基于大数据的供应链金融信用风险评估实证研究
2022-06-21周雷邱勋朱奕毛晓飞
周雷 邱勋 朱奕 毛晓飞


摘 要:通过将前沿大数据征信技术与评分卡方法相结合,以整车制造行业供应链为场景,对供应链金融信用风险进行测度。借助Python软件,从“企查查”API数据接口和万得数据库获取相关数据,对27家核心企業122条供应链多维指标进行数据挖掘、WOE编码和变量筛选,构建指标体系。然后,运用大数据和人工智能建模思路,建立涵盖14个特征解释变量的Logistic回归模型,并运用多种工具训练和改进模型形成可用于实务的Logistic评分卡。经实证检验,最终确定的信用评估模型区分能力强,风险预测准确率能达到96.77%。基于大数据的Logistic评分卡将供应链信用等级数字化,相较于传统的信用评级更具有实用性,因此,大数据技术的运用对提升供应链金融信用风险评估和管理水平具有重要价值。
关键词:供应链金融;信用风险;Logistic评分卡;人工智能
中图分类号:F832 文献标识码:B 文章编号:1674-2265(2022)05-0064-07
DOI:10.19647/j.cnki.37-1462/f.2022.05.009
一、引言
金融科技创新驱动数字供应链金融快速发展,但也使信用风险的识别与评估更加复杂。为了对供应链金融信用风险进行有效识别与管控,大多数学者从理论分析与风险测度两方面展开研究。在理论分析方面,付玮琼(2020)[1]运用供应链金融网络拓扑结构及依赖共生模型来说明核心企业主导模式下的依赖性垄断现象及其对供应链金融风险的作用机理。曹允春等(2020)[2]指出大数据等金融科技技术不断推动供应链金融智慧化,各交易主体跨界联动及数据挖掘可以解决传统风险评估中的供应链关系识别、信用风险指标关联性等问题。赵成国和江文歆(2021)[3]基于供应链金融生态发展逻辑,从资源、组织、知识分析视角建立供应链金融生态风险管理内外协同共生机制,并提出了供应链金融生态风险评估和管理建议。周雷等(2021)[4]运用博弈论分析了区块链赋能供应链金融的作用机理,指出区块链的智能合约技术有助于提高信用风险评估效率。在风险测度方面,大数据征信在很大程度上改变了传统征信对数据采集、加工和分析的方式以及对客户信用风险预测的效果(张瑜等,2021)[5],特别是能够通过重新设计信用评级模型以及创新风险识别系统,更有效地控制和评估供应链金融风险(Tian等,2019)[6]。因此,部分学者使用主成分分析和逻辑回归模型、Rough和GADEMATEL模型、GA-BP神经网络模型、PSO-SVM供应链金融预警模型、Copula 模型等进行了信用风险测度(余得生和李星,2019;周茜等,2019;孙中叶和徐晓燕,2021;李健和张金林,2019;胡海青等,2020)[7-11]。
国家“十四五”规划指出,要加快构建全国一体化大数据中心体系,加强信用信息归集、共享、公开和应用。大数据技术在供应链金融信用风险评估中的应用,对于防控信用风险、提升供应链发展水平具有重要的现实意义。但是,从已有的相关文献来看,理论研究和机理分析较多,部分实证研究也大多从学术角度出发,未能提供可以直接实践应用的供应链金融信用风险评价工具;或者仅针对某个特定供应链企业案例展开,对整个行业场景的实践指导价值较弱。鲜有学者将实务中普遍运用的评分卡工具用于供应链金融信用风险测度,而本文将前沿大数据征信模型与评分卡工具相结合,针对具体行业场景的供应链金融信用风险评估以应用为导向进行深入研究,具有一定的创新性和现实针对性。
二、场景选择与变量筛选
(一)场景选择
大数据供应链金融信用风险评估模型的构建首先需要选择合适的研究对象和模型训练场景。整车制造行业具有典型的供应链协同特征,该行业一般以整车制造企业为核心企业,上游汽车零配件供应商与下游整车经销商围绕整车制造核心企业合作,形成上下游相互协作的供应链。整车制造行业供应链的供应商数量多、交易脉络复杂、应收账款和资金需求量较大,具有开展应收账款质押融资的有利条件。而应收账款质押融资正是供应链金融发展较为成熟的主流模式。因此,本文以整车制造行业供应链为场景探索大数据技术在供应链金融信用风险评估中的应用具有典型性和代表性。样本具体选择条件如下:(1)核心企业为整车制造的上市公司,属于国民经济行业分类中的“汽车制造业——汽车整车制造业”;(2)中小融资企业选取自核心企业的上游供应商,考虑数据可得性,根据证监会《上市公司行业分类指引》将中小板、创业板中的汽车制造业供应商认定为所选样本。根据以上筛选条件,共选取27家上市公司核心企业和122条样本供应链作为本文实证研究对象。
在选择场景的基础上,评估指标设计参考中国知网(CNKI)的35篇相关文献,并咨询大数据技术应用与供应链金融领域的专家,初步确定了42个原始指标供筛选。指标主要包括六个维度:中小融资企业情况、核心企业情况、供应链关系、宏观经济状况、信用评级情况、信息披露质量。各项指标数据来源为:供应链关系数据,通过“企查查”关系图谱API接口获取,数据爬取前申请Key,以JSON(JavaScript Object Notation)半结构化数据形式返回;上市公司的主体信用评级数据,采用华政ESG信用评级作为代理变量;核心企业和中小融资企业的信息披露质量数据,也选自华政ESG信用评级中的信息披露选项;其他指标主要通过万得数据库整理导出。上述指标数据选取的时间点为2020年12月31日,均使用Python3.8软件编程进行数据挖掘和建模分析。
在整车制造供应链场景下,设定被解释变量为汽车行业上市公司主体的好坏,对好样本赋值为0,坏样本赋值为1。由于我国汽车行业上市公司截至2021年10月没有发生实质的退市,通常上市公司总体评级参考标准为A级以上,因此,本文将A级作为好坏样本的切分点,评级为A级及以上的样本标签为好样本,A级以下(不含A级)的为坏样本。根据采集的数据,122个汽车行业供应链样本中,好样本95个,占比77.87%;坏样本27个,占比22.13%。为解决数据平衡性问题,笔者使用Python进行了SMOTE过采样算法处理。
(二)变量筛选
1. 分箱与WOE编码。运用大数据技术构建Logistic评分卡模型,先需要对各原始特征变量进行分箱与WOE编码处理,然后再筛选出满足Logistic回归模型要求的解释变量。分箱的本质是连续变量的离散化,即对不同属性的变量,根据不同的类别打上不同的特征值;分箱最终的目的是让每一组内差异尽可能小,组间的差异尽可能大。分箱之后需要对变量进行编码。WOE编码是Logistic评分卡模型常用的编码方式。WOE称为证据权重(Weight of Evidence),计算公式如(1)式所示。WOE在信贷业务中是衡量违约概率的指标,其本质是坏客户与好客户的比例的对数。WOE越大,该分箱的坏客户比例越高,也就是说通过对变量进行WOE编码,并将WOE作为特征值,则特征值不仅代表了变量的一个分类,还代表了这个分类对预测违约概率的权重或者说对信用风险评估的贡献度。
公式(1)中,[pi1]是第[i]分箱中坏客户占所有坏客户的比例,[pi0]是第[i]分箱中好客户占所有好客户的比例;[*Bi]是第[i]分箱中坏客户数;[*BT]是所有坏客户数;[*Gi]是第[i]分箱中好客户数;[*GT]是所有好客户数。
以资产负债率为例,该变量为连续变量,经分箱处理后,可以划分为三档区间,分别为低于43.60%、介于43.60%与64.52%之间以及高于64.52%。然后运用采集的数据,根据公式(1)可以计算出资产负债率变量各分箱对应的WOE,如表1所示。根据表1,资产负债率变量各分箱的WOE与坏客户率成正比,坏客户率越高,WOE越大。因此, WOE不仅可以作为资产负债率变量离散化处理后各分箱类别的特征值,而且反映了该类别对预测违约概率的权重。采用同样的方法,可以对本文各评估指标变量都进行分箱与WOE编码,作为变量的特征值用于后续的分析、筛选与建模。
2. 相关性分析与IV变量筛选。经过分箱与WOE编码,类别变量实现了赋值,连续变量也进行了离散化处理并取得了特征值,从而可以进行相关性分析与IV(信息增益值)变量筛选。两变量间的线性相关性可用皮尔森相关系数来衡量,该系数的取值范围为[-1,1]。相关系数越接近0,说明两变量线性相关性越弱;越接近1或-1则两变量线性相关性越强。当指标间两两相关系数的绝对值大于0.7时,说明两者的相关性较强,会影响其对被解释变量的可解释性。因此,当两指标间的相关系数绝对值大于0.7时,选择IV较高的指标作为备选解释变量,去除区分能力较低的指标。将连续变量离散化必然伴随信息的损失,并且分箱越少,信息损失越大。为了衡量特征变量上的信息量以及特征对预测函数的贡献度,定义IV如公式(2)所示。
其中,[n]代表分箱个数,[i]代表第[i]个分箱,[bad%]是这个分箱的坏客户,即标签为1的客户占整个特征中所有坏客户的比例,[good%]是这个分箱的好客户,即标签为0的客户占整个特征中所有好客户的比例。
IV通过在WOE基础上乘以系数,不仅避免了负数出现,而且考虑了分箱中样本占总体样本的比例及其预测贡献。对分箱而言,IV越大代表了这个分箱的坏客户越多。对整个变量而言,IV代表了特征变量上的信息量对模型的贡献度和排序的区分度。换言之,代表了分箱后模型对违约概率的预测效率。根据信息增益值IV的判定标准,一般需要大于0.03,模型预测方为有效,因此,在两两相关系数大于0.7的各组变量中去除IV较低指标的基础上,还需要去除虽然相关系数小于0.7,但是IV小于0.03的指标,这些指标包括营业利润、信息披露质量、公司治理能力、GDP增长率、产业景气指数AIC、核心企业资产负债率。
3.多重共线性检验。多重共线性指解释变量之间由于存在相关关系而导致回归模型失真的情况。本文选取VIF(方差膨胀系数)来衡量多重共线性,如公式(3)所示,其中[Ri]是被筛选的解释变量[i]与其他解释变量的复相关系数。
VIF值越大代表解释变量多重共线性程度越严重。本文将VIF阈值设置为10,当VIF>10,被视为出现多重共线性的情況。因此,筛选出所有方差膨胀系数小于10的变量,这些变量之间没有严重的多重共线性,可以构建Logistic回归模型。
三、Logistic回归模型
(一)模型建立
Logistic回归模型是指被解释变量为二级计分或二类评定的回归分析,一般形式如式(4)。
公式(4)中,[w0]表示常数项,[Xk]代表各解释变量,[wk]表示对应的回归系数,[ε]为随机误差项。被解释变量为企业违约发生比的自然对数,其中[p]为违约概率,越接近0表示企业违约风险越低,越接近1表示企业违约风险越高;[p1-p]被定义为发生比(odds),表示客户违约的相对概率。
通过指标体系构建,并运用相关性分析、多重共线性检验、IV等多种方法进行变量筛选,最终根据机器学习梯度下降树算法GBDT重要程度排序,确定被纳入Logistic回归模型的具体变量,共包括14个特征解释变量。为了区分核心企业与中小融资企业的财务指标变量,将核心企业的指标名称加上尾缀“.H”,同时所有解释变量都经过了分箱和WOE编码。WOE编码可以把原始指标与坏客户率之间可能存在的非线性特征转换为线性,这为构建包括Logistic回归在内的广义线性模型奠定了基础。然后,通过估计Logistic回归,得到大数据供应链金融信用风险评估模型的系数,如表2所示。需要说明的是,由于WOE编码始终与坏客户率成正相关,即变量的WOE编码值与供应链金融违约概率成正比,因此,所有的模型系数均为正数。但是,对于指标本身的原始实际值与违约概率成负相关关系的负向指标,在后续制作Logistic评分卡与解释模型结果时,需要将其还原,以方便理解。例如,负向指标营业利润率,该指标越高,坏客户比例越低,WOE编码就越小,则预测违约概率也越低,因此,该指标的模型系数虽然也为正数,但是实际是负相关关系。
由于Logistic回归模型的被解释变量是对数发生比[lnp1-p],因此,每个特征解释变量的估计系数都可以解释为对该对数发生比的作用。将表2中的模型系数用对数发生比模型表示,如下式所示。该模型即是本文构建的大数据供应链金融信用风险评估模型,各变量的回归系数均至少在5%的水平下显著。
(二)模型检验
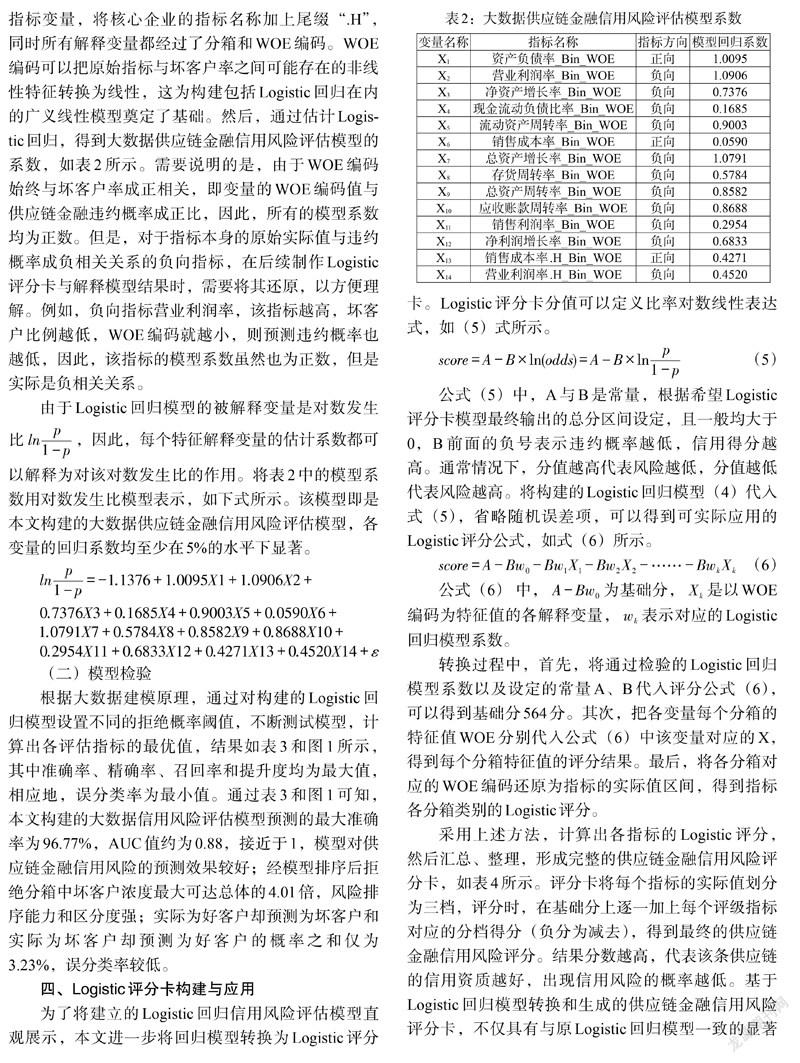
根据大数据建模原理,通过对构建的Logistic回归模型设置不同的拒绝概率阈值,不断测试模型,计算出各评估指标的最优值,结果如表3和图1所示,其中准确率、精确率、召回率和提升度均为最大值,相应地,误分类率为最小值。通过表3和图1可知,本文构建的大数据信用风险评估模型预测的最大准确率为96.77%,AUC值约为0.88,接近于1,模型对供应链金融信用风险的预测效果较好;经模型排序后拒绝分箱中坏客户浓度最大可达总体的4.01倍,风险排序能力和区分度强;实际为好客户却预测为坏客户和实际为坏客户却预测为好客户的概率之和仅为3.23%,误分类率较低。
四、Logistic评分卡构建与应用
为了将建立的Logistic回归信用风险评估模型直观展示,本文进一步将回归模型转换为Logistic评分卡。Logistic评分卡分值可以定义比率对数线性表达式,如(5)式所示。
公式(5)中,A与B是常量,根据希望Logistic评分卡模型最终输出的总分区间设定,且一般均大于0,B前面的负号表示违约概率越低,信用得分越高。通常情况下,分值越高代表风险越低,分值越低代表风险越高。将构建的Logistic回归模型(4)代入式(5),省略随机误差项,可以得到可实际应用的Logistic评分公式,如式(6)所示。
公式(6) 中,[A-Bw0]为基础分,[Xk]是以WOE编码为特征值的各解释变量,[wk]表示对应的Logistic回归模型系数。
转换过程中,首先,将通过检验的Logistic回归模型系数以及设定的常量A、B代入评分公式(6),可以得到基础分564分。其次,把各变量每个分箱的特征值WOE分别代入公式(6)中该变量对应的X,得到每个分箱特征值的评分结果。最后,将各分箱对应的WOE编码还原为指标的实际值区间,得到指标各分箱类别的Logistic评分。
采用上述方法,计算出各指标的Logistic评分,然后汇总、整理,形成完整的供应链金融信用风险评分卡,如表4所示。评分卡将每个指标的实际值划分为三档,评分时,在基础分上逐一加上每个评级指标对应的分档得分(负分为减去),得到最终的供应链金融信用风险评分。结果分数越高,代表该条供应链的信用资质越好,出现信用风险的概率越低。基于Logistic回归模型转换和生成的供应链金融信用风险评分卡,不仅具有与原Logistic回归模型一致的显著性水平,而且具有很强的可解释性和实际操作应用价值,能够使供应链金融业务人员无须深入了解大数据建模原理,即可根据评分卡直接得出客户的信用评分,以辅助授信决策和风险管理。
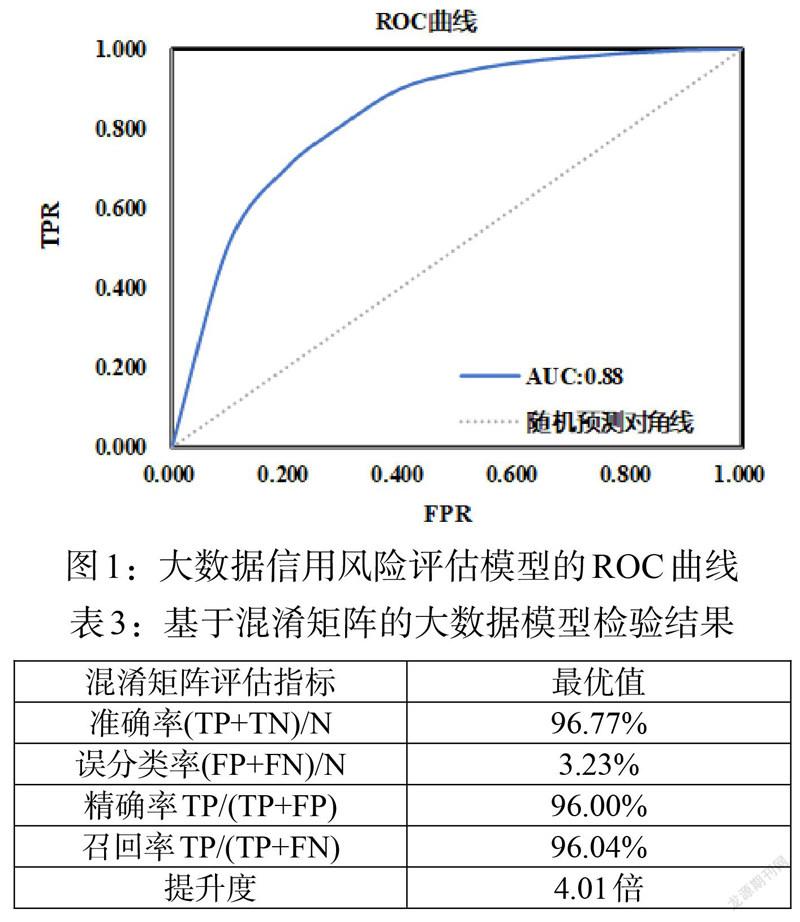
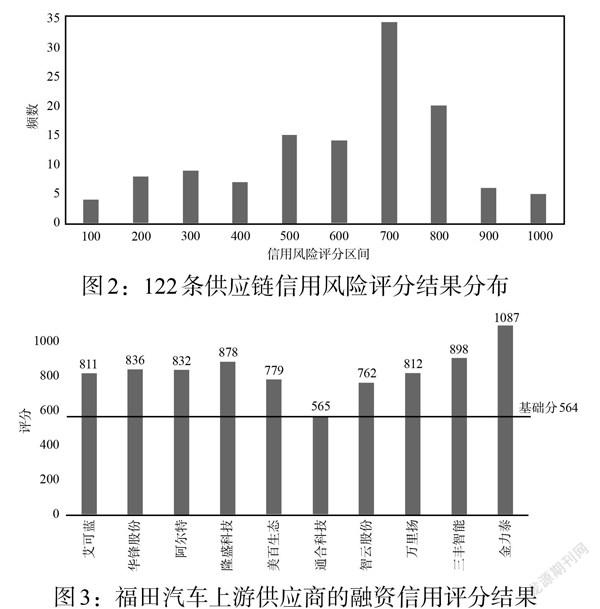
运用上述Logistc评分卡,对122条供应链的信用风险进行评分,评分区间的频数分布如图2所示。从总体上看,汽车行业供应链金融信用风险得分集中在[200,800]区间,其中[700,800]区间最多,而高于900分的情况较少。进一步以一家供应链核心企业——北汽福田汽车股份有限公司(A股,以下简称福田汽车)为例,将福田汽车及其上游中小融资企业真实的原始数据代入Logistic评分卡模型,计算福田汽车上游中小融资企业的信用评分,结果如图3所示。根据模型输出结果,这10家供应链上游融资企业的信用风险评分均属于中上水平。其中评分最高的金力泰为福田汽车上游重要供应商,从事汽车原厂涂料的生产和销售,在垂直细分领域具有极强的竞争力;评分最低的通合科技为新能源电动汽车充电电源及配套设备供应商,在创业板上市,尚未形成稳定的盈利能力,但评分仍略高于基础分,总体信用风险可控,若能抓住“双碳”机遇,加大技术投入和产品研发,仍具有广阔的发展前景。
根据华政ESG评分,上述各家企业的信用评级均为BBB级,与本文构建的大数据供应链金融信用风险评估模型的評分结果较为吻合,但是本文模型的区分度更高,更加精准地刻画了汽车行业供应链金融的信用风险状况,即实现了信用等级的数字化。传统风险评估模型的底层指标筛选和建模逻辑大多采用德尔菲法、层次分析法等依赖专家经验判断的方法,指标选择、区间分级和权重确定存在一定的主观性,评级结果以信用等级形成给出,精确度和可解释性有限。而基于大数据技术建立的供应链金融信用风险评估模型,不事先设定指标区间和权重,通过数据挖掘和机器学习构建和优化评估体系,不仅能定量、客观地预测违约概率,而且通过将模型转换为Logistic评分卡,建立起原始指标与评分结果间的对应关系,实现了信用等级数字化、可解释的呈现,能够清晰获知被评估对象的精确得分和每项指标的特征分。
综上,本文建立的Logistic回归模型对供应链金融信用风险的预测准确率高,基于该模型构建的评分卡方便业务人员操作应用,且相较于传统第三方评级机构10个等级的信用评级结果,评分更加精确,也更具实用性和参考价值,能够具体解释和分析评分结果与指标特征间的定量关系。
五、结论与建议
本文运用大数据技术和人工智能建模思路,借助Python3.8软件,对整车制造企业供应链金融信用风险进行测度,从“企查查”API数据接口和万得数据库挖掘相关数据,将27家核心企业122条供应链指标数据分箱、WOE编码和变量筛选,建立了涵盖14个特征解释变量的Logistic回归模型,并运用多种工具验证模型,生成了Logistic评分卡。实证检验结果表明:本文最终确定的Logistic回归模型对供应链金融的信用风险区分能力较强,预测准确率能够达到96.77%;基于上述模型构建的Logistic评分卡将不同信用等级数字化,相较于已有的第三方信用评级工具更加具有大数据征信参考价值和实用性。因此,运用大数据技术测度供应链金融信用风险对提升供应链融资风险管理水平具有重要的现实意义。
具体而言,根据构建的大数据供应链金融信用风险评估模型回归系数以及最终生成的供应链金融信用风险评分卡,核心企业与中小融资企业自身的财务指标和表现,均会对供应链金融信用风险产生显著影响,主要结论如下:
其一,核心企业的经营状况、盈利能力对供应链金融信用风险有重要影响。在5%的显著性水平下,核心企业的销售成本率与供应链金融违约概率成正相关关系;营业利润率与供应链金融违约概率成负相关关系。(1)销售成本率指标刻画核心企业经营过程中的成本费用控制能力,核心企业成本费用控制能力越强,销售成本率越低,信用评分越高,供应链金融违约的概率越小。(2)营业利润率刻画核心企业的盈利能力和发展前景,核心企业营业利润率越高,盈利能力越强,发展前景就越好,整条供应链的信用评分就越高,越能带来更多的融资便利,违约风险就越低。
其二,反映供应链上下游中小融资企业的偿债能力、盈利能力和运营效率的财务指标对供应链金融信用风险的影响均较大。(1)在5%的显著性水平下,中小融资企业的资产负债率与供应链金融信用风险成正相关关系。资产负债率是综合反映企业偿债能力的重要指标,资产负债率越高,企业债务负担越重,信用评分就越低,债务违约概率就越大。(2)在5%的显著性水平下,中小融资企业的营业利润率、总资产增长率与供应链金融违约概率成负相关关系。其中,营业利润率衡量中小融资企业的盈利能力,该指标越大,表明企业的盈利能力越强,从而保障企业还款付息,信用评分就越高,供应链金融链条的违约风险也就越小;总资产增长率反映了中小融资企业的增长潜力,资产增长越快,相应的评分就越高,信用风险越低。(3)在5%的显著性水平下,中小融资企业的应收账款周转率、总资产周转率、流动资产周转率均与供应链融资违约概率成负相关关系。周转率指标衡量企业的运营效率和资产的流动性,上述指标越大,表明企业的运营效率越高,资产变现能力越强,相应的信用评分就越高,供應链融资违约概率就越小。
结合以上实证研究结论,可以从大数据技术赋能供应链金融信用风险评估和治理的角度提出以下建议:第一,供应链上的核心企业和中小融资企业要运用大数据等新一代信息技术提高财务管理水平和信用风险治理能力,从而提升供应链金融质效和整条供应链的财务健康度。根据实证检验结果,供应链上的核心企业与中小融资企业具有密切的信用联系,两者的财务指标和经营状况均会对供应链金融信用风险产生显著影响。在数字化时代,要运用大数据、人工智能等新一代信息技术,精准评估供应链信用风险,同时引导核心企业和上下游中小融资企业加大技术投入,推进企业智能化改造和数字化转型,改进财务管理,降低运营成本,提升财务绩效和风控能力,从而获得更高的信用评分,提升供应链融资可获得性,满足核心企业和中小融资企业的各类金融服务需求,提高整条供应链的财务健康度和协同运营绩效,实现可持续发展。第二,构建供应链数据化生态圈,实现供应链上核心企业、上下游中小融资企业的融资交易流程透明化。传统供应链金融的相关利益方主体存在信息不对称现象,运用大数据、区块链等技术构建供应链数据化生态圈,能够使得供应链各主体的运营和金融活动中所发生的数据和信息均被不可篡改地完整记录在平台上,实现信息流、资金流、物联和商流的全程可追溯,金融机构、大数据征信机构等相关主体经授权可随时查询数据,采集动态、可信的各类供应链企业财务指标与全周期贸易信息,从而为全面、准确评估供应链金融信用风险奠定基础,在有效识别、评估和管控信用风险的前提下,拓展数字供应链金融新生态,赋能供应链健康发展。
参考文献:
[1]付玮琼.核心企业主导的供应链金融模式风险机理研究 [J].企业经济,2020,39(01).
[2]曹允春,林浩楠,李彤.供应链金融创新发展下的风险变化及防控措施 [J].南方金融,2020,(04).
[3]赵成国,江文歆.金融生态视角下供应链金融风险管理体系构建 [J].财会通讯,2021,(06).
[4]周雷,邓雨,张语嫣.区块链赋能下供应链金融服务小微企业融资博弈分析 [J].金融理论与实践,2021,(09).
[5]张瑜,廖长勇,王新军.基于分层模型的银行客户信用风险预测研究 [J].金融发展研究,2021,(10).
[6]Tian Z,Hassan A F S,Razak N H A. 2019. Big Data and SME financing in China [J].Journal of Physics: Conference Series,1018(1).
[7]余得生,李星.供应链金融模式下的中小企业信用风险评估:以电子制造业为例 [J].征信,2019,(10).
[8]周茜,谢雪梅,张哲.供应链金融下科技型小微企业信用风险测度与管控分析:基于免疫理论 [J].企业经济,2019,(08).
[9]孙中叶,徐晓燕.农业供应链金融风险评估研究:基于GA-BP神经网络模型 [J].技术经济与管理研究,2021,(08).
[10]李健,张金林.供应链金融的信用风险识别及预警模型研究 [J].经济管理,2019,41(08).
[11]胡海青,陈迪,张丹,张琅.基于Copula的供应链金融质物组合价格风险测度研究 [J].运筹与管理,2020,29(03).
An Empirical Study on Credit Risk Assessment in Supply Chain Finance Based on Big Data
—— Taking the Vehicle Manufacturing Industry as the Example
Zhou Lei1,3/Qiu Xun2/Zhu Yi1/Mao Xiaofei3
(1. School of Business,Suzhou Vocational University,Suzhou 215104,China;
2. School of Financial Management,Zhejiang Financial College,Hangzhou 310018,Zhejiang,China;
3. School of Economics and Management,Southeast University,Nanjing 211189,Jiangsu,China)
Abstract:By combining the cutting-edge big data credit technology with the scorecard method,the credit risk of supply chain finance is measured by taking the whole vehicle manufacturing industry supply chains as the scenario. Firstly,with the help of Python,relevant data is obtained from the "Qichacha" API and Wind database,data mining,WOE coding and variable screening were carried out for the indicator system with multi-dimensional indicators of 122 supply chains contained 27 core enterprises. Then,by using big data and AI modeling technologies,a logistic regression model covering 14 characteristic explanatory variables is established,and multiple tools are used to train and improve the model to form a logistic scorecard that can be used in practice. After empirical testing,the finalized credit assessment model has strong differentiation ability and can reach 96.77% risk prediction accuracy. The logistic scorecard based on big data digitizes the supply chain credit rating,which is more practical compared to the traditional credit rating,so the use of big data is of great value to improve the credit risk assessment and management of supply chain finance.
Key Words:supply chain finance,credit risk,logistic scorecard,AI
Abstract:By combining the cutting-edge big data credit technology with the scorecard method,the credit risk of supply chain finance is measured by taking the whole vehicle manufacturing industry supply chains as the scenario. Firstly,with the help of Python,relevant data is obtained from the "Qichacha" API and Wind database,data mining,WOE coding and variable screening were carried out for the indicator system with multi-dimensional indicators of 122 supply chains contained 27 core enterprises. Then,by using big data and AI modeling technologies,a logistic regression model covering 14 characteristic explanatory variables is established,and multiple tools are used to train and improve the model to form a logistic scorecard that can be used in practice. After empirical testing,the finalized credit assessment model has strong differentiation ability and can reach 96.77% risk prediction accuracy. The logistic scorecard based on big data digitizes the supply chain credit rating,which is more practical compared to the traditional credit rating,so the use of big data is of great value to improve the credit risk assessment and management of supply chain finance.
Key Words:supply chain finance,credit risk,logistic scorecard,AI
收稿日期:2022-01-09 修回日期:2022-02-10
基金項目:江苏高校哲学社会科学研究基金项目“数字经济时代金融科技服务实体经济高质量发展研究”(2022SJA1415);浙江省高校科研资助项目“金融本质视角下的区块链金融风险监管研究”(Y201941951)。
作者简介:周雷,男,江苏苏州人,苏州市职业大学讲师、研究员,东南大学SRTP项目指导教师,研究方向为金融科技;邱勋,男,江西于都人,浙江金融职业学院副教授,研究方向为金融科技;朱奕,女,江苏苏州人,苏州市职业大学商学院,研究方向为金融科技;毛晓飞,女,江苏镇江人,东南大学经济管理学院,研究方向为供应链金融。
