选择性集成学习多判别器生成对抗网络
2022-06-17申瑞彩翟俊海侯璎真
申瑞彩,翟俊海+,侯璎真
1.河北大学 数学与信息科学学院,河北 保定 071002
2.河北大学 河北省机器学习与计算智能重点实验室,河北 保定 071002
近年来,深度学习技术在许多方向取得巨大进展,通过构建类似人脑结构的多层神经元网络,对输入信息进行特征抽取与合成等操作,进而形成更加抽象的高维特征,大量实验数据证明,该算法已经大大超越了传统机器学习算法。在深度学习的发展过程中,出现了以生成对抗网络(generative adversarial networks,GAN)为代表的模型,该模型由生成网络与判别网络两部分组成,生成器从潜在空间中采样,产生数据,判别网络则对输入的数据进行鉴别,二者相互竞争,相互促进。
随着模型应用的广泛,存在的问题日渐突出,一种提高模型性能的方式是将模型在有监督的环境下进行训练,但该方式实现较为困难,因此未得到普及。而无监督环境下对模型训练又会带来诸多问题,同时现有的许多模型普遍采用单判别网络的形式,判别网络在模型中具有重要作用,仅含有单判别网络的模型易受判别误差的影响,从而影响生成网络学习。2016年提出的生成多对抗网络模型(generative multi-adversarial networks,GMAN)则考虑到了这一问题,作者将生成对抗网络中的判别网络采用多判别网络的形式,这一改进提升了模型性能,但作者并未对判别结果进行筛选,另外判别网络均采用相似的网络设置,在训练中模型会趋近于一种网络表达。因此,如何优化以及解决上述问题具有一定的研究意义。
本文针对在生成对抗网络中存在的尚未解决的问题,提出了一种全新的网络结构。将选择性集成学习的方式引入到判别网络中,同时采用依据基判别网络的判别性能动态调整基判别网络的投票权重的软投票策略,充分发挥基判别网络的优势抑制基判别网络劣势的影响,有效减少了判别误差。实验证明文本提出的模型性能上均优于现有的几种竞争模型。
本文的主要贡献包括以下三方面:
(1)提出基于选择性集成学习的生成对抗网络模型;
(2)在无监督方式下,本文所提模型在生成样本质量与多样性上均得到大幅度提升;
(3)提出的基于选择性集成学习思想的模型在收敛速度方面较传统模型均有明显提高。
1 相关工作
生成模型是无监督学习任务中常用的一类方法,其可直接学习样本数据中的分布。在神经网络兴起之前,生成模型主要对数据的分布进行显式建模。应用较多的有基于有向图模型的赫姆霍兹机(Helmholtz machines)、变分自编码器(variational autoencoder,VAE)、基于无向图模型的受限玻尔兹曼机(restricted Boltzmann machines,RBM)和深度玻尔兹曼机(deep Boltzmann machines,DBM)等。
当被建模变量为高维时,上述生成模型将面临指数级计算量,为优化这一问题,生成式对抗网络(GAN)被提出。该模型至今已有多种变体,并广泛应用于计算机视觉和图形应用等领域。而后根据不同的任务,生成对抗网络架构也有相应的变化。2015 年提出深度卷积神经网络(unsupervised representation learning with deep convolutional generative adversarial networks,DCGAN),将卷积融入到神经网络结构中,这一模型在后续研究中得到广泛应用。
生成式对抗网络(GAN)理论上可以收敛到最优的纳什均衡点,这足以保证生成网络可以学习到真实数据分布,然而在实际应用中,模型常出现模式崩溃,为解决这一问题,提出了条件式生成对抗网络(conditional generative adversarial networks,CGAN),但该模型训练需要大量已标记数据,目前如何获取已标记数据仍无有效方法。在InfoGAN(interpreter representation learning by information maximizing generative adversarial nets)中作者为强制生成器学习特定于因子的生成,将潜在因子和生成器分布之间的互信息最大化。
2016 年发表的Ensembles of generative adversarial networks中,模型采用多生成器集成的方式来提高生成样本的多样性,但此模型并未解决模式单一问题。同年提出的CoGAN(coupled generative adversarial networks)模型,通过训练具有共享参数的两个生成器以学习数据的联合分布,共享参数将两个生成器引导到相似的子空间,该模型关注在生成网络中且在不同域上进行训练。2016年提出的GMAN模型,利用多判别器的集合来引导生成网络产生更好的样本,从而稳定生成器的训练,在这一文章中作者注重从理论方面阐述模型架构。本文主要受这一模型启发,但作者并未考虑到判别性能较差的判别网络对模型的收敛带来的影响而是采用所有网络的判别结果。
文中提出的基于选择性集成学习的多判别网络根据判别网络在某一类别上的判别精确度动态赋予判别网络投票权重,从而有效发挥了各判别网络的优势。
2 基础知识
本章介绍将要用到的基础知识,包括生成对抗网络和集成学习。
2.1 生成对抗网络
生成对抗网络(GAN)核心思想源于博弈论中的纳什均衡,模型主要包含两部分,生成图像的生成网络,判别图像真伪的判别网络,生成网络与判别网络均由参数化的神经网络组成。网络模型如图1所示。
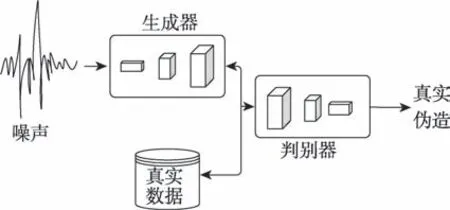
图1 生成对抗网络模型Fig.1 Model of generative adversarial networks
生成器的输入为服从某一分布p的随机向量,假设真实数据的分布为,在给定一定量真实数据集的条件下,对生成对抗网络进行训练,生成器将学习到近似于真实数据的分布。该网络的目标为最小化真实数据分布与生成数据分布之间的距离,可用式(1)来表示:
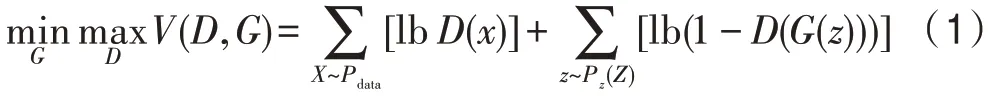
2.2 选择性集成学习方法
本文采用的选择性集成学习是集成学习方式的一种,即在集成学习的基础上增加了对基学习器的选择阶段。传统集成学习方式得到的是一系列弱学习器,之后并未对弱学习器进行有效处理,在实验中设置了将全部弱学习器的信息进行采纳,结果证明相比于仅使用单判别器的情况,这种方式对网络性能略有提升,因基判别网络的判别性能不一,采用这一方式并未使网络达到最优值,综上该方式并不可取。而选择性集成学习通过一定的集成策略,对基学习器进行处理,与本文的思想相吻合。
该方法如图2 所示,通过弱学习器的选择性集成,集成策略依问题而定,该集成策略将满足要求的个体学习器权重增加,降低不满足要求的个体学习器的权重,从而改善模型的整体性能。
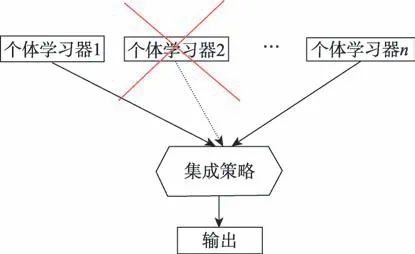
图2 选择性集成学习示意图Fig.2 Diagram of selective ensemble learning
下面介绍集成策略,集成策略一般分为平均法、投票法、学习法三种方法。
(1)平均法分为简单平均与加权平均。
简单平均:

加权平均:
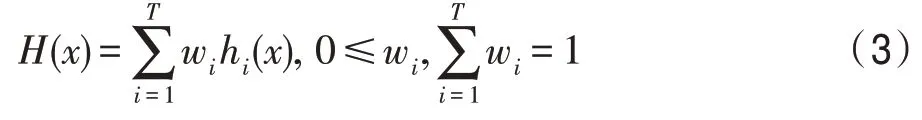
其中,w是个体学习器h的权重。
(2)投票法主要分为相对多数投票法、绝对多数投票法和加权投票法。
(3)学习法通过将得到的一系列初级学习器的结果作为次级学习器的输入,从而进行集成,该方法的典型代表为Stacking 方法。
3 提出模型
传统生成对抗网络被定义为min-max 学习框架,模型包含生成网络与判别网络,早先证实如果给予足够的网络学习能力,判别器会达到理想的全局最优解,此时()=(),即生成器学习到了真实数据分布。若模型仅由单判别网络进行判别,易受判别网络性能影响出现误差。为减少误差、加速模型收敛,本文引入集成学习机制,模型如图3 所示。具体地,将生成对抗网络中的判别网络改成集成判别系统,同时基判别网络采用不同的网络设置,以避免在训练中所有网络趋近于一种表达形式,具体的网络设置将会在实验部分进行介绍,对于每个判别网络都将接收来自真实数据集的样本及生成网络生成的样本,并独立判断。由于基判别器判别性能不一,将所有判别结果进行采纳势必影响生成网络学习,有必要对判别结果进行处理,从而发挥基判别网络的优势,削弱甚至避免由判别网络性能不佳产生的影响。由于判别能力不同,设固定权重显然不妥,应根据判别网络当前判别能力进行权值分配。综上,该模型最终决定采用可以动态调整基判别网络的投票权重的软投票策略。该投票策略的具体做法是根据不同分类器在同一类别上的精确率做Softmax 运算,其结果为不同分类器在该类别上的预测权重值。权重值如式(4)所示:

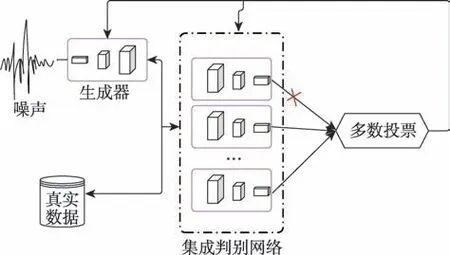
图3 选择性集成学习多判别器生成对抗网络模型Fig.3 Selective ensemble learning for multi-discriminator generative adversarial network model
其中,w表示第个基分类器第类的权重,p表示第个基分类器第类别的精确率。
目标函数如下:
(1)生成网络
在集成判别模型中,生成网络的输入为随机噪声,输出被传送到集成判别系统中。为了生成网络得到更有效的训练,生成网络目标函数如式(5)所示:

其中,≤,为一次训练结束后选择集成判别网络的数量,为集成判别系统中的集成网络数量,D表示第个基判别器。
(2)判别网络
在集成判别网络中,各基判别器的输入为来自生成样本与真实数据集中的样本,其目标仍是正确区分各样本。
这与传统生成对抗网络中判别器的目标一致,因此在该网络模型中基判别网络的目标函数可写成式(6)的形式:
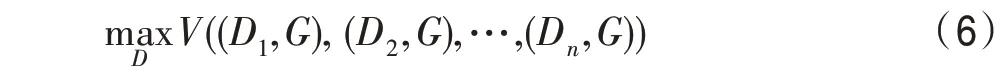
其中,为集成判别网络的个数,(D,)表示基判别网络D的损失函数。max(·)表示集成判别网络的损失函数。
4 实验与结果
为验证模型的有效性,分别在CelebA(RGB 图)和MNIST(灰度图)数据集上进行多个对比实验。其中CelebA 数据集共包含200 000 张彩色图像,图像尺寸为178×218,为便于实验采用了其中的30 000张图像,并将图像处理为128×160;使用的MNIST数据集共包含55 000 张灰色图像,图像尺寸为28×28。实验的环境为Tensorflow1.0,Python3.7.3,NVIDIA GFORCE GTX980,Windows10 操作系统。
4.1 度量标准
本文选择的度量指标主要用来评价模型生成样本的质量与多样性。具体地使用:
(1)IS(inception score)评价指标,如式(7)所示:

其中,(|)表示输入图像服从的概率分布,()表示全体图像的概率分布。该评价指标较好地度量了生成样本与真实样本的差距,若生成样本与真实样本越接近,则值越大。

表1 针对MNIST 数据集的各网络卷积层配置Table 1 Convolution layers configuration of each discriminant network for MNIST dataset
(2)FID(Fréchet inception distance)评价指标
该指标通过计算真实样本与生成样本在特征层的距离很好地度量了生成样本的优劣,其数学表达式如式(8)所示:

其中,表示真实样本的特征均值;表示生成样本的特征均值;表示真实样本特征的协方差矩阵;表示生成样本特征的协方差矩阵。
该评价指标将生成样本与真实样本特征图的均值与协方差矩阵进行比较,当生成样本与真实样本的特征越相近,其值越小。
(3)KID(kernel inception distance)评价指标
若生成样本与真实样本之间的差异越小,则其值越小。
4.2 实验结果
主要从以下方面进行实验:(1)集成不同判别网络数量对生成样本的影响;(2)将模型与同方向工作进行对比;(3)分析模型的时间复杂度。
(1)集成不同数量判别网络
实验细节:随机噪声服从~(-1,1);网络训练采用Adam 优化器(学习率l=2×10,动量参数=0.5);生成网络的结构为(7,7,32),(7,7,64),(14,14,128),(28,28,64),(28,28,1);因小卷积核在分辨率较低时表现较好,且可减少参数量,所以网络中与DCGAN 的5×5 的卷积核不同,本文选用了3×3 的卷积核,另外在最后一层采用了1×1 的卷积,基判别网络间的不同之处在滤波器的数量,即数量上的乘以2 或4,或除以2 或4,具体设置如表1 所示。
图4 为分别使用平均法与投票法时模型生成样本的情况,投票法比平均法生成样本质量较高。另外,分别使用三种评价指标对两种集成策略下不同的模型生成的样本进行评价,结果如表2~表4 所示。通过对比可知采用平均法的模型总体没有采用投票法的性能高,这是由于平均法中没有减小性能较差的模型的影响,而采用具有动态调整权值的投票法则最大程度地提高了判别网络的准确率(*对应的模型为在此指标下的最佳模型)。

图4 采用不同集成策略生成的样本对比Fig.4 Network generated samples by different integration strategies
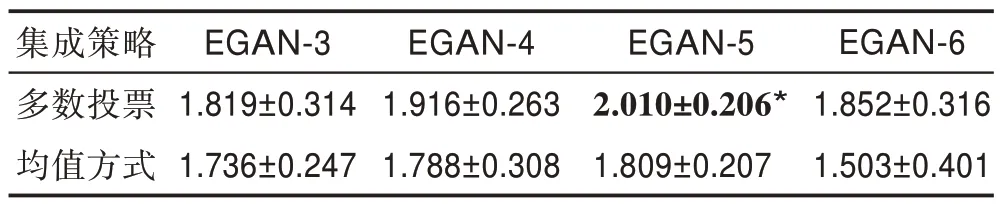
表2 不同集成模型在两种集成策略下的IS 得分Table 2 IS score of different integration models under two integration strategies
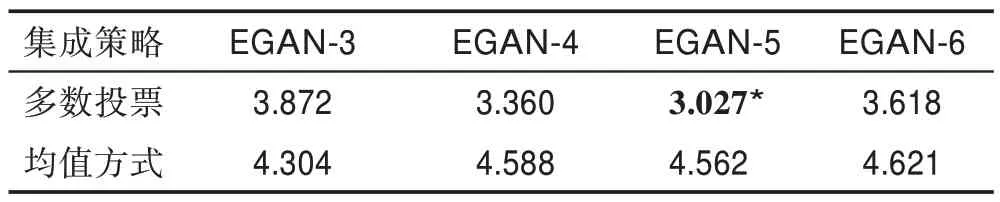
表3 不同集成模型在两种集成策略下的FID 得分Table 3 FID score of different integration models under two integration strategies
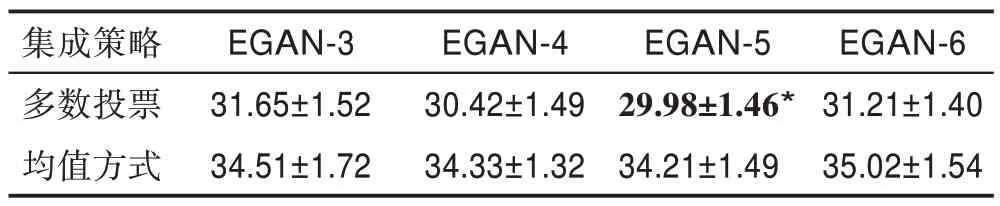
表4 不同集成模型在两种集成策略下的KID 得分Table 4 KID score of different integration models under two integration strategies

图5 EGAN-n(n=3,4,5,6)模型生成的手写体图像Fig.5 Handwritten images generated by EGAN-n (n=3,4,5,6)

图6 不同模型生成的手写体图像对比Fig.6 Comparison of handwritten images generated by different models
图5 为EGAN-(=3,4,5,6)模型在迭代次数分别为1、2、4、5、10 epochs 时生成的手写体图像,可知当训练为10 epochs 时,4 种模型均达到收敛状态,其中EGAN-5 网络生成样本最优,其次为EGAN-4、EGAN-6,最后EGAN-3。
另外从结果可看出生成样本质量与集成数量并非正比关系,而是达到某一阈值后出现性能下降的情况。为验证这一结论,继续设置了分别集成8 判别网络、9 判别网络以及更多数量的判别网络,实验中生成样本情况并未好转。由此可见,当网络集成数量超过一定数量时性能会随着集成数量的增加而降低。
通过使用不同评价指标对两种集成策略下设置的不同集成数量的判别网络模型进行评价,可知多数投票总体比均值集成方法结果较好,同时可知无论是在IS、FID 还是KID 指标下,EGAN-5 网络模型都是最优的。
(2)与同方向工作比较
这一部分主要与GMAN 模型以及生成对抗网络(GAN)、深度卷积生成对抗网络(DCGAN)模型进行比较。为保持公平一致性,对GAN 以及DCGAN 进行了同等数量的集成,并在相同环境下进行实验。采用相同的评价指标进行评价,实验结果如图6 所示。可知本文所提模型在4 epochs 时生成样本已达到清晰状态,另外三种比较模型收敛较慢且最终生成样本较为粗糙。采用不同评价指标的结果列于表5,从表中可看出文中所提模型在几种评价指标下均最优。

表5 不同模型在三种评价指标下的得分情况Table 5 Score of different models under three evaluation indices
实验细节:随机噪声服从~(-1,1);网络训练采用Adam 优化器(学习率l=2×10,动量参数=0.5);生成网络的结构为(5,4,1 024),(10,8,512),(20,16,256),(40,32,128),(80,64,64),(160,128,3);由于较大的卷积核在高分辨率下表现更好,同时为了减少参数量,使用1×5 与5×1 的卷积核代替5×5的卷积核,这是由于同时使用1×5 与5×1 的卷积核与单独使用5×5 的卷积核的感受野相同,在判别网络中卷积核具体设置为5×5、3×3、1×5、5×1、1×1。基判别网络间的不同之处在于滤波器的数量,即数量上的乘以2 或4,或除以2 或4,具体设置如表6 所示。

表6 针对CelebA 数据集的各网络卷积层配置Table 6 Convolution layers configuration of each discriminant network for CelebA dataset
(1)集成不同数量模型的比较
图7 为采用平均法与多数投票法时模型的生成样本情况,可知在采用多数投票法时生成样本质量较好。另外还使用不同评价指标对两种集成策略下的样本进行评价,结果如表7~表9 所示。图8 展示了不同模型在不同迭代次数下生成的人脸图像,同样EGAN-5 模型性能最佳,因为其生成样本的质量与多样性最优。另外,将本文的模型在不同集成策略下进行了比较,模型中采用多数投票的方式均比采用均值的方式表现较好。表7~表9 展示了在三种评价指标下各种模型的得分情况(*对应的模型为在此指标下最佳的模型)。
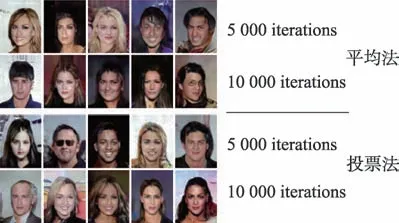
图7 采用不同集成策略生成的样本对比Fig.7 Network generated samples by different integration strategies
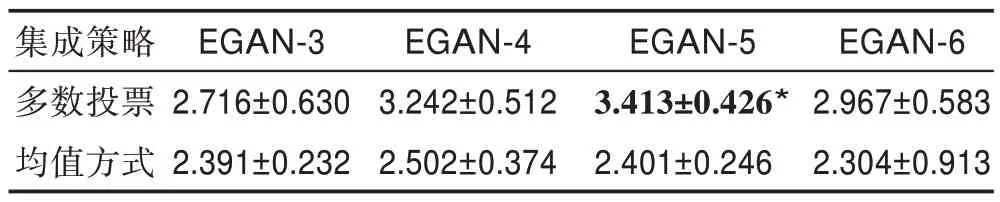
表7 不同集成模型在两种集成策略下的IS 得分Table 7 IS score of different integration models under two integration strategies

表8 不同集成模型在两种集成策略下的FID 得分Table 8 FID score of different integration models under two integration strategies
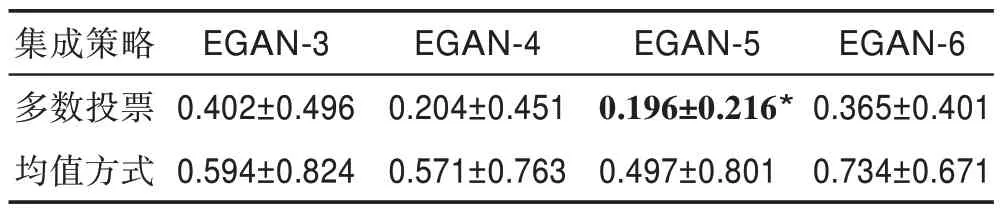
表9 不同集成模型在两种集成策略下的KID 得分Table 9 KID score of different integration models under two integration strategies
通过设置不同集成数量的判别网络模型,在两种集成策略下可以看出选用多数投票的方法总体比选用均值的方法模型性能较高,而无论是在IS、FID还是KID 指标下EGAN-5 模型都是最优的。

图8 EGAN-n(n=3,4,5,6)模型生成的人脸图像Fig.8 Face images generated by EGAN-n (n=3,4,5,6) model

图9 不同模型生成的人脸图像对比Fig.9 Comparison of face images generated by different models
(2)与同方向工作比较
这一部分主要与GMAN 模型以及生成对抗网络(GAN)、深度卷积生成对抗网络(DCGAN)模型进行比较。为保持公平一致性,本文对GAN 以及DCGAN 进行了同等数量的集成,并在相同环境下进行实验,采用相同的评价指标进行评价,实验结果如图9 所示。从图中可看出本文的模型明显优于几种对比模型。另外采用不同评价指标的结果列于表10,从表中可看出本文所提模型在几种评价指标下均最优。
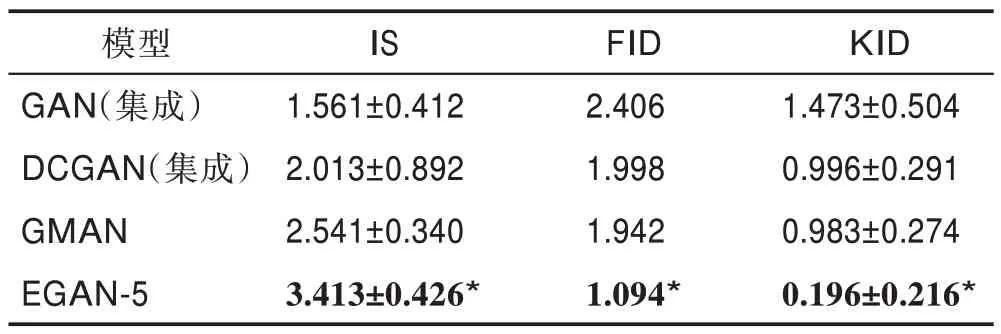
表10 不同模型在三种评价指标下的得分情况Table 10 Score of different models under three evaluation indices
4.3 模型时间复杂度
卷积神经网络的时间复杂度如式(9)所示:
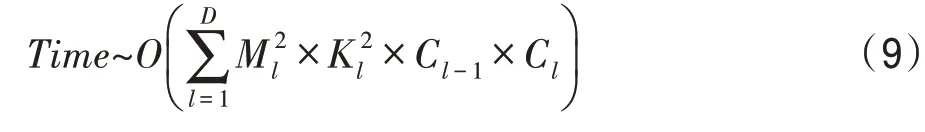
其中,表示卷积神经网络的深度;表示卷积层输出特征图的边长;表示卷积核的边长;表示神经网络第个卷积层;C表示神经网络第层的卷积核个数。
通过实验可以发现,在MNIST 数据集下,GAN(集成)采用全连接的方式,DCGAN(集成)网络中卷积核为5×5,GMAN 模型卷积核3×3,本文EGAN-5 模型采用了3×3 的卷积核,同时在最后一层使用了1×1的小卷积核,最终DCGAN(集成)的复杂度约为3.14×10,GMAN 模型的复杂度约为1.206×10,而本文模型约为4.37×10;同样在CelebA 数据集上,DCGAN(集成)的卷积核为5×5,GMAN 的卷积核为3×3,本文模型不仅引入了3×3 卷积核、1×1 卷积核,还通过使用1×5 和5×1 的卷积核来代替5×5 的卷积核,从而提取更“全面”的信息。具体地DCGAN(集成)的复杂度约为1.044 5×10,GMAN 的复杂度约为5.199×10,而本文模型的复杂度约为3.269×10。因此在不同数据集上,相比GMAN 和DCGAN 模型,本文模型的复杂度都是最低的。
图10 为运行一个epoch 时各模型花费的时间对比。可知无论是在MNIST 数据集还是在CelebA 数据集上,本文模型所需时间都是最短的,其次为GMAN模型,最后为DCGAN(集成)模型。
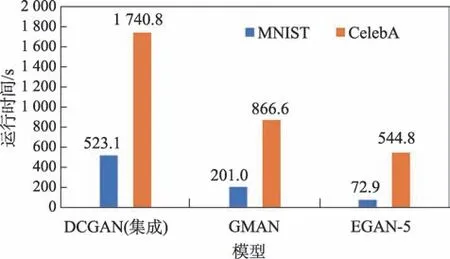
图10 不同模型训练一个epoch 所需的时间Fig.10 Time required for different models to be trained in an epoch
另外,本文还比较了EGAN-5 模型生成的部分样本与使用的数据集中的部分样本,结果如图11所示。

图11 生成的部分样例(左)与数据集的部分样例(右)Fig.11 Some generated samples(left)and some samples in dataset(right)
5 结束语
本文提出了一种新的模型框架,将选择性集成学习的思想引入到生成对抗网络中,并根据判别网络的判别精确度动态赋予判别网络投票权重,从而充分发挥各判别网络的优势,避免了因判别网络判别性能不足产生的影响。在本文的工作中,通过大量的实验以及对比实验,详细分析了在不同迭代次数上不同集成数量模型的表现,以及在不同数据集上模型的时间复杂度。本文采用了前人工作中的优点,比如深度卷积神将网络(DCGAN)中新颖的卷积方式,完全取代了全连接。文中还存在一定的不足,接下来会更加注重模型的设计以及细节,还会把工作的重心放在生成网络上以及更加关注网络的质量。
