大数据在拧紧数据分析中的应用
2022-06-20樊宇杨建业
樊宇 杨建业
(一汽-大众汽车有限公司,长春 130000)
1 前言
总装车间拧紧质量是整车装配质量非常重要的一环,而拧紧曲线是分析拧紧装配问题的重要工具,其真实且完整的记录了整个拧紧过程中扭矩和角度的信息,便于追溯、分析和优化拧紧问题。常见的拧紧缺陷主要有空转、脱手、过冲、预紧过多、杂质、套筒脱开[1]、位置不正。通过分析拧紧曲线可以得到大多数缺陷的原因。本文主要介绍利用大数据技术提升拧紧曲线的分析效率及准确率,进而加快拧紧质量提升。
2 数据处理
大数据分析与人工分析拧紧数据的方式相比,前者可节省曲线查看的时间,并且不依赖拧紧专业人士分析,在分析效率及准确率上具有优势,2 种分析方法的对比如图1 所示。

图1 人工和大数据分析流程对比
2.1 数据采集
为避免影响生产,建立大数据服务器与生产的拧紧服务器的接口,完成相关数据的采集,包括车辆信息、拧紧数据、状态、曲线等。数据收集完毕后,在专用的大数据分析服务器中进行数据处理。
2.2 数据预处理
对采集的数据进行数据清洗,也就是对数据进行筛选,去除离散数据。
2.3 数据存储
预处理后的数据保存在大数据服务器的数据库中。
3 特征提取
拧紧曲线的异常判定,需要对曲线的多个特征进行判定,不能只从单一特征进行判定。由于拧紧曲线本身的复杂度高,扭矩、角度、扭矩面积积分、斜率等均可反应出拧紧曲线的状态。本文涉及的大数据分析方法,采用的特征数据如表1 所示。
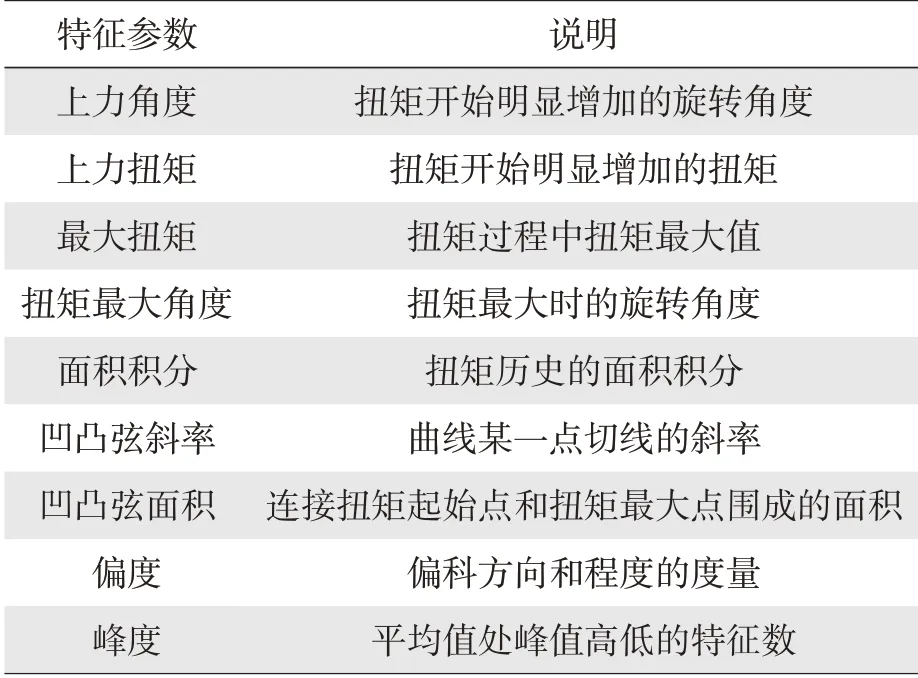
表1 特征数据
4 聚类算法
本文讨论的聚类算法为K-Means 算法[2-5],是由MacQueen 于1967 年提出的。其思想很简单,对于给定的包含n个d 维数据点的数据集x,找出k个类中心,按照样本之间的距离大小,将数据集划分为k个簇,使得数据集中的点与所属类别的质心的距离平方和最小。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大,理论公式见公示(1)。
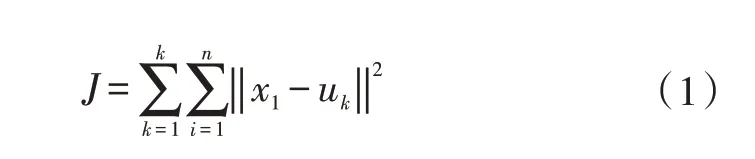
式中,J为簇内误差平方和;k为簇的数量;n为每个样本点中特征的数目;i为组成点x的每个特征;x为簇中的一个样本;u为簇中的质心。
该算法需要人工指定k值,且对k值非常敏感[6]。通过K-Means 算法,将曲线进行聚类处理。将拧紧数据按照所属工位、拧紧工具、拧紧程序编号分类汇总到不同的数据场景。
5 神经网络学习
神经网络是由众多的神经元可调的连接权值连接而成,具有大规模并行处理、分布式信息存储、良好的自组织、自学习能力特点。本文讨论的神经网络算法为反向传播(Back Propagation,BP)算法,又称为误差反向传播算法,是人工神经网络中的一种监督式的学习算法。本文中讨论的拧紧场景自学习流程如图2 所示。
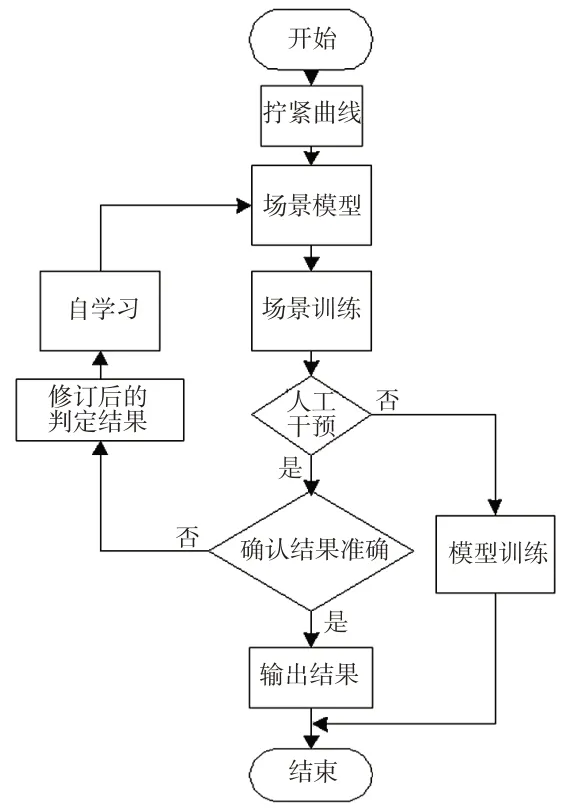
图2 自学习流程
6 大数据开发工具
商业智能(Business Intelligence,BI)工具作为目前主流的大数据分析工具,在成本、效率、开发周期上具有巨大优势,并且集成了数据获取、数据预处理、分析与挖掘、数据可视化等功能[7]。选择合适的BI 工具并在此基础上采用Java、Python 等主流语言进行二次开发是当前环境下较为经济的选择。
7 总装拧紧大数据应用
拧紧大数据系统作为拧紧数据采集系统的拓展,后者将拧紧结果传递给德国大众公司的FIS 系统(等同其他公司的MOM、MES 系统),而前者的分析结果不会上传给FIS 系统,仅作为对结果曲线的分析,并为管理人员提供快速分析拧紧数据的工具。
7.1 缺陷定义
目前螺栓的控制方式主要有扭矩法和角度法,图3 为螺栓拧紧过程中的曲线,图中Ms为扭矩实际值,Ws为角度实际值,W-为角度下限,W+为角度上限,M-为扭矩下限,M+为扭矩上限。通过对拧紧曲线设置监控窗口,可以分析导致拧紧缺陷的原因。

图3 拧紧曲线监控
根据监控窗口分析方法,并结合实际生产中的经验数据,定义出常见的拧紧缺陷及监控方法,见表2。

表2 缺陷定义
7.2 数据处理
剔除MIO(手动返修合格)和MNIO(返修不合格)等无效数据,对有效数据的拧紧曲线进行预处理,生成扭矩数列和角度数列,以使数据满足特征提取的需要,为后续特征值运算做准备。
7.3 聚类处理
对所有处理后的数据进行聚类分析,进行多次聚类迭代运算,生成聚类结果,即数据场景。
7.4 数据标注
数据场景形成后,软件系统将为该场景创建独立的分析模型,由模型定期使用场景中的数据进行机器学习训练,并分析场景中每条拧紧数据不合格的原因。为了跟踪监督模型的分析行为,需要指定人工定期复查。在人工复查工作的过程中,可能发现场景模型的分析结果与实际情况不符,即存在预测偏差。为了纠正场景模型的预测偏差,需要对场景模型进行纠正,即对其进行异常类别的人工标注。异常标注功能是将人工分析的纠偏信息反馈到场景模型,进而影响此后场景模型分析结果的若干软件操作,以提高识别准确率。
场景模型的标注有效率是实际得到纠正的被标注数据数量与所有标注数据数量的比值,是对场景模型接受人工干预标注后的效果评估,是目前评价拧紧场景的主要指标。
标注有效率低于限定值的场景不得申请认证审核。图4 为部分典型缺陷类型的拧紧曲线示例。
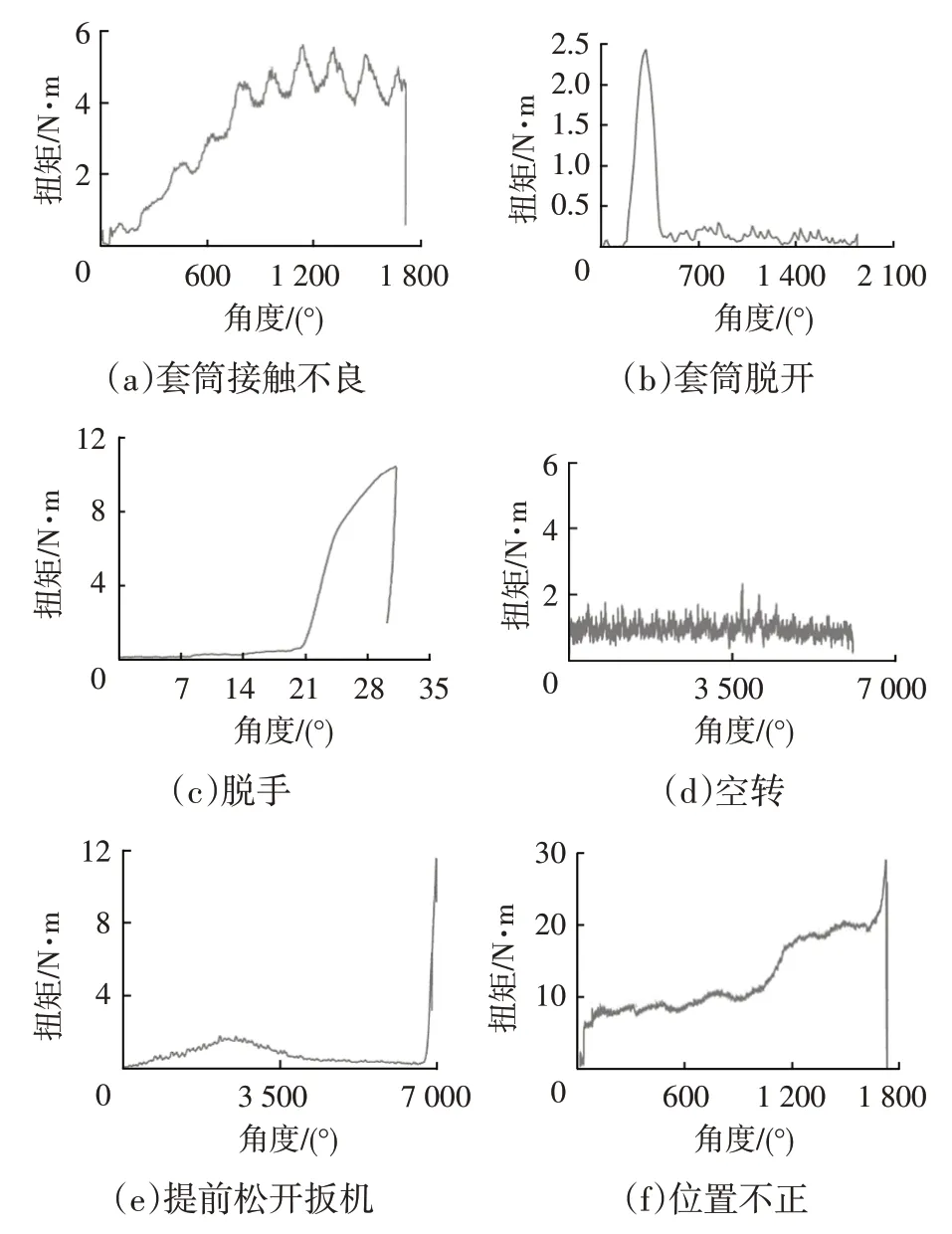
图4 部分典型缺陷类型的曲线
7.5 模型训练
场景模型的训练集准确率是软件系统中的相应神经网络框架在数据训练过程中自动统计的过程结果,反映了场景模型的完善程度和稳定度。训练集准确率高低可以为场景审核的先后顺序提供参考。
场景模型的响应时间是指从场景模型接收到拧紧数据到场景模型分析得出异常原因所花费的时间。响应时间可以作为未来拧紧场景扩展应用时性能评估的依据。
7.6 场景审核认证
稳定运行且分析行为正常的场景,必须经过专家对其数据进行抽检验证。场景被认可后,才能正式成为相关数据分析活动的依据或获得其他扩展应用的资格。这里对场景数据抽检验证、认可的行为即为拧紧场景的认证审核。
当某个拧紧场景的各项评价指标均高于某一标准且在一段时间内保持稳定,则可提交给相关审核人员进行拧紧场景审核。
审核人员在确认规划的审核申请信息清楚完整无遗漏后,如果认同所有场景和对应异常种类,就可以开始对该场景的审核,审核数据量为规划技术部门和质保技术部门共同商议决定。为了保证审核的公正性,场景的数据标注应从审核开始之日起暂停。
在审核期内,审核人员只需抽查该场景中接收到的新拧紧数据(即拧紧时间为审核开始时间之后的数据),检验场景模型对于该数据曲线的分析结果是否正确。审核数量及审核正确率达到某一指标后即视为该场景通过审核认证,后续该场景判定的异常可视为正确的判定,可直接用于指导拧紧问题分析。拧紧场景审核流程如图5所示。

图5 拧紧场景审核流程
7.7 数据可视化
本文讨论的大数据分析系统的基础开发工具为Apache Superset,并在此基础上进行二次开发。
7.7.1 拧紧趋势分析
选定时间范围内的车型总合格率和区域合格率趋势,直观展示车间拧紧合格率的变化趋势,如图6 所示。
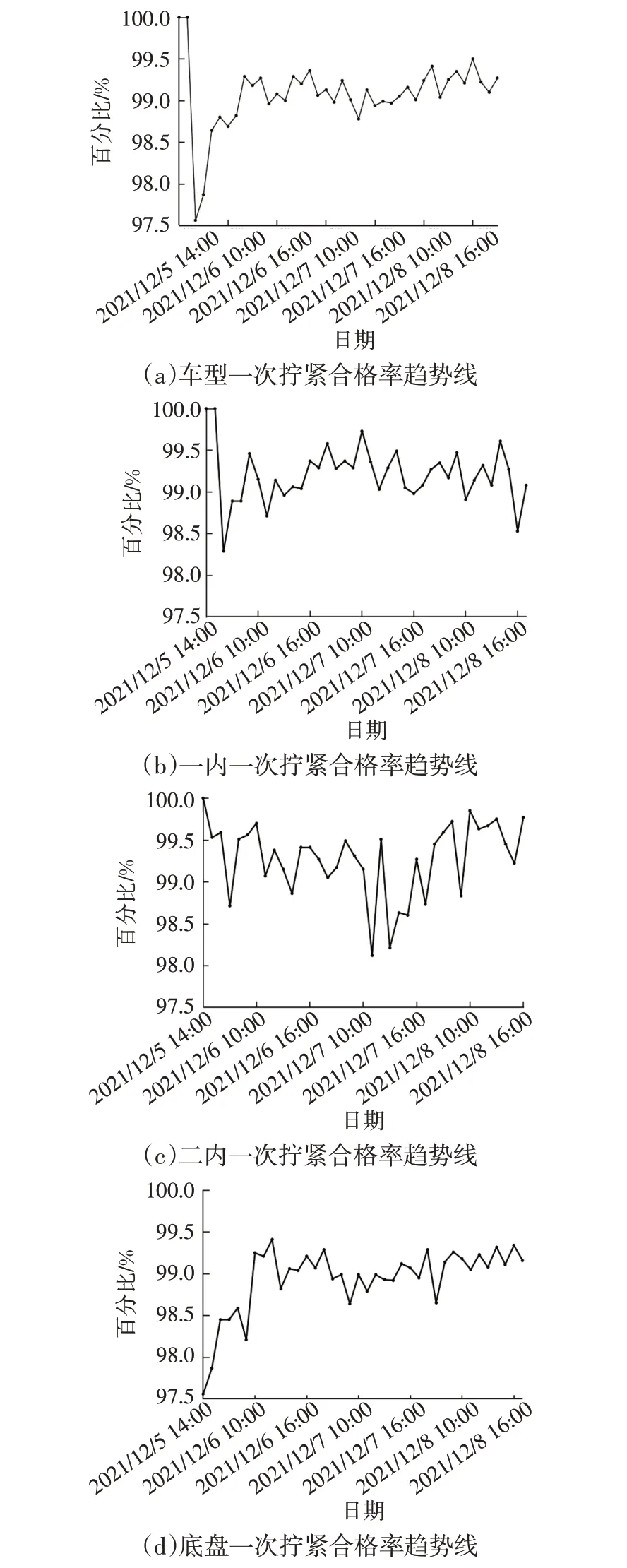
图6 合格率趋势图
7.7.2 工位合格率展示
选定时间范围内的工位合格率采用气泡图的方式直观展示。如图7 所示。

图7 工位合格率气泡图
7.7.3 大数据分析结果总览
选定时间范围内大数据分析的结果采用直方图进行展示,缺陷原因所对应的人机料法环的因素采用饼图进行展示,可直观了解车间在此期间内的缺陷类别及过程要素,如图8 所示。
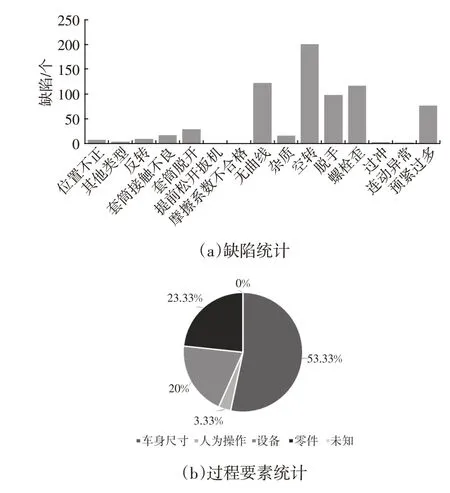
图8 拧紧缺陷统计展示
7.7.4 大数据分析结果展示
选定时间范围内螺栓的合格率按照降序进行排序,可点击每一个螺栓的结果进入拧紧大数据分析结果展示页面,可展示当前螺栓,当前时间范围内所有的分析结果,如图9 所示。
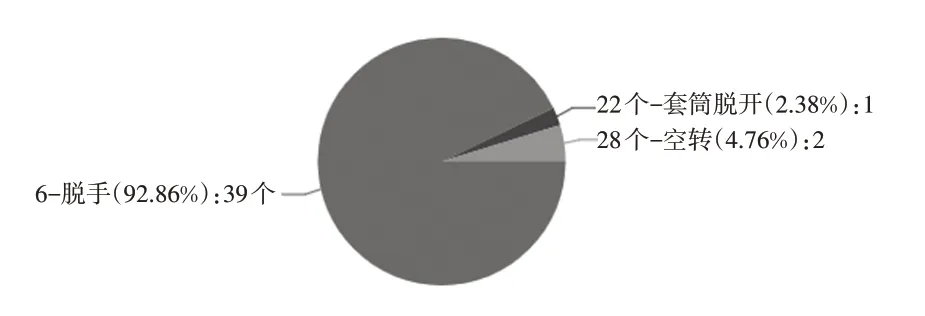
图9 大数据分析结果展示页面
8 结束语
本文主要研究的工作如下。
a.建立大数据对拧紧数据的分析方案。包括数据接口的建立、数据采集、数据预处理、数据存储等。以及采用K-Means 聚类算法和BP 神经网络算法进行数据分析;
b.建立一套拧紧大数据的应用流程和方法,包括缺陷定义、数据标注、场景审核;
c.利用BI 工具对数据结果进行可视化展示。包括拧紧趋势分析、工位合格率展示、大数据分析总览及展示。
拧紧大数据系统是现有拧紧数据采集系统(各公司叫法不一,主要功能是采集螺栓的拧紧数据)的延伸。现有数据采集对于曲线只是采集和储存,并无分析功能,对于拧紧结果只有合格与不合格的判定,没有不合格原因的分析。拧紧大数据系统依托开放平台开发,其与拧紧数据采集系统的接口和数据标准在大数据系统开发前已定义清晰,可与现有拧紧数据采集系统实现互通。大数据分析的结果可以在对应螺栓的拧紧数据采集系统中与拧紧结果一同显示。
基于大数据搭建的拧紧数据分析系统,结合BI 工具展示,用于指导分析拧紧缺陷问题,直观展示不合格螺栓的缺陷原因,提升拧紧缺陷的分析效率及准确率。随着大数据技术的成熟与逐步应用,未来大数据在总装的应用将会更加广泛。
