选取一个值分别训练模型,λ1取0.7,λ2取0.3时模型取得最好的训练效果。在确定λ1与λ2之后,λ3在[0,1]之间每隔0.1选取一个值分别训练模型,λ3取0.1时模型取得最好的训练效果。调整λ3值之后,我们又重新对λ1与λ2的取值进行了验证实验,结果如图4所示。通过对比实验与验证实验,最终确定λ1、λ2和λ3的值。 图4 λ1取值在5个数据集上的验证实验结果 为了利用文档标题和关键词之间的密切关系,提升序列到序列模型的关键词短语的预测表现,本文提出了双任务损失联合训练的序列到序列关键词短语生成模型Joint-MT。在双任务模型训练的过程中添加一致性约束来加强两个任务之间的相互联系,既提升了文内关键词预测的效果,又提升了缺失关键词预测的效果。在未来的工作中,希望结合Transformer[1]方法,让模型能更好地融合文本的深层语义,进一步提升缺失关键词的预测效果。2.3 注意力机制
2.4 复制机制
2.5 多任务联合训练损失函数
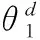
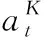
3 实验与结果分析
3.1 数据集
3.2 对比实验
3.3 实验配置
3.4 实验评价指标
3.5 结果分析

4 结束语
