基于图文融合的多模态舆情分析
2022-06-17朱婷鸽李琳娜刘继明
刘 颖,王 哲,房 杰,2,朱婷鸽,2,李琳娜,刘继明
1.西安邮电大学图像与信息处理研究所,西安 710121
2.西安邮电大学电子信息现场勘验应用技术公安部重点实验室,西安 710121
3.西安邮电大学网络舆情监测与分析中心,西安 710121
4.西安邮电大学通信与信息工程学院,西安 710121
互联网时代具有开放性、多元性以及互动性等特点,这促使全民信息交流日趋便利。当下网络信息传递具有如下特点:(1)双向传播,信息发布方和接收方交流更加密切,接收方甚至可以对真假难辨的信息进行二次传播,从而造成虚假信息爆炸式增长。(2)发布门槛走低,对于信息的发布方来说,只要注册账号就可以进行信息发布。一个突发的热点问题就可能对政府和企业造成极大的损失,因而企业和政府只有对舆情事件做出合适的应对决策,才能有效化解负面舆情。目前,针对网络舆情监测研究,主要围绕网络舆情概念、舆情演进特征、舆情信息获取、舆情分析和预警监测系统建立等方面展开。其中舆情分析是最关键的技术之一,而网络舆情的情感分析尤为重要,其原因在于网络舆情分析的主要原则是根据民众对事件的情感态度来判断事件的走向。
“情感分析”一词由文献[2]提出,但最早提出情感分析任务的是Pang 等研究者,他们将文本的主观计算过程定义为情感分析和观点挖掘。在线评论的情感分析需要考虑情感强度和情感极性,其主要任务是识别人们所表达的主观态度或观点。目前大多数研究者对单模态情感进行了分析,例如文献[4]调查了一些基于情感分析的机器学习方法,文献[5]考察了句子层面的情绪,文献[6]总结了情感分析的主要任务和应用。随着网络的多元化发展,人们不再满足于仅仅使用文字在社交媒体上发布自己的状态,而是更青睐于文本与图像结合的方式表达自己的情感。因此,结合文本和图像信息进行舆情情感分析的研究变得越来越重要。
本文的重点是对网络舆情的情感分析进行综述。具体来讲,本文以网络舆情监控系统的构建流程为主线,对基于图文的网络舆情情感分析进行了总结,并对网络舆情情感分析面临的挑战和未来的发展方向进行了探讨。
1 网络舆情概述
1.1 网络舆情的基本概念
网络舆情是社会舆情在互联网上反应的一种特殊形式,是网民认知、情感、态度和行为倾向的集合,更多的是民众情感的体现,涉及时政、环境卫生、公共安全等广泛领域。社会化媒体公众参与度的提高促进了网络舆论的发展,同时也使其传播方式和演进方式不断发生变化。针对热点问题的舆情信息混杂着理性和非理性的成分,如果不能对舆情信息进行正确、及时的处理,可能会产生严重的社会后果。网络舆情分析可以有效掌握公众对热点事件的看法,及时预测公共事件的发展趋势,从而引导舆论健康发展。舆情情感分析综合了计算机科学、社会学、数学、心理学等多个学科,通过文本、图片或图文融合对情感进行分类,进而分析情感趋势,把握公众的心理状态。因此,通过对网络舆情进行情感分析,可以有效掌握网民的态度、情绪和行为,从而达到疏导和控制网络舆情事件的目的。
1.2 网络舆情分析系统概述
网络舆情分析系统目的在于对社交媒体上的舆情进行价值和趋向判断,在工作流程层面,其系统的构成主要包括四个模块:舆情数据的采集与处理模块、舆情数据分析模块、分析结果管理模块以及舆情报告导出模块。舆情数据的采集与处理模块包括舆情数据采集和数据的预处理,其作用是记录管理舆情信息,同时允许用户进行信息检索。数据分析模块包括话题热度计算和极性判断,该模块负责对收集到的舆情信息进行情感分析。分析结果管理模块包括分析报告、舆情结果检索以及进行趋势分析,其作用是将舆情分析的结果量化,同时分析趋势并将结果展现出来。舆情报告导出模块允许用户将可视化结果根据不同的需要格式保存到本地。其工作流程如图1 所示。
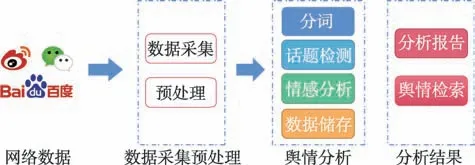
图1 舆情分析系统流程图Fig.1 Public opinion analysis system flowchart
2 基于单模态的网络舆情情感分析
网络舆情监测研究最早兴起于国外,文献[8]指出早在20 世纪90 年代Allan 等就将主题检测和跟踪技术应用到网络舆情的数据分析中。随着网络的不断普及和Twitter 等社交平台不断兴起,Hughes 等人在2009 年通过对突发事件中Twitter 用户的态度和行为的研究,提出了Twitter 平台如何疏导网络舆情的方法。国内研究相对较晚,刘英杰最早对舆情监测系统构建进行了研究,对舆情信息的情感维度在空间的特征和演化规律进行了分析。黄微等人对网络舆情信息的语义识别技术进行了对比探讨。这些早期的研究都对未来网络舆情检测研究奠定了基础。在早期舆情情感分析研究中,主要研究的对象是文本或图像,所采用的方法大多数是传统的机器学习方法,例如贝叶斯分类、最大邻近算法等。近年来,随着深度学习的不断发展,研究者们逐渐倾向于用神经网络来学习文本或图像的特征以实现情感分析。
2.1 基于文本数据舆情情感分析
文本数据在新闻、网上评论、自媒体推文等网络信息中较为常见,是目前网络信息中的主要数据形式。文本数据的舆情情感分析又称为数据挖掘,是指对带有主观情感色彩的文本进行情感倾向挖掘,并对其情感态度进行分类的过程。本文情感分析过程大致如图2 所示。
常用的文本预处理策略包含分词和词性标注。分词即将一个连续的句子分割成若干独立的词序列,作为文本信息的特征项。常用的方法有基于词典的分词方法和基于统计的分词方法。基于词典的方法是将分割的字符串与情感字典中的已有词汇进行对比。例如崔彦琛等人利用PMI-IR(point-wise mutual information-information retrieval)、SO-PMI(semantic orientation pointwise mutual information)等算法,建立了消防舆情词典,其中包括通用词典、消防领域情感词典和网络语言情感词典,并证明了其高效性、准确性以及在消防领域的适用性和专业性。该方法的优点是处理简单,效率高,其不足之处则在于太过依赖于词典的规模与判别规则。在网络舆情中,词语的更新速度快,词典分词法很难满足要求。因此,基于统计分词的方法得到了较为广泛的应用,其中最经典的模型为-gram。该模型的原理是给定一个句子,gram 就可以计算出一个概率值。通过列举出所有可能的分词方式,再根据所有可能的分词方式分别计算该句子的概率,选择使句子概率最大的分词方式作为最终分词结果。词性标注指在分词的基础上,根据上下文条件对每个词进行词性判断并添加标签的过程。例如文献[14]通过对关键词进行情感标注实现对文本数据的预处理,实验效果大大提升。
文本表示与特征提取是情感分析中最为关键的一步。舆情信息的情感识别,最重要的就是提取出文本中的非结构化信息,从而判断情感倾向。因此,良好的文本表示模型对于提高情感识别效果至关重要。目前文本表示模型以及优缺点如表1 所示。
传统上,BoW(bag-of-words)模型已用于提取自然语言处理(natural language processing,NLP)和文本挖掘中句子和文档的特征。BoW 模型将文档转换为具有固定长度的数字特征向量,并对向量中的每个元素进行评分。尽管BoW 受欢迎,但其仍有一些缺点。首先,该向量的维度等于词汇表的大小,因此随着词汇表大小的增加,文档的向量表示也增加。其次,由于忽略了单词顺序,BoW 模型几乎不能对单词的语义进行编码。第三,每个文档可以在词汇表中包含非常少量的已知单词,导致具有大量零分数的向量,称为稀疏向量或稀疏表示。
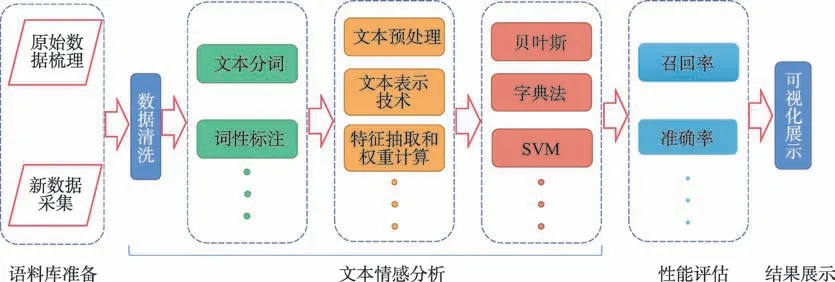
图2 文本情感分析流程Fig.2 Text sentiment analysis process

表1 文本表示模型及其优缺点Table 1 Text representation model and its advantages and disadvantages
针对此问题,引入了一个更复杂的模型bag-of-grams 的分组词汇表,这是BoW 模型的扩展,改变了词汇的范围,并允许一袋单词从文档中获取更多的意义。该模型可以在短上下文中考虑单词顺序,但它仍然存在数据稀疏性和高维度的问题。
为了克服BoW 模型和-grams 模型的缺点,提出了词嵌入的技术。单词嵌入使用神经网络来学习文本的表示,使得具有相同含义的单词具有相似的表示。单词嵌入将词汇表中的单词转换为连续实数的向量。该技术通常涉及将高维稀疏向量嵌入到可以编码单词的一些语义和句法属性的低维密集向量中。嵌入向量的每个维度表示单词的潜在特征。目前,文本特征提取的最新趋势集中在Glove(global vectors)或word2vec等大型语料库上预先训练的单词嵌入。
(1)基于传统方法
传统的情感分析方法主要基于情感词典或机器学习,并使用分类、回归等方法实现特征提取和分类。基于词典的方法依赖于情感词典,情感词典是包含情感极性信息的单词或短语的列表。2016 年,Saif 等人提出了SentiCircles 模型,通过考虑不同语境下单词的共现模式来捕捉语义,并更新预先分配的语义情感词汇强度和极性,从而获取更合适的情感词典。该模型在Twitter 文本上的表现比SentiStrength模型更具竞争性。然而,在分析实时Web 平台生成的评论文本时,其无法及时更新情感词典,从而导致对新词情感的识别难度的增加。因此仅使用基于词典的方法,冗长的分析过程和有限的准确度将限制该技术在本领域的应用。
机器学习方法可分为有监督学习和无监督学习,在数据量足够、数据类型多样的情况下,该方法与基于词典的方法相比,能够有效避免上述问题。李婷婷等人改进了支持向量机方法和条件随机场方法,结合多种特征组合,弥补了传统机器学习方法中特征提取的不足。然而基于传统的情感分析方法存在数据稀疏问题和字序问题,且需要大量标记的文本。
(2)基于深度学习方法
深度学习可以避免繁琐的特征选择过程,自动抽象特征,学习相应的参数,并捕获复杂的特征。基于深度学习的方法在输入层和输出层之间嵌入隐藏层,以模拟其他算法无法学习的数据中间表示。该机制可以有效地从高维数据中学习更深层次的信息。
对于情感分类问题,卷积神经网络(convolutional neural networks,CNN)由于结构简单,训练效率高,广泛用于文本情感分类。Stojanovski等人使用CNN提取消息文本的特征,并融合不同的分类算法对新闻相关的Twitter 消息进行情感分析,以提供公众对某些事件的反应见解。然而单纯的CNN 模型在训练过程中放弃了上下文之间的关系,因此无法很好地解决时序问题,也无法准确分析过渡句子等数据。Sun等人使用区域卷积神经网络(regions with CNN features,RCNN)来保留句子的时间关系,从而捕获单词之间更多的语义关系。因此,他们解决了在处理基于方面的情感分析任务时,传统神经网络模型在句子之间的连接较少并且单词之间的语义信息较少的问题,在基于方面的情感分析中,具有良好的适应性。Chen等人提出了一种称为双通道卷积神经网络的字符嵌入情感分析方法(character embedding with dual-channel convolutional neural network,char-DCCNN)。该方法将中文语料库划分为单个中文,然后将它们训练成字符向量,依次将表示文本的向量矩阵输入到双通道CNN 中,通过少量标记数据和少量迭代获得良好的分类性能。实验表明,该方法改善了微博中短评论的情感类别结果,然而字符嵌入增加了文本的分布式表示的复杂性和计算成本。
循环神经网络(recurrent neural network,RNN)能够循环保持信息(即使用以前的信息连接到当前的任务,并用过去的文本猜测当前的文本)。然而,RNN 有一个明显的长期依赖性问题:当历史文本太长时,文本的有效信息无法保存。鉴于此,裴颂文等人提出了一种特殊的RNN 结构LSTM(long shortterm memory),该模型可以充分利用目标情绪词和句子中情绪极性词之间的关系。受到该模型的启发,Xing 等人提出了一种用于情感分析的方面感知LSTM(aspect-aware LSTM,AALSTM),它在上下文建模阶段将方面信息整合到LSTM 单元中。该方法在给定方面保留有效信息,同时过滤掉给定方面的无用信息,并且其最终的情绪表示更有效。
罗帆等人将RNN 与CNN 相结合,提出了一种分层神经网络(hierarchical RNN-CNN,H-RNN-CNN)作为表示情感分析文本的通用模型。为防止信息可能在长文本中丢失,使用CNN 来捕捉句子之间的关系。Rehman 等人提出了LSTM 和深层CNN 的混合模型用于情感分析。与基于CNN 的方法或基于LSTM 的方法相比,该模型具有更高的准确性,然而其更适合具有更多参数的小数据集。Liu 等人提出了一种混合模型,在CNN的基础上,通过BiLSTM(bidirectional long short-term memory)提取与文本上下文相关的全局特征,并融合两个互补模型提取的特征。
2.2 基于视觉数据的情感分析
社交媒体中,人们常常在发布动态、观点等信息的同时会为其配上图像。其原因在于图像不仅可以在情感方面影响其他人,而且也能够直接或间接地表达发布人的态度和情感。“视觉情感分析”的主要目的有两点:一是模拟并检测个人可观察表达的情绪;二是检测视觉媒体所发布的图像表达其作者或在观察者中唤起的情绪。虽然前者从个人(或群体)中提取面部表情或身体姿态从而判断情感的研究较为成熟,然而后者对于社交媒体中非语言情感表达的基于视觉的情感分析领域研究还是一个较新的领域。在视觉情感分析中,“情感”表现为人们与视觉元素互动的结果。鉴于情感总是朝向对象或实体,视觉情感同样被定义为视觉内容中存在的对象、场景或事件。例如,一张展示美味食物的图像可能表达了积极情绪;通过体验这些图像,观众可能会引发积极情绪。当这些情感体验被提炼成一组语义标签时,可以构建计算机视觉问题,以从低级视觉多媒体(即原始像素、运动等)学习功能映射,到分类,本地化和汇总任务中的高级情感标签。一般情况下,对于一个图片的情感识别需要由图像预处理、特征提取、分类器识别三部分组成,其流程如图3 所示。
其中图像预处理是为了减小图像中干扰识别效果的信息,目前常用的预处理操作包括对象检测技术、单图像超分辨率技术、图像增强技术(如缩放、旋转和平移)。特征提取的目的是提取图片中与情感相关且区分能力强的特征,是情感识别中最为关键的一步。图像特征一般分为浅层特征、中层特征和深层特征。分类器的识别则是按照特征提取的结果进行分类。
计算机图像分析算法的起点在于特征的选取。特征是一个数字图像中“可重复性”的重要部分,算法的成功通常取决于其所使用和定义的特征的合适性。现有的图像特征一般分为浅层特征、中层特征和深层特征。浅层特征主要指颜色、形状、线条等特征,中层特征一般指图像中存在的对象、目标等特征,而深层特征则是指行为、场景和情感等语义相关特征。传统的关于视觉内容情感语义分析研究大多数是直接建立低级视觉特征和情感语义之间的映射关系,然而,由于社交媒体中的视觉情感语义是由认知语义间接驱动的,该方法不适用于社交媒体中视觉内容的情感分析。此外,社交媒体中的视觉内容也可以自由分享,多样化的数据与其情感取向之间的关系极其复杂,语义鸿沟问题十分严重。
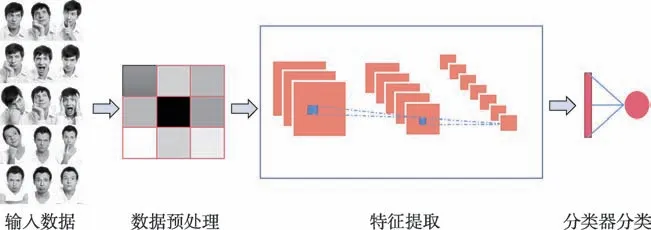
图3 图像情感识别流程图Fig.3 Image sentiment recognition flowchart
为了填补这一语义空白,研究者们努力利用中层表征作为视觉底层特征和情感取向之间的桥梁。近年来,由于深度学习在计算机视觉领域取得了巨大成功,研究者们开始将深度学习技术应用于视觉内容的情感分析和观点挖掘。因此,现有的社交媒体视觉内容特征提取可以分为基于中层表征的方法和基于深度学习的方法。
现有的基于中层表征的方法主要利用视觉底层特征形成中层情感本体进行概念检测,而忽略了本体概念之间的区别和联系。Yuan 等人定义了一个通过提取场景描述符的底层特征,并利用四个特征对分类器进行Liblinear 训练,生成102 个预定义的中层属性,然后利用这些属性预测情感。与直接使用视觉底层特征的方法相比,该方法使得情感预测结果更具解释性。Borth 等人提出了另一个具有代表性的中层表示框架,如图4 所示。
他们使用形容词-名词对(adjective noun pairs,ANP)构建了一个大规模的视觉情感本体(visual sentiment ontology,VSO),作为视觉情感分析的中层描述符。他们还提出了一套名为SentiBank的ANP概念检测器,用于检测视觉内容中1 200 个ANP。ANP 的响应可以作为视觉情感预测的中间层特征。视觉内容的情感信息主要由图像中的对象来传达。因此,Chen 等人提出了一种基于VSO 和SentiBank 的视觉情感概念分析方法。他们首先定位视觉内容的对象,然后用形容词来描述相关属性,将ANP 检测问题分解为目标定位和概念建模。该方法将情感语义分析与目标检测相结合,为视觉情感分析提供了一个新的视角。然而,结果表明,该方法在提高情感分类性能的同时,增加了计算复杂度。为了解决基于VSO的模型中ANP 与视觉内容的情感取向相关性的问题,Cao 等人提出了一种用于视觉情感分析的视觉情感主题模型(visual sentiment topic model,VSTM)。VSTM 的主要优点是包含了对视觉内容主题的宏观描述。现有的基于VSO 和SentiBank 的应用程序将ANP 概念的响应作为中间层特征,忽略了这些ANP概念的情感信息。为解决此问题,Li等人提出了一种充分利用ANP 文本情感信息的方法。他们根据ANP 的文本情感值和图像中相应的响应来计算图像的整体情感值,然后将图像情感值作为一维特征进行图像情感预测。实验结果表明,利用文本情感分析提高图像情感分析的性能是可行的。
深度学习采用多层模型将底层特征转化为抽象的特征空间,与人工特征相比,可以更好地描述输入数据的内在信息。更重要的是,社交媒体中大量的视觉数据可以为深度学习提供足够的训练样本。现有的基于深度学习的视觉情感分析方法可以分为两类:端到端模式和管道模式。
端到端方法尝试使用诸如卷积神经网络(CNN)之类的深度模型来建立图像像素和视觉情感取向之间的映射。在端到端的方法中,文献[42]提出了两个条件概率神经网络(conditional probability neural network,CPNN),称为二进制CPNN(BCPNN)和增广CPNN(ACPNN),其目的是预测一组已考虑的标签上的概率分布。文献[43]改变了预先训练的CNN 对象分类的最后一层的维数,以提取所考虑的情绪标签的概率分布,将原有的损失层替换为分类损失和情感分布损失通过加权组合集成的函数,然后对修改后的CNN 进行微调,以预测情绪分布。文献[44]训练了一个CNN 进行情绪分析,然后实证地研究了每个层的贡献,使用每一层的激活来训练不同的线性分类器。同时,还研究了权值初始化对微调的影响,通过改变输出域,根据实验结果和观察结果提出了一种改进的CNN 架构。
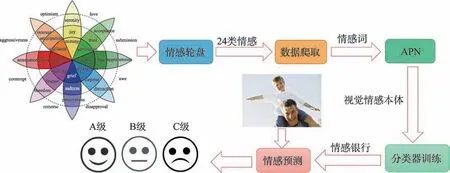
图4 中层语义情感分析流程Fig.4 Middle-level semantic sentiment analysis process
基于管道模式的视觉情感分析中,研究者首先利用深度学习模型建立视觉内容到认知语义的映射关系,然后基于认知语义预测视觉内容的情感取向。一般来说,基于管道模式的深度学习方法更易于理解,因为它们模拟了人类的视觉感知。然而,概念(或事件)检测性能是影响这些方法性能的关键因素。例如,Chen 等升级了文献[37]中提出的SentiBank。他们使用深度卷积神经网络来检测图像中存在的本体概念。文献[40]通过提取一组描述图像的ANP 来表示图像的情感。然后,以相应的ANP 响应作为权重,计算提取出的文本情感值的加权和。利用从图像中提取的ANP 组成文本的情感,而不是只考虑在SentiBank中定义的ANP 响应作为中层表示,最后使用逻辑回归器来推断情感倾向。在最先进的方法中,与用户的社交图像相关的文本噪声问题是非常普遍的。Ahsan 等人提出了一种基于管道模式的深度学习方案来分析社会事件图像的视觉情感。他们首先生成一系列社会事件概念,并利用CNN 架构计算出相应的概念得分,然后根据这些概念得分预测社会事件图像的情感取向。
所有这些视觉情感分析方面的工作都表明了更高精度技术的潜力,然而情绪的多面性表明单独的视觉情感分析将无法在多媒体数据中充分衡量或描述人们的体验倾向和意见。
3 图文融合的舆情情感分析
近年来,在情感分析领域出现了许多新的观点,特别是在视觉情感分析方面。例如,在人工智能领域取得巨大成功的深度学习,已经开始应用于不同类型社交媒体数据的情感分析。当前,研究者们主要致力于社交媒体文本的情感提取。然而单一模态的舆情情感分析有很多不足,其信息很容易受到其他因素的干扰,从而造成情感分析效果不理想。图片包含着太多的个人主观性,不利于情感判断,图5形象化展示了单模态的不足。目前,在舆情信息中,图片是除文本信息以外用户使用最为广泛的数据,因此图文融合的舆情情感分析成为当前的热点。

图5 单模态情感分析的不足Fig.5 Shortcomings of monomodal sentiment analysis
基于图文的舆情情感分析是多模态情感分析的一部分,目前仍处于起步阶段。文献[48]采用了图文融合的情感分析方法,该算法证明了图像特征与文本特征的互补关系。其实验结果表明,相较于单模态的实验结果,基于图文的情感分析具有更好的效果。进行图文融合情感分析,最重要的一步是提取文本特征和图片特征,随后根据图文的融合策略判断情感类型。图文融合舆情情感分析的一般过程如图6所示。
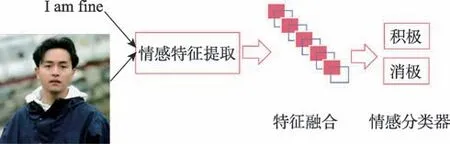
图6 图文融合情感分析过程Fig.6 Image and text fusion sentiment analysis process
图文融合策略主要是关于图文信息的融合和图文相关性的融合,包括特征层融合、决策层融合和一致性回归融合,具体如图7 所示。
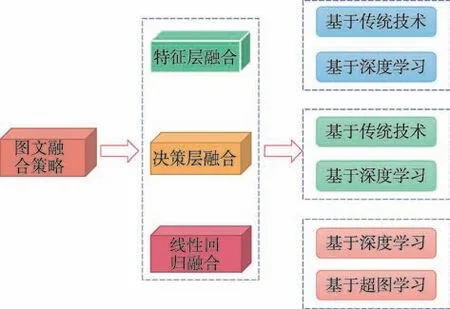
图7 图文融合策略分类Fig.7 Image and text fusion strategy classification
3.1 基于特征层融合的舆情情感分析
基于特征层融合的过程是在特征层上对情感信息进行处理,使其融合特征具有两个模态的信息。首先分别提取文本和图像的情感特征,接着将提取到的特征通过直接或加权连接的方式结合在一起而形成融合情感特征,最后输入到分类器中进行舆情情感分类。特征层融合流程如图8 所示。

图8 特征层融合过程Fig.8 Feature layer fusion process
(1)基于传统技术的情感分析
文献[50]提出了一种跨媒体词袋模型。对于多模态图文分析,通过使用词袋模型赋予文本和图像统一的表示形式,从而形成消息的特征向量。在此基础上,应用Logistic回归进行情感预测。文献[51]基于NN(-nearest neighbor)和Minkowski距离融合了文本和图像特征,使用Bi-gram 模型进行特征提取,其提取文本特征的同时提取图像的颜色和纹理信息,并提出了一种新的基于相似度的邻域分类器。其主要思想为选择有价值的特征,并处理这些消息上的情感极性分类(二分类)。具体过程为:首先计算一个测试集中的帖子和另一个训练集中的帖子的文本和图像的余弦相似度。然后构建一个二维空间,其中两个轴分别代表文本和图像,一个点由文本和图像的余弦相似度组成。最后将该点与(1,1)之间的距离视为最终的相似度(即距离越小,这两个帖子越相似),并基于NN 获得该帖子的分类结果。
(2)基于深度学习的情感分析
文献[52]提出了一种基于卷积神经网络(CNN)的多媒体情感分析方法,其主要针对图像中文本和视觉信息的情感预测问题。该框架的总体架构由三个组件组成:文本CNN、图像CNN 和多CNN。通过两个独立的CNN 学习文本特征和视觉特征,其特征的联合表示作为另一个CNN 的输入以获取两种表示。以此为基础使用Logistic 回归作为分类器进行分类。文献[53]提出了一种多模态情感分析框架,解决了图像局部的高维语义信息问题。对于图像特征的提取,采用了图像描述的方法,并在图像描述模型中采用了目标检测与多示例学习对作为辅助,提取精细化的图像特征。将CNN 编码的图像作为双向网格LSTM 的输入,采用多示例学习(multiple instance learning,MIL)方法和目标检测方法(single shot multibox detector,SSD)分别提取图像全局特征和图像中所有独立物体所在的矩形框。通过注意力模型(attention model)综合了LSTM 的输出与SSD 提取出的两方面信息。对于文本特征,使用多层卷积神经网络(CNN)进行文本特征提取,最后的文本特征经过softmax 全连接层输出。特征融合阶段,为了图像特征与文本特征的统一,首先使用单层的一维卷积对图像特征进行编码,然后把编码后的图像特征与文本特征融合,并经过softmax输出进行情感预测。文献[54]提出了一种图文融合的微博情感分析方法。该方法首先经过参数迁移和微调的方法构建图片情感分类模型FCNN(fine-tuned CNN),得到图片的情感极性概率;然后通过词嵌入技术以及双向网络构建文字情感分类模型WBLSTM(word-embedding bidirectional LSTM),得到文字的情感极性概率;最后根据late fusion 融合思想对图片情感极性概率和文本情感极性概率进行融合,从而对图文微博的情感极性进行预测。文献[55]提出了一种共记忆网络模型进行多模态情感分析,其关键是对图像和文本的双向交互进行建模。首先分别使用一个视觉记忆网络和文本记忆网络提取特征表示,并引入注意力机制聚集关键内容。然后通过共同记忆网络通过迭代将图像特征输入到文本记忆网络中查询关键字,将文本特征输入到视觉记忆网络中查询图像的关键内容,并将图像和文本的最终特征表示向量结合起来,最终通过softmax 进行情感分类。文献[56]提出了一种视觉方面注意网络(visual aspect attention network,VistaNet),其关键在于将视觉信息建模为注意力,而不是特征。VistaNet 框架是一个三层体系结构,底层为单词编码层,通过软注意力机制将每个词语赋予一个在句子表征中的“重要性”相对应的权重。中间层为句子编码层,从底层聚合句子级表示,使用视觉方面注意将其聚合为文档级表示,同时利用视觉信息来增强注意机制。顶层为文档指定情感标签的分类层,获得文档的高级表示之后,利用softmax 进行情感分析。
3.2 基于决策层融合的舆情情感分析
决策层融合首先分别提取文本和图像的情感特征,并将提取的每个模态特征分别输入各自的分类器中进行情感分类,最后根据两个模态的分类结果选择合适的融合规则进行融合和决策。决策层融合流程如图9 所示。
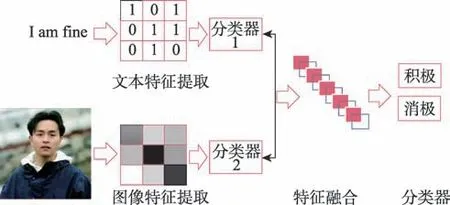
图9 决策层融合过程Fig.9 Decision layer fusion process
(1)基于传统方法的情感分析
文献[57]提出了一种基于转移变量的图文融合微博情感分析方法。首先基于主题情感统一模型构建USAMTV(unsupervised sentiment analysis model based on transition variable)模型(基于转移变量的无监督情感分析模型),该模型通过添加转发主题转移变量和连词情感转移变量分别处理句子主题从属关系和情感从属关系,从而提取文本特征。对于图片特征,根据文献[58]中的视觉语义特征提取方法来进行图片情感分析,并且将其特征以情感浓度指标的方式来影响微博的整体情感倾向,最后整体进行微博的情感分析。
(2)基于深度学习的情感分析
文献[59]提出了一种深度多模态注意融合(deep multimodal attentive fusion,DMAF)模型,该模型利用了视觉和语义内容之间的区别特征和内在关联。首先,提出了两个独立的单峰注意模型(视觉注意力模型和语义注意力模型),分别学习图像和文本中最具辨别力的特征和情感分类。在此基础上,提出了一种基于深度中间融合的多模态注意模型,通过利用不同模式下的互补信息和非冗余信息,将两个单独的注意模型结合起来,挖掘不同模式特征之间的相关性,进而进行多模态情感分析。最后,通过后期融合方案对多模态情感进行分类。
文献[60]提出了一种基于深度卷积神经网络的微博视觉和文本情感分析,其核心为基于CNN的模型学习信息文本和相关图像的更高层次的表示。在文本特征提取方面,采用预先训练的单词向量训练文本DNN(deep convolutional neural network)模型,提取文本特征。图像特征提取方面,通过DropConnect来减少过度拟合来训练模型,提取视觉特征。最后,使用后期融合来分析模型的性能,并且使用Logistic回归进行情感预测。同样是基于卷积神经网络,文献[48]试图通过探索图文情感特征之间的内部联系和互补作用,增强图文微博的情感倾向性预测的准确性。词向量形式的文本和图像分别经过基于CNN的情感分析模型得到对应的文本特征和图像特征,把两种特征分别经过三个基于CNN 的模型(wordlevel CNN、phrase-leval CNN 和sentence-level CNN)的训练得到词语级、短语级和句子级的图文特征并向量化后输入分类器WdCla、PhCla 和StCla,得到三种语义级别的图文情感分类结果。在此基础上构造一个集成分类器EnsCla 进行决策融合,得到最终的图文微博的情感极性。
3.3 基于一致性回归融合的舆情情感分析
特征层融合和决策层融合的方法都忽视了文本和图像特征之间的一致性关系,但是跨模态一致性回归模型则很好地解决了这个问题。其主要思想为同一事物通过不同模态的表示所表达的情感是一致的,因此主要是对两种模态之间的相关性进行学习融合。首先分别提取文本和图像的情感特征,然后将提取的两个模态特征输入回归模型中,通过相关性学习算法学习相关性权重并进行舆情情感分析。一致性回归模型流程图如图10 所示。
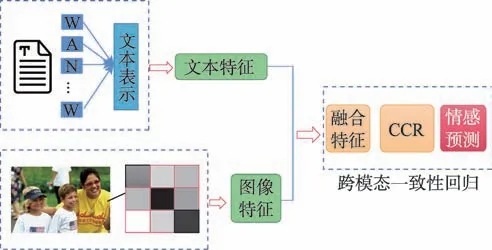
图10 一致性回归模型Fig.10 Consistency regression model
文献[61]提出了一种跨模态一致性回归(crossmodality consistent regression,CCR)模型,用于视觉和文本情感分析。其主要思想是对相关但不同的模态特征加以一致性的约束。在视觉特征提取方面,采用类似于文献[62]的卷积神经网络进行视觉情感分析,在文本特征提取方面,采用最新的分布式文档表示进行文本情感分析。最后,通过视觉和文字的特征,训练出一种跨模式一致的回归模型,模型在相关但不同的模态之间施加一致的约束,通过集成不同的模态特征进行情感分析。文献[64]提出了一个弱监督的多模式深度学习(weakly supervised multimodal deep learning,WS-MDL)模型,该模型在统一的框架中解决了目前多模态融合的两个问题,即挖掘跨多个模态的相关性,以实现模态独立和人工标注的负担和主观性,目前还没有一个大规模的多模态情感数据集具有精确的人工标注。特别的是将来自社交媒体用户贡献的表情通道的情感作为弱标签来初始化模型学习,并使用CNN 和动态CNN 从图像和文本模态中获取倾斜的联合特征。同时,为了训练多模态情感分类器,提出了一种多模态卷积神经网络,它从不同的模式中学习有区别的联合特征表示。为了推断标签噪声,引入了一种弱监督学习范式,通过概率图形模型描述了不同模式下预测标签之间的相关性。实验结果显示,该方案在情感预测方面具有较好的效果。
基于超图的方法除了能够反映高阶信息外,还可以利用大量的未标记数据集,采用传递学习的方式。鉴于此,文献[69]提出了一种名为Bi-MHG(bi-layer multimodal hypergraph learning)的双层多模态超图学习方法。该方法包括两个超图层,即tweet级超图和特征级超图,其目标是捕捉异质模态之间的噪声相关性,以及允许模型接收缺失模态作为输入。用一种新的交替优化方法进行双层超图学习。最后,根据测试微博的相关度得分得到测试微博的情感极性。
现有的多模态情感分析方法大多只考虑数据内容,这些方法很难有效地捕捉视觉和文本表示之间的非线性关系,忽略了社会图像之间的联系信息。针对这些问题,文献[74]提出了一种层次深度融合(hierarchical deep fusion,HDF)模型,该模型能够探索图像、文本及其社会联系之间的跨模态相关性,学习全面的互补特征,从而进行更有效的情感分析。HDF 模型结构如图11 所示。
首先,通过三个层次化LSTM(H-LSTM)网络将视觉内容和文本内容结合起来,并学习图像和文本在三个层次上的相关性。然后,将社会图像中的多种类型的链接转化为一个加权关系网络,通过DeepWalk进行网络嵌入。最后,将联合图像-文本表示和节点嵌入视为输入到多层感知器(multi-layer perceptron,MLP)的两个视图,该多层感知器探索非线性交叉模态相关性,捕获互补信息以进行多模态情感预测。
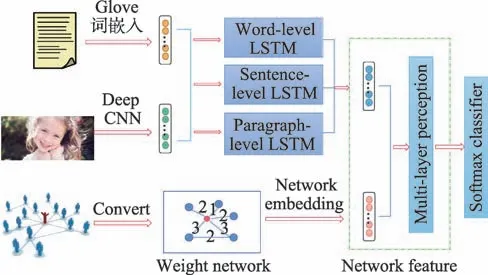
图11 HDF 模型Fig.11 HDF model
文献[76]提出了一种用于多模态情感分析的深层语义网络MultiSentiNet,从图像中提取包括对象和场景在内的深层语义特征作为情感分类的附加信息。具体地,该模型将文本、对象和场景的三重特征定义为多模态tweet 的表示,并将其作为多模态情感分析任务的附加信息。模型结构如图12 所示。
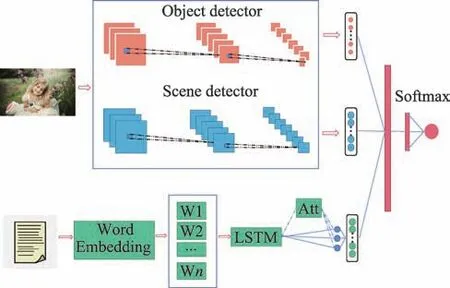
图12 MultiSentiNet模型Fig.12 MultiSentiNet model
在视觉方面,选择VGG模型作为视觉目标提取的目标检测器,同时使用最先进的场景VGG 模型作为场景检测器进行场景特征提取。为了更好地理解文本,采用LSTM 模型进行文本特征提取,同时提出了视觉特征引导的注意机制来提取对情感有重要影响的词语,并将这些信息性词语的表征与视觉语义特征、对象和场景进行聚合。最后利用高级的三重特性:对象、场景和文本来表示多模态tweet。首先使用融合层来聚合这些三重特征,以获得最终的多模态表示,然后在顶部添加一个softmax 分类器进行情感分类,最后提出一个视觉特征引导的注意LSTM 模型来提取对整个tweet 的情感有重要影响的词,并将这些词的表达与视觉语义特征、对象和场景进行聚合。
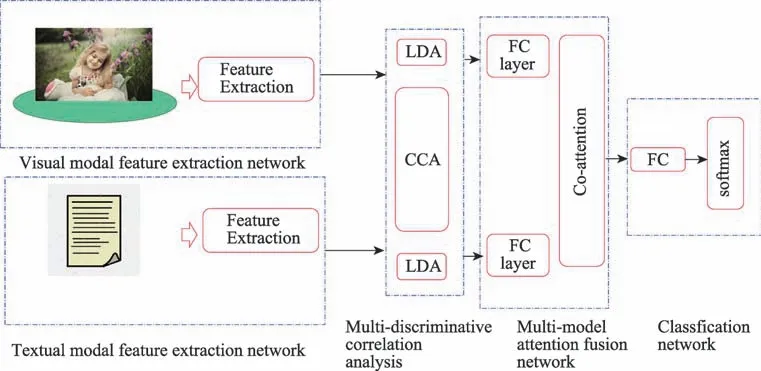
图13 层次化深度关联融合网络Fig.13 Hierarchical and deeply interlinked integration network
文献[79]提出了一种基于层次化深度关联融合网络的多媒体数据情感分类模型,该模型能同时兼顾视觉模态和文本模态最大相关性和两模态各自的线性判别性,解决了图片和文字之间的精细语义配准问题。层次化深度关联融合网络模型如图13 所示。
首先通过特征提取模型、文本模态和视觉模态特征产生最大相关的判别性特征。然后进一步通过co-attention 网络融合特征,进而加大深层融合后的特征表示。最后合并最新的图像视觉特征和文本语义特征,通过全连接神经网络学习后再输入情感分类器进行分类。
4 基于图文舆情情感分析数据集
目前,针对图文情感分析的数据集一般来源于个人制作,对于科研方面基本属于半公开或不公开状态。本文将介绍几种典型的相关公开数据集,以便更好地推动图文舆情情感分析领域的发展。具体如表2 所示。
Yelp 数据集:该数据集创建于2014 年,是涵盖商户、点评和用户数据的一个子集,数据集包括来自于波士顿、芝加哥、洛杉矶、纽约和旧金山关于餐厅和食品的44 305 条评论,244 569 张图片。通过1~5 这5个分值对数据集的情感倾向进行标注。可以用于个人、教育和学术。数据集由5 个文件组成,每个文件分别对应一个对象类型,该文件指定了业务ID、用户ID、星号(介于1 和5 之间的整数值)、审查文本、日期和投票。数据集地址为https://www.kaggle.com/yelpdataset/yelp-dataset。
Tumblr 数据集:该数据集由Bourlai 等人提出。Tumblr 是一种微博服务,用户在上面发布的多媒体内容通常包含图片、文本和标签等。数据集是根据选定的15 种情绪搜索对应的情绪标签的推文,并且只选择其中既有文本又有图片的部分,然后进行了数据处理,删除了那些文本中原本就包含对应情绪词的内容,以及那些不是英文为主的推文。数据集共有256 897 个多模态推文。数据集的情感标注包含高兴、悲伤、厌恶在内的15 种情绪。
MVSA 数据集:该数据集由Niu等人提出,其中的所有图像-文本对都是采用一个公共流API的方式从Twitter 收集,同时采用了406 个情感词汇对其进行过滤,以此来获取有价值的推文。数据集一共有2 592条图文数据,数据集的情感标注是积极、消极和中性3种。数据集地址为http://mcrlab.net/research/mvsa-sentiment-analysis-on-multi-view-social-data/。

表2 图文数据集总结Table 2 Summary of image and text datasets
Flickr 数据集:Flickr 是雅虎旗下的图片分享网站,该数据集由文献[83]提出,用于语言相似性的指称度量的研究。数据集由31 783 张日常活动、事件和场景的照片和158 915 个标题组成。
Twitter15/17 数据集:Twitter15(4 290/1 432/1 459)数据集由Lu 等人提出,用于多模态社交媒体帖子中的姓名标记任务。该数据集通过用体育和社会事件相关的词语作为关键词进行数据查询,包含一对推文及其在2016 年5 月、2017 年1 月和2017 年6 月提取的相关图片。Twitter-17(4 000/3 257/1 000)由Zhang等人提出,用于多模态命名实体识别问题。情感标注为三分类。
Multi-ZOL:该数据集收集整理了中国领先的IT信息和商业门户网站ZOL.com 上的关于手机的评论。原始数据有5 288 条多模态评论,构成了Multi-ZOL 数据集。在这个数据集中,每条多模态数据包含一个文本内容、一个图像集,以及至少一个但不超过六个评价方面,分别是性价比、性能配置、电池、寿命、外观和感觉、拍摄效果和屏幕。对于每个方面,数据集的情感标注是一个从1 到10 的情感得分。数据集下载地址为https://github.com/xunan0812/MIMN。
Twitter 反讽数据集:Twitter 反讽数据集构建自Twitter 平台,由Cai 等提出,包括2.4 万条的tweet,图像和图像属性的样本。数据集按照80%∶10%∶10%的比例被划分为训练集、验证集和测试集。数据集的情感标注为“是讽刺/不是讽刺”二分类。
5 算法评价指标及分析
一般来说,准确度是评估不同算法性能最常用的指标。然而,考虑到基准数据集中样本的不均匀性,仅使用这一指标进行绩效评价是不公平的。为了解决这一问题,更好地展示各算法的实验结果,本文引入准确率(Accuracy)、召回率(Recall)、F1 值三种评价指标进行综合评价。在具体介绍之前先引入几个符号,如表3 所示。
(1)准确率:代表所有预测正确的样本占总样本的比例,其定义如式(1)所示。
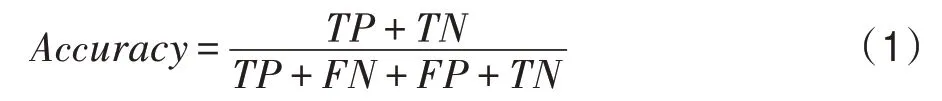

表3 公式符号Table 3 Formula symbols
(2)召回率:针对的是原来的样本,指的是样本中的正例被预测正确的概率,其定义如式(2)所示。

(3)F1值:同时把查准率和查全率考虑其中,让二者同时达到最高,取一个平衡,其定义如式(3)所示。

5.1 基于特征层融合算法分析
表4 给出了基于特征层融合的实验结果。表5总结了基于特征层融合算法的优缺点。通过对其优缺点的分析可知,特征层融合方法虽然综合考虑了两个模态间的信息,但在处理特征间的差异问题上仍存在缺陷。例如VistaNet 模型,其优势是第一次将图像作为注意力纳入基于评论的情感分析。然而当评论中存在反讽情绪时,会导致模态间的差异性逐渐增大,情感不一致的问题愈加突出。
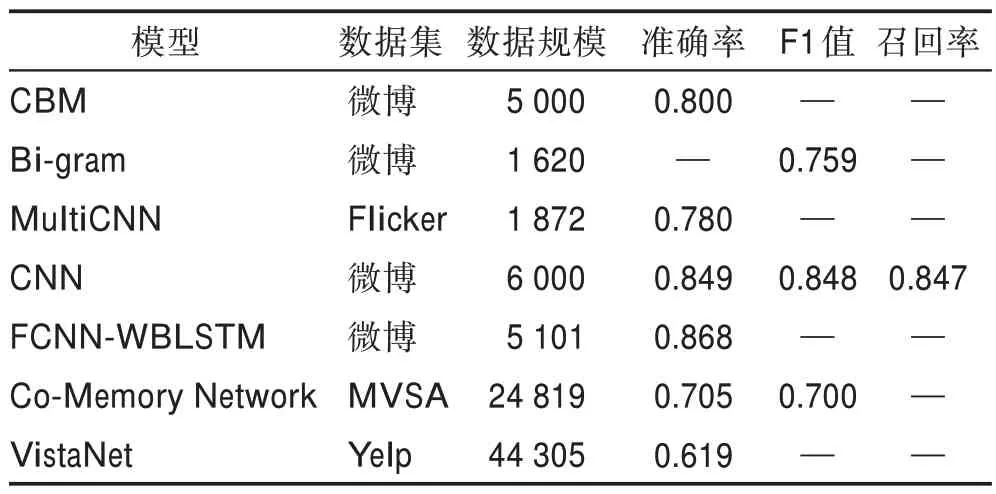
表4 特征层融合算法实验结果Table 4 Experimental results of feature layer fusion algorithms
5.2 基于决策层融合的算法分析
决策层融合避免了两种模态特征由于本质上不同造成的干扰。表6 给出了基于决策融合的实验结果。表7 列出了决策层融合算法优缺点,从中可以看出特征层融合的不足之处是无法学习到特征之间的情感互补关系。例如DNN 模型,其不足之处是文本和视觉内容之间的关系经常被忽略。因此在某种意义上,如何将两个模态信息进行有效融合仍是图文融合舆情情感分析的挑战性问题。

表5 特征层融合算法优缺点Table 5 Advantages and disadvantages of feature layer fusion algorithms
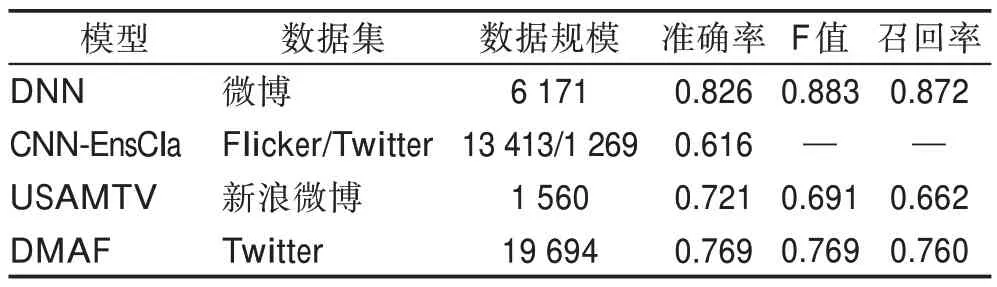
表6 决策层融合算法实验结果Table 6 Experimental results of decision layer fusion algorithms
5.3 基于一致性回归模型算法分析
相较于决策层融合,一致性回归融合重点关注了文本和图像的情感特征的一致性。表8 给出了基于一致性回归融合的实验结果。表9 总结了一致性回归算法优缺点,从中可以看出,虽然一致性回归融合关注了情感特征的一致性,但忽略了文本和图像情感特征之间的情感异性。
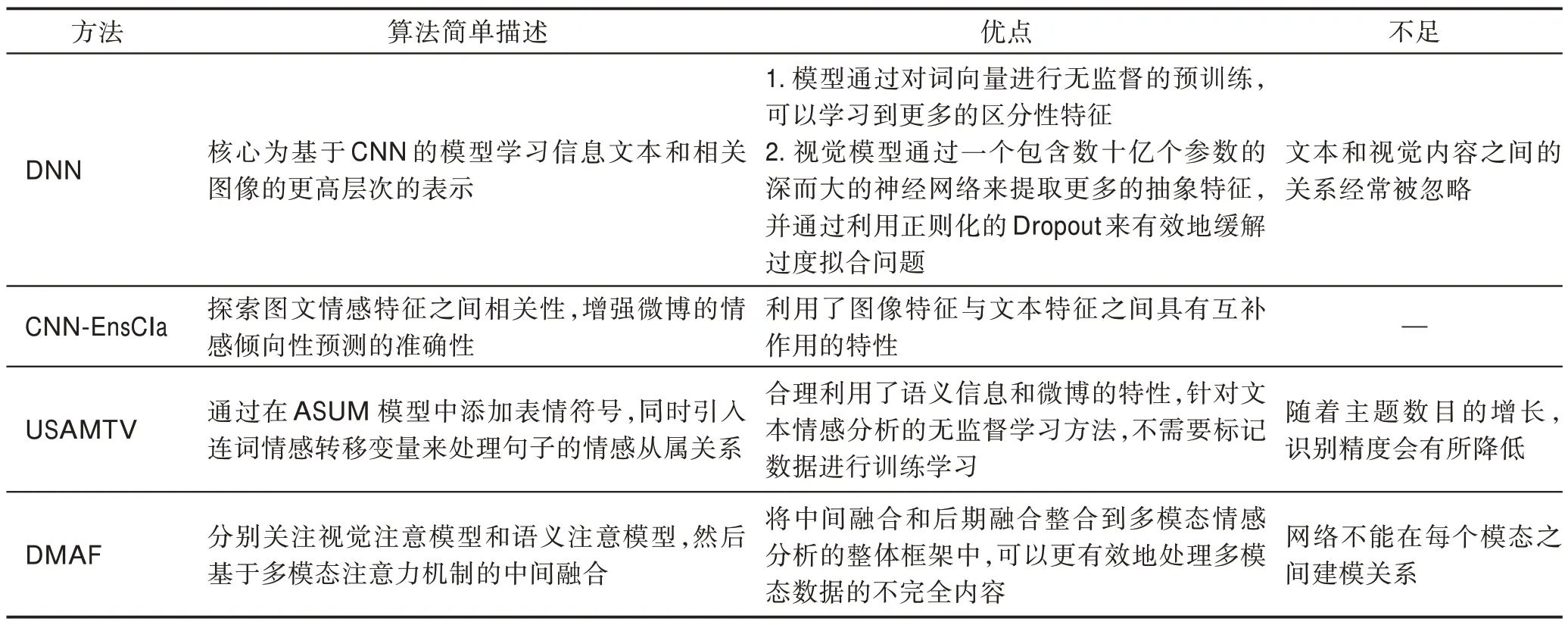
表7 决策层融合算法优缺点Table 7 Advantages and disadvantages of decision layer fusion algorithms
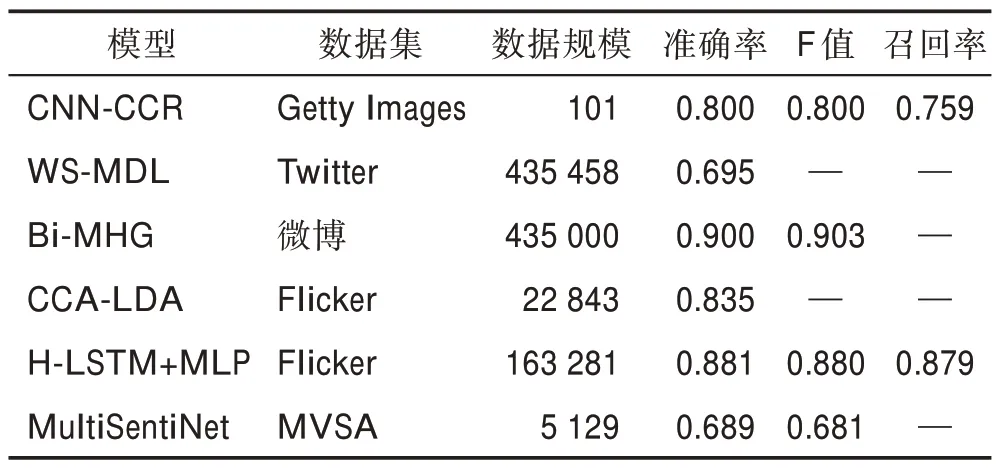
表8 一致性回归融合算法实验结果Table 8 Experimental results of consistent regression fusion algorithms
6 总结和展望
总体而言,得益于深度神经网络强大的特征表达能力,基于深度学习的联合视觉文本情感分析和视听内容多模态情感分析取得了突破性进展。尽管如此,社交网络中的视觉文本数据和网络视频的多模态情感分析仍然有许多问题亟待解决。
(1)现有的视觉-文本联合情感分析方法大多采用不同的融合策略来整合文本和视觉信息,忽略了文本和视觉内容之间的相关性。此外,大量深度学习模型已被应用于现有的联合视觉-文本情感分析研究中,而社交媒体文本情感分析的丰硕成果却往往被忽视。因此,如何将已有的文本情感分析研究成果应用到视觉-文本情感联合分析中,仍值得深入研究。
(2)基准数据集的缺乏是多媒体情感分析,尤其是视觉分析和多模态分析的瓶颈。此外,样本的不均匀性和情感标签的不可靠性增加了在不同方法之间进行公平比较的难度。例如,相当多的研究人员在他们自己的数据集上进行实验,其中许多数据集只包含有限数量的样本,这些样本的标签并不完全正确。更糟糕的是,阳性样本和阴性样本的数量往往有很大的差异。在这些数据集上的实验结果并不令人信服,因为没有可信的数据集,性能评估就没有意义。然而,现有的研究很少关注这一问题。因此,收集足够的样本,给它们贴上可靠的情感标签,并将其公之于众,也是一项有意义的任务。
(3)现有的基于管道模式的视觉情感分析研究通常使用一组概念(如形容词和名词)来构建描述视觉内容的本体。在概念检测过程中,要么对整个图像进行聚焦,要么只对其中的局部对象进行聚焦,但人类对视觉内容的感知是多维的。因此,可以对视觉内容中的概念进行整体和局部的检测,从而形成多角度、多层次的视觉内容描述,提高情感分析的性能。然而,如何全面、统一地描述社交媒体中各种各样的视觉内容并有效检测情感相关语义,仍是一个有待解决的问题。
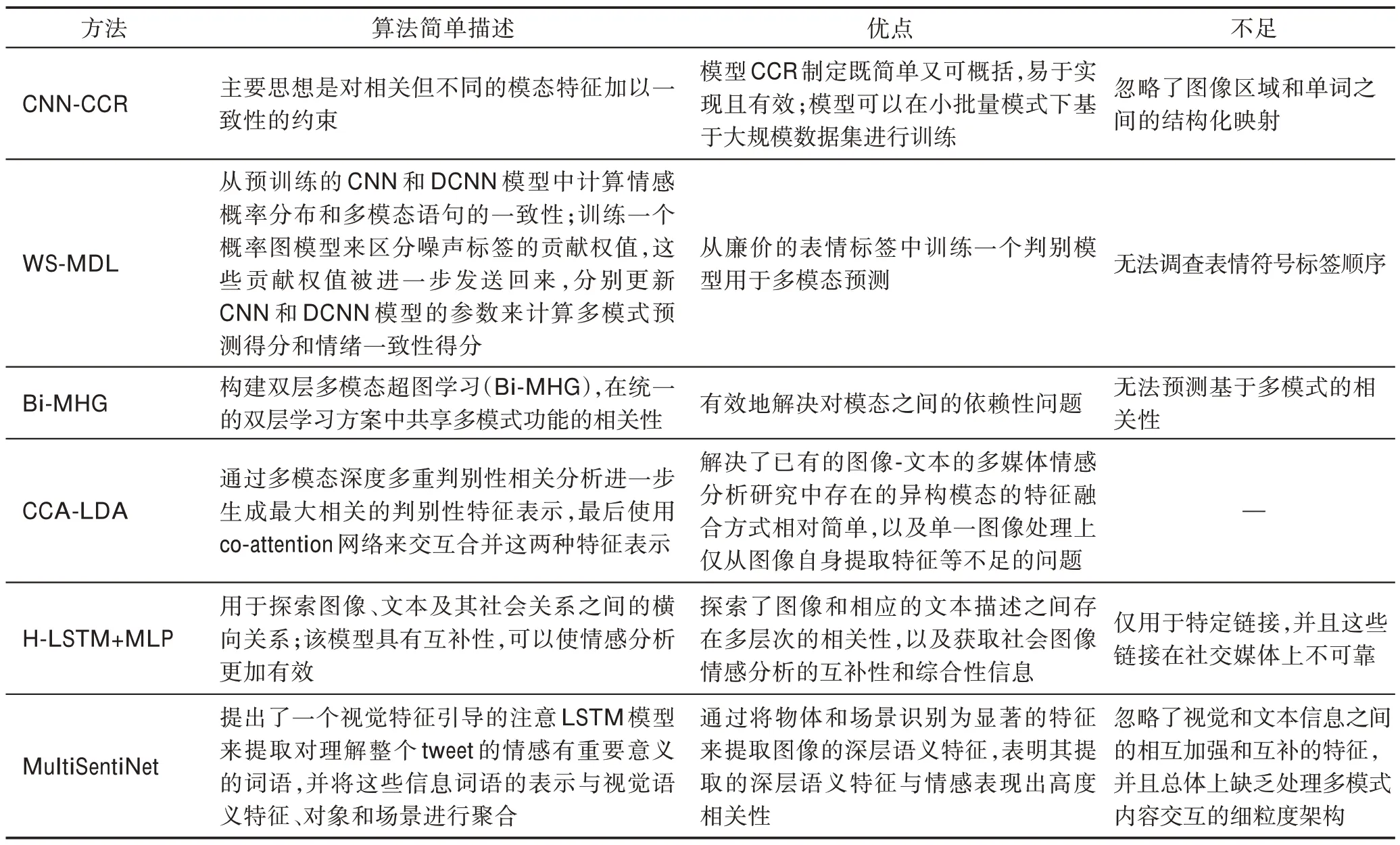
表9 一致性回归融合算法优缺点Table 9 Advantages and disadvantages of consistent regression fusion algorithms
(4)目前,社交媒体用户将图像、视频等视觉内容与文字描述一起发布是非常常见的。在大多数情况下,文本内容和视觉内容之间存在相关性。一方面,文本描述可用于为相应的视觉内容生成情感标签。另一方面,在视觉-文本情感联合分析中,可以综合利用视觉和文本的内容来获得更可靠的预测。然而,社交媒体消息的文本描述可能会产生噪音或误导,其原因是评论可能与相应的图像内容无关。在这种情况下,跨媒体的做法将产生负面影响。因此,无论是视觉情感分析,还是联合视觉文本情感分析,挖掘和评价文本与视觉内容之间的相关性并加以利用都是一个关键问题。
7 结论
随着社会媒体的迅速发展,多媒体数据已经成为人类情感和观点的重要载体,因而对社交网络中的多媒体内容进行情感分析具有重要的科学研究和实际应用价值。本文在对网络舆情情感分析的相关文献进行全面回顾的基础上得出如下结论:多模态用于网络舆情情感分析是利用互补信息渠道进行情感分析的一种有效方法,其通常优于单模态的分析方法。最后,本文深入探讨了潜在的研究方向和研究趋势。
