基于后结构化电子病历的胰腺癌科研数据平台设计
2022-06-18姚晴虹
万 歆,姚晴虹
(上海交通大学医学院附属瑞金医院,上海 200025)
0 引言
电子病历在我国各医院已经实施多年,结构化电子病历不仅能为医学科研工作提供高质量的数据,还能支持病历数据的跨院交流。目前,电子病历结构化处理一般有2 种方式:电子病历前结构化和后结构化。电子病历前结构化是指使用结构化的电子病历模板采集数据;电子病历后结构化是指医生填写完病历后,再通过算法进行电子病历结构化。
上述2 种电子病历结构化处理方式均存在一些问题:(1)在电子病历前结构化中,由于医学术语收集需要医疗人员负责,加之疾病种类繁多,因此需要制作大量的结构化模板。如果没有足够的医疗人员从事结构化模板制作的工作,结构化病历模板就难以实现。前期能实现结构化的电子病历模板始终有限,且病历存在复杂性和多样性,因此目前电子病历前结构化的全覆盖较难实现。此外,在临床上还存在即使有结构化电子病历模板,医务人员也并未完全按照结构化模板录入的现象。(2)电子病历后结构化则存在如何从自然语言文本中提取明确、有效信息的困难。目前,国内外对于信息抽取和文本处理,常采用机器学习、篇章分析、Web 信息抽取、语言文本处理等技术。
胰腺癌是一种生存概率极低的疾病。多年来,我院在开展胰腺癌手术和术后随访等方面积累了大量的经验和数据[1-3]。为了更好地研究这种疾病,提高胰腺癌患者术后的生存概率,临床医生希望能搭建一个胰腺癌科研数据平台,从电子病历、检验、检查、病理等报告中获取有效的数据,以用于胰腺癌的研究。目前,大部分科研数据的处理都是通过SPSS 软件进行处理,但是SPSS 不能处理非结构化的电子病历文本[4-6],且无法进行全院数据共享,难以开展大规模的数据研究,因此搭建一个可以处理结构化和非结构化文本并且可以全院共享的胰腺癌科研数据平台迫在眉睫。
本文基于胰腺癌这种特定类型的疾病,应用临床知识建立符合这种疾病特点的数据模型,并采用基于字符匹配的知识理解分词法,对不同的数据模型采用不同的分词方法,最终形成统一的胰腺癌科研数据平台和可供临床使用的可视化界面。本研究提供的可复用软件代码和分词方法,可为构建类似需求的其他病历研究平台提供借鉴。
1 需求分析
我院从2008 年开始使用SQL Server 数据库和C#自主开发电子病历系统,目前已经平稳运行10 余年,积累了大量数据。目前临床科室希望建设专科专病数据库,能从中抽取临床数据以用于诊断和科研。而我院部分科室的部分病种实施了全结构化电子病历,部分科室使用半结构化电子病历,即关键字段结构化,其余文本为非结构化自由文本,因此在电子病历系统中存在大量非结构化的病历文本。如何对这些电子病历文本进行后结构化处理,并从中抽取出科研、临床所需数据,是搭建胰腺癌科研数据平台的关键[7-8]。胰腺癌科研数据平台须包含患有胰腺癌并在我院实施手术的患者的所有信息,医生可以通过浏览器对胰腺癌专科数据库进行检索,从中获得科研数据,从而为胰腺癌科研项目提供数据支撑[9-12]。
2 平台设计
胰腺癌科研数据平台的开发环境分为2 个部分:硬件环境和软件环境。在硬件环境方面,目前我院的主应用服务器采用互为集群的2 台服务器,并采用多台辅助服务器提供查询、报表、备份、监测服务,以保证平台性能的稳定。为了保证网络安全、稳定运行,核心及汇聚交换机均采用双机热备的方式进行工作,确保在交换机之间的线路或主干设备发生故障时,整个系统仍能运行,业务仍可以正常开展。在软件环境方面,数据库采用SQL Server 2015,数据抽取、转换、加载(extract transform load,ETL)工具采用SQL Server Integration Services(SSIS)2015,前端开发工具采用SQL Server Reporting Services(SSRS)2015。
平台数据处理主事务的流程如下:首先,由临床医生提供数个典型的胰腺癌病例,按这些典型病例分析电子病历中的关键词,进行数据平台专病数据模型设计,模型设计应该具有足够的弹性,以便在病例足够丰富时对模型进行快捷修改。然后,按照专病数据模型,采用基于字符串匹配和知识理解的分词法,通过可扩展标记语言(extensible markup language,XML)函数和SQL Server 标量值函数对XML 文本进行语义解析,从中获取并返回有用的信息。使用SQL Server 标量值函数将半结构化数据和非结构化数据进行结构化,并采用SSIS 2015 抽取结构化后的电子病历数据和医院信息系统(hospital information system,HIS)、实验室信息系统(laboratory information system,LIS)等临床信息系统产生的异构数据,通过提取、清洗、转换、集成等一系列步骤融合到统一的结构化数据平台,并保存到胰腺癌专科数据库。最后,在胰腺癌专科数据库的基础上,采用SSRS 2015 开发浏览器界面,供用户查询数据,为科研提供数据支撑。
胰腺癌科研数据平台采用浏览器/服务器(Browser/Server,B/S)架构进行设计,分为基础层、业务层、数据处理层和数据展现层,如图1 所示。基础层包括服务器和存储设备;业务层由各种数据库构成,包含HIS 数据库、LIS 数据库等各类异构数据库;数据处理层从业务层抽取和处理数据,并保存到胰腺癌专科数据库;数据展现层可对用户权限进行管理,展示最终的数据查询结果,并支持查询结果打印和导出功能。
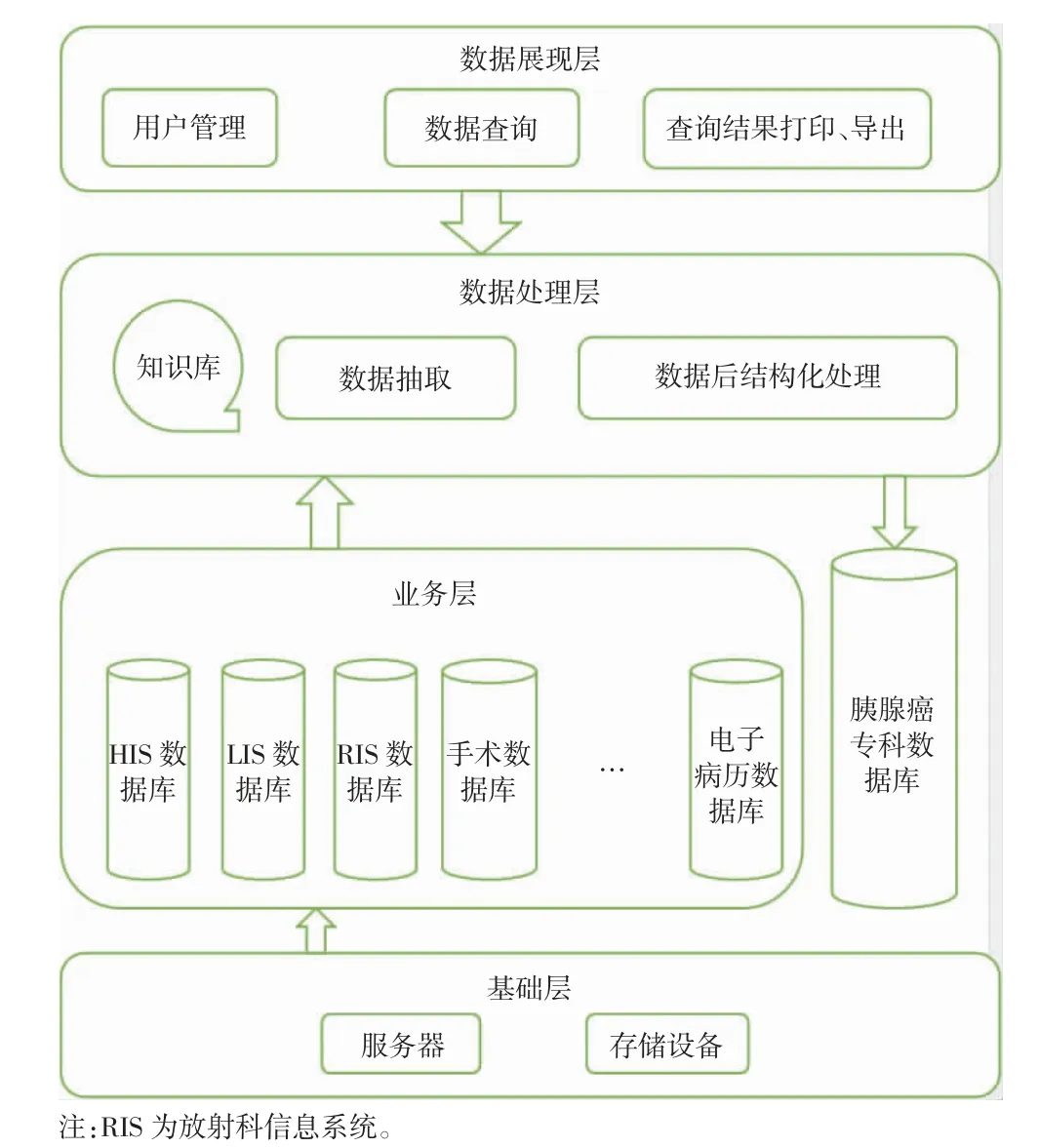
图1 胰腺癌科研数据平台架构图
3 平台实现
胰腺癌科研数据平台包括数据抽取、数据处理、查询分析3 个模块,模块结构图如图2 所示。数据抽取模块包括结构化数据库抽取和非结构化数据库抽取2 个子模块,这2 个子模块分别对应不同结构化的数据库,实现数据抽取功能;数据处理模块包括后结构化数据处理和结构化数据处理2 个子模块,可实现对数据的清洗和结构化处理,并将处理好的数据保存到胰腺癌专科数据库;查询分析模块包括数据查询和查询结果打印导出2 个子模块,可实现按临床医生的需求展示数据并将查询结果打印和导出。
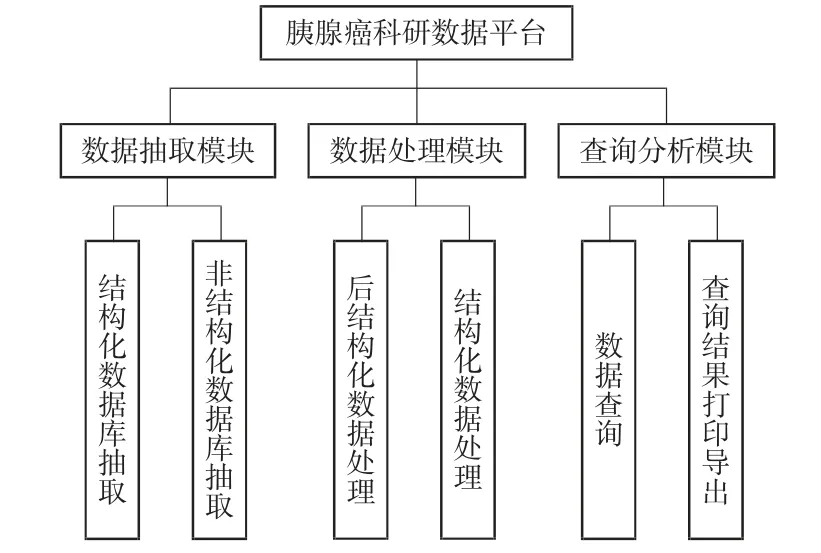
图2 胰腺癌科研数据平台模块结构图
3.1 数据抽取模块实现
根据胰腺癌研究的需要,在SQL Server 上构建数据库,对数据源进行抽取操作。采集的数据分为完全结构化数据和非完全结构化数据,数据抽取源流图如图3 所示,下文对其源流分别进行说明。
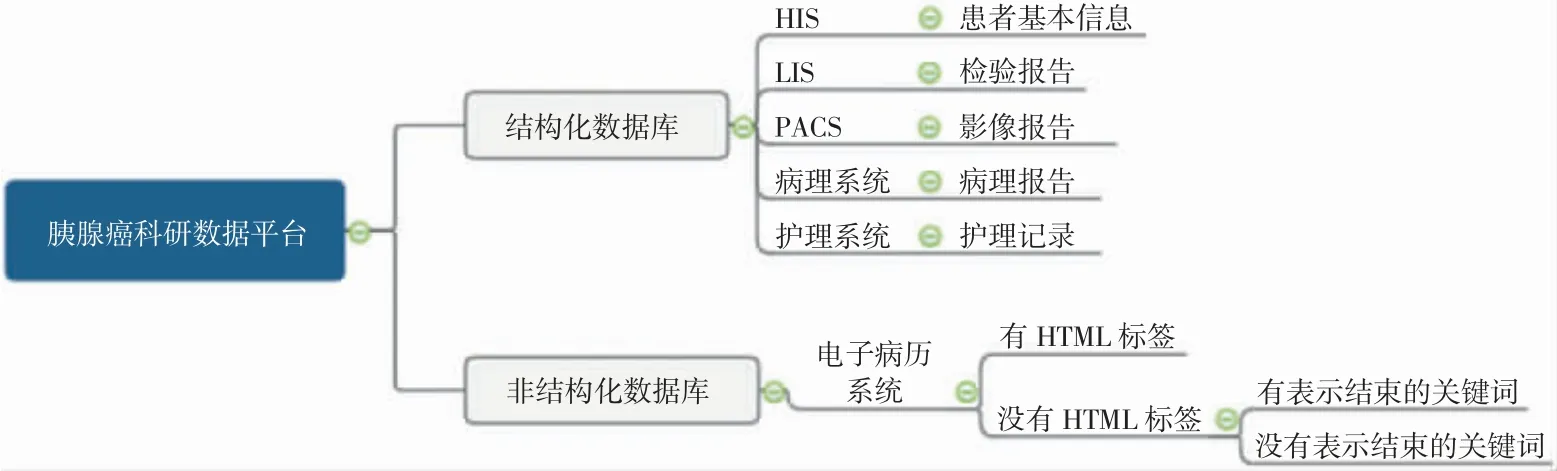
图3 胰腺癌科研数据平台的数据抽取源流图
3.1.1 结构化数据库抽取模块实现
结构化数据库包括HIS、LIS、影像归档和通信系统(picture archiving and communication systems,PACS)、病理系统、护理系统,其中HIS 为Sybase数据库,其他系统为SQL Server 数据库。应用SSIS 2015,采用对象连接与嵌入数据库(object link and embed data base,OLE DB)方式连接数据库,按以下步骤分别抽取数据:先从HIS 中抽取出院主要诊断为胰腺癌并在我院实施手术的患者的基本信息,其中患者住院流水号为该患者该次住院的唯一标识;再通过患者住院流水号从LIS、PACS、病理系统、护理系统中抽取这些患者的病史数据。
从LIS 的检验报告中获得的数据有各种检验指标,包括术前1 d 和术后10 d 的血常规、肝功能、淀粉酶、空腹血糖、癌症指标、肌酐等检验指标,术后引流液淀粉酶、总蛋白、白细胞等检验指标。这些检验指标可通过比对患者的手术日期和检验采样日期,从LIS 中获取。
从PACS 中获得各种医学影像检查报告,如B超、CT、MRI 等报告,也可通过住院流水号获取该次住院期间的报告,或通过医疗卡号获取住院前的检查报告。
从病理系统获得的病理报告,包括术中冰冻病理、术后石蜡病理、分子病理报告、病理补充报告,其中,分子病理报告需要通过分词,并按“标本类型”“检测项目”“检测方法”“结论”这4 个关键词分别抽取。
从护理系统中获得的数据有术后10 d 内患者每天的最高体温、每天引流量等生命体征信息。通过比对手术日期和护理记录日期,提取患者每天的最高体温,计算当天引流量的总和,并用SSIS 2015 将这些数据抽取到胰腺癌科研数据平台。
3.1.2 非结构化数据库抽取模块实现
非结构化数据库为电子病历数据库,该数据库为SQL Server 数据库,采用XML 格式存储数据。
从电子病历系统获得的数据含有患者的病史信息;从入院记录中可获取身高、体质量、身体质量指数(body mass index,BMI)、自发症状、病程、基础疾病、吸烟史、喝酒史、家族史等信息;从手术记录中可以获取有无胰管置管、置管部位、胰管直径、缝线型号、胰腺吻合方式、术中出血量、术中输血量等,入院记录和手术记录中的部分电子病历数据须进行后结构化处理。
参照胰腺癌数据模型在数据平台构建相关表,例如主表(用于保存患者的主数据)、检验表(用于保存患者术前、术后的检验指标数据)、病理表(用于保存结构化病理报告)、3 张临时表(用于处理引流量、体征、手术信息)、1 张控制表(用于保存上次抽取的时间),通过SSIS 2015 调用控制表来控制增量数据的抽取。主表和检验表的结构如图4 所示。

图4 主表和检验表的结构
SSIS 2015 数据抽取流程图如图5 所示。通过SSIS 2015 将所有相关的非结构化数据抽取到一个通用的平台,在SQL Server 数据库中设置每天定时自动执行的计划任务。考虑到手术记录可能会有补充、修改的情况,每月20 日前抽取从上1 个月1 日起至本月20 日的数据,并覆盖数据库中的原数据,20 日以后不再变动上个月的数据,并在计划任务失败时,发送邮件通知平台开发人员。数据库计划任务设置界面如图6 所示。
图5 SSIS 2015 数据抽取流程图
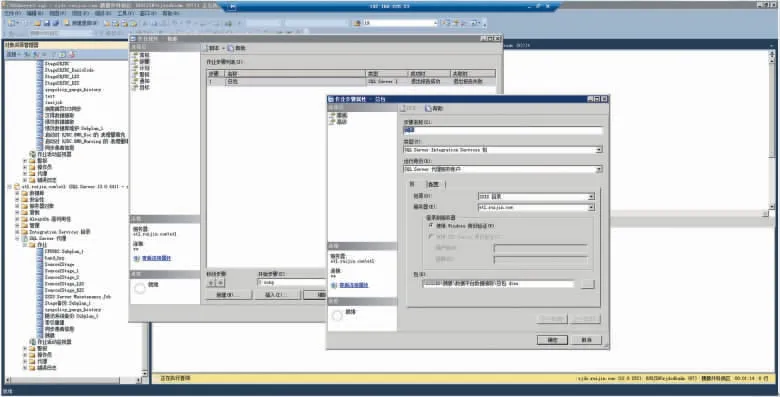
图6 数据库计划任务设置界面
当自动执行的数据库计划任务失败时,可以手动抽取和处理数据,并在界面上显示数据操作的过程和处理日志,如图7 所示。
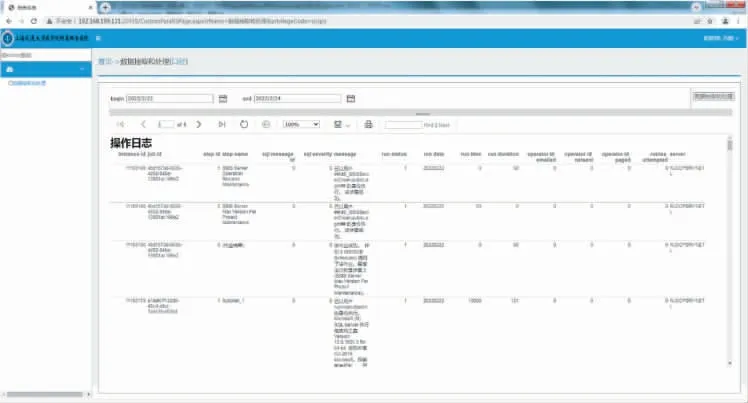
图7 数据抽取和处理日志界面
3.2 数据处理模块实现
3.2.1 结构化数据处理模块实现
结构化的数据处理相对简单,将抽取到的部分不规范的数据先进行清洗处理,再保存到胰腺癌专科数据库。例如,在检验指标中,部分术前糖类抗原199(CA199)的值大于1 个固定值,如“>18890”“>20400”,部分术前癌糖类抗原724(CA724)的值“>300”,对于这些数据,数据库保存为字符型,但在统计平均值、中位数等数值时不予统计。
3.2.2 后结构化数据处理模块实现
为了满足后续的数据处理需求,对胰腺外科病区电子病历的文本进行分析和后结构化处理。电子病历以XML 格式文本存储,文本的特点为多短句形式,有句号、逗号等标点符号,含有专业术语及缩写,也有由数字表示的定量数据。电子病历文本的组织结构可具体表示为信息项、信息标识,信息项中有强信息标识项,如超文本编辑语言(hypertext markup language,HTML)标签;也有弱信息标识项,如带中文冒号的文字“特殊既往史:”。
经过分析,电子病历文本根据标签和结束关键词的存在与否分为3 类,并分别进行抽取。为了使文本处理过程更加合理,采用SQL Server 通用标量值函数,在存储过程脚本中调用这些定制的标量值函数,在SSIS 2015 中按照固定格式执行上述存储过程来抽取文本。
第一类医学术语有HTML 标签,比如入院记录中的标签有主诉、疾病史、手术外伤史、家族史等。使用正则表达式/
第二类医学术语没有HTML 标签,有表示结束的关键词,比如患者病程通常包含在主诉中,并使用表示时间的关键词。对该类医学术语采用不确定型有穷自动机(non deterministic finite automaton,NFA)引擎运行匹配回溯算法,以指定顺序测试正则表达式的所有可能的扩展匹配项,具体实现方法:先用xml.value()函数按HTML 标签从入院记录抽取患者主诉,采用NFA 引擎运行匹配回溯算法分析这段文本,找到表示时间的关键词,如天、日、周、星期、月、年,再将这些关键词前面的表示定量的中文和阿拉伯数字抽取出来,如果关键词后面还有“余”字,也一起抽取,最后形成文字如“1 天”“半年”“数月余”等。在患者入院记录中含有“主述:上腹疼痛3 周”,通过关键词“主述”,先抽取“上腹疼痛3 周”,再分离“3 周”并保存到“病程”字段中。如果有2 个以上的时间,如主诉为“反复右上腹痛伴恶心呕吐6 年余,加重1 周”,则将这2 个时间按时间长短从小到大合并为“1 周/6年余”,并保存到“病程”字段中。
第三类医学术语既没有HTML 标签,也没有表示结束的关键词,需要具体分析。采用基于知识理解的分词法,通过预处理SQL 和语句切分SQL 抽取文本。比如缝线型号,经分析只有在“重建消化道”用到“胰肠吻合”时,才会产生“缝线型号”的相关数据。对此类医学术语采用不要求回溯的确定型有穷自动机(deterministic finite automaton,DFA)正则表达式引擎执行。在处理此类医学术语时,先将文本片段中的英文逗号和句号转换为中文的逗号和句号,再用中文的句号和逗号进行语句切分。比如抽取“缝线型号”,先从手术记录抽取含“重建消化道”的文本,调用SQL Server 标量值函数,传入医学术语“胰肠吻合:”抽取表示吻合方式的数据。
对于抽取到的数据,通过正则表达式[f v]匹配文本中的非打印控制字符,包括空格、制表符、换页符等,将抽取的文本片段中的非打印控制字符删除,再通过正则表达式[ s* ]匹配空白行,并删除空白行,最后得到所需的文本片段。SQL Server 标量值函数语句如图8 所示。在SSIS 2015 程序中应用标量值函数的SQL 语句示例如图9 所示。

图8 SQL Server 标量值函数语句片段
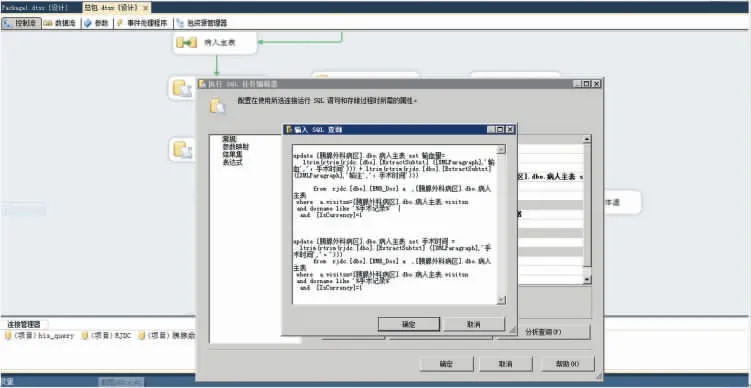
图9 应用标量值函数的SQL 语句示例
3.3 查询分析模块实现
在胰腺癌科研数据平台的基础上,本文采用SSRS 2015 开发前端界面,用以查询、展示胰腺癌专科数据库;前端界面支持按手术日期、患者年龄、性别查询等多种查询方式,可提供统计分析报表,如统计胰腺癌患者年龄、性别、出生省份等,对后结构化数据如抽烟、喝酒情况进行统计;能提供平均值、标准差、方差、众数、中位数、极大值、极小值等统计值,如术前检验指标统计。
模块具体实现方法如下:通过在SQL Server 数据库端创建存储过程脚本,将手术起止日期等作为查询参数,以此为依据在数据库中进行查询,得出相应结果。在存储过程中应用SQL 函数,如取平均值avg、取标准差stdev、取方差值var、取最大值max、取最小值min 等函数。在SSRS 2015 中选择存储过程脚本作为数据集生成报表,部署到报表服务器,然后为用户授权,用户可以查询相关报表。数据查询分析的部分界面如图10~15 所示。查询结果支持导出、打印功能,并可以导出Word、Execl、PPT、PDF、TIFF、CSV、XML 等多种格式的文件,便于医护人员后续进行手工处理。
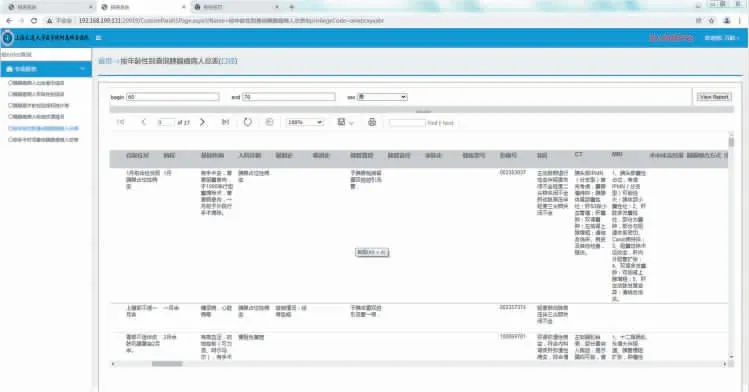
图10 按年龄、性别查询患者信息界面
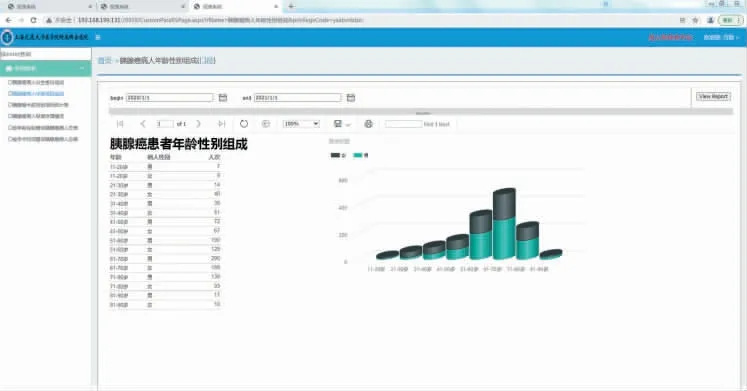
图11 胰腺癌患者年龄性别组成统计界面
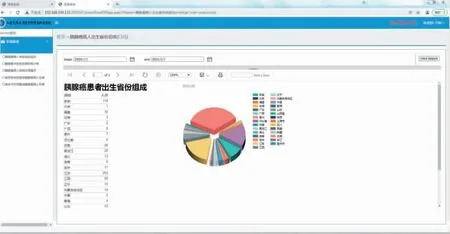
图12 胰腺癌患者出生省份组成统计界面
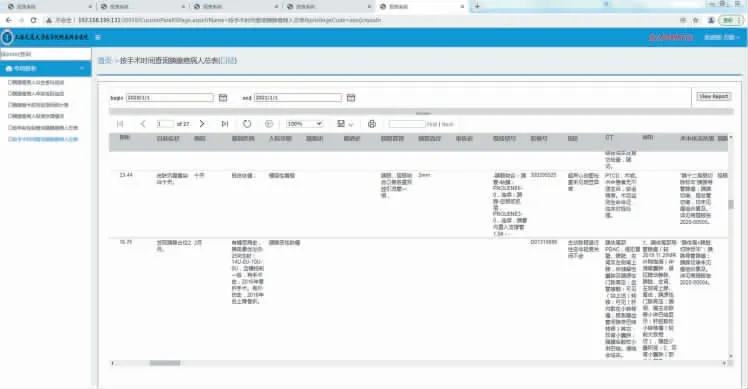
图13 按手术时间查询患者信息界面
4 应用效果
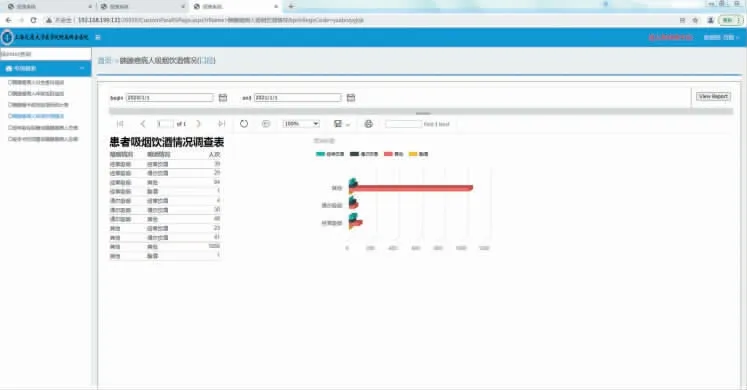
图14 患者吸烟、饮酒情况调查界面
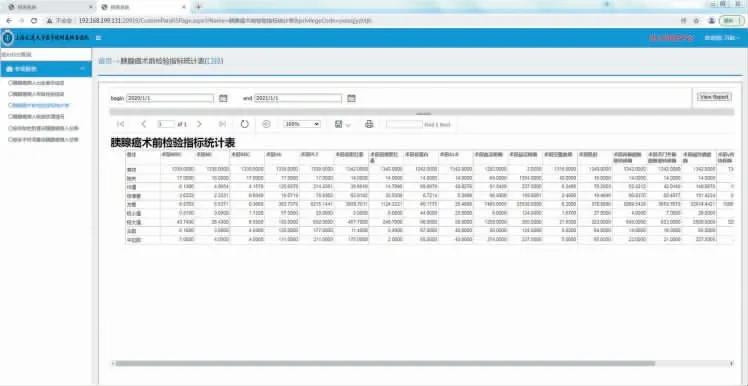
图15 胰腺癌术前检验指标统计界面
胰腺外科原来聘用专职文员进行电子病历科研数据抽取,但人工处理耗时长,容易产生手工误差。胰腺癌科研数据平台将散落在各个不同版本的系统中的非结构化、半结构化数据集成到一起,能快速得到科研数据。本平台在应用方面具有如下优势:(1)相较于SPSS 等数据统计分析工具,本平台可以完成非结构化文本的处理,从非结构化的文本中提取科研数据,例如从入院记录中提取BMI、抽烟和喝酒情况,进行量化处理后可以获取如标准差、方差、众数、中位数等统计值。(2)本平台采用B/S架构,数据报表可以共享,医院的科研人员只要应用浏览器即可在授权后使用数据。对于有诸多分院的医疗机构,采用B/S 架构有利于各分院实现科研合作和数据共享。
5 结语
本文通过分类处理的方式,建立了胰腺癌科研数据平台。本平台为胰腺癌科研项目提供了真实可靠的数据,为进一步的数据分析提供了数据支持。本平台在非结构化文本后结构化处理方面有创新性,且为其他科室的专病专科电子病历数据抽取提供了可行方案。同时,本研究创建的SQL Server 标量值函数为电子病历后结构化提供了新的思路和执行方案。另外,本平台使用的基于知识理解的分词法产生的新词汇可存入医学字典,为后续类似的病历文本抽取提供了分词支持,为数据采集质控提供了算据、算法、算例,为全流程数字化治理提供了新的思路。然而,本平台在数据分析方面有一定的不足之处,对于数据分析处理的方式过少,需要后续进一步改进,增强应用性和高效性。
